
Build AI/Machine Learning on Kubernetes
Cloud-native AI provides a set of essential features and services to help clients to build an AI platform, accelerate AI workloads and simplify MLOps.
Resource Scalability
Improves the utilization of GPUs and CPUs and enhances the scalability of heterogeneous resources.
Efficient Scheduling
Schedules AI and big data tasks in an efficient manner and provides end-to-end support for the entire AI production process.
Accelerated Data Access
Improves data access performance and integrates heterogeneous data sources.
Observability
Supports various methods that are used to observe tasks, user quotas, and resources.
Flexibility and Extensibility
Allows you to create a custom cloud-native AI platform by modifying the component-based extensible architecture.
Standard Kubernetes
Runs on standard Kubernetes and is compatible with public clouds, Apsara Stack, hybrid clouds, and ACK edge clusters.
Features
Efficient Utilization of Heterogeneous Resources
Supports GPU scheduling, GPU sharing and memory isolation. You can configure various policies to allocate GPUs and monitor the consumption of GPU resources from multiple dimensions.
Improved Data Access Performance
Separates computing and storage. Fluid abstracts data for cloud-native AI and big data applications to accelerate data access. Fluid also enhances the security isolation of data and eliminates data silos that are caused by different storage types.
AI Task Scheduling
Supports various scheduling policies (such as gang scheduling, capacity scheduling, and binpack scheduling) to meet the requirements of AI tasks and enhance cluster resource utilization.
Auto Scaling of Heterogeneous Resources
Performs intelligent load shifting to prevent cloud resource waste. Cloud-native AI also supports elastic model training and model-based inference.
Observable Cluster Tasks, Users, and Resources
Provides monitoring dashboards for tasks, user quotas, and cluster resources to help you evaluate inputs and outputs.
Scenarios

Benefits
-
Resource Allocation Based on Project Groups
You can divide project members into isolated groups. Then, you can allocate and isolate resources based on groups or manage the permissions of different groups.
-
Isolation and Sharing among Users
You can allocate cluster resources to user groups based on your business requirements. You can also manage the permissions of users in each group. The permissions include the read and write permissions of users on jobs, and the read and write permissions of jobs on data.
-
Elastic Quotas
You can use elastic quota groups for capacity scheduling to share resources and appropriately allocate resources to users. This improves the overall resource utilization of clusters.
Benefits
-
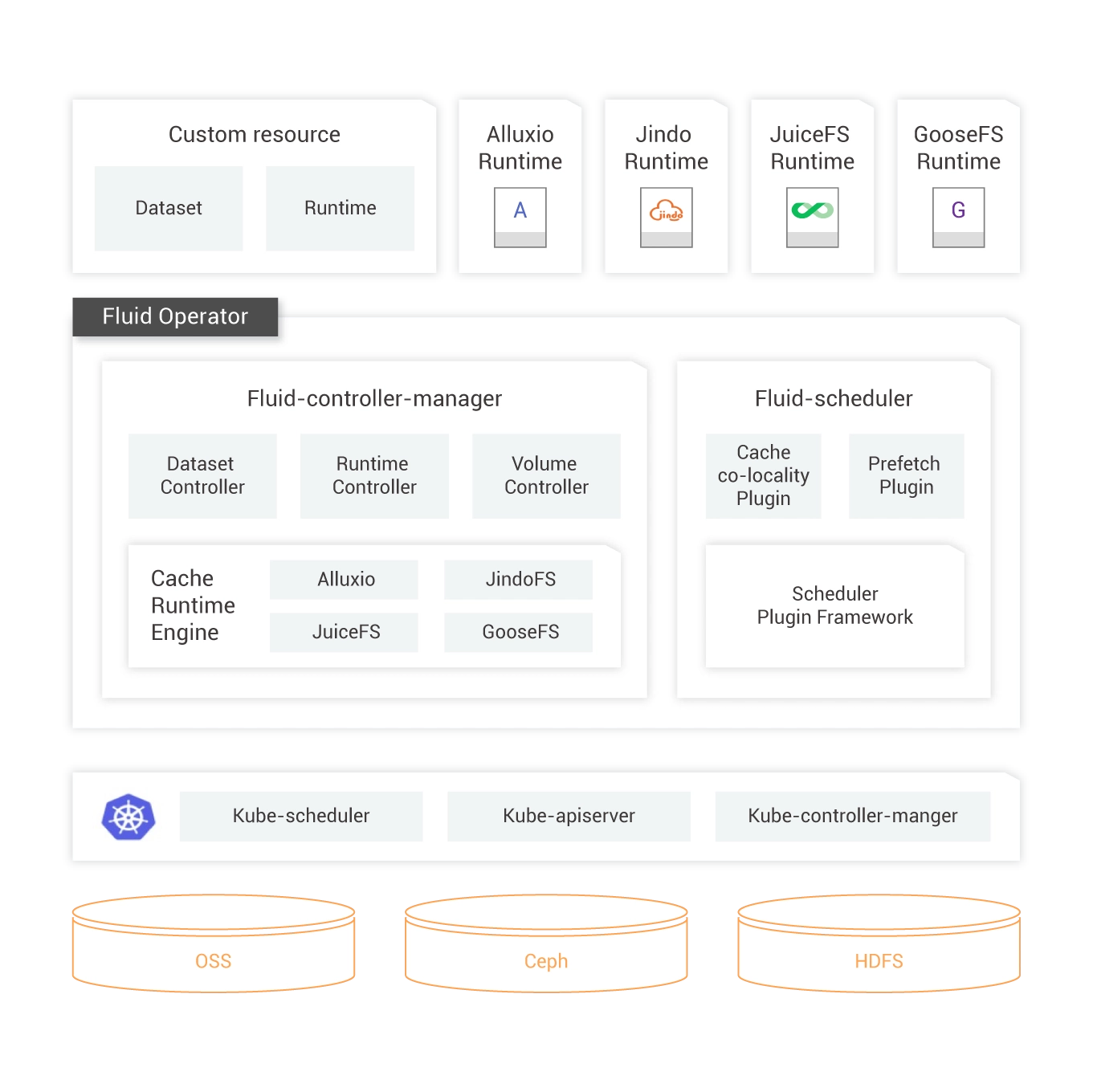
Native Support for Dataset Abstraction
Cloud-native AI packages the fundamental capabilities that are required by data-intensive applications into functions. This achieves efficient data access and reduces management costs of heterogeneous data.
-
Data preload and Acceleration on the Cloud
Fluid uses the distributed caching engines to support data preload and acceleration on the cloud. This ensures the observability, portability, and automatic horizontal scalability of cached data.
-
Collaborative Orchestration of Data and Applications
When you schedule applications and data on the cloud, you can coordinate the orchestration of applications and data based on characteristics and locations to improve the overall performance.
-
Namespace Management
You can access data from multiple data sources at the same time in one dataset. The data sources include Object Storage Service (OSS), Hadoop Distributed File System (HDFS), Ceph, and other storage services. This is suitable for hybrid cloud scenarios.
-
Management of Heterogeneous Data Sources
You can access data from multiple data sources at the same time in one dataset. The data sources include Object Storage Service (OSS), Hadoop Distributed File System (HDFS), Ceph, and other storage services. This is suitable for hybrid cloud scenarios.
Benefits
-
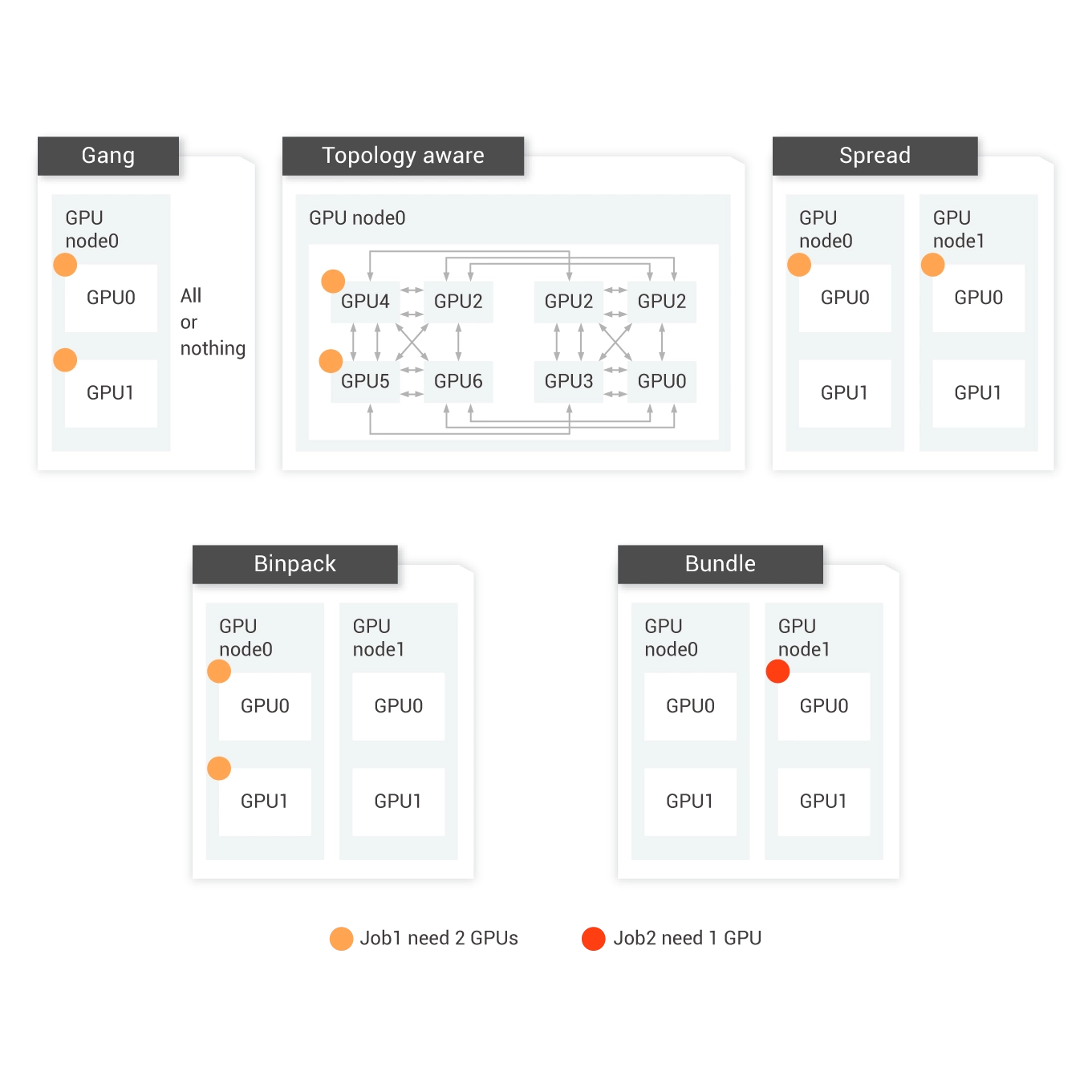
GPU Sharing and Scheduling
You can run multiple containers on one GPU by using GPU sharing and scheduling.
-
Topology-Aware GPU Scheduling
You can select a suitable GPU combination and achieve optimal training speed during GPU scheduling.
-
Binpack Scheduling
Jobs are initially allocated to one node. When the node has insufficient resources, jobs are allocated to another node. This minimizes cross-node data transmission and prevents resource fragmentation.
-
Gang Scheduling
Resources are only allocated to a job only when all subtasks of the job have sufficient resources. This prevents resource deadlocks where in which large jobs preempt the resources of small jobs.
Benefits
-
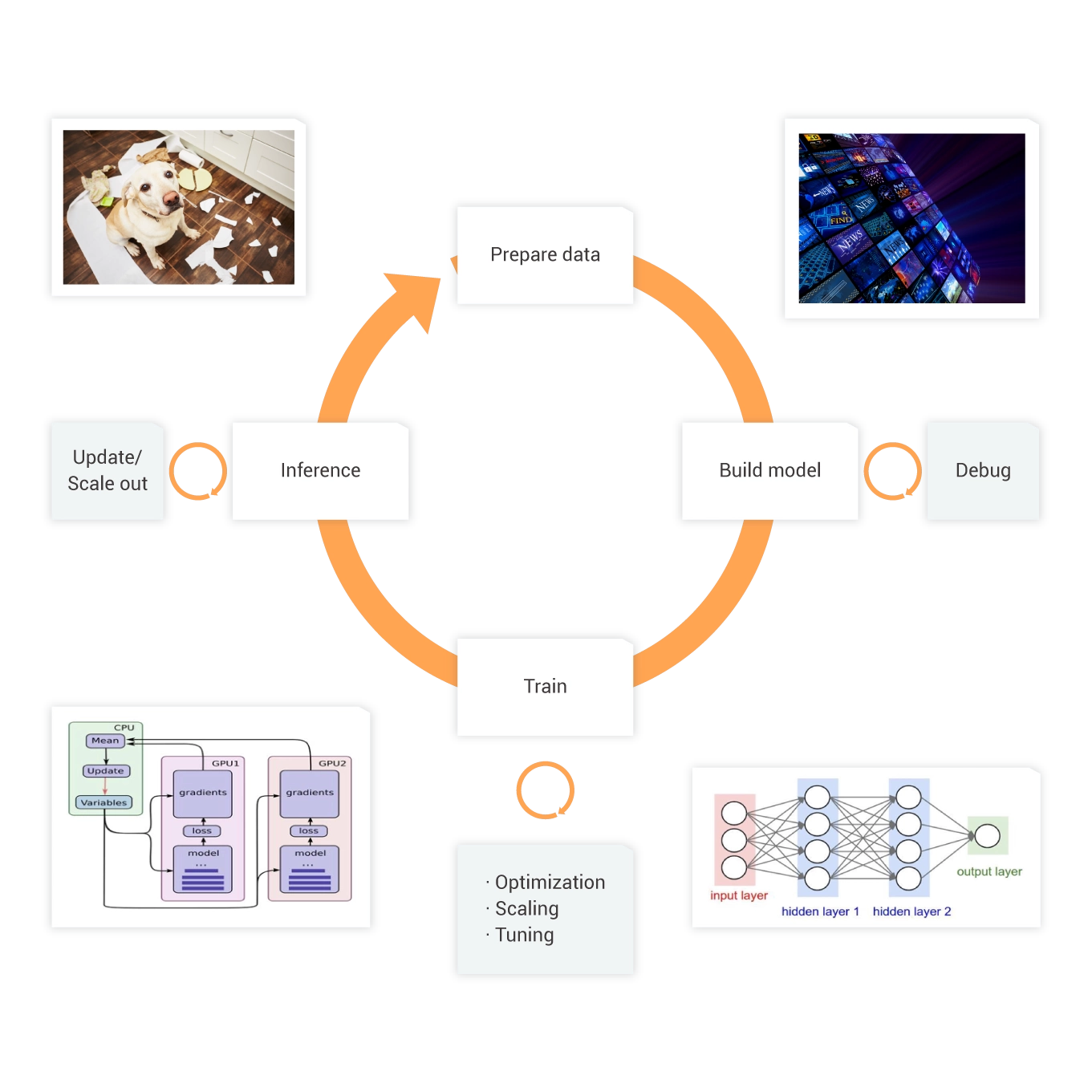
Arena AI Toolkit
The command lines and SDKs for Go, Java, and Python are compatible with heterogeneous underlying resources. This allows you to manage environments, schedule tasks, allocate GPUs, and monitor resources in a simplified manner.
-
The toolkit is compatible with various deep learning frameworks, such as TensorFlow, PyTorch, Caffe, Message Passing Interface (MPI), and Hovorod. The toolkit covers the entire process of Machine Learning Model Operationalization Management (MLOps), including training dataset management, AI task management, model development, distributed training, evaluation, and inference model release.
-
The R&D console provides an on-demand algorithm development environment where you can perform management operations throughout the entire R&D lifecycle. The operations include notebook management, AI task management, model management, and model release.
Benefits
-
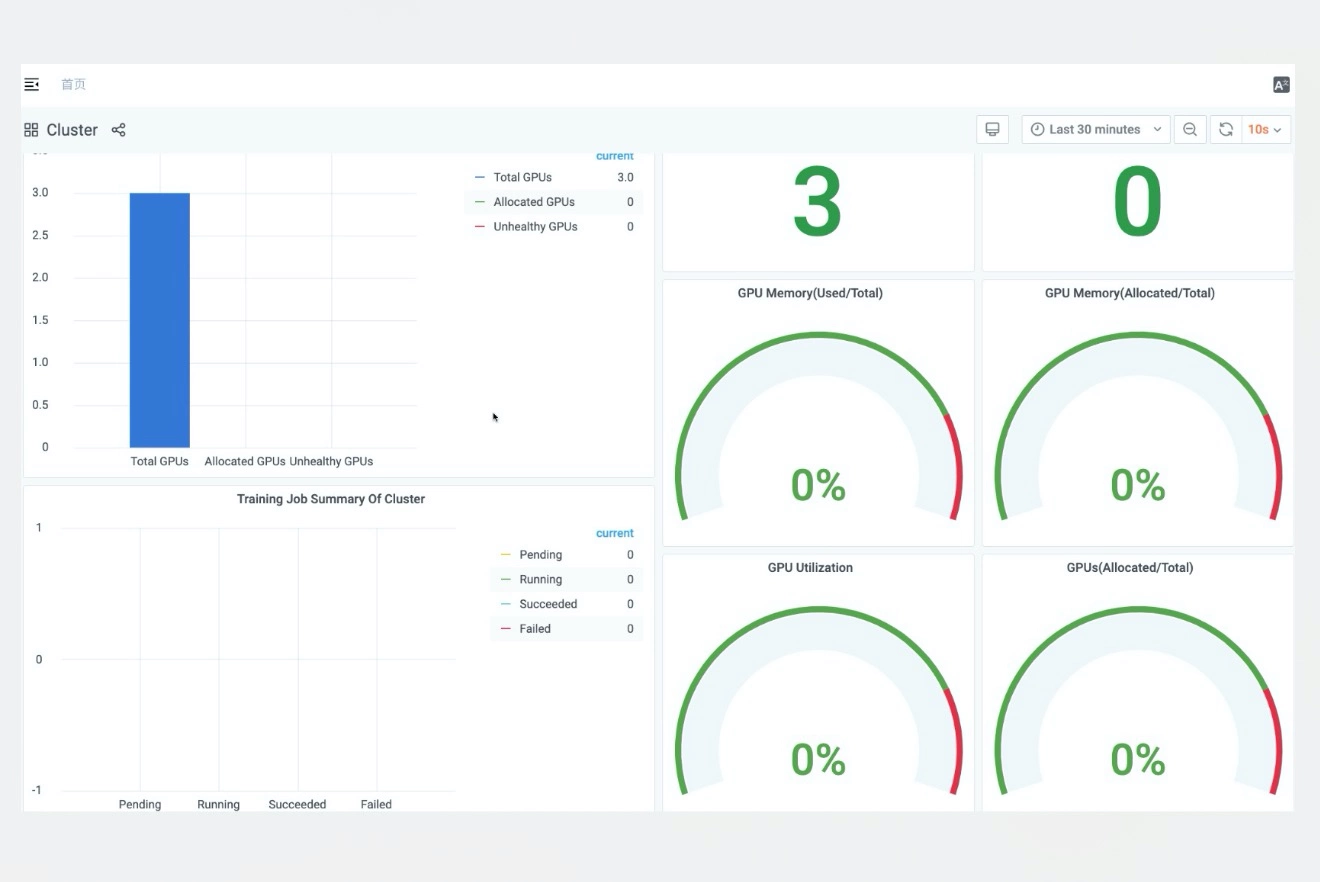
Dashboards for Real-Time GPU Utilization
You can monitor resource utilization from multiple dimensions in real time.
-
Dataset Management and Acceleration
You can accelerate access to existing datasets with one click to improve efficiency.
-
User and User Group Management
You can create users and user groups based on projects and manage user permissions and quotas in a fine-grained manner.
-
Elastic Quota Management
Capacity scheduling allows user groups to dynamically share resources.

