SQL query in DataAnalysis lets you write and run SQL statements against multiple data sources—MaxCompute, Hologres, EMR, and more—and export or visualize the results without leaving the DataWorks console.
DataWorks recommends the new version of DataAnalysis for the latest features and a better experience.
Supported data sources
SQL query supports the following data sources: MaxCompute, Hologres, EMR, CDH, StarRocks, ClickHouse, SelectDB, Doris, AnalyticDB for MySQL 3.0, AnalyticDB for PostgreSQL, Tablestore, MySQL, PostgreSQL, Oracle, and SQL Server.
Only data sources added to a workspace are available.
Prerequisites
Before you begin, ensure that you have:
-
Access to at least one DataWorks workspace containing the data sources you want to query. Contact an administrator to add you as a workspace member with the Data Analyst, Model Designer, Developer, O&M, Workspace Administrator, or Project Owner role
-
Permissions on the data sources within that workspace (see Data source permissions below)
Data source permissions
Data source scope
You can query data only from workspaces you have access to.
Access identity modes
DataAnalysis supports two identity modes for data source access:
| Access identity mode | Description | Supported data sources | How to get access |
|---|---|---|---|
| Executor identity | The Alibaba Cloud account currently logged on to DataWorks. | MaxCompute and Hologres | Ask the MaxCompute project administrator or Hologres instance administrator to grant you member access permissions. |
| Data source default access identity | The access identity configured when the data source was created. | All data sources | Ask a user with Workspace Administrator permissions to grant your current Alibaba Cloud account access. |
If IP whitelist-based access control is enabled for the MaxCompute project, add the DataAnalysis whitelist to the MaxCompute project's IP whitelist.
Open SQL query
Log on to DataWorks DataAnalysis, switch to the target region, and click Enter DataAnalysis.
-
If the navigation bar shows Go To New DataAnalysis, you are on the legacy DataAnalysis page.
-
If the navigation bar shows Return To Legacy DataAnalysis, click it to switch back to the legacy page. (Not recommended)
Step 1: Add a folder
Add folders to organize the data sources and tables you want to query. After adding a folder, you can browse its tables, view table schemas, and generate SQL statements directly from the folder tree.
-
On the SQL Analysis page, click the
 icon to the right of the search box above the folder list.
icon to the right of the search box above the folder list. -
Select the type of dataset to add:
Dataset type Description Data Map - Metadata Table metadata collected in Data Map. Each data source or computing resource becomes one dataset. Data Map - Data Album Data albums that group tables by subject. Each data album becomes one dataset. My Favorites Tables you have added to your favorites in Data Map. My MaxCompute Tables All MaxCompute tables owned by the currently logged-on account. Public Tables Public datasets provided by MaxCompute, useful for generating test data.
You can add up to 12 datasets. Remove datasets you no longer need to stay within the limit.
Step 2: Create an SQL query
Query based on the data catalog
-
In the folder tree on the left, open an added dataset, such as My MaxCompute Tables.
-
Right-click the table you want to analyze and select Generate SQL Statement. A temporary file containing a recommended SQL statement is generated.
-
Modify the SQL statement as needed, then click Save to save the file to My Files.
Query based on a data source
-
In the folder tree on the left, hover over My Files and click the
 icon to create a file.
icon to create a file. -
Write an SQL statement in the new file and save it to My Files.
DataWorks autocompletes MaxCompute table names as you type, for tables your account has permissions on.
Query based on a shared SQL file
In the folder tree on the left, click Other People's Files to browse SQL files shared by other users. Open a file, then click Copy The SQL on the details panel.
Query based on a public dataset
After adding a public dataset, click the dataset. On the details panel, select an engine from the top bar and click Generate SQL Statement. Public datasets are intended for testing.
Step 3: Configure the query engine and run the query
-
Click the
 icon in the upper-right corner of the SQL editor to configure the query engine.
icon in the upper-right corner of the SQL editor to configure the query engine.Configuration item Description Workspace The workspace where the execution engine is located. Make sure you have access to the workspace—if not, contact a workspace administrator to add you as a workspace member. Data Source Type The type of the execution engine. If no project is specified in the SQL statement, the engine defaults to the configured data source. Data Source Name The name of the execution engine. Access Identity Mode Select Executor Identity (MaxCompute and Hologres only; requires membership and Select permissions) or Data Source Default Access Identity (all data sources; grant your account access if your account differs from the configured identity). -
Click Run All to run the full statement, or select part of the statement and click Run Selected.
For MaxCompute SQL, an estimated cost is shown before execution. Access cost estimates anytime via More > Cost Estimate in the toolbar.
-
After execution, review the Run Log, Run Result, and the corresponding SQL on the query result page.
Toggle between side-by-side and top-and-bottom layouts using the button in the upper-right corner of the results panel.
Step 4: Visualize query results
In the toolbar on the left of the query results, click the chart button to automatically generate a visualization from the results.
Click the Copilot button above the chart to try the DataWorks Copilot Ask feature.
Step 5: Export and share
Export query results to a local file, OSS, a MaxCompute table, a workbook, or DingTalk Sheet.
To move large datasets between data sources, use an offline sync task in Data Integration for more reliable data migration.
Local file
Download results as CSV, TXT, or XLS.
When downloading large amounts of data from MaxCompute, change the SQL execution mode to Run And Generate Temporary Table: click theicon in the lower-left corner of the SQL Query menu.
| Item | Description |
|---|---|
| Download limits | Only MaxCompute and EMR engines are supported. For more information, see Number of data rows that can be downloaded. If the data protection mechanism is enabled for the MaxCompute project, downloads fail. See Why are my query results or download options limited? |
| Download scope | Data Displayed In The Table Only downloads only the current page, up to 10,000 records. All Data exports all queried results within the download limit. |
| Download method | Download Without Approval (default, no request required). Download After Approval requires Fraud Detection rules and submitting a download request—available in DataWorks Enterprise Edition only. |
Object Storage Service (OSS)
Export results in CSV, text, ORC, or Parquet format to an Object Storage Service (OSS) bucket. Suitable for archiving large volumes or integrating with other cloud services.
On first use, grant DataWorks access to your OSS resources: in the File path drop-down, click the one-click authorization link and follow the instructions to complete RAM authorization.
| Configuration item | Description |
|---|---|
| File path | Click the folder icon to select the OSS bucket and folder for the output file. |
| File name | Auto-generated by the system. Edit as needed. |
| Text type | Export format: csv, text, orc, or parquet. |
| Separator | Column delimiter. Default: comma (,). |
| Encoding format | File encoding: UTF-8 or GBK. |
| CU | Computing units (CUs) for the export task. Default: 1 CU. |
| Resource group | Serverless resource group for the export task. If left blank, uses the data integration resource group configured in DataAnalysis > System Administration. |
Click OK to start the export. Monitor progress, run logs, and configuration on the task page. After the task succeeds, download the exported file from the OSS console.
MaxCompute table
Save results directly to a MaxCompute table—no local download or re-upload needed. Set the table lifecycle as needed.
This option appears only when querying a MaxCompute engine.
Workbook
Save results to a workbook for further data analysis and share the latest analysis results with others.
DingTalk Sheet
Export results to a DingTalk Sheet.
More operations
Manage SQL file versions
On the SQL file editing page, click More > Version in the top toolbar to compare auto-saved and manually saved versions and select the version you want to save.
Search code
Above the folder tree, click ![]() and enter a keyword to search across SQL files. Available in DataWorks Standard Edition and later.
and enter a keyword to search across SQL files. Available in DataWorks Standard Edition and later.
View run history
Above the folder tree, click ![]() to view historical SQL query execution records.
to view historical SQL query execution records.
FAQ
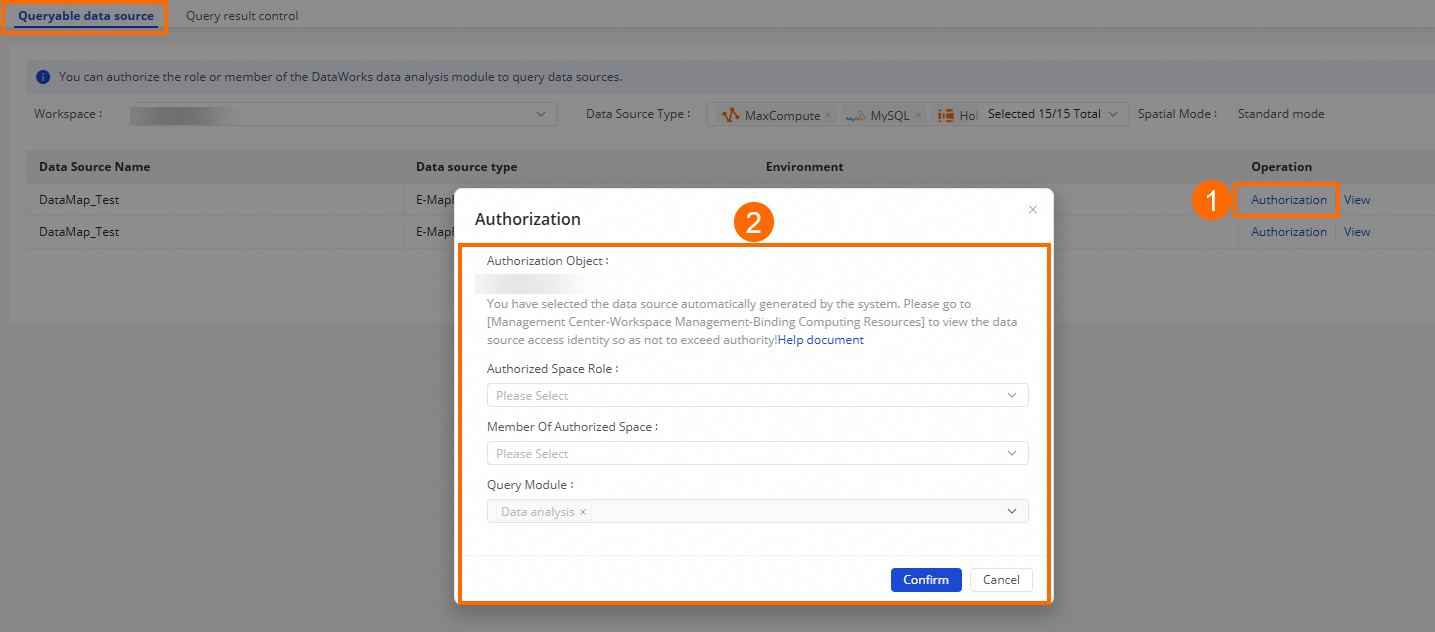
How do I grant the default access identity permission for a data source?
-
Log on to the DataWorks console. In the top navigation bar, select the target region. In the left navigation pane, choose Data Governance > Security Center, then click Go to Security Center.
-
In the left navigation pane, click Security Policy > Data Query And Analysis Control.
-
Switch to the target workspace, find the data source, and click Authorize to grant access.
Why does an SQL query fail with "This node can only run on exclusive resource groups"?
Go to DataAnalysis > More > System Administration and configure the Schedule Resource Group and Data Integration Resource Group for the engine.
Why are my query results or download options limited?
Only a portion of results may be displayed by default. To adjust the limits:
-
Log on to the DataWorks console. In the top navigation bar, select the target region. In the left navigation pane, choose Data Governance > Security Center, then click Go to Security Center.
-
In the left navigation pane, click Security Policy > Data Query And Analysis Control.
-
On the Query Result Control tab, adjust Maximum value of single display record, Maximum value of single copy record, Maximum value of single download record, and Allow Downloads.

For more details, see Data query and analysis control.