Alibaba Cloud Elasticsearch (ES) クラスターの不均衡な負荷は、いくつかの理由で発生する可能性があります。これらには、不適切なシャード設定、不均一なセグメントサイズ、ホットデータとコールドデータの非分離、Server Load Balancer (SLB) インスタンスやマルチゾーンアーキテクチャで使用される持続的接続などが含まれます。このトピックでは、Elasticsearch クラスターの不均衡な負荷の分析と解決策について説明します。
問題の説明
ノード間のディスク使用率はほぼ同じですが、CPU 使用率または load_1m メトリックの値が不均衡な負荷を示しています。
ノード間でディスク使用率が大幅に異なり、CPU 使用率または load_1m メトリックの値が不均衡な負荷を示しています。
原因
- 重要
ほとんどの場合、不均衡な負荷は不適切なシャードの割り当てが原因です。最初にシャードの割り当てを確認することをお勧めします。
ホットデータとコールドデータがノード上で分離されていません。
重要たとえば、クエリでルーティングパラメーターを指定したり、ホットデータをクエリしたりすると、不均衡な負荷が発生する可能性があります。
SLB インスタンスとマルチゾーンアーキテクチャを使用する場合、リリースされない持続的接続が原因でトラフィック分布が不均一になることがあります (これはまれに発生します)。詳細については、「不均一な持続的接続」をご参照ください。
他の理由で不均衡な負荷が発生した場合は、Alibaba Cloud のテクニカルサポートエンジニアに連絡して問題をトラブルシューティングしてください。
不適切なシャードの割り当て
シナリオ
A 社は Alibaba Cloud Elasticsearch クラスターを購入しました。クラスターには 3 つの専用マスターノードと 9 つのデータノードが含まれています。各専用マスターノードは 16 vCPU と 32 GiB のメモリを提供します。各データノードは 32 vCPU と 64 GiB のメモリを提供します。主要なデータは test インデックスに保存されます。ピーク時 (16:21 から 18:00) には、読み取りパフォーマンスは約 2,000 QPS、書き込みパフォーマンスは 1,000 QPS で、コールドデータとホットデータの両方がクエリされます。さらに、2 つのノードの CPU 使用率が 100% に達し、Elasticsearch サービスに影響を与えています。
分析
ネットワークと Elastic Compute Service (ECS) インスタンスを確認します。ECS インスタンスが正常な場合は、ネットワークのモニタリングデータを表示します。
ネットワークのモニタリングデータは、ピーク時にネットワークリクエストの数とクエリ QPS が増加することを示しています。さらに、関連ノードの CPU 使用率が大幅に増加します。この情報に基づき、高負荷のノードが主にクエリリクエストの処理に使用されていると結論付けることができます。
GET _cat/shards?vコマンドを実行して、インデックスのシャードをクエリします。コマンドの出力は、シャードがノードに均等に割り当てられていないことを示しています。test インデックスのシャードは、主に高負荷のノードに割り当てられています。さらに、ディスク使用率のモニタリングデータは、高負荷のノードのディスク使用率が他のノードよりも大きいことを示しています。シャードの不均一な割り当てがストレージの不均一性を引き起こしていると結論付けることができます。データをクエリまたは書き込む際、ストレージが大きいノードが主要なクエリおよび書き込みワークロードを処理します。
GET _cat/indices?vコマンドを実行して、インデックスの情報をクエリします。コマンドの出力は、インデックスに 5 つのプライマリシャードと各プライマリシャードに 1 つのレプリカシャードがあることを示しています。さらに、クラスター構成は、シャードが均等に割り当てられておらず、特定のドキュメントが削除されていることを示しています。Elasticsearch がデータを検索するとき、.del でマークされたドキュメントも検索してフィルター処理します。これにより、追加のリソースが消費され、検索効率が大幅に低下します。オフピーク時に force merge 操作を呼び出すことをお勧めします。

クラスターログと低速検索ログを表示します。
ログは、クエリがすべて通常の term クエリであり、クラスターログにエラーが発生していないことを示しています。したがって、Elasticsearch クラスターでは、CPU リソースを消費するエラーやクエリ文は発生していません。
まとめ
前述の分析は、不均一な CPU 使用率が主に不均一なシャードの割り当てによって引き起こされていることを示しています。インデックスのシャードを再割り当てする必要があります。プライマリシャードとレプリカシャードの合計数が、クラスター内のデータノード数の倍数であることを確認してください。最適化後、ノード間の CPU 使用率に大きな差はなくなります。次の図は CPU 使用率を示しています。

解決策
インデックスを作成する前に、シャードを適切に計画してください。詳細については、「シャード評価のガイドライン」をご参照ください。
シャード評価のガイドライン
シャードの数と各シャードのサイズは、Elasticsearch クラスターの安定性とパフォーマンスを決定します。ビジネスシナリオを定義するのが難しい場合に、多数のシャードがクラスターのパフォーマンスに影響を与えるのを防ぐために、Elasticsearch クラスターの各インデックスに対してシャードを適切に計画する必要があります。
Elasticsearch V7.X より前のバージョンでは、デフォルトで 1 つのインデックスに 5 つのプライマリシャードと各プライマリシャードに 1 つのレプリカシャードがあります。Elasticsearch V7.X 以降では、デフォルトで 1 つのインデックスに 1 つのプライマリシャードと 1 つのレプリカシャードがあります。
低スペックのノードの場合、各シャードのサイズは 30 GB を超えないようにしてください。高スペックのノードの場合、各シャードのサイズは 50 GB を超えないようにしてください。
ログ分析シナリオや非常に大きなインデックスの場合、各シャードのサイズは 100 GB を超えないようにしてください。
プライマリシャードとレプリカシャードの合計数は、データノードの数と同じか、その倍数である必要があります。
説明設定するプライマリシャードが多いほど、Elasticsearch クラスターのパフォーマンスオーバーヘッドは大きくなります。
単一ノード上のシャード数は、メモリサイズに 30 を掛けた値に基づいて決定することをお勧めします。多くのシャードが計画されている場合、ファイルハンドルの枯渇が容易に発生し、クラスターの障害につながる可能性があります。
ノード上の各インデックスに対して、最大 5 つのシャードを構成します。
クラスターで自動インデックス作成機能を有効にしている場合、シナリオベースの構成機能を使用してシャード構成を変更できます。シャードが均等に割り当てられていることを確認してください。詳細については、「シナリオベースのテンプレートを使用してクラスターの構成を変更する」をご参照ください。
不均一なセグメントサイズ
シナリオ
A 社の Elasticsearch クラスター内のノードで CPU 使用率が急激に増加しました。これにより、クエリのパフォーマンスに影響が出ています。クエリは主に test インデックスに対して実行されます。このインデックスには 3 つのプライマリシャードと、各プライマリシャードに 1 つのレプリカシャードがあります。シャードはノードに均等に割り当てられています。インデックスには delete.doc でマークされた多くのドキュメントが含まれており、ECS インスタンスが正常であることを確認済みです。

分析
クエリ本文に
"profile": trueを追加します。クエリ結果は、Elasticsearch が test インデックスのシャード 1 をクエリするのに、他のシャードよりも長い時間がかかることを示しています。
preference=_primaryとpreference=_replicaを指定したクエリリクエストを送信し、クエリ本文に"profile": trueを追加して、プライマリシャードとレプリカシャードのクエリに必要な時間を表示します。シャード 1 (プライマリシャード) のクエリに必要な時間は、そのレプリカシャードのクエリに必要な時間よりも長くなっています。これは、不均衡な負荷がシャード 1 によって引き起こされていることを示しています。
GET _cat/segments/index?v&h=shard,segment,size,size.memory,ipとGET _cat/shards?vコマンドを実行して、シャード 1 の情報をクエリします。コマンドの出力は、シャード 1 に大きなセグメントが含まれており、シャード内のドキュメント数がそのレプリカシャードよりも多いことを示しています。この情報に基づき、不均衡な負荷が不均一なセグメントサイズによって引き起こされていると判断できます。
説明ドキュメント数の不一致は、さまざまな理由で発生する可能性があります。例:
プライマリシャードとレプリカシャード間のデータ同期に遅延が存在します。ドキュメントが継続的にプライマリシャードに書き込まれる場合、データの不整合が発生する可能性があります。ただし、ドキュメントの書き込みを停止すると、プライマリシャードとそのレプリカシャードのドキュメント数は同じになります。
データがプライマリシャードに書き込まれた後、システムはデータ書き込みリクエストをそのレプリカシャードに転送します。自動生成されたドキュメント ID を使用してプライマリシャードにドキュメントを書き込む場合、書き込み操作中にプライマリシャードで削除操作を実行することはできません。削除操作 (たとえば、書き込んだばかりのドキュメントを削除するための Delete by Query リクエストを送信する) を実行すると、その操作はレプリカシャードでも実行されます。その後、システムは書き込みリクエストをレプリカシャードに転送します。ドキュメント ID はシステムによって自動生成されるため、ドキュメントは検証なしでレプリカシャードに書き込まれます。その結果、レプリカシャードのドキュメント数がプライマリシャードのドキュメント数と異なります。さらに、プライマリシャードには
doc.deleteでマークされた多くのドキュメントが含まれます。
解決策 (いずれかを選択)
オフピーク時に force merge 操作を呼び出して、小さなセグメントをマージし、delete.doc でマークされたドキュメントを削除します。
プライマリシャードが存在するノードを再起動して、レプリカシャードをプライマリシャードに昇格させます。新しいプライマリシャードを使用して新しいレプリカシャードを生成します。これにより、新しいプライマリシャードとレプリカシャードのセグメントが同じであることが保証されます。
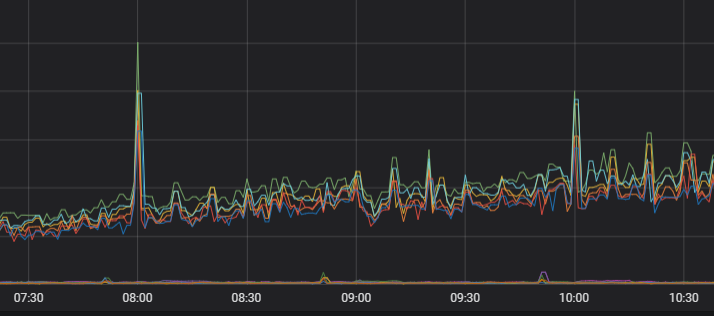
次の図は、最適化後の負荷を示しています。
不均一な持続的接続
シナリオ
A 社は、ゾーン B とゾーン C の 2 つのゾーンにまたがって Elasticsearch クラスターをデプロイしています。クラスターがサービスを提供しているとき、ゾーン C のノードの負荷はゾーン B のノードの負荷よりも高くなります。不均衡な負荷がハードウェアや不均一なデータ分布によって引き起こされたものではないことを確認済みです。
分析
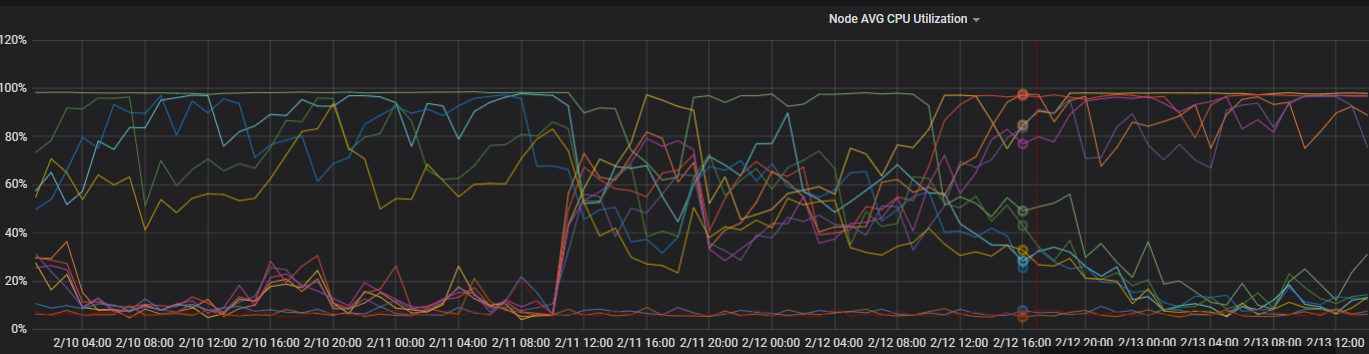
過去 4 日間の 2 つのゾーンのノードの CPU 使用率を表示します。
モニタリングデータは、ノードの CPU 使用率が大幅に変化したことを示しています。
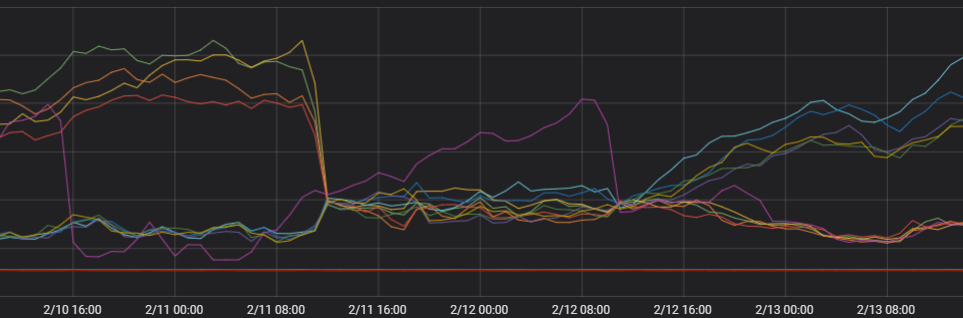
ノードへの TCP 接続を表示します。
モニタリングデータは、2 つのゾーンの TCP 接続数が大幅に異なることを示しています。これは、不均衡な負荷がネットワーク接続によって引き起こされていることを示しています。
クライアント接続を確認します。
クライアントは持続的接続を使用し、少数の新しい接続を確立します。このシナリオでは、マルチゾーンネットワークの独立したスケジューリングのリスクがあります。ネットワークサービスは、接続数に基づいて独立してスケジュールされます。各スケジューリングユニットは、接続を作成するための最適なノードを選択します。独立したスケジューリングは、より高いパフォーマンスを提供します。ただし、新しい接続の数が少ない場合、複数のスケジューリングユニットが同じノードを選択して接続を確立する可能性があります。Elasticsearch クラスターのクライアントノードは、まず同じゾーンにある別のノードにリクエストを転送します。これにより、ゾーン間で不均衡な負荷が発生します。
解決策 (いずれかを選択)
クライアントで
httpClientBuilder.setConnectionTimeToLive()を構成します。たとえば、接続の有効期間を 5 分に設定するには、httpClientBuilder.setConnectionTimeToLive(5, TimeUnit.MINUTES)とします。詳細については、「HttpAsyncClientBuilder」をご参照ください。説明クライアントで接続の有効期間を設定する場合、ES が推奨する httpClientBuilder.setConnectionTimeToLive() を使用する必要があります。httpClientBuilder.setKeepAliveStrategy() などの他のパラメーターを設定しても、同じ効果が得られない場合があります。
クライアントを同時に再起動して、新しい接続を確立します。
独立したクライアントノードを使用して、複雑なトラフィックを転送します。これにより、ジョブの責任分担を通じて負荷の不均衡のリスクを軽減します。クライアントノードの負荷が高くても、データノードは影響を受けません。
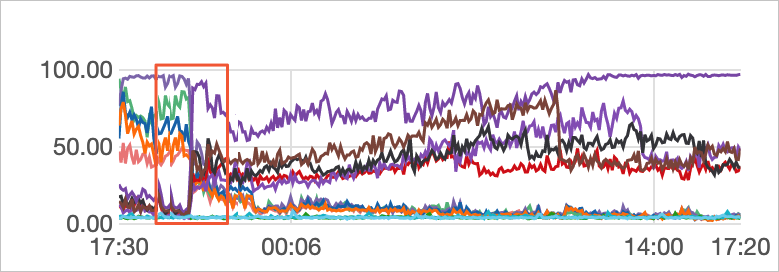
次の図は、最適化後の負荷を示しています。

単一インデックスの不均一なシャード
シナリオ: シャードがノード間で均等に分散しているにもかかわらず、ビジネスインデックスのシャード数が高負荷のノードで多くなっている、またはこれらのノードで単一のシャードがより多くのデータを含んでいることが観測されます。
解決策: index.routing.allocation.total_shards_per_node を設定して、各ノード上の単一インデックスに割り当てられるシャードの最大数を設定します。パラメーター値は、数式
(プライマリシャード + レプリカシャード)/データノード数を使用して計算されます。パラメーター値は整数でなければなりません。結果が 10 進数の場合は切り上げます。PUT index_name/_settings { { "index.routing.allocation.total_shards_per_node" : "3" } }