このトピックでは、データ転送サービスを使用して OceanBase データベースから Kafka インスタンスにデータを同期する方法について説明します。
背景情報
Kafka は、広く利用されているパフォーマンス専有型の分散ストリームコンピューティングプラットフォームです。データ転送サービスは、自己管理型 Kafka インスタンスと、Oracle 互換モードまたは MySQL 互換モードの OceanBase データベースとの間のリアルタイムデータ同期をサポートし、メッセージ処理能力を拡張します。そのため、データ転送サービスは、リアルタイムのデータウェアハウス構築、データクエリ、レポート配信などのビジネスシナリオで広く利用されています。
前提条件
データ転送サービスには、クラウドリソースにアクセスするための権限が付与されている必要があります。詳細については、「データ転送のためのロールへの権限付与」をご参照ください。
ソース OceanBase データベースにデータ同期用の専用データベースユーザーを作成し、そのユーザーに対応する権限を付与している必要があります。詳細については、「データベースユーザーの作成」をご参照ください。
制限事項
同期できるのは物理テーブルのみです。
データ転送サービスは、Kafka 0.9、1.0、および 2.x をサポートしています。
データ同期中に、同期対象のソーステーブルの名前を変更し、新しい名前が同期範囲外になった場合、そのソーステーブルのデータはターゲット Kafka インスタンスに同期されません。
同期するテーブルの名前、およびテーブル内の列の名前に中国語文字を含めることはできません。
データ転送サービスは、オブジェクトのデータベース名、テーブル名、および列名が ASCII エンコードされており、特殊文字が含まれていない場合にのみ、そのオブジェクトの移行をサポートします。特殊文字とは、改行、スペース、および次の文字を指します:. | " ' ` ( ) = ; / & \。
データ転送サービスは、スタンバイの OceanBase データベースをソースとしてサポートしていません。
注意事項
ソースが OceanBase データベースで DDL 同期が有効になっているデータ同期タスクにおいて、ソースデータベースのテーブルに対して
RENAME操作を実行した場合、増分同期中のデータ損失を避けるために、タスクを再起動することを推奨します。OceanBase データベース V4.x を使用し、増分同期を選択した場合、生成列に STORED 属性を指定する必要があります。この属性を指定しないと、増分ログに生成列の情報が保存されず、増分同期でデータエラーが発生する可能性があります。
更新された行にラージオブジェクト (LOB) カラムが含まれる場合は、次の点にご注意ください:
LOB カラムが更新された場合、
UPDATEまたはDELETE操作前の LOB カラムに格納されていた値は使用しないでください。次のデータ型は LOB カラムに格納されます:JSON、GIS、XML、ユーザー定義型 (UDT)、および LONGTEXT や MEDIUMTEXT などの TEXT。
LOB カラムが更新されない場合、
UPDATEまたはDELETE操作前後の LOB カラムに格納されている値は NULL になります。
ノード間、またはクライアントとサーバー間の時計が同期していない場合、増分同期中のレイテンシーが不正確になることがあります。
たとえば、時計が標準時より進んでいる場合、レイテンシーは負の値になることがあります。時計が標準時より遅れている場合、レイテンシーは正の値になることがあります。
タスクのデータ転送が再開されると、Kafka インスタンス内で一部のデータ (直近1分以内) が重複する可能性があります。そのため、下流システムでの重複排除が必要です。
OceanBase データベースから Kafka インスタンスにデータを同期する際、ソースで一意なインデックスを作成する文の実行に失敗した場合、Kafka インスタンスは一意なインデックスの作成と削除の DDL 文を消費します。下流で一意なインデックスを作成する DDL 文の実行に失敗した場合は、この例外を無視してください。
データ同期タスクの作成時に [増分同期] のみを選択した場合、データ転送サービスは、ソースデータベースのローカル増分ログを少なくとも 48 時間保持することを要求します。
データ同期タスクの作成時に [完全同期] と [増分同期] を選択した場合、データ転送サービスは、ソースデータベースのローカル増分ログを少なくとも 7 日間保持することを要求します。そうしないと、データ転送サービスが増分ログを取得できず、データ同期タスクが失敗したり、ソースとターゲットのデータが不整合になったりする可能性があります。
サポートされるソースおよびターゲットのインスタンスタイプ
次の表では、OB_MySQL は MySQL 互換モードの OceanBase データベースを、OB_Oracle は Oracle 互換モードの OceanBase データベースを表します。
ソース | ターゲット |
OB_MySQL (OceanBase クラスターインスタンス) | Kafka (Alibaba Cloud 上の Kafka インスタンス) |
OB_MySQL (OceanBase クラスターインスタンス) | Kafka (VPC 内の自己管理型 Kafka インスタンス) |
OB_MySQL (OceanBase クラスターインスタンス) | Kafka (パブリックネットワーク上の Kafka インスタンス) |
OB_MySQL (サーバーレスインスタンス) | Kafka (Alibaba Cloud 上の Kafka インスタンス) |
OB_MySQL (サーバーレスインスタンス) | Kafka (VPC 内の自己管理型 Kafka インスタンス) |
OB_MySQL (サーバーレスインスタンス) | Kafka (パブリックネットワーク上の Kafka インスタンス) |
OB_Oracle (OceanBase クラスターインスタンス) | Kafka (Alibaba Cloud 上の Kafka インスタンス) |
OB_Oracle (OceanBase クラスターインスタンス) | Kafka (VPC 内の自己管理型 Kafka インスタンス) |
OB_Oracle (OceanBase クラスターインスタンス) | Kafka (パブリックネットワーク上の Kafka インスタンス) |
サポートされる DDL
CREATE TABLE重要作成されるテーブルは同期オブジェクトである必要があります。同期されたテーブルに対して
CREATE TABLE文を実行するには、まずこのテーブルに対してDROP TABLE文を実行します。ALTER TABLEDROP TABLETRUNCATE TABLE説明遅延削除では、同じトランザクションに同一の
TRUNCATE TABLEDDL 文が 2 つ含まれます。この場合、下流での消費に対してべき等性が実装されます。ALTER TABLE…TRUNCATE PARTITIONCREATE INDEXDROP INDEXCOMMENT ON TABLERENAME TABLE重要名前が変更されたテーブルは同期オブジェクトである必要があります。
操作手順
- ApsaraDB for OceanBase コンソールにログインし、データ同期タスクを購入します。
詳細については、「データ同期タスクの購入」をご参照ください。
[データ伝送] > [データ同期] を選択します。表示されたページで、データ同期タスクの [設定] をクリックします。

既存のタスクの構成を参照する場合は、[リファレンス構成] をクリックします。 詳細については、「データ同期タスクの構成の参照とクリア」をご参照ください。
[ソースとターゲットの選択] ページで、パラメーターを設定します。
パラメーター
説明
同期タスク名
数字と文字の組み合わせに設定することを推奨します。スペースを含めることはできず、長さは 64 文字を超えることはできません。
ソース
OceanBase データソースを作成済みの場合は、ドロップダウンリストから選択します。 それ以外の場合は、ドロップダウンリストで [新規データソース] をクリックし、右側に表示されるダイアログボックスで作成します。 パラメーターの詳細については、「OceanBase データソースの作成」をご参照ください。
重要ソースは、[インスタンスタイプ] が [OceanBase データベーステナントインスタンス] である OceanBase データベースであってはなりません。
ターゲット
Kafka データソースを作成済みの場合は、ドロップダウンリストから選択します。それ以外の場合は、ドロップダウンリストで [新規データソース] をクリックし、右側に表示されるダイアログボックスで作成します。詳細については、「Kafka データソースを作成する」をご参照ください。
タグ (オプション)
ドロップダウンリストからターゲットタグを選択します。 また、[タグの管理] をクリックして、タグを作成、変更、削除することもできます。 詳細については、「タグを使用してデータ同期タスクを管理する」をご参照ください。
[次へ] をクリックします。[同期タイプの選択] ページで、現在のデータ同期タスクの同期タイプを指定します。

サポートされている同期タイプは [完全同期] と [増分同期] です。 [増分同期] は [DML 同期] と [DDL 同期] をサポートしています。 サポートされている DML 操作は
INSERT、DELETE、およびUPDATEです。 必要に応じてオプションを選択できます。 詳細については、「DDL/DML 同期を設定する」をご参照ください。[次へ] をクリックします。[同期オブジェクトの選択] ページで、今回のデータ同期タスクで同期するオブジェクトを選択します。
[オブジェクトの指定] または [照合ルール] オプションを使用して、同期オブジェクトを指定できます。 このトピックでは、[オブジェクトの指定] オプションを使用して同期オブジェクトを指定する方法について説明します。 照合ルールの設定方法については、「照合ルールの設定と変更」をご参照ください。
説明[同期タイプの選択] ステップで [DDL 同期] を選択した場合は、一致ルールを使用して同期オブジェクトを選択することをお勧めします。これにより、一致ルールに合致するすべての新規オブジェクトが確実に同期されます。オブジェクトの指定を使用して同期オブジェクトを選択した場合、新規または名前が変更されたオブジェクトは同期されません。
OceanBase データベースから Kafka インスタンスにデータを同期する場合、複数のテーブルから複数の Topic にデータを同期できます。
[同期オブジェクトの選択] セクションで、[オブジェクトの指定] を選択します。
左側のペインで、同期するオブジェクトを選択します。
[>] をクリックします。
[オブジェクトを Topic にマッピング] ダイアログボックスで [既存の Topic] ドロップダウンリストをクリックし、目的の Topic を選択します。

[OK] をクリックします。
データ転送サービスでは、テキストを使用してオブジェクトをインポートできます。また、オブジェクトの Topic を変更したり、行フィルターを設定したり、単一またはすべてのオブジェクトを削除したりすることもできます。ターゲットデータベースのオブジェクトは、Topic > データベース > テーブルの構造でリストされます。
説明[一致ルール] を選択して同期オブジェクトを指定すると、指定した一致ルールの構文に基づいてオブジェクト名の変更が実装されます。 操作エリアでは、フィルター条件の設定と、シャーディング列および同期する列の選択のみを行うことができます。 詳細については、「一致ルールの設定と変更」をご参照ください。

操作
説明
オブジェクトのインポート
右側のリストで、右上隅にある [オブジェクトのインポート] をクリックします。
表示されるダイアログボックスで、[OK] をクリックします。
重要この操作は以前の選択を上書きします。注意して進めてください。
[同期オブジェクトのインポート] ダイアログボックスで、同期するオブジェクトをインポートします。 CSV ファイルをインポートして、行フィルター条件、フィルター列、およびシャーディング列を設定できます。詳細については、「同期オブジェクトの設定のダウンロードとインポート」をご参照ください。
[検証] をクリックします。
検証が成功したら、[OK] をクリックします。
Topic の変更
データ転送サービスでは、ターゲットのオブジェクトの Topic を変更できます。詳細については、「Topic の変更」をご参照ください。
設定の構成
WHERE句を使用して行ごとにデータをフィルタリングし、シャーディング列と同期する列を選択できます。[設定] ダイアログボックスでは、以下の操作を実行できます。
[行フィルター] セクションで、標準 SQL の
WHERE句を指定し、行単位でデータをフィルターします。詳細については、「SQL 条件を使用してデータをフィルターする」をご参照ください。[シャーディングカラム] ドロップダウンリストから、使用するシャーディングカラムを選択します。複数のフィールドをシャーディングカラムとして選択できます。このパラメーターは任意です。
特に指定がない限り、プライマリキーをシャーディング列として選択します。プライマリキーが負荷分散されていない場合は、潜在的なパフォーマンスの問題を避けるために、一意の識別子を持つ負荷分散されたフィールドをシャーディング列として選択します。シャーディング列は次の目的で使用できます:
負荷分散:ターゲットテーブルが同時書き込みをサポートしている場合、メッセージを送信するために使用されるスレッドは、シャーディング列に基づいて認識できます。
順序性:データ転送サービスは、シャーディング列の値が同じであれば、メッセージが順序通りに受信されることを保証します。順序性は、列に対する DML 文の実行順序を指定します。
[列の選択] セクションで、同期する列を選択します。 詳細については、「列のフィルタリング」をご参照ください。
1つまたはすべてのオブジェクトの削除
データ転送サービスでは、データマッピング中に右側のリストに追加された単一またはすべての同期オブジェクトを削除できます。
単一の同期オブジェクトの削除
右側のリストで、削除する同期オブジェクトにマウスカーソルを合わせ、[削除] をクリックします。
すべての同期オブジェクトの削除
右側のリストの右上で、[すべて削除] をクリックします。表示されるダイアログボックスで [OK] をクリックして、すべての同期オブジェクトを削除します。
[次へ] をクリックします。[同期オプション] ページで、パラメーターを設定します。
完全同期
以下の表では、[同期タイプの選択] ページで [フル同期] を選択した場合にのみ表示されるフル同期パラメーターについて説明します。
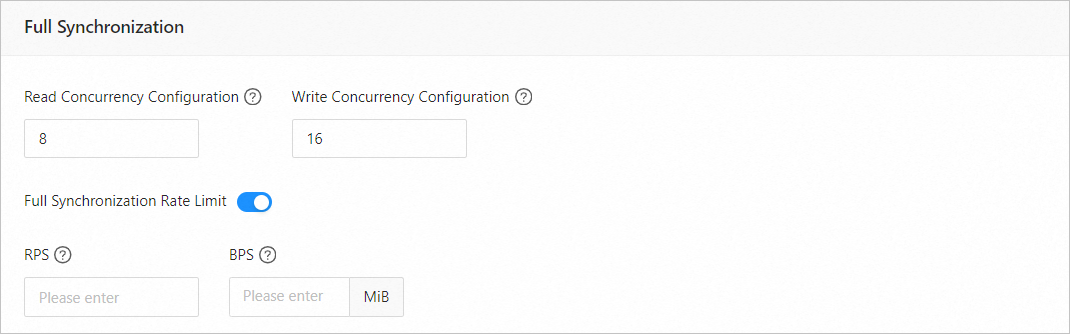
パラメーター
説明
読み取り同時実行数
完全同期中にソースからデータを読み取るための同時実行数。最大値は 512 です。高い同時実行数はソースに過度の負荷をかけ、ビジネスに影響を与える可能性があります。
書き込み同時実行数
完全同期中にターゲットにデータを書き込むための同時実行数。最大値は 512 です。高い書き込み同時実行数はターゲットに過度の負荷をかけ、ビジネスに影響を与える可能性があります。
完全同期のレート制限
必要に応じて完全同期のレートを制限するかどうかを選択できます。完全同期のレートを制限することを選択した場合、1秒あたりのレコード数 (RPS) と1秒あたりのバイト数 (BPS) を指定する必要があります。RPS は、完全同期中にターゲットに同期される1秒あたりの最大データ行数を指定し、BPS は、完全同期中にターゲットに同期される1秒あたりの最大データ量をバイト単位で指定します。
説明ここで指定された RPS と BPS の値は速度制限のためだけです。実際の完全同期パフォーマンスは、ソースとターゲットの設定やインスタンス仕様などの要因に左右されます。
増分同期
次の表は、[同期タイプの選択] ページで [増分同期] を選択した場合にのみ表示される増分同期パラメーターについて説明しています。
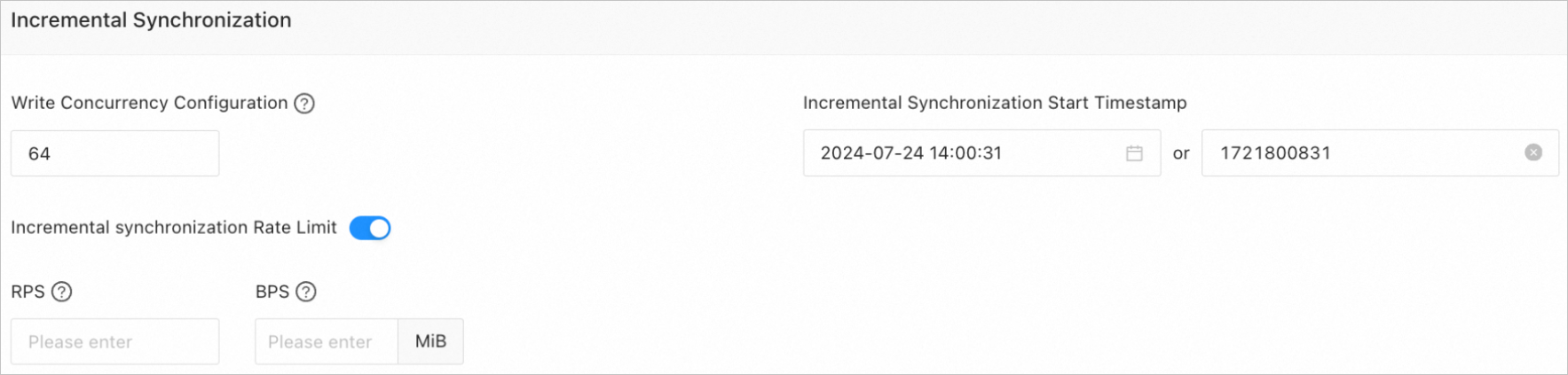
パラメーター
説明
書き込み同時実行数
増分同期中にターゲットにデータを書き込むための同時実行数。最大値は 512 です。高い書き込み同時実行数はターゲットに過度の負荷をかけ、ビジネスに影響を与える可能性があります。
増分同期のレート制限
必要に応じて増分同期のレートを制限するかどうかを選択できます。増分同期のレートを制限することを選択した場合、RPS と BPS を指定する必要があります。RPS は、増分同期中にターゲットに同期される1秒あたりの最大データ行数を指定し、BPS は、増分同期中にターゲットに同期される1秒あたりの最大データ量をバイト単位で指定します。
説明ここで指定された RPS と BPS の値は速度制限のためだけです。実際の増分同期パフォーマンスは、ソースとターゲットの設定やインスタンス仕様などの要因に左右されます。
増分同期の開始タイムスタンプ
[完全同期] を選択した場合、このパラメーターは使用できません。
[増分同期] を選択し、[完全同期] を選択していない場合は、データの同期を開始する時点を指定します。デフォルト値は現在のシステム時刻です。詳細については、「増分同期のタイムスタンプを設定する」をご参照ください。
詳細パラメーター

パラメーター
説明
シリアル化方式
ターゲット Kafka インスタンスにデータを同期するためのメッセージフォーマット。有効な値は [Default]、[Canal]、[DataWorks] (バージョン 2.0 対応)、[SharePlex]、[DefaultExtendColumnType]、[Debezium]、[DebeziumFlatten]、[DebeziumSmt]、および [Avro] です。詳細については、「データフォーマット」をご参照ください。
重要MySQL 互換モードの OceanBase データベースのみが、[Debezium]、[DebeziumFlatten]、[DebeziumSmt]、および [Avro] をサポートします。
メッセージフォーマットが [DataWorks] に設定されている場合、DDL 操作
COMMENT ON TABLEおよびALTER TABLE…TRUNCATE PARTITIONは同期されません。
パーティション分割ルール
OceanBase データベースから Kafka Topic にデータを同期するためのルールです。データ伝送サービスは、[Hash]、[Table]、および [One] をサポートしています。さまざまなシナリオにおける DDL 文の配信と例の詳細については、以下の説明をご参照ください。
ハッシュでは、データ伝送サービスはプライマリキーまたはシャーディング列の値に基づいてハッシュアルゴリズムを使用し、Kafka Topic のパーティションを選択します。
[テーブル] は、データ転送サービスがテーブル内のすべてのデータを同じパーティションに配信し、テーブル名をハッシュキーとして使用することを示します。
[One] は、順序性を保証するために、JSON メッセージが Topic 配下のパーティションに配信されることを示します。
業務システム識別子 (オプション)
データのソースである業務システムを識別します。このパラメーターは、[シリアル化方式] に [DataWorks] を選択した場合にのみ表示されます。業務システム識別子は 1~20 文字です。
次の表は、さまざまなシナリオでの DDL 文の配信について説明しています。
パーティション分割ルール
複数のテーブルを含む DDL 文
(例:RENAME TABLE)
不明なテーブルを含む DDL 文
(例:DROP INDEX)
単一のテーブルを含む DDL 文
Hash
DDL 文は、関連するテーブルに関連付けられた Topic のすべてのパーティションに配信されます。
DDL 文が 3 つのテーブル A、B、C を含むと仮定します。A が Topic 1 に関連付けられ、B が Topic 2 に関連付けられ、C が現在のタスクに関与していない場合、DDL 文は Topic 1 と Topic 2 のすべてのパーティションに配信されます。
DDL 文は、現在のタスクのすべての Topic のすべてのパーティションに配信されます。
DDL 文がデータ転送サービスによって識別できないと仮定します。現在のタスクに 3 つの Topic がある場合、DDL 文はこれら 3 つの Topic のすべてのパーティションに配信されます。
DDL 文は、テーブルに関連付けられた Topic のすべてのパーティションに配信されます。
Table
DDL 文は、テーブルに関連付けられた Topic の特定のパーティションに配信されます。パーティションは、関連するテーブル名のハッシュ値に対応します。
DDL 文が 3 つのテーブル A、B、C を含むと仮定します。A が Topic 1 に関連付けられ、B が Topic 2 に関連付けられ、C が現在のタスクに関与していない場合、DDL 文は Topic 1 と Topic 2 の関連するテーブル名のハッシュ値に対応するパーティションに配信されます。
DDL 文は、現在のタスクのすべての Topic のすべてのパーティションに配信されます。
DDL 文がデータ転送サービスによって識別できないと仮定します。現在のタスクに 3 つの Topic がある場合、DDL 文はこれら 3 つの Topic のすべてのパーティションに配信されます。
DDL 文は、テーブルに関連付けられた Topic のパーティションに配信されます。
One
DDL 文は、テーブルに関連付けられた Topic の固定パーティションに配信されます。
DDL 文が 3 つのテーブル A、B、C を含むと仮定します。A が Topic 1 に関連付けられ、B が Topic 2 に関連付けられ、C が現在のタスクに関与していない場合、DDL 文は Topic 1 と Topic 2 の固定パーティションに配信されます。
DDL 文は、現在のタスクのすべての Topic の固定パーティションに配信されます。
DDL 文がデータ転送サービスによって識別できないと仮定します。現在のタスクに 3 つの Topic がある場合、DDL 文はこれら 3 つの Topic の固定パーティションに配信されます。
DDL 文は、テーブルに関連付けられた Topic の固定パーティションに配信されます。
[事前チェック] をクリックします。
事前チェック中に、データ伝送サービスはソースとターゲット間の接続を検出します。事前チェック中にエラーが返された場合は、次の操作を実行できます。
問題を特定してトラブルシューティングし、再度事前チェックを実行します。
失敗した事前チェック項目の「操作」列にある[スキップ]をクリックします。操作による影響を確認するダイアログボックスで、[OK]をクリックします。
事前チェックに合格すると、[タスクの開始] をクリックします。
今すぐタスクを開始する必要がない場合は、[保存] をクリックします。タスクは、[同期タスク] ページで手動で開始することも、後でバッチ操作で開始することもできます。バッチ操作の詳細については、「データ同期タスクでバッチ操作を実行する」をご参照ください。
データ転送サービスでは、同期タスクの実行中に同期オブジェクトを変更できます。詳細については、「同期オブジェクトとそのフィルター条件の表示と変更」をご参照ください。データ同期タスクが開始されると、選択した同期タイプに基づいて実行されます。詳細については、「データ同期タスクの詳細の表示」をご参照ください。
データ同期タスクでネットワーク障害またはプロセスのスロースタートが原因で実行例外が発生した場合、同期タスクの