
Benefits
-
![]()
High Stability
DataHub is derived from the real-time transmission system of Alibaba Group. DataHub has been proven stable and reliable during Double 11 over the years.
-
![#]()
High Throughput
Up to terabytes of data can be written to a topic per day. Up to hundreds of GB of data can be written to a shard per day.
-
![#]()
Low Cost
DataHub is an out-of-the-box solution that helps you transmit data with low cost based on the pay-as-you-go billing method.
-
![#]()
Integrated Ecosystem
DataHub is based on the Apsara distributed operating system and is deeply integrated with Alibaba Cloud big data systems. DataHub seamlessly connects with MaxCompute, Realtime Compute for Apache Flink, and Hologres.




Data Synchronization Capabilities
Comprehensive data import and synchronization capabilities and flexible data caching and interaction

Data Import
DataHub supports various SDKs and APIs and provides multiple third-party plug-ins such as Flume and Logstash. You can import data to DataHub in an efficient manner.

Data Delivery
The DataConnector module can synchronize imported data to downstream storage and analysis systems in real time, such as MaxCompute, OSS, and Tablestore. This significantly reduces your workload.

Data Cache
DataHub supports flexible cache schedules, repeated consumption in downstream systems, and automatic backup to ensure high data reliability.

Multiple Interfaces
You can access DataHub by using the web-based console or by calling APIs and SDKs.
Scenarios

Heterogeneous Data Sources and Multiple Downstream Big Data Systems
You can import heterogeneous data that is generated by applications, websites, IoT devices, or databases to DataHub in real time. You can manage the data in a unified manner by using DataHub. You can also deliver the data to downstream systems such as analysis systems and archiving systems. This way, you can build a data streaming pipeline and extract more data value.
Benefits
-
 System Decoupling
System DecouplingDataHub can decouple big data systems from business systems. DataHub can also decouple the components of a big data system.
-
Real-time Channel
Business data can be delivered to big data systems by using DataHub. This shortens the data analysis period.
Related Services
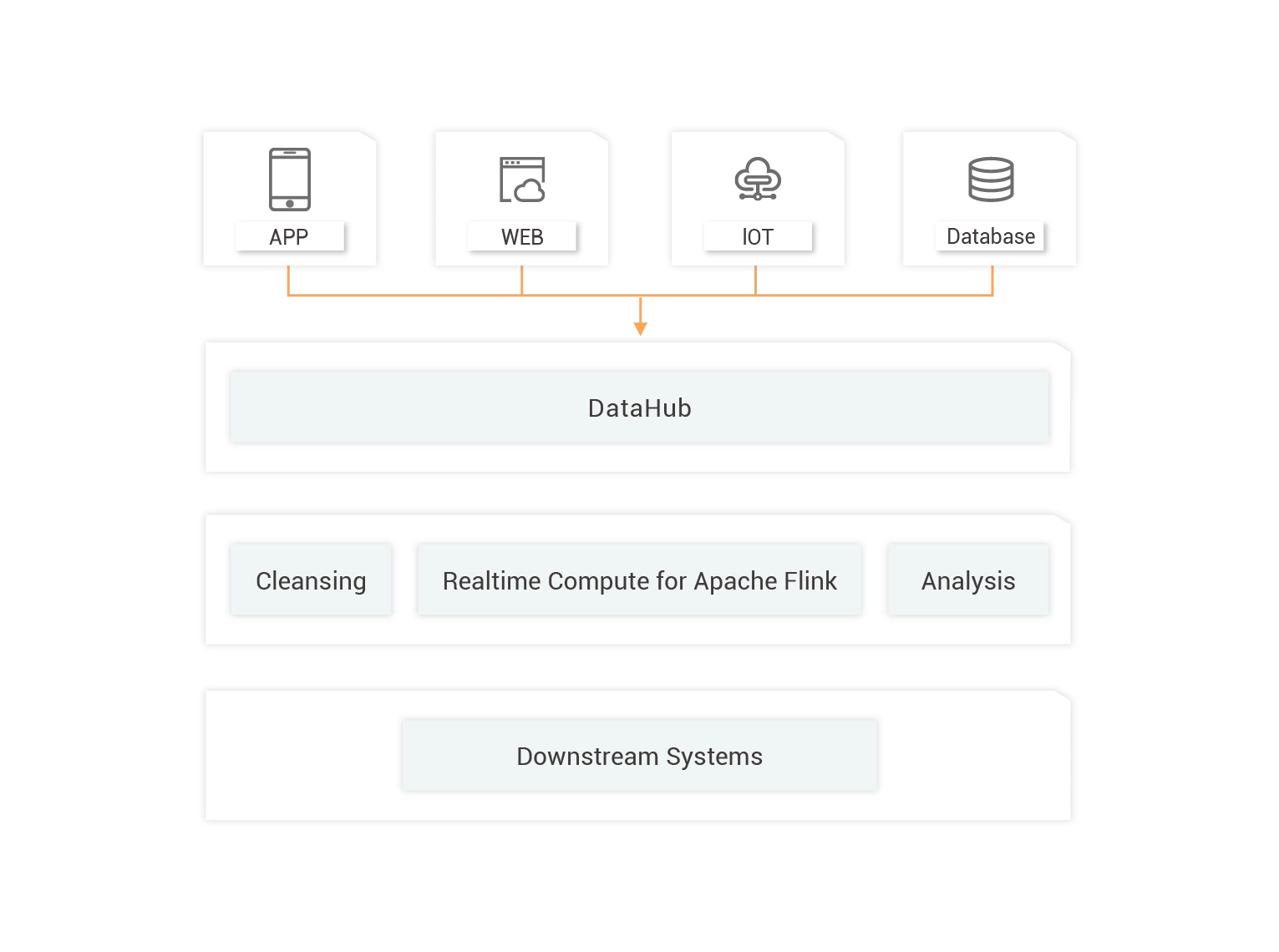
Real-time Analysis of Internet Advertising
For Internet companies, advertising remains a major source of income. Advertising is essentially a selling process that requires real-time decision-making and online conversion. In traditional offline computing solutions, advertising-related data generated on the current day are processed on the next day. However, these solutions can no longer meet business requirements. The entire industry requires real-time computing solutions.
Benefits
-
Real-time Convergence of Data Sources
You can use DataHub to collect user information from different data sources. Then, you can use Realtime Compute for Apache Flink to monitor advertisements in real time, report invalid links, and monitor fraud traffic.
-
Real-time Analysis and Decision-making
Data from different platforms is computed in a unified manner to prevent data silos. You can quickly respond to business changes in real time, eliminate traffic loss, and increase advertising exposure.
Related Services
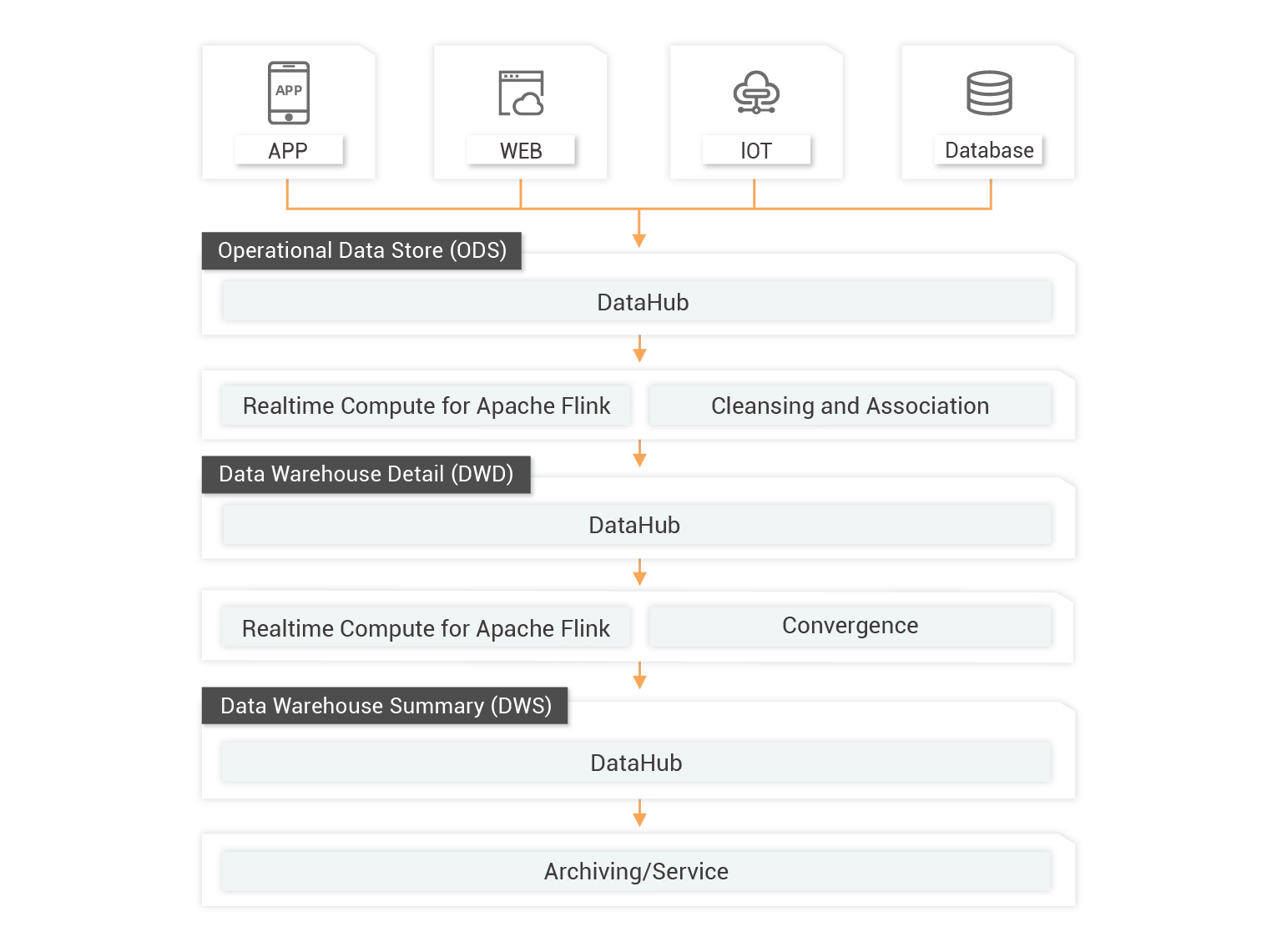
Real-time Warehouse as a Replacement of Traditional Databases
Increasing requirements for real-time business data analyzation and processing have posed a big challenge to traditional offline data warehouses. To address this challenge, you can use DataHub and Realtime Compute for Apache Flink to build a real-time data warehouse based on the Kappa architecture. You can divide the data warehouse into three layers: Data Warehouse Detail (DWD), Data Warehouse Summary (DWS), and Application Data Service (ADS).
Benefits
-
Unified Kappa Architecture
Compared with the Lambda architecture, the Kappa architecture uses one link instead of the traditional two links to reduce maintenance costs.
-
Real-time Big Data
DataHub allows you to reuse data in real time based on your business requirements. This feature helps you minimize repeated computing and storage and unify business metrics.

