ワイドカラムモデルは、Bigtable または HBase のデータモデルに似ており、メタデータやビッグデータの格納など、さまざまなシナリオに適しています。 ワイドカラムモデルは、データをデータテーブルに格納します。 1 つのデータテーブルにはペタバイトレベルのデータを格納でき、数千万クエリ/秒 (QPS) をサポートします。 データテーブルはスキーマフリーであり、ワイドカラム、バージョンの最大数、および生存時間 (TTL) 管理をサポートしています。 また、データテーブルは、自動採番主キー列、ローカルトランザクション、アトミックカウンター、フィルター、条件付き更新などの機能もサポートしています。
概要
Tablestore のワイドカラムモデルは、Bigtable または HBase のデータモデルに似ています。 ワイドカラムモデルは、行、列、および時間で定義される 3 次元構造で、データをデータテーブルに格納します。 データテーブルの各行には、異なる列を含めることができます。 データテーブルの属性列は、動的に追加または削除できます。 データテーブルを作成するときに、データテーブルの属性列に厳密なスキーマを定義する必要はありません。
コンポーネント
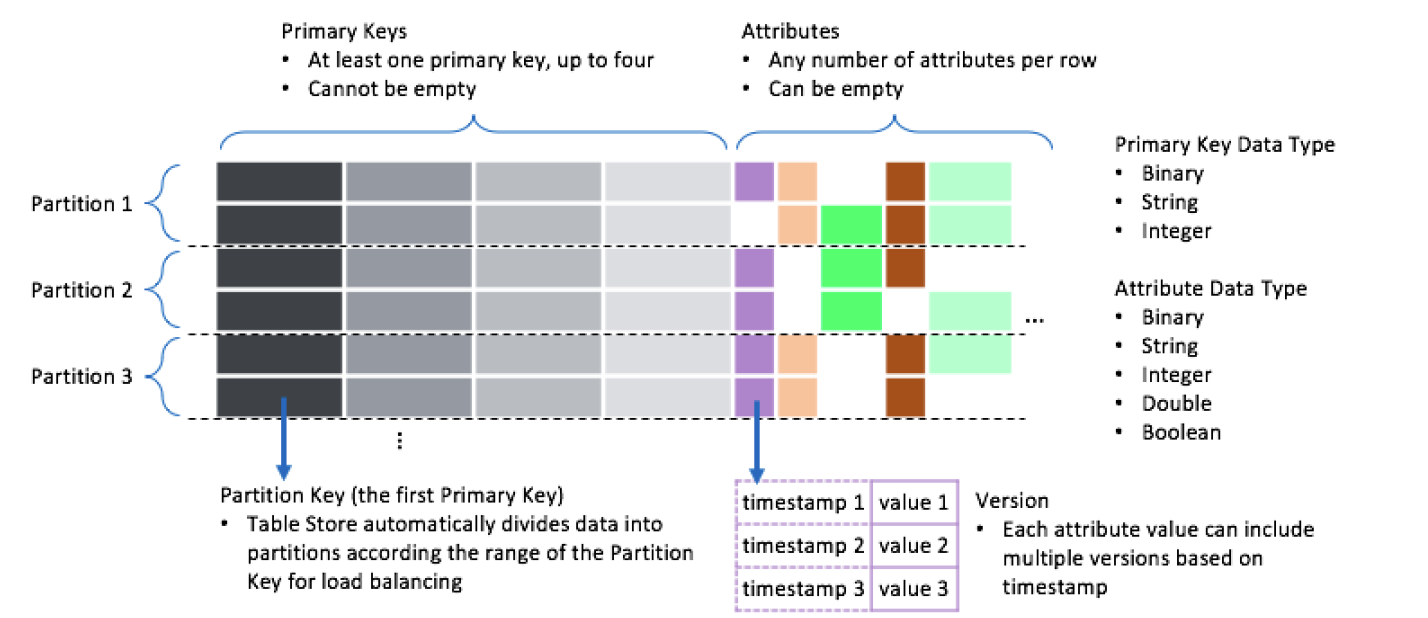
上の図は、ワイドカラムモデルのコンポーネントを示しています。 次の表に、コンポーネントについて説明します。
コンポーネント | 説明 |
プライマリキー | プライマリキーは、データテーブルの行を一意に識別します。 プライマリキーは、1 ~ 4 つのプライマリキー列で構成されます。 |
パーティションキー | 最初のプライマリキー列は、パーティションキーと呼ばれます。 Tablestore は、パーティションキー値に基づいてデータテーブルのデータをパーティション分割します。 同じパーティションキー値を共有する行は、データアクセスリクエストのバランスのとれた分散を確保するために、同じパーティションに割り当てられます。 |
属性列 | 行のプライマリキー列以外のすべての列は、属性列と呼ばれます。 各属性列には、異なるバージョンの値を含めることができます。 Tablestore は、各行に含めることができる属性列の数に制限を課していません。 |
バージョン | 属性列の各値には、一意のバージョン番号があります。 バージョン番号はタイムスタンプであり、これに基づいて属性列値の TTL を管理できます。 詳細については、「バージョン番号」をご参照ください。 |
データの型 | Tablestore は、String、Binary、Double、Integer、および Boolean のデータ型をサポートしています。 詳細については、「データ型」をご参照ください。 |
TTL | 各データテーブルの TTL を指定できます。 たとえば、データテーブルの TTL を 1 か月に設定した場合、Tablestore は、1 か月前にデータテーブルに書き込まれたデータを自動的に削除します。 詳細については、「TTL」をご参照ください。 |
バージョンの最大数 | データテーブルの各属性列の値の最大バージョン数を指定できます。 バージョンの最大数を使用して、各属性列の値のバージョン数を制御できます。 属性列の実際のバージョン数がバージョンの最大値を超えると、Tablestore は以前のバージョンを非同期的に削除します。 詳細については、「バージョンの最大数」をご参照ください。 |
コアコンポーネント
データテーブル、行、プライマリキー、および属性は、Tablestore のワイドカラムモデルのコアコンポーネントです。 データテーブルは行で構成されます。 各行は、プライマリキーと 1 つ以上の属性で構成されます。 最初のプライマリキー列は、パーティションキーと呼ばれます。
次の表に、プライマリキー、属性、およびパーティションキーについて説明します。
プライマリキー列と属性列でサポートされているデータ型の詳細については、「命名規則とデータ型」をご参照ください。
コンポーネント | 説明 |
プライマリキー | プライマリキーは、データテーブルの行を一意に識別します。 プライマリキーは、1 ~ 4 つのプライマリキー列で構成されます。 データテーブルを作成するときは、プライマリキー列の名前、データ型、およびシーケンスを含め、プライマリキー列を指定する必要があります。 Tablestore は、データテーブルの行のプライマリキー値に基づいて、データテーブルのデータにインデックスを付けます。 デフォルトでは、データテーブルの行は、プライマリキー値に基づいて昇順にソートされます。 |
パーティションキー | 最初のプライマリキー列は、パーティションキーと呼ばれます。 負荷分散を確実にするために、Tablestore は、行のパーティションキー値が属する範囲に基づいて、データの行を対応するパーティションとマシンに自動的に分散します。 同じパーティションキー値を共有する行は、同じパーティションに属します。 パーティションには、異なるパーティションキー値を持つ行が格納されている場合があります。 Tablestore は、特定のルールに基づいてパーティションを分割およびマージします。 説明 パーティションキー値は、データをパーティション分割するための基本単位です。 同じパーティションキー値を共有するデータは、さらに分割することはできません。 パーティションが大きすぎて分割できないのを防ぐために、同じパーティションキー値を共有するすべての行の合計サイズを最大 10 GB にすることをお勧めします。 パーティションキーの選択方法の詳細については、「テーブル操作」をご参照ください。 |
属性 | 1 つの行に複数の属性列を含めることができます。 行の属性列の数に制限はなく、各行の属性列は異なる場合があります。 行の属性列の値は空にすることができます。 複数の行の同じ属性列の値は、異なるデータ型にすることができます。 属性列には、複数のバージョンの値を格納できます。 属性列に保持できる値のバージョン数を指定できます。 また、属性列値の TTL 値を指定することもできます。 詳細については、「データバージョンと TTL」をご参照ください。 |
ワイドカラムモデルとリレーショナルモデルの違い
次の表に、ワイドカラムモデルとリレーショナルモデルの違いについて説明します。
モデル | 特性 |
ワイドカラムモデル | 3 次元構造 (行、列、および時間)、スキーマフリー、ワイドカラム、バージョンの最大数、および TTL 管理 |
リレーショナルモデル | 2 次元構造 (行と列) および固定スキーマ |
制限
ワイドカラムモデルの一般的な制限については、「制限」をご参照ください。
セカンダリインデックスまたは検索インデックスを使用してデータクエリを高速化する場合は、インデックスの制限に注意してください。 詳細については、「セカンダリインデックスの制限」および「検索インデックスの制限」をご参照ください。
SQL 文を使用してデータのクエリと分析を行う場合は、SQL クエリの制限に注意してください。 詳細については、「SQL の制限」をご参照ください。
機能
機能 | 説明 | 参照 |
テーブルの操作 | インスタンス内のすべてのデータテーブルをリストしたり、データテーブルを作成したり、データテーブルの構成をクエリおよび更新したり、データテーブルを削除したりできます。 | |
基本的なデータ操作 | PutRow、GetRow、UpdateRow、および DeleteRow 操作を呼び出して単一行の操作を実行したり、BatchWriteRow、BatchGetRow、および GetRange 操作を呼び出して複数行の操作を実行したりできます。 テーブル内の単一行または複数行の操作を実行する操作を呼び出すことで、テーブル内のデータを読み書きできます。 | |
バージョンの最大数と TTL | バージョンの最大数と TTL 機能を使用して、データのライフサイクルを管理し、ストレージ効率を最適化し、コストを削減できます。 | |
自動採番主キー列 | パーティションキーではないプライマリキー列を自動採番主キー列として指定できます。 自動採番主キー列を含むテーブルにデータを書き込む場合、自動採番主キー列の値を指定する必要はありません。 Tablestore は、自動採番主キー列の値を自動的に生成します。 自動採番主キー列に生成される値は一意であり、パーティション内で単調に増加します。 | |
条件付き更新 | 条件付き更新を使用する場合、テーブル内のデータは、条件が満たされた場合にのみ更新できます。 条件が満たされない場合、更新は失敗します。 | |
ローカルトランザクション | 同じパーティションキー値を共有するデータのローカルトランザクションを作成できます。 ローカルトランザクションでデータを読み書きし、ビジネス要件に基づいてローカルトランザクションをコミットまたは破棄できます。 | |
アトミックカウンター | アトミックカウンターを使用すると、列にアトミックカウンターを実装し、さまざまなトピックのページビュー (PV) 数など、オンライン アプリケーションのリアルタイム統計データを提供できます。 | |
フィルター | フィルターは、サーバー側で結果をソートします。 フィルター条件を満たす結果のみが返されます。 この機能により、転送されるデータ量が効果的に削減され、応答時間が短縮されます。 | |
セカンダリインデックス | データテーブルに 1 つ以上のインデックステーブルを作成し、インデックステーブルのプライマリキー列を使用してクエリを実行できます。 セカンダリインデックスは、グローバルセカンダリインデックスとローカルセカンダリインデックスに分類されます。
| |
検索インデックス | 検索インデックスは、転置インデックスと列のストアに基づいて、ビッグデータシナリオでの多次元データクエリと統計分析に使用されます。 検索インデックスは、非プライマリキー列に基づくクエリ、全文検索、プレフィックスクエリ、あいまい検索、ブールクエリ、ネストされたクエリ、ジオクエリなど、さまざまなクエリメソッドをサポートしています。 また、検索インデックスは、並列スキャンと複数の集約操作もサポートしています。 集約操作を実行して、行の最大値と最小値、行数と個別行数、合計、平均を取得し、特定の条件で結果をグループ化できます。 |
|
SQL クエリ | SQL クエリ機能は、複数のデータエンジンに統一されたアクセスインターフェイスを提供します。 SQL クエリ機能を使用して、Tablestore 内のデータに対して複雑なクエリと分析を効率的に実行できます。 また、インデックスと SQL クエリ機能を組み合わせて使用して、クエリを最適化することもできます。 | |
トンネルサービス | トンネルサービスは、フルモード、増分モード、および差分モードでデータをエクスポートおよび消費するために使用されるトンネルを提供します。 トンネルを作成すると、それを使用して、テーブルの履歴データと増分データを消費できます。 |
課金ルール
課金項目には、読み取りスループット、書き込みスループット、ストレージ使用量、およびインターネット経由のアウトバウンドトラフィックが含まれます。 詳細については、「課金概要」をご参照ください。
FAQ
参照
インスタンスデータのデータセンターレベルのディザスタリカバリを実装するには、ゾーン冗長ストレージ (ZRS) 冗長タイプのインスタンスを作成します。 詳細については、「ZRS」をご参照ください。
データストレージのセキュリティとネットワークアクセスセキュリティを確保するために、データテーブルを暗号化するか、VPC を Tablestore インスタンスにバインドして VPC 経由でのみアクセスできるようにすることができます。 詳細については、「データの暗号化」および「ネットワークセキュリティ管理」をご参照ください。
重要なデータが誤って削除されるのを防ぐために、データバックアップ機能を使用して重要なデータを定期的にバックアップできます。 詳細については、「Tablestore でデータをバックアップする」をご参照ください。
データテーブルの履歴データと増分データを消費するには、トンネルサービスを使用できます。 詳細については、「トンネルサービス」をご参照ください。
モニタリングメトリックのアラート通知を構成するには、CloudMonitor を使用できます。 詳細については、「モニタリングとアラート」をご参照ください。
データを可視化するには、DataV または Grafana を使用できます。 たとえば、DataV または Grafana を使用して、データをチャートに表示できます。 詳細については、「データの可視化」をご参照ください。