Hologres stores table data in three formats: row-oriented, column-oriented, and hybrid. Each format is optimized for different query patterns. Select the format when you create a table—changing it later requires recreating the table.
Choose a storage format
Use this table to identify the format that matches your workload. Column-oriented is the default.
| Column-oriented | Row-oriented | Hybrid | |
|---|---|---|---|
| Best for | OLAP workloads: complex queries, joins, full scans, aggregations | High-QPS primary key (PK) point queries | Tables that need both PK point queries and OLAP; non-PK point queries |
| Column limit | 300 | 3,000 | 300 |
| Default indexes | Multiple indexes, including bitmap indexes for string columns | PK index only | Row + column indexes |
| Storage overhead | Low | Low | Higher (data stored in both row and column format) |
| `orientation` value | column (default) | row | row,column |
Hybrid storage incurs higher storage overhead because every write goes to both the row-oriented and column-oriented copies. Use it only when a single table genuinely needs both PK lookups and analytical queries.
Set the storage format
Specify the orientation property when you create a table.
From V2.1:
CREATE TABLE <table_name> (...) WITH (orientation = '[column | row | row,column]');All versions:
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'orientation', '[column | row | row,column]');
COMMIT;How it works
The three formats differ in how they lay out data on disk and which indexes they build. This determines which query types they serve efficiently.
Column-oriented stores each column's values contiguously. A query such as SELECT SUM(revenue) FROM orders WHERE region = 'APAC' reads only the revenue and region columns—skipping all others. This reduces I/O for analytical queries that touch a small subset of columns across many rows.
Row-oriented stores each row's values contiguously. A query such as SELECT * FROM orders WHERE id = '1001' does a single PK lookup and retrieves the entire row in one scan. This is efficient when you need all columns of a specific row immediately.
Hybrid maintains both a row-oriented copy and a column-oriented copy of every row. The query optimizer selects the copy that delivers better performance based on the execution plan. Every write must succeed in both copies before the operation returns.
Column-oriented
Column-oriented tables use ORC format. Data is encoded with algorithms such as Run-Length Encoding (RLE) and dictionary encoding, then compressed with Snappy, Zlib, Zstd, or LZ4. The storage layer also builds bitmap indexes and uses late materialization to reduce unnecessary data reads.
When a column-oriented table has a primary key (PK), the system generates a row identifier (RID) for each row. With indexes such as a distribution key or clustering key defined on frequently queried columns, the engine locates the shard and file quickly.
From V2.1:
CREATE TABLE public.tbl_col (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT NOT NULL,
in_time TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id)
)
WITH (
orientation = 'column',
clustering_key = 'class',
bitmap_columns = 'name',
event_time_column = 'in_time'
);
SELECT * FROM public.tbl_col WHERE id = '3333';
SELECT id, class, name FROM public.tbl_col WHERE id < '3333' ORDER BY id;All versions:
BEGIN;
CREATE TABLE public.tbl_col (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT NOT NULL,
in_time TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id)
);
CALL set_table_property('public.tbl_col', 'orientation', 'column');
CALL set_table_property('public.tbl_col', 'clustering_key', 'class');
CALL set_table_property('public.tbl_col', 'bitmap_columns', 'name');
CALL set_table_property('public.tbl_col', 'event_time_column', 'in_time');
COMMIT;
SELECT * FROM public.tbl_col WHERE id = '3333';
SELECT id, class, name FROM public.tbl_col WHERE id < '3333' ORDER BY id;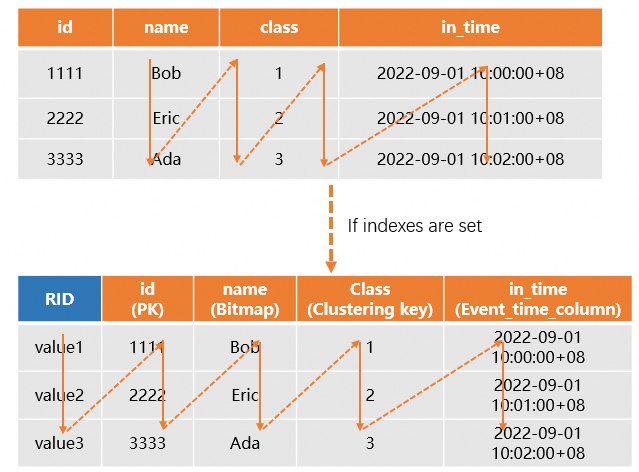
Row-oriented
Row-oriented tables use SST format. Data is stored in key-ordered, compressed blocks. The storage layer builds Block Index and Bloom Filter indexes, and a background compaction mechanism keeps files organized for efficient PK lookups.
Recommended: define only the primary key
When a row-oriented table has a PK, the system automatically sets the PK as both the distribution key and the clustering key, and generates an RID for each row. A PK-based point query scans only one PK index to retrieve all columns.
When you create a row-oriented table, define only the PK. The system configures the distribution key and clustering key automatically.
From V2.1:
CREATE TABLE public.tbl_row (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT,
PRIMARY KEY (id)
)
WITH (
orientation = 'row',
clustering_key = 'id',
distribution_key = 'id'
);
-- PK-based point query
SELECT * FROM public.tbl_row WHERE id = '1111';
-- Multiple key lookup
SELECT * FROM public.tbl_row WHERE id IN ('1111', '2222', '3333');All versions:
BEGIN;
CREATE TABLE public.tbl_row (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT,
PRIMARY KEY (id)
);
CALL set_table_property('public.tbl_row', 'orientation', 'row');
CALL set_table_property('public.tbl_row', 'clustering_key', 'id');
CALL set_table_property('public.tbl_row', 'distribution_key', 'id');
COMMIT;
-- PK-based point query
SELECT * FROM public.tbl_row WHERE id = '1111';
-- Multiple key lookup
SELECT * FROM public.tbl_row WHERE id IN ('1111', '2222', '3333');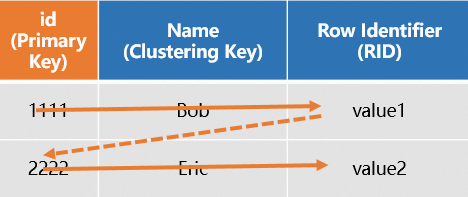
Not recommended: mismatched PK and clustering key
If you define different fields for the PK and the clustering key, every PK-based query requires two scans:
Use the PK index to locate the clustering key value and RID.
Use the clustering key and RID to fetch the full row.
This double-scan pattern significantly reduces query performance.
From V2.1:
-- Avoid: clustering_key differs from PK
CREATE TABLE public.tbl_row (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT,
PRIMARY KEY (id)
)
WITH (
orientation = 'row',
clustering_key = 'name', -- different from PK (id)
distribution_key = 'id'
);All versions:
BEGIN;
CREATE TABLE public.tbl_row (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT,
PRIMARY KEY (id)
);
CALL set_table_property('public.tbl_row', 'orientation', 'row');
CALL set_table_property('public.tbl_row', 'clustering_key', 'name'); -- different from PK (id)
CALL set_table_property('public.tbl_row', 'distribution_key', 'id');
COMMIT;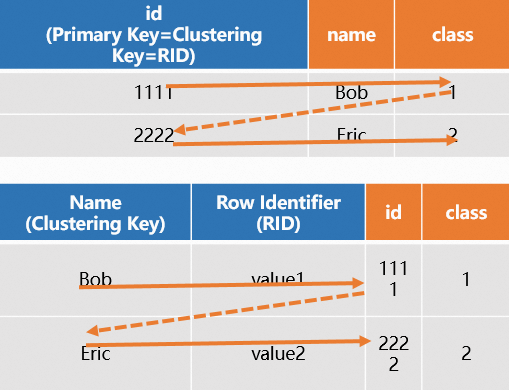
Hybrid
Hybrid storage (introduced in V1.1) stores data in both row-oriented and column-oriented formats simultaneously. A primary key is required. Every write completes atomically—the operation succeeds only after both copies are written.
During queries, the optimizer selects the format that delivers higher efficiency:
PK point queries (
SELECT * FROM tbl WHERE pk = xxx) and Fixed Plan scenarios: row-oriented path.Non-PK point queries (
SELECT * FROM tbl WHERE col1 = xx AND col2 = yyy): the optimizer reads matching rows from the column-oriented copy first, then fetches full rows from the row-oriented copy using the retrieved key values. This avoids full table scans while returning all columns.General queries: column-oriented path.
From V2.1:
CREATE TABLE public.tbl_row_col (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT NOT NULL,
PRIMARY KEY (id)
)
WITH (
orientation = 'row,column',
distribution_key = 'id',
clustering_key = 'class',
bitmap_columns = 'name'
);
SELECT * FROM public.tbl_row_col WHERE id = '2222'; -- PK point query
SELECT * FROM public.tbl_row_col WHERE class = 'Class Two'; -- Non-PK point query
SELECT * FROM public.tbl_row_col WHERE id = '2222' AND class = 'Class Two'; -- General OLAP queryAll versions:
BEGIN;
CREATE TABLE public.tbl_row_col (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT,
PRIMARY KEY (id)
);
CALL set_table_property('public.tbl_row_col', 'orientation', 'row,column');
CALL set_table_property('public.tbl_row_col', 'distribution_key', 'id');
CALL set_table_property('public.tbl_row_col', 'clustering_key', 'class');
CALL set_table_property('public.tbl_row_col', 'bitmap_columns', 'name');
COMMIT;
SELECT * FROM public.tbl_row_col WHERE id = '2222'; -- PK point query
SELECT * FROM public.tbl_row_col WHERE class = 'Class Two'; -- Non-PK point query
SELECT * FROM public.tbl_row_col WHERE id = '2222' AND class = 'Class Two'; -- General OLAP query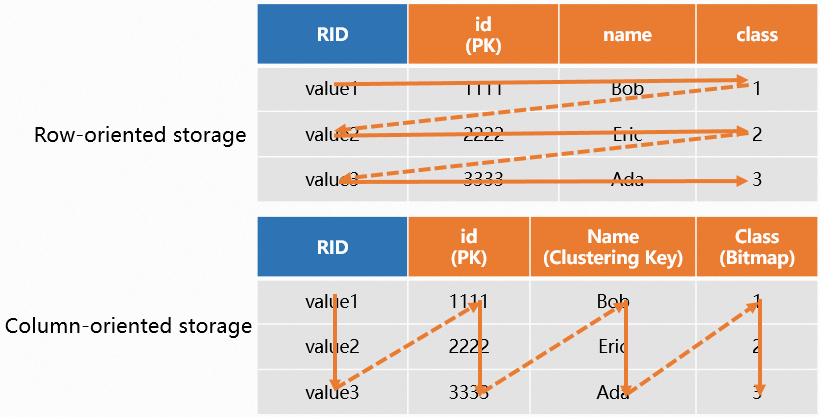
Usage examples
The following examples use the V2.1 WITH (orientation = ...) syntax. For the equivalent set_table_property syntax compatible with all versions, see the sections above.
-- Column-oriented table (default)
CREATE TABLE tbl_col (
a INT NOT NULL,
b TEXT NOT NULL
)
WITH (
orientation = 'column'
);
-- Row-oriented table
CREATE TABLE public.tbl_row (
a INTEGER NOT NULL,
b TEXT NOT NULL,
PRIMARY KEY (a)
)
WITH (
orientation = 'row'
);
-- Hybrid table (row + column)
CREATE TABLE tbl_col_row (
pk TEXT NOT NULL,
col1 TEXT,
col2 TEXT,
col3 TEXT,
PRIMARY KEY (pk)
)
WITH (
orientation = 'row,column'
);FAQ
If hybrid storage supports both PK point queries and OLAP queries, why not always use it?
Hybrid storage incurs higher storage overhead because data is written twice—once in row format and once in column format. Use hybrid storage only when a single table genuinely needs both high-QPS PK lookups and analytical queries. For OLAP-only tables, column-oriented storage is more efficient. For PK-lookup-only tables, row-oriented storage avoids the overhead.
Can I change a table's storage format after creation?
No. Direct conversion is not supported. To change the storage format, recreate the table with the new orientation value.
Why does row-oriented storage support more columns than column-oriented?
Column-oriented tables build multiple indexes by default, including bitmap indexes for string columns. As column count grows, these indexes increase storage overhead and slow down writes. Row-oriented tables index only the primary key, so the per-column cost is much lower.
What happens if a row-oriented table exceeds 3,000 columns or a column-oriented table exceeds 300 columns?
These are recommended limits, not hard limits. Exceeding them degrades performance: column-oriented tables with many columns incur high index storage and write overhead; row-oriented tables with very many columns increase row size and reduce point query throughput. Stay within the recommended limits for production workloads.
What's next
For guidance on combining storage format selection with other table properties—such as distribution key, clustering key, and partitioning—based on your query patterns, see Scenario-based table creation optimization guide.