

Next-generation Platform for Elastic Big Data Processing
E-MapReduce (EMR) is a cloud-native open source big data platform that provides easy-to-integrate open source big data computing and storage engines, such as Hadoop, Hive, Spark, StarRocks, Doris, Presto and Trino. EMR computing resources can be flexibly scaled. You can deploy EMR clusters on top of Alibaba Cloud Elastic Compute Service (ECS), Container Service for Kubernetes (ACK), or a serverless architecture.
Widely adopted for log analytics, customer analytics and profiling, IoT analytics, and financial data analysis, EMR reduces IT costs, streamlines operations and maintenance, and frees organizations to focus on core innovation—positioning it as an industry‑leading platform for large‑scale data processing.
Benefits

-
Full Compatibility with Open Source Components
EMR is 100% built on open source components and evolves with the iterations of open source component versions.

-
High Security and Reliability
EMR allows you to create a big data computing environment within minutes. Features such as intelligent diagnostics and analysis, Kerberos authentication, and data encryption are supported.

-
Cost-effectiveness
Computing resources are used on demand, hot and cold data is stored at different layers, and preemptible Alibaba Cloud instances are supported.

-
Elastic Resources
Cluster resources can be dynamically adjusted by Cluster workload or in the specified period of time. Auto scaling for clusters can be completed within minutes, and multiple elastic resource types are supported.
Scenarios




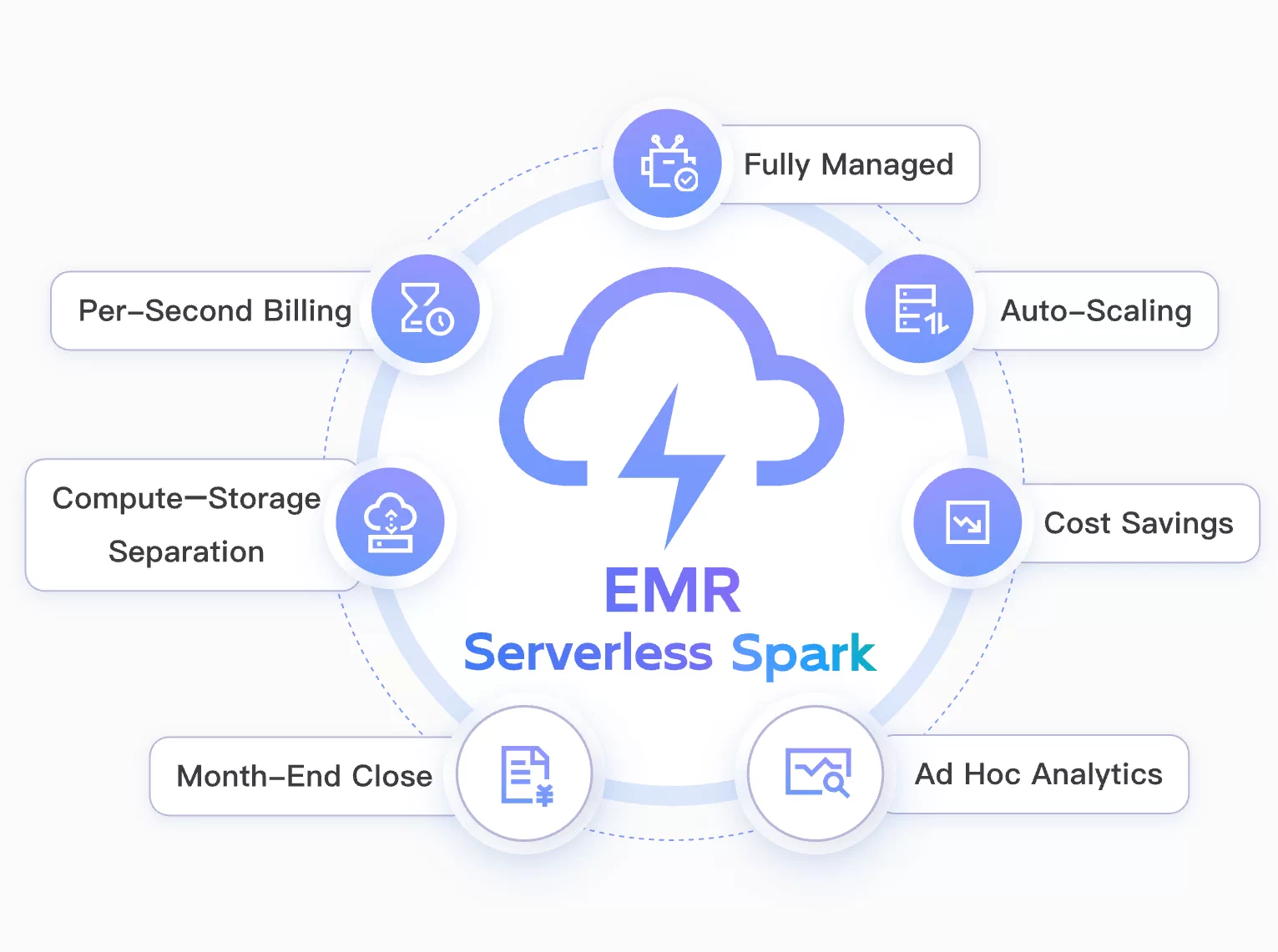
Serverless Elastic Compute
Elastic, pay-as-you-go Spark with EMR Serverless
EMR Serverless Spark decouples compute and storage with per-second billing, reducing burst compute costs by 40%+ for elastic workloads such as month-end close and ad hoc analytics.
Benefits
Compute–Storage Separation
Scale compute independently without re-provisioning storage.
Per-Second Billing
Pay only for the resources used, by the second.
Lower Burst Cost
Reduce burst compute costs by 40%+ for spiky workloads.

Serverless Real-time Analytics
Fully managed EMR Serverless StarRocks for sub-second analytics
EMR Serverless StarRocks provides a fully managed, vectorized MPP engine for sub-second ad hoc queries, with automatic scale in/out for traffic spikes, high availability without ops overhead, and 30%–70% lower storage cost via compute–storage separation.
Benefits
Sub-Second Ad Hoc Queries
Vectorized MPP delivers interactive performance at scale.
Auto Scaling
Scale in/out automatically to absorb peak traffic.
Fully Managed HA
Reduce ops overhead while maintaining high availability.
Lower Storage Cost
Cut storage cost by 30%–70% with compute–storage separation.
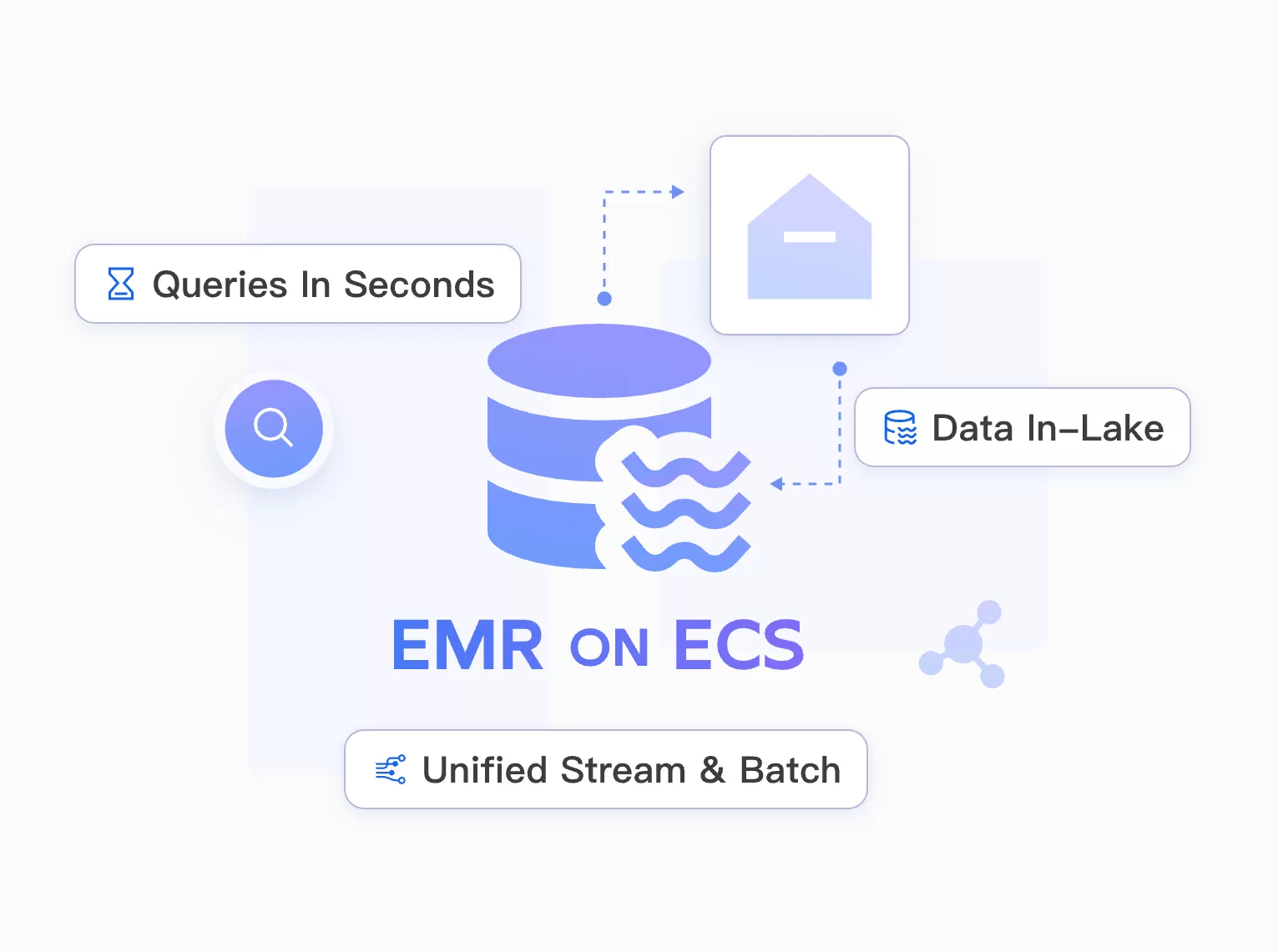
Real-time Lakehouse Analytics
Stream–batch unified analytics on EMR on ECS
EMR on ECS unifies streaming and batch processing to ingest data into the lake in minutes and return query results in seconds, powering real-time dashboards and user behavior analytics.
Benefits
Unified Stream & Batch
Run streaming and batch workloads on a single architecture.
Fast Ingestion & Queries
Minutes-level ingestion with seconds-level query responses.
Real-time Insights
Enable live dashboards and user behavior analytics.
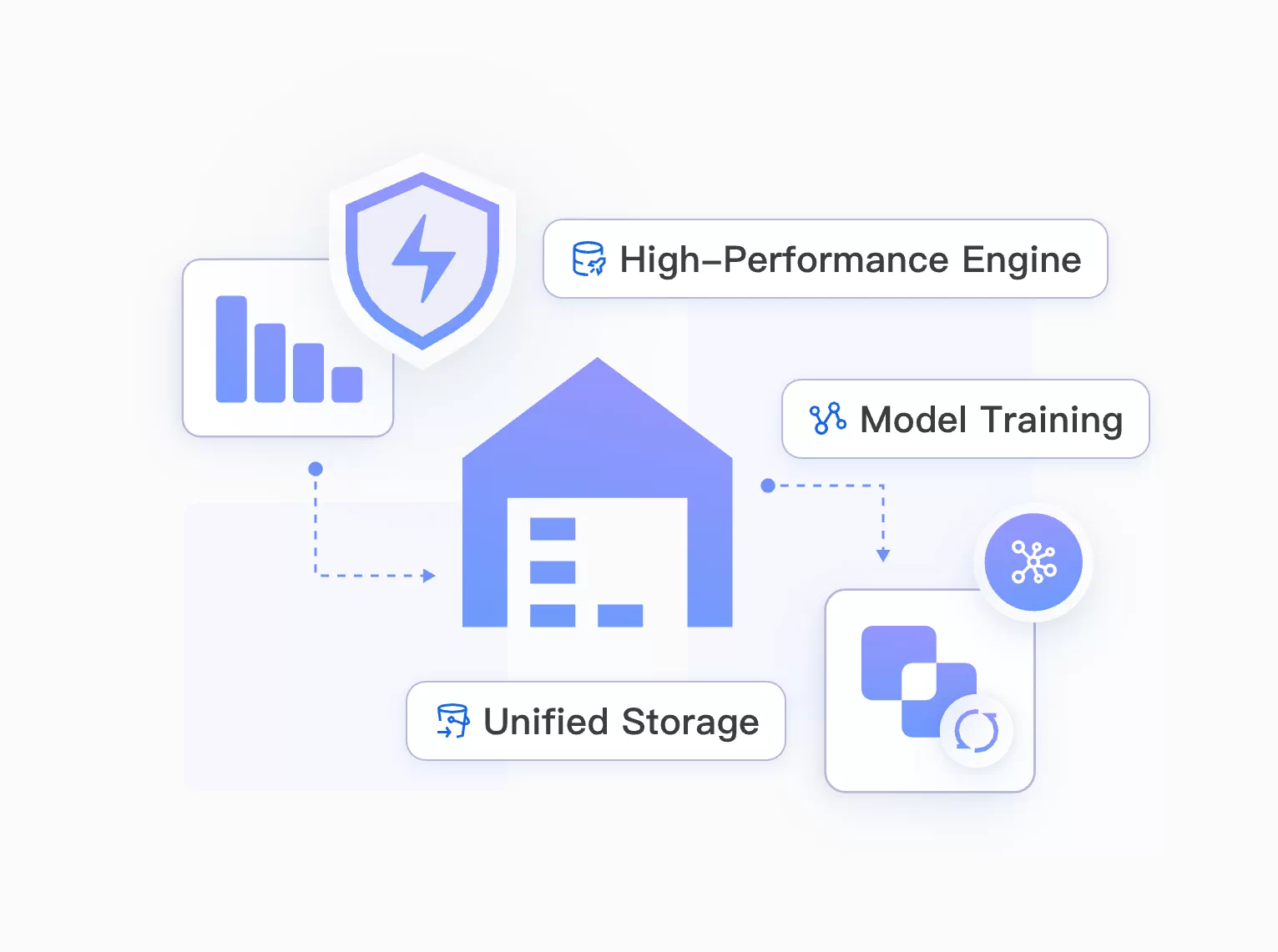
AI-Enhanced Data Processing
End-to-end AI pipeline from Spark to model training
EMR integrates Spark feature engineering with PAI large-model training to deliver an end-to-end pipeline—from data preprocessing to Qwen3 fine-tuning.
Benefits
Integrated Feature-to-Training Flow
Link Spark feature engineering directly to PAI training.
End-to-End Automation
Move from preprocessing to Qwen3 fine-tuning in one pipeline.
Faster Iteration
Shorten the cycle from data preparation to model updates.
Customer Success Stories
Learn about how EMR enables Customer's realtime data analytics.





Upgraded Support For You
1 on 1 Presale Consultation, 24/7 Technical Support, Faster Response, and More Free Tickets.
1 on 1 Presale Consultation
24/7 Technical Support
6 Free Tickets per Quarter


