Cerebro は、Elasticsearch 向けのオープンソースの管理ツールです。軽量で迅速に起動でき、クラスターのヘルス状態の表示、インデックスデータの管理、検索クエリの実行に使用できます。開発者や運用エンジニアは、これを使用して Elasticsearch クラスターを迅速に確認および管理します。
事前準備
クラスターエンドポイントの取得
ES クラスターには、Virtual Private Cloud (VPC) 経由のプライベートエンドポイント、またはパブリックエンドポイントのいずれかを使用して接続できます。
VPC プライベートエンドポイント:プライベートネットワーク経由で ES クラスターにアクセスし、低レイテンシーと高い安定性を実現します。このエンドポイントは、クラスター作成後にデフォルトで有効になります。
パブリックエンドポイント:インターネット経由で ES クラスターにアクセスします。このエンドポイントは手動で有効にする必要があります。
パブリックネットワークアクセスの有効化
ES コンソールにログインし、インスタンスの 基本情報 ページに移動します。
左側のナビゲーションウィンドウで、設定と管理 > セキュリティ設定 を選択し、パブリックネットワークアクセスを有効にします。クラスターのステータスが 初期化中 から 有効 に変わると、パブリックネットワークアクセスが有効になります。
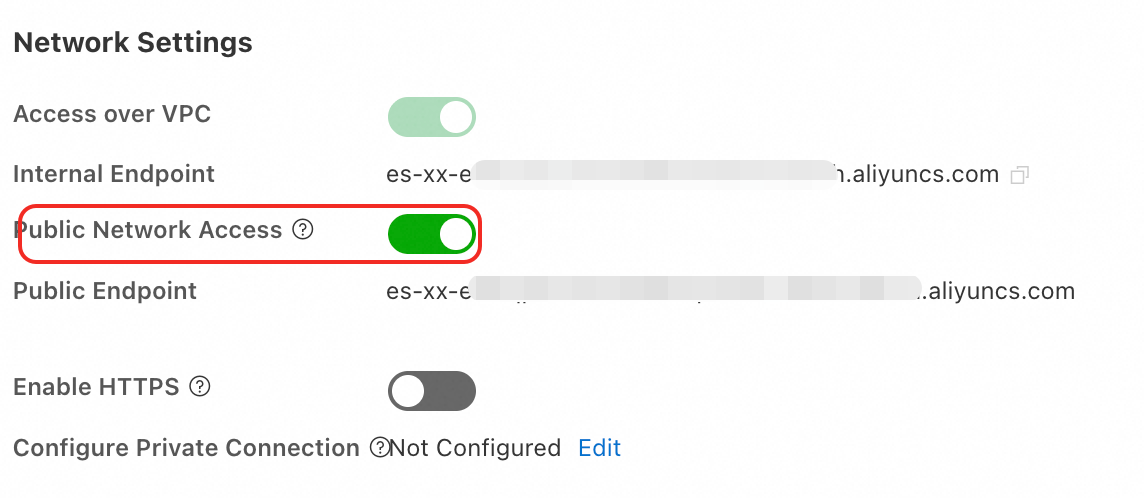 重要
重要パブリックエンドポイントは、ご利用の ES クラスターのセキュリティを低下させます。パブリックエンドポイントを使用する場合は、IP アドレスホワイトリストを設定し、使用後は速やかにパブリックネットワークアクセスを無効にしてください。
IP アドレスホワイトリストの設定
クラスターのセキュリティを確保するため、アクセスに使用するデバイスの IP アドレスを ES クラスターの VPC プライベートホワイトリストまたはパブリックアクセスホワイトリストに追加します。ホワイトリストに含まれる IP アドレスを持つデバイスのみが ES クラスターにアクセスできます。
デバイスの IP アドレスを取得します。
以下のシナリオに基づいて、デバイスの IP アドレスを取得します。
シナリオ
取得する IP アドレス
方法
オンプレミスデバイスから ES クラスターに接続する
オンプレミスデバイスのパブリック IP アドレス。
デバイスが自宅や企業ネットワークなどの LAN (ローカルエリアネットワーク) 内にある場合は、LAN のパブリック出口 IP アドレスを ES クラスターのパブリックアクセスホワイトリストに追加します。
curl ipinfo.io/ipコマンドを実行して、オンプレミスデバイスのパブリック IP アドレスを照会します。異なる VPC 内の ECS インスタンスから ES クラスターに接続する
ECS インスタンスのパブリック IP アドレス
ECS コンソールにログインし、インスタンスリストで表示します。
同じ VPC 内の ECS インスタンスから ES クラスターに接続する
ECS インスタンスのプライベート IP アドレス
ECS コンソールにログインし、インスタンスリストで表示します。
取得した IP アドレスをホワイトリストグループに追加します。
ES コンソールにログインし、インスタンスの 基本情報 ページに移動します。左側のナビゲーションウィンドウで、設定と管理 > セキュリティ設定 を選択します。表示されるダイアログボックスで [変更] をクリックして、VPC プライベートホワイトリストまたはパブリックアクセスホワイトリストを設定します。
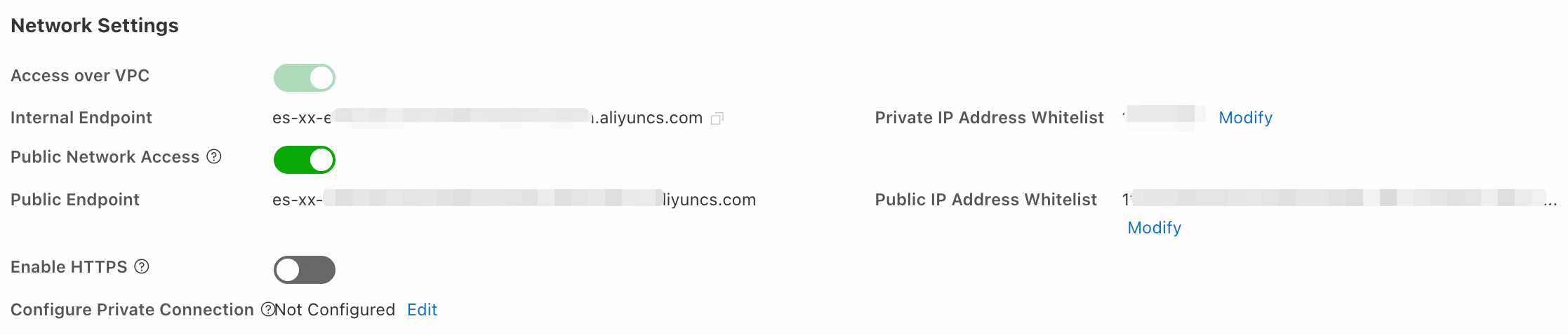
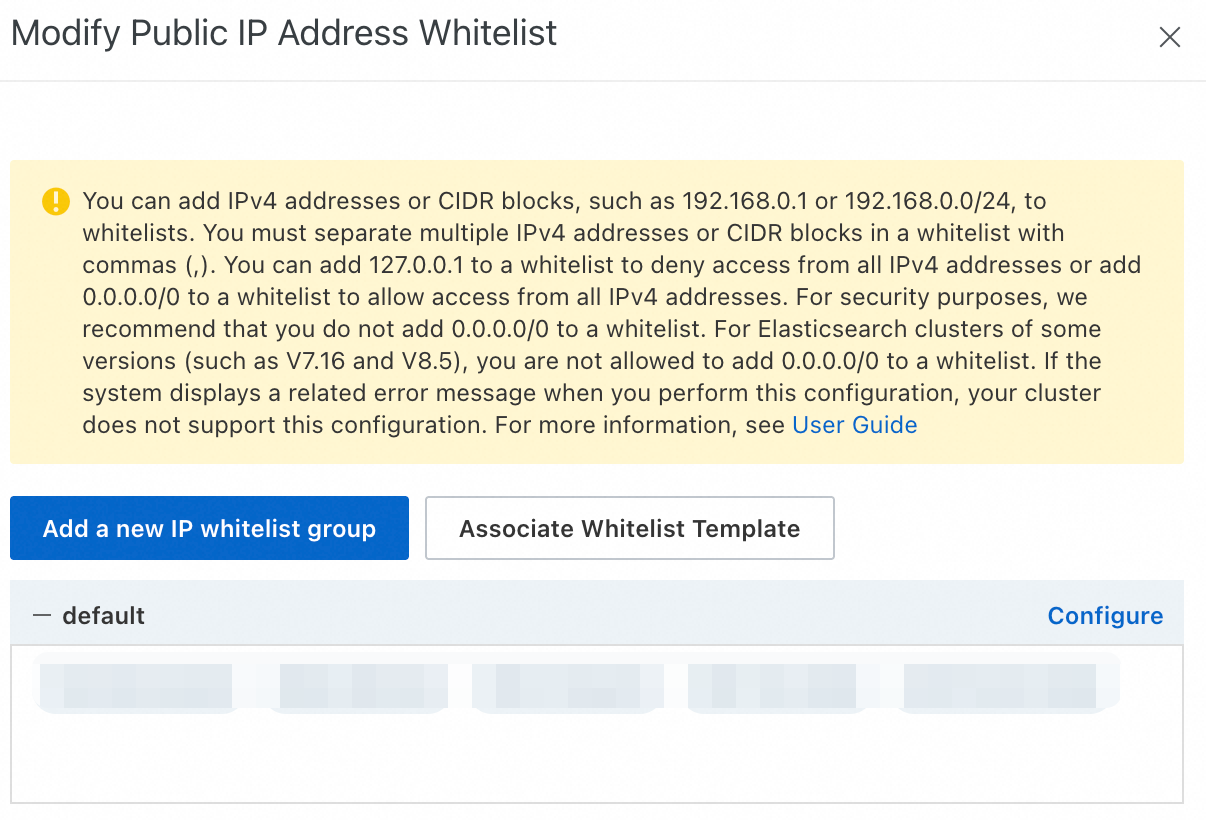
default グループの右側にある [設定] をクリックします。表示されるダイアログボックスで、VPC プライベートホワイトリストまたはパブリックアクセスホワイトリストに IP アドレスを追加します。1 つのクラスターに対して最大 300 個の IP アドレスまたは CIDR ブロックを設定できます。複数の IP アドレスまたは CIDR ブロックはカンマ (,) で区切ります。カンマの前後にスペースを追加しないでください。
[IP ホワイトリストグループの追加] をクリックしてカスタムグループを作成することもできます。
ホワイトリストグループは IP アドレスの管理にのみ使用され、アクセス権限には影響しません。グループ内のすべての IP アドレスは同じ権限を持ちます。
設定タイプ
フォーマットと例
重要な注意事項
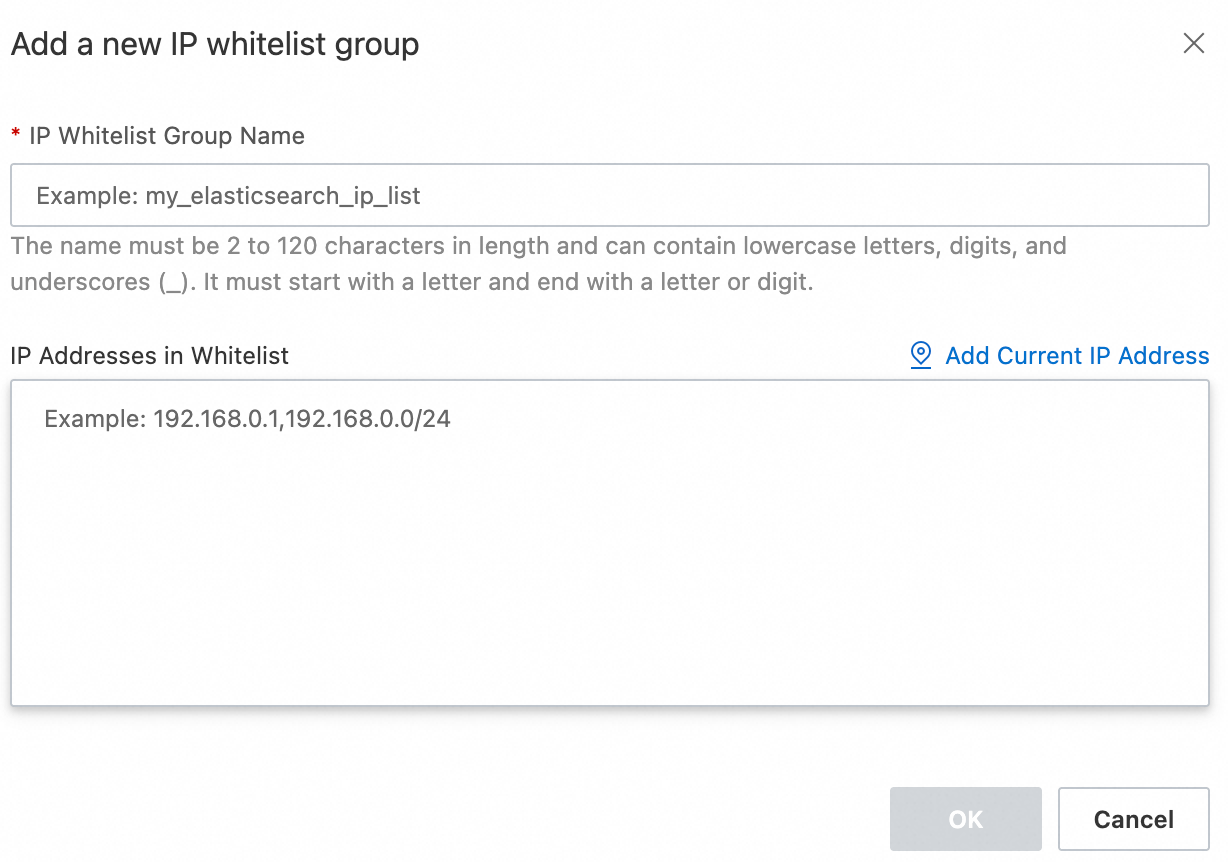
IPv4 アドレスフォーマット
単一 IP アドレス:
192.168.0.1CIDR ブロック:
192.168.0.0/24
アクセスを拒否する場合:
127.0.0.1すべての IP アドレスからのアクセスを許可する場合:
0.0.0.0/0重要この設定はリスクが高いため、ホワイトリストを
0.0.0.0/0に設定しないことを強く推奨します。一部のクラスターバージョン (7.16 や 8.5 など) およびリージョンでは、
0.0.0.0/0がサポートされていません。コンソールのインターフェイスまたはエラーメッセージが優先されます。
IPv6 アドレスフォーマット
(v2 デプロイメントアーキテクチャを使用し、中国 (杭州) リージョンにあるクラスターでのみサポート)
単一 IP アドレス:
2401:XXXX:1000:24::5CIDR ブロック:
2401:XXXX:1000::/48
すべてのアクセスを拒否する場合:
::1すべての IP アドレスからのアクセスを許可する場合:
::/0重要セキュリティリスクが高いため、
::/0を設定しないことを強く推奨します。一部のクラスターバージョンでは
::/0がサポートされていません。コンソールのインターフェイスまたは設定プロンプトが優先されます。
設定が完了したら、[確認] をクリックします。
クラスターへの接続
1. Cerebro のインストールと設定
ECS インスタンスに接続します。この例では Linux システムを使用します。詳細については、「ECS インスタンスへの接続」をご参照ください。
Cerebro は Java 仮想マシン (JVM) 上で動作します。ECS インスタンスに JDK をインストールします。JDK のバージョンは 1.8 以降である必要があります。詳細については、「OpenJDK の手動デプロイ」をご参照ください。
Cerebro のインストールパッケージをダウンロードして解凍します。
# Cerebro v0.9.0 をダウンロード wget https://github.com/lmenezes/cerebro/releases/download/v0.9.0/cerebro-0.9.0.tgz # パッケージを解凍 tar -zxvf cerebro-0.9.0.tgzCerebro の設定ファイルを変更して、Cerebro を Elasticsearch クラスターに関連付けます。
application.conf ファイルを開きます。
vim cerebro-0.9.0/conf/application.confhosts パラメーターを設定し、ファイルを保存します。
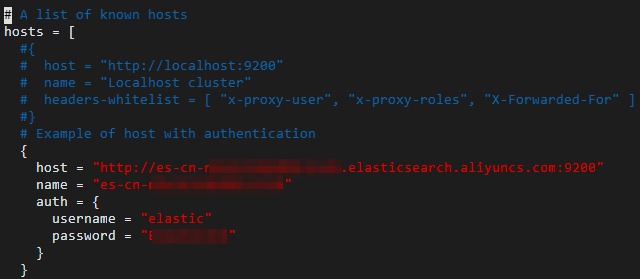 説明
説明複数のインスタンスをカンマで区切って関連付けることができます。
パラメーター
説明
host
事前準備で取得したクラスターエンドポイント:
VPC プライベートエンドポイント:フォーマットは
http://<Elasticsearch クラスターのプライベートエンドポイント>:9200です。パブリックエンドポイント:フォーマットは
http://<Elasticsearch クラスターのパブリックエンドポイント>:9200です。
ES クラスターでは、デフォルトで HTTP が有効になっています。データ転送中の機密性、セキュリティ、完全性を確保するために、HTTPS を有効にして使用することを推奨します。ES コンソールにログインしてインスタンスの 基本情報 に移動し、左側のナビゲーションウィンドウで 設定と管理 > セキュリティ設定 をクリックして HTTPS を有効にします。
重要HTTPS を有効にする前に、アプリケーションコードを更新して HTTPS 接続をサポートするようにしてください。そうしないと、HTTP を使用する既存のコードは安全な接続を確立できなくなります。
name
ご利用の Elasticsearch クラスターの ID。Elasticsearch コンソールにログインします。クラスターリストで ID を表示します。
username
デフォルトのユーザー名は elastic です。このユーザーはクラスターの完全な権限 (管理者アカウントのようなもの) を持っています。
セキュリティのため、本番環境では elastic ユーザーを直接使用しないでください。Elasticsearch X-Pack が提供するロールベースアクセス制御 (RBAC) メカニズムを使用してカスタムロールを作成し、権限を割り当て、その後ユーザーにロールを割り当てます。これにより、詳細な権限コントロールが可能になります。詳細については、「Elasticsearch X-Pack のロール管理を使用したユーザー権限の制御」をご参照ください。
password
ユーザー名のパスワード。
2. Cerebro サービスの起動
必要に応じて、Cerebro をフォアグラウンドまたはバックグラウンドで起動します。
フォアグラウンドで起動 (デバッグ用)
cd cerebro-0.9.0 bin/cerebroCerebro が正常に起動すると、次の図に示す結果が表示されます。

バックグラウンドで起動 (本番環境で推奨)
cd cerebro-0.9.0 nohup bin/cerebro > cerebro.log 2>&1 &tail -f cerebro.logを実行してログを表示します。pkill -f cerebroを実行してサービスを停止します。
3. Cerebro へのアクセスと Elasticsearch クラスターへの接続
ご利用の ECS インスタンスのセキュリティグループを設定します。[インバウンド] セクションで、アクセスするデバイスの IP アドレスを追加し、ポート 9000 をオープンします。詳細な手順については、「セキュリティグループルールの追加」をご参照ください。

ブラウザで、http://<ECS インスタンスのパブリック IP アドレス>:9000 と入力します。
Cerebro のログインページに、設定ファイルで構成された ES クラスターが表示されます。それらをクリックして接続できます。
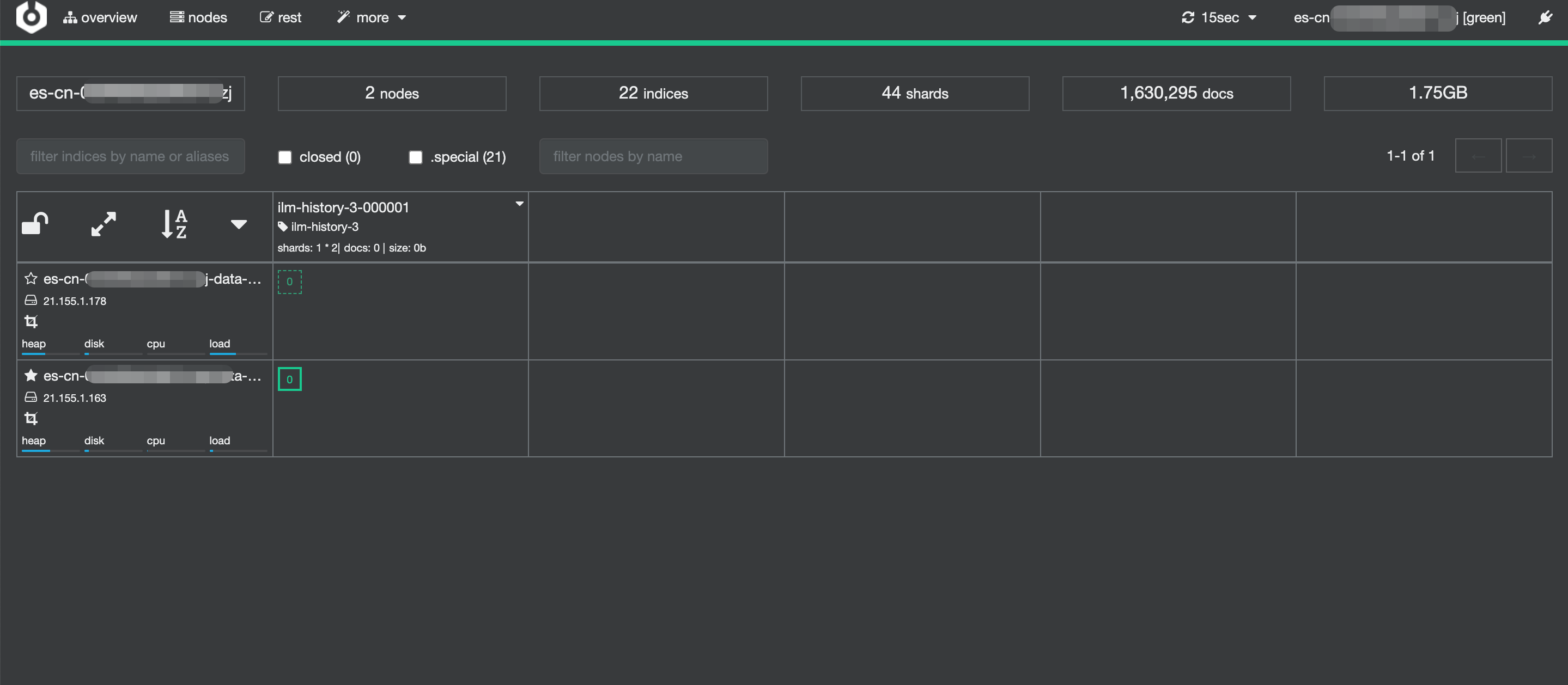
正常に接続した後、Cerebro コンソールでクラスターのステータスを表示し、インデックスを管理します。Cerebro の使用方法の詳細については、「Cerebro」をご参照ください。
よくある質問とトラブルシューティング
問題 1:Cerebro の起動失敗
考えられる原因:JDK がインストールされていない、または JDK のバージョンが 1.8 未満である。ポートが占有されている。ファイルの権限が不十分である。
解決策:
java -versionを実行して、JDK のバージョンが 1.8 以降であることを確認します。application.confのhttp.portパラメーターを変更してポートを変更します。chmod +x bin/cerebroを実行して、bin/cerebroスクリプトに実行権限を追加します。
問題 2:Elasticsearch クラスターへの接続失敗
考えられる原因:IP アドレスホワイトリストが設定されていない。Elasticsearch のエンドポイントまたはポートが正しくない。ECS セキュリティグループが必要なポートでのトラフィックを許可していない。ユーザー名またはパスワードが正しくない。
解決策:Alibaba Cloud Elasticsearch コンソールで IP アドレスホワイトリストの設定を確認します。
application.confファイルに正しいhostの値が含まれていることを確認します。ECS セキュリティグループがポート 9200 (Elasticsearch) およびポート 9000 (Cerebro) でのトラフィックを許可しているかどうかを確認します。ユーザー名とパスワードが正しいことを確認します。