DataStudio is the code development workspace in DataWorks. This page describes its layout and the features available for workflows and nodes, so you can start building data pipelines right away.
Go to the DataStudio page
Log on to the DataWorks console. In the top navigation bar, select the target region. In the left-side navigation pane, choose Data Development and Governance > Data Development. Select a workspace from the drop-down list, then click Go to Data Development.
On the DataStudio page, create workflows and nodes based on your data development requirements. For details, see Create a workflow and DataWorks nodes.
Page layout
The DataStudio page has five functional areas.
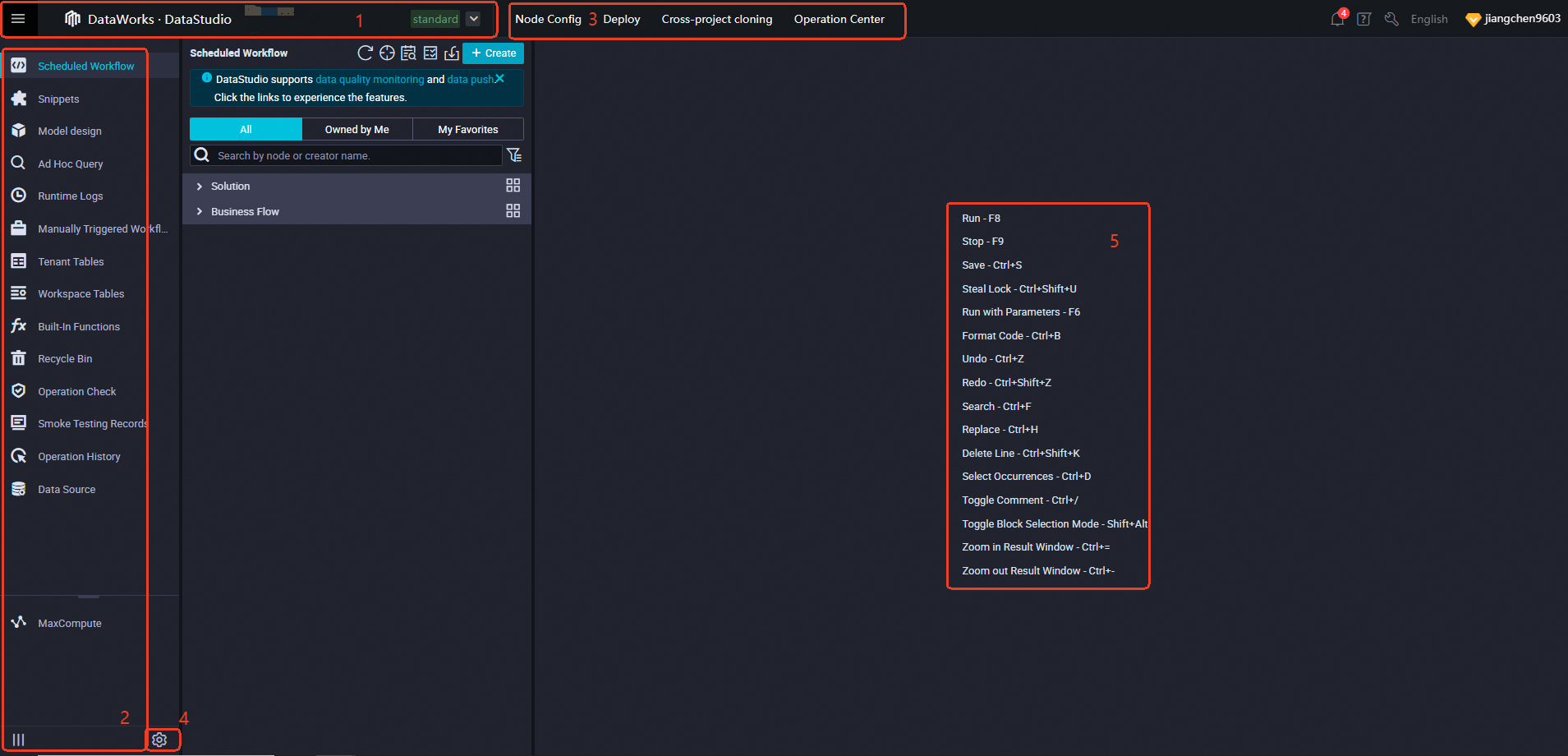
| Area | What you can do here |
|---|---|
| 1 | Switch workspaces, navigate to other DataWorks services, or return to the DataWorks console homepage. |
| 2 | Access DataStudio modules — Scheduled Workflow, Manually Triggered Workflows, Ad Hoc Query, and more — from the left-side navigation pane. |
| 3 | Use shortcuts to cross-workspace features (cross-project cloning, Operation Center) and common DataWorks functions (notifications, help, workspace settings). |
| 4 | Open Settings to manage personal preferences, code templates, scheduling defaults, and security configurations. |
| 5 | View commonly used editor keyboard shortcuts. For a full list, see Editor shortcuts. |
Area 1: Workspace and service navigation
From Area 1, you can:
-
Switch workspaces: Click the workspace name to switch to another workspace in the current region.
-
Navigate to DataWorks services: Click the navigation icon to jump to any DataWorks service. The services are grouped as follows:
-
Data Integration: Data Integration and Upload and Download
-
Data Modeling: Data Warehouse Planning, Data Standard, Data Metric, and Dimensional Modeling
-
Data Development And Task Operation: DataStudio, Operation Center, and Code Review
-
Data Governance: DataMap, Data Quality, Security Center, Data Security Guard, and Data Asset Governance
-
Data Analysis: SQL Query, WebExcel, and DataAnalysis
-
Data Service: DataService Studio
-
More: Deploy Center, Approval Center, DataWorks(Home), Migration Assistant, Global Member Management, and Open Platform
-
-
Return to the console homepage: Open the navigation panel and click the icon in the lower-left corner.
Area 2: DataStudio modules
Area 2 contains the left-side navigation pane. Click the toggle icon to show or hide module names.
The available modules are:
| Module | Use when you want to... |
|---|---|
| Scheduled Workflow | Create auto triggered nodes using different compute engines and deploy them to production for scheduled O\&M. |
| Manually Triggered Workflows | Create nodes that run on demand rather than on a schedule. |
| Runtime Logs | Review node run records from the past three days in DataStudio. |
| Ad Hoc Query | Test code quickly without deploying it to production. |
| Tenant Tables | Browse all production tables under the current Alibaba Cloud account. |
| Workspace Tables | Manage tables visually — the available operations depend on the compute engine used to create the table. |
| Built-In Functions | Look up descriptions of all built-in MaxCompute functions. |
| Recycle Bin | Manage nodes, resources, and functions deleted from Scheduled Workflow or Manually Triggered Workflows. |
| Snippets | Manage SQL script templates that define reusable data processing logic with input and output parameters. |
| Operation History | Filter and review historical operation records by type, operator, or time. |
| Operation Check | Filter and review operations by type and check status. |
| MaxCompute Resources | Manage MaxCompute resources and view their operation history. |
| MaxCompute Functions | Manage MaxCompute functions and view their operation history. |
Before you can use a compute engine for data development, add a data source of that engine type to DataWorks and associate the computing resource with DataStudio.
If a module icon is not visible, add it from Settings > Personal Settings. For details, see Personal settings.
Area 3: Shortcuts and common features
Area 3 provides quick access to cross-workspace operations and shared DataWorks features.
Cross-workspace operations:
-
Cross-project cloning: Clone and migrate nodes — including compute nodes and synchronization nodes — between workspaces.
-
Operation Center: Perform O\&M on deployed nodes. Switch between the development and production environments from within Operation Center.
Common DataWorks features:
| Feature | Description |
|---|---|
| Notification Center | Get the latest DataWorks updates. |
| Helps | Access guidance on specific features based on your needs. |
| Workspace Manage | View workspace details: basic information, scheduling properties, security settings, and associated data sources and open source clusters. For details, see Create and manage workspaces. |
| Language switch | Switch the console language (for example, from English to Chinese). |
| Account information | View your account details and node status statistics in the Workbench section. |
Area 4: Settings
Click the Settings icon in Area 4 to open the Settings page. The following tabs are available:
| Tab | What you configure |
|---|---|
| Personal Settings | DataStudio modules, editor preferences, and general settings such as the DataWorks theme. |
| Template Management | Customize code templates for your workflows. |
| Scheduling Settings | Enable periodic scheduling and set default scheduling properties for auto triggered nodes. Auto triggered nodes run as scheduled only after periodic scheduling is enabled. |
| Security Settings and Others | Data Security: Mask sensitive data in DataStudio query results. Code Review: Require code review before deployment and assign reviewers. |
Workflow features
The Scheduled Workflow pane opens by default when you go to DataStudio. Create a workflow before organizing your data development operations. For details, see Create a workflow.
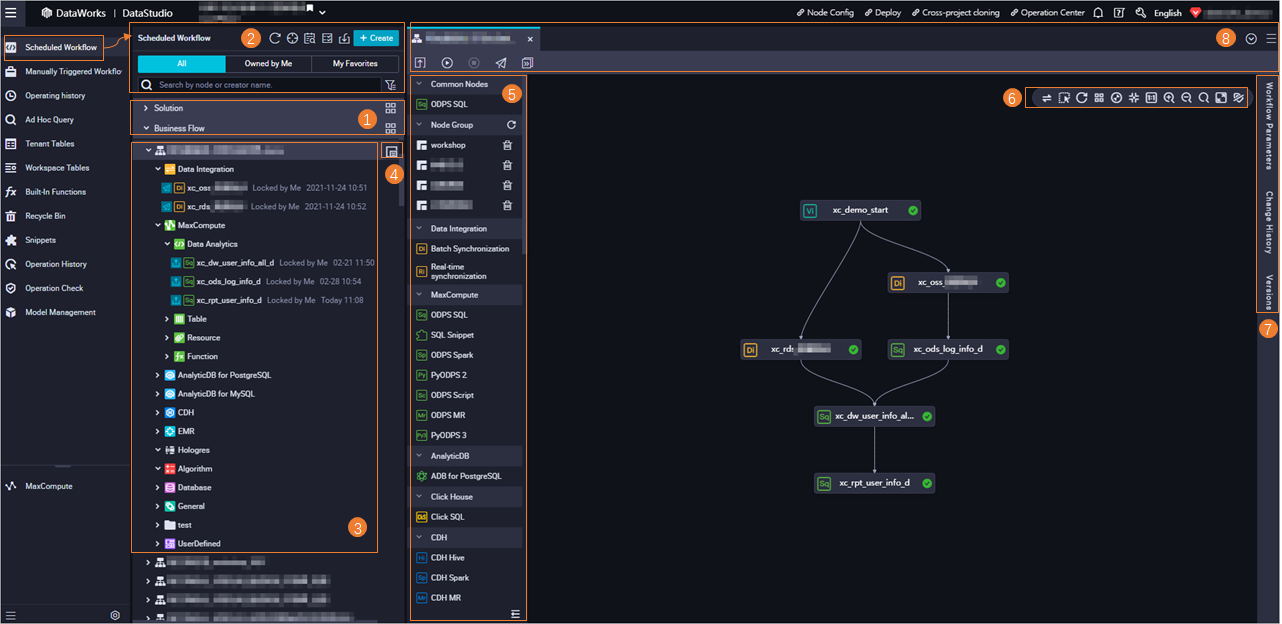
The Scheduled Workflow pane has eight functional areas.
Area 1: Solutions and workflows
Switch between Solution and Business Flow views. Click the expand icon to show all solutions or workflows in the workspace.
-
[Solution](https://www.alibabacloud.com/help/en/document_detail/139128.html#task-2511604): A container that groups multiple workflows. A workflow can belong to one or more solutions. View solutions as a list or as cards.
-
[Business Flow](https://www.alibabacloud.com/help/en/document_detail/137500.html#task-2510738): A workflow is the unit for organizing your data development operations.
Area 2: Toolbar and directory trees
Toolbar actions:
| Action | Description |
|---|---|
| Refresh | Refresh the pane after modifying a workflow or solution. |
| Locate | Find the node whose configuration tab is currently open. |
| Search Code | Search across all nodes in Scheduled Workflow, Manually Triggered Workflows, Ad Hoc Query, and Recycle Bin by keyword — useful for identifying which node writes to a specific table. |
| Batch Operation | Modify properties for multiple nodes, resources, or functions at once: owner, compute engine instance, resource group for scheduling, rerun settings, scheduling type, scheduling cycle, and timeout. |
| Import Data | Upload data from a local file to a MaxCompute table. |
| Create | Quickly create a workflow, node, table, resource, or function. |
Directory trees:
The directory tree shows nodes, resources, and functions organized by solution and workflow. Switch between three views:
-
All: All objects in the current workspace.
-
Owned by Me: Objects owned by the current account.
-
My Favorites: Objects added to favorites by the current account.
Node search:
-
Exact search: Enter a node name or the creator's identifier, then click the search icon.
-
Search by node type: Click the filter icon to restrict results to specific node types.
To hide compute engine instances or node folders from the directory tree, select Hide Engine Instances or Hide Node Folders. These options apply only to workflows of the latest version. Hide engine instances when a compute engine has only one instance; hide node folders (such as Data Analytics, Table, Resource, and Function) when you don't need them.
Area 3: Workflow directory tree
The directory tree in Area 3 lists all objects in each workflow.
Objects in the directory tree:
| Object | Description |
|---|---|
| Workflow | The unit for business development. |
| Node | The smallest unit for code development. Node types include engine nodes, algorithm nodes, Data Integration nodes, database nodes, and general nodes. |
| Table | Tables managed visually in DataStudio. |
| Resource | Resources uploaded visually in DataStudio. Visual upload is supported for MaxCompute, E-MapReduce (EMR), and Cloudera's Distribution including Apache Hadoop (CDH) compute engines only. |
| Function | Functions registered visually in DataStudio. Visual registration is supported for MaxCompute, EMR, and CDH compute engines only. |
Node status indicators:
Each node name shows its current status with an icon:
-
Uncommitted: The current version has not been committed. Click the icon to commit.
-
Not deployed: The node is committed but not yet deployed. Click the icon to deploy.
The last edit time appears after each node name. Double-click a workflow name to open its configuration tab (Areas 5–8) and start development.
Area 4: Resource Group Orchestration
Resource Group Orchestration lets you change the resource groups for scheduling used by multiple nodes in a workflow at once. This is useful when you have multiple resource groups in a workspace and need to rebalance resource utilization. After reassigning resource groups, deploy the affected nodes to apply the change in production.
Area 5: Node creation panel
Use this panel to create nodes quickly.
-
Common Nodes: Displays frequently used node types in the current workspace for fast selection.
-
Node Group: Reference a set of nodes across workflows. Add frequently used nodes to a node group and reuse the group in other workflows.
-
Quick node creation: Drag nodes from sections such as Data Integration, MaxCompute, and EMR directly onto the workflow canvas.
Area 6: Canvas tools
Use the canvas toolbar to adjust how the workflow is displayed and navigated.
| Tool | Description |
|---|---|
| Switch Layout | Switch between Vertical, Horizontal, and Grid layouts. |
| Box | Select multiple nodes to form a group for bulk operations. |
| Refresh | Refresh the canvas after modifying the workflow. |
| Format | Horizontally align all nodes on the canvas. |
| Adapt | Fit the entire workflow layout to the canvas size. |
| Center | Center all nodes on the canvas. |
| 1:1 | Reset the directed acyclic graph (DAG) scale to 100%. |
| Zoom In | Zoom in on the workflow canvas. |
| Zoom Out | Zoom out on the workflow canvas. |
| Search | Find a node by keyword. Fuzzy matching is supported. |
| Toggle Full Screen View | View the current workflow in full screen. |
| Hide Engine Information | Show or hide the engine information displayed on each node. |
Area 7: Right-side tabs
| Tab | Description |
|---|---|
| Workflow Parameters | Assign values to variables in ODPS SQL nodes across the entire workflow at once. |
| Change History | Review operation records for nodes in the current workflow. |
| Versions | View all versions of the workflow. A new version is created each time nodes are committed. |
Area 8: Workflow toolbar
| Action | Description |
|---|---|
| Submit | Commit one or more updated nodes in the current workflow to the Deploy page. |
| Run | Run all nodes in the current workflow. |
| Stop | Stop all running nodes in the current workflow. |
| Deploy | Go to the Deploy page to review and deploy nodes from the current workflow. |
| Operation Center | Go to Operation Center in production to view O\&M details for nodes in the current workflow. |
| View opened tabs | View all configuration tabs currently open from the drop-down list. |
| Close opened tabs | Close one or more open configuration tabs. |
Workflow shortcut menu
Right-click a workflow name to open the shortcut menu.
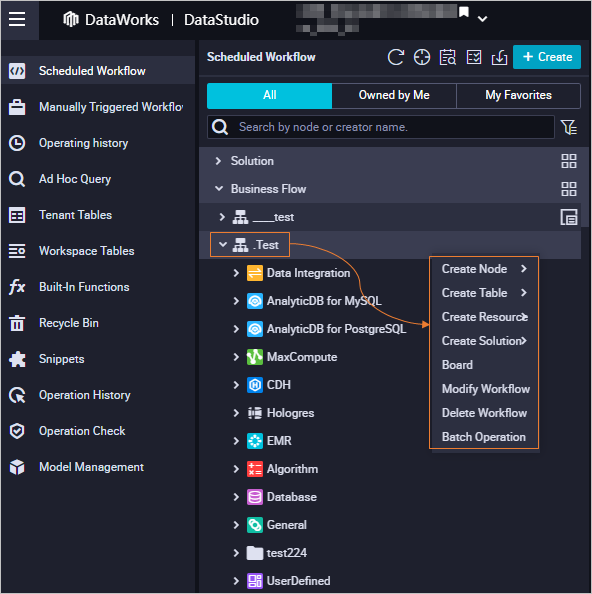
| Feature | Description |
|---|---|
| Create Node | Create a node. The menu shows recently used node types and pre-fills the Engine Instance and Node Type based on the last-used node of that type. |
| Create Table | Create a table. |
| Create Resource | Create a resource. Supported for MaxCompute, CDH, and EMR only. |
| Create Function | Create a function. Supported for MaxCompute, CDH, and EMR only. |
| Board | Navigate to the workflow canvas. |
| Change | Edit the workflow name, owner, or description. |
| Delete | Delete the workflow and all its objects. This action is irreversible — proceed with caution. Two options are available when an object cannot be deleted: Terminate the Delete Operation (default) stops the entire operation; Skip Current Object and Continue to Delete Other Objects skips the undeletable object and continues. |
| Batch Operation | Modify properties for multiple nodes, resources, or functions at once — including owner, compute engine instance, and scheduling settings — and commit or deploy them in bulk. |
Node features
Different node types share similar features. The following description uses an ODPS SQL node as an example.
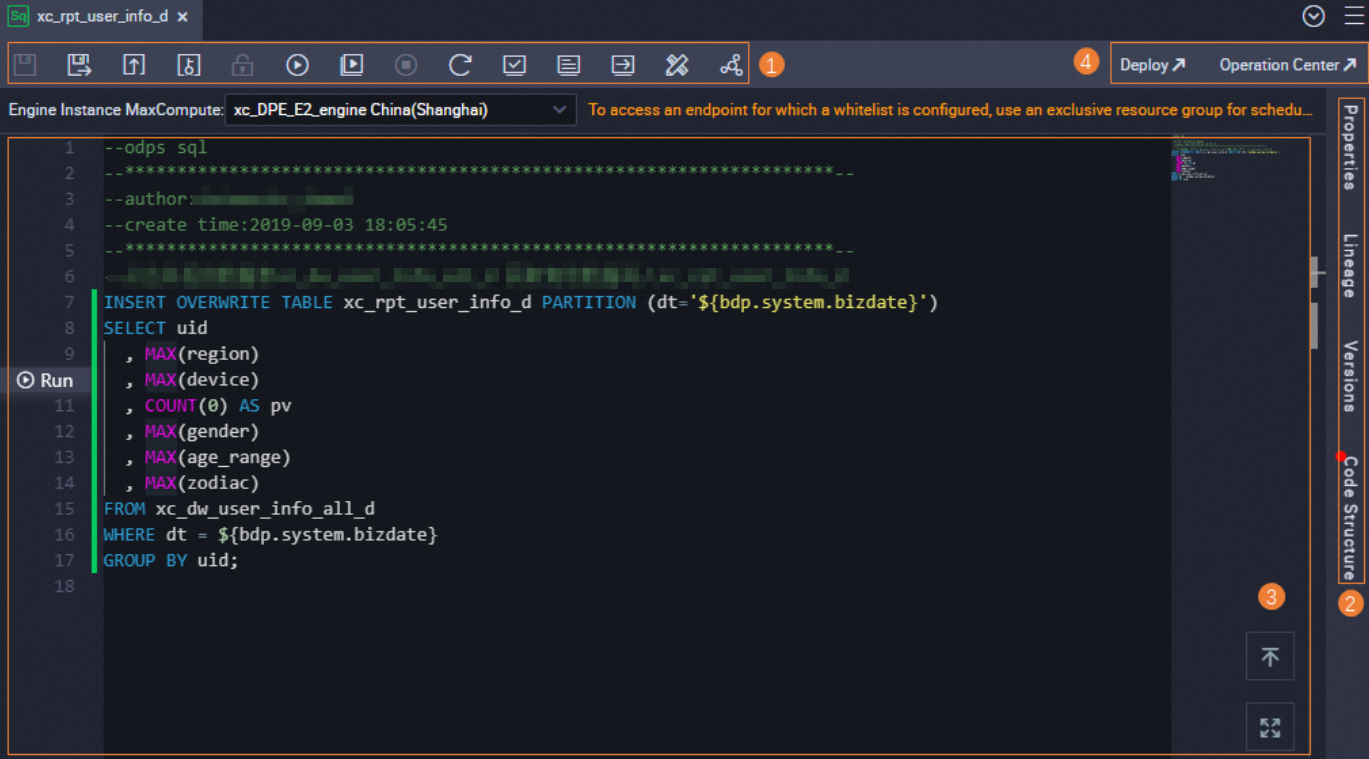
Area 1: Top toolbar
| Action | Description |
|---|---|
| Save | Save the current node's code and configurations. |
| Save as Ad-Hoc Query Node | Save the current code as an ad hoc query, accessible from the Ad Hoc Query pane. See Create an ad hoc query. |
| Submit | Commit the current node. |
| Unlock | Commit the node and allow other users to edit it. |
| Steal Lock | Take over editing rights for a node you don't own. |
| Run | Run the node. Variable values are set once and persist across runs — modifying the code does not reset them. If no resource group for scheduling is assigned, DataWorks prompts you to select one. |
| Run with Parameters | Run the node with custom parameter values. DataWorks prompts for variable values each time you click this icon, replacing the initial values with the ones you provide. If no resource group for scheduling is assigned, DataWorks prompts you to select one. |
| Stop | Stop the running node. |
| Reload | Refresh the configuration tab and revert to the last saved state. |
| Perform Smoke Testing in Development Environment | Test the node in the development environment by simulating scheduling parameter value replacement. Select a data timestamp — DataWorks replaces the corresponding values with those you specify. Save and commit any scheduling parameter changes before running smoke testing, or the new values won't take effect. |
| View Log of Smoke Testing in Development Environment | View the run logs for nodes tested in the development environment. |
| Access Scheduling System in Development Environment | Go to Operation Center in the development environment for O\&M operations. See View auto triggered instances. |
| Format Code | Auto-format the code to prevent excessively long single lines. |
| Share | Share the current node with other users. |
Area 2: Side panel tabs
Properties tab:
| Section | What you configure |
|---|---|
| General | View the node name, ID, and type; set the owner and description. |
| Scheduling Parameter | Add scheduling parameters and configure dynamic value assignment. |
| Schedule | Configure time-based scheduling properties after deployment: instance generation mode, scheduling cycle and time, rerun behavior, and timeout. |
| Resource Group | Assign a resource group for scheduling to the node. |
| Dependencies | Configure node dependencies. See Configure same-cycle scheduling dependencies and Configure cross-cycle scheduling dependencies. |
| Input and Output Parameters | Pass the output of an ancestor node to a descendant node using context-based parameter assignment. |
Other tabs:
| Tab | Description |
|---|---|
| Lineage | View dependencies and auto-captured lineage between the current node and other nodes. Check this tab before modifying or deleting a node to understand the downstream impact. |
| Versions | View all versions of the node. A version is created each time the node is committed and deployed. |
| Code Structure | View the code structure of the node using SQL operators. |
Node version states:
| State | Meaning |
|---|---|
| Yes | Committed to the development environment; no deployment package created yet. |
| Deployed | Deployed to production. View it on the Auto Triggered Tasks page in Operation Center. See View and manage auto triggered tasks. |
| Not Deployed | Committed to development but not yet deployed to production. Committing again makes the previous version a pending version. |
| The deployment is cancelled | Committed but the deployment was cancelled on the Create Deploy Task page. |
Area 3: SQL editor
Write SQL statements in the editor. Three icons are available:
-
Go to first line: Jump to the beginning of the editor.
-
Full screen: Expand the editor to full screen.
-
Run snippet: Quickly run a selected code snippet to verify it. This icon appears only when you click a line of code. See Debug a code snippet.
Area 4: Upper-right actions
| Action | Description |
|---|---|
| Deploy | Go to the Create Deploy Task page to review deployment details or perform O\&M after deployment. |
| Operation Center | Go to Operation Center in production for O\&M operations. |
Node shortcut menu
Right-click a node name to open the shortcut menu.
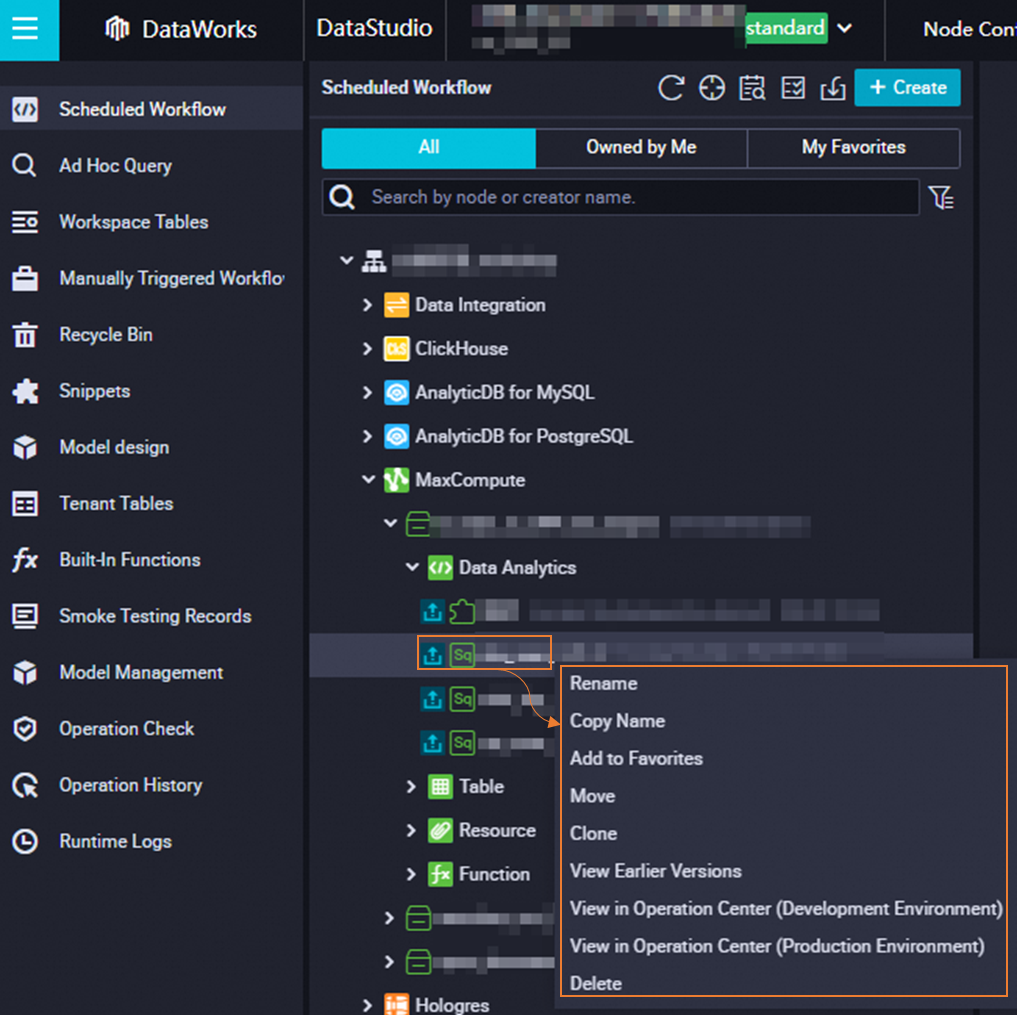
| Feature | Description |
|---|---|
| Rename | Change the node name. |
| Add to Favorites | Add the node to favorites. View favorited nodes under My Favorites in the Scheduled Workflow pane. To remove a node from favorites, right-click and select Remove from Favorites. |
| Move | Move the node to another workflow. |
| Clone | Create a copy of the node with the same type, owner, and resource properties. The clone gets a new name. |
| View Earlier Versions | View all historical versions of the node, including the committer, commit time, change type, status, and remarks. |
| View in Operation Center | Navigate to Operation Center to view node details. If the node is deployed to both environments, select View in Operation Center (Production Environment) or View in Operation Center (Development Environment). |
| Submit for Code Review | Submit the node code for review. Nodes must pass code review before they can be deployed. |
| Delete | Delete the node and its dependency configurations from ancestor and descendant nodes. If the node is deployed to production, also create and deploy a deployment package on the Create Deploy Task page to remove it from production. See Undeploy nodes. |