A for-each node iterates over the result set returned by an assignment node, running the inner workflow once per element or row. Use for-each nodes when your pipeline needs to process a list of values — such as dates from a Shell node or query results from an ODPS SQL node — one item at a time.
Key concepts
| Term | Description |
|---|---|
| for-each node | A special DataWorks node that loops through the output of an assignment node. Loops run serially — each loop starts only after the previous one completes. |
| assignment node | The upstream node that supplies the dataset to iterate over. Must be configured as the ancestor node of the for-each node. |
| inner node | A node inside the for-each node's inner workflow. When you create a for-each node, DataWorks automatically creates three inner nodes: a start node, a Shell node, and an end node. |
| start node / end node | Markers for the beginning and end of each loop iteration. They do not process any loop task. |
Edition requirement
For-each nodes require DataWorks Standard Edition or above. For edition differences, see Differences among DataWorks editions.
How it works
Composition of a for-each node
When you create a for-each node, DataWorks automatically creates three inner nodes organized into an inner workflow:
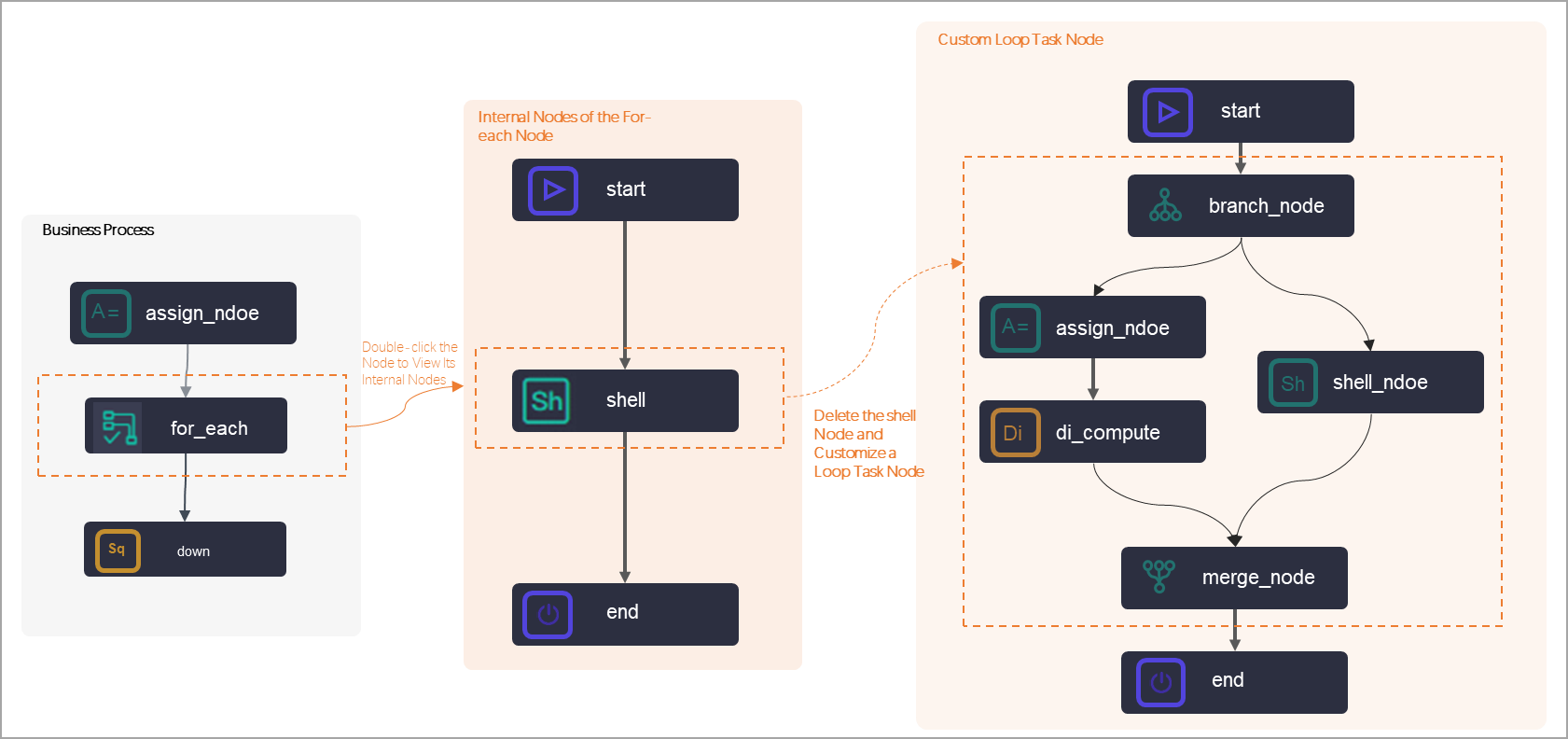
| Inner node | Role |
|---|---|
| Start node | Marks the start of each loop iteration. Does not process any task. |
| Shell node | The default loop task node. Delete it and replace it with your own nodes if needed. |
| End node | Marks the end of each loop iteration. Does not process any task. |
The inner workflow must always start with the start node and end with the end node. The number of loops is determined by the assignment node's output, not the end node.
Customizing the inner workflow
Delete the dependencies between existing inner nodes and wire up your own. For complex loop tasks, add multiple inner nodes and connect them as needed. If any inner node uses a branch node for logical decisions, include a merge node as well.
How the for-each node relates to its assignment node
The relationship between a for-each node and its assignment node works like a for loop in code:
# Assignment node output (the dataset)
data = [element_0, element_1, element_2, ...]
# For-each node execution (one iteration per element/row)
for i in range(len(data)):
process(data[i]) # inner workflow runs hereThe assignment node produces the dataset (data). The for-each node iterates over it, exposing built-in variables you can reference inside the inner workflow.
Relationship to the workflow
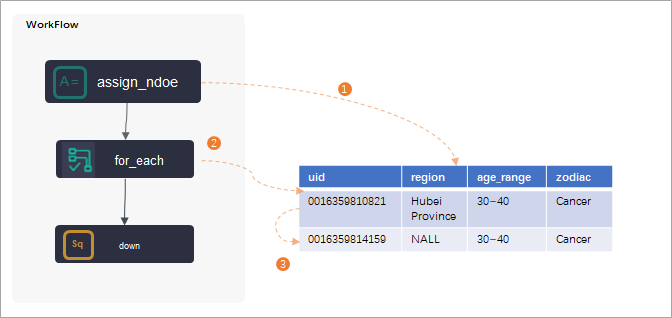
The assignment node must be configured as the ancestor node of the for-each node. After the assignment node runs and produces its output, the for-each node receives that output and begins iterating.
Number of loops
The loop count depends on the assignment node type:
| Assignment node type | Output format | Loop count |
|---|---|---|
| Shell or Python | One-dimensional array, elements separated by commas (,) | Number of elements |
| ODPS SQL | Two-dimensional array (query result rows) | Number of rows |
Shell or Python example
If the assignment node outputs:
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01The for-each node runs 5 loops — one per comma-separated element.
ODPS SQL example
If the assignment node's last SELECT statement returns:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | Hubei Province | 30 to 40 years old | Cancer |
| 0016359814159 | Unknown | 30 to 40 years old | Cancer |
+----------------------------------------------+The for-each node runs 2 loops — one per row.
Limits
Maximum loops: 1,024. If the number of loops for a for-each node exceeds 1,024, an error is reported.
Serial execution only: Parallel execution is not supported. Each loop starts only after the previous loop finishes.
Built-in variables
Use these variables inside the inner workflow to access data from the assignment node during each loop:
| Variable | Description |
|---|---|
${dag.loopDataArray} | The full dataset returned by the assignment node. Available in every loop iteration (the value does not change between loops). |
${dag.foreach.current} | The current element (1D array) or the current row as a comma-separated string (2D array). Equivalent to data[i] in a for loop. |
${dag.offset} | Zero-based index of the current iteration. Starts at 0 for the first loop. Equivalent to i in a for loop. |
${dag.loopTimes} | One-based count of completed loops. Starts at 1 after the first loop finishes. |
${dag.foreach.current[n]} | For a 1D array: the element at index n. For a 2D array: the value in column n of the current row. |
${dag.loopDataArray[i][j]} | For a 2D array: the value at row i, column j in the full dataset. |
If the inner workflow itself contains an assignment node, access that node's output using the standard assignment node method. See Configure an assignment node.
Examples
Shell assignment node
Assignment node output (one-dimensional array, 5 elements):
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01Loop count: 5
| Variable | Loop 1 | Loop 2 |
|---|---|---|
${dag.loopDataArray} | 2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01 | (same) |
${dag.foreach.current} | 2021-03-28 | 2021-03-29 |
${dag.offset} | 0 | 1 |
${dag.loopTimes} | 1 | 2 |
${dag.foreach.current[3]} | 2021-03-30 | — |
Note: ${dag.foreach.current[3]} returns the element at index 3 (the fourth element) of the full array, regardless of which loop is currently running.ODPS SQL assignment node
Assignment node output (two-dimensional array, 2 rows):
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | Hubei Province | 30 to 40 years old | Cancer |
| 0016359814159 | Unknown | 30 to 40 years old | Cancer |
+----------------------------------------------+Loop count: 2
| Variable | Loop 1 | Loop 2 |
|---|---|---|
${dag.loopDataArray} | (full table above) | (same) |
${dag.foreach.current} | 0016359810821,Hubei Province,30--40 years old,Cancer | 0016359814159,unknown,30--40 years old,Cancer |
${dag.offset} | 0 | 1 |
${dag.loopTimes} | 1 | 2 |
${dag.foreach.current[0]} | 0016359810821 | 0016359814159 |
${dag.loopDataArray[1][0]} | 0016359814159 | — |
Note:${dag.foreach.current[0]}returns the value in column 0 (theuidcolumn) of the current row.${dag.loopDataArray[1][0]}returns the value at row 1, column 0 of the full dataset — always0016359814159, regardless of the current loop.
Usage notes
Dependencies
A for-each node must depend on the assignment node. Configure the assignment node as the ancestor node of the for-each node so that the for-each node receives the assignment node's output.
Debugging
For-each nodes cannot be tested directly in DataStudio when using a standard mode workspace. To verify a for-each node's behavior:
Commit and deploy both the assignment node and the for-each node to Operation Center in the development environment.
Run both nodes together — running only the for-each node does not produce the assignment node's output.
To verify that the assignment node correctly passes its output to the for-each node, use the data backfill feature to backfill data for both nodes at the same time.
View logs
To view the operational logs of a for-each node:
Open the Cycle Task page in Operation Center and find the for-each node.
Open the directed acyclic graph (DAG) of the node.
Right-click the node name and select View Internal Nodes.