

A Key Component of the Cloud-Native Data Lake Framework
A data lake is a centralized repository used for big data and AI computing. It allows you to store structured and unstructured data at any scale. Data Lake Formation (DLF) is a key component of the cloud-native data lake framework. DLF provides an easy way to build a cloud-native data lake. It seamlessly integrates with a variety of compute engines and allows you to manage the metadata in data lakes in a centralized manner and control enterprise-class permissions.
• Easy data collection: systematically collects structured, semi-structured, and unstructured data and supports massive data storage.
• Flexible architecture: uses an architecture that separates computing from storage. You can plan resources on demand at low costs. This improves data processing efficiency to meet the rapidly changing business requirements.
• Easy data management: uses unified data storage, separately stores cold and hot data, and manages data lifecycle. This solves a variety of O&M issues, such as the failure to copy data across clusters.
• Easy value extraction: connects to different types of data computing and analytics platforms. This solves the data silo issues and provides insight into business value.
Features
-
![]()
Data Ingestion
Multiple data types and data ingestion channels
Allows you to cleanse data in a centralized manner. -
![]()
Metadata Service
Intelligent metadata discovery
Collects metadata from different data sources to facilitate centralized management. -
![]()
Permission Management
Enterprise-class data permission management
Allows you to set permissions on databases, tables, and fields. -
![]()
Multi-engine Access
Access to multiple upstream compute engines
Helps you deploy an end-to-end data lake solution. -
![]()
Open Ecosystem
Compatible with Hive metastore
Provides APIs in multiple programming languages for easy integration. -
![]()
Data Acceleration
JindoFS-based data acceleration
Accelerates data lake analytics with high performance.






Scenarios
Scenarios
![]() Typical scenarios
Typical scenarios
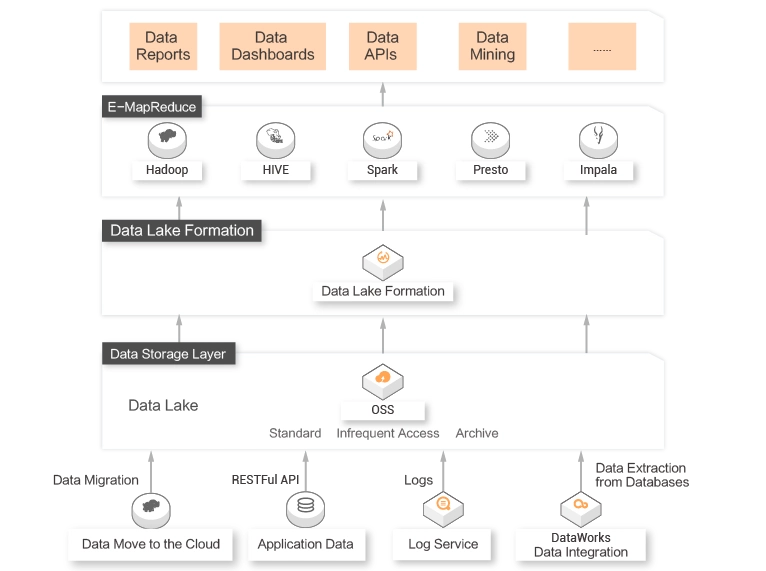
A data processing and analytics platform needs to be built on top of services in the Alibaba Cloud big data ecosystem, such as E-MapReduce, Realtime Compute for Apache Flink, and Data Lake Analytics (DLA).
Scale-out of storage and computing resources does not keep pace with the increasing data volume. Therefore, cost optimization is required.
Metadata from different storage systems is difficult to manage.
Benefits
-
 Metadata management
Metadata management
DLF can automatically discover and collect metadata from multiple engines and manage the metadata in a centralized manner to solve the data silo issues.Professional services
The Alibaba Cloud big data team provides you with expert-level services.
Scenarios
![]() Typical scenarios
Typical scenarios
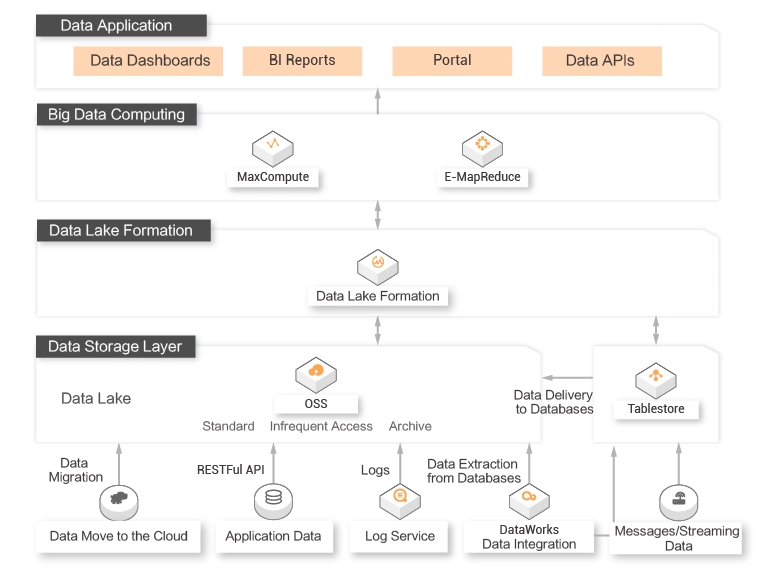
In most cases, a data lake architecture or a data warehouse architecture is used in big data scenarios.
Advantages:
If a data lake architecture is used, the underlying file storage system is opened to make data ingestion flexible.
If a data warehouse architecture is used, enterprise-class requirements for data processing efficiency, large-scale data management, security, and compliances can be fulfilled.
Data lakes need to be integrated with data warehouses to keep pace with business development. DLF and Alibaba Cloud data warehouses, such as MaxCompute, Hologres, and AnalyticDB for MySQL, help you build a data lakehouse. The lakehouse dynamically transfers data and computing resources across data lakes and warehouses. This way, a complete big data ecosystem is built.
Benefits
-
Zero O&M
DLF provides a fully managed service. It allows you to build a data lake in the cloud with a few clicks.High security
DLF uses a unified permission management system to control permissions on databases, tables, and columns.
Scenarios
![]() Typical scenarios
Typical scenarios
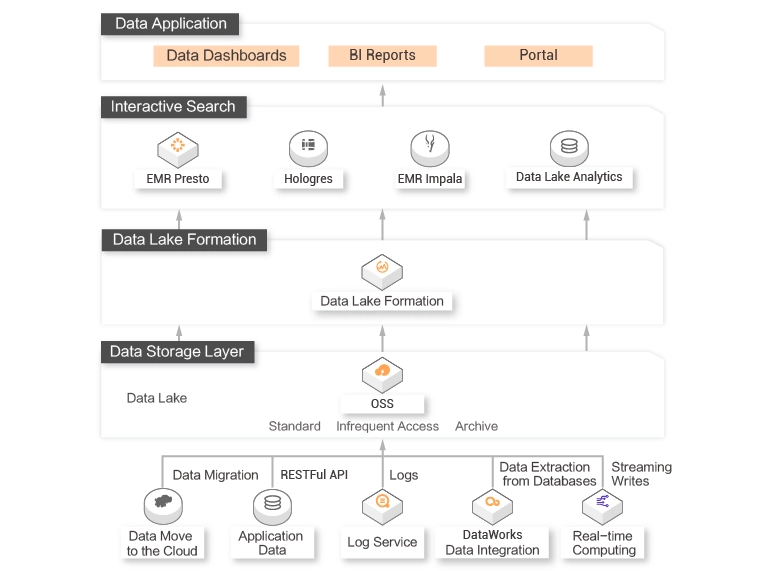
A large amount of different types of OSS data needs to be queried and analyzed in multiple dimensions, for example, real-time analysis, OLAP query, and result output to a business system.
When you query data, data lakes can access multiple compute engines in the cloud. You do not need to transfer all data to a query system.
Benefits
-
Real-time data ingestion
DLF ingests data into a data lake in real time to ensure the timeliness of business.Automatic metadata discovery
DLF can automatically capture, orchestrate, and prepare data for analytics. Complex manual operations are not required.
Scenarios
![]() Typical scenarios
Typical scenarios
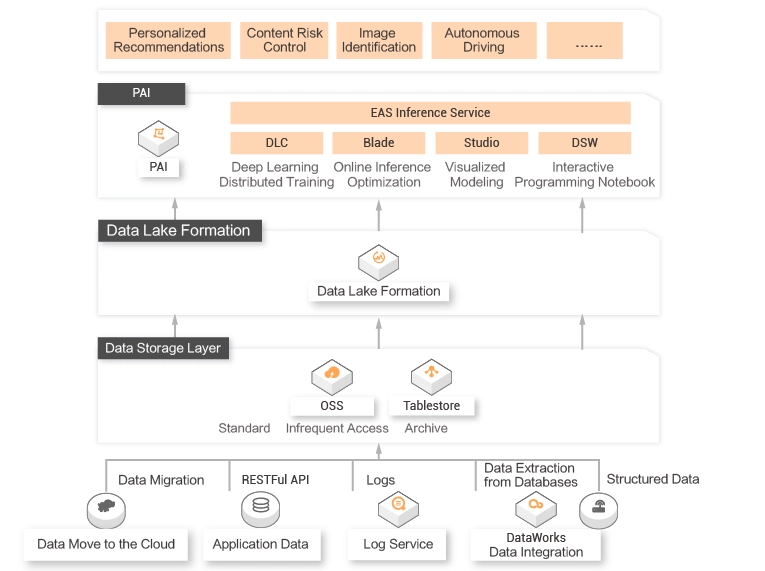
Data lakes are required for users in machine learning and deep learning scenarios.
In machine learning scenarios, you may encounter issues, such as large amounts of data, slow model training, and poor algorithm performance. Data lakes must be able to connect to mature machine learning platforms and dynamically adjust GPU resources to reduce costs.
Benefits
-
Easy to use
DLF seamlessly integrates with Machine Learning Platform for AI (PAI) and provides a variety of APIs for integration.Unified data cleansing
DLF allows you to cleanse and normalize data before data is ingested into a data lake. This helps you perform subsequent analytics operations by using PAI.
Industry Scenarios
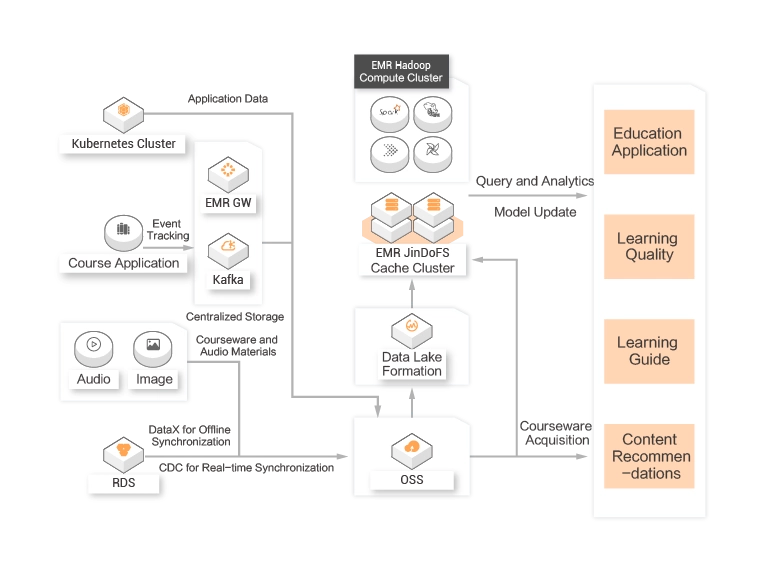
Online Education
An Online Education Platform with More Than 100 Million Users![]() Customer requirements
Customer requirements
Data, such as courseware materials, application logs, and studying samples, needs to be stored and managed in a centralized manner.
Courseware playback, offline analytics, and machine learning need to be implemented for various types of data in different online education scenarios.![]() Customer value
Customer value
DLF can connect to OSS and a large number of compute engines to meet different analytics requirements.
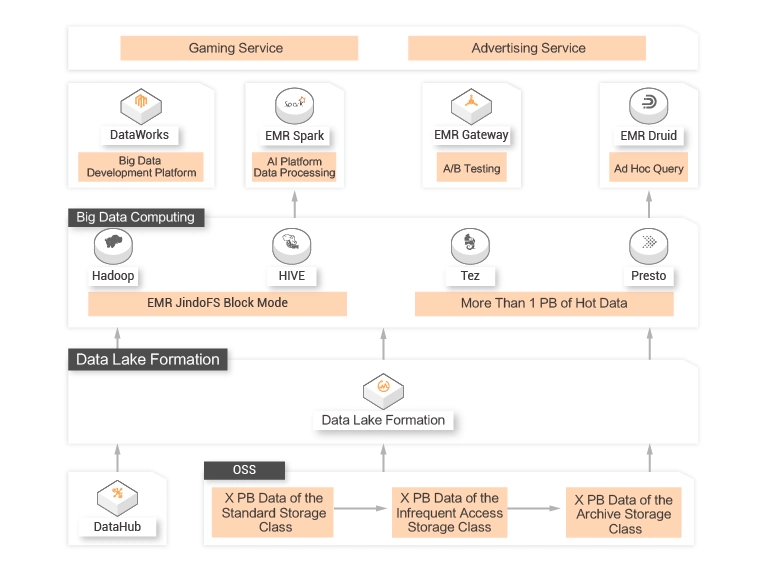
Online Gaming
A Leading Interactive Entertainment Company in Asia![]() Customer requirements
Customer requirements
Data needs to be analyzed to adjust the game difficulties, reduce item drop rates, and increase resource production rates. This helps improve the gaming experience and increase the retention rate of players.
Cloud resources need to be dynamically scaled and upgraded. An architecture that separates computing from storage is required to ensure resource elasticity.![]() Customer value
Customer value
DLF helps you build a data lake in the cloud that separates storage from computing. In addition, DLF can be interconnected with real-time computing and analytics engines. This helps you adjust business in real time.
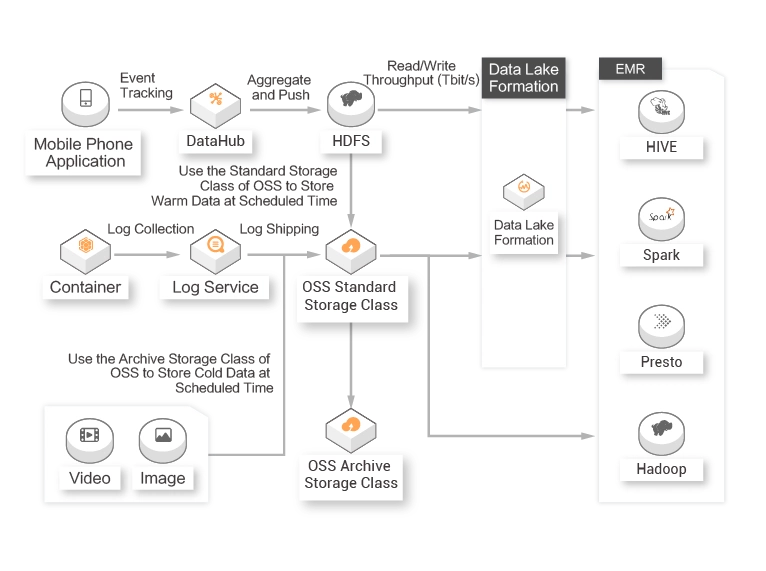
Interactive Entertainment New Media
An Internet New Media Platform with More Than 100 Million Active Users Per Month![]() Customer requirements
Customer requirements
The metadata from multiple storage systems needs to be managed in a centralized manner. Data sharing and analytics are required for business development.![]() Customer value
Customer value
DLF allows you to manage the metadata from different storage systems in a centralized manner. The metadata discovery service of DLF can collect and catalog data from your databases and Object Storage Service (OSS) buckets.
Related Products and Services

E-MapReduce
Big Data processing service

MaxCompute
Large-scale data warehousing

Hologres
Real-time analytics compatible with PostgreSQL

