
Support for Heterogeneous Computing in All Scenarios
Elastic GPU Service provides a complete service system that combines software and hardware to help you flexibly allocate resources, elastically scale your system, improve computing power, and lower the cost of your AI-related business. It applies to scenarios (such as deep learning, video encoding and decoding, video processing, scientific computing, graphical visualization, and cloud gaming).
Elastic GPU Service provides GPU-accelerated computing capabilities and ready-to-use, scalable GPU computing resources. GPUs have unique advantages in performing mathematical and geometric computing, especially floating-point and parallel computing. GPUs provide 100 times the computing power of their CPU counterparts.
Varied Computing Capabilities
It has a large number of arithmetic logic units (ALUs) that can be used for large-scale parallel computing. Elastic GPU Service uses the latest GPU acceleration chips and provides various accelerator cards (such as FPGA, GPU, and ASIC) to serve business purposes (such as AI, graphics, transcoding, and encryption).
Ease of Use
GPU resources are globally deployed across different geographical locations. Simple logic control units allow you to scale your system based on your business requirements. Elastic GPU Service also provides auxiliary tools (like AIACC, FastGPU, and cGPU).
High Network Performance
It uses the SHENLONG architecture to improve server performance and reduce I/O latency. GPU supports up to 24 million pps, a bandwidth of up to 64 Gbit/s over VPCs. It is suitable for high-throughput scenarios where multiple threads run in parallel to process computing tasks.
GPU Software for Improving Computing Efficiency
AIACC-Training
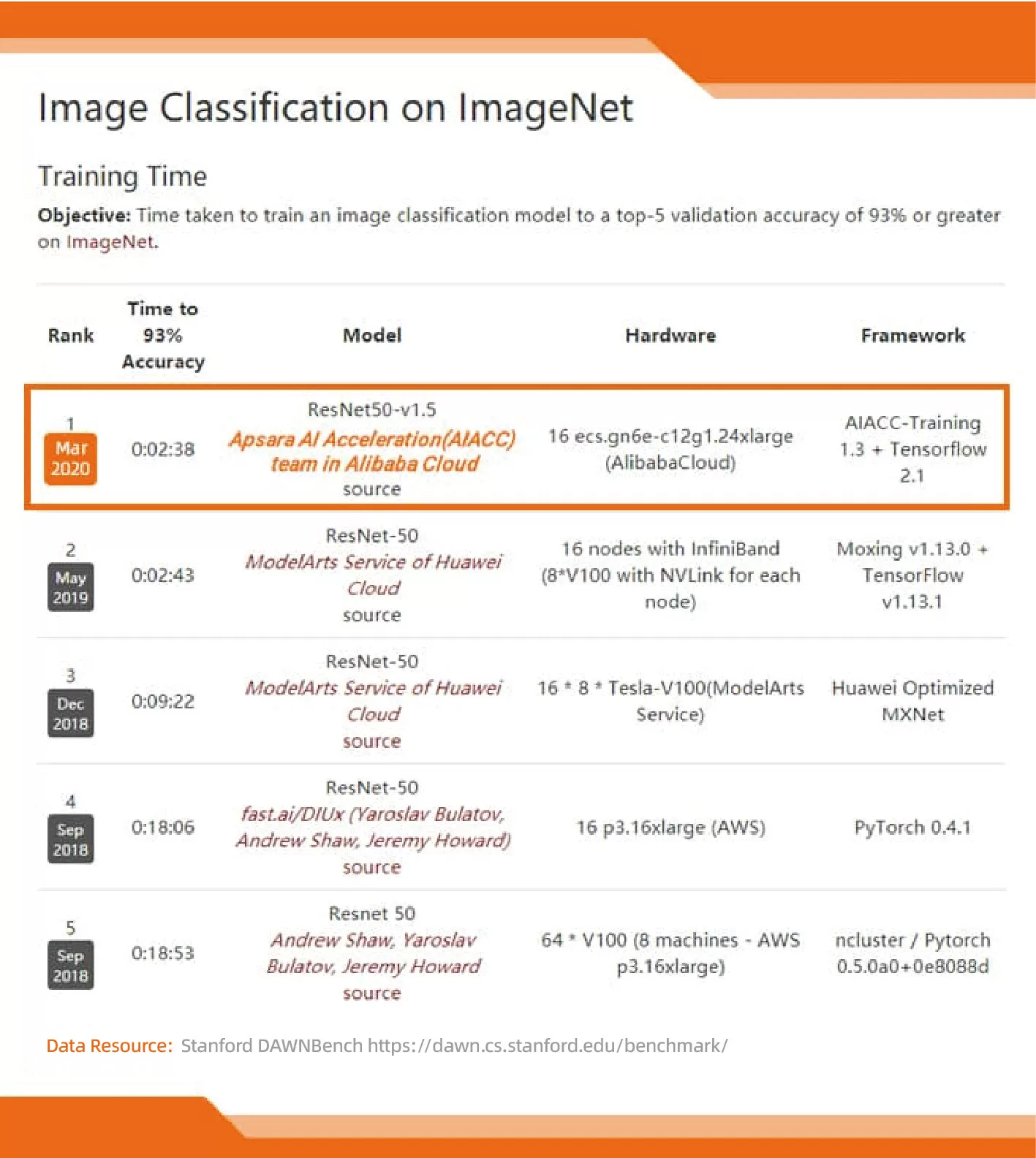
Alibaba Cloud AIACC-Training is an AI accelerator optimized for Alibaba Cloud environments. It can significantly improve the efficiency of AI distributed training and network bandwidth utilization. AIACC-Training has set two world records:
Fastest training speed in the DAWNBench ImageNet competition (held by Stanford University)
Lowest training cost in the DAWNBench ImageNet competition (held by Stanford University)
Learn More >
Features
-
 Supports Main Frameworks
Supports Main FrameworksDistributed training frameworks: TensorFlow, PyTorch, MXNet, and Caffe
-
50%-300% Performance Improvements
Bandwidth-intensive network models
-
High-Performance Communication for One or More Multi-GPU Servers
Supports FP16 gradient compression and mixed precision compression
-
API Extensions for MXNet
Supports data parallelism and model parallelism of the InsightFace type
-
Deep Optimization for RDMA Networks
Hybrid link communication (RDMA and VPC)
Works Best With


AIACC-Inference
Alibaba Cloud AIACC-Inference is an AI accelerator optimized for Alibaba Cloud environments. It can significantly improve GPU utilization and inference performance. AIACC-Inference has set two world records:
Lowest inference latency in the DAWNBench ImageNet competition (held by Stanford University)
Lowest inference cost in the DAWNBench ImageNet competition (held by Stanford University)
Learn More >
Features
-
Supports Multiple Frameworks
Tensorflow, Pytorch, MXNet, and other deep learning frameworks can export models in the Open Neural Network Exchange (ONNX) format to improve inference performance
-
30%-400% Performance Improvements
Compute-intensive network models
-
Supports Multiple Model Precisions
Model optimization on FP32 and FP16
Works Best With
GPU Cluster Deployment Tool
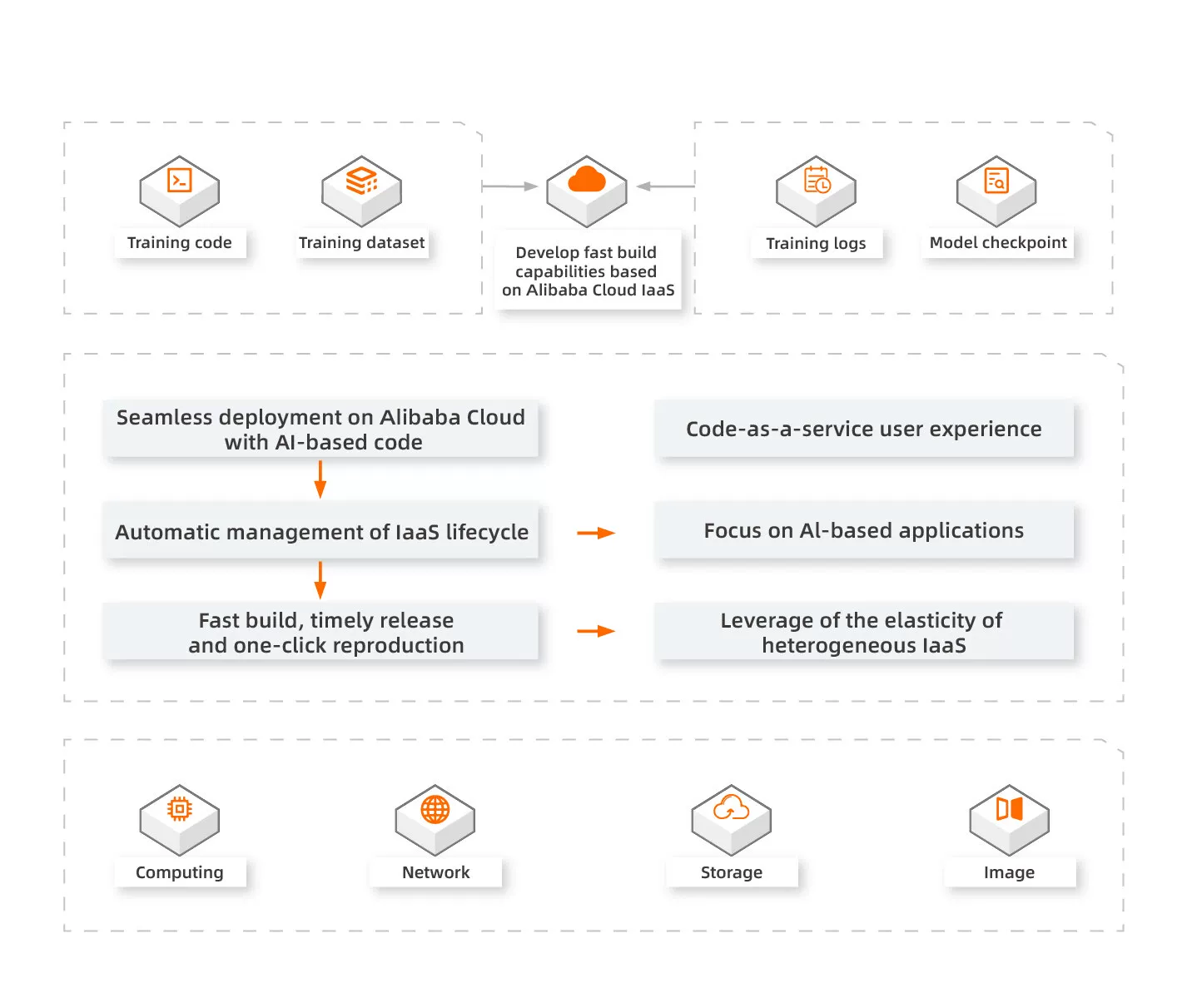
Alibaba Cloud FastGPU is a set of fast deployment tools for GPU clusters to help deploy GPU computing resources on the cloud with just a few clicks. FastGPU is simple to configure and can be used anywhere with ease. FastGPU provides a time-saving, cost-effective, and easy-to-use solution for the fast deployment of GPU clusters.
Learn More >
Features
-
Quick Deployment
API operations for fast deployment of offline training and inference scripts in GPU clusters
-
Easy Management
Provides a command-line tool to manage the status and lifecycle of GPU clusters
-
Efficient and Time-Saving
You do not need to perform deployment operations for computing, storage, and network at the IAAS layer of Alibaba Cloud. The appropriate environment is automatically attained when you obtain cluster resources.
Works Best With
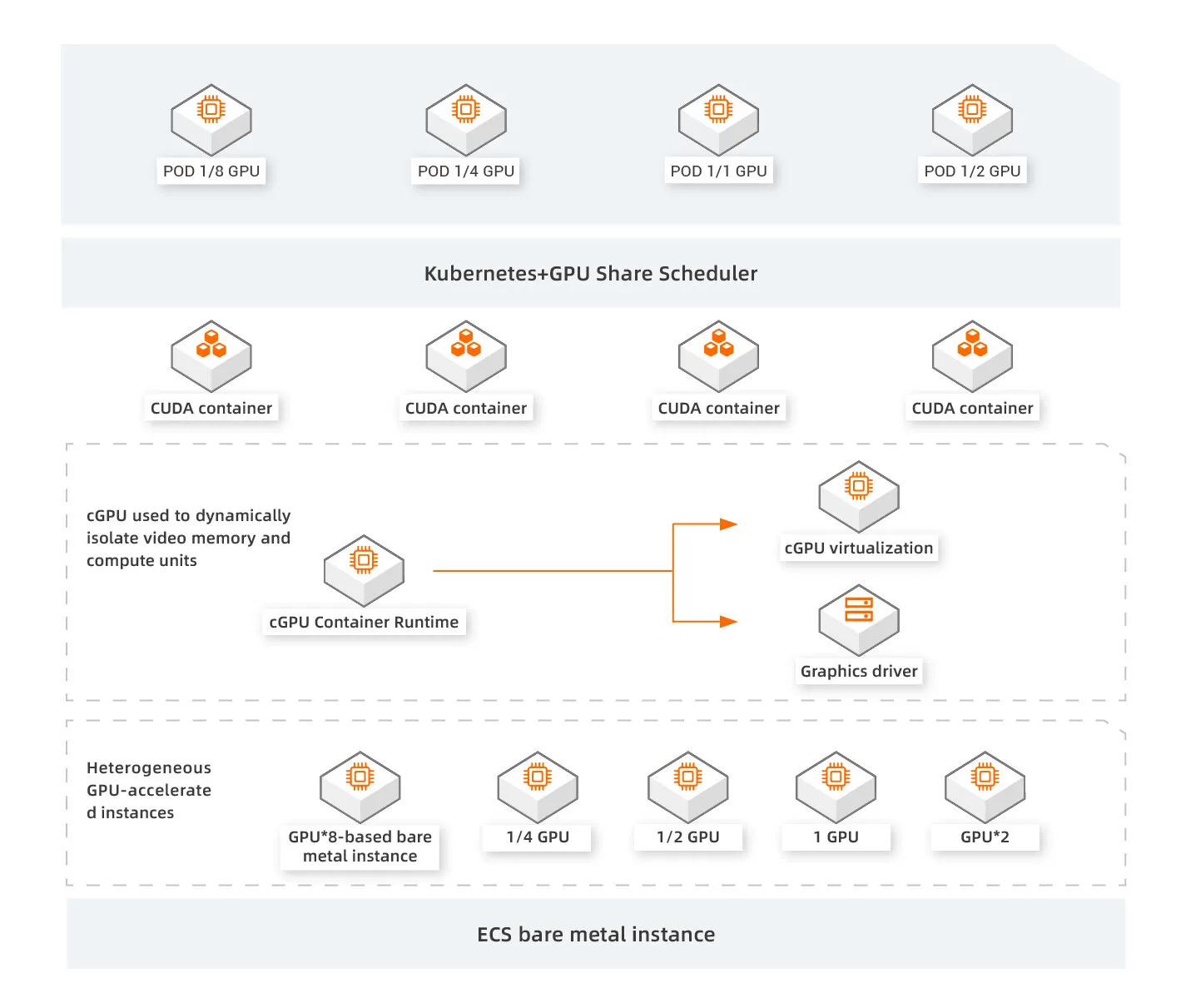
GPU Sharing Software for Containers
It allows multiple containers to use a single GPU by splitting and assigning GPU resources to multiple isolated containers. cGPU can run multiple containers on a single GPU and isolate the GPU applications among the containers. This way, the GPU hardware resource utilization is improved.
Learn More >
Features
-
GPU Splitting
Splits GPU resources to improve GPU utilization
-
GPU Sharing
Cost savings through GPU sharing across multiple AI applications
-
Flexibility
Flexibly splits computing power and GPU memory to meet application requirements
Works Best With

Elastic GPU Service VS self-managed GPU-accelerated servers
| Item | Elastic GPU Service | Self-Managed GPU-Accelerated Server |
|---|---|---|
|
|
· Allows you to create one or more GPU-accelerated instances with ease · Flexible instance configuration changes — when instance no longer meets your needs, a simple reboot is all it takes to switch between various specs within the same family. · Provides adjustable bandwidths |
· Requires an extended subscription period · Has configurations that cannot be changed · Requires one-off purchase of outbound bandwidth that cannot be adjusted |
|
|
· Provides a web-based console for online management · Has a built-in mainstream operating system (such as an activated genuine Windows operating system) and allows the operating system to be replaced online · Allows you to purchase and install GPU drivers when you purchase the instance |
· Does not provide online management tools and requires manual management and maintenance ・You need to bring your own operating system, install, and replace it by yourself ・You must manually prepare and install the operating systems |
|
|
· Stores three copies of each piece of data. When one copy is corrupted, the data can be restored quickly · Hardware failures can be recovered quickly and automatically |
· You must manually build a disaster recovery environment and use expensive traditional storage devices · You must manually fix the corrupted data |
|
|
· Supports the subscription and pay-as-you-go billing methods. You can select an appropriate billing method based on your business needs · Allows you to purchase on-demand resources without making a large upfront investment |
· Requires you to purchase resources by paying upfront to meet the configuration requirements of peak hours · Requires a large upfront investment and results in a waste of resources |
Scenarios
Industry-Leading Solution and High Performance
Alibaba Cloud Elastic GPU Service provides industry-leading solutions that can deliver high performance, scalability, and enterprise-grade reliability on engineering simulation and analysis. With the help of large GPU memory size and high GPU performance, you can leverage its computing power to perform complex simulations and solve challenging problems.
Benefits
-
Optimized Solution
Leverages CFD modeling to reduce resolution time significantly
-
Accelerated Electronic Design of Computational Electromagnetics
Help design high-performance electronic products and components by simulating an electromagnetic performance and predicting electromagnetic radiation, interference, and transmission
-
Engineering Simulation
Virtualized applications on the cloud that boost productivity and save IT budgets
Works Best With
HD Video Processing for the Best Display
Video processing tasks often encounter issues (such as large data volumes and long processing times). GPU can compute tasks in parallel and can be used for video processing optimization. GPU is mainly used in fields (such as large-scale high-definition video transcoding, 4K and 8K livestreaming, multi-user video conferencing, and video source repairing).
Benefits
-
High Performance
Optimizations to improve computing performance
-
Superior Computing Power
Supports fast processing of multi-frame data and computing power to process a large number of computing tasks
Works Best With
High-Performance Computing
GPU plays an essential role in scientific computing (such as meteorological prediction, hydrocarbon exploration, and molecular dynamics research), which requires large-scale parallel computing. In combination with elastic computing, GPU provides the computing power required for large-scale floating-point operations. Such computing power is available online and offline.
Benefits
-
Auto Scaling
Integrates with ESS and SLB to implement auto scaling
-
Superior Computing Power
Provides the latest GPUs and quick deployment methods to meet the large computing requirements of scientific computing
Works Best With


Success Stories

The biggest deciding factor was recognition accuracy - the Vision AI Platform recognized license plates for mosaic processing with more than 90% accuracy from the very beginning of the validation process.
After further detailed tuning, the system was able to automatically perform recognition and mosaic processing with an accuracy of over 95% at the time of introduction.
– Mr. Chiaki Uchiyama, Section Leader, Frima Marketing Section, Frima Division, IDOM Co.
IDOM Inc. (Chiyoda-ku, Tokyo) operates a used car sales and purchase business that handles one of the largest scale vehicle distribution data in Japan, recently opening super-sized stores with enhanced maintenance, sheet metal, and after-sales services.
The IDOM platform allows users to freely upload photos of vehicles they plan to sell, but it faces limitation problems of self-service and increased working hours due to manual checks and reworks. Alibaba Cloud can help provide highly accurate image recognition technology and face-to-face support.

Ms-meta.HK leveraged a variety of services by Alibaba Cloud in its solution implementation. These services (along with Alibaba Cloud's local technical experts and dedicated support team) enabled Ms-meta.HK to easily launch its Metaverse offering to the public.
Ms-meta.HK is a decentralized, community-driven Metaverse project based in Hong Kong. Ms-meta.HK actively utilizes Alibaba Cloud’s cloud rendering and traffic distribution technologies in its Metaverse. Collaborating with Alibaba Cloud allows Ms-meta.HK to optimize the virtual scenes in its Metaverse and reduce the loading time to provide customers with a better user experience. Furthermore, the company can protect its publicly exposed servers thanks to Alibaba Cloud's robust security offering. Ms-meta.HK hopes to further optimize its Metaverse infrastructure services with the help of Alibaba Cloud.

As part of its core business, ADVANCE utilizes various cloud-native data storage and management solutions on Alibaba Cloud to manage its data warehouse and data analytics processes for its AI and machine learning algorithm. For example, ADVANCE uses ApsaraDB for Redis for in-memory caching and high-speed access, ApsaraDB for MongoDB for flexible and semi-structured data storage, DataWorks for data aggregation, processing, and governance between various data sources, and Realtime Compute for Apache Flink for real-time big data processing.
Advance Intelligence Group (ADVANCE) is an Al-driven technology company in the Asia-Pacific and one of the top players in the Southeast Asian (SEA) market, especially in Indonesia.
ADVANCE is committed to providing its customers with enhanced AI services. Alibaba Cloud will continue to support ADVANCE to achieve success through innovative cloud infrastructure services. The combination of AI and cloud computing will deliver much more value to customers with greater efficiency, productivity, and digital security.

