Monstache は、MongoDB の oplog を追跡することで、ApsaraDB for MongoDB から Alibaba Cloud Elasticsearch へリアルタイムでデータを同期します。このチュートリアルでは、映画のデータセットを使用して、フル同期、増分同期、および Kibana ベースのデータ分析を実演し、完全なセットアップ手順を説明します。
Monstache は、MongoDB の oplog に基づいてリアルタイムでデータを同期し、サブスクライブします。MongoDB の change stream と集約パイプラインをサポートし、MongoDB データベースと新しいバージョンの Elasticsearch クラスター間のデータ同期を可能にします。Monstache の機能に関する詳細については、「特徴」をご参照ください。
前提条件
開始する前に、以下が揃っていることを確認してください。
Elastic Compute Service (ECS) インスタンス、ApsaraDB for MongoDB インスタンス、および Elasticsearch クラスターを作成する権限を持つ Alibaba Cloud アカウント
Linux のコマンドライン操作に関する基本的な知識
仕組み
Monstache は、MongoDB の oplog をイベントソースとして使用します。MongoDB でのすべての挿入、更新、削除は oplog に記録されます。Monstache は oplog を追跡し、変更をほぼリアルタイムで Elasticsearch に伝播します。oplog はレプリカセットの機能であるため、MongoDB インスタンスはレプリカセットインスタンスまたはシャードクラスターインスタンスである必要があります。スタンドアロンインスタンスはサポートされていません。
ステップ 1:必要なリソースの作成
以下のリソースを同じ VPC (仮想プライベートクラウド) 内に作成します。3つすべてを同じ VPC に配置することで、データが内部ネットワーク経由で安全かつ高速に転送されることが保証されます。
Elasticsearch クラスターの作成。作成時に、[自動インデックス作成] 機能を有効にします。このチュートリアルでは、Elasticsearch V6.7 Standard Edition クラスターを使用します。詳細については、「Alibaba Cloud Elasticsearch クラスターの作成」および「YML ファイルの設定」をご参照ください。
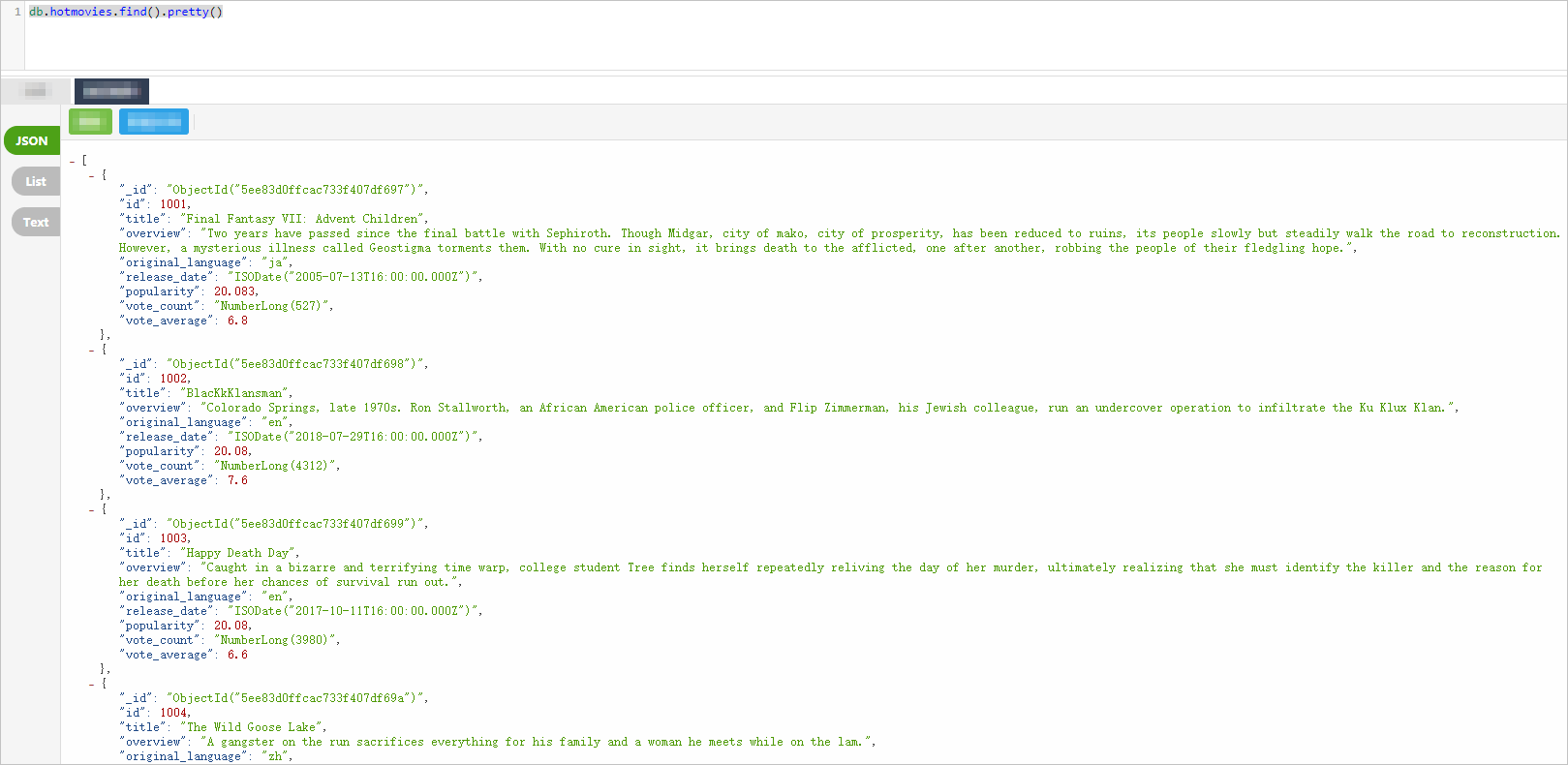
ApsaraDB for MongoDB レプリカセットインスタンスの作成。このチュートリアルでは、ApsaraDB for MongoDB V4.2 レプリカセットインスタンスを使用します。作成後にテストデータを準備します。以下の図は、例として使用する映画データセットの一部を示しています。詳細については、「レプリカセットインスタンスのクイックスタート」をご参照ください。
重要ApsaraDB for MongoDB インスタンスは、レプリカセットインスタンスまたはシャードクラスターインスタンスである必要があります。Monstache はイベントソースとして oplog を使用しますが、これはこれらのインスタンスタイプでのみ利用可能です。
Elastic Compute Service (ECS) インスタンスの作成。ECS インスタンスは Monstache をホストし、Linux を実行している必要があります。詳細については、「ウィザードを使用したインスタンスの作成」をご参照ください。
インストールする Monstache のバージョンが、ご利用の ApsaraDB for MongoDB インスタンスおよび Elasticsearch クラスターのバージョンと互換性があることを確認する必要があります。バージョンの互換性情報については、「Monstache のバージョン」をご参照ください。
ステップ 2:Monstache のインストール
ソースからビルドして、ECS インスタンスに Monstache をインストールします。Monstache をインストールする前に、Go の環境変数が設定されていることを確認してください。
ECS インスタンスにログインします。詳細については、「パスワードまたはキーを使用して Linux インスタンスに接続」をご参照ください。
説明この例では、一般 (非 root) ユーザーを使用します。
Go をダウンロードして展開します。
wget https://dl.google.com/go/go1.14.4.linux-amd64.tar.gz tar -xzf go1.14.4.linux-amd64.tar.gzGo の環境変数を設定します。
~/.bash_profileを開きます。vim ~/.bash_profile以下の行を追加します。
GOPROXYは Alibaba Cloud の Go モジュールプロキシを指しており、ダウンロード速度を向上させます。export GOROOT=/home/test1/go export GOPATH=/home/go/ export PATH=$PATH:$GOROOT/bin:$GOPATH/bin export GOPROXY=https://mirrors.aliyun.com/goproxy/変更を適用します。
source ~/.bash_profileMonstache リポジトリをクローンします。
説明エラー
git: command not foundが表示された場合は、まず git をインストールしてください:sudo yum install -y git。git clone https://github.com/rwynn/monstache.gitrel5 ブランチに切り替えてインストールします。
cd monstache git checkout rel5 sudo go installインストールを検証します。
monstache -v期待される出力:
5.5.5
ステップ 3:データ同期の設定と開始
Monstache は設定に TOML を使用します。このチュートリアルでは、mydb データベース内の hotmovies と col コレクションからデータを同期します。
monstache ディレクトリに設定ファイルを作成します。
vim config.toml以下の設定を追加します。プレースホルダーの値を実際のエンドポイントと認証情報に置き換えてください。
# 接続設定 mongo-url = "mongodb://<your_mongodb_user>:<your_mongodb_password>@dds-bp1aadcc629******.mongodb.rds.aliyuncs.com:3717" elasticsearch-urls = ["http://es-cn-mp91kzb8m00******.elasticsearch.aliyuncs.com:9200"] # 同期するコレクション (起動時にフル同期し、その後 oplog を追跡) direct-read-namespaces = ["mydb.hotmovies","mydb.col"] # oplog 追跡の代わりに MongoDB の change stream を使用する場合 (MongoDB 3.6+ が必要): #change-stream-namespaces = ["mydb.col"] # 特定のコレクションにフィルター (oplog リスナーのみ、フル同期はトリガーしない): #namespace-regex = '^mydb\.col$' # Elasticsearch の認証情報 # 本番環境では、デフォルトの elastic アカウントの代わりに専用のアカウントを作成してください。 # アカウントには必要な権限のみを割り当ててください。「Elasticsearch X-Pack が提供する RBAC メカニズムを使用して # アクセス制御を実装する」をご参照ください。 elasticsearch-user = "elastic" elasticsearch-password = "<your_es_password>" # Elasticsearch にドキュメントをプッシュする同時 Go スレッド数 elasticsearch-max-conns = 4 # コレクションとデータベースの削除を Elasticsearch に伝播する dropped-collections = true dropped-databases = true # 同期の進捗を monstache.monstache に保存し、再起動後に同期を再開できるようにする resume = true resume-strategy = 0 # デバッグロギングを有効にする (Elasticsearch へのすべてのリクエストをログに記録) verbose = true # 高可用性モード: 同じ cluster-name を共有するプロセスが協調動作する cluster-name = 'es-cn-mp91kzb8m00******' # インデックスマッピング: デフォルトの database.collection インデックス名をオーバーライドする [[mapping]] namespace = "mydb.hotmovies" index = "hotmovies" type = "movies" [[mapping]] namespace = "mydb.col" index = "mydbcol" type = "collection"主要なパラメーター:
パラメーター 説明 mongo-urlご利用の ApsaraDB for MongoDB インスタンスのプライマリノードの接続文字列。ApsaraDB for MongoDB コンソールのインスタンス詳細ページから取得します。接続する前に、ECS インスタンスのプライベート IP アドレスを MongoDB インスタンスのホワイトリストに追加してください。「シャードクラスターインスタンスのホワイトリストを設定」をご参照ください。 elasticsearch-urlsご利用の Elasticsearch クラスターの内部エンドポイントを http://<endpoint>:9200のフォーマットで指定します。クラスターの [基本情報] ページから取得します。「クラスターの基本情報を表示」をご参照ください。direct-read-namespaces起動時に MongoDB からコピーするコレクション (フル同期) を database.collectionとして指定します。「direct-read-namespaces」をご参照ください。change-stream-namespacesoplog 追跡の代わりに MongoDB の change stream を使用します。設定すると、oplog 追跡は無効になります。MongoDB 3.6+ が必要です。「change-stream-namespaces」をご参照ください。 namespace-regexMonstache がリッスンするコレクションをフィルターするための正規表現。これは変更イベントリスナーに対するフィルターのみであり、フル同期をトリガーしません。 elasticsearch-userElasticsearch 認証用のユーザー名。デフォルトは elasticです。elasticsearch-passwordElasticsearch ユーザーのパスワード。忘れた場合はリセットしてください。「Elasticsearch クラスターのアクセスパスワードをリセット」をご参照ください。 elasticsearch-max-connsElasticsearch に書き込む同時 Go スレッドの数。デフォルトは 4です。dropped-collectionstrue(デフォルト) の場合、MongoDB コレクションが削除されると、マッピングされた Elasticsearch インデックスを削除します。dropped-databasestrue(デフォルト) の場合、MongoDB データベースが削除されると、マッピングされた Elasticsearch インデックスを削除します。resumetrueの場合、oplog のタイムスタンプをmonstache.monstacheに保存し、再起動後にデータ損失なく同期を再開できるようにします。cluster-nameが設定されている場合、自動的にtrueに設定されます。「resume」をご参照ください。resume-strategy再開戦略 ( resumeがtrueの場合のみ有効)。0はタイムスタンプを使用します。「resume-strategy」をご参照ください。verbosetrueの場合、Elasticsearch のリクエストトレースを含むデバッグロギングを有効にします。デフォルトはfalseです。cluster-name高可用性モードを有効にします。同じ cluster-nameを共有する Monstache プロセスが互いに協調します。「cluster-name」をご参照ください。mappingデフォルトのインデックス名 ( database.collection) をオーバーライドします。「インデックスマッピング」をご参照ください。説明Monstache はさらに多くの設定パラメーターをサポートしています。スクリプトベースの変換、GridFS のインデックス作成、複雑なフィルタリングなどの高度なシナリオについては、「Monstache の設定」および「高度な設定」をご参照ください。
Monstache を開始します。
monstache -f config.toml-fフラグは指定された設定ファイルをロードします。設定でverbose = trueが設定されているため、Monstache はすべての Elasticsearch リクエストトレースをログに記録します。
ステップ 4:データ同期の検証
MongoDB のクエリには Data Management (DMS) コンソールを、Elasticsearch のクエリには Kibana コンソールを使用します。
DMS へのアクセスについては、「DMS を使用してレプリカセットインスタンスに接続」をご参照ください。
Kibana へのアクセスについては、「Kibana コンソールにログイン」をご参照ください。
フル同期後のドキュメント数の確認
以下のクエリを実行して、両方のシステムで同じドキュメント数が表示されることを確認します。
MongoDB:
db.hotmovies.find().count()期待される出力:
[
10000
]Elasticsearch:
GET hotmovies/_count期待される出力:
{
"count" : 10000,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
}
}挿入同期のテスト
MongoDB に2つのドキュメントを挿入します。
db.hotmovies.insert({id: 11003,title: "Beauty",overview: "How a group of IT women with high IQ become outstanding",original_language:"cn",release_date:"2020-06-17",popularity:67.654,vote_count:65487,vote_average:9.9})
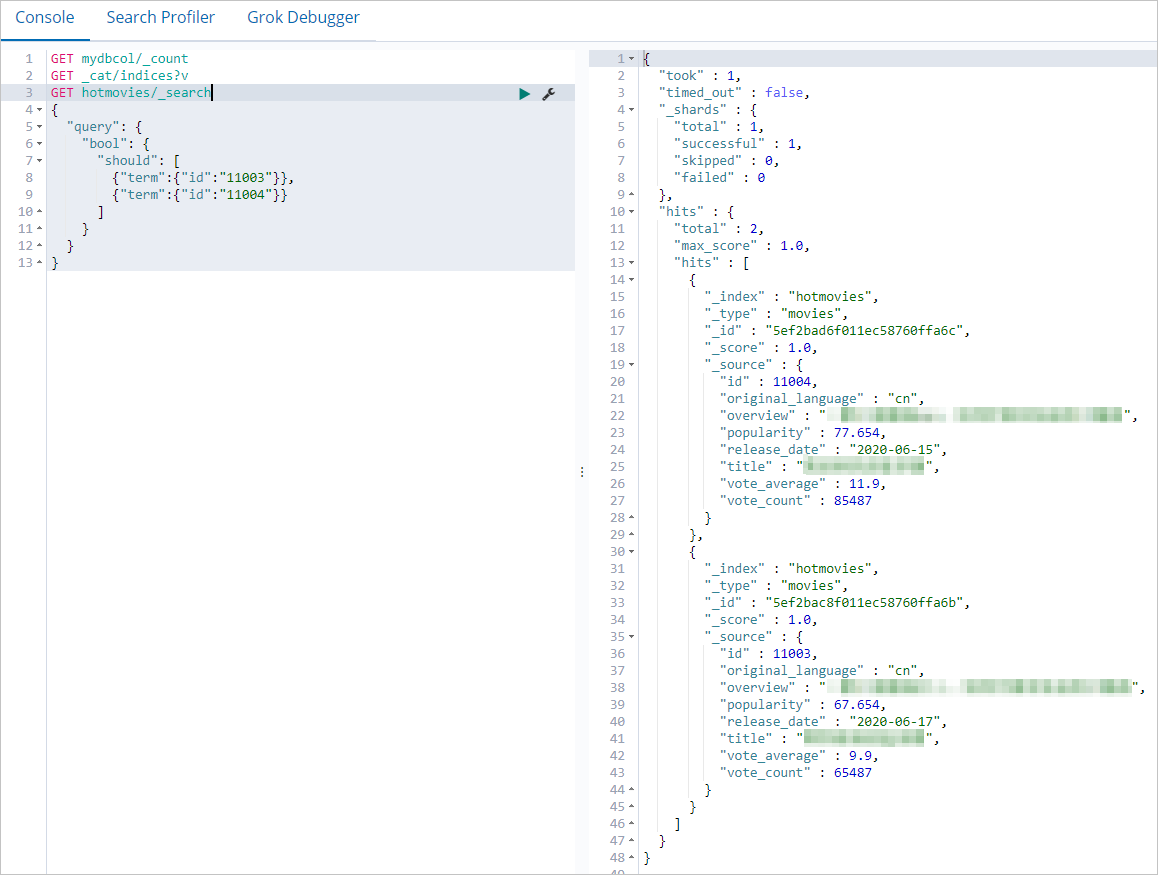
db.hotmovies.insert({id: 11004,title: "Heroic Programmers",overview: "How a group of IT men with high IQ become outstanding",original_language:"cn",release_date:"2020-06-15",popularity:77.654,vote_count:85487,vote_average:11.9})Elasticsearch をクエリして、ドキュメントが同期されたことを確認します。
GET hotmovies/_search
{
"query": {
"bool": {
"should": [
{"term":{"id":"11003"}},
null
]
}
}
}
更新同期のテスト
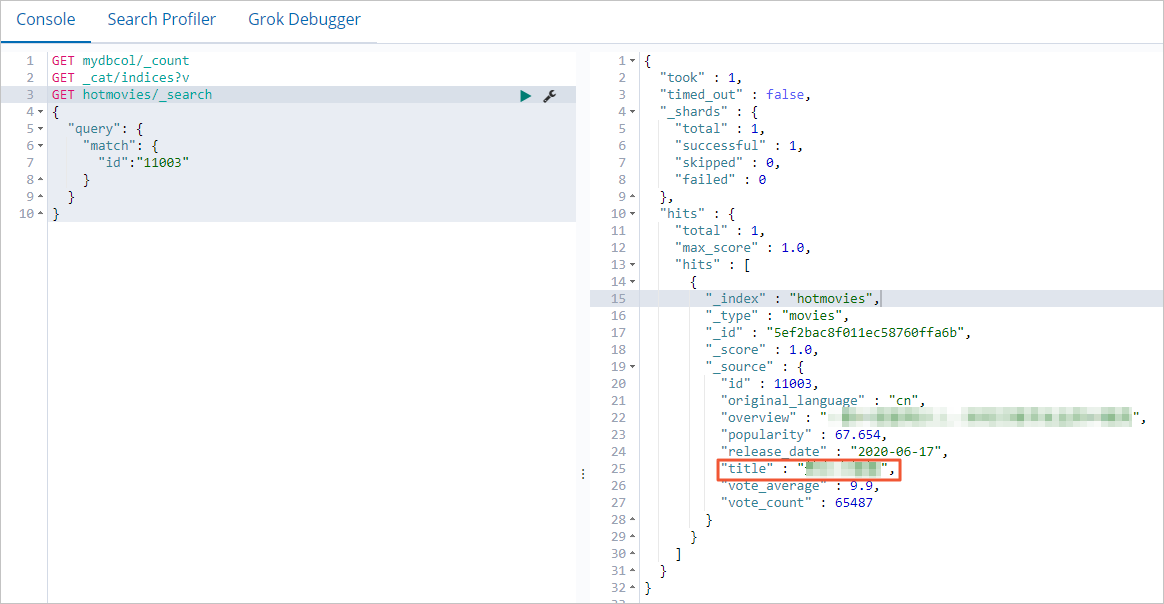
MongoDB でドキュメントを更新します。
db.hotmovies.update({'title':'Beauty'},{$set:{'title':'Beautiful Programmers'}})Elasticsearch をクエリして更新を確認します。
GET hotmovies/_search
{
"query": {
"match": {
"id":"11003"
}
}
}
削除同期のテスト
MongoDB からドキュメントを削除します。
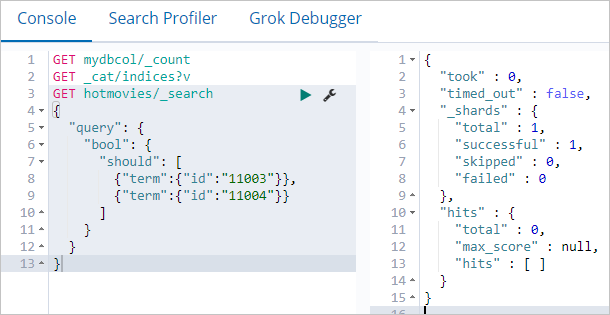
db.hotmovies.remove({id: 11003})
db.hotmovies.remove({id: 11004})Elasticsearch をクエリしてドキュメントが削除されたことを確認します。
GET hotmovies/_search
{
"query": {
"bool": {
"should": [
{"term":{"id":"11003"}},
null
]
}
}
}
ステップ 5:Kibana でのデータ分析
このチュートリアルでは Kibana V6.7.0 を使用します。他のバージョンではナビゲーションが異なる場合があります。
Kibana コンソールにログインします。詳細については、「Kibana コンソールにログイン」をご参照ください。
インデックスパターンを作成します。
左のナビゲーションウィンドウで、[Management] をクリックします。
[Kibana] セクションで、[Index Patterns] をクリックします。
[Create index pattern] をクリックします。
[インデックスパターン] を設定し、[次のステップ] をクリックします。
[タイムフィルターフィールド名] を [タイムフィルターを使用しない] に設定します。
[Create index pattern] をクリックします。
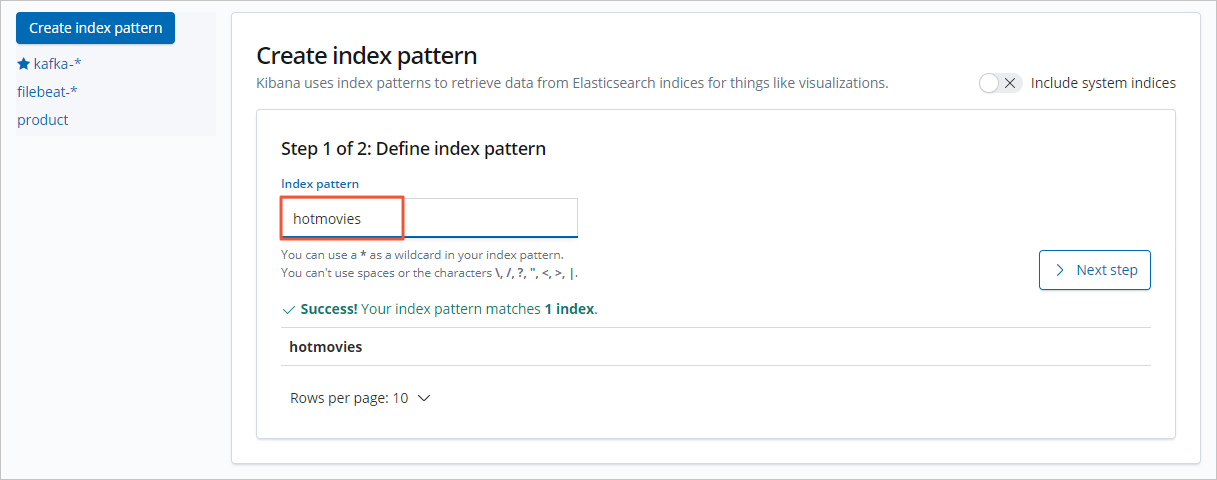
人気映画トップ 10 の円グラフを作成します。
左のナビゲーションウィンドウで、[Visualize] をクリックします。
検索ボックスの横にある [+] をクリックします。
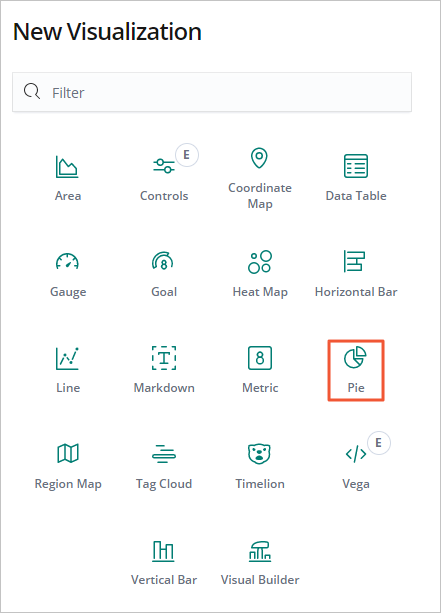
[New Visualization] ダイアログボックスで、[Pie] をクリックします。
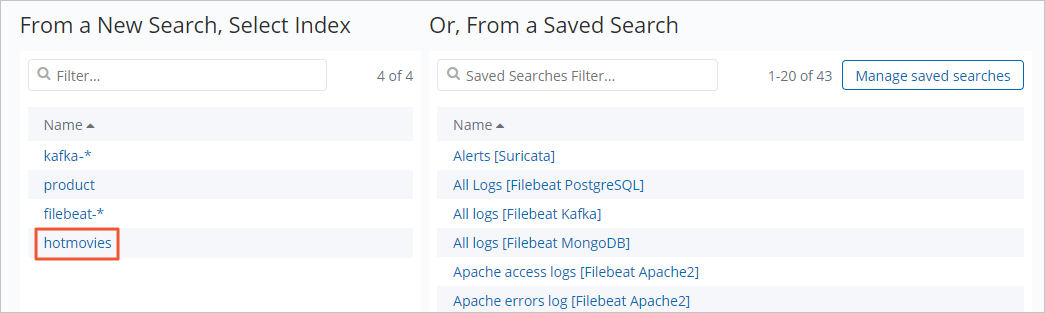
[hotmovies] インデックスパターンをクリックします。
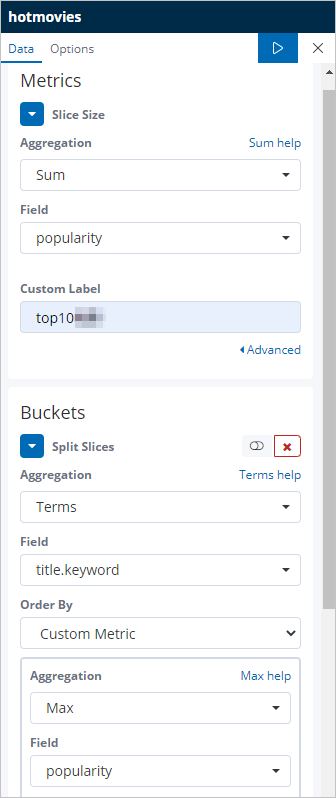
図のように [Metrics] と [Buckets] セクションを設定します。
 アイコンをクリックして設定を適用します。
アイコンをクリックして設定を適用します。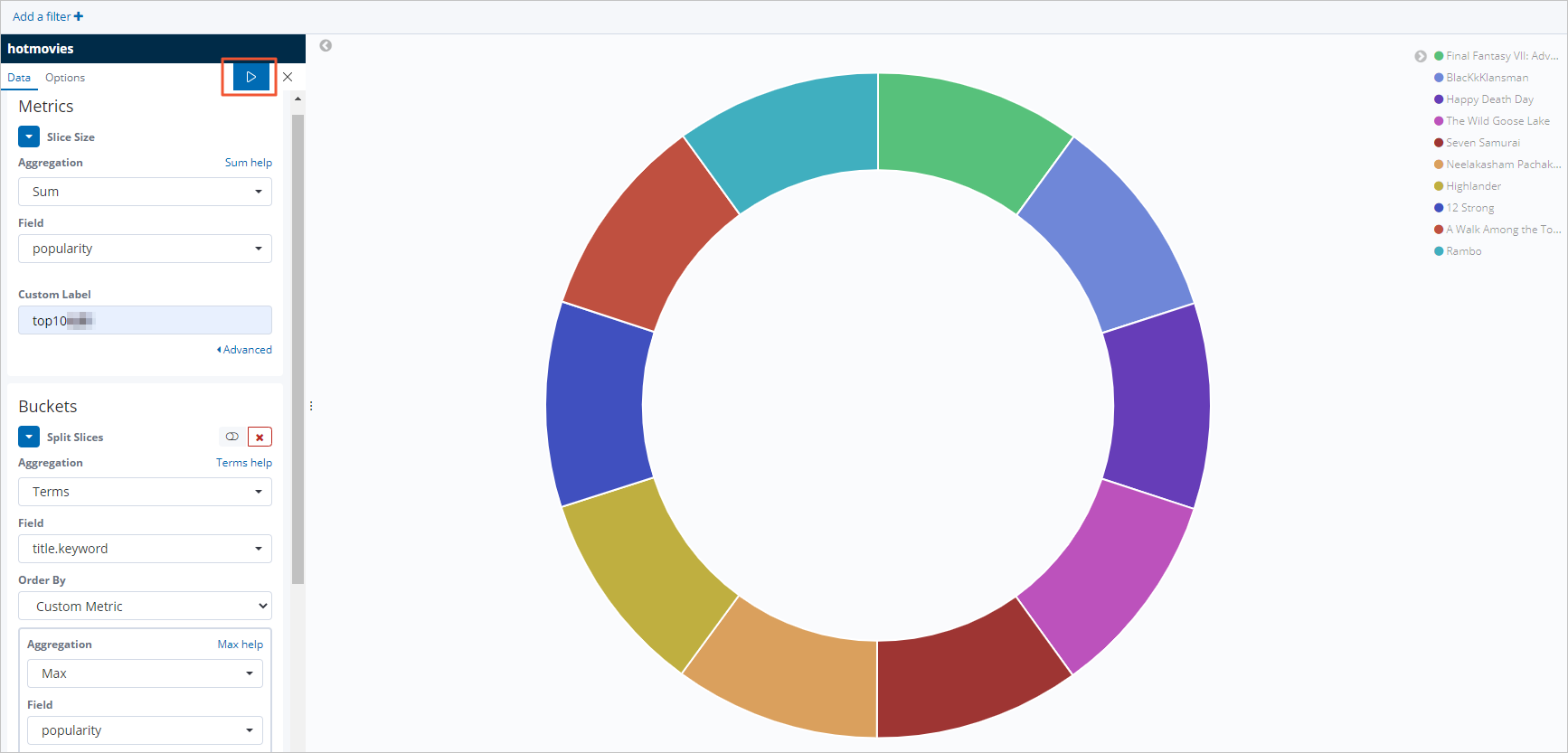
よくある質問
高可用性を有効にし、同時実行数を増やした後、データ損失が発生します。どうすればよいですか?
まず、Elasticsearch クラスターが正常であるかどうかを確認します。クラスターが異常な状態にある場合は、「Elasticsearch よくある質問」を参照してクラスターレベルの問題を診断・解決し、その後 elasticsearch-max-conns の値を下げて、さらなるデータ損失がないか監視します。
クラスターが正常である場合、問題は Monstache にある可能性が高いです。Monstache のドキュメントで既知の問題や設定のガイダンスを確認してください。