サービスのトラフィックがピーク時とオフピーク時の間で変動するなど、クラスターのリソース使用率が低い場合があります。クラスターをスペックダウンして、リソースをビジネス要件に合わせて調整し、コストを最適化できます。これは、ノードの仕様の削減、ノード数の削減、またはストレージタイプの調整によって行うことができます。
スペックダウンに関する注意事項
クラスターをスペックダウンすると、サービスの遅延、構成の競合、課金の変更が発生する可能性があります。続行する前に、以下の前提条件をよくお読みください。
サービスの安定性
クラスター構成の変更中のサービスの安定性には、次のルールが適用されます。
クラスター
サービスステータス
対策
高ペイロード + レプリカなし
高ペイロード: スペックダウン中の書き込みまたはクエリオペレーションの高い同時実行性、CPU 使用率 > 60%、ヒープメモリ使用量 > 50%。
時折のアクセスタイムアウト
クライアントでリトライメカニズムを有効にします。
スペックダウンする前に、インデックスのレプリカ数を少なくとも 1 に増やします。
スペックダウン後のデータノード数 ≤ 2。
データ損失の原因となる可能性があります。
この操作はオフピーク時に実行してください。
構成の制約
データノードのストレージ領域のスペックダウンは、v3 デプロイメントアーキテクチャを使用するクラスターでのみサポートされます。
スペックダウン中にクラスターのバージョンをアップグレードすることはできません。
1 回のスペックダウン操作で変更できるノードのタイプは 1 つだけです。
エラスティックデータノードはスペックダウンできません。
同じクラスターでの 2 回の連続したスペックダウン操作の間隔は 30 分以上である必要があります。
スペックダウン後の CPU 仕様の制約
基本ルール: ターゲット仕様の CPU とメモリは、現在の仕様の少なくとも半分である必要があります。
次の仕様にスペックダウンすることはできません:
1 コア 2 GiB、2 コア 2 GiB、2 コア 4 GiB、または4 コア 4 GiB。Kibana ノードは2 コア 2 GiBにスペックダウンできます。特殊なケース: 許可されていない仕様にスペックダウンするには、新しいクラスターを作成してからデータ移行を実行する必要があります。
コストへの影響
スペックダウンの注文を送信すると、システムは新しい構成に基づいて課金します。詳細については、「従量課金」および「サブスクリプション」をご参照ください。
スペックダウン前のチェック
以下のチェックを行わずにクラスターをスペックダウンすると、クラスターがクラッシュしたり、データが失われたり、サービスが利用できなくなったりする可能性があります。各項目をチェックして確認する必要があります。
クラスターのヘルス
GET _cluster/healthを実行して、クラスターのステータスが GREEN であることを確認します。ペイロードのセキュリティ
クラスターは、次の条件を満たす場合にのみスペックダウンできます:
ノードタイプ
CPU 使用率
JVM ヒープメモリ使用量
専用マスターノード
過去 24 時間の単一ノードのピーク使用率 < 30%
過去 24 時間の単一ノードのピーク使用率 < 25%
他のロールのノード
両方の条件を満たす必要があります:
• 過去 24 時間の単一ノードのピーク使用率 < 50%
• 過去 24 時間の全ノードの平均使用率 < 30%
両方の条件を満たす必要があります:
• 過去 24 時間の単一ノードのピーク使用率 < 50%
• 過去 24 時間の全ノードの平均使用率 < 30%
インデックスの準備
GET /_cat/indices?vを実行して、CLOSE 状態のインデックスを確認します。見つかった場合は、POST /<index_name>/_openを実行して一時的に開きます。これらのインデックスを開かないと、次の理由で構成の変更が失敗する可能性があります:インデックスが CLOSE 状態の場合、クラスターのステータスは GREEN に変更できません。Elasticsearch は、シャード割り当てルールの調整など、特定の機密性の高い構成変更を実行する前に、クラスターのステータスが GREEN である必要があります。
構成の変更中、クラスターはシャードを再割り当てします:
クローズされたインデックスのシャードは再割り当てできません。
これにより、GREEN ステータスに依存する操作が失敗します。
これにより、クラスターのステータスが GREEN に変わるのを防ぎます。到達できる最高のステータスは YELLOW です。
GET _cat/indices?vを実行して、各インデックスのレプリカ数が少なくとも 1 であることを確認します。マルチゾーンインスタンスの場合、各インデックスのレプリカ数がインスタンスで利用可能なゾーンの数より少ないことを確認してください。レプリカ数を 1 に設定することをお勧めします。スペックダウンが完了したら、手動でレプリカ数を増やすことができます。
方法 1: コンソールでクラスターをスペックダウンする
仕様、ディスクタイプ、ディスク領域のスペックダウン
インスタンス ページで、 をクリックします。

代替エントリポイント: 基本情報 ページで、 をクリックします。
ダウングレード設定 ページで、必要に応じて構成パラメーターを調整します。
重要利用可能な構成パラメーターは、クラスターのタイプとバージョンによって異なります。ダウングレード設定 ページのパラメーターが優先されます。
ノードの仕様 (ノードストレージタイプ) をスペックダウンできます。パフォーマンスレベルは高いものから低いものへとソートされます:
ローカルディスク: ローカル SSD (NVMe SSD ローカルディスク) -> ローカル SATA ディスク (SATA HDD ローカルディスク)。
説明ローカルディスクは、ECS インスタンスが配置されている物理サーバ上のハードディスクデバイスです。ECS インスタンスにローカルストレージアクセスを提供し、高いストレージ I/O パフォーマンスを必要とし、マスストレージに対して費用対効果の高いビジネスシナリオに適しています。
ESSD: エンタープライズ SSD (ESSD) は、25 GE ネットワーキングとリモートダイレクトメモリアクセス (RDMA) テクノロジーを組み合わせて、単一ディスクで最大 100 万のランダム読み取り/書き込み IOPS と低単一リンクレイテンシを提供します。
説明ESSD-PL0 は標準 SSD にスペックダウンできません。
旧世代ディスク: 標準 SSD -> ウルトラディスク -> ベーシックディスク。
説明これらのディスクは、一部のリージョンとゾーンで段階的に廃止されています。ESSD を選択することをお勧めします。
データノードのストレージ領域のスペックダウン (v3 デプロイメントモードを使用するクラスターでのみサポート): クラスターの安定性を確保するために、スペックダウン後のディスク領域使用率は 60% 未満である必要があります。スペックダウンを開始する前に、次の条件が満たされていることを確認してください: 現在のディスク使用率 < (スペックダウン後のディスク領域 × 0.6)。

v2 デプロイメントモードを使用するクラスターは、コンソールからのストレージ領域のスペックダウンや API の呼び出しをサポートしていません。スペックダウンを実行するには、テクニカルサポートに連絡する必要があります。
インテリジェントアップデート (デフォルトで有効): 指定した構成変更に基づいて、システムが最適な方法を自動的に選択します。
強制更新 (デフォルトで無効、非推奨): このオプションはヘルスチェックをスキップし、クラスターを強制的に再起動します。これにより、長時間のサービス中断が発生する可能性があります。回復時間はデータ量によって異なります。
[利用規約] と [サービスレベルアグリーメント] をクリックして表示します。同意する場合は、[今すぐ購入] をクリックします。システムは、設定項目に最適な変更ポリシーを自動的に選択し、課金方法に従って課金します。
変更中、クラスターのステータスは 初期化中 になります。クラスターのパフォーマンスが変動し、一時的な切断が発生する可能性があります。変更が完了すると、クラスターのステータスは 正常 に更新され、クラスター内のノードの IP アドレスが変更されます。
データノードのスケールイン
インスタンスの 基本情報 ページで、 をクリックします。

必要に応じて、削除するノードのタイプとノード数を選択します。
重要Alibaba Cloud ES は、スケールインの前にノードのセキュリティチェックを自動的に実行します。チェックが失敗した場合は、エラーメッセージに基づいて問題をトラブルシューティングしてから、スケールイン操作をリトライしてください。
利用可能な構成パラメーターは、クラスターのタイプとバージョンによって異なります。[コンソール] ページのパラメーターが優先されます。この例では、バージョン 8.17.0 のベクトル検索版クラスターを使用しています。

OK をクリックします。システムはスケールイン操作を実行し、クラスターの構成と課金方法に基づいて課金します。
変更中、クラスターのステータスは 初期化中 になります。クラスターのパフォーマンスが変動し、一時的な切断が発生する可能性があります。変更が完了すると、クラスターのステータスは 正常 に更新され、クラスター内のノードの IP アドレスが変更されます。
方法 2: API を呼び出してクラスターをスペックダウンする
クラスターをスペックダウンするための API の詳細については、「UpdateInstance」をご参照ください。
データ移行とロールバック
データセキュリティを確保するために、スケールインするデータノードは空である必要があります。選択したデータノードにデータが含まれている場合、システムはデータを移行するように促します。移行後、選択したノードにはインデックスデータが含まれなくなり、新しいインデックスデータは書き込まれません。
データ移行
クラスターのスケールイン セクションで、プロンプトの データ移行ツール をクリックします。
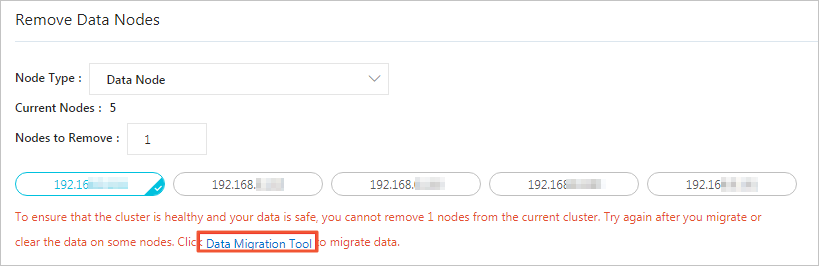
データ移行ツールは、Elasticsearch シャード割り当てフィルタリング機能を使用して、スムーズなデータ移行を実行します。データ移行プロセスは、サービスに対して透明です。
データの移行 ダイアログボックスで、ノードの移行方法を選択します。

パラメーター
説明
スマート移行
システムは移行するデータノードを自動的に選択します。
カスタム
移行するデータノードを手動で選択します。
データ移行契約に同意し、OK をクリックします。
データロールバック
データ移行は長いプロセスになることがあります。この間、クラスターのステータスやデータの変更により、移行が失敗する可能性があります。タスクリストでタスクの詳細を表示できます。データ移行が失敗した場合、または完了後に、次のステップを実行して移行されたノードをロールバックできます:
Elasticsearch クラスターの Kibana コンソールにログインし、プロンプトに従って Kibana コンソールのホームページに移動します。
Kibana コンソールへのログイン方法の詳細については、「Kibana コンソールにログインする」をご参照ください。
説明この例では、Elasticsearch V6.7.0 クラスターを使用しています。他のバージョンのクラスターでの操作は異なる場合があります。コンソールでの実際の操作が優先されます。
表示されたページの左側のナビゲーションウィンドウで、[開発ツール] をクリックします。
[コンソール] で、次のコマンドを実行して、移行されたノードの IP アドレスを取得します。
GET _cluster/settingsコマンドが正常に実行されると、次の結果が返されます。
{ "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": "192.168.xx.xx,192.168.xx.xx,192.168.xx.xx" } } } } } }次のコマンドを実行して、移行されたノードのデータをロールバックします。
特定のノードのデータをロールバックします。構成で、ロールバックするノードの IP アドレスを削除し、ロールバックしないノードの IP アドレスは保持します。
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": "192.168.xx.xx,192.168.xx.xx" } } } } } }すべての移行されたノードのデータをロールバックします。
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": null } } } } } }
次のコマンドを実行して、データロールバックが完了したことを確認します。
GET _cluster/settingsコマンドが正常に実行され、結果に移行されたノードの IP アドレスが含まれていない場合、ロールバックは完了です。シャードがノードに再割り当てされているかどうかも確認できます。
説明データ移行またはロールバック中に、
GET _cat/shards?vコマンドを実行してタスクのステータスを表示できます。