Use the HTTP trigger node to let an external scheduling system trigger a DataWorks workflow after the external job completes.
Prerequisites
Before you begin, ensure that you have:
-
DataWorks Enterprise Edition or higher
-
A workflow with the target compute node already created (for example, a MaxCompute SQL node)
How it works
The HTTP trigger node acts as a bridge between your external scheduler and DataWorks. It does not run computing tasks itself—it waits for a trigger command from outside, then unblocks downstream nodes.
Two deployment patterns:
No upstream nodes
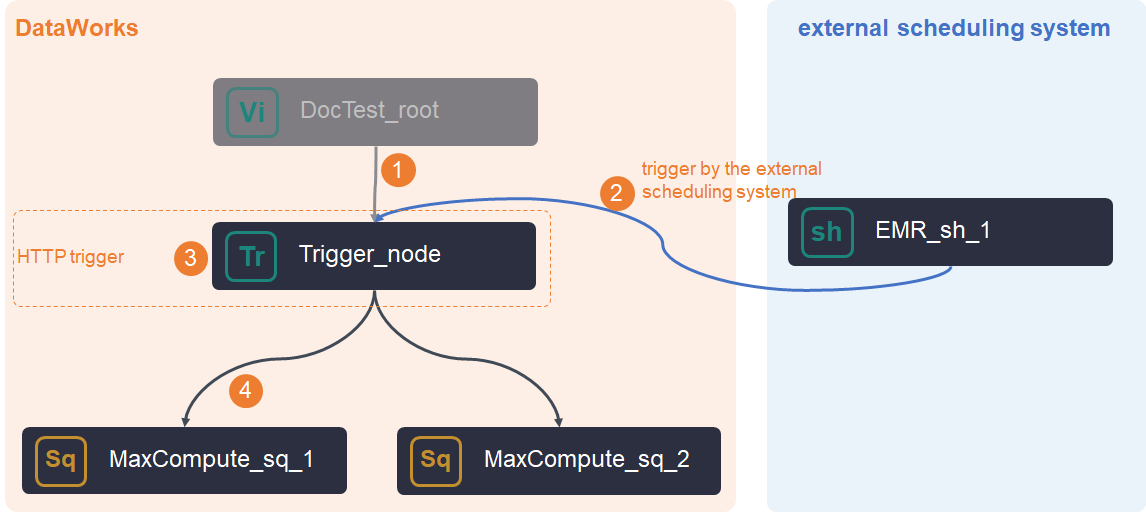
Create the HTTP trigger node, configure the trigger in your external system, and set up scheduling dependencies in DataWorks.
With upstream nodes
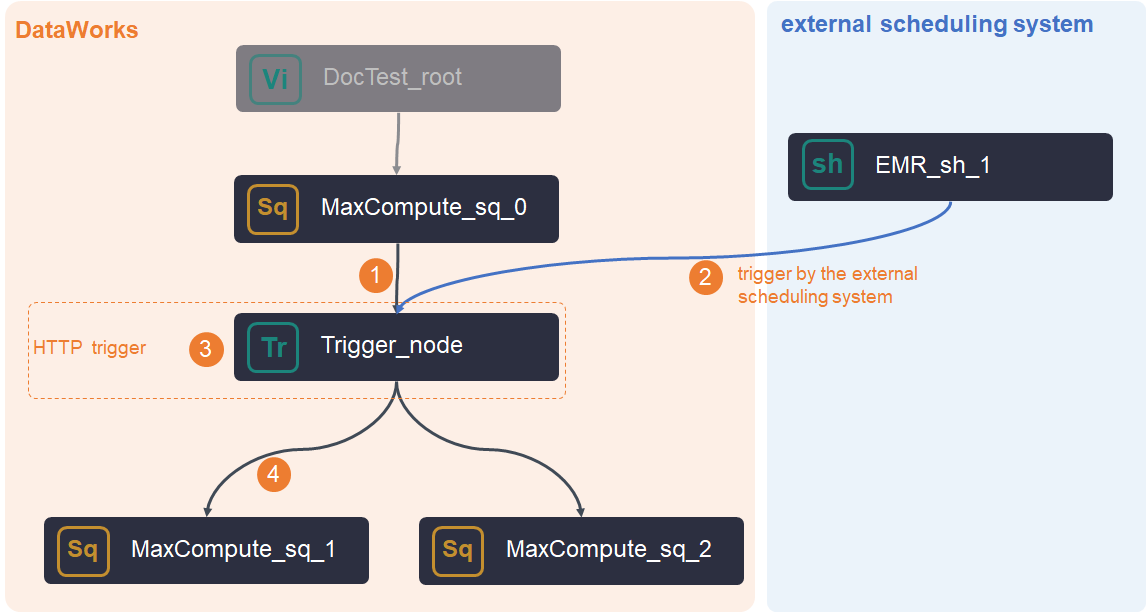
The node triggers downstream tasks only after both conditions are met: all upstream nodes complete successfully, and the external system issues a trigger command.
If the external system sends the command before upstream nodes finish, DataWorks holds the command and releases it once upstream nodes complete.
The trigger command is valid for 24 hours. If upstream nodes do not complete within this window, the command expires and you must reissue it.
Limitations
-
Requires DataWorks Enterprise Edition or higher. See Feature details by DataWorks edition.
-
Supports only T+1 instance generation—the external system can trigger the node starting from the day after it is deployed to production.
-
Cannot be triggered by data backfill instances. To get historical run results for downstream nodes, run a data backfill operation (see Data backfill instance O&M). Backfill bypasses the external trigger and runs downstream nodes directly, so you cannot use it to test external triggering.
-
Acts only as a trigger and cannot run computing tasks directly. Configure the task node as a downstream node of the HTTP trigger node.
-
If you rerun the trigger node after the workflow runs normally, also issue a new trigger command from your external system. Rerunning the HTTP trigger node does not re-trigger downstream nodes that already completed successfully.
-
Supported regions: China (Hangzhou), China (Shanghai), China (Beijing), China (Shenzhen), China (Chengdu), China (Hong Kong), Japan (Tokyo), Singapore, Malaysia (Kuala Lumpur), Germany (Frankfurt), and US (Silicon Valley).
Trigger logic
The HTTP trigger node fires only when all of the following conditions are true:
| Condition | What to check |
|---|---|
| A cycle instance exists for the node | Find it in the Cycle Instance panel of Operation Center |
| The instance is in Pending Trigger state | A successfully triggered instance cannot be triggered again |
| All parent nodes have completed successfully | Instances are in the success state |
| The scheduled time of the cycle instance has passed | Check the instance schedule |
| The scheduling resource group has sufficient resources | Verify resource group capacity |
| The node is not frozen | Check the node status in Data Studio |
Tip: The two conditions most commonly missed are the 24-hour command validity window and the Pending Trigger state requirement. If a trigger command fails silently, check these first.
Create an HTTP trigger node
-
Log on to the DataWorks console. In the top navigation bar, select the region. In the left-side navigation pane, choose Data Development and O&M > Data Development, select the workspace, and click Go to Data Development.
-
On the Data Studio page, hover over the
 icon and select Create Node > General > HTTP Trigger. Alternatively, open the target workflow, right-click General, and select Create Node > HTTP Trigger.
icon and select Create Node > General > HTTP Trigger. Alternatively, open the target workflow, right-click General, and select Create Node > HTTP Trigger. -
In the Create Node dialog box, configure Path and Name, then click Confirm.
-
Click Properties on the right side of the node editor to configure scheduling properties. See Configure basic properties for details.
The default upstream node is the workflow root node. Configure any additional upstream nodes manually.
-
Save and submit the node:
-
Click the
 icon to save the node.
icon to save the node. -
Click the
 icon to submit.
icon to submit. -
In the dialog box, fill in Change description and click OK.
-
If the workspace is in standard mode, click Deploy in the upper-right corner after submitting. See Deploy tasks.
ImportantConfigure Rerun and Parent Nodes on the Properties tab before submitting.
-
-
For ongoing node management, see Perform basic O&M operations on auto triggered nodes.
Trigger the node from an external system
All methods call the RunTriggerNode API (version 2020-05-18).
API
For information about how to call the API, see RunTriggerNode.
Java SDK
-
Add the DataWorks SDK dependency to your
pom.xml:<dependency> <groupId>com.aliyun</groupId> <artifactId>dataworks_public20200518</artifactId> <version>8.0.0</version> </dependency>For SDK installation, see Get started with Alibaba Cloud SDK V1.0 for Java.
-
For a complete code sample, go to the RunTriggerNode debug pageRunTriggerNode debug page and click the SDK Sample tab.
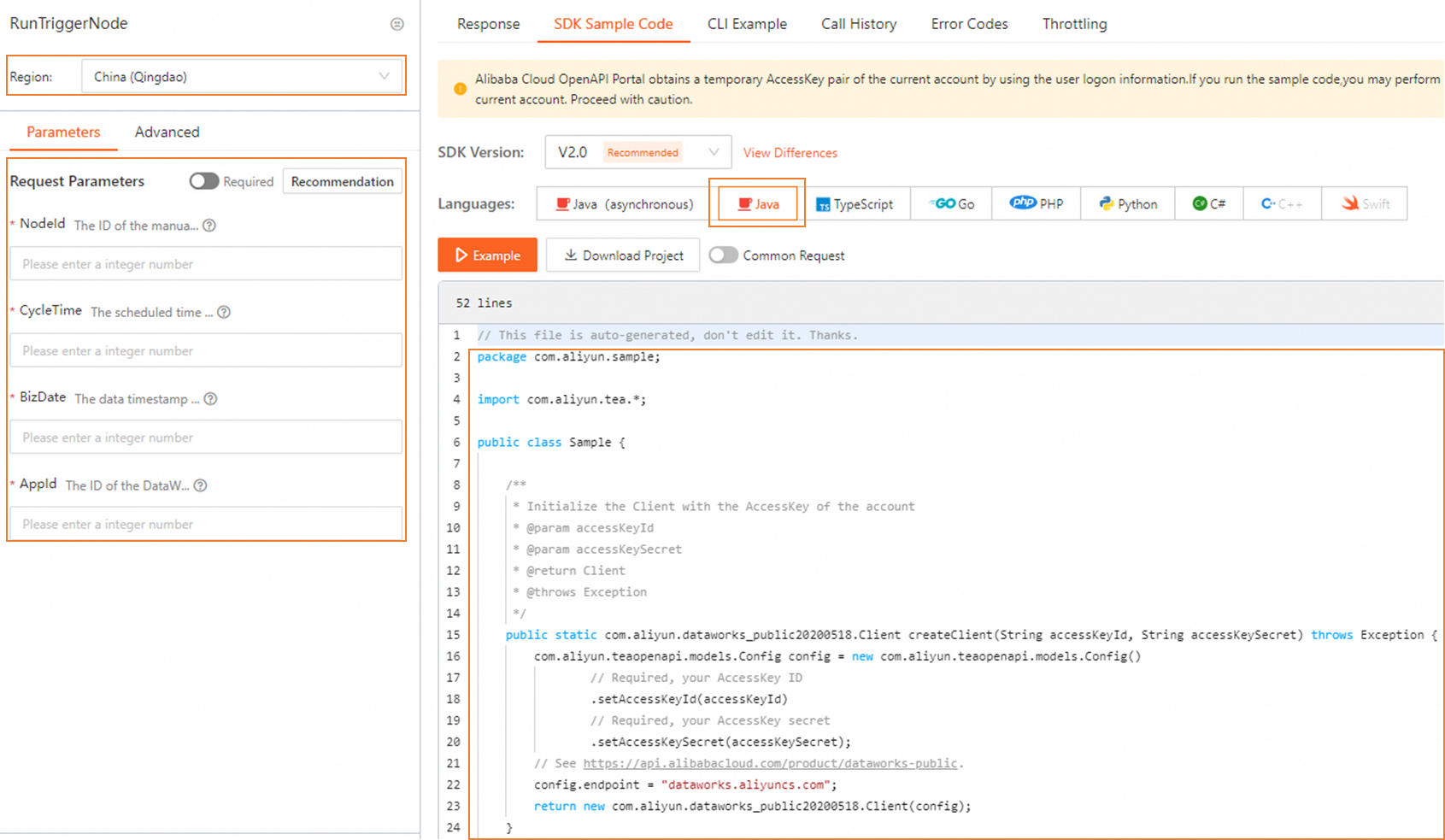
Python SDK
-
Install the DataWorks SDK:
pip install aliyun-python-sdk-dataworks-public==2.1.2For SDK installation, see Integrate an SDK.
-
For a complete code sample, go to the RunTriggerNode debug pageRunTriggerNode debug page and click the SDK Sample tab.
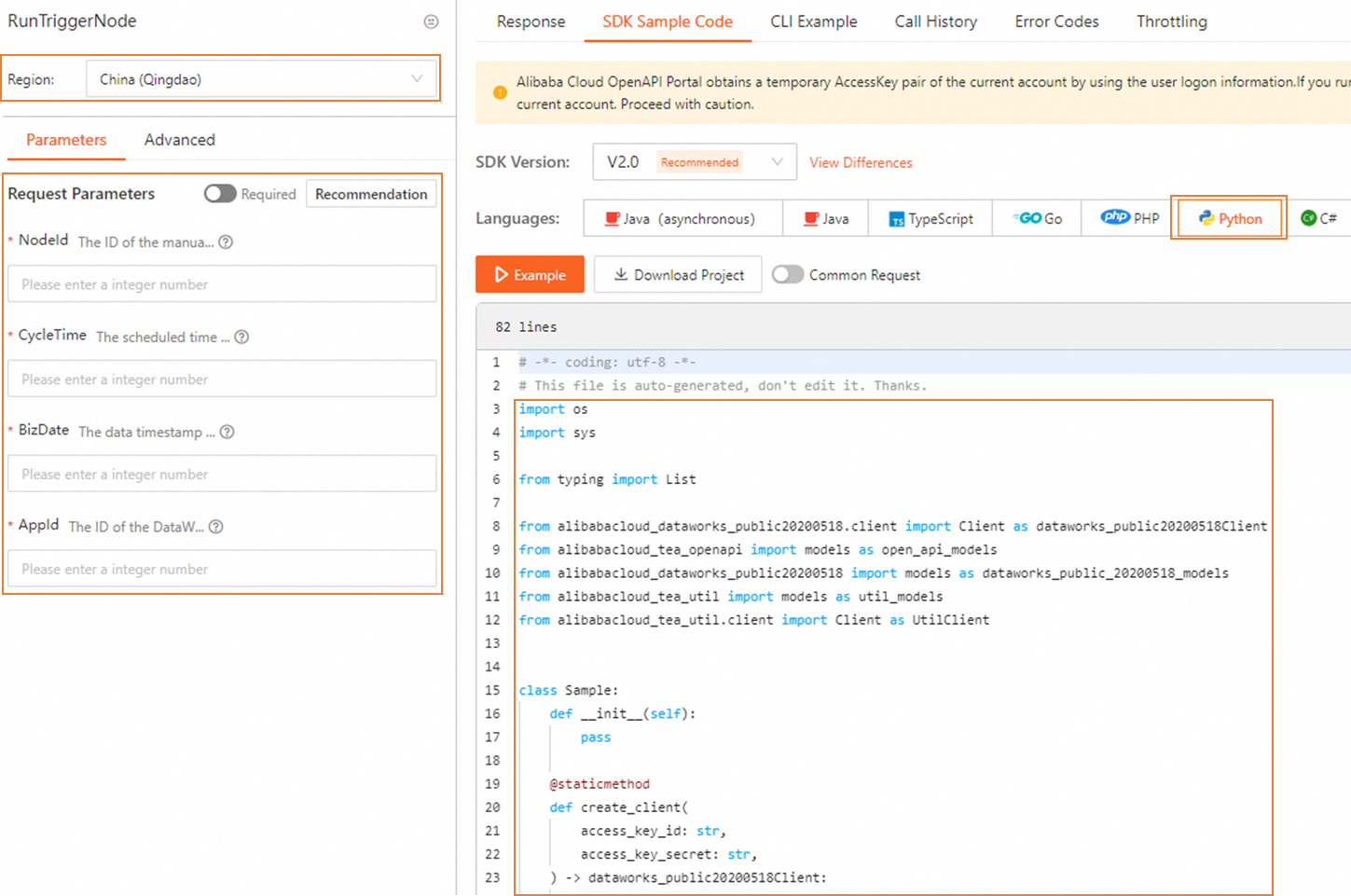
Verify the trigger
After issuing a trigger command, confirm the node ran successfully:
-
In Operation Center, open the Cycle Instance panel and find the instance for the HTTP trigger node.
-
Confirm the instance status has changed from Pending Trigger to success.
-
Check that downstream nodes are running or have completed.
If the trigger does not fire, verify the conditions in Trigger logic, and confirm the command was issued within the 24-hour validity window.