Tablestore では、SQL クエリ機能を使用してデータを効率的にクエリできます。 Tablestore コンソールでマッピングテーブルを作成した後、SELECT 文を実行して、マッピングテーブルが作成されたデータテーブル内のデータを効率的にクエリできます。
前提条件
RAM ユーザーとしてデータをクエリする場合、RAM ユーザーが作成され、すべての SQL 操作権限が RAM ユーザーに付与されます。 RAM ユーザーにアタッチされたカスタムポリシーで
"Action": "ots:SQL*"を設定することで、すべての SQL 操作権限を RAM ユーザーに付与できます。 詳細については、「RAM ポリシーを使用して RAM ユーザーに権限を付与する」をご参照ください。データテーブルが作成されている。
使用上の注意
SQL クエリ機能は、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)、中国 (香港)、日本 (東京)、シンガポール、マレーシア (クアラルンプール)、英国 (ロンドン)、米国 (シリコンバレー)、インドネシア (ジャカルタ)、ドイツ (フランクフルト)、SAU (リヤド - パートナーリージョン)、および米国 (バージニア) の各リージョンでご利用いただけます。
手順 1:マッピングテーブルを作成する
Tablestore コンソール にログオンします。
上部のナビゲーションバーで、リソースグループとリージョンを選択します。
[概要] ページで、管理するインスタンスの名前をクリックするか、インスタンスの [アクション] 列の [インスタンスの管理] をクリックします。
[SQL 文を実行してクエリする] タブで、マッピングテーブルを作成します。
説明SQL 文を直接記述してマッピングテーブルを作成することもできます。 詳細については、「テーブルのマッピングテーブルを作成する」および「多次元インデックスのマッピングテーブルを作成する」をご参照ください。
 アイコンをクリックします。説明
アイコンをクリックします。説明マッピングテーブルが作成されていない場合、[SQL 文を実行してクエリする] タブをクリックすると、[マッピングテーブルの作成] ダイアログボックスが表示されます。
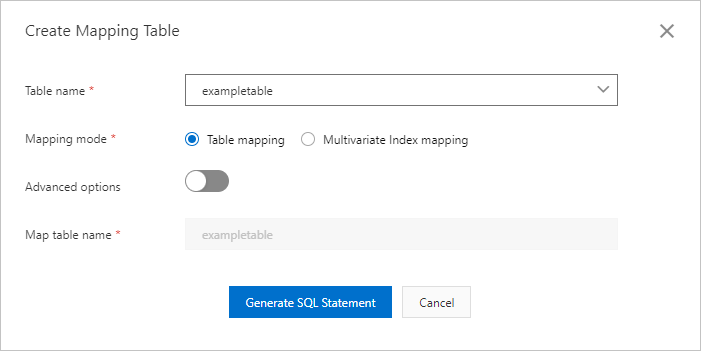
[マッピングテーブルの作成] ダイアログボックスで、パラメーターを設定します。 次の表にパラメーターを示します。
パラメーター
説明
テーブルの種類
マッピングテーブルを作成するテーブルの種類。有効な値:
[共通テーブル]: データテーブルのマッピングテーブルを作成します。 これはデフォルト値です。
[時系列テーブル]: 時系列テーブルのマッピングテーブルを作成します。
テーブル名
マッピングテーブルを作成するテーブルの名前。
マッピングモード
マッピングテーブルを作成するモード。 このパラメーターは、[テーブルの種類] パラメーターを [共通テーブル] に設定した場合にのみ使用できます。有効な値:
[テーブルのマッピングテーブル]: 既存のデータテーブルのマッピングテーブルを作成します。 これはデフォルト値です。
[多次元インデックスのマッピングテーブル]: 既存の多次元インデックスのマッピングテーブルを作成します。
詳細設定
マッピングテーブルの一貫性モードのオプションと、不正確な集約を有効にするかどうかを指定します。[詳細設定] をオンにすると、一貫性モードと不正確な集約のパラメーターを設定できます。 [マッピングモード] パラメーターを [テーブルのマッピングテーブル] に設定した場合のみ、詳細設定パラメーターを使用できます。
整合性モード
実行エンジンでサポートされている整合性モード。 このパラメーターは、[詳細設定] をオンにした場合にのみ使用できます。有効な値:
[結果整合性]: クエリ結果は結果整合性モードになります。 これはデフォルト値です。 データがテーブルに書き込まれてから数秒後にデータをクエリできます。
[強力な整合性]: クエリ結果は強力な整合性モードになります。 データがテーブルに書き込まれた直後にデータをクエリできます。
不正確な集計
集約操作の精度を損なうことによってクエリのパフォーマンスを向上させるかどうかを指定します。 このパラメーターは、[詳細設定] をオンにした場合にのみ使用できます。有効な値:
[はい]: 集約操作の精度を損なうことによってクエリのパフォーマンスを向上させます。 これはデフォルト値です。
[いいえ]: 集約操作の精度を損なうことによってクエリのパフォーマンスを向上させません。
多次元インデックス名
マッピングテーブルを作成する多次元インデックスの名前。 このパラメーターは、[マッピングモード] パラメーターを [多次元インデックスのマッピングテーブル] に設定した場合にのみ使用できます。
マッピングテーブル名
作成するマッピングテーブルの名前。
[テーブルの種類] パラメーターを [共通テーブル] に、[マッピングモード] パラメーターを [テーブルのマッピングテーブル] に設定した場合、マッピングテーブルの名前はデータテーブルの名前と同じで、変更できません。 テーブルの種類パラメーターを共通テーブルに、[マッピングモード] パラメーターを [多次元インデックスのマッピングテーブル] に設定した場合は、マッピングテーブルの名前を入力します。
[テーブルの種類] パラメーターを [時系列テーブル] に設定した場合は、ビジネス要件に基づいてマッピングテーブルの名前を入力します。 時系列テーブルのマッピングテーブルが作成されると、システムはマッピングテーブル名に
Time series table name::プレフィックスを自動的に追加します。
分析ストアを有効にする
分析ストア機能は、時系列データを長期間保存し、時系列データを分析するシナリオで使用されます。 分析ストア機能を使用すると、時系列データを低コストで保存し、時系列データを効率的にクエリおよび分析できます。 詳細については、「時系列分析ストア」をご参照ください。
このパラメーターは、[テーブルの種類] パラメーターで [時系列テーブル] を選択した場合にのみ使用できます。 デフォルトでは、[分析ストアを有効にする] はオフになっています。 ビジネス要件に基づいてパラメーターを設定します。
分析ストアを使用して時系列データを保存および分析しない場合は、[分析ストアを有効にする] パラメーターのデフォルト設定を保持します。
時系列データを低コストで保存するか、時系列データを効率的にクエリおよび分析する場合は、分析ストアが作成され、[分析ストアを有効にする] がオンになっていることを確認します。
重要分析ストア機能は、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口) の各リージョンでサポートされています。
[分析ストアを有効にする] がオンになっているマッピングテーブルを作成する場合、分析ストアを削除するときに、同時にマッピングテーブルを削除する必要があります。 そうしないと、分析ストアを削除できません。
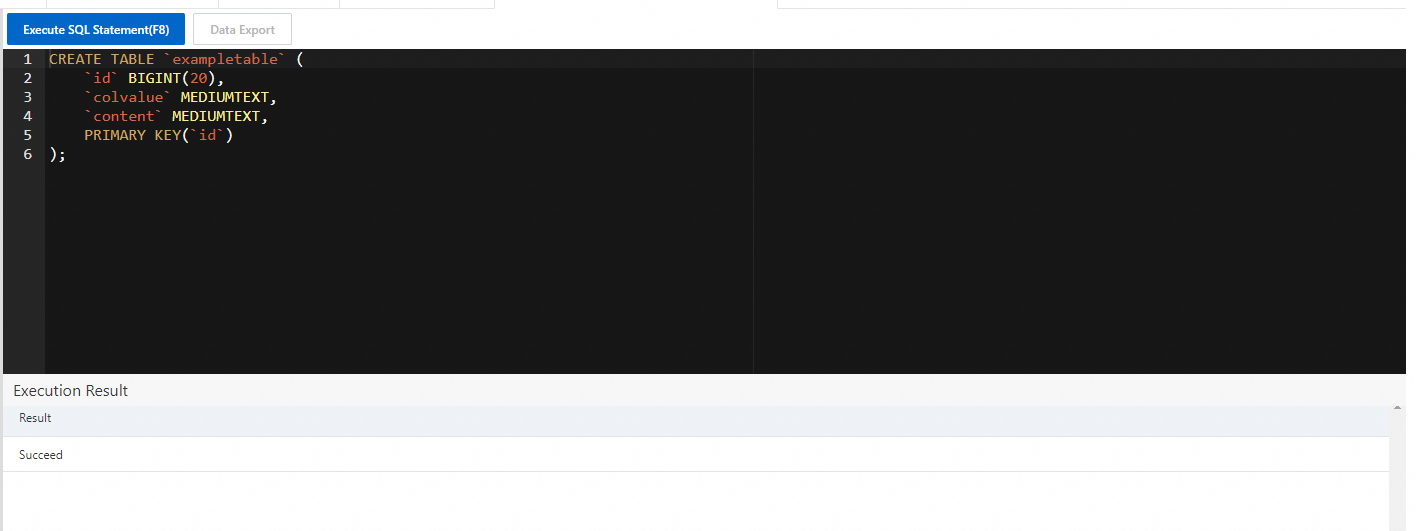
[SQL 文の生成] をクリックします。
システムはマッピングテーブルを作成するための SQL 文を自動的に生成します。 SQL 文の例:
CREATE TABLE `exampletable` ( `id` BIGINT(20), `colvalue` MEDIUMTEXT, `content` MEDIUMTEXT, PRIMARY KEY(`id`) );重要マッピングテーブルのフィールドのデータ型がデータテーブルのフィールドのデータ型と一致していることを確認します。 データ型マッピングの詳細については、「SQL でのデータ型マッピング」をご参照ください。
ビジネス要件に基づいてマッピングテーブルのスキーマを変更した後、SQL 文をドラッグ選択し、[SQL 文の実行 (F8)] をクリックします。
実行が成功すると、実行結果は [実行結果] セクションに表示されます。
重要マッピングテーブルを作成する場合、マッピングテーブルに指定するスキーマには、後続のデータクエリ操作に必要な列が含まれている必要があります。
実行する SQL 文をドラッグ選択する必要があります。 SQL 文をドラッグ選択しないと、システムは最初の SQL 文を実行します。
一度に実行できる SQL 文は 1 つだけです。 複数の SQL 文を同時に実行すると、システムはエラーを報告します。
手順 2:データをクエリする
マッピングテーブルが作成されると、[SQL 文を実行してクエリする] タブで SELECT 文を実行してデータをクエリできます。 詳細については、「データのクエリ」をご参照ください。
[データエクスポート] をクリックしてデータをエクスポートします。 最大 2,000 件のデータエントリをローカル CSV ファイルにエクスポートして保存できます。
データエクスポートボタンを使用して、最大 2,000 件のデータエントリをエクスポートできます。 大量のデータをエクスポートするには、DataX や CLI などのツールを使用して、Tablestore のデータをローカルファイルにダウンロードして保存します。 詳細については、「Tablestore データをローカルファイルにダウンロードする」をご参照ください。
FAQ
参考資料
CLI、SDK、Java Database Connectivity ( JDBC )、または Go 用 Tablestore ドライバーを使用して、SQL 文に基づいてデータをクエリすることもできます。 詳細については、「Tablestore SDK を使用する」、「SQL クエリ」、「JDBC」、および「Go 用 Tablestore ドライバーを使用する」をご参照ください。
Tablestore インスタンスを DataWorks または Data Management ( DMS ) に接続し、SQL 文を実行して Tablestore データをクエリおよび分析することもできます。 詳細については、「Tablestore インスタンスを DataWorks に接続する」および「Tablestore を DMS に接続する」をご参照ください。
SQL 文を実行してデータクエリと計算を高速化するには、セカンダリインデックスまたは多次元インデックスを作成できます。 詳細については、「インデックス選択ポリシー」および「計算プッシュダウン」をご参照ください。
MaxCompute、Spark、Hive、HadoopMR、Function Compute、Flink、PrestoDB などの計算エンジンを使用して、テーブル内のデータを計算および分析することもできます。 詳細については、「概要」をご参照ください。
データを視覚化するには、Grafana を使用できます。 たとえば、Grafana を使用して Tablestore データをグラフに表示できます。 詳細については、「Tablestore を Grafana に接続する」をご参照ください。