Realtime Compute for Apache Flink and Hologres work together to support a layered streaming warehouse — an approach called Streaming Warehouse — where each data layer (operational data store, data warehouse detail, and data warehouse service) is stored in Hologres and can serve downstream queries independently. This guide walks through an end-to-end e-commerce example: ingesting MySQL CDC data into Hologres, joining and aggregating it in real time with Flink, and querying the results.
How it works
The pipeline has four layers:
-
ODS (operational data store): Flink reads Change Data Capture (CDC) events from three MySQL tables (
orders,orders_pay,product_catalog) and writes them into Hologres in real time. -
DWD (data warehouse detail): Flink joins the three ODS tables in real time and writes the consolidated result to
dwd_ordersin Hologres using partial updates. -
DWS (data warehouse service): Flink consumes the binary logging stream from
dwd_ordersand aggregates the data intodws_usersanddws_shops. -
Query serving: Hologres responds to point queries on DWS aggregate tables at up to one million records per second (RPS), and to online analytical processing (OLAP) queries on the DWD table within seconds.

Three Hologres capabilities make this architecture work:
| Capability | Role in this pipeline |
|---|---|
| Binary logging | Drives Flink to read incremental changes from Hologres tables, enabling Hologres to act as a streaming source (not just a sink) |
| Hybrid row-column storage | Stores both row-oriented and column-oriented data in a single table with strong consistency, so the same table supports point queries, lookup joins, and OLAP analytics simultaneously |
| Strong resource isolation | Separates write workloads from read/query workloads. Implement isolation using read/write splitting for primary and secondary instances, or using the virtual warehouse architecture. Either approach prevents Flink's binary log reads from affecting online query performance. |
Prerequisites
Before you begin, make sure that you have:
-
A Hologres exclusive instance (shared instances are not supported)
-
An ApsaraDB RDS for MySQL instance, a Hologres instance, and a Realtime Compute for Apache Flink workspace all in the same virtual private cloud (VPC). If they are in different VPCs, set up cross-VPC connectivity first — see How do I access other services across VPCs?. To use Internet access instead, see How do I access the Internet?
-
A RAM user or RAM role with the required permissions for Flink, Hologres, and MySQL
Step 1: Set up the infrastructure
Set up MySQL
-
Create an ApsaraDB RDS for MySQL instance in the same VPC as your Flink workspace and Hologres instance.
-
Create a database named
order_dwand a standard account. -
Create the three business tables and insert sample data.
-
Click Execute(F8), then click Execute in the panel that appears.
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, -- 0: phone, 1: pc create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- Insert sample data INSERT INTO product_catalog VALUES (1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'), (4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56'); -
Set up Hologres
-
Create a Hologres exclusive instance with the following settings:
-
Product Type: Exclusive instance (subscription) or Exclusive instance (pay-as-you-go)
-
Specifications: Compute Group Type
-
Reserved Computing Resources of Virtual Warehouse: 64 (required to support an additional virtual warehouse)
-
VPC: the same VPC as your MySQL instance
-
-
Create the
order_dwdatabase in Hologres.-
In the Hologres console, go to Instances and click your instance name.
-
Click Connect to Instance on the instance details page.
-
In HoloWeb, click Create Database in the top navigation bar.
-
Enter
order_dwas the Database Name, set Policy to SPM, and click OK. -
Assign the admin role to your Alibaba Cloud account, RAM user, or role. See Manage databases.
If your RAM user or role does not appear in the User drop-down list, add it as a superuser on the Security Center > User Management page. Binary log expansion is enabled by default in Hologres V2.0 and later.
-
-
Create a second virtual warehouse named
read_warehouse_1for query isolation. The initial virtual warehouseinit_warehousehandles all data writes.read_warehouse_1will handle external queries, so that read and write workloads do not interfere with each other. Before creatingread_warehouse_1, reduce the computing resources allocated toinit_warehouse:-
In HoloWeb, go to Security Center > Compute Group Management and confirm the instance name.
-
Find
init_warehouse, click Modify Configuration in the Actions column, reduce its compute group resources, and click OK. -
Click Create Compute Group, enter
read_warehouse_1as the Compute Group Name, and click OK.
-
Set up Flink
-
Create a Flink workspace in the same VPC as your MySQL and Hologres instances.
-
Log on to the Realtime Compute for Apache Flink console, find the workspace, and click Console in the Actions column.
-
Create a session cluster to provide an execution environment for catalogs and scripts.
-
Create a Hologres catalog. In Flink, go to Development > Scripts, click New, paste the following SQL, select it, and click Run. The catalog connects to the
init_warehousevirtual warehouse. Options you set here automatically apply to all tables created within this catalog — including thetable_property.binlog.levelandtable_property.binlog.ttlsettings that enable binary logging for every new table.Connector options in the catalog's
WITHclause andtable_property.*settings apply to all tables subsequently created in this catalog. See Manage Hologres catalogs and the "Connector options in the WITH clause" section of the Hologres connector topic.Option Description How to get the value endpointThe VPC endpoint of your Hologres instance In the Hologres console, click the instance name. Under Network Information, copy the endpoint next to Select VPC. See Endpoint. usernameThe custom account name or the AccessKey ID of your Alibaba Cloud or RAM account Make sure the account has the required permissions. See Hologres permission models for an overview of access control, and Create a custom user for instructions. This example uses the BASIC$flinktestcustom account and stores the password in a variable for security.passwordThe password of the custom account or the AccessKey secret See Manage variables for how to use the ${secret_values.holosecrect}variable pattern.CREATE CATALOG dw WITH ( 'type' = 'hologres', 'endpoint' = '<ENDPOINT>', 'username' = 'BASIC$flinktest', 'password' = '${secret_values.holosecrect}', 'dbname' = 'order_dw@init_warehouse', -- Connect to the init_warehouse virtual warehouse 'binlog' = 'true', 'sdkMode' = 'jdbc', -- Recommended mode 'cdcmode' = 'true', 'connectionpoolname' = 'the_conn_pool', 'ignoredelete' = 'true', -- Prevents retraction events when writing to wide tables; without this, a delete from orders_pay would nullify the corresponding row in dwd_orders 'partial-insert.enabled' = 'true', -- Allows INSERT statements that only specify some columns, leaving other columns unchanged 'mutateType' = 'insertOrUpdate', -- Required for partial updates to work correctly 'table_property.binlog.level' = 'replica', -- Enable binary logging for all tables created in this catalog 'table_property.binlog.ttl' = '259200' -- Retain binary log data for 3 days (in seconds) );Replace the following placeholder values:
-
Create a MySQL catalog. In the SQL editor, paste the following SQL, select it, and click Run.
Option Description hostnameThe internal endpoint IP address or hostname of your ApsaraDB RDS for MySQL instance. In the RDS console, click the instance name, go to Basic Information, click View Details next to Network Type, and copy the internal endpoint. portThe MySQL port. Default: 3306.usernameThe username for your ApsaraDB RDS for MySQL database. passwordThe database password. This example uses the mysql_pwvariable. See Variable management.CREATE CATALOG mysqlcatalog WITH ( 'type' = 'mysql', 'hostname' = '<hostname>', 'port' = '<port>', 'username' = '<username>', 'password' = '${secret_values.mysql_pw}', 'default-database' = 'order_dw' );Replace the following placeholder values:
Step 2: Build the ODS layer
What you'll see at the end of this step: Three Hologres tables (orders, orders_pay, product_catalog) contain the same data as their MySQL counterparts, with binary logging enabled for streaming downstream.
The CREATE DATABASE AS (CDAS) statement replicates all tables from a source database to a destination in a single statement. Binary logging is enabled automatically on every destination table because table_property.binlog.level = 'replica' was set when creating the dw catalog.
-
Create a synchronization job.
-
In Flink, go to Development > ETL, and create an SQL stream draft named
ODS. -
Paste the following SQL:
-- CDAS replicates all tables from mysqlcatalog.order_dw to dw.order_dw. -- Binary logging is inherited from the catalog definition. CREATE DATABASE IF NOT EXISTS dw.order_dw AS DATABASE mysqlcatalog.order_dw INCLUDING all tables /*+ OPTIONS('server-id'='8001-8004') */; -- Specify a server-id range for the MySQL CDC connectorData is synced to the
publicschema oforder_dwby default. To target a different schema, see the “Use the Hologres catalog as the destination in a CREATE TABLE AS statement” section of Manage Hologres catalogs. Schema changes in MySQL are not automatically reflected in Hologres until a data change (insert, update, or delete) occurs in the source table. -
Click Deploy to create a deployment.
-
Go to O&M > Deployments, find the
ODSdeployment, and click Start > Initial Mode > Start.
-
-
Load the ODS table group to the read virtual warehouse. The Hologres table group
order_dw_tg_defaultcontains all tables inorder_dw. Loading it toread_warehouse_1means queries run on the read virtual warehouse while Flink writes go throughinit_warehouse. In HoloWeb, open the SQL Editor, confirm you are on the correct instance and database, and run:-- List table groups in the current database SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; -- Load the table group to the read virtual warehouse CALL hg_table_group_load_to_warehouse ('order_dw.order_dw_tg_default', 'read_warehouse_1', 1); -- Verify the table group is loaded SELECT * FROM hologres.hg_warehouse_table_groups;See Create a virtual warehouse instance for more details.
-
Switch the virtual warehouse to
read_warehouse_1in the upper-right corner of HoloWeb.
-
Verify that data has been synced. Run the following queries in the SQL editor:
SELECT * FROM orders; SELECT * FROM orders_pay; SELECT * FROM product_catalog;All rows inserted into MySQL in step 1 should appear in the results.

Step 3: Build the DWD layer
What you'll see at the end of this step: A single wide table dwd_orders in Hologres contains merged order data from all three source tables, updated in real time. Binary logging is enabled on dwd_orders so it can drive DWS aggregation in the next step.
This step uses two INSERT statements running in parallel inside a statement set. Each statement targets only a subset of columns in dwd_orders (partial update). This is why ignoredelete and partial-insert.enabled were set in the catalog: each INSERT independently updates its columns without overwriting the other's columns.
Why a temporal join, not a regular join?
The orders-to-product_catalog join uses FOR SYSTEM_TIME AS OF proctime(), which is a temporal join (lookup join). A regular streaming join would buffer records from both sides and accumulate unbounded state as new records arrive — the state grows without limit as orders come in. A temporal join looks up the latest snapshot of product_catalog for each incoming orders event instead, with no state accumulation. Use a temporal join whenever one side of the join is a slowly changing dimension table.
Why partial inserts, not full-row inserts?
dwd_orders is a wide table that merges data from two independent streams: orders (which has user, shop, product, and fee columns) and orders_pay (which has payment columns). Each stream writes only its own subset of columns. A full-row INSERT would require each stream to know all columns, causing one stream to overwrite the other's columns with nulls. With partial-insert.enabled = 'true' and mutateType = 'insertOrUpdate', each INSERT touches only the columns it specifies, leaving the rest unchanged.
-
Create the
dwd_orderstable using the Hologres catalog. In Flink, go to Development > Scripts, paste the following SQL, select it, and click Run:-- All fields except the primary key must be nullable because two separate INSERT -- statements write to different columns; any column can be null until both writes complete. CREATE TABLE dw.order_dw.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'platform 0: phone, 1: pc', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); -- Extend the binary log TTL to one week (the catalog default is 3 days) ALTER TABLE dw.order_dw.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' ); -
Start the DWD Flink job.
-
In Flink, go to Development > ETL and create an SQL stream draft named
DWD. -
Paste the following SQL:
BEGIN STATEMENT SET; -- Write order data joined with product catalog names INSERT INTO dw.order_dw.dwd_orders (order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name) SELECT o.*, dim.catalog_name FROM dw.order_dw.orders AS o LEFT JOIN dw.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; -- Write payment data into the same wide table INSERT INTO dw.order_dw.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM dw.order_dw.orders_pay; END; -
Click Deploy to create a deployment.
-
Go to O&M > Deployments, find the
DWDdeployment, and click Start in the Actions column.
-
-
Verify the DWD table. In HoloWeb, run:
SELECT * FROM dwd_orders;Each row should contain merged data from both
ordersandorders_pay. Rows where payment data has not yet arrived will have nullpay_id,pay_platform, andpay_create_time.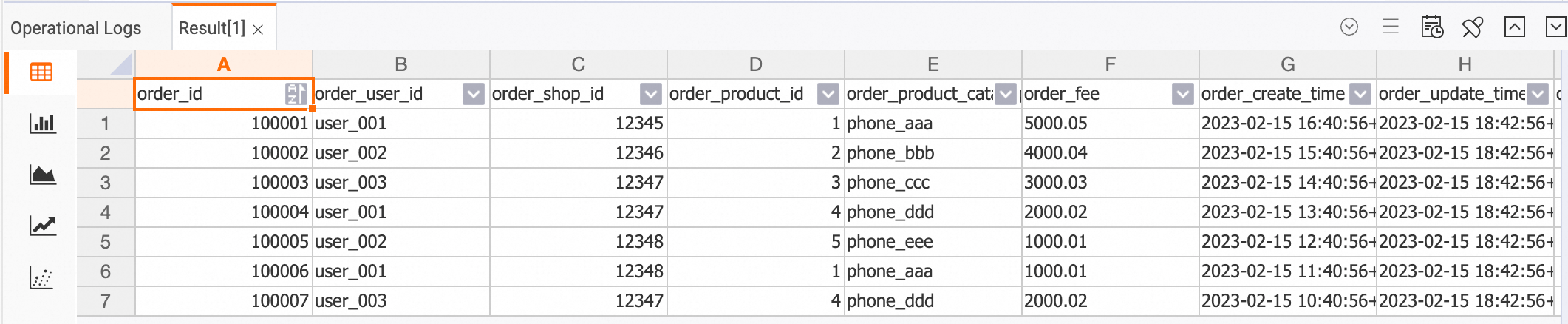
Step 4: Build the DWS layer
What you'll see at the end of this step: Two aggregate tables — dws_users (total payment per user per day) and dws_shops (total payment per shop per day) — update in real time as new orders and payments arrive.
Flink reads binary log events from dwd_orders and groups them by user/shop and date. Hologres receives the aggregated results via upsert, updating the running totals.
-
Create the aggregate tables in Hologres. In Flink, go to Development > Scripts, paste the following SQL, select it, and click Run:
-- User-level aggregate table: total daily payment per user CREATE TABLE dw.order_dw.dws_users ( user_id string not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'Total amount of payment that is complete on that day', PRIMARY KEY(user_id, ds) NOT ENFORCED ); -- Shop-level aggregate table: total daily payment per shop CREATE TABLE dw.order_dw.dws_shops ( shop_id bigint not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'Total amount of payment that is complete on that day', PRIMARY KEY(shop_id, ds) NOT ENFORCED ); -
Start the DWS Flink job.
-
In Flink, go to Development > ETL and create an SQL stream draft named
DWS. -
Paste the following SQL:
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dws_users SELECT order_user_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd') AS ds, SUM(order_fee) FROM dw.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- Only aggregate rows where both order and payment data have been written GROUP BY order_user_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd'); INSERT INTO dw.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd') AS ds, SUM(order_fee) FROM dw.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL GROUP BY order_shop_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd'); END; -
Click Deploy to create a deployment.
-
Go to O&M > Deployments, find the
DWSdeployment, and click Start in the Actions column.
-
-
Verify the DWS tables. In HoloWeb, run:
dws_users table
SELECT * FROM dws_users;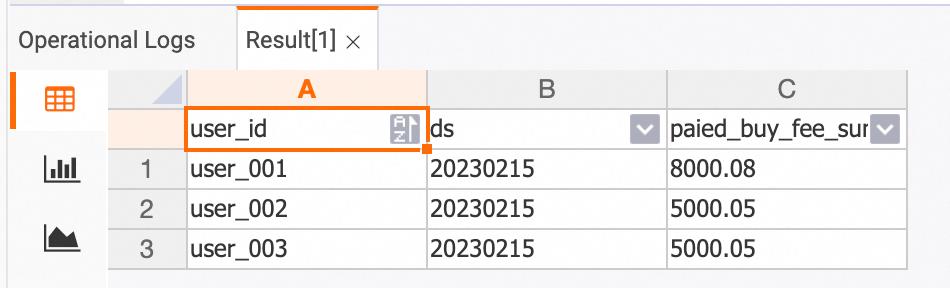
dws_shops table
SELECT * FROM dws_shops;
-
Confirm that the tables update in real time. Insert a new order and payment record into MySQL:
INSERT INTO orders VALUES (100008, 'user_003', 12345, 5, 6000.02, '2023-02-15 09:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 19:40:56');Then re-query the Hologres tables. The updated values should reflect the new order:
dwd_orders table
SELECT * FROM dwd_orders;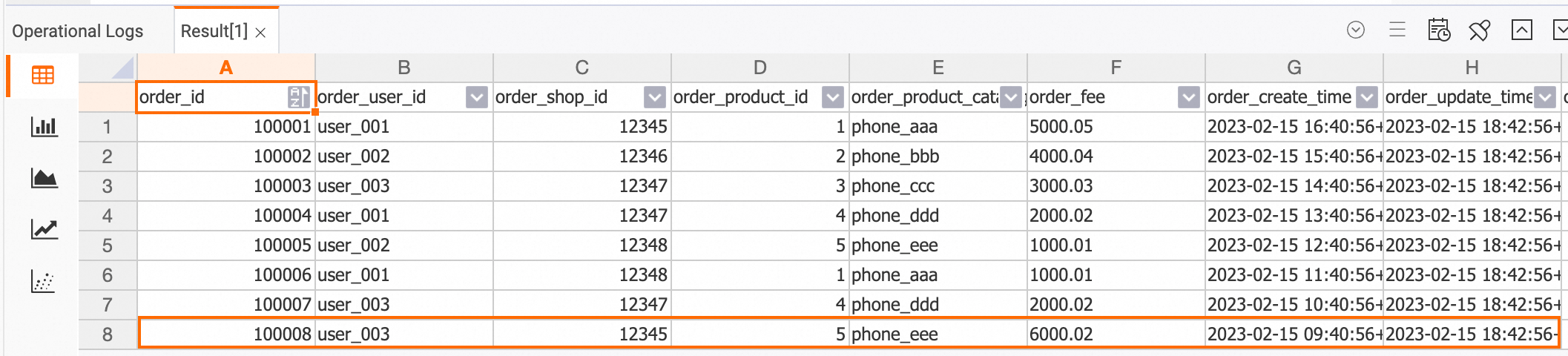
dws_users table
SELECT * FROM dws_users;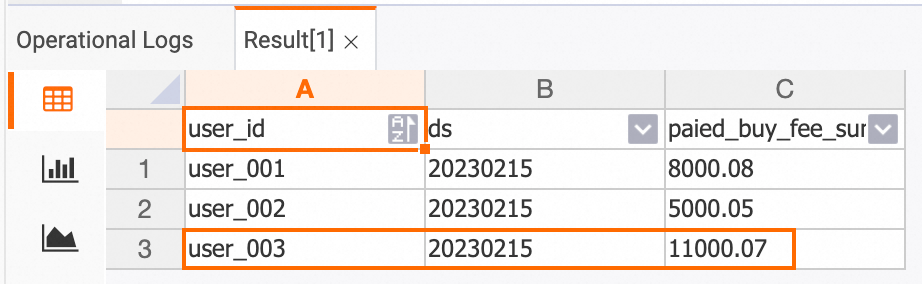
dws_shops table
SELECT * FROM dws_shops;
Data profiling
Because binary logging is enabled at every layer, you can inspect data changes at any point in the pipeline without modifying the production jobs.
Streaming mode
Use the Print connector to see real-time changes flowing through a specific filter. This creates a temporary streaming job that outputs matching records to Flink's task manager logs.
-
In Flink, go to Development > ETL and create an SQL stream draft named
Data-exploration. -
Paste the following SQL:
CREATE TEMPORARY TABLE print_sink ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int, pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'print' ); -- Stream binary log events from dwd_orders, starting from a specific time, filtered by user INSERT INTO print_sink SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('startTime'='2023-02-15 12:00:00') */ WHERE order_user_id = 'user_001'; -
Click Deploy, then go to O&M > Deployments and Start the deployment.
-
View the output:
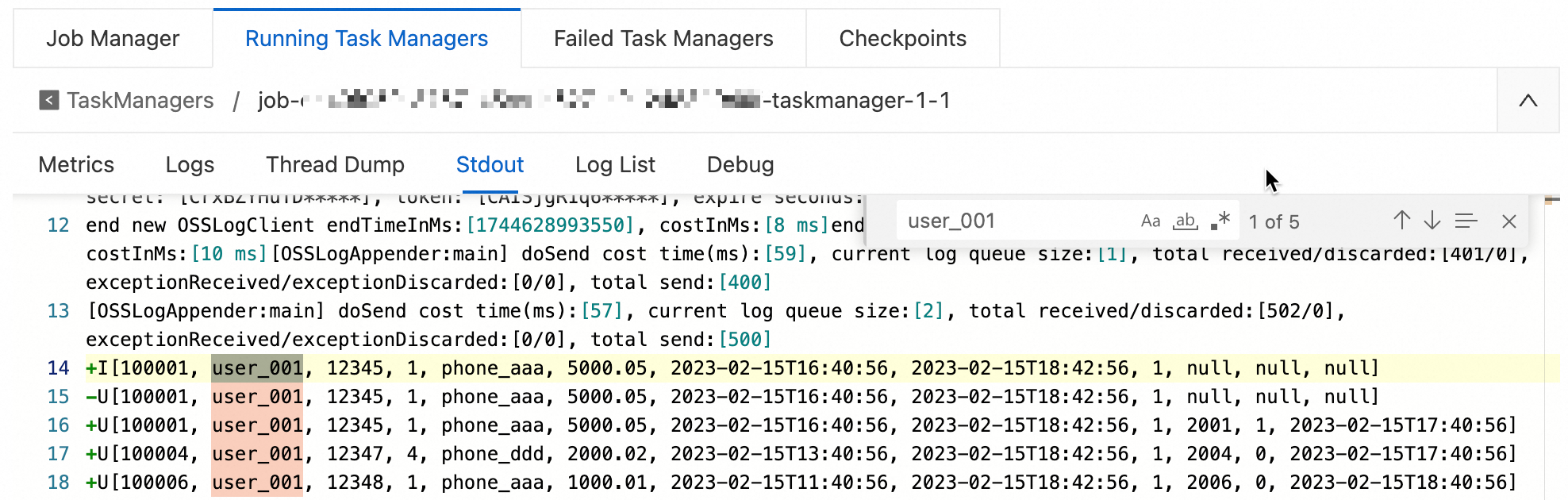
-
Go to O&M > Deployments and click the deployment name.
-
Under the Logs tab, open the Logs subtab.
-
Select Running Task Managers, then click a value in the Path, ID column.
-
On the Stdout tab, search for
user_001.
-
Batch mode
In batch mode, no streaming job is started. Instead, Flink runs a one-time query that returns the current state of the data. Use this to inspect intermediate results or verify computation correctness.
-
In Flink, go to Development > ETL and create a new SQL stream draft.
-
Paste the following SQL and click Debug (not Run or Deploy):
-- Disable binary log reading to query the table as a static snapshot -- Filter pushdown is supported in batch mode, improving execution efficiency SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('binlog'='false') */ WHERE order_user_id = 'user_001' AND order_create_time > '2023-02-15 12:00:00';See Debug a deployment for more information.

Query the data warehouse
The completed streaming warehouse supports several query patterns out of the box.
Point query on DWS aggregate tables
Query aggregate tables by primary key. Hologres supports up to one million RPS on DWS tables.
-- Get the total payment amount for user_001 on 2023-02-15
SELECT * FROM dws_users
WHERE user_id = 'user_001' AND ds = '20230215';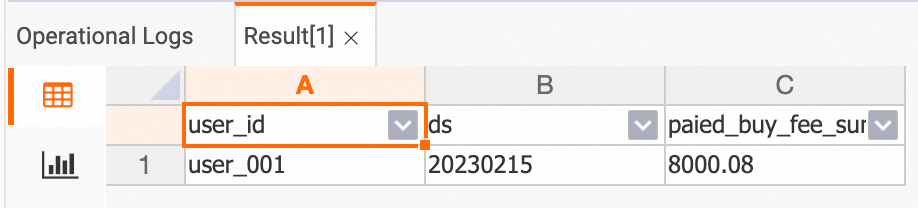
OLAP query on the DWD table
Run ad-hoc analytical queries on dwd_orders. Hologres returns results within seconds.
-- Get orders placed by user_001 via phone (pay_platform = 0) in February 2023
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00'
AND order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time
LIMIT 100;
Real-time report
Aggregate order volume and revenue by product category for a given month:
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD') AS order_create_date,
order_product_catalog_name,
COUNT(*) AS order_count,
SUM(order_fee) AS total_fee
FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00'
AND order_create_time < '2023-03-01 00:00:00'
GROUP BY order_create_date, order_product_catalog_name
ORDER BY order_create_date, order_product_catalog_name;
Key considerations
When adapting this pattern to your own project, keep the following constraints in mind:
-
Schema changes are not automatically propagated: If you add or rename a column in a MySQL source table, the change is not reflected in the corresponding Hologres table until a data change (insert, update, or delete) occurs in that source table.
-
Wide table columns must be nullable: Because two separate INSERT statements write to different subsets of columns in
dwd_orders, every non-primary-key column must allow nulls. A row may temporarily have nulls in payment columns until theorders_paystream writes its data. -
`ignoredelete = 'true'` is required for wide-table writes: Without this option, a delete event from
orders_paytriggers a Flink retraction message that nullifies the entire corresponding row indwd_orders, erasing the order data that the first INSERT wrote. -
DWS aggregation filters on both `pay_id` and `order_fee`: The
WHERE pay_id IS NOT NULL AND order_fee IS NOT NULLcondition ensures that aggregation only runs on rows where both the order stream and the payment stream have written their data. Rows with nulls in either column are partially populated and excluded from totals. -
Binary log TTL: The catalog default sets a 3-day TTL (
259200seconds) for all tables.dwd_ordersoverrides this to 7 days (604800seconds) because it drives both the DWS aggregation job and any data profiling jobs that may need to replay historical events. -
Exclusive Hologres instance required: Shared Hologres instances do not support binary logging or virtual warehouses.
What's next
-
INSERT INTO statement — how to write multiple INSERT statements in a single Flink deployment
-
Build a streaming data lakehouse by using Realtime Compute for Apache Flink and Apache Paimon