DataWorks lets you build an offline data warehousing and analytics system on MaxCompute. From the DataWorks console, configure MaxCompute nodes, enable periodic scheduling, and manage metadata to keep data pipelines running efficiently.
This topic covers billing, environment setup, permission management, and core development workflows.
How it works
DataWorks and MaxCompute operate as three distinct layers:
-
DataWorks — the orchestration layer. It handles task development, scheduling, data governance, and O&M monitoring.
-
MaxCompute — the compute and storage layer. All SQL execution, data storage, and job processing happen here.
-
Resource groups — the execution layer. They provide the compute capacity that runs your scheduled tasks and data synchronization jobs.
A typical end-to-end workflow looks like this:
-
Sync source data into MaxCompute using Data Integration.
-
Develop and schedule ODPS SQL tasks in DataStudio.
-
Deploy tasks to the production environment.
-
Monitor and troubleshoot scheduled runs in Operation Center.
Understanding this separation matters for billing: DataWorks charges for orchestration (editions and resource groups), while MaxCompute charges separately for compute and storage. See Billing for details.
Prerequisites
Before you begin, make sure you have:
-
DataWorks activated. See Purchase.
-
MaxCompute activated. See Activate MaxCompute.
-
A DataWorks workspace created. See Create and manage workspaces.
Billing
Using DataWorks DataStudio and Operation Center with MaxCompute generates two separate bills: one from DataWorks, one from MaxCompute (and any other Alibaba Cloud services used).
DataWorks fees
| Fee | Description |
|---|---|
| Edition fee | Charged when you purchase DataWorks Standard, Professional, or Enterprise Edition. |
| Scheduling resource fee | Scheduling resources are required to run periodic tasks. Purchase a serverless resource group (recommended) or an old-version exclusive resource group. |
| Synchronization resource fee | Data synchronization tasks consume both scheduling and synchronization resources. Purchase a serverless resource group (recommended) or an old-version exclusive resource group. |
A single serverless resource group covers task scheduling, data synchronization, and DataService Studio.
Scheduling fees do not apply when you:
-
Run tasks manually using Run or Run with Parameters in the DataStudio toolbar.
-
Run tasks that fail or run as dry runs.
For details on how scheduling fees are calculated, see Issuing logic of scheduling tasks in DataWorks.
Fees from other Alibaba Cloud services
These charges appear on the bills of the respective services, not DataWorks.
| Fee | When it applies |
|---|---|
| Database fees | Running data synchronization tasks that read from or write to databases |
| MaxCompute computing and storage fees | Running tasks on ODPS SQL nodes that create tables or process data in MaxCompute |
| Network fees | Establishing network connections using Express Connect, Elastic IP Address (EIP), or Internet Shared Bandwidth |
For MaxCompute billing details, see Billable items of MaxCompute.
Environment preparation
Complete this section before developing tasks. After finishing, you will have:
-
A DataWorks edition and resource group configured for your workload.
-
A MaxCompute project associated with your DataWorks workspace as a data source.
-
Workspace members added with the appropriate roles for collaborative development.
Select an edition and resource group
| Item | Options | Reference |
|---|---|---|
| DataWorks edition | Basic Edition: Covers cloud data migration, task development, scheduling, and data governance. Standard, Professional, or Enterprise Edition: Required for advanced data governance and data security features. | Compare DataWorks editions |
| Resource group | Serverless resource group (recommended): One resource group serves scheduling, data synchronization, and DataService Studio simultaneously. Old-version exclusive or shared resource group: Meets basic scheduling needs. Note that old-version resource groups will be discontinued. | Overview of DataWorks resource groups |
Set up the development environment
| Task | What it involves | Reference |
|---|---|---|
| Set up data synchronization | Add a MaxCompute project to your workspace as a data source. Synchronization tasks can only be configured after the data source is added. | Associate a MaxCompute computing resource |
| Set up data development and analysis | Add a MaxCompute project as a data source and associate it with DataStudio to enable task development, data analysis, and periodic scheduling. | Associate a MaxCompute computing resource. Then follow Preparations before data development: Associate a computing resource or a cluster with DataStudio. |
| Set up collaborative development | Add RAM users to your workspace as members and assign the Development role to enable collaborative development. | Add and manage workspace members and their role permissions |
Permission management
DataWorks uses a two-level permission model:
-
Data access permissions — control which MaxCompute tables a RAM user can query.
-
Service and feature permissions — control which DataWorks console features a RAM user can access.
Data access permissions
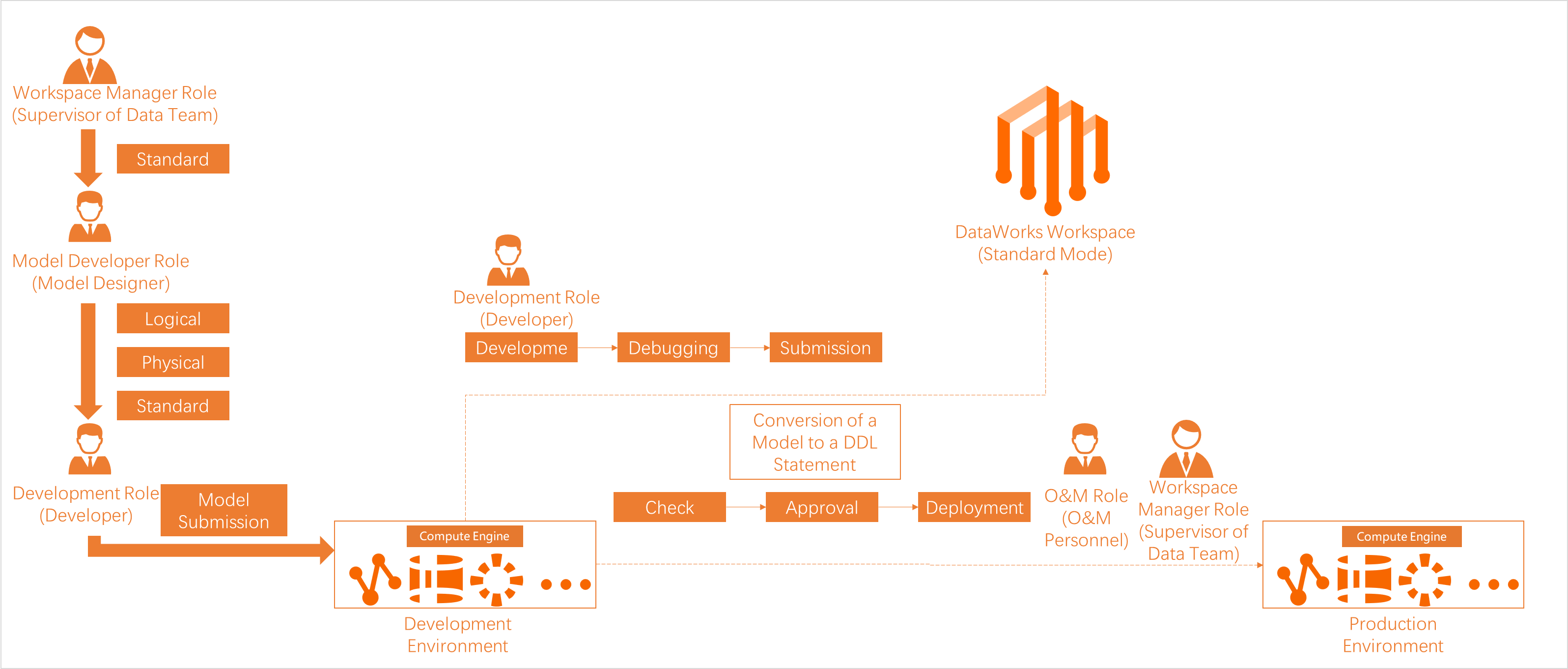
You can use an ODPS SQL or ad hoc query node to query data in MaxCompute tables. DataWorks workspaces run in either basic mode or standard mode. This topic uses a workspace in standard mode, which supports fine-grained permission management and isolation between development and production environments.
In standard mode, two different identities execute tasks:
-
Development environment: The personal Alibaba Cloud account of the task executor runs tasks by default.
-
Production environment: A scheduling access identity (an Alibaba Cloud account) runs tasks. This identity has high permissions on the production MaxCompute project.
Which account executes a query depends on how you reference the project in SQL:
| SQL pattern | Development environment | Production environment |
|---|---|---|
select col1 from projectname_dev.tablename; (dev project) |
Personal account of the task executor | Scheduling access identity |
select col1 from projectname.tablename; (prod project by name) |
Personal account of the task executor (requires Security Center permission request to access prod data) | Scheduling access identity |
select col1 from tablename; (current project) |
Personal account of the task executor | Scheduling access identity |
To view which MaxCompute projects are associated with each environment and the accounts configured for them, go to the Workspace page and check the Compute Engine Information section. For details, see Associate a MaxCompute computing resource.
RAM user permissions by environment:
After you assign a RAM user a workspace-level role, their MaxCompute permissions differ by environment:
-
Development environment: The RAM user is automatically granted the permissions of the corresponding role in the MaxCompute development project.
-
Production environment: The RAM user has no default permissions. To query tables in the production MaxCompute project, go to Security Center to request the required permissions.
For a full reference on MaxCompute data permissions, see MaxCompute data permissions.
Service and feature permissions
Before a RAM user can develop data in DataWorks, assign them a workspace-level role. See Best practices: Grant permissions to RAM users.
Two authorization mechanisms are available:
-
RAM policy-based authorization: Controls access to DataWorks service modules (such as preventing access to Data Map) and console-level operations (such as deleting a workspace).
-
Role-based access control (RBAC): Controls access to workspace-level modules (such as DataStudio development operations) and global-level modules (such as Data Security Guard).
Getting started
Data integration
Data Integration reads data from and writes data to MaxCompute. Synchronization flows in both directions: from an external data source into MaxCompute, or from MaxCompute into an external system.
Supported synchronization scenarios: batch synchronization, real-time synchronization, and full and incremental synchronization.
To choose the right synchronization scenario, see Data Integration overview.
Data modeling and development
Data Modeling
Data Modeling is the starting point for end-to-end data governance. It applies the Alibaba data mid-end methodology to structure enterprise data using four modules: data warehouse planning, data standard, dimensional modeling, and data metric. This gives teams a shared framework for interpreting business data consistently.
DataStudio
DataStudio wraps the MaxCompute compute engine so you can develop and schedule tasks without writing complex command-line scripts. It supports:
-
Data development: Create and schedule different node types — ODPS SQL, PyODPS 2, PyODPS 3, ODPS Spark, MaxCompute Script, MaxCompute MR, and general-purpose nodes such as Shell, Branch, Assignment, Do-while, and For-each.
-
Data synchronization: A subset of batch and real-time synchronization scenarios. See Data Integration for the full scenario list.
Useful references for task development:
After developing tasks, complete the following steps before production:
-
Configure scheduling properties — Set scheduling dependencies and parameters to enable periodic execution.
-
Debug nodes — Run tasks in the development environment to validate logic and avoid wasting compute resources in production.
-
Deploy nodes — Deploy tasks to the production environment. Deployed tasks appear on the Auto Triggered Nodes page in Operation Center.
-
Manage nodes — Deploy, undeploy, or batch-update scheduling properties for multiple tasks.
-
Manage the development process — Use code review, forceful smoke testing, and customizable code review workflows to enforce development standards.
References: Scheduling properties overview, Task debugging process, Publish tasks, Batch operations, Development process control.
Operation Center
Operation Center is an end-to-end O&M and monitoring platform for scheduled tasks. Use it to:
-
View task status and run history.
-
Run intelligent diagnostics and rerun failed tasks.
-
Set up intelligent baselines to monitor and enforce output-time SLAs for critical tasks.
Data Quality
Data Quality monitors data across the end-to-end R&D process by combining rule-based quality checks with task scheduling. When a quality rule is violated, DataWorks alerts you and can block downstream tasks from running until the issue is resolved.
Data governance
After you associate a MaxCompute data source with a workspace, DataWorks automatically collects metadata from it. Three modules support data governance:
| Module | Description | Reference |
|---|---|---|
| Data Map | Enterprise-grade metadata management platform. Search, browse, and understand data assets across your organization based on unified metadata services. | Data Map overview |
| Security Center / Data Security Guard / Approval Center | End-to-end data security governance. Covers data asset classification, sensitive data identification, access authorization management, data masking, access audit, and risk detection. | Security Center overview, Data Security Guard overview, Approval Center overview |
| Data Governance Center | Automatically identifies governance issues based on experience-derived rules and provides solutions covering both pre-event prevention and post-event remediation. | Data Governance Center overview |
Data analysis and services
| Module | Description | Reference |
|---|---|---|
| DataAnalysis | Run SQL-based queries online, explore data, edit and share query results, save results as chart cards, and generate visualized reports for daily reporting. | DataAnalysis overview |
| DataService Studio | Build and publish API services for internal and external consumers. Manages APIs centrally so teams can share and access data through a unified service layer. | DataService Studio overview |
Open Platform
Open Platform lets your application systems integrate with DataWorks programmatically.
| Module | What it does | Reference |
|---|---|---|
| OpenAPI | Call DataWorks API operations from your applications to automate big data processing, reduce manual O&M, and minimize data risks. | OpenAPI |
| OpenEvent | Subscribe to DataWorks change events so your applications can detect and react to pipeline state changes in real time. | OpenEvent overview |
| Extensions | Register a local program as an extension to manage extension point events and processes in your DataWorks workspace. | Extensions overview |
Appendix: Relationship between DataWorks and MaxCompute
DataWorks provides orchestration capabilities — scheduling, metadata management, data governance, and data security — while MaxCompute handles all data computing and storage.
In a workspace in standard mode, you associate separate MaxCompute compute engines with the development and production environments. This isolates storage and resources between the two environments.
For basic mode workspaces, only the production environment is available, and you can associate only one MaxCompute compute engine.
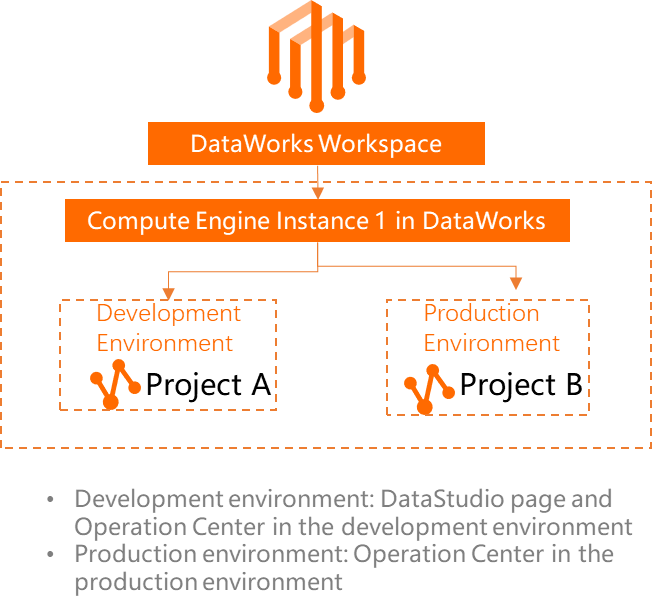
-
To add a MaxCompute data source, associate it with DataStudio, and view which MaxCompute projects are used in each environment, see Associate a MaxCompute computing resource.
-
To understand how DataWorks issues and tracks scheduled tasks, see Issuing logic of scheduling nodes in DataWorks.