

JindoFS SDK is fully open for use
Big Data and OSS
In the field of traditional big data, we often use HDFS as the underlying storage, and then run MapReduce and SQL on Hadoop jobs on it. With the development of big data technology on the cloud, and the increasingly prominent bottleneck problem of the age-old HDFS, more and more users have begun to migrate HDFS data to object storage systems (such as Alibaba Cloud OSS) and then directly store them on OSS. Run MapReduce and SQL jobs. At the same time, customers are accustomed to putting machine learning data sets on OSS and performing related machine learning operations at the same time. Users gradually rely on OSS to build their data warehouses and data lakes. At this time, the speed of OSS operations will become a major factor affecting the execution efficiency of jobs.
OSS SDK
[Official SDK](https://help.aliyun.com/document_detail/52834.html) is the official SDK developed by the Alibaba Cloud OSS team, which provides Bucket management, file management, file upload and download, version management, authorized access, pictures Processing and other API interfaces. The official SDK provides Java, Python, C++ and other versions, all of which encapsulate the Restful API. The official SDK provides interfaces for all-round management of OSS resources. These interfaces are very comprehensive and relatively low-level.
Hadoop-OSS-SDK
[Hadoop-OSS-SDK](https://hadoop.apache.org/docs/stable/hadoop-aliyun/tools/hadoop-aliyun/index.html) is packaged based on the official SDK (Java version), providing Hadoop Abstraction layer for the FileSystem interface. Big data ecological systems such as Hive and Spark cannot directly use the official SDK, but they can directly operate the FileSystem interface to read and write OSS files. Hadoop-OSS-SDK is the glue between Hadoop big data ecology and OSS. The FileSystem interface mainly focuses on the file management, file upload and download functions of OSS. It does not care about the bucket management and image processing of the official SDK. It is not a substitute for the official SDK. Using the FileSystem interface, users don't need to care about when to use simple upload and when to use multipart upload, because the FileSystem interface considers these things for the user. However, if you use the official SDK, you must consider these issues, which is more complicated to use.
JindoFS SDK
[JindoFS SDK](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md) is an easy-to-use JindoFS client, currently mainly used in E-Mapreduce clusters , providing JindoFS cluster access capabilities and the ability to operate OSS files. Compared with Hadoop-OSS-SDK, it has done a lot of performance optimization. Now, the JindoFS SDK is open to the public, and we can use the SDK to obtain the ability to access OSS and obtain better performance.
JindoFS SDK is equivalent to Hadoop-OSS-SDK and can directly replace Hadoop-OSS-SDK. Different from Hadoop-OSS-SDK, JindoFS SDK is implemented directly based on OSS Restful API instead of encapsulating based on Java SDK. JindoFS SDK also provides the Hadoop FileSystem interface, and JindoFS SDK has implemented a series of performance optimizations for file management, file upload and download.
How compatible is the JindoFS SDK?
The open source version of Hadoop (as of writing this article, the latest stable version of Hadoop is 3.2.1) is based on OSS SDK version 3.4.1, which implements FileSystem interfaces such as create, open, list, and mkdir, thus supporting Hive and Spark Wait for programs to access OSS. The interfaces implemented in Hadoop-OSS-SDK are also fully supported in JindoFS SDK. The usage method is exactly the same, except that the key of some configuration items is different. It is very convenient to use, as long as the user puts the jar package of JindoFS SDK into the lib directory of hadoop, and then adds the accessKey of oss. JindoFS SDK has enhanced the compatibility of Hadoop3, such as supporting random reading of OSS (pread interface), supporting ByteBuffer reading, etc.
How much is the performance improved by using the JindoFS SDK?
We did a [JindoFS SDK and Hadoop-OSS-SDK performance comparison test](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_vs_hadoop_sdk.md), in this test we prepare Three sets of data sets have been collected and tested from different angles. Some operations such as reading, writing, moving, and deleting need to be covered, and the performance of large files and small files needs to be tested separately. This test covers most of the scenarios in normal user jobs. 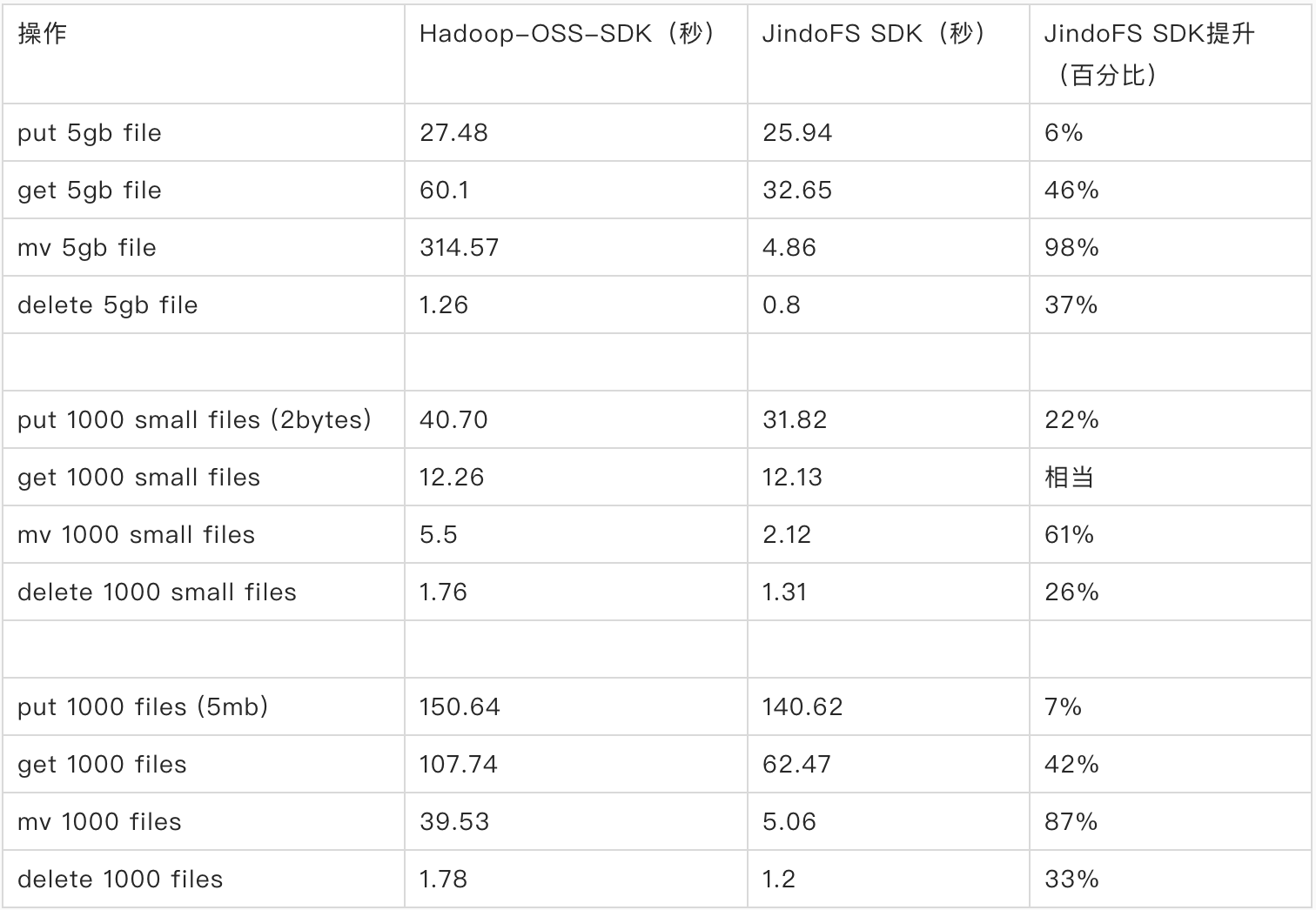 It can be seen from this test that the JindoFS SDK is , mv, and delete operations are significantly better than Hadoop-OSS-SDK.
Install the SDK
1. Install the jar package
Let's go to [github repo](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md) to download the latest jar package jindofs-sdk-x.x.x.jar, and install the sdk package to Hadoop classpath
cp ./jindofs-sdk-*.jar hadoop-2.8.5/share/hadoop/hdfs/lib/jindofs-sdk.jar
Note: Currently, the SDK only supports Linux and MacOS operating systems, because the bottom layer of the SDK uses native code.
2. Create a client configuration file
Add the following environment variables to the /etc/profile file export B2SDK_CONF_DIR=/etc/jindofs-sdk-conf Create a file /etc/jindofs-sdk-conf/bigboot.cfg containing the following main content ``` [bigboot] logger.dir = /tmp/bigboot-log [bigboot-client] client.oss.retry=5 client.oss.upload.threads=4 client.oss.upload.queue.size=5 client.oss.upload.max.parallelism=16 client.oss.timeout.millisecond=30000 client.oss.connection.timeout.millisecond=3000 ``` We can pre-configure oss ak, secret, endpoint in hadoop-2.8.5/etc/hadoop/core-site. xml to avoid filling in ak temporarily every time it is used. ``` fs.AbstractFileSystem.oss.implcom.aliyun.emr.fs.oss.OSSfs.oss.implcom.aliyun.emr.fs.oss.JindoOssFileSystemfs.jfs.cache.oss-accessKeyIdxxxfs.jfs.cache.oss-accessKeySecretxxxfs .jfs.cache.oss-endpointoss-cn-xxx.aliyuncs.com ``` Now the installation is complete, very convenient.
In addition, we recommend configuring the [password-free function](https://help.aliyun.com/document_detail/156418.html) to avoid saving the accessKey in plain text and improve security.
Usage scenario: Access OSS with Hadoop Shell
Let's try to use hadoop shell to access oss, we can use the following command to access a temporary oss bucket
``` hadoop fs -ls oss://:@./ ```
This method is not recommended for production, because the accessKey will be included in the log as part of the path.
If we have configured the accessKey in core-site.xml in advance, or configured the password-free function, then we can directly use the following command ``` hadoop fs -ls oss:/// ```
Usage scenario: store Hive tables in OSS
By default hive uses HDFS as the underlying storage, we can replace the underlying storage of hive with OSS, just modify the following configuration in hive-site.xml ``` hive.metastore.warehouse.diross://bucket/user/hive/ warehouse ``` Then, the table we created through hive will be directly stored on OSS. Subsequent queries through hive will query OSS data.
CREATE TABLE pokes_jfs(foo INT, bar STRING);
If you do not want to put the entire hive warehouse on OSS, you can also specify the location of a single table on OSS.
CREATE TABLE pokes_jfs (foo INT, bar STRING) LOCATION 'oss://bucket/warehouse/pokes_jfs.db';
Usage scenario: query OSS tables with Spark
Spark uses its own hadoop client package, so we need to copy the JindoFS SDK to the spark directory as well.
cp ./jindofs-sdk-*.jar spark-2.4.6/jars/
Then execute spark-sql to query the Hive OSS table
bin/spark-sql
select * from pokes_jfs;
In the field of traditional big data, we often use HDFS as the underlying storage, and then run MapReduce and SQL on Hadoop jobs on it. With the development of big data technology on the cloud, and the increasingly prominent bottleneck problem of the age-old HDFS, more and more users have begun to migrate HDFS data to object storage systems (such as Alibaba Cloud OSS) and then directly store them on OSS. Run MapReduce and SQL jobs. At the same time, customers are accustomed to putting machine learning data sets on OSS and performing related machine learning operations at the same time. Users gradually rely on OSS to build their data warehouses and data lakes. At this time, the speed of OSS operations will become a major factor affecting the execution efficiency of jobs.
OSS SDK
[Official SDK](https://help.aliyun.com/document_detail/52834.html) is the official SDK developed by the Alibaba Cloud OSS team, which provides Bucket management, file management, file upload and download, version management, authorized access, pictures Processing and other API interfaces. The official SDK provides Java, Python, C++ and other versions, all of which encapsulate the Restful API. The official SDK provides interfaces for all-round management of OSS resources. These interfaces are very comprehensive and relatively low-level.
Hadoop-OSS-SDK
[Hadoop-OSS-SDK](https://hadoop.apache.org/docs/stable/hadoop-aliyun/tools/hadoop-aliyun/index.html) is packaged based on the official SDK (Java version), providing Hadoop Abstraction layer for the FileSystem interface. Big data ecological systems such as Hive and Spark cannot directly use the official SDK, but they can directly operate the FileSystem interface to read and write OSS files. Hadoop-OSS-SDK is the glue between Hadoop big data ecology and OSS. The FileSystem interface mainly focuses on the file management, file upload and download functions of OSS. It does not care about the bucket management and image processing of the official SDK. It is not a substitute for the official SDK. Using the FileSystem interface, users don't need to care about when to use simple upload and when to use multipart upload, because the FileSystem interface considers these things for the user. However, if you use the official SDK, you must consider these issues, which is more complicated to use.
JindoFS SDK
[JindoFS SDK](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md) is an easy-to-use JindoFS client, currently mainly used in E-Mapreduce clusters , providing JindoFS cluster access capabilities and the ability to operate OSS files. Compared with Hadoop-OSS-SDK, it has done a lot of performance optimization. Now, the JindoFS SDK is open to the public, and we can use the SDK to obtain the ability to access OSS and obtain better performance.
JindoFS SDK is equivalent to Hadoop-OSS-SDK and can directly replace Hadoop-OSS-SDK. Different from Hadoop-OSS-SDK, JindoFS SDK is implemented directly based on OSS Restful API instead of encapsulating based on Java SDK. JindoFS SDK also provides the Hadoop FileSystem interface, and JindoFS SDK has implemented a series of performance optimizations for file management, file upload and download.
How compatible is the JindoFS SDK?
The open source version of Hadoop (as of writing this article, the latest stable version of Hadoop is 3.2.1) is based on OSS SDK version 3.4.1, which implements FileSystem interfaces such as create, open, list, and mkdir, thus supporting Hive and Spark Wait for programs to access OSS. The interfaces implemented in Hadoop-OSS-SDK are also fully supported in JindoFS SDK. The usage method is exactly the same, except that the key of some configuration items is different. It is very convenient to use, as long as the user puts the jar package of JindoFS SDK into the lib directory of hadoop, and then adds the accessKey of oss. JindoFS SDK has enhanced the compatibility of Hadoop3, such as supporting random reading of OSS (pread interface), supporting ByteBuffer reading, etc.
How much is the performance improved by using the JindoFS SDK?
We did a [JindoFS SDK and Hadoop-OSS-SDK performance comparison test](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_vs_hadoop_sdk.md), in this test we prepare Three sets of data sets have been collected and tested from different angles. Some operations such as reading, writing, moving, and deleting need to be covered, and the performance of large files and small files needs to be tested separately. This test covers most of the scenarios in normal user jobs.  It can be seen from this test that the JindoFS SDK is , mv, and delete operations are significantly better than Hadoop-OSS-SDK.
Install the SDK
1. Install the jar package
Let's go to [github repo](https://github.com/aliyun/aliyun-emapreduce-datasources/blob/main/docs/jindofs_sdk_how_to.md) to download the latest jar package jindofs-sdk-x.x.x.jar, and install the sdk package to Hadoop classpath
cp ./jindofs-sdk-*.jar hadoop-2.8.5/share/hadoop/hdfs/lib/jindofs-sdk.jar
Note: Currently, the SDK only supports Linux and MacOS operating systems, because the bottom layer of the SDK uses native code.
2. Create a client configuration file
Add the following environment variables to the /etc/profile file export B2SDK_CONF_DIR=/etc/jindofs-sdk-conf Create a file /etc/jindofs-sdk-conf/bigboot.cfg containing the following main content ``` [bigboot] logger.dir = /tmp/bigboot-log [bigboot-client] client.oss.retry=5 client.oss.upload.threads=4 client.oss.upload.queue.size=5 client.oss.upload.max.parallelism=16 client.oss.timeout.millisecond=30000 client.oss.connection.timeout.millisecond=3000 ``` We can pre-configure oss ak, secret, endpoint in hadoop-2.8.5/etc/hadoop/core-site. xml to avoid filling in ak temporarily every time it is used. ``` fs.AbstractFileSystem.oss.implcom.aliyun.emr.fs.oss.OSSfs.oss.implcom.aliyun.emr.fs.oss.JindoOssFileSystemfs.jfs.cache.oss-accessKeyIdxxxfs.jfs.cache.oss-accessKeySecretxxxfs .jfs.cache.oss-endpointoss-cn-xxx.aliyuncs.com ``` Now the installation is complete, very convenient.
In addition, we recommend configuring the [password-free function](https://help.aliyun.com/document_detail/156418.html) to avoid saving the accessKey in plain text and improve security.
Usage scenario: Access OSS with Hadoop Shell
Let's try to use hadoop shell to access oss, we can use the following command to access a temporary oss bucket
``` hadoop fs -ls oss://:@./ ```
This method is not recommended for production, because the accessKey will be included in the log as part of the path.
If we have configured the accessKey in core-site.xml in advance, or configured the password-free function, then we can directly use the following command ``` hadoop fs -ls oss:/// ```
Usage scenario: store Hive tables in OSS
By default hive uses HDFS as the underlying storage, we can replace the underlying storage of hive with OSS, just modify the following configuration in hive-site.xml ``` hive.metastore.warehouse.diross://bucket/user/hive/ warehouse ``` Then, the table we created through hive will be directly stored on OSS. Subsequent queries through hive will query OSS data.
CREATE TABLE pokes_jfs(foo INT, bar STRING);
If you do not want to put the entire hive warehouse on OSS, you can also specify the location of a single table on OSS.
CREATE TABLE pokes_jfs (foo INT, bar STRING) LOCATION 'oss://bucket/warehouse/pokes_jfs.db';
Usage scenario: query OSS tables with Spark
Spark uses its own hadoop client package, so we need to copy the JindoFS SDK to the spark directory as well.
cp ./jindofs-sdk-*.jar spark-2.4.6/jars/
Then execute spark-sql to query the Hive OSS table
bin/spark-sql
select * from pokes_jfs;
Related Articles
-
A detailed explanation of Hadoop core architecture HDFS
Knowledge Base Team
-
What Does IOT Mean
Knowledge Base Team
-
6 Optional Technologies for Data Storage
Knowledge Base Team
-
What Is Blockchain Technology
Knowledge Base Team
Explore More Special Offers
-
Short Message Service(SMS) & Mail Service
50,000 email package starts as low as USD 1.99, 120 short messages start at only USD 1.00


