
개요
ApsaraDB for SelectDB는 Apache Doris를 기반으로 하는 차세대 클라우드 네이티브 실시간 데이터 웨어하우스 서비스입니다. 사용법이 간단하고 오픈소스이며, 클라우드 네이티브 스토리지-컴퓨팅 분리, 실시간 쿼리 성능, 빠른 통합, 뛰어난 호환성을 지원합니다. ApsaraDB for SelectDB는 초당 쿼리(QPS) 수만 건의 실시간 보고서 쿼리, 1초 미만의 레이턴시를 제공하는 다차원 Ad hoc 분석, 다른 솔루션보다 10배 더 비용 효율적인 로그 분석 솔루션, 비용을 최대 80%까지 절감할 수 있는 데이터 레이크하우스 분석 플랫폼 등을 제공합니다.
혜택
-

클라우드 네이티브 아키텍처: 비용 및 확장성 문제 해결
클라우드 네이티브 아키텍처는 스토리지와 컴퓨팅 리소스를 분리합니다. 따라서 비즈니스 요구사항에 따라 컴퓨팅과 스토리지 리소스를 별도로 확장할 수 있습니다. 전체 데이터는 안정적이고 비용 효율적인 Object Storage Service(OSS) 버킷에 저장됩니다. 스토리지 단가가 90%까지 절감됩니다. 데이터를 여러 컴퓨팅 클러스터와 공유할 수 있습니다. 이를 통해 스토리지 중복을 방지하고 강력한 물리적, 논리적 격리 기능을 제공합니다. ApsaraDB for SelectDB의 총 소유 비용(TCO)은 자체 관리형 데이터 웨어하우스에 비해 50% 낮습니다.
-

실시간 쿼리: 성능 문제 해결
ApsaraDB for SelectDB는 광범위한 테이블 집계, 다중 테이블 연관 분석 및 동시성이 높은 포인트 쿼리 시나리오에서 뛰어난 쿼리 성능을 제공합니다. ApsaraDB for SelectDB는 ClickBench의 글로벌 분석 데이터베이스 목록에서 1위를 차지했습니다. 여러 지표에서 전 세계 상위권에 랭크된 ApsaraDB for SelectDB. ApsaraDB for SelectDB는 동시성이 높은 데이터 가져오기 및 실시간 업데이트를 지원합니다. 데이터가 생성된 후 단 몇 초 만에 데이터를 분석할 수 있습니다.
-

사용 편의성: 사용성 문제 해결
ApsaraDB for SelectDB는 사용하기 쉬운 다양한 데이터 가져오기 방법을 지원하여 데이터를 빠르게 가져올 수 있습니다. ApsaraDB for SelectDB는 MySQL 연결 프로토콜 및 구문과 호환되며, 수십 개의 데이터베이스 및 빅데이터 에코시스템 서비스와 원활하게 통합할 수 있습니다. 따라서 사용자의 학습 비용이 절감됩니다. ApsaraDB for SelectDB는 시각화된 개발 툴을 제공하여 데이터 개발 프로세스를 간소화합니다.
특징

실시간 스케일링
ApsaraDB for SelectDB는 여러 컴퓨팅 클러스터를 지원합니다. 비즈니스 요구사항에 따라 클러스터를 확장하거나 축소할 수 있습니다. 비즈니스 중단 없이 몇 분 안에 확장을 완료할 수 있습니다.

데이터 레이크 분석
ApsaraDB for SelectDB는 Hive, Iceberg, Hudi 등 다양한 유형의 데이터 레이크를 지원하며, 데이터 레이크에서 데이터를 쿼리하고 다시 쓸 수 있습니다.

반정형 데이터 분석
ApsaraDB for SelectDB는 간단하고 빠른 반정형 데이터 분석 기능을 제공하며 모든 유형의 변형 및 역인덱스를 지원합니다.
시나리오
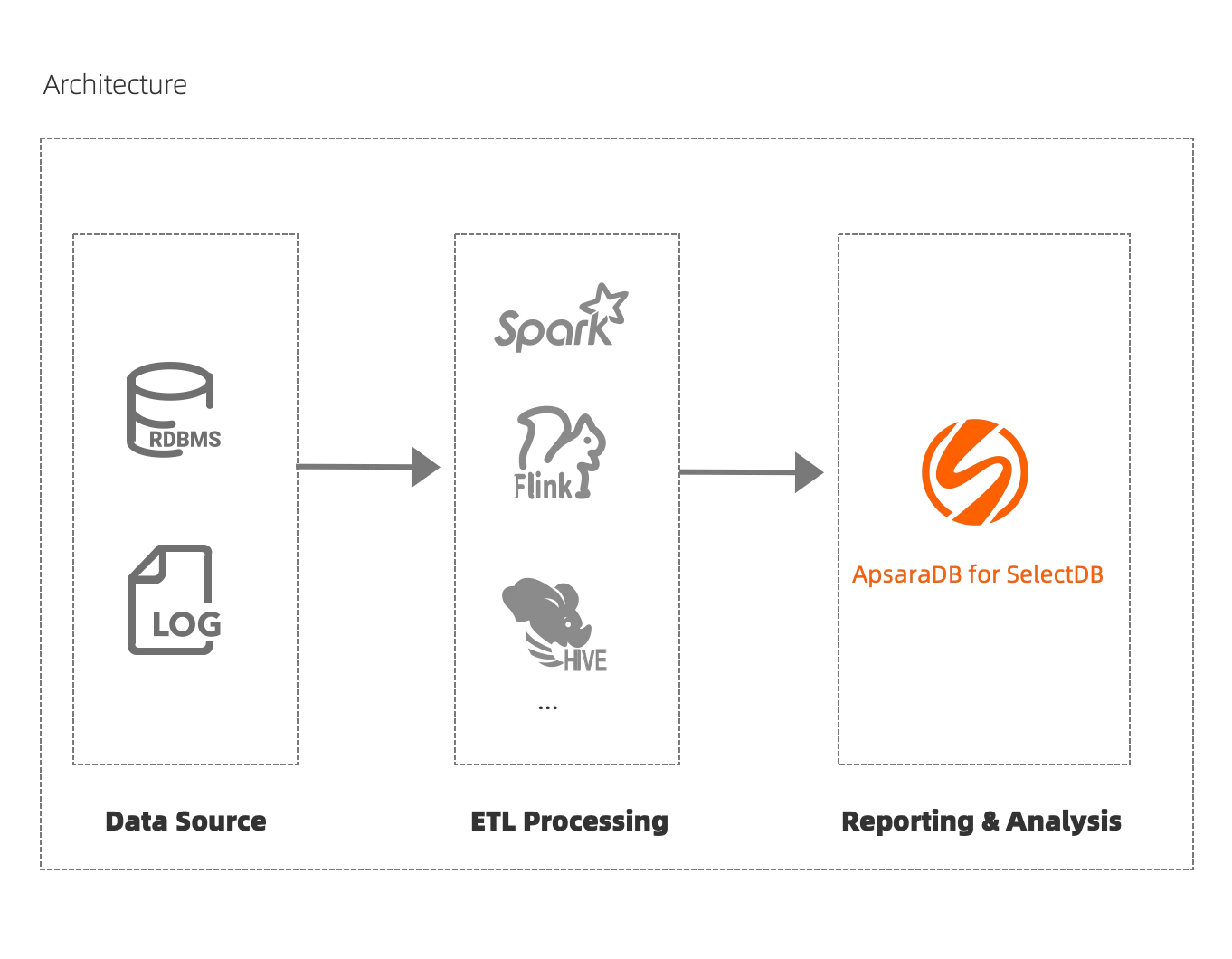
기존 솔루션은 데이터 생성부터 가시적인 데이터 출력까지 몇 시간의 긴 레이턴시, 느린 쿼리 응답과 낮은 동시성(수십 개의 동시 쿼리만 지원), 데이터 손실 또는 중복 데이터, 서비스 가용성 저하 등 여러 가지 문제에 직면해 있습니다. ApsaraDB for SelectDB를 사용하면 온라인 및 동시성이 높은 보고서 쿼리를 처리할 수 있으며, 빠르고 안정적이며 가용성이 높은 실시간 서비스를 제공할 수 있습니다.
혜택
-
실시간 데이터 쓰기
초당 수백만 개의 데이터 레코드 쓰기를 지원하는 ApsaraDB for SelectDB는 MySQL, PostgreSQL, Oracle과 같은 데이터베이스 에코시스템 및 Flink, Kafka, Dataworks와 같은 빅데이터 에코시스템과 통합할 수 있습니다. 이를 통해 데이터 쓰기 프로세스가 간소화됩니다.
-
1초 미만의 쿼리 응답
ApsaraDB for SelectDB는 새로운 쿼리 최적화 도구, 고성능 파이프라인 실행 엔진, 다양한 유형의 인덱스를 사용해 쿼리 속도를 대폭 향상시킵니다. ApsaraDB for SelectDB는 다중 테이블 집계 쿼리의 결과를 기반으로 생성되는 매우 일관성 있는 구체화된 보기를 제공하며, 통계 집계를 위한 초 단위 쿼리의 요구 사항을 충족하기 위해 자동 쿼리 재작성을 지원합니다.
-
최대 10,000개의 동시 쿼리 지원
ApsaraDB for SelectDB는 파티션 및 버킷별 데이터 가지치기, 데이터 건너뛰기 인덱스(Zonemap 및 Bloomfilter), 포인트 쿼리 인덱스(기본 키 및 역인덱스)를 지원합니다. 이렇게 하면 읽어야 할 데이터의 양이 줄어들고 동시 쿼리 기능이 향상됩니다. 하이브리드 행-열 스토리지 및 사용자 정의 쿼리 옵티마이저와 결합하면 단일 시스템에서 수만 개의 QPS로 매우 동시적인 포인트 쿼리를 지원할 수 있습니다.




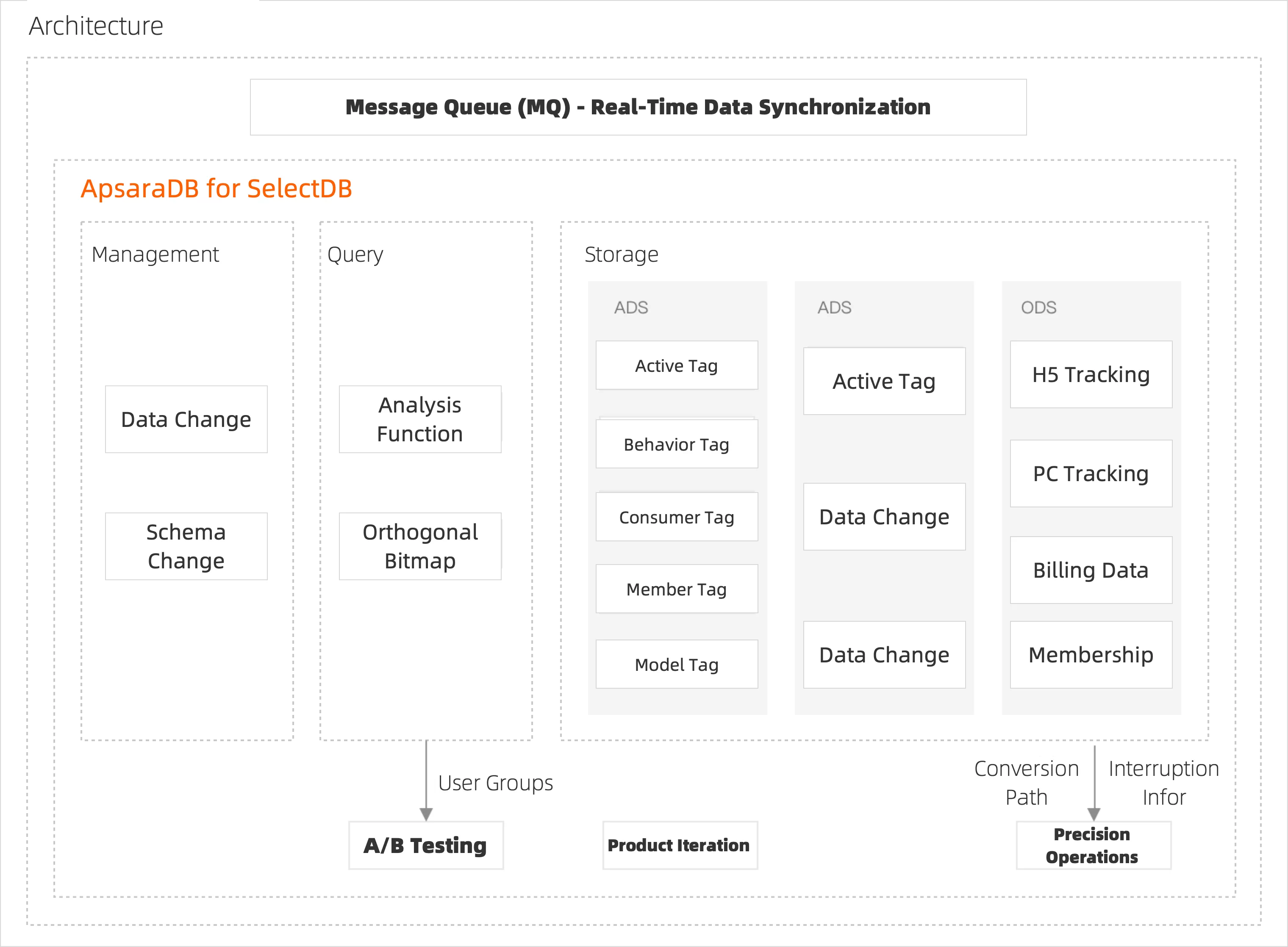
기존 솔루션에는 복잡한 컴퓨팅 및 분석 프로세스, 느린 쿼리 응답, 유연하지 못한 테이블 스키마, 유연한 비즈니스 변화에 대한 부적응, 데이터 변경 시 데이터 업데이트 지연 등 여러 가지 문제가 존재합니다. ApsaraDB for SelectDB를 사용하면 다차원 분석 플랫폼을 구축하고 사용자 프로필 및 행동 분석과 같은 맞춤형의 세분화된 작업을 구현할 수 있습니다. 이를 통해 보다 정확한 방식으로 사용자를 파악하고 비즈니스 개발을 추진할 수 있습니다.
혜택
-
고성능 데이터 업데이트
ApsaraDB for SelectDB는 대량의 과거 데이터를 오프라인에서 주기적으로 재계산하지 않고도 행 또는 특정 열의 데이터 업데이트를 지원하는 동시성 높은 데이터 업데이트 기능을 제공합니다. 이를 통해 몇 초 내에 데이터 적시성을 보장합니다. ApsaraDB for SelectDB는 간단하고 효율적인 내장형 추출, 변환, 로드(ETL) 기능을 제공합니다. SQL 문을 실행하여 데이터를 쉽게 처리하고 변환할 수 있습니다.
-
가벼운 테이블 스키마 변경
ApsaraDB for SelectDB는 몇 초 내에 온라인으로 완료할 수 있는 가벼운 테이블 스키마 변경을 지원합니다. ApsaraDB for SelectDB는 Map, Array, JSON 등 다양한 반정형 데이터 유형과 수천 개의 컬럼 처리를 지원하는 고성능 와이드 테이블 처리 기능을 제공합니다. 이를 통해 비즈니스 유연성과 다양성에 대한 요구 사항을 완벽하게 충족합니다.
-
몇 초 만에 대화형 분석
ApsaraDB for SelectDB는 리텐션 분석 기능, 프로파일 분석 기능 등 다양한 Ad hoc 분석 기능과 직교 비트맵 처리 기능을 제공합니다. 이를 통해 다차원 Ad hoc 분석의 개발 프로세스를 크게 간소화하고 수 초 내에 대화형 데이터 분석을 구현할 수 있습니다.

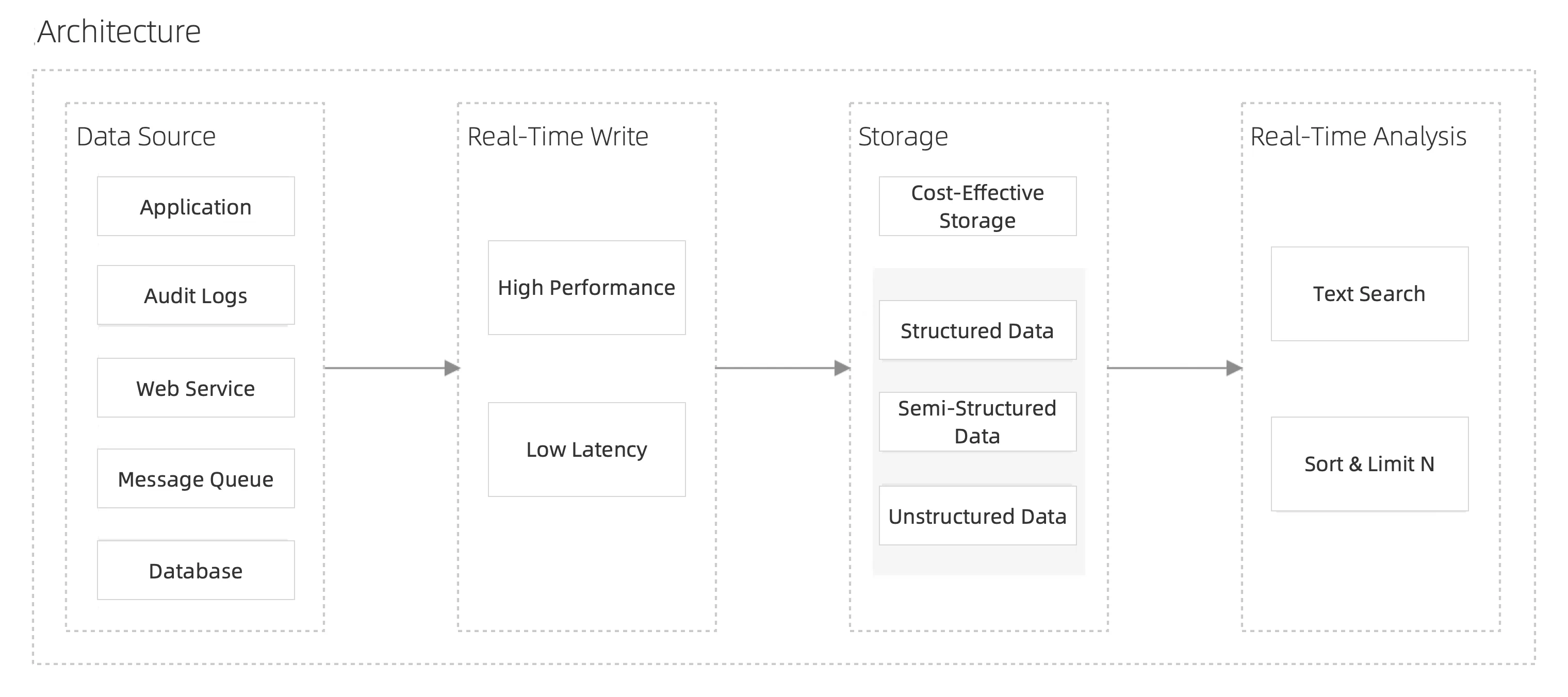
대량의 로그가 존재하고 높은 처리량의 쓰기와 실시간 가시성 데이터가 필요한 로깅 시나리오에서는 리소스 비용을 줄이는 것이 큰 과제입니다. 또한 로깅 시나리오에서는 문제 해결 및 전체 텍스트 검색과 같은 요구 사항을 충족하기 위해 빠른 텍스트 검색 기능이 필요합니다. ApsaraDB for SelectDB는 스토리지-컴퓨팅 분리, 열 중심 데이터 저장, 역 인덱스와 같은 기능을 사용하여 실시간 쿼리, 저비용 저장, 대용량 로그의 고효율 처리를 구현합니다. 이는 Elasticsearch 솔루션보다 10배 더 비용 효율적인 대체 솔루션입니다.
혜택
-
대용량 데이터의 실시간 쓰기
ApsaraDB for SelectDB는 최적화된 고성능 역인덱스를 제공합니다. 쓰기 속도는 Elasticsearch 역인덱스보다 4배 더 빠릅니다. 서버에서 그룹 커밋 메커니즘이 사용되며, 초 단위 실시간 가시 데이터가 보장되는 경우 실시간 쓰기 처리량을 초당 수 기가바이트까지 향상시킵니다.
-
비용 효율적인 데이터 저장
ApsaraDB for SelectDB는 열 중심 스토리지, 간소화된 역인덱스, 고비율 압축을 사용합니다. 차지하는 저장 공간은 Elasticsearch의 20%입니다. ApsaraDB for SelectDB는 스토리지와 컴퓨팅 리소스를 분리하는 아키텍처를 사용합니다. 저장 공간의 단위당 비용은 Elasticsearch의 33.3%이며, 총 비용은 Elasticsearch의 6.7%입니다.
-
효율적인 쿼리 프로세스
ApsaraDB for SelectDB를 사용하면 파티셔닝 및 버킷화, 시간 범위 필터링을 통해 쿼리의 데이터 범위를 좁힐 수 있습니다. 역인덱스와 키워드를 사용해 일치하는 로그 행을 빠르게 찾을 수 있습니다. 이를 통해 대규모 데이터 스캔을 방지하고 몇 초 만에 응답을 얻을 수 있습니다.
관련 서비스


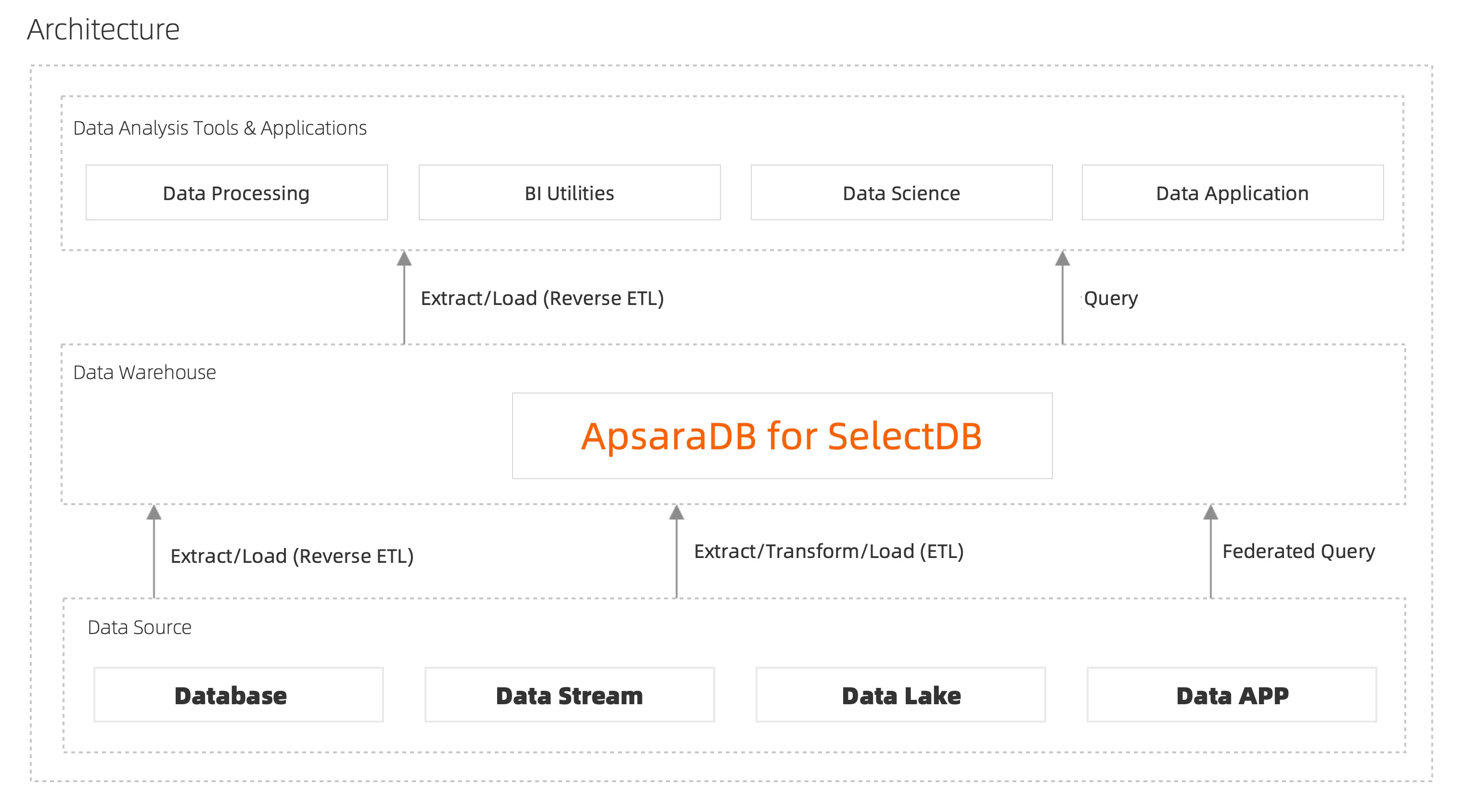
기존의 빅데이터 플랫폼 솔루션은 여러 데이터 레이크 쿼리 엔진과 데이터 웨어하우스 시스템을 결합하여 복잡하고 다양한 빅데이터 분석 요구사항을 충족합니다. 이로 인해 높은 인건비와 리소스 비용, 복잡한 데이터 개발 및 사용, 데이터 분석의 적시성 저하 등의 문제가 발생합니다. ApsaraDB for SelectDB를 사용하면 데이터 레이크하우스 분석 시스템을 구축하여 저비용의 효율적인 방식으로 데이터 분석 요구 사항을 신속하게 충족할 수 있습니다.
혜택
-
대폭 절감된 비용
ApsaraDB for SelectDB는 하나의 시스템으로 다양한 분석 요구사항을 완벽하게 지원할 수 있어 이중화 시스템 구축이 크게 줄어듭니다. 따라서 빅데이터 플랫폼의 인건비 및 유지보수 비용과 중복 리소스의 오버헤드를 줄일 수 있습니다. 종합적인 비용은 최대 80%까지 절감할 수 있습니다.
-
간소화되고 통합된 개발
ApsaraDB for SelectDB는 데이터 레이크하우스와 경량 추출, 로드, 변환(ELT) 기능을 지원합니다. 따라서 Spark나 Flink에 의존하지 않고도 데이터 소스에서 데이터 웨어하우스까지 데이터 동기화 및 데이터 정리를 원활하게 완료할 수 있습니다. 여러 시스템 간에 전환하거나 SQL 구문의 호환성을 고려할 필요 없이 통합 쿼리 게이트웨이로 ApsaraDB for SelectDB를 사용할 수 있습니다.
-
빠른 데이터 분석
ApsaraDB for SelectDB는 최고의 쿼리 및 분석 엔진을 제공하며, 데이터 캐싱 및 통계 수집 기능을 지원합니다. ApsaraDB for SelectDB의 분석 성능은 Presto 및 Trino의 3~5배에 달합니다. 탄력적인 컴퓨팅 리소스와 내부 테이블을 사용하여 보기를 가속화하고 성능을 더욱 향상시킬 수 있습니다.



