The node context feature automatically passes parameters between upstream and downstream nodes. Supported parameter types include constants, variables, and query results from upstream nodes, enabling dynamic task scheduling and execution.
Limits
Product edition: The Add assignment parameter feature (used to pass query results) is available only in DataWorks Standard Edition and higher.
Node type restrictions: Only specific node types support passing query results using an assignment parameter. Supported types include EMR Hive, EMR Spark SQL, ODPS Script, Hologres SQL, AnalyticDB for PostgreSQL, ClickHouse SQL, and MySQL nodes.
How it works
Node context parameters pass values by defining an output parameter on the upstream node (provider) and referencing it on the downstream node (consumer).

Upstream node (provider): Generates a value and passes it as an output parameter. You can provide the value in one of the following two ways:
Configure standard output parameters: In the Output Parameters section of the upstream node, define a parameter and assign a value to it. The value can be a constant, such as
'abc', or a system context variable, such as${status}.Configure assignment output parameters: The system captures the result of the last query in the node's code (for example,
SELECT 'table_A';) and assigns it to a built-in output parameter namedoutputs. The value of this parameter is then passed to downstream nodes. The parameter value depends on the execution result of the code. This method is supported by assignment nodes and some SQL-based nodes.
Downstream node (consumer): Receives and uses the value provided by the upstream node.
Establish a scheduling dependency: Configure a scheduling dependency on the upstream node.
Configure an input parameter: In the Input Parameters section of the downstream node, add an input parameter and set its value source to an output parameter of the upstream node.
Reference the value in code: In the code of the downstream node, reference the received value in the format
${input_parameter_name}. For example, if the upstream node passes the valuetable_A, the codeSELECT * FROM ${input};is resolved toSELECT * FROM table_A;at runtime.
Access the parameter configuration area
Log on to the DataWorks console, switch to the desired region, and in the left-side navigation pane, choose . Select the target workspace from the drop-down list and click Go to Data Development.
On the Data Studio panel, double-click the target node to open its editing page.
Click Properties on the right side, and then click
 on the right side of the Node Context section to enter the node context parameter configuration area.
on the right side of the Node Context section to enter the node context parameter configuration area.
Configure output parameters
When you configure output parameters for the current node in the node context area, you can configure them based on your business requirements.
Configure standard output parameters: Passes constants or variables configured as output parameters of the current node to downstream nodes.
Configure assignment output parameters: Configures the query result of the current node as an output parameter to be passed to downstream nodes.
Configure standard output parameters
To pass the parameter information configured on an upstream node to a downstream node, see the following content.
Parameter | Description |
No. | The number is controlled by the system and increments automatically. |
Parameter name | Specify a custom name for the output parameter. |
Type | Supports constants and variables. You can select a type based on your business requirements. |
Value | The value of the output parameter. Supported value types include constants and variables:
|
Description | A brief description of the parameter. |
Source | The source of the current parameter. Options include System Added, Parsed From Code, and Manually Added. |
Actions | Supports Save, Edit, and Delete actions. Note Editing and deletion are not supported when downstream nodes depend on the parameter. Before a downstream node references an upstream node, check carefully to ensure that the upstream output is defined correctly. |
After you configure the parameters, click Save in the Actions column.
Configure assignment output parameters
To pass the query result of the current task as a parameter to downstream tasks, see the following content.
Locate the section of the node.
Click Add assignment parameter to add an output assignment parameter with a single click.
After you click Add assignment parameter, the assignment parameter passes the query result of the current node to downstream nodes that reference the parameter. If the result is empty, the current node is not blocked, but the downstream nodes that reference the parameter may fail.
The downstream node must add the assignment parameter of the upstream node as an input parameter. Its usage is similar to that of an assignment node. For more information, see Assignment node.
After you configure the output parameters of the current node, you can view the output name added by the system in on the configuration page. Downstream nodes can use this output name to bind the dependency with the current node.
Configure input parameters
Configure input parameters for the current node in the node context area. This allows you to obtain output parameters from upstream nodes for use in the current node.
The input parameters of a node can be used to obtain the output parameters of its upstream nodes. After an input parameter is added, you can use it in the code of the current node in the same way that you use a scheduling parameter variable in code.
Only after the current node is set to depend on an upstream node can you add the output of that upstream node as an input parameter of the current node in the Input Parameters area.
An output parameter has been configured on the upstream node. See Configure output parameters.
Set up the upstream-downstream dependency.
On the editing page of the downstream node, click Properties on the right side.
In the dialog box after Node Output in , enter and select the output name that you specified when you configured the upstream node in Configure output parameters.
Click Add.
Configure input parameters on the downstream node.
In the Node Context area, click Add Input Parameter. Configure the parameters based on the following table:
Parameter
Description
No.
The number is controlled by the system and increments automatically.
Parameter name
Specify a custom name for the input parameter. You can later reference the parameter information passed from upstream by using this parameter name on the node editing page.
Value source
The value of the parameter comes from an output parameter of the upstream node. The actual value is the actual output result of the upstream node.
Description
You can enter a brief custom description of the parameter.
Parent node ID
Automatically parsed from the upstream node.
Source
The source of the current parameter.
Options include System Added, Parsed From Code, and Manually Added.
Actions
Supports Save, Edit, and Delete actions.
After you configure the parameters, click Save in the Actions column.
Use input parameters in downstream nodes
To use the defined input parameters in a node, use the same method as for other system variables. Reference them in the format ${input_parameter_name}. The following section uses a Shell node as an example to describe how to reference the parameters.
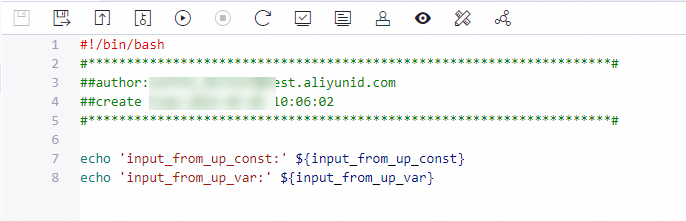
When you run the task, run the workflow that contains the upstream and downstream nodes so that the upstream and downstream nodes run in sequence. Otherwise, the input parameters used by the downstream node are invalid.
Global variables supported by the system
System variable
System variable
Description
${projectId}
Project ID.
${projectName}
MaxCompute project name.
${nodeId}
Node ID.
${gmtdate}
00:00:00 on the day of the scheduled time of the instance, in the format yyyy-MM-dd 00:00:00.
${taskId}
Task instance ID.
${seq}
The sequence number of the task instance, which indicates its order among the instances of the same node on the current day.
${cyctime}
Scheduled time of the instance.
${status}
Status of the instance: SUCCESS or FAILURE.
${bizdate}
Business date.
${finishTime}
End time of the instance.
${taskType}
Run type of the instance: NORMAL, MANUAL, PAUSE, SKIP (dry run), UNCHOOSE, or SKIP_CYCLE (weekly or monthly dry run).
${nodeName}
Node name.
For information about other parameter settings, see Scheduling parameter formats.