このトピックでは、Alibaba Cloud Elasticsearch (ES) に関するよくある質問 (FAQ) を一覧で紹介します。インスタンスの購入、サブスクリプションの解約、設定、アクセス、クエリ、データ書き込み、プラグイン、アナライザー、ログ、再起動、負荷またはステータスの異常、バックアップと復元、モニタリングとアラートなどのトピックをカバーしています。
FAQ の概要
購入またはサブスクリプション解約に関する問題
製品機能に関する質問
データ移行と同期に関する問題
インスタンスの再起動に関する問題
クラスターの負荷またはステータスの異常に関する問題
クラスターのクエリと書き込みに関する問題
クラスターの設定と変更に関する問題
クラスターのアップグレード時に「UpgradeVersionMustFromConsole」というプロンプトが表示されます。どうすればよいですか?
クラスターの YML ファイル設定で http.max_content_length と discovery.zen.ping_timeout の値を調整できますか?
クラスターのアップグレード時に「cluster unhealthy」というプロンプトが表示されますが、クラスターのステータスは Green と確認されています。どうすればよいですか?
クラスターデータノードのスケールイン時に、「The number of reserved nodes must be greater than 2」というエラーが報告されます。どうすればよいですか?
auto_expand_replicas インデックスを使用すると、データ移行またはノードのスケールインが失敗します。どうすればよいですか?
プラグイン、アナライザー、シノニムに関する問題
課題ログ
データのバックアップと復元に関する問題
クラスターのモニタリングとアラートに関する問題
クラスターアクセスに関する問題
クライアントを使用して Alibaba Cloud ES クラスターに接続するにはどうすればよいですか?また、オープンソースの ES との違いは何ですか?
Alibaba Cloud ECS インスタンスと ES インスタンスが同じ VPC 内で異なるゾーンにある場合、ECS インスタンスは内部ネットワーク経由で ES インスタンスにアクセスできますか?
ES にアクセスできません:Failed to establish a new connection: [Errno 61] Connection refused
Elasticsearch-Head プラグインバージョン 5.0.0 が Alibaba Cloud ES (全バージョン) にアクセスできません。どうすればよいですか?
インデックス関連の問題
購入またはサブスクリプション解約に関する問題
ES インスタンスの購入時に誤った設定を選択した場合はどうすればよいですか?
ES インスタンスの購入後に、選択した設定が期待どおりでないことが判明した場合は、以下の表を参照して、設定に応じた解決策を見つけてください。
クラスターのサブスクリプションを解約またはリリースする前に、データをバックアップしてください。詳細については、「手動バックアップと復元」をご参照ください。サブスクリプションの解約またはリリース後、クラスターに保存されているデータは削除され、復元できなくなります。
設定 | ソリューション |
課金方法 | 従量課金インスタンスを購入した場合、課金方法をサブスクリプションに変更できます。詳細については、「インスタンスの課金方法を従量課金からサブスクリプションに変更する」をご参照ください。 |
バージョン | インスタンスがバージョン変更をサポートするには、次のいずれかの条件を満たす必要があります:
インスタンスのバージョンをアップグレードする方法については、「インスタンスのバージョンをアップグレードする」をご参照ください。バージョンのアップグレードが上記の条件を満たさない場合は、インスタンスのサブスクリプションを解約またはリリースし、希望のバージョンの別のインスタンスを購入することを推奨します。 |
リージョン | これは変更できません。サブスクリプションを解約して新しいインスタンスを購入することを推奨します。 |
ゾーン | ゾーンを移行できます。詳細については、「ゾーンの移行とアップグレード」をご参照ください。 説明 ゾーンを移行する際は、ES インスタンスが正常に作成されていること、つまりインスタンスのステータスが「正常」であることを確認してください。 |
ゾーン数 | これは変更できません。サブスクリプションを解約して新しいインスタンスを購入することを推奨します。 |
インスタンスタイプ | この設定は変更できます。詳細については、「クラスターのアップグレード」をご参照ください。 |
ストレージクラス | この設定は変更できます。詳細については、「クラスターのアップグレード」をご参照ください。 |
ディスク暗号化 | これは変更できません。サブスクリプションを解約して新しいインスタンスを購入することを推奨します。 |
ノードあたりのストレージ容量 | この設定項目は変更できます。詳細については、「クラスターのアップグレード」をご参照ください。 |
データノード数 | この設定は変更できます。詳細については、「クラスターのアップグレード」をご参照ください。 |
ネットワークタイプ、Virtual Private Cloud、vSwitch | これらは変更できません。サブスクリプションを解約して新しいインスタンスを購入することを推奨します。 説明 Virtual Private Cloud (VPC) のみがサポートされています。 |
ユーザー名 | デフォルトのユーザー名は elastic です。この設定項目は変更できません。Kibana コンソールでユーザーを作成し、そのユーザーに必要な権限を付与できます。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用してアクセスの制御を実装する」をご参照ください。 |
ログインパスワード | これは変更できます。詳細については、「インスタンスのアクセスパスワードをリセットする」をご参照ください。 |
上記の表に記載されていない設定については、クラスターのアップグレードまたはダウングレードのページをご確認ください。詳細については、「クラスターのアップグレード」および「クラスターのダウングレード」をご参照ください。
ES の購入ページに表示されるバージョンに対応する具体的なバージョンは何ですか?
購入ページのバージョン | 具体的なバージョン |
8.15 | 8.15.1 |
8.13 | 8.13.4 |
8.9 | 8.9.1 |
8.5 | 8.5.1 |
7.16 | 7.16.2 |
7.10 | 7.10.0 |
7.7 | 7.7.1 |
6.8 | 6.8.6 |
6.7 | 6.7.0 |
6.3 | 6.3.2 |
5.6 | 5.6.16 |
5.5 | 5.5.3 |
インスタンスを購入する際、すでに自己管理のクラスターがある場合は、マイナーバージョンが近いなど、類似のバージョンを選択することを推奨します。自己管理のクラスターがない場合は、最新バージョンを選択することを推奨します。
ES インスタンスの購入時に利用可能な VPC がない場合はどうすればよいですか?
この問題は、Resource Access Management (RAM) ユーザーに VPC のリストを取得する権限が付与されていない場合に発生します。RAM ユーザーに VPC のリストを取得する権限が付与されているか確認してください。詳細については、「RAM ユーザー情報の表示」をご参照ください。権限が付与されていない場合は、RAM ユーザーに権限を付与してください。詳細については、「カスタムポリシーの作成」をご参照ください。
ES インスタンスの購入時に VPC はあるものの、利用可能な vSwitch がない、または vSwitch リストが空で、「vSwitch: may not be empty」というエラーが報告される場合はどうすればよいですか?
この問題は、選択したゾーンに利用可能な vSwitch がないために発生します。この問題を解決するには、VPC コンソールの vSwitch ページに移動し、選択したゾーンに利用可能な vSwitch があるか確認してください。利用可能な vSwitch がない場合は、作成する必要があります。詳細については、「IPv4 CIDR ブロックを持つ VPC の作成」をご参照ください。
インスタンスのサブスクリプションを解約して新しいインスタンスを購入した場合、新しいインスタンスのエンドポイントは変更されますか?
新しいインスタンスを購入した後、ビジネスの中断を防ぐために、古いインスタンスをリリースする前にクライアントコードを変更することを推奨します。
ES インスタンスをリリースまたはサブスクリプション解約するにはどうすればよいですか?
従量課金または期限切れのサブスクリプションインスタンスをリリースする方法については、「インスタンスのリリース」をご参照ください。
期限切れでないサブスクリプションインスタンスの場合:
Alibaba Cloud マネジメントコンソールにログインします。上部のナビゲーションバーで、を選択します。費用とコストコンソールの左側のナビゲーションウィンドウで、サブスクリプションの解約をクリックします。サブスクリプションの解約ページで、クラスターのサブスクリプション解約または注文のキャンセルを実行します。詳細については、「リソースのサブスクリプションを解約する方法」をご参照ください。
シングルノードの ES インスタンスを購入できますか?
いいえ。インスタンスを購入する際には、少なくとも 2 つのデータノードを選択する必要があります。詳細については、「購入ページのパラメーター」をご参照ください。
インスタンス購入時にリソースが売り切れの場合はどうすればよいですか?
インスタンスを作成しようとしてリソースが売り切れている場合は、次の対策を講じることを推奨します:
リージョンを変更する
ゾーンを変更する
リソース設定を変更する
要件を調整してもリソースが利用できない場合は、しばらく待ってから再度インスタンスの購入を試みることを推奨します。インスタンスのリソースは動的です。リソースが不足している場合、Alibaba Cloud はできるだけ早く補充しますが、このプロセスには時間がかかります。
既存の 1 コア 2 GiB 仕様のインスタンスのユーザーは、なぜできるだけ早くインスタンスをアップグレードすべきなのですか?
1 vCPU と 2 GiB のメモリを持つデータノードは、Elasticsearch クラスターのパフォーマンスに影響を与える可能性があります。Alibaba Cloud Elasticsearch は 2021 年 5 月以降、これらの仕様のデータノードを提供していません。これらの仕様の既存のデータノードは引き続き使用できます。1 vCPU と 2 GiB のメモリを持つデータノードはオンライン学習にのみ適しており、本番環境には適していません。サービスレベルアグリーメント (SLA) は、これらのデータノードを含むクラスターには適用されません。したがって、1 vCPU と 2 GiB のメモリを持つデータノードをできるだけ早くアップグレードすることを推奨します。詳細については、「クラスターのアップグレード」をご参照ください。
購入後、ES インスタンスが常に「作成中」の状態のままの場合はどうすればよいですか?
インスタンスが作成された後、アクティブになるまでには時間がかかります。必要な時間は、クラスターの仕様、データ構造、データサイズによって異なり、通常は数時間です。
ES クラスターを作成した後、Kibana ノードを別途購入する必要がありますか?
いいえ。ES クラスターを購入すると、Kibana ノードがデフォルトで有効になります。この設定は変更できません。要件に基づいて Kibana ノードの仕様を選択できます。詳細については、「Alibaba Cloud Elasticsearch インスタンスの作成」をご参照ください。
パフォーマンスと安定性のために、2 CPU コアと 4 GiB のメモリ以上の仕様を持つ Kibana ノードを購入することを推奨します。1 CPU コアと 2 GiB のメモリを持つ Kibana ノードは無料ですが、テスト用にのみ推奨されます。
作成したインスタンスが見つからないのはなぜですか?
選択したリージョンが正しいか確認してください。ES コンソールの上部で選択されているリージョンを確認することを推奨します。リージョンが正しいにもかかわらず ES インスタンスが見つからない場合は、ブラウザのキャッシュをクリアするか、別のローカルネットワークを試すことを推奨します。
ES インスタンスの購入時に専用マスターノードとクライアントノードを購入する必要があるのはどのようなシナリオですか?
専用マスターノードは、インデックスの作成または削除、どのノードがクラスターの一部であるかの追跡、どのシャードをどのノードに割り当てるかの決定など、クラスターレベルの操作を実行します。専用マスターノードの安定性は、クラスターの健全性にとって重要です。次のシナリオでは、独立した専用マスターノードを購入することを推奨します:
クラスター内のプライマリノードとして機能するデータノードが高い負荷にさらされている。
書き込み集中型のシナリオ。
高いクラスターの安定性が要求されるシナリオに最適です。
コーディネーティングノードは、主にクエリと書き込みリクエストをデータノードに転送し、クエリ結果をマージすることで処理します。特に集約シナリオでは、専用のコーディネーティングノードを購入することを推奨します。ベストプラクティスとして、データノード 5 台ごとにコーディネーティングノードを 1 台追加し (最低 2 台)、その仕様がデータノードの仕様と一致することを確認してください。仕様と容量の評価の詳細については、「仕様と容量の評価」をご参照ください。
ES インスタンスの購入時に入力するパスワードのデフォルトアカウントは何ですか?
デフォルトのユーザー名は elastic です。カスタムユーザーを作成することもできます。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用してアクセスの制御を実装する」をご参照ください。
製品機能に関する質問
Alibaba Cloud ES インスタンスのバージョンをアップグレードまたはダウングレードできますか?
一部のバージョンのみが直接のバージョンアップグレードをサポートしています。これには、5.5 から 5.6、5.6 から 6.3、および 6.3 から 6.7 へのアップグレードが含まれます。
他のバージョン間でアップグレードまたはダウングレードするには、まずターゲットバージョンの ES インスタンスを購入し、次に元のインスタンスからターゲットインスタンスにデータを移行し、最後に元のインスタンスのサブスクリプションを解約またはリリースする必要があります。
Alibaba Cloud ES の無料トライアルインスタンスは、バージョン 8.5 および 8.9 のみをサポートしており、作成後に変更することはできません。
バージョンを直接アップグレードするには、「バージョンのアップグレード」をご参照ください。
Elasticsearch クラスターの作成方法については、「Alibaba Cloud ES インスタンスの作成」をご参照ください。
Elasticsearch クラスター間のデータ移行については、「Alibaba Cloud Elasticsearch クラスター間のデータ移行」をご参照ください。
期限切れでないサブスクリプションインスタンスのサブスクリプションを解約するには、「返金ポリシー」をご参照ください。従量課金インスタンスをリリースするには、「インスタンスのリリース」をご参照ください。
SSH 経由でクラスターにログインして設定を変更できますか?
いいえ。セキュリティ上の理由から、SSH 経由で ES クラスターにログインすることは許可されていません。クラスター設定を変更するには、ES のクラスター設定機能を使用してください。詳細については、「クラスター設定」をご参照ください。
Logstash 6.7 は ES 6.3 と互換性がありますか?
はい、互換性があります。詳細については、「互換性マトリックス」をご参照ください。
Quick BI は ES データソースをサポートしていますか?
Quick BI を使用してパブリックネットワーク経由で ES に接続できますが、Quick BI の IP アドレスを ES のパブリックアクセスホワイトリストに追加する必要があります。
ES はスコアリングプラグインをサポートしていますか?
ES は、インデックスからアナライザーを作成してデータを検索し、スコアに基づいて結果をソートすることをサポートしています。詳細については、「Basic Edition:インスタンス作成からデータ取得まで」をご参照ください。
ES は LDAP をサポートしていますか?
はい、Elasticsearch は Lightweight Directory Access Protocol (LDAP) をサポートしています。LDAP を使用して Elasticsearch クラスターに送信されるリクエストを認証したい場合は、同じバージョンのオンプレミス Elasticsearch クラスターをデプロイして認証テストを実施する必要があります。テストが成功した場合、ES コンソールで対応するテンプレートを設定できます。詳細については、「X-Pack との LDAP 認証統合のベストプラクティス」をご参照ください。
ES には Java SDK がありますか?
はい、あります。各 ES バージョンには対応する SDK が必要です。詳細については、「Java API」をご参照ください。
ES インスタンスのカーネルバージョンはどこで確認できますか?
デフォルトでは、ES クラスターは最新バージョンのカーネルを使用します。カーネルバージョンの詳細については、「カーネルバージョンリリースノート」をご参照ください。クラスターが最新バージョンのカーネルを使用していない場合、クラスターの基本情報ページに新しいカーネルパッチが利用可能ですというメッセージが表示されます。このメッセージをクリックすると、クラスターの現在のカーネルバージョンが表示されます。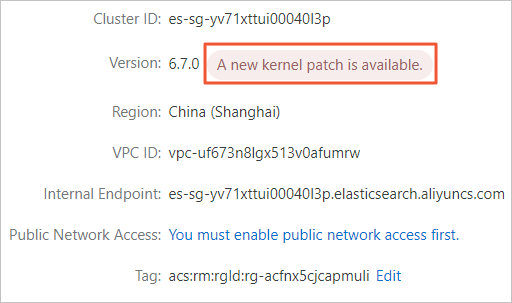
ES の強制再起動機能はいつ使用できますか?また、この機能を使用した場合の影響は何ですか?
インスタンスのステータスが「正常」(黄色または赤色) でない場合、再起動操作はサポートされません。この場合、インスタンスを強制的に再起動する必要があります。この機能を使用すると、再起動フェーズ中にサービスの不安定化、データの損失、または読み書きの失敗が発生する可能性があります。注意して進めてください。
ES の Log4j2 脆弱性が修正されたことを確認するにはどうすればよいですか?
クラスターが正常に再起動された後、脆弱性は修正されます。詳細については、「[脆弱性アラート] Apache Log4j2 の任意コード実行の脆弱性」をご参照ください。
Log4j2 脆弱性を修正するために ES のバージョンをアップグレードする必要がありますか?
いいえ、必要ありません。修正手順の指示に従って脆弱性を修正するだけで十分です。
異なるリージョンにある ES インスタンス間のイントラネット相互通信を有効にするにはどうすればよいですか?
異なるリージョンにある ES インスタンス間のイントラネット相互通信は、次の 2 つの方法で有効にできます:
VPC ピアリング接続を使用する。詳細については、「VPC ピアリング接続を使用して VPC 間のプライベート接続を有効にする」をご参照ください。
Cloud Enterprise Network (CEN) インスタンスを使用する。詳細については、「Cloud Enterprise Network を使用してリージョン間でネットワークインスタンスを接続する」をご参照ください。
Elasticsearch クラスター間でデータを移行するにはどうすればよいですか?
別の Alibaba Cloud Elasticsearch クラスター、自己管理の Elasticsearch クラスター、またはサードパーティの Elasticsearch ソースから Alibaba Cloud Elasticsearch クラスターにデータを移行できます。データ移行のソリューションとツールは、データ移行のシナリオによって異なります。詳細については、「データ移行ソリューションの選択」をご参照ください。
HTTPS プロトコルを有効にするためにクライアントノードを購入する必要がありますか?
以下の ES バージョンでは、HTTPS を有効にするためにクライアントノードを購入する必要はありません。既存のクライアントノードは無効にできます。
7.16 以降のバージョン。
上記のバージョン以外の ES バージョンでは、HTTPS を有効にするためにクライアントノードを有効にする必要があります。クライアントノードは購入後にサブスクリプションを解約したり無効にしたりすることはできません。
セキュリティ上の理由から、Elasticsearch クラスターで HTTPS を有効にすると、システムはクラスターが依存する証明書を定期的に維持および更新します。V7.10 以前の Elasticsearch クラスターのデータノードにインストールされた証明書のローリングアップデートは実行できません。証明書の更新中にノードの再起動がオンラインサービスに与える影響を軽減するため、システムはリクエストを転送するために使用されるクライアントノードに証明書をデプロイします。クライアントノードを含まない Elasticsearch クラスターで HTTPS を有効にすると、システムはクラスターにクライアントノードを購入するように促すメッセージを表示します。クラスターで HTTPS を有効にする前に、クラスターにクライアントノードを購入する必要があります。詳細については、「HTTPS の有効化」をご参照ください。
単一の ES ノードでサポートされるシャードの最大数はいくつですか?
Alibaba Cloud Elasticsearch では、Elasticsearch V7.x クラスターの単一データノード上のインデックスに最大 1,000 個のシャードを割り当てることができます。他のバージョンの Elasticsearch クラスターでは、単一データノード上のインデックスに割り当て可能なシャードの数に制限はありません。Elasticsearch クラスターの仕様に基づいて、単一データノード上のインデックスにシャードを設定する必要があります。詳細については、「仕様とストレージ容量の評価」および「シャードのサイズ設定」をご参照ください。
max_shards_per_node パラメーターを使用して、クラスターのシャードの最大数を一時的に変更するには、次のコマンドを使用できます:
PUT /_cluster/settings
{
"transient": {
"cluster": {
"max_shards_per_node":10000
}
}
}長期的な解決策として、このパラメーターを過度に大きな値に設定しないでください。クラスターのノード数を増やすか、シャード数を減らしてください。過度の圧力によるクラスターの不安定化を防ぐために、シャードを適切に計画してください。
.monitoring-es で始まるインデックスはどのように生成され、何に使用されますか?
デフォルトでは、X-Pack モニタリングクライアントは 10 秒ごとにクラスターからモニタリングデータを収集し、対応する Alibaba Cloud Elasticsearch インスタンスの .monitoring-* というプレフィックスが付いたインデックスにデータを保存します。たとえば、v6.x インスタンスには、.monitoring-es-6-* と .monitoring-kibana-6-* の 2 つの主要なインデックスタイプがあり、これらは毎日ローテーションされます。収集されたデータは、.monitoring-es-6- というプレフィックスと現在の日付のサフィックスが付いたインデックスに保存されます。
.monitoring-es-6-* インデックスは大量のディスク領域を消費します。これらは主に、クラスターのステータス、クラスターの統計、ノードの統計、インデックスの統計などの情報を保存します。詳細については、「モニタリングインデックスの設定」をご参照ください。
ES データディスクのディスク暗号化にはどの暗号化アルゴリズムが使用されますか?
ES は、業界標準の AES-256 暗号化アルゴリズムと Key Management Service (KMS) を使用してディスクを暗号化します。詳細については、「ディスク暗号化の概要」をご参照ください。
Alibaba Cloud ES サービスはポート 9300 をサポートしていますか?
Alibaba Cloud ES 5.x バージョンのみが、ポート 9300 (TCP 用) とポート 9200 (HTTP または HTTPS 用) の両方をサポートしています。他のバージョンはポート 9200 のみをサポートしています。
バージョン 6.0 以降の Alibaba Cloud ES インスタンスは、ポート 9300 での Transport Client を使用したアクセスをサポートしていません。ポート 9300 にアクセスするには、5.x バージョンのインスタンスを購入する必要があります。
データ移行と同期に関する問題
MongoDB から Alibaba Cloud ES にデータを同期するにはどうすればよいですか?
Monstache を使用して、MongoDB のデータを Alibaba Cloud Elasticsearch にリアルタイムで同期できます。詳細については、「Monstache を使用して MongoDB のデータを Elasticsearch にリアルタイムで同期する」をご参照ください。
インスタンスの再起動に関する問題
ES インスタンスまたはノードの再起動にはどのくらいの時間がかかりますか?
Elasticsearch クラスターまたはノードを再起動すると、システムは推定時間を表示します。時間は、クラスターまたはノードの仕様、データ構造、およびデータ量に基づいて推定されます。ほとんどの場合、クラスターの再起動には数時間かかります。詳細については、「インスタンスまたはノードの再起動」をご参照ください。
ES インスタンスのパブリックネットワークアクセスを有効または無効にすると、再起動がトリガーされますか?
いいえ、トリガーされません。ただし、設定が有効になるためにインスタンスのステータスが一時的に変更されます。これは通常の使用には影響しません。
クラスターのアクセスパスワードを変更すると、クラスターの再起動がトリガーされますか?
いいえ、トリガーされません。パスワードの変更はクラスターの再読み込みのみをトリガーし、再起動は行いません。詳細については、「インスタンスのアクセスパスワードをリセットする」をご参照ください。
インデックスにレプリカシャードがない場合、クラスターの再起動に影響しますか?
はい、影響します。再起動中にクラスターが継続的なサービスを提供できなくなる可能性があります。クラスター全体の負荷が高くなく、インデックスにレプリカシャードがある場合、通常は再起動中もサービスを継続して提供できます。ただし、一部のシナリオでは、再起動中にアクセスタイムアウトが発生する可能性があります。たとえば、強制再起動の同時実行性が高い場合、クラスターの負荷が非常に高く、クラスターにすでにアクセスできない場合、レプリカシャードがない場合、または再起動または強制再起動中に多くの書き込みやクエリがある場合などです。クライアント側でリトライメカニズムを設計し、オフピーク時に操作を実行することを推奨します。
ロールノード (Kibana ノードなど) または単一ノードを再起動するにはどうすればよいですか?
ロールノードの再起動
インスタンスの基本情報ページで、再起動をクリックします。操作タイプにロールノードの再起動を選択し、対応するロールノードを選択します。詳細については、「インスタンスまたはノードの再起動」をご参照ください。
単一ノードの再起動
単一ノードは、次の 2 つの方法のいずれかで再起動できます:
インスタンスの基本情報ページで、再起動をクリックし、操作タイプをノードの再起動に設定し、再起動したいノードを選択します。詳細については、「インスタンスまたはノードの再起動」をご参照ください。
インスタンスの基本情報ページのノード可視化セクションで、再起動したいノードにポインターを合わせます。表示されるポップオーバーで、再起動をクリックします。詳細については、「クラスターのステータスとノード情報の表示」をご参照ください。
インスタンスの再起動が停止した場合はどうすればよいですか?
まず、タスクリストでインスタンス変更タスクの詳細を表示することを推奨します。7.16 以外のバージョンでは、インスタンスの再起動には数時間かかります。詳細については、「インスタンスのタスク進捗の表示」をご参照ください。変更の進捗が長時間変わらない場合は、以下の指示に従って問題をトラブルシューティングできます。
考えられる原因 | ソリューション |
プラグインの問題によりノードが起動しない。 | 対応するプラグインを削除します。 |
ディスク使用率が高いためシャードを割り当てられない。 説明 クラスターモニタリングでクラスターのディスク使用率を表示できます。詳細については、「メトリックの表示と例外の処理」をご参照ください。 | インデックスを削除するか、インデックスのレプリカ数を一時的に 0 に設定します。 |
クラスターパラメーターの設定の問題によりシャードを割り当てられない。 |
|
レプリカ数がノード数より多い。 | レプリカ数をリセットします。 |
クラスターの仕様が小さすぎて、メモリ不足 (OOM) エラーが発生する。 |
ES インスタンスのノードの定期的な再起動を設定できますか?
いいえ、できません。ノードの定期的な再起動はサポートされていません。この要件がある場合は、RestartInstance API 操作を呼び出すことができます。ただし、定期タスクを記述し、対応するノード情報を設定する必要があります。
クラスターの負荷またはステータスの異常に関する問題
ES を使用していると、一部のノードの CPU と負荷は正常ですが、他のノードはアイドル状態です。どうすればよいですか?
この問題は、クラスターの負荷が不均衡であるために発生します。負荷の不均衡は、不適切なシャード設定、不均一なセグメントサイズ、ホットデータとコールドデータの分離不足、Server Load Balancer (SLB) インスタンスやマルチゾーンアーキテクチャで使用される持続的接続など、いくつかの原因が考えられます。実際のシナリオに基づいて問題を解決してください。詳細については、「クラスターの負荷の不均衡」をご参照ください。
トラブルシューティングを行う前に、クラスターの仕様を確認してください。クラスターが 1 CPU コアと 2 GiB のメモリ (学習用仕様) を持つ場合は、2 CPU コアと 4 GiB のメモリ以上にアップグレードしてください。詳細については、「クラスターのアップグレード」をご参照ください。
1 コア 2 GiB の仕様は学習シナリオにのみ適しており、本番環境には適していません。製品のサービスレベルアグリーメント (SLA) の対象外です。安定性が低いため、この仕様は現在購入できません。1 コア 2 GiB のインスタンスをできるだけ早くより高い仕様にアップグレードすることを推奨します。
2 コア 4 GiB の仕様は、テスト環境での使用を推奨します。本番環境では、より高い仕様を使用することを推奨します。
ES クラスターのステータスが黄色になった場合はどうすればよいですか?
原因
インデックスに設定したレプリカ数が現在のノード数から 1 を引いた数より大きい場合、クラスターのステータスは黄色になります。
ソリューション
GET _cat/indices?vコマンドを実行してインデックスシャードの分布を表示し、ステータスが黄色のインデックスを特定して、そのレプリカシャード数を 0 に設定します。クラスターが正常に戻った後、対応するインデックスのレプリカシャード数を元の値に戻します。警告レプリカシャード数を 0 に設定すると、ノードがオフラインになった場合にデータが失われる可能性があります。注意して進めてください。クラスターが正常に戻った後 (約 1 分後)、できるだけ早くレプリカシャード数を元の値に戻してください。
PUT test/_settings { "index" : { "number_of_replicas":"0" } }
高負荷により ES クラスターのステータスが赤色に変わった場合はどうすればよいですか?
プライマリシャードが配置されているノードの異常により、クラスターが赤色に変わります。GET /_cat/indices?v コマンドを実行してインデックスシャードの分布を表示し、赤色のインデックスを特定して、以下の一般的な原因と解決策に基づいてトラブルシューティングを行ってください。
一般的な原因 | ソリューション |
負荷の不均衡によるクラスターリソースの不足。 | プライマリシャードとレプリカシャードの合計数をクラスターのデータノード数の整数倍に変更して、ノード間の負荷を均等にします。詳細については、「不均一なシャード分布を調整するにはどうすればよいですか?」をご参照ください。 |
クラスターに不要なインデックスデータが含まれている。 | .monitor で始まるモニタリングインデックスなど、不要なインデックスを定期的にクリアします。詳細については、「モニタリングインデックスの設定」をご参照ください。 |
未割り当てのシャード。 |
|
キャッシュがリソースを消費している。 |
|
アップグレードなどのクラスター変更操作が進行中。 | 現在の変更を中断し、アップグレードページで「強制変更」を選択することを推奨します。詳細については、「クラスターのアップグレード」をご参照ください。 |
インスタンスの仕様が低く、1 コア 2 GiB や 2 コア 4 GiB の仕様など、リソースが不足している。 | クラスターをアップグレードします。詳細については、「クラスターのアップグレード」をご参照ください。 説明
|
ディスク使用率が 85% を超えている | 不要になった既存データを削除するか、ディスクの容量を拡張することを推奨します。詳細については、「高いディスク使用率と読み取り専用インデックス」をご参照ください。 |
モニタリングでクラスターの CPU 使用率が高すぎることが確認されたり、アラートが届いたりした場合はどうすればよいですか?
一般的な原因とそれに対応する解決策は次のとおりです。
一般的な原因 | ソリューション |
書き込みまたはクエリの QPS の増加が CPU 使用率の増加につながることが示されている。 | 同時書き込み量を減らす、書き込みとクエリの QPS を下げる、またはクラスターをスケールアウトすることができます。本番環境でストレステストを実施して、適切な仕様を選択することを推奨します。 |
インデックスキャッシュが過剰なリソースを消費している。 |
|
クラスターのリソースが不足している。 | クラスターをアップグレードします。詳細については、「クラスターのアップグレード」をご参照ください。 |
単一ノードで CPU 使用率が高く、負荷が不均衡である。 | プライマリシャードとレプリカシャードの合計数をクラスターのデータノード数の整数倍に変更して、ノード間の負荷を均等にすることができます。詳細については、「Elasticsearch クラスターのノード間でシャードが均等に分散されていない場合はどうすればよいですか?」をご参照ください。 |
ES のディスク使用率が高すぎる場合はどうすればよいですか?
DELETE /index_name コマンドを実行して不要なインデックスを削除することを推奨します。ディスク使用率が 75% を下回った後、コンソールでクラスターのディスク容量と仕様をアップグレードできます。詳細については、「クラスターのアップグレード」をご参照ください。単一ノードのディスク使用率が高すぎる場合は、シャードも最適化する必要があります。詳細については、「Elasticsearch クラスターのノード間でシャードが均等に分散されていない場合はどうすればよいですか?」をご参照ください。
高いディスク使用率が Elasticsearch サービスに影響を与えないように、ディスク使用率のモニタリングとアラートを有効にすることを推奨します。アラート通知を迅速に確認し、予防措置を講じてください。詳細については、「メトリックの表示と例外の処理」をご参照ください。ノードのディスク使用率が特定のしきい値を超えると、クラスターは次のように影響を受けます:
85% を超える:新しいシャードを割り当てられません。
90% を超える:ES は、対応するノードからディスク使用率の低い他のデータノードにシャードを移行しようとします。
ディスク使用率が 95% を超えると、システムは Elasticsearch クラスター内のすべてのインデックスに read_only_allow_delete 属性を強制的に設定します。その結果、インデックスにデータを書き込むことができなくなります。インデックスからの読み取りまたは削除のみが可能です。
モニタリングで ES のメモリ使用量が高すぎることが確認されたり、アラートが届いたりした場合はどうすればよいですか?
一般的な原因とそれに対応する解決策は次のとおりです。
一般的な原因 | ソリューション |
クラスターキャッシュがメモリを消費している。 | 短期的には、 |
書き込みアクティビティが過剰である。 | 読み書き操作を停止し、レート制限プラグインをインストールして、クラスターのレート制限を有効にします。詳細な手順については、「クラスターレート制限プラグイン (aliyun-qos) の使用」をご参照ください。 |
不要なインデックスがメモリを消費している。 | 不要なインデックスを削除してリソースを解放します。.monitoring-* プレフィックスを持つモニタリングインデックスなど、モニタリングインデックスの保持期間を設定できます。詳細については、「モニタリングログの設定」をご参照ください。 |
単一ノードのメモリ使用率が高く、シャード分布が不均一である。 | シャードの負荷を最適化します。プライマリシャードとレプリカシャードの合計数をクラスターのデータノード数の整数倍に設定します。詳細については、「シャードが不均一に分散されている場合はどうすればよいですか?」をご参照ください。 |
クライアントアプリケーションからの特殊文字の長い文字列を含むクエリなど、異常なクエリ。 | 時間のかかるクエリタスクに関する情報を取得するには、 |
不均一なシャード分布を調整するにはどうすればよいですか?
シャードを再割り当てし、適切に計画することを推奨します。プライマリシャードとレプリカシャードの合計数がクラスターのデータノード数の整数倍になるようにしてください。この方法は、データを各データノードに均等に分散させ、不均一な分布による単一ノードの高負荷を防ぎます。以下は、プライマリシャードとレプリカシャードの割り当ての例です:
クラスターに 3 つのデータノードがある場合、プライマリシャード数を 3、レプリカシャード数を 1 に設定できます。この設定により、合計 6 つのシャードになります。
クラスターに 8 つのデータノードがある場合、プライマリシャード数を 4、レプリカシャード数を 1 に設定して合計 8 つのシャードにするか、プライマリシャード数を 8、レプリカシャード数を 1 に設定して合計 16 のシャードにすることができます。
シャード数を調整した後、オフピーク時にインデックスを再作成して、変更を既存のデータに適用する必要があります。レプリカシャード数を増やすと、Elasticsearch クラスターの可用性とクエリパフォーマンスが向上しますが、クラスターのメモリ使用量も増加します。
シャードの数と各シャードのサイズの両方が、Elasticsearch クラスターの安定性とパフォーマンスに寄与します。Elasticsearch クラスター内のすべてのインデックスのシャードを適切に計画する必要があります。これにより、複雑なビジネスシナリオで問題となる可能性のある、過剰なシャード数によるクラスターパフォーマンスの低下を防ぎます。シャード計画の詳細については、「シャードの評価」をご参照ください。
不均一なシャード分布は、クラスターの負荷の不均衡につながる可能性があります。不均一なシャード分布は、次の方法で確認できます:
メトリックの説明とトラブルシューティングの提案をご参照ください。ノードの CPU、メモリ、またはディスクの負荷が高い場合、これはシャードが均等に分散されていないことを示します。
GET _cat/shards?vコマンドを実行して、インデックスのシャード情報を表示します。インデックスのシャードの多くが負荷の高いノードにある場合、これは不均一なシャード分布を示します。
クラスターの負荷が高く、プライマリログに「java.lang.StackOverflowError for the entire cluster」というエラーが報告されます。どうすればよいですか?
このスタックオーバーフローエラーは、Lucene によってスタックに書き込まれるデータ量が制限を超えたために発生します。この問題は、正規表現ベースのクエリとあいまい一致が原因です。この問題は Elasticsearch V6.0 以降で修正されています。できるだけ早くクラスターのバージョンをアップグレードするか、クエリを最適化することを推奨します。詳細については、「java.lang.StackOverflowError for the entire cluster」をご参照ください。
JVM 設定で実際に割り当てられたメモリ量を照会するにはどうすればよいですか?
この値を表示するには、GET _nodes/stats/jvm?pretty コマンドを実行できます。デフォルトでは、この値はクラスターのメモリの半分であり、変更できません。
クラスターのクエリと書き込みに関する問題
キューサイズを調整するにはどうすればよいですか?
YML 設定で thread_pool.write.queue_size パラメーターを設定することで、キューサイズを調整できます。詳細については、「YML パラメーターの設定」をご参照ください。このパラメーターを調整する前に、GET /_cat/thread_pool?v コマンドを実行して現在のキュー使用量を確認できます。
6.0 より前のバージョンの Elasticsearch クラスターでは、thread_pool.index.queue_size パラメーターを使用する必要があります。
特定の期間のデータを照会またはエクスポートするにはどうすればよいですか?
Elasticsearch で特定の期間のデータを照会するには、範囲クエリを使用できます。詳細については、「範囲クエリ」をご参照ください。
特定の期間のデータをエクスポートするには、Logstash を使用してデータをフィルタリングできます。詳細については、「Logstash 設定ファイル」をご参照ください。
ES の一括挿入操作に数量制限はありますか?
デフォルトでは、一括送信のデータ量は 100 MB を超えることはできません (詳細については、「HTTP 設定」をご参照ください)。この制限を超えた場合は、各リクエストで書き込むデータ量を調整できます。各書き込みリクエストのデータ量は、ドキュメント数に単一ドキュメントのサイズを掛けたものです。ただし、ドキュメント数だけではデータ量を正確に見積もることはできません。データ量は各ドキュメントのサイズと複雑さにも依存するためです。個々のドキュメントが大きい場合は、各リクエストのドキュメント数を減らすことができます。各書き込みリクエストのデータ量を 5 MB から 15 MB でテストを開始することを推奨します。具体的なチューニング方法については、「一括リクエストの使用とサイズ設定のドキュメント」をご参照ください。
Elasticsearch のクエリ結果と実際の時刻に時差があります。どうすればよいですか?
デフォルトでは、Elasticsearch は協定世界時 (UTC) を使用しており、これはローカルのタイムゾーンと異なる場合があります。Elasticsearch はタイムゾーンの調整をサポートしていないため、手動で時刻変換を処理する必要があります。次のいずれかの方法を使用して時差を解決できます:
日付タイプのデータを照会する際、タイムゾーンを指定するか、タイムスタンプを使用できます。詳細については、「<field> のパラメーター」をご参照ください。
時刻データを書き込む際、タイムゾーンを指定できます。例:
"time" : "2022-07-15T12:58:17.136+0800"(UTC+8)。Kibana を使用してデータを表示できます。Kibana が Elasticsearch から日付タイプのフィールドを取得すると、JavaScript を使用してブラウザのローカルタイムゾーンを決定します。その後、フィールドの時刻値を UTC からブラウザのタイムゾーンに変換して結果を表示します。詳細については、「Kibana コンソールでデータ可視化のタイムゾーンを変更するにはどうすればよいですか?」をご参照ください。
Logstash でデータを同期していて 8 時間の時差がある場合は、パイプライン設定に対応する時刻オフセットを手動で追加する必要があります。例:
filter{ ruby{ code => "event.set('update_time', event.get('update_time').time.localtime + 8*60*60)" } }。
ES クラスターへのクエリで結果が返されるまでに時間がかかる、または結果がまったく返されない場合はどうすればよいですか?
結果が返されるまでに時間がかかる、または結果がまったく返されないクエリは、スロークエリと見なされます。コンソールでスロークエリログを表示して調査できます。詳細については、「スロークエリログ」をご参照ください。原因を特定するには、「メトリックの表示と例外の処理」をご参照ください。以下の表に、一般的な原因とその解決策を示します。
一般的な原因 | ソリューション |
シャードの負荷が不均衡。 | プライマリシャードとレプリカシャードの合計数がクラスターのデータノード数の整数倍になるようにすることで、シャードの負荷を最適化できます。詳細については、「Elasticsearch クラスターのノード間でシャードが均等に分散されていない場合はどうすればよいですか?」をご参照ください。 |
クラスターのリソースが不足している。 | クラスターでリソースを大量に消費するクエリを実行する場合は、クエリ文を最適化するか、クラスター設定をアップグレードすることを推奨します。例としては、集約、term、スクリプト、あいまい一致クエリなどがあります。Elasticsearch クラスターのアップグレードの詳細については、「クラスターのアップグレード」をご参照ください。 説明 Elasticsearch クラスターの健全性は、クエリのパフォーマンスに影響します。メモリ使用率が 80% 未満で、ノードの負荷が均等である場合にパフォーマンスが最適になります。 |
クラスターへの書き込み時に「Data too large... which is larger than the limit of」というエラーが報告されます。どうすればよいですか?
原因
書き込み量が多すぎて、サーキットブレーカーが作動しました。クラスターのリソースが現在の書き込みリクエスト量を処理するのに不足しています。
ソリューション
重要以下の操作を実行できない場合は、すべてのクエリと書き込み操作を停止し、クラスターを強制的に再起動する必要があります。クラスターが正常な状態に戻った後、必要な操作を実行してください。
POST /index_name/_cache/clear?fielddata=trueコマンドを実行してインデックスキャッシュをクリアします。これで問題が解決しない場合は、次のステップに進みます。GET /_cat/indices?vコマンドを実行して、クラスター内のノード間でシャードが不均等に分散しているかどうかを確認します。詳細については、「Elasticsearch クラスターのノード間でシャードが均等に分散されていない場合はどうすればよいですか?」をご参照ください。問題が解決しない場合は、次のステップに進みます。同時書き込みを減らし、不要なインデックスを削除してリソースを解放し、Kibana モニタリングの使用を減らします。
Kibana モニタリングを無効にするには、次のコマンドを実行します:
PUT _cluster/settings { "persistent": { "xpack.monitoring.collection.enabled": false } }これで問題が解決しない場合は、次のステップに進みます。
クラスターをアップグレードしてクラスター容量を増やします。
ES はインデックスの一括削除をサポートしていますか?
はい、サポートしています。YML パラメーターを設定し、削除のためのインデックス命名規則をワイルドカードを許可に設定する必要があります。クラスターが再起動された後、ワイルドカードを使用してインデックスを一括削除できます。詳細については、「YML パラメーターの設定」をご参照ください。
削除されたインデックスは回復できません。この設定は注意して使用してください。
新しいインデックスを作成する際に、「index uuid conflicted」というエラーが時々発生し、インデックスドキュメントを書き込めません。どうすればよいですか?
これは既知の問題です。この問題を解決するには、インスタンスのカーネルバージョンを 1.5.0 以降にアップグレードしてください。詳細については、「インスタンスのバージョンをアップグレードする」をご参照ください。
index.max_result_window (ページングクエリの最大ドキュメント数) を変更するにはどうすればよいですか?
ES の index.max_result_window パラメーターのデフォルト値は 10000 です。このパラメーターは、ページングクエリで返されるドキュメントの最大数 (`from` + `size`) を指定します。クエリがこの値を超えると、次のエラーが報告されます:Result window is too large, from + size must be less than or equal to: [10000]。
深いページングを必要とする検索シナリオでは、index.max_result_window パラメーターの値を増やす必要がある場合があります。次のコマンドを実行して、要件に応じて index.max_result_window の値を変更できます。コマンドの値は参考用です。このパラメーター設定は、Elasticsearch クラスターの再起動後も維持されます。
PUT /my_index/_settings
{
"index": {
"max_result_window": 50000
}
}クエリが多くの結果を返す場合、from と size パラメーターを使用して深いページングを実行することは推奨しません。この操作は大量の CPU とメモリリソースを消費するためです。深いページングのシナリオでは、代わりに scroll または search after を使用することを推奨します。
ES データの更新時に「Rejecting mapping update to [] as the final mapping would have more than 1 type」というエラーが報告されます。どうすればよいですか?
このエラーは、更新操作で指定されたタイプが元のインデックスのタイプと異なる場合に発生します。ES インデックスは複数のタイプを持つことができないため、データを更新する際には元のインデックスと同じタイプを使用する必要があります。
Elasticsearch 7.0 以降では、マッピングからタイプ定義が削除され、タイプは _doc に設定されます。
インデックス内のドキュメントの詳細な内容を照会するにはどうすればよいですか?
Kibana コンソールにログインして、次のコマンドを実行できます:
GET _search
{
"query": {
"match_all": {}
}
}インデックスパターンを作成した後、Kibana の Discover ツールを使用してドキュメントを表示することもできます。詳細については、「Kibana ガイド」をご参照ください。
クラスターの設定と変更に関する問題
ES を使用する前に、クラスターのリソースと仕様、シャードのサイズと数量を適切に計画するにはどうすればよいですか?
「仕様とストレージ容量の評価」もご参照ください。
ES インスタンスの設定パラメーターを表示するにはどうすればよいですか?
インスタンスの基本情報ページで設定パラメーターを表示できます。詳細については、「インスタンスの基本情報の表示」をご参照ください。
Transport Client を使用して ES インスタンスにアクセスする場合、cluster.name パラメーターをインスタンス ID に設定します。詳細については、「Transport Client (5.x)」をご参照ください。
クラスター設定を変更すると ES サービスに影響しますか?
クラスター設定を変更すると、ローリングリスタートがトリガーされます。クラスターのステータスが正常 (緑色) で、各インデックスに少なくとも 1 つのレプリカがあり、リソース使用率が過剰でない場合、クラスターは再起動中もサービスを提供し続けることができます。クラスターモニタリングページでリソース使用率を確認できます。たとえば、ノードの CPU 使用率が約 80%、ノードのヒープメモリ使用率が約 50%、ノードの load_1m がデータノードの CPU コア数より低い場合、リソース使用率は過剰とは見なされません。ただし、クラスター設定はオフピーク時に変更することを推奨します。
ノード数を変更した後、クラスターは自動的にシャードを再調整しますか?
はい、します。Elasticsearch クラスターのノード数が変更されると、システムは自動的にシャードを再割り当てします。ただし、この再割り当てプロセスは、ノード間でシャードが均等に分散されることを保証するものではありません。インデックスのサイズ、シャードの数、ノードの数などの要因により、データが不均等に分散されたままになることがあります。クラスターの負荷の不均衡のトラブルシューティングと解決の詳細については、「クラスターの負荷の不均衡」をご参照ください。
ES インスタンスはディスクタイプの変更をサポートしていますか?
はい。ディスクをダウングレードする場合、サポートされるストレージパフォーマンスパスは、エンタープライズ SSD から標準 SSD、そして Ultra ディスクです。ディスクをアップグレードする場合、パスは Ultra ディスクから標準 SSD、そしてエンタープライズ SSD です。
ES は他のタイプのノードをコールドデータノードに変更することをサポートしていますか?
いいえ、サポートしていません。この操作はインスタンスを不安定にする可能性があります。詳細については、「Elasticsearch 5.x の「Hot-Warm」アーキテクチャ」をご参照ください。
インスタンスの仕様をアップグレードした後、設定をダウングレードできますか?また、その方法は?
はい、設定をダウングレードできます。詳細については、「クラスターのデータノードをスケールインする」または「クラスターのダウングレード」をご参照ください。
ビジネス量が一時的に急増した場合、通常のビジネス運用を確保するためにクラスター設定を変更するにはどうすればよいですか?
ビジネス量が一時的に急増した場合は、まずノードをスケールアウトし (クラスターのアップグレード)、次にデータノードをスケールインする (クラスターのデータノードをスケールインする) ことを推奨します。これらの変更は、有効になるためにクラスターの再起動が必要です。再起動の前に、次の条件が満たされていることを確認してください:
インスタンスのステータスが正常 (緑色) である。
各インデックスに少なくとも 1 つのレプリカがあり、リソース使用率が過度に高くない。これはクラスターモニタリングページで確認できます。たとえば、ノードの CPU 使用率が約 80%、ノードのヒープメモリ使用率が約 50%、ノードの load_1m がデータノードの CPU コア数より低い必要があります。
クラスターのアップグレード時に「UpgradeVersionMustFromConsole」というプロンプトが表示されます。どうすればよいですか?
この問題は、アップグレードパスがサポートされていないために発生します。Alibaba Cloud ES は、バージョン 5.5.3 から 5.6.16、5.6.16 から 6.3.2、および 6.3.2 から 6.7.0 へのアップグレードのみをサポートしています。
ES バージョンのアップグレードにはどのくらいの時間がかかりますか?
アップグレードに必要な時間は、データサイズ、データ構造、およびクラスターの仕様によって異なります。このプロセスは通常、約 1 時間かかります。
ES バージョンのアップグレードはクラスターサービスに影響しますか?
Elasticsearch クラスターをアップグレードする際、クラスターへの読み書きは引き続き可能ですが、他の変更はできません。アップグレードはオフピーク時に実行することを推奨します。アップグレード手順と注意事項の詳細については、「クラスターのバージョンをアップグレードする」をご参照ください。
クラスターのアップグレード中にエラーまたはタイムアウトが発生します。どうすればよいですか?
この問題は通常、クラスターが異常な状態にあるために発生します。この場合、すべてのクエリと書き込み操作を停止し、「Elasticsearch クラスターが重負荷により赤色の状態になった場合はどうすればよいですか?」の指示に従って問題をトラブルシューティングしてください。クラスターが正常な状態に回復した後、再度設定のアップグレードを試みてください。または、クラスターの健全性ステータスを無視して強制アップグレードを実行することもできます。ただし、強制アップグレードは ES サービスを中断させる可能性があります。注意して進めてください。
その他のアップグレードの問題については、エラーメッセージに基づいてトラブルシューティングと解決を行う必要があります。
クラスター設定を変更できません。どうすればよいですか?
この問題をトラブルシューティングするには、次の手順を実行します:
クラスターノードがローカルディスクを使用しているかどうかを確認します。ローカルディスクを使用するノードの設定変更はサポートされていません。ノードの仕様をアップグレードするには、まずディスクタイプを変更する必要があります。
フロントエンドの検証で在庫不足が示された場合は、別のゾーンで設定変更を試みるか、現在のゾーンで他のユーザーがインスタンスをリリースするのを待ちます。
フロントエンドの検証でクラスターのステータスが不健全であることが示された場合は、クローズ状態のインデックスがないか確認し、一時的にステータスをオープンに変更します。クラスターのステータスが赤色の場合は、オフラインノードや未割り当てシャードなどの問題がないか確認し、まずこれらのクラスターの問題を解決します。
クラスターがダウングレードの次の条件を満たしているかどうかを確認します:
ダウングレードのターゲットノード仕様の CPU とメモリは、現在の仕様の少なくとも半分である必要があります。ノード仕様を 1 コア 2 GiB、2 コア 2 GiB、2 コア 4 GiB、または 4 コア 4 GiB にダウングレードすることはできません。
説明2 コア 4 GiB または 4 コア 4 GiB のインスタンスにダウングレードするには、希望の仕様で新しいインスタンスを作成し、Logstash などのデータ移行方法を使用してデータを移行する必要があります。
クラスターの負荷が要件を満たしている場合にのみ、クラスターをダウングレードできます。ダウングレードの制限と注意事項の詳細については、「クラスターのダウングレード」をご参照ください。
ダウングレード中にディスク容量を減らすことはできません。
クラスターの YML ファイル設定で http.max_content_length と discovery.zen.ping_timeout の値を調整できますか?
いいえ、これらのパラメーターは設定できません。Alibaba Cloud Elasticsearch が提供するパラメーターのみを設定できます。詳細については、「YML パラメーターの設定」をご参照ください。
discovery.zen.ping_timeout、discovery.zen.fd.ping_timeout、discovery.zen.fd.ping_interval、および discovery.zen.fd.ping_retries パラメーターは通常、調整する必要はありません。
ES インスタンスの VPC を切り替えることはできますか?
ES インスタンスの VPC を切り替えることはできません。回避策として、希望の VPC で新しい ES インスタンスを購入し、データを移行してから、元のインスタンスをリリースすることができます。
ES インスタンスのディスクタイプを変更すると、既存のデータは失われますか?
いいえ、既存のデータは失われません。ただし、アップグレード中にクラスターに書き込まれた新しいデータは失われる可能性があります。アップグレードはオフピーク時に行うか、クラスターへのデータ書き込みを停止した後に行うことを推奨します。詳細については、「クラスターのアップグレード」をご参照ください。
クラスターのアップグレード時に「cluster unhealthy」というプロンプトが表示されますが、クラスターのステータスは Green と確認されています。どうすればよいですか?
この問題は、クラスター内の一部のインデックスがクローズ状態にある場合に発生する可能性があります。POST /<index_name>/_open コマンドを実行して、一時的にインデックスを開くことができます。詳細については、「クラスターのアップグレード」をご参照ください。
ES はデータ移行を避けるために CPU を直接アップグレードできますか?
いいえ、できません。CPU のアップグレードまたはダウングレードは、ブルーグリーン変更をトリガーし、古いノードから新しいノードにデータを移行し、ノードの IP アドレスを変更します。
コールドデータノードをダウングレードできないのはなぜですか?
特定の条件が満たされている場合にのみ、クラスターをダウングレードできます。たとえば、選択したターゲット仕様の CPU とメモリは、現在の仕様の少なくとも半分である必要があり、ノード仕様を 1 コアと 2 GiB のメモリ、2 コアと 2 GiB のメモリ、4 コアと 4 GiB のメモリ、または 2 コアと 4 GiB のメモリにダウングレードすることはできません。詳細については、「クラスターのダウングレード」をご参照ください。
設定ダウングレードの条件が満たされない場合は、新しいインスタンスを作成し、データを移行してから、元のクラスターをリリースすることができます。詳細については、「データ移行ソリューションの選択」をご参照ください。
クラスターデータノードのスケールイン時に、「This operation will cause the current cluster resources (Disk/CPU/Memory) to be insufficient or cause shard allocation abnormalities」というエラーが報告されます。どうすればよいですか?
考えられる原因 | ソリューション |
クラスターリソースの不足。 スケールイン操作後、クラスターには現在のシステムデータまたは負荷を処理するためのディスク、メモリ、CPU などのリソースが不足しています。 |
|
シャード割り当てエラー。 Lucene の原則に基づき、Elasticsearch は同じインデックスの複数のレプリカシャードを単一のデータノードに割り当てません。その結果、スケールイン操作によってインデックスのレプリカ数が残りのデータノード数以上になると、シャード割り当てエラーが発生します。 |
|
クラスターデータノードのスケールイン時に、「The cluster is currently in an abnormal state or has unfinished tasks」というエラーが報告されます。どうすればよいですか?
クラスター診断機能を使用してクラスターを診断し、提供された診断結果と提案に基づいて問題をトラブルシューティングできます。詳細については、「Elasticsearch クラスターの診断を実行する」をご参照ください。
クラスターデータノードのスケールイン時に、「The number of reserved nodes must be greater than 2」というエラーが報告されます。どうすればよいですか?
クラスターの信頼性と安定性を確保するため、スケールイン操作後には少なくとも 2 つのデータノードが残っている必要があります。マルチゾーンクラスターの場合、各ゾーンも少なくとも 2 つのデータノードを保持する必要があり、すべてのゾーンで残りのデータノード数が同じである必要があります。スケールイン計画がこれらの要件を満たさない場合は、削除するノード数を調整するか、クラスターをアップグレードする必要があります。
クラスターデータノードのスケールイン時に、「The current ES cluster configuration does not support this operation」というエラーが報告されます。どうすればよいですか?
GET _cluster/settings コマンドを実行してクラスター設定を表示し、データ割り当てを許可しない設定があるかどうかを確認します:"cluster.routing.allocation.enable" : "none"。この設定が存在する場合は、一時的に "cluster.routing.allocation.enable" : "all" に変更できます。この設定が他の操作に影響する場合は、スケールインが完了した後に元に戻す必要があります。
auto_expand_replicas インデックスを使用すると、データ移行またはノードのスケールインが失敗します。どうすればよいですか?
原因
この問題は、X-Pack の権限管理機能を使用している場合に発生する可能性があります。以前のバージョンでは、対応する .security インデックスはデフォルトで
"index.auto_expand_replicas" : "0-all"設定を使用しており、これによりデータ移行またはノードのスケールインが失敗します。ソリューション
インデックス設定を表示します。
GET .security/_settings次の出力が返されます:
{ ".security-6" : { "settings" : { "index" : { "number_of_shards" : "1", "auto_expand_replicas" : "0-all", "provided_name" : ".security-6", "format" : "6", "creation_date" : "1555142250367", "priority" : "1000", "number_of_replicas" : "9", "uuid" : "9t2hotc7S5OpPuKEIJ****", "version" : { "created" : "6070099" } } } } }次のいずれかの方法で設定を変更します:
方法 1
PUT .security/_settings { "index" : { "auto_expand_replicas" : "0-1" } }方法 2
PUT .security/_settings { "index" : { "auto_expand_replicas" : "false", "number_of_replicas" : "1" } }重要number_of_replicas パラメーターは、インデックスのレプリカ数を指定します。このパラメーターは必要に応じて設定できます。値が 1 以上で、利用可能なデータノード数以下であることを確認してください。
ES のキャッシュをクリアするにはどうすればよいですか?
Kibana コンソールにログインして、次のコマンドを実行できます:
特定のインデックスのキャッシュをクリアする
POST /<index_name>/_cache/clear?fielddata=trueすべてのキャッシュをクリアする
POST /_cache/clear
ES クラスターのゾーンを変更するにはどうすればよいですか?
手順については、「ゾーン内の Elasticsearch ノードの移行または Elasticsearch クラスターのデプロイメントモードのアップグレード」をご参照ください。
ES クラスターは独立したディスク拡張をサポートしていますか?
はい、サポートしています。詳細については、「クラスターのアップグレード」をご参照ください。
スケールアウトはクラスターのローリングリスタートをトリガーします。この操作はオフピーク時に実行することを推奨します。
ES は JVM パラメーターの変更をサポートしていますか?
Alibaba Cloud Elasticsearch は、公式の Elasticsearch が推奨する JVM パラメーター設定を使用しています。これらの設定は変更できません。デフォルトでは、ヒープサイズはクラスターメモリの半分に設定され、最大 32 GB です。詳細については、「ヒープサイズ設定」をご参照ください。
プラグイン、アナライザー、シノニムに関する問題
IK アナライザーを使用する際、辞書の内容をカスタマイズおよび拡張するにはどうすればよいですか?
Alibaba Cloud ES の IK 分析プラグインのコールドおよびホットアップデート機能を使用して、辞書に単語を追加または削除できます。詳細については、「analysis-ik プラグインの使用」をご参照ください。
IK 分析プラグインの使用中に「ik startOffset」エラーが報告されます。どうすればよいですか?
このエラーは ES 6.7 のバグが原因です。解決するには、クラスターを再起動してください。詳細については、「インスタンスまたはノードの再起動」をご参照ください。
ローカルの IK 辞書ファイルが失われた場合、クラスター管理ページから復元できますか?
いいえ、できません。クラスター管理ページでは辞書ファイルの削除または更新のみが可能です。公式のメイン辞書とストップワード辞書ファイルをダウンロードし、ファイル内のメイントークンとストップワードをシステム辞書の名詞に置き換えてから、ファイルを再アップロードすることを推奨します。
IK アナライザーの辞書を更新した後、新しい辞書を既存のデータに有効にするにはどうすればよいですか?
インデックスの再作成操作を実行する必要があります。デフォルトでは、更新された IK アナライザーの辞書は新しいデータにのみ適用されます。インデックス内の既存のデータに辞書の更新を適用するには、インデックスの再作成操作を実行する必要があります。詳細については、「インデックス再作成ホワイトリストの設定」をご参照ください。
FullGC に標準値はありますか?
FullGC (ヒープ領域全体をクリーンアップする) イベントが問題であるかどうかを判断するには、ビジネスのレイテンシを分析し、過去と現在の状況を比較する必要があります。CMS コレクターは、メモリ使用率が 75% に達するとガベージコレクションを開始します。これにより、突然のトラフィックスパイクを処理するための十分なヘッドルームが確保されます。
未使用のプラグインをアンインストールできますか?
一部のプラグインのみアンインストールできます。Elasticsearch クラスターのプラグインページの組み込みプラグインタブで、どのプラグインがアンインストール可能かを確認できます。操作列に「削除」が表示されている場合、そのプラグインはアンインストール可能です。詳細については、「組み込みプラグインのインストールと削除」をご参照ください。
Alibaba Cloud ES IK 分析プラグインの辞書とオープンソースの IK プラグインの辞書は同じですか?
はい、同じです。Alibaba Cloud ES IK 分析プラグインの組み込み辞書は、対応するバージョンのオープンソース IK 分析プラグインの辞書と同じです。詳細については、「IK Analysis for Elasticsearch」をご参照ください。
カスタムプラグインは外部ネットワークにアクセスできますか? (例:GitHub から辞書ファイルを読み取る)
カスタムプラグインは外部ネットワークにアクセスできません。外部ファイルにアクセスするには、OSS にアップロードしてそこから読み取ることができます。
カスタムプラグインはホットアップデートをサポートしていますか?
いいえ、サポートしていません。ただし、IK 辞書と同じホットアップデート方法を使用するようにプラグインを設定することで、この機能を有効にできます。詳細については、「IK Analysis for Elasticsearch」をご参照ください。
analysis-aliws アナライザーはどのように設定され、ファイル形式は何ですか?
詳細については、「AliNLP アナライザープラグイン (analysis-aliws) の使用」をご参照ください。
辞書ファイルの要件は次のとおりです:
ファイル名:aliws_ext_dict.txt である必要があります。
ファイル形式:UTF-8 である必要があります。
内容:1 行に 1 単語で、先頭または末尾に空白を含まないようにします。UNIX または Linux の改行 (\n) を使用します。ファイルが Windows で生成された場合は、アップロードする前に Linux マシンで dos2unix ツールを使用して辞書ファイルを変換します。
ES シノニム、IK トークン化、AliNLP トークン化の違いは何ですか?
トークナイザーの種類 | 使用方法 | 機能の説明 | サポートされるファイルタイプ | トークナイザまたはアナライザ |
シノニム | クラスター設定モジュールでシノニムファイルをアップロードして使用します。 | ファイルに複数のシノニムを記述します。そのうちの 1 つをクエリすると、他のものも表示されます。 | UTF-8 エンコードの TXT ファイル | カスタム |
IK トークン化 | analysis-ik プラグイン経由。 | システムは main.dic ファイルに基づいて段落を分割します。段落から分割された 1 つ以上の単語を含むクエリを送信すると、システムはクエリ結果で段落全体を返します。システムは stop.dic ストップワードファイルも使用します。段落が分割された後、stop.dic ファイルで見つかった単語はフィルタリングされます。これらの辞書ファイルは公式ドキュメントで確認できます。 | UTF-8 エンコードの DIC ファイル | トークナイザー:
|
AliNLP トークン化 | analysis-aliws プラグイン経由。 | IK トークン化に似ていますが、別のストップワードファイルは含まれません。ストップワードはメイン辞書ファイル aliws_ext_dict.txt に統合されており、辞書は公開されていません。カスタムストップワードは現在サポートされていません。 | ファイル名は aliws_ext_dict.txt、UTF-8 エンコードである必要があります |
|
ES IK トークン化モードはどこで設定されますか?
analysis-ik プラグインは、Alibaba Cloud ES が提供する組み込みの IK アナライザーであり、削除できません。標準またはローリングアップデート方法を使用して、プラグインの組み込みメイン辞書とストップワードリストを更新できます。その後、インデックスのマッピングを設定する際に、更新された辞書とストップワードリストを使用できます。analysis-ik プラグインの使用方法の詳細については、「analysis-ik プラグインの使用」をご参照ください。
Alibaba Cloud ES がサポートする組み込みの中国語アナライザーは何ですか?
Alibaba Cloud ES は、analysis-ik と analysis-aliws の 2 つの組み込み中国語アナライザーをサポートしています。対応する辞書を設定した後、これらのアナライザーを使用できます。
OSS 経由で辞書ファイルをホットアップデートする際、OSS 側の辞書ファイルの内容が変更された場合、ES 側は自動的に更新されますか?
いいえ、されません。Alibaba Cloud ES は現在、OSS からの辞書ファイルの自動ホットアップデートをサポートしていません。OSS ファイルの内容が変更された後、変更を有効にするには手動で再設定してアップロードする必要があります。すでに IK トークン化、シノニム、または AliNLP トークン化が設定されているインデックスの場合、辞書の更新は新しいデータにのみ適用されます。すべてのデータに変更を適用するには、インデックスを再作成する必要があります。
Alibaba Cloud ES で使用される IK アナライザーはリモート辞書をサポートしていますか?
いいえ、サポートしていません。Alibaba Cloud ES が提供する IK アナライザーでは、辞書をアップロードまたは更新できます。詳細については、「IK 分析プラグイン (analysis-ik) の使用」をご参照ください。ただし、リモート辞書や IKAnalyzer.cfg.xml などの関連設定はサポートしていません。
Alibaba Cloud ES 7.10 インスタンスにベクトル検索プラグイン (aliyun-knn) をインストールするにはどうすればよいですか?
Alibaba Cloud ES 7.10 インスタンスでは、aliyun-knn プラグインは組み込みの apack プラグインに統合されています。したがって、aliyun-knn プラグインをインストールまたはアンインストールするには、apack プラグインで操作を実行する必要があります。詳細については、「apack プラグインの物理レプリケーション機能の使用」をご参照ください。他のバージョンのインストール手順については、「ベクトル検索プラグイン (aliyun-knn) の使用」をご参照ください。
インスタンスのマイナーエンジンバージョンが 1.4.0 以降の場合、apack プラグインはすでに最新バージョンであり、更新する必要はありません。GET _cat/plugins?v コマンドを実行してプラグインのバージョンを取得できます。
プラグインをインストールした後の再起動はクラスターサービスに影響しますか?
クラスター全体の負荷が低く、インデックスにレプリカシャードがある場合、通常は再起動中もサービスは利用可能です。ただし、一部のシナリオでは、再起動中にアクセスタイムアウトが発生する可能性があります。たとえば、強制再起動中に高い同時実行性がある場合、クラスターの負荷が非常に高い場合、インデックスにレプリカシャードがない場合、または再起動中に大量の書き込みおよびクエリ操作がある場合などです。クライアントでリトライメカニズムを実装し、オフピーク時に操作を実行することを推奨します。
ログに関する問題
ES は .security ログの保持期間の設定をサポートしていますか?
はい、インデックスライフサイクル管理 (ILM) を使用してこれを設定できます。詳細な手順については、「インデックスライフサイクルを使用して Heartbeat データを管理する」をご参照ください。
.security インデックスには、elastic アカウントに関連する情報が保存されます。このインデックスを定期的に削除すると、ES にログインできなくなる可能性があります。
ES ログをローカルに保存するにはどうすればよいですか?
ListSearchLog API を呼び出すことができます。詳細については、「ListSearchLog」をご参照ください。
ES のクエリおよび更新ログが表示されません。どうすればよいですか?
スローログを設定し、ログエントリのタイムスタンプの精度を下げることができます。詳細については、「リファレンス」をご参照ください。
ES インスタンスのスローログを設定および表示するにはどうすればよいですか?
デフォルトでは、ES インスタンスのスローログは 5〜10 秒かかる読み取りおよび書き込み操作を記録します。インスタンスのKibana コンソールにログインし、コマンドを実行してログ記録の時間しきい値を下げることができます。これにより、より多くのログをキャプチャできます。詳細については、「参照ドキュメント」をご参照ください。
スローログの形式の変更はサポートされていません。
ES インスタンスからスローログを定期的にプログラムで取得するにはどうすればよいですか?
ListSearchLog API 操作を呼び出して、ES インスタンスから定期的にスローログを取得できます。詳細については、「ListSearchLog」をご参照ください。
どのクライアントが ES インスタンスを使用しているかを確認するにはどうすればよいですか?
ES インスタンスのアクセスログまたは監査ログを表示できます:
追加、削除、変更、クエリなどのインスタンス上の操作に関する情報を表示するには、監査ログを有効にする必要があります。
アクセスログを有効にして、クラスターノードとその IP アドレス、クライアント IP アドレス、bodySize、リクエスト内容、リクエスト時間、uri などの情報を表示します。
制限、注意事項、およびアクセスログと監査ログの有効化の詳細については、「ログのクエリ」をご参照ください。
データのバックアップと復元に関する問題
ES インスタンスのスナップショットを異なるバージョンのインスタンスに復元できますか?
自動バックアップの場合、スナップショットは元のインスタンスにのみ復元できます。または、クラスター間のスナップショット復元機能を使用できます。詳細については、「自動バックアップと復元」および「クラスター間 OSS リポジトリの設定」をご参照ください。
手動スナップショットの場合、スナップショットから他のクラスターに直接データを復元できます。互換性の問題を避けるため、元のクラスターと同じバージョンの宛先クラスターを使用することを推奨します。詳細については、「手動バックアップと復元」をご参照ください。
Alibaba Cloud ES コンソールでバージョンアップグレードのために ES データをバックアップする際に、不健全なクラスター状態を解決するにはどうすればよいですか?
ES クラスターのステータスが不健全な場合、スナップショットバックアップをトリガーできません。まずクラスターのステータスを緑色に復元することを推奨します。
自動バックアップを有効にしましたが、OSS を設定していません。これはバックアップが失敗したことを意味しますか?
Alibaba Cloud ES はデフォルトで OSS バケットを提供します。自動バックアップからデータを取得するには、Kibana コンソールにログインし、Kibana で GET _snapshot/aliyun_auto_snapshot/_all コマンドを実行します。
スナップショット経由でデータを移行 (復元) する際、宛先でシャードの異常が表示されます。シャード回復コマンド POST /_cluster/reroute?retry_failed=true を実行しても成功せず、対応するインデックスに異常が表示されます。どうすればよいですか?
スナップショットからデータを移行 (復元) する際、次の問題が発生する可能性があります:
問題のあるインデックスを削除し、_restore API を呼び出して復元します。復元コマンドに max_restore_bytes_per_sec パラメーターを追加して、ノードの回復速度を制限します。デフォルト値は 40 MB/秒です。
POST /_snapshot/aliyun_snapshot_from_instanceId/es-cn-instanceId_datetime/_restore
{
"indices": "myIndex",
"settings": {
"max_restore_bytes_per_sec" : "150mb"
}
}次のような他のパラメーターも指定できます:
compress:データ圧縮を有効にするかどうかを指定します。デフォルト値は true です。
max_snapshot_bytes_per_sec:各ノードのスナップショットレートを指定します。デフォルト値は 40 MB/秒です。
ES のデータをローカルマシンにエクスポートできますか?
はい。Alibaba Cloud ES はデータバックアップ機能を提供しています。詳細については、「データバックアップ」をご参照ください。データを OSS にバックアップし、「オブジェクトのダウンロード」の指示に従ってローカルマシンにダウンロードできます。
クラスター間でスナップショットを復元するにはどうすればよいですか?
共有 OSS リポジトリを使用してデータを復元できます。操作、条件、および注意事項の詳細については、「共有 OSS リポジトリの設定」をご参照ください。同じ Alibaba Cloud アカウントに属し、異なるリージョンにあるクラスター間でデータを移行したい場合は、「スナップショットのバックアップと回復コマンド」を使用できます。利用可能なデータ移行ソリューションの詳細については、「データ移行ソリューションの選択」をご参照ください。
Alibaba Cloud ES はどのようなデータバックアップソリューションを提供していますか?
Alibaba Cloud ES のデータバックアップソリューション、その使用シナリオ、および制限事項については、「データバックアップ」をご参照ください。
クラスターのモニタリングとアラートに関する問題
X-Pack Watcher アラートを設定するにはどうすればよいですか?
DingTalk または WeCom ロボットを設定して X-Pack Watcher アラートを受信する方法については、「DingTalk ロボットを設定して X-Pack Watcher アラートを受信する」および「WeCom ロボットを設定して X-Pack Watcher アラートを受信する」をご参照ください。
Alibaba Cloud ES の X-Pack Watcher を使用すると、特定の条件が満たされたときに操作を実行できます。たとえば、ログインデックスにエラーログが表示されたときに自動的に DingTalk メッセージを送信するトリガーを設定できます。X-Pack Watcher は ES ベースのモニタリングおよびアラートサービスです。
「GC memory allocation failed」というアラートが表示されます。どうすればよいですか?
考えられる原因には、高いクラスター負荷、高い秒間クエリ数 (QPS)、または大量のデータ書き込みがあります。次のように問題をトラブルシューティングして解決します:
高いクラスター負荷:詳細については、「高いクラスターディスク使用率と読み取り専用の問題のトラブルシューティング」をご参照ください。
高い QPS または大量の書き込みデータ:クラスターにクラスター速度制限プラグイン (aliyun-qos) をインストールして、読み書きの速度制限を実装できます。詳細については、「クラスター速度制限プラグイン (aliyun-qos) の使用」をご参照ください。
説明イメージ検索の場合、aliyun-knn プラグインをインストールし、クラスターとインデックスを計画できます。詳細については、「aliyun-knn プラグインの使用」をご参照ください。
クラスターのステータスメトリック値は何を意味しますか?
ClusterStatus(value) メトリックは、クラスターの健全性を示します。値 0.00 は、クラスターが健全であることを示します。次の表に、ClusterStatus(value) メトリックの値を示します。詳細については、「メトリックの表示と例外の処理」をご参照ください。
値 | 意味 |
0.00 | クラスターのステータスは正常です。 |
1.00 | クラスターは準健康状態です。現在のクラスターの 1 つ以上のインデックスのレプリカシャードが失われていますが、継続的な使用には影響しません。 |
2.00 | クラスターのステータスは異常です。現在のクラスターの 1 つ以上のインデックスのプライマリシャードが失われている (未割り当て) ため、クラスターの正常な使用に影響があり、できるだけ早く修正する必要があります。 |
ES のディスク使用率を表示するにはどうすればよいですか?
コンソールまたは Kibana の X-Pack モニタリングで ES のディスク使用率を表示できます。詳細については、「メトリックの表示と例外の処理」および「モニタリングログの設定」をご参照ください。
CMS GC 中に「promotion failed」エラーが報告された場合はどうすればよいですか?
Alibaba Cloud Elasticsearch で Concurrent Mark Sweep (CMS) ガベージコレクターを使用している場合、「promotion failed」エラーが発生することがあります。このエラーは通常、旧世代領域が不足していることを示し、オブジェクトが旧世代領域に昇格できなくなります。この CMS ガベージコレクションの問題が発生した場合は、次の解決策を検討してください:
モニタリングとログ分析:
ガベージコレクション (GC) ログを表示して詳細な情報を取得します。ログを分析して、頻繁な CMS GC または Full GC 操作が発生しているかどうかを判断し、
CMS GC promotion failedエラーが旧世代領域の不足によって引き起こされているかどうかを確認します。Alibaba Cloud Elasticsearch ログクエリページにログインします。
promotion failedを含むログレコードを検索して、問題の原因をよりよく理解します。
ヒープメモリサイズとガベージコレクター設定の調整:
Elasticsearch のバージョンが 6.7.0 以降で、データノードのメモリが 32 GB 以上の場合は、ガベージコレクターを G1 に切り替えてガベージコレクションのパフォーマンスを最適化することを推奨します。
クラスターのリソース使用率とビジネス要件に基づいて、インスタンスのメモリを増やすかどうかを評価します。
チューニングの推奨事項:
メモリ関連の問題が解決しない場合は、インデックスデータ全体の量、クエリ負荷、およびクラスターリソース設定を評価する必要がある場合があります。必要に応じて、Alibaba Cloud の技術サポートに連絡して、専門的なチューニングガイダンスを受けてください。
基本モニタリングでデータが表示されない場合はどうすればよいですか?
クラスターアクセスに関する問題
クライアントを使用して Alibaba Cloud ES クラスターに接続するにはどうすればよいですか?また、オープンソースの ES との違いは何ですか?
内部またはパブリックエンドポイントを使用して Alibaba Cloud ES クラスターに接続できます。このエンドポイントは、オープンソースの Elasticsearch クラスターのクラスターエンドポイントに相当します。詳細については、「クライアントを使用して Alibaba Cloud Elasticsearch クラスターにアクセスする」をご参照ください。
クライアントで ES インスタンスにアクセスする際に Basic 認証 (セキュリティ認証) を無効にできますか?
いいえ、できません。ES インスタンスには X-Pack 機能が含まれており、Kibana の認証メカニズムとして Basic 認証を提供しています。したがって、Basic 認証を無効にすることはできません。
Alibaba Cloud ECS インスタンスと ES インスタンスが同じ VPC 内で異なるゾーンにある場合、ECS インスタンスは内部ネットワーク経由で ES インスタンスにアクセスできますか?
はい、できます。同じ VPC 内のインスタンスは、ゾーンに関係なく、内部ネットワーク経由で相互にアクセスできます。
ES のパブリックまたはプライベートアクセスホワイトリストを設定するにはどうすればよいですか?
インターネットまたは VPC 経由で Alibaba Cloud Elasticsearch インスタンスにアクセスするには、デバイスの IP アドレスをインスタンスのパブリックまたはプライベート IP アドレスホワイトリストに追加する必要があります。詳細については、「インスタンスのパブリックまたはプライベート IP アドレスホワイトリストの設定」をご参照ください。IP アドレスホワイトリストを設定する前に、次の点に注意してください:
パブリックアクセスホワイトリストを設定する場合、まずパブリックエンドポイントスイッチを有効にする必要があります。これはデフォルトで無効になっています。
ホワイトリストには最大 50 個の IP アドレスまたは IP アドレス範囲を追加できます。
ホワイトリストに IP アドレス範囲を追加する場合、入力する IP アドレスは、マスクが適用された後のサブネットの最初の IP アドレスである必要があります。
0.0.0.0/0 を他の特定の IP アドレスまたは IP アドレス範囲と同時にホワイトリストに追加することはできません。この操作はエラーを引き起こします。テスト目的で 0.0.0.0/0 を追加するには、単独でホワイトリストに追加する必要があります。
インターネットから ES インスタンスに接続するにはどうすればよいですか?
パブリックエンドポイントを使用してインターネット経由で Elasticsearch インスタンスにアクセスできます。ただし、まずインスタンスのパブリック IP アドレスホワイトリストを設定する必要があります。詳細については、「インスタンスのパブリックまたはプライベート IP アドレスホワイトリストの設定」をご参照ください。接続するには、エンドポイント、ユーザー名、パスワードなどのパラメーターを提供する必要があります。詳細については、「クライアントを使用して Alibaba Cloud Elasticsearch クラスターにアクセスする」をご参照ください。
ES にアクセスできません:Failed to establish a new connection: [Errno 61] Connection refused
考えられる原因と解決策は次のとおりです。
考えられる原因 | ソリューション |
パブリックネットワークアクセスが利用できない。 | パブリックドメイン名を使用して ES クラスターにアクセスする場合は、次の手順で問題をトラブルシューティングします:
|
プライベートネットワークアクセスが利用できない。 | プライベートドメイン名を使用して ES クラスターにアクセスする場合は、次の手順で問題をトラブルシューティングします:
|
クラスターが不健全である。 | ネットワーク接続が正常であるにもかかわらず ES クラスターにアクセスできない場合は、クラスターのステータスを確認し、結果に基づいて問題を解決します:
|
パスワードをリセットすると ES へのアクセスに影響しますか?
Elasticsearch コンソールで Elasticsearch クラスターの elastic アカウントのパスワードをリセットした場合、そのアカウントでのクラスターへのアクセスのみが影響を受けます。他のアカウントでのアクセスは影響を受けません。カスタムアカウントを使用して Elasticsearch クラスターにアクセスすることを推奨します。カスタムアカウントには、必要な権限を持つロールが割り当てられている必要があります。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用してアクセスの制御を実装する」をご参照ください。
パスワードを変更してもインスタンスの再起動はトリガーされません。
Elasticsearch-Head プラグインバージョン 5.0.0 が Alibaba Cloud ES (全バージョン) にアクセスできません。どうすればよいですか?
この問題は通常、Chrome のクロスドメイン制限が原因です。次の方法は、Mac 上の Chrome でこの問題を解決します。他のオペレーティングシステムについては、Chrome のクロスドメイン設定のドキュメントをご参照ください。
空のフォルダを作成します。
ターミナルを開き、次のコマンドを入力します。
open -n /Applications/Google\ Chrome.app/ --args --disable-web-security --user-data-dir=path_to_new_empty_folder
Elasticsearch-Head プラグインは、Elasticsearch バージョン 5.x 以降ではメンテナンスされていません。Cerebro を使用して Alibaba Cloud ES クラスターにアクセスすることを推奨します。詳細については、「Cerebro を使用してクラスターに接続する」をご参照ください。
インデックス関連の問題
インデックスを閉じるにはどうすればよいですか?
ES インデックスが閉じられると、クエリや書き込みはサポートされなくなります。
POST /<index_name>/_open #インデックスのステータスをオープンに設定
POST /<index_name>/_close #インデックスのステータスをクローズに設定