
Lindorm は、大量のデータを低コストで保存および分析でき、ワイドテーブル、時系列データ、ファイル、検索エンジンなどの複数のデータモデルをサポートする、クラウドベースのデータベースサービスです。 Lindorm は、オンラインデータを数ミリ秒で処理できます。 統合 SQL 文を使用して、Lindorm の複数モデルのデータをクエリ、検索、分析できます。 Lindorm では、組み込みのストリームコンピューティングエンジンを使用して、リアルタイムでコンピューティングを実行することもできます。 Lindorm は、金融、課金、ロギング、モノのインターネット (IoT)、車のインターネット (IoV)、産業用インターネット、モニタリング、レコメンデーションシステム、リスク管理、医用画像など、さまざまな業界の企業にとって理想的なデータベースサービスです。
メリット
-
費用対効果
Lindorm は、数千万の同時リクエストに対して数ミリ秒で応答できます。 Lindorm は、費用対効果の高いストレージメディアを使用して、複数のデータエンジンで共有可能なストレージプールを構築し、ホットデータとコールドデータのインテリジェントな分離と適応型データ圧縮をサポートしています。
-
スケーラビリティ
Lindorm では、ストレージとコンピューティングリソースが分離され、個別にスケーリング可能なアーキテクチャが使用されています。 また、実際の使用量に基づいてスケーリングし、支払うことが可能なサーバーレスサービスも提供されています。
-
高い安定性
Lindorm は高可用性アーキテクチャ上に構築され、エンタープライズグレードの安定性を備えています。 このアーキテクチャは、アリババグループの本番環境で 10 年を超える実績を持ち、信頼性が証明されています。
-
高い互換性
Lindorm は、複数のオープンソースサービスの標準 API との互換性を備えています。 IoV や産業用 IoT シナリオで Lindorm を Spark や Flink などのさまざまなコンピューティングエンジンと接続し、ビジネスを主流のエコシステムとスムーズに統合できます。
特徴
コンバージドデータモデル
Lindorm は、クラウドネイティブストレージに基づいてさまざまなデータエンジンを構築し、統合マルチモデルクエリモードまたはオープンソース API を使用してデータをクエリできるため、柔軟で効率的な開発が可能です。
ワイドテーブルエンジン
ワイドテーブルエンジンは、大量のキー値データとテーブルデータを格納するために使用されます。 グローバルセカンダリインデックス、多次元クエリ、動的列、Time to Live (TTL) を使用できます。 メタデータ、注文、請求書、ユーザーペルソナ、ソーシャルネットワーキング情報、フィード、ログの保存などのシナリオに適用できます。 ワイドテーブルエンジンは、Apache HBase、Apache Phoenix、Apache Cassandra など、複数のオープンソースソフトウェアのオープン標準との互換性を備えています。
時系列エンジン
時系列エンジンは、IoT やモニタリングなどのシナリオで、測定データやデバイスの運用データなどの時系列データを保存および処理するために使用されます。 HTTP API を使用でき、OpenTSDB API との互換性を備えています。 また、SQL クエリもサポートされています。 時系列エンジンは、時系列データ専用の圧縮アルゴリズムを備えています。 時系列エンジンは、多次元クエリおよび大量のデータのアグリゲートコンピューティングをサポートし、ダウンサンプリングおよび事前集約を実行できます。
検索エンジン
検索エンジンは、全文検索、アグリゲートコンピューティング、大量のテキストおよびテーブルデータの複雑な多次元クエリなどの機能を備えています。 また、ワイドテーブルや時系列エンジンのインデックスをシームレスに保存することもできます。 そのため、データの取得とクエリが高速化されます。 検索エンジンは、ログ、請求書、ユーザーペルソナのクエリなどのシナリオに適用できます。 検索エンジンは、オープンソースの Solr プラットフォームのオープン標準との互換性を備えています。
ファイルエンジン
Lindorm は、大量の非構造化データを格納するように設計され、HDFS との互換性を備えた、柔軟でコスト効率の高いファイルストレージ機能を使用できます。 Lindorm では、複数のデータエンジンで共有可能な統合ストレージプールを使用でき、外部システムからデータエンジン内の下層ファイルにアクセスできます。 Lindorm は、ビッグデータ分析やデータレイクなどのさまざまなビジネスに適して、オープンソースの HDFS クライアントを使用してアクセスできます。
時空間エンジン
時空間エンジンは、大量の空間、時空間、および GIS データを保存および処理するように設計され、GeoMesa や GeoTools などのオープンソースツールの標準 API との互換性を備えています。 このエンジンは、時空間データの効率的な多次元インデックス作成機能と、空間および時空間データのクエリ機能を備えています。 時空間エンジンと DLA を使用して、複雑な時空間データから情報を分析およびマイニングできます。 時空間エンジンは、輸送、旅行、物流、IoT、ナビゲーション、航空、モバイル基地局などの時空間データに基づくビジネスに最適です。
インテリジェントな統合ストレージ
Lindorm が備えるさまざまなエンジンは、高い信頼性、スケーラビリティ、ハイブリッド機能を提供する費用対効果の高い統合ストレージプールを共有しています。 さらに、Lindorm では、オープンソースの HDFS ファイルシステムとの互換性を備えた標準 API が用意されています。
ホットデータとコールドデータのインテリジェントな分離ストレージ
Lindorm のデータは、データがアクセスされる頻度に基づいて、柔軟な方法で異なるレイヤーに格納されます。その結果、コールドデータのストレージコストが削減され、ホットデータのアクセスパフォーマンスが向上します。 アプリケーションを変更することなく、Lindorm に保存されているデータに直接アクセスできます。
複数のストレージメディア
Lindorm は、高性能から低コストまで、複数のシナリオに対応する、一連のストレージメディアをサポートしています。
豊富なクエリ機能
Lindorm は、セカンダリインデックス、転置インデックス、時系列インデックスなどの複数のデータクエリ機能と統合され、大量のデータをすばやくクエリおよび処理できます。
グローバルセカンダリインデックス
Lindorm はグローバル分散構造に基づいて構築され、強力な整合性と冗長性を確保できます。 Lindorm はスキーマレスデータモデルとの互換性を備え、インデックスをオンデマンドで自動的に使用して主キーなしでクエリを高速化します。
統合ストレージ検索
Lindorm では、ワイドテーブルエンジン、時系列エンジン、検索エンジンなど、複数のエンジンが統合され、データを統一された方法で保存およびクエリできます。 たとえば、ワイドテーブルと時系列エンジンに保存されているデータを、リアルタイムで検索エンジンに同期できます。 そのため、大量のデータに対して、ストレージ、多次元クエリ、フルテキストインデックスなどのハイブリッド操作を統一された方法で実行できます。
エンタープライズサポート
Lindorm は、セキュリティ、信頼性、効率性など、大規模な重要なビジネスを実行するために企業が必要とする複数の機能を備えています。 そのため、Lindorm はモノのインターネット (IoT) および車のインターネット (IoV) ビジネスに最適です。
グローバルな地理的冗長性
Lindorm は、グローバルなデータ分散とマルチマスターデータレプリケーションをサポートしています。 そのため、アプリケーションは地理的に近いデータにアクセスできます。 さらに、Lindorm は自動ディザスタリカバリとフォールトトレランスをサポートしているため、世界中の複数のリージョンにアプリケーションをデプロイできます。
強力な整合性と高い可用性
Lindorm は、異なるゾーンにデータの複数のレプリカを保存し、クラスターのクロスゾーンデプロイをサポートして、複数のデータセンターと強力なデータ整合に基づくデータリカバリを実現しています。 結果整合性モードを使用して、パフォーマンスと可用性を向上させることもできます。
安全なアクセス
Lindorm では、アクセスを制御し、認証、権限制御、暗号化、監査など、プロセス全体でデータのセキュリティを確保するために、VPC やセキュリティグループなどのさまざまな方法を使用できます。
バックアップと復元
Lindorm は、オンデマンドの定期的なデータのバックアップと復元をサポートしています。 大量のバックアップデータを、指定した時点に中断することなくすばやく復元できます。 そのため、企業や政府の規制を遵守できます。
低遅延
Lindorm は、数千万の同時リクエストに対して数ミリ秒で応答できます。
インテリジェントな診断
Lindorm は、低速リクエストやホットデータなどの一般的な問題を診断するために使用可能な LDInsight と統合されています。 LDInsight は、パフォーマンス診断、容量分析、スキーマ設計、自動トラブルシューティング、推奨事項の提案にも使用できます。
エコシステムとの互换性
Lindorm は、Spark、Flink、Data Lake Analytics (DLA)、MaxCompute などのコンピューティングエンジンとシームレスに統合できます。
データトンネル
LTS や DTS などの他のサービスを使用して、Lindorm と ApsaraDB for HBase、ApsaraDB for RDS MySQL、Log Service などの一般的なストレージサービスとの間でリアルタイムデータを同期したり、完全な履歴データを移行したりできます。
コンピューティングと分析
Lindorm は標準のインターフェイスを備え、必要に応じてデータ形式を変換します。 Lindorm を Spark、Flink、DLA、Hive などのオープンソースのコンピューティングエンジンと統合して、リアルタイムのインタラクティブ分析と複雑な分析を一括で実行できます。
データの可視化
Lindorm を QuickBI と DataV に接続して、視覚化された方法でデータを表示および分析できます。
シナリオ
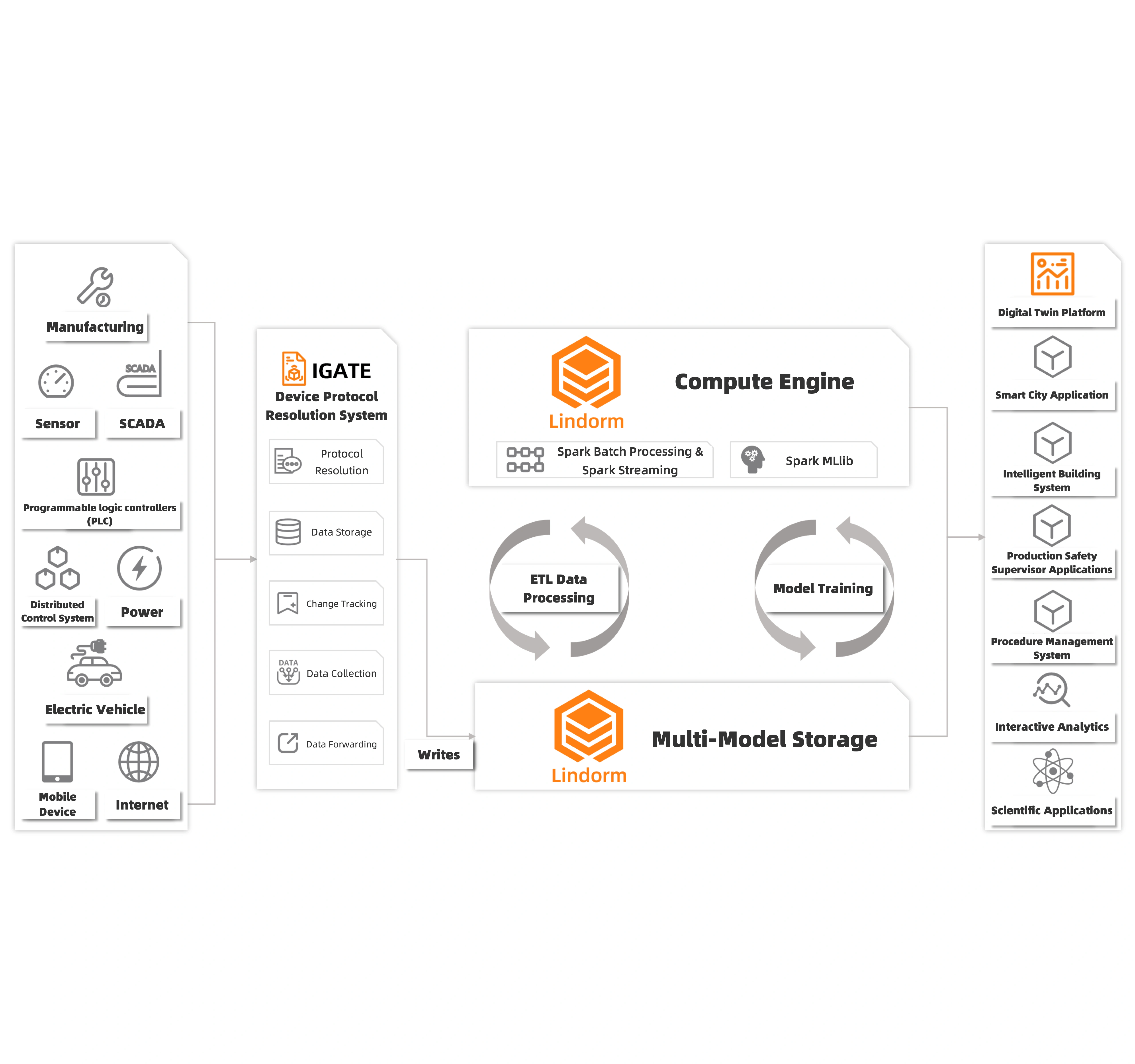
産業用データクラウドから統合された IT および OT データの保存と分析
Lindorm を使用して、産業用 IoT からの大量の異種 IT および OT データを保存できます。 Lindorm が備えるデータエンジンを使用すると、費用対効果が高く安定した方法で高性能分散コンピューティングを実行できます。インテリジェントな生産、インタラクティブなデータの探索と分析、AI/ML データ処理、大規模なグラフコンピューティングなどのさまざまなシナリオで要件を満たすことができます。 Lindorm は、従来の産業シナリオでは分離されている IT および OT データを正規化および統合するために、産業用インターネットのさまざまな上流および下流サービスと通信を行います。 より効率的な方法で情報を送信し、リソースを構成して、工業生産におけるデジタルおよびインテリジェントなアップグレードを実装できます。
メリット
-
費用対効果
高い圧縮比、コールドデータとホットデータの分離、さまざまな仕様をサポートします。
-
スケーラビリティ
ストレージとコンピューティングリソースを分離したアーキテクチャを活用します。 クラスターのスケーリングと、ストレージの拡張が可能です。
-
ハイパーコンバージェンス
コンピューティングリソースとストレージリソースを統合し、複数の分散コンピューティングモデルをサポートします。 すぐに使用できるさまざまなストレージモードとアクセスモードを備えています。
-
優れたパフォーマンス
多数の収集ポイントからのデータを、高いスループットと低い遅延で書き込みます。 Lindorm のデータは、効率的に測定、計算、および処理できます。
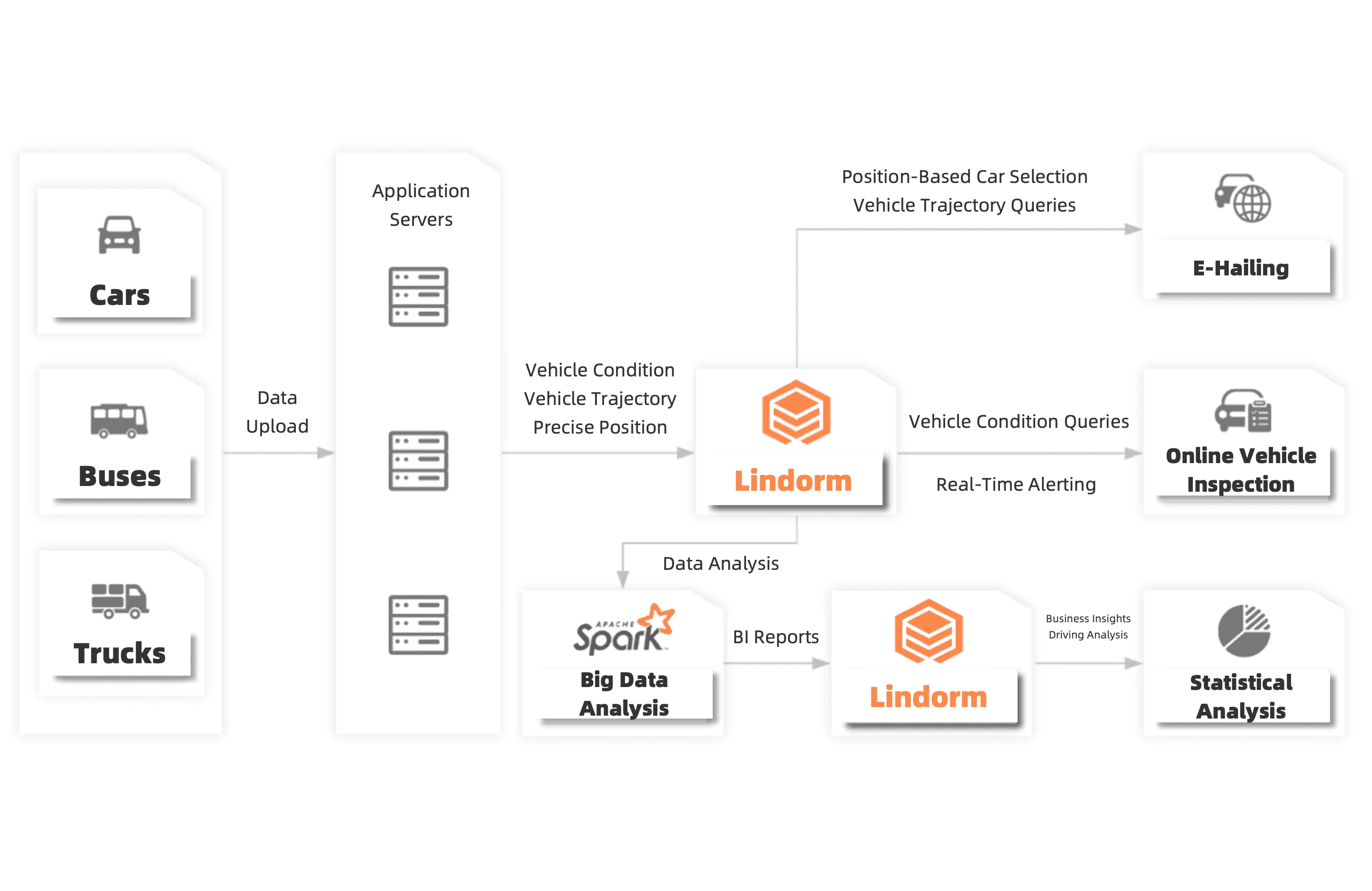
車両の軌跡とステータスデータの保存と処理
Lindorm を使用して、IoV シナリオでの走行軌跡、車両ステータス、正確な位置データなどの重要なデータを保存できます。 Lindorm は、スケーラブルで信頼性が高く、費用対効果の高いサービスを提供します。 オンラインのライドヘイリング、ロジスティクス、および新エネルギー車の検出のための効果的なエッジサービスを作成できます。
メリット
-
費用対効果
高い圧縮比、コールドデータとホットデータの分離、さまざまな仕様をサポートします。
-
スケーラビリティ
ストレージとコンピューティングリソースを分離したアーキテクチャを活用します。 クラスターのスケーリングと、ストレージの拡張が可能です。
-
低遅延
数千万の同時リクエストに対し、数ミリ秒で応答します。
-
柔軟な使用方法
動的カラムと TTL メカニズムをサポートしています。 機能またはタグを動的カラムに対して自動的に追加または削除でき、データは TTL 設定に基づいて自動的に期限が切れます。 Lindorm は、複数バージョンのデータも保存します。
-
データトンネル
LTS を使用して、Lindorm とサードパーティシステム間でデータを簡単かつ効率的に同期できます。
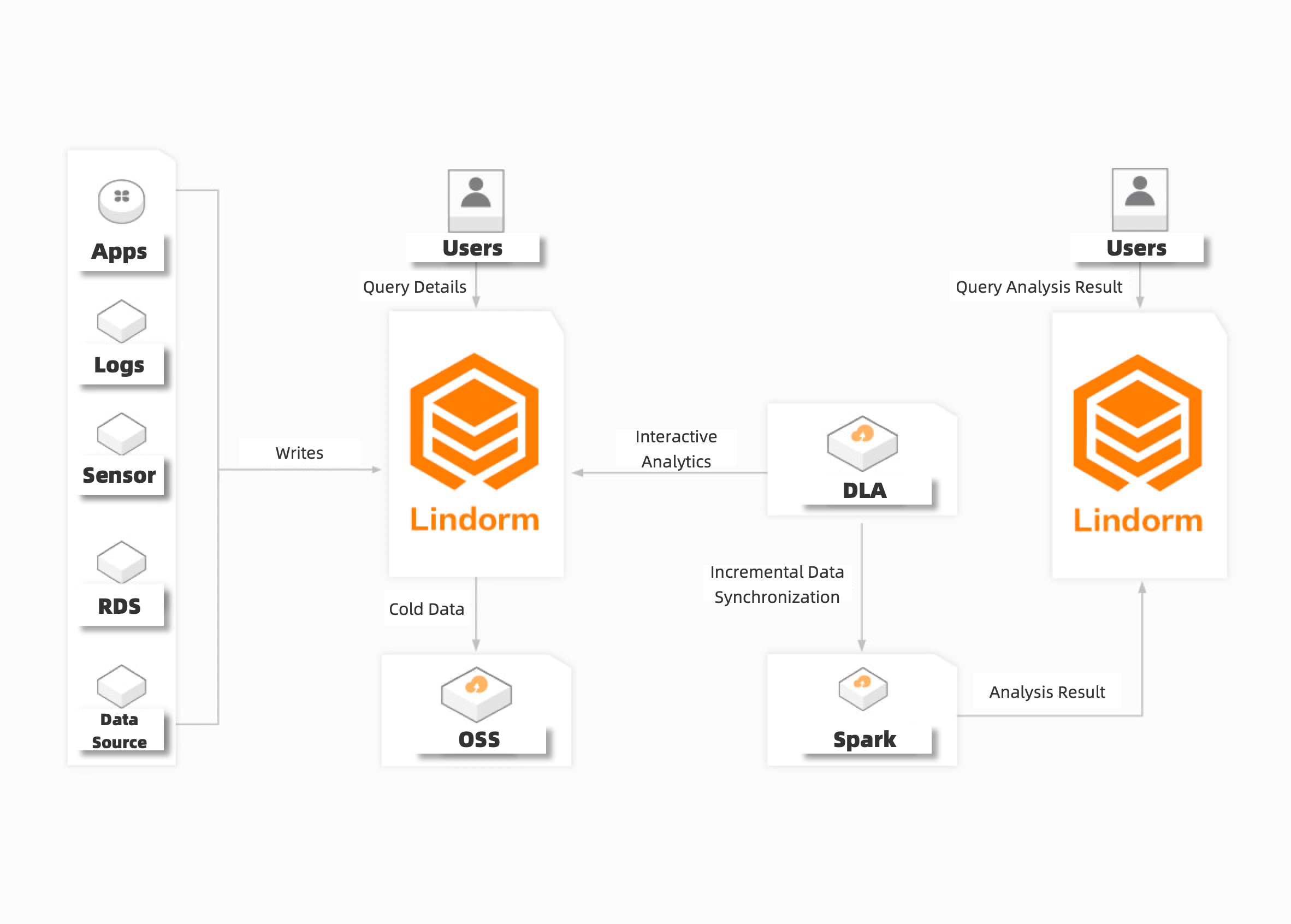
大量のデータに対する費用対効果の高いストレージと分析
Lindorm を使用すると、大量のデータを低コストで保存し、一度に複数のデータセットをインポートし、リアルタイムでデータをクエリできます。 全データまたは増分データを効率的に同期できます。 Lindorm は、Spark や MaxCompute などのビッグデータプラットフォームと統合できます。 統合により、大量のデータをオフラインで分析できます。
メリット
-
費用対効果
高い圧縮比、コールドデータとホットデータの分離、さまざまな仕様をサポートします。
-
データトンネル
トンネルデータ伝送:Lindorm を使用すると、Lindorm Tunnel Service (LTS) を使用して、Lindorm とサードパーティシステム間のデータを簡単かつ効率的に同期できます。
-
高速インポート
BulkLoad を使用すると、大量のデータを Lindorm にインポートできます。 従来の方法よりも高速なデータ転送を実行できます。
-
高い同時実行性
水平スケーリングにより、数千万 QPS を達成できます。
-
スケーラビリティ
Lindorm では、ストレージとコンピューティングを分離したアーキテクチャを使用しています。 クラスターのスケーリングと、ストレージの拡張が可能です。
お問い合わせ >
Alibaba Cloud のグローバルな営業チームが、さまざまなトピックでお客様をサポートし、Alibaba Cloud の利用をお手伝いします。

