
Lindorm is a cloud-based database service that can store and analyze large amounts of data with low costs and supports multiple data models including wide tables, time series data, files, and search engines. Lindorm is capable of processing online data within milliseconds. You can use unified SQL statements to query, search, and analyze data of multiple models in Lindorm. Lindorm also allows you to perform computing in real time by using its built-in stream computing engine. Lindorm is the ideal database service for businesses in a variety of scenarios, including finance, billing, logging, Internet of Things (IoT), Internet of Vehicles (IoV), industrial Internet, monitoring, recommendation systems, risk control, and medical imaging.
Benefits
-
Cost-effectiveness
Lindorm can respond to tens of millions concurrent requests within milliseconds. Lindorm uses cost-effective storage media to build a storage pool that can be shared by multiple data engines and supports intelligent separation of hot and cold data and adaptive data compression.
-
Scalability
Lindorm utilizes an architecture in which storage and computing resources are decoupled and can be separately scaled. Lindorm also provides serverless services which you can scale and pay for based on actual usage.
-
High stability
Lindorm is built on a high availability architecture and provides enterprise-grade stability. This architecture has been tested by the production environment of Alibaba Group for more than 10 years and has proven reliability.
-
High compatibility
Lindorm is compatible with the standard APIs of multiple open source services. You can connect Lindorm with various computing engines such as Spark and Flink in IoV and industrial IoT scenarios to smoothly integrate your business into the mainstream ecosystems.
Features
Converged data models
Lindorm builds a variety of data engines based on cloud native storage and allows you to query data by using the unified multi-model query mode or open-source APIs for flexible and efficient development.
Wide table engine
The wide table engine is used to store large amounts of key-value data and table data. It provides global secondary indexes, multi-dimensional queries, dynamic columns, and Time to Live (TTL). It is applicable to scenarios such as the storage of metadata, orders, bills, user personas, social networking information, feeds, and logs. The wide table engine is compatible with the open standards of multiple open source software, such as Apache HBase, Apache Phoenix, and Apache Cassandra.
Time series engine
The time series engine is used to store and process time series data such as measurement data and device operational data in scenarios such as IoT and monitoring. It provides an HTTP API and is compatible with the OpenTSDB API. It also supports SQL queries. The time series engine provides a dedicated compression algorithm for time series data. The time series engine supports multi-dimensional queries and aggregate computing of large amounts of data and provides downsampling and pre-aggregation.
Search engine
The search engine provides capabilities such as full-text searches, aggregate computing, and complex multi-dimensional queries of large amounts of text and table data. It can also be seamlessly used to store the indexes of the wide table and time series engines. This accelerates the data retrieval and queries. The search engine is applicable to scenarios such as the queries of logs, bills, and user personas. It is compatible with the open standards of the open source Solr platform.
File engine
Lindorm is designed to store large amounts of unstructured data and can provide flexible and cost-efficient file storage capabilities that are compatible with HDFS. Lindorm provides a unified storage pool that is shared by multiple data engines and allows external systems to access the underlying files in the data engines. Lindorm is suitable for various businesses such as big data analysis and data lakes, and can be accessed by using open-source HDFS clients.
Spatiotemporal engine
The spatiotemporal engine is designed to store and process large amounts of spatial, spatiotemporal, and GIS data and is compatible with the standard APIs of open source tools such as GeoMesa and GeoTools. This engine features efficient multi-dimensional indexing capability for spatiotemporal data and query capability for spatial and spatiotemporal data. You can use the spatiotemporal engine with DLA to analyze and mine information from complex spatiotemporal data. The spatiotemporal engine is ideal for business based on spatiotemporal data, such as transportation, travel, logistics, IoT, navigation, aviation, and mobile base stations.
Intelligent unified storage
Different engines in Lindorm share a cost-effective unified storage pool that can provide high reliability, scalability, and hybrid capabilities. In addition, Lindorm provides standard APIs that is compatible with open-source HDFS file systems.
Intelligent separation storage of hot and cold data
Data in Lindorm is stored in different layers in a flexible manner based on the frequency at which the data is accessed, which reduces the storage costs of cold data and improves the access performance of hot data. Applications can directly access data stored in Lindorm without modification.
Multiple storage media
Lindorm supports a series of storage media that covers multiple scenarios from high performance to low costs.
Rich Query Features
Lindorm is integrated with multiple data query features such as secondary indexes, inverted indexes, and time series indexes to quickly query and process large amounts of data.
Global secondary index
Lindorm is built based on a global distributed structure and provides strong consistency and redundancy. Lindorm is compatible with schemaless data models and automatically use indexes on demand to accelerate queries without primary keys.
Integrated storage retrieval
Lindorm integrates multiple engines, including the wide table engine, time series engine, and search engine, to store and query data in a unified manner. For example, you can synchronize the data stored in wide table and time series engine to the search engine in real time. This way, you can perform hybrid operations such as storage, multi-dimensional queries, or full-text index on large amount of data in a unified manner.
Enterprise Support
Lindorm provides multiple capabilities that are required by enterprises to run their large-scale critical business, such as security, reliability, and efficiency. Therefore, Lindorm is ideal for Internet of Things (IoT) and Internet of Vehicles (IoV) businesses.
Global geo-redundancy
Lindorm supports global data distribution and multi-master data replication. This way, applications can access data that is geographically near. In addition, Lindorm supports automatic disaster recovery and fault tolerance, which allow you to deploy applications in multiple regions around the globe.
Strong consistency and high availability
Lindorm stores multiple replicas of data in different zone and supports the cross-zone deployment of clusters to achieve data recovery based on data centers and strong data consistency. You can also use the eventual consistency mode to achieve better performance and availability.
Secure access
Lindorm provides a variety of methods such as VPC and security groups to control access and utilize a complete process that includes authentication, permission control, encryption, and audit to ensure data security.
Backup and restoration
Lindorm supports on-demand regular data backup and restoration. You can quickly restore large amounts of backup data at the specified point of time without interruption. This can help you comply to the regulations of enterprises and the government.
Low latency
Lindorm can respond to tens of millions concurrent requests within milliseconds.
Intelligent diagnostics
Lindorm is integrated with LDInsight that can be used to diagnose common problems such as slow requests and hot data. LDInsight can also be used for performance diagnostics, capacity analysis, schema design, automatic troubleshooting, and suggestion recommendation.
Compatibility with Ecosystem
Lindorm can be seamlessly integrated with computing engines, such as Spark, Flink, Data Lake Analytics (DLA), and MaxCompute.
Data tunnel
You can use other services such as LTS and DTS to synchronize real-time data or migrate full historical data between Lindorm and common storage services, such as ApsaraDB for HBase, ApsaraDB for RDS MySQL, and Log Service.
Computing and analytics
Lindorm provides standard interfaces and converts data format as required. You can integrate Lindorm with open-source computing engines such as Spark, Flink, DLA, and Hive to perform real-time interactive analysis and complex analysis in batch.
Data visualization
Lindorm can connect to QuickBI and DataV to view and analyze data in a visualized manner.
Scenarios
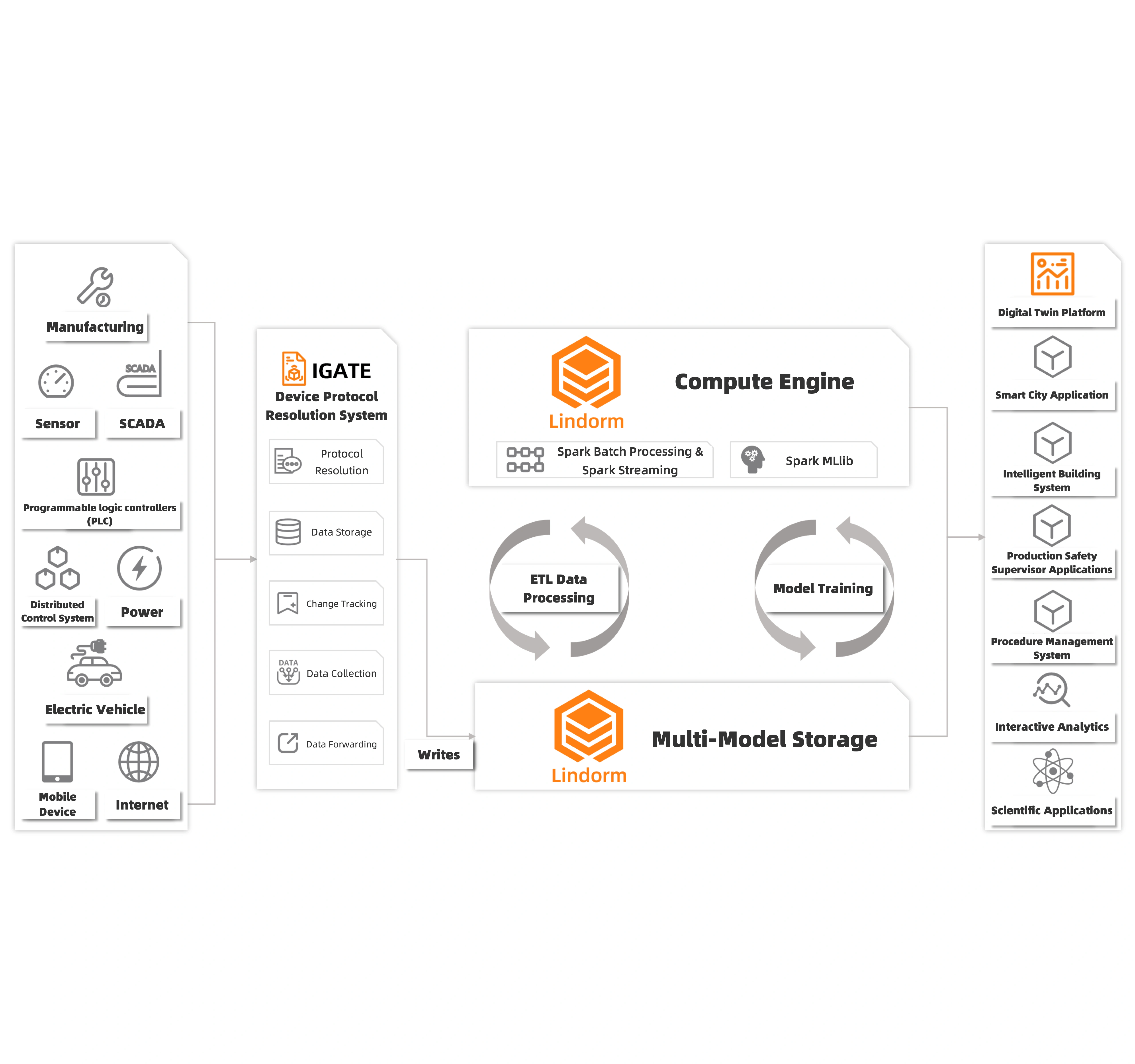
Storage and analysis for converged IT and OT data from the industrial data cloud
You can use Lindorm to store large amounts of heterogeneous IT and OT data from the industrial IoT. The data engines provided by Lindorm allow you to perform high-performance distributed computing in a cost-effective and stable manner, which can meet your requirements in a variety of scenarios such as intelligent production, interactive data exploration and analysis, AI/ML data processing, and large-scale graph computing. Lindorm communicates with a variety of upstream and downstream services in the industrial Internet to normalize and converge IT and OT data that is isolated in traditional industrial scenarios. This way, you can transmit information and configure resources in a more efficient way to implement digital and intelligent upgrade in industrial manufacturing.
Benefits
-
Cost-effectiveness
Supports high compression ratios, cold and hot data separation, and various specifications.
-
Scalability
Utilizes an architecture with storage and computing resources decoupled. This allows you to scale clusters and expand storage.
-
Hyper convergence
Integrates computing and storage resources and supports multiple distributed computing models. Provides various storage modes and access modes for out-of-the-box usage.
-
High performance
Writes data from a large number of collection points with high throughput and low latency. Data in Lindorm can be efficiently measured, calculated, and processed.
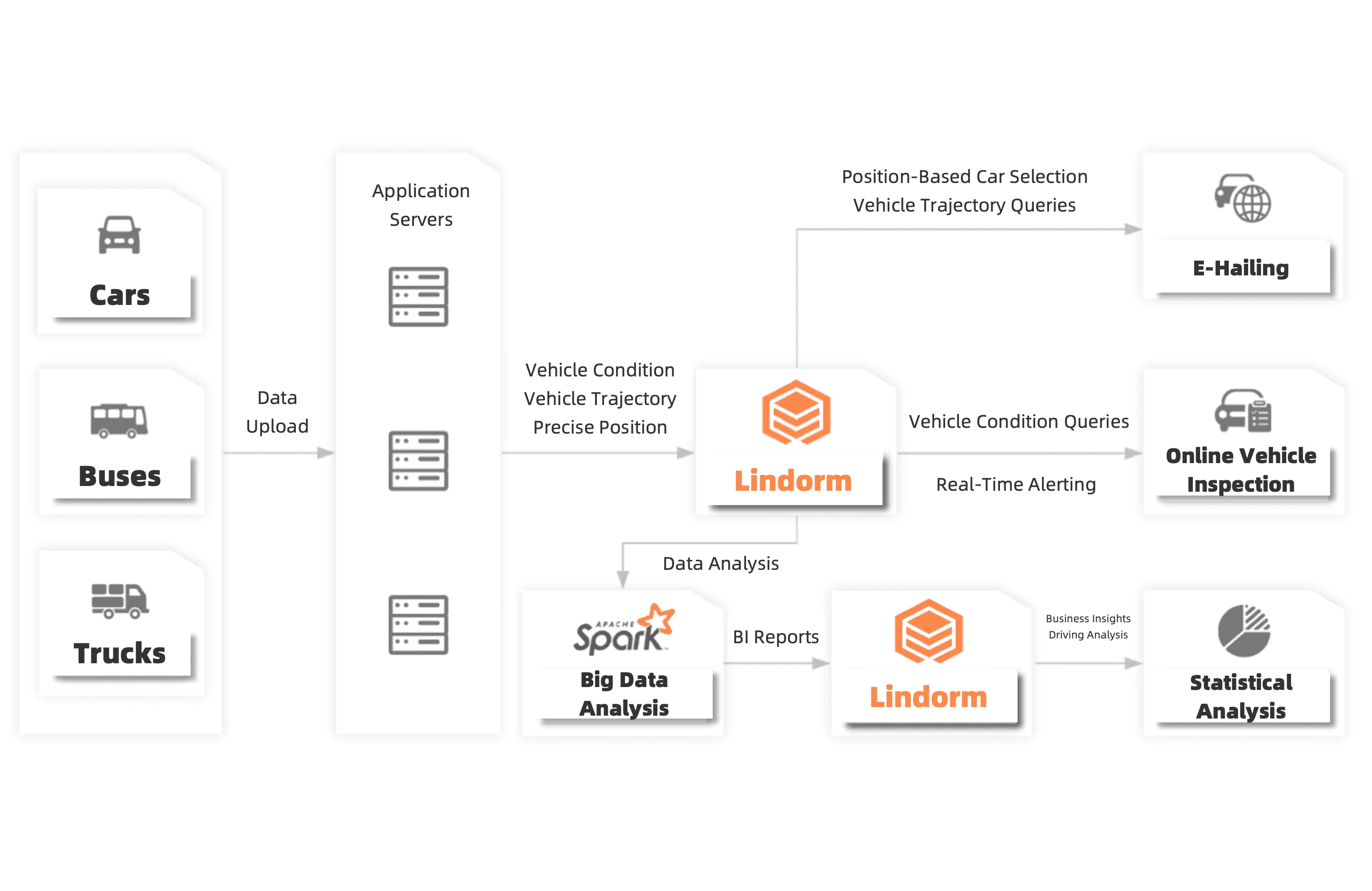
Storage an processing of vehicle trajectory and status data
You can use Lindorm to store important data such as driving trajectory, vehicle status, and precise positioning data in IoV scenarios. Lindorm provides scalable, reliable, and cost-effective services. It allows you to create effective edge services for online ride-hailing, logistics, and new energy vehicle detection.
Benefits
-
Cost-effectiveness
Supports high compression ratios, cold and hot data separation, and various specifications.
-
Scalability
Utilizes an architecture with storage and computing resources decoupled. This allows you to scale clusters and expand storage.
-
Low latency
Responds to tens of millions concurrent requests within milliseconds.
-
Flexible usage
Supports dynamic columns and the TTL mechanism. Features or tags can be automatically added or removed from dynamic columns and data automatically expires based on the TTL setting. Lindorm also stores multiple versions of data.
-
Data tunnel
Allows you to use LTS to synchronize data between Lindorm and third-party systems in a simple and efficient manner.
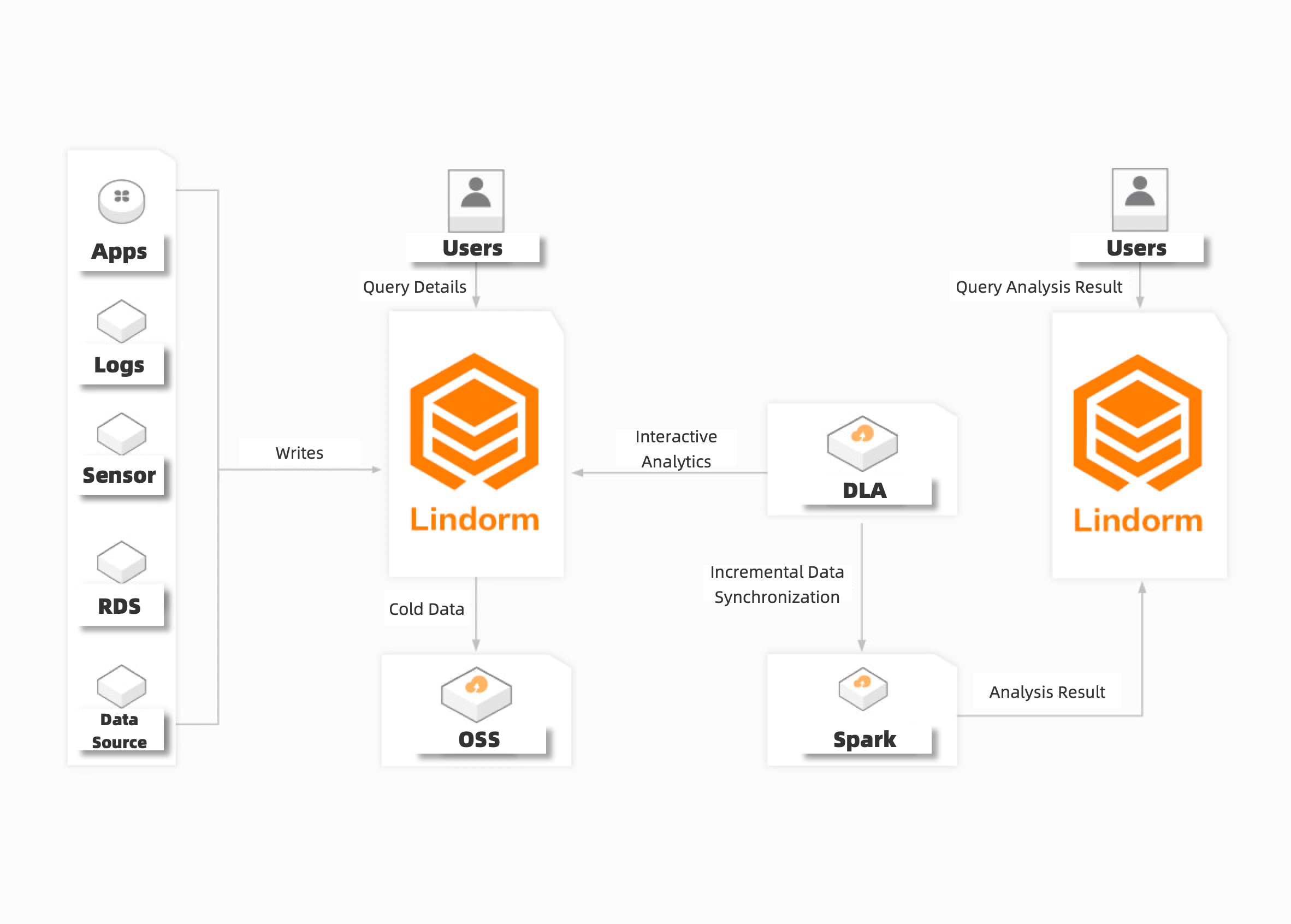
Cost-effective storage and analysis for large amounts of data
Lindorm allows you to store large amounts of data at low costs, import multiple datasets at a time, and query data in real time. You can synchronize full data or incremental data in an efficient manner. Lindorm can be integrated with big data platforms, such as Spark and MaxCompute. This enables offline analysis of large amounts of data.
Benefits
-
Cost-effectiveness
Supports high compression ratios, cold and hot data separation, and various specifications.
-
Data tunnel
Tunneled data transmission: Lindorm allows you to use Lindorm Tunnel Service (LTS) to synchronize data between Lindorm and third-party systems in a simple and efficient manner.
-
Fast import
Allows you to import a large amount of data to Lindorm by using BulkLoad. This makes data transmission faster than that of traditional methods.
-
High concurrency
Provides horizontal scaling to reach tens of millions of QPS.
-
Scalability
Lindorm uses a storage and computing-decoupled architecture. This allows you to scale clusters and expand storage.
Contact Sales
We have a global sales team available to assist you with a variety of topics, and to get you up-and-running with Alibaba Cloud.

