Use Data Transmission Service (DTS) to continuously synchronize data from a self-managed SQL Server database hosted on Elastic Compute Service (ECS) to an AnalyticDB for PostgreSQL instance. DTS supports schema synchronization, full data synchronization, and incremental data synchronization in a single task.
When not to use DTS
If the source ApsaraDB RDS for SQL Server instance meets any of the following conditions, use the backup feature of ApsaraDB RDS for SQL Server instead. For details, see Migrate data from a self-managed database to an ApsaraDB RDS for SQL Server instance.
| Condition | Threshold |
|---|---|
| Number of databases | More than 10 |
| Log backup interval (single database) | Less than 1 hour |
| DDL statements per hour (single database) | More than 100 |
| Log write rate (single database) | 20 MB/s or higher |
| Tables requiring Change Data Capture (CDC) | More than 1,000 |
| Table types present | Heap tables, tables without primary keys, compressed tables, or tables with computed columns |
Run the following SQL statements to check whether the source database contains unsupported table types:
-
Check for heap tables:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.indexes WHERE index_id = 0); -
Check for tables without primary keys:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id NOT IN (SELECT parent_object_id FROM sys.objects WHERE type = 'PK'); -
Check for primary key columns not in clustered index columns:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id WHERE t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN ( SELECT pk_columns.object_id FROM ( SELECT sic.object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id = sis.object_id AND sic.index_id = sis.index_id AND sis.is_primary_key = 'true' ) pk_columns LEFT JOIN ( SELECT sic.object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id = sis.object_id AND sic.index_id = sis.index_id AND sis.index_id = 1 ) cluster_columns ON pk_columns.object_id = cluster_columns.object_id WHERE pk_columns.column_id != cluster_columns.column_id ); -
Check for compressed tables:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.objects t, sys.schemas s, sys.partitions p WHERE s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id = p.object_id AND p.data_compression != 0; -
Check for tables with computed columns:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.columns WHERE is_computed = 1);
If any query returns rows, those tables require special handling or may affect your choice of incremental synchronization mode.
Prerequisites
Before you begin, make sure that:
-
The SQL Server version is supported by DTS. For supported versions, see Overview of data synchronization scenarios.
-
The destination AnalyticDB for PostgreSQL instance is created. For instructions, see Create an instance.
-
The available storage space of the destination instance is larger than the total size of the data in the source database.
Supported operations
DML: INSERT, UPDATE, DELETE
DDL:
| Statement | Notes |
|---|---|
| CREATE TABLE | Partitioned tables and tables that contain functions are not synchronized. |
| ADD COLUMN, DROP COLUMN | |
| DROP TABLE | |
| CREATE INDEX, DROP INDEX |
DTS does not synchronize DDL operations that contain user-defined types or transactional DDL operations.
Limitations
Source database limits
-
Tables must have PRIMARY KEY or UNIQUE constraints with all fields unique; otherwise, the destination database may contain duplicate records.
-
When selecting tables as sync objects and editing them in the destination, a single task can synchronize up to 5,000 tables. For more tables, configure multiple tasks or synchronize the entire database.
-
A single task can synchronize up to 10 databases. For more than 10 databases, configure multiple tasks.
-
Transaction log retention requirements:
-
Incremental sync only: logs must be retained for more than 24 hours.
-
Full + incremental sync: logs must be retained for at least 7 days.
-
After full synchronization completes, the retention period can be reduced to more than 24 hours.
-
-
If CDC is enabled for the tables to be synchronized:
-
The
srvnamefield in thesys.sysserversview must match the return value of theSERVERPROPERTYfunction. -
For self-managed SQL Server databases, the database owner must be the
sauser. -
For ApsaraDB RDS for SQL Server databases, the database owner must be the
sqlsauser. -
Enterprise Edition requires SQL Server 2008 or later.
-
Standard Edition requires SQL Server 2016 SP1 or later.
-
SQL Server 2017 (Standard or Enterprise Edition) is not recommended; update to a later version.
-
Other limits
-
DTS supports initial schema synchronization for schemas, tables, views, functions, and procedures. Source and destination databases are heterogeneous — data types do not have a one-to-one mapping. Evaluate the impact of data type conversion before synchronizing. For type mappings, see Data type mappings for schema synchronization.
-
DTS does not synchronize the schemas of assemblies, service brokers, full-text indexes, full-text catalogs, distributed schemas, distributed functions, CLR stored procedures, CLR scalar-valued functions, CLR table-valued functions, internal tables, systems, or aggregate functions.
-
DTS does not synchronize data of these types: TIMESTAMP, CURSOR, ROWVERSION, HIERACHYID, SQL_VARIANT, SPATIAL GEOMETRY, SPATIAL GEOGRAPHY, or TABLE.
-
DTS does not synchronize tables with computed columns.
-
If CDC is enabled for more than 1,000 tables in a single task, the precheck fails.
-
Reindexing is not allowed during incremental synchronization; doing so may cause the task to fail or result in data loss.
-
During full synchronization, concurrent INSERT operations cause fragmentation in the destination tables. After synchronization, the destination tablespace will be larger than the source.
-
Write data to the destination database only through DTS during synchronization. Using other tools to write data simultaneously may cause data loss or inconsistency.
Schema synchronization behavior
-
DTS synchronizes foreign keys from source to destination.
-
During full and incremental synchronization, DTS temporarily disables foreign key constraint checking and cascade operations at the session level. If you perform cascade UPDATE or DELETE operations on the source during synchronization, data inconsistency may occur.
Choose an incremental synchronization mode
DTS provides two modes for synchronizing incremental data from SQL Server. The mode you choose affects which table types are supported and whether DTS modifies the source database.
| Hybrid log and CDC mode | Log-based mode | |
|---|---|---|
| Full name | Log-based parsing for non-heap tables and CDC-based incremental synchronization for heap tables | Incremental synchronization based on logs of source database |
| Supports heap tables | Yes | No |
| Supports tables without primary keys | Yes | No |
| Supports compressed tables | Yes | No |
| Supports tables with computed columns | Yes | No |
| Source database intrusion | Yes — DTS creates a trigger (dts_cdc_sync_ddl), a heartbeat table (dts_sync_progress), and a DDL history table (dts_cdc_ddl_history) in the source database, and enables CDC for the source database and specific tables. |
No — DTS adds a heartbeat table (dts_log_heart_beat) to the source database only. |
How to choose:
-
If your source tables include heap tables, tables without primary keys, compressed tables, or tables with computed columns, use hybrid log and CDC mode.
-
If your source tables all have clustered indexes containing primary key columns and you want to minimize changes to the source database, use log-based mode.
Billing
| Synchronization type | Fee |
|---|---|
| Schema synchronization + full data synchronization | Free |
| Incremental data synchronization | Charged. See Billing overview. |
Supported synchronization topologies
-
One-way one-to-one synchronization
-
One-way one-to-many synchronization
-
One-way many-to-one synchronization
For details, see Synchronization topologies.
Required permissions
| Database | Required permissions |
|---|---|
| Self-managed SQL Server | sysadmin fixed server role. See CREATE USER and GRANT (Transact-SQL). |
| AnalyticDB for PostgreSQL | LOGIN; SELECT, CREATE, INSERT, UPDATE, and DELETE on destination tables; CONNECT and CREATE on the destination database; CREATE on destination schemas; COPY (memory-based batch copy). The initial account of the instance has these permissions by default. See Create a database account and Manage users and permissions. |
Prepare the source SQL Server database
Configure the SQL Server recovery model and create backups before setting up the DTS task. These steps require sysadmin privileges.
If you are synchronizing incremental data from multiple databases, repeat all steps in this section for each database.
Set the recovery model to full
Run the following statement on the source database. Alternatively, use SQL Server Management Studio (SSMS) — see View or Change the Recovery Model of a Database (SQL Server).
USE master;
GO
ALTER DATABASE <database_name> SET RECOVERY FULL WITH ROLLBACK IMMEDIATE;
GOReplace <database_name> with the name of the source database. Example:
USE master;
GO
ALTER DATABASE mytestdata SET RECOVERY FULL WITH ROLLBACK IMMEDIATE;
GOCreate a database backup
Skip this step if you have already created a full backup.
BACKUP DATABASE <database_name> TO DISK='<backup_file_path>';
GO| Placeholder | Description | Example |
|---|---|---|
<database_name> |
Name of the source database | mytestdata |
<backup_file_path> |
Full path and file name for the backup file | D:\backup\dbdata.bak |
Example:
BACKUP DATABASE mytestdata TO DISK='D:\backup\dbdata.bak';
GOCreate a log backup
BACKUP LOG <database_name> TO DISK='<backup_file_path>' WITH INIT;
GOExample:
BACKUP LOG mytestdata TO DISK='D:\backup\dblog.bak' WITH INIT;
GOConfigure the synchronization task
Step 1: Open the DTS console
Go to the Data Synchronization page in the DTS console.DTS console
Alternatively, log on to the Data Management (DMS) console. In the top navigation bar, click DTS. In the left-side navigation pane, choose DTS (DTS) > Data Synchronization.
Step 2: Select a region
In the upper-left corner, select the region where the synchronization instance resides.
Step 3: Create a task and configure databases
Click Create Task. Configure the source and destination database connections:
Source database
| Parameter | Value |
|---|---|
| Database type | SQL Server |
| Access method | Self-managed Database on ECS |
| Instance region | Region of the ECS instance hosting SQL Server |
| ECS instance ID | ID of the ECS instance |
| Database account | Account with sysadmin privileges |
| Database password | Password for the account |
| Encryption | Select Non-encrypted or SSL-encrypted |
Destination database
| Parameter | Value |
|---|---|
| Database type | AnalyticDB for PostgreSQL |
| Access method | Alibaba Cloud Instance |
| Instance region | Region of the destination instance |
| Instance ID | ID of the destination AnalyticDB for PostgreSQL instance |
| Database name | Name of the target database |
| Database account | Account with the required permissions |
| Database password | Password for the account |
Step 4: Test connectivity and configure network access
Click Test Connectivity and Proceed. DTS checks the connection to both databases and configures network access automatically where possible:
-
Alibaba Cloud database instances: DTS automatically adds DTS server CIDR blocks to the instance whitelist.
-
Self-managed databases on ECS: DTS automatically adds DTS server CIDR blocks to the ECS security group rules. Manually add those CIDR blocks to the whitelist of the self-managed database on the ECS instance.
-
On-premises or third-party cloud databases: Manually add DTS server CIDR blocks to the database whitelist. For the CIDR blocks to add, see Add the CIDR blocks of DTS servers to the security settings of on-premises databases.
-
Adding DTS server CIDR blocks to whitelists or security group rules exposes those endpoints to the network. Take precautions: use strong credentials, restrict exposed ports, authenticate API calls, audit whitelist entries regularly, and consider using Express Connect, VPN Gateway, or Smart Access Gateway for private connectivity.
-
After the DTS task is complete or released, remove the DTS CIDR blocks from whitelists and security group rules. Remove any IP address whitelist group whose name contains
dtsfrom the Alibaba Cloud instance whitelist and the ECS security group rules, and remove DTS CIDR blocks from the self-managed database whitelist.
Step 5: Select objects and configure settings
Basic settings
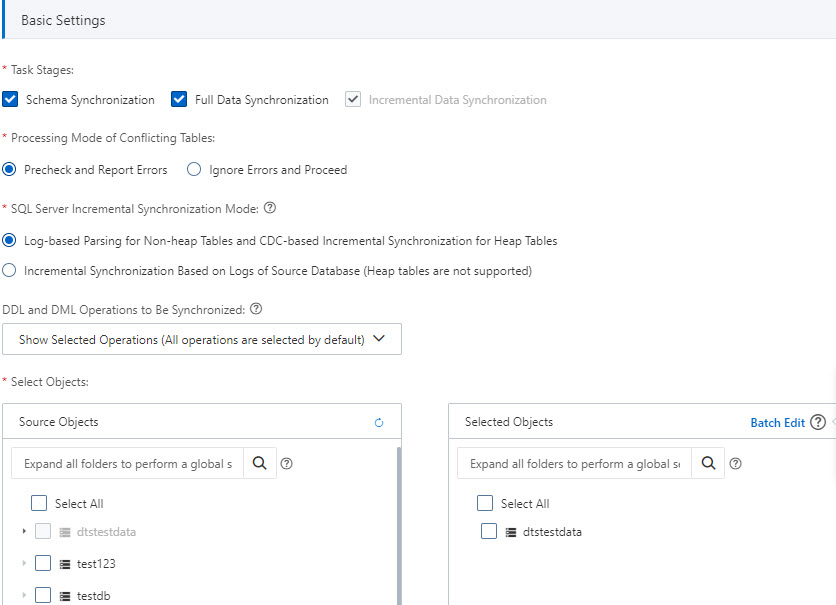
| Parameter | Description |
|---|---|
| Task stages | Select Schema Synchronization and Full Data Synchronization in addition to the default Incremental Data Synchronization. Full data synchronization loads historical data into the destination before incremental sync begins. |
| Processing mode of conflicting tables | Precheck and Report Errors: fails the precheck if the destination already contains tables with the same names as the source. Use object name mapping to resolve naming conflicts. Ignore Errors and Proceed: skips the precheck. During full sync, existing records with matching primary keys are retained in the destination. During incremental sync, they are overwritten. |
| DDL and DML operations to be synchronized | Select the operations to synchronize. For supported operations, see Supported operations. To select operations for a specific table, right-click the table in Selected Objects and choose the operations. |
| SQL Server incremental synchronization mode | Select a mode based on your table types and source database constraints. For guidance, see Choose an incremental synchronization mode. |
| Select objects | In Source Objects, select the objects to synchronize and click |
| Rename databases and tables | To rename a single object, right-click it in Selected Objects. To rename multiple objects at once, click Batch Edit. See Map object names. |
| Filter data | Specify WHERE conditions to filter rows. See Use SQL conditions to filter data. |
Advanced settings
| Parameter | Description |
|---|---|
| Set alerts | Configure alerting for task failures or synchronization latency exceeding a threshold. Select Yesalert notifications to specify an alert threshold and contacts. See Configure monitoring and alerting. |
| Retry time for failed connections | The time range in which DTS retries a failed connection after the task starts. Range: 10–1440 minutes. Default: 720 minutes. Set this to more than 30 minutes. If the shortest retry time is set across multiple tasks sharing the same source or destination database, that shortest value takes precedence. Note
If DTS retries a connection, you are charged for the DTS instance. Specify the retry time range based on your business requirements, or release the DTS instance promptly after the source and destination instances are released. |
Step 6: Configure primary key and distribution key columns
Click Next: Configure Database and Table Fields. Set the primary key columns and distribution key columns for each destination table.

Step 7: Run the precheck
Click Next: Save Task Settings and Precheck.
The task cannot start until it passes the precheck.
For any failed item, click View Details, fix the issue, and click Precheck Again.
For an alert item that you can safely ignore, click Confirm Alert Details next to the item, then click Ignore > OK > Precheck Again. Ignoring alerts may result in data inconsistency.
Step 8: Wait for the precheck to complete
Wait until the success rate reaches 100%, then click Next: Purchase Instance.
Step 9: Purchase the synchronization instance
Configure billing and instance class:
| Parameter | Description |
|---|---|
| Billing method | Subscription: pay upfront; cost-effective for long-term use. Pay-as-you-go: billed hourly; suitable for short-term use. Release the instance when no longer needed to avoid ongoing charges. |
| Instance class | Select a class based on the required synchronization throughput. See Specifications of data synchronization instances. |
| Subscription duration | If using subscription billing, select 1–9 months or 1–3 years. |
Step 10: Accept the service terms
Read and select the checkbox for Data Transmission Service (Pay-as-you-go) Service Terms.
Step 11: Start the task
Click Buy and Start. The task appears in the task list. Monitor the synchronization progress from there.
What's next
-
Map object names — rename source objects in the destination database
-
Synchronization topologies — set up one-to-many or many-to-one topologies
-
Data type mappings for schema synchronization — review type conversion behavior
-
Billing overview — understand incremental sync charges