多次元インデックスは、転置インデックスと列ストアを使用して、ビッグデータの多次元クエリと統計分析をサポートします。非プライマリキー列のクエリ、ブールクエリ、fuzzy クエリ、全文検索、ベクトル検索、および max、min、count、group by などのアグリゲーションには、多次元インデックスを使用します。
背景情報
検索インデックスは、ワイドテーブルモデルにのみ適用されます。
検索インデックス、データベース、検索エンジンは、いずれもビッグデータにおける複雑なクエリの問題に対処しますが、以下の点で異なります。
結合、トランザクション、関連性分析を除き、Tablestore はデータベースと検索システムの両方の機能を提供します。一般的なデータベース + 検索エンジン アーキテクチャを置き換えます。
結合、トランザクション、または複雑な関連性分析を必要としないシナリオでは、Tablestore の検索インデックスを使用します。

インデックスの概要
検索インデックスは、転置インデックスと列ストアを使用して、ビッグデータに対する多次元クエリと統計分析の問題を解決します。非プライマリキー列のクエリ、前方一致クエリ、ファジークエリ、ブールクエリ、ネストされたクエリ、ジオクエリ、全文検索、ベクトル検索、および統計的集約 (max、min、count、sum、avg、distinct_count、group_by、percentiles、histogram) をサポートしています。
次の図は、検索インデックスで使用される転置インデックス、列ストア、および多次元空間インデックス構造を示しています。
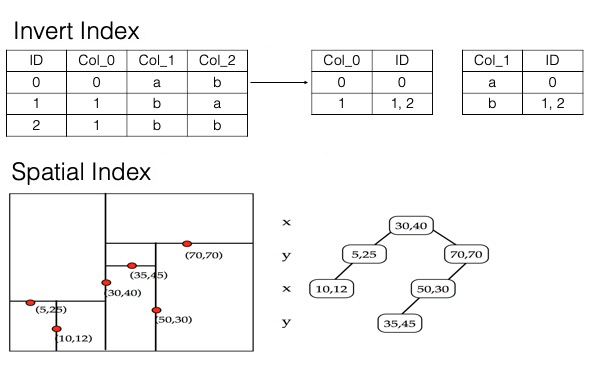
従来のデータベースインデックス (MySQL など) とは異なり、検索インデックスは最左一致の原則に制限されません。ほとんどの場合、テーブルごとに 1 つの検索インデックスのみが必要です。たとえば、名前、学生 ID、性別、学年、クラス、自宅住所などの列を持つ学生テーブルでは、3 年生で名前が田中太郎の学生、自宅住所が 1 km 以内の男子学生、3 年 2 組で特定の住宅地に住んでいる学生などの組み合わせクエリをサポートするために、1 つの検索インデックスのみが必要です。
インデックスの比較
Tablestore は、データテーブルでのプライマリキークエリに加えて、クエリを高速化するための 2 つのインデックスタイプ (セカンダリインデックスと検索インデックス) をサポートしています。次の表は、これら 3 つのクエリ方法を比較したものです。
|
クエリ方法 |
原理 |
シナリオ |
|
プライマリキー |
データテーブルは大きなマップのように機能します。プライマリキーによってのみデータをクエリできます。 |
完全なプライマリキーまたはキープレフィックスがわかっているシナリオに適しています。 |
|
セカンダリインデックス |
クエリ機能を拡張するプライマリキー列を持つインデックステーブルを作成します。 |
クエリ列が事前に決定されており、列数が少ないシナリオに適しています。 |
|
検索インデックス |
転置インデックス、BKD tree、列ストアなどの構造を使用して、豊富なクエリ機能を提供します。 |
プライマリキーおよびセカンダリインデックスの範囲を超えるすべてのクエリおよび分析シナリオに適しています:非プライマリキー列のクエリ、任意の列でのブールクエリ、関係クエリ、全文検索、ジオクエリ、ファジークエリ、ネストされたクエリ、NULL 値クエリ、および統計的集約。 |
シナリオ
検索インデックスは、アプリケーションシステムでデータクエリと分析に広く使用されています。次の表に、一般的なシナリオを示します。
|
アプリケーションシステム |
シナリオ例 |
|
E コマースプラットフォーム |
商品のカテゴリ分類と属性フィルタリングを実装し、ユーザーが商品を迅速に検索およびフィルタリングできるようにします。 |
|
ソーシャルアプリケーション |
ユーザーのフォロー関係や友人関係をクエリしたり、興味タグに基づいてユーザーを推薦・マッチングしたりします。 |
|
ログ分析 |
キーワード検索と時間範囲クエリを実行して、問題を迅速に特定し、ログデータを分析します。 |
|
IoT データ分析 |
デバイスデータのクエリや分析を行います。たとえば、デバイスタイプや地理的位置によって、データのフィルタリングやカウントを行います。 |
|
アプリケーションパフォーマンス監視 |
メトリックデータの集約とクエリを行います。たとえば、時間範囲やアプリケーション名で、データのフィルタリングや要約を行います。 |
|
位置情報サービス |
ジオクエリと周辺検索を実行して、近隣の店舗、観光スポット、サービスに関する情報を提供します。 |
|
テキスト検索エンジン |
全文検索と関連性ソートを実行して、ドキュメント、記事、その他のコンテンツを迅速に見つけます。 |
機能
機能一覧
次の表に、多次元インデックスの機能を示します。
|
機能 |
説明 |
ドキュメント |
|
任意の列 (プライマリキー列および非プライマリキー列を含む) でのクエリ |
任意の列でデータをクエリします。ほとんどのクエリシナリオに適しています。 プライマリキーまたはプレフィックスクエリでニーズを満たせない場合は、対象フィールドを含む多次元インデックスを作成し、列の値でクエリを実行します。 |
基本クエリなどの任意の多次元インデックスクエリ |
|
ブールクエリ |
複数のフィールドを組み合わせて効率的なフィルタリングを行います。注文システム、ログ分析、ユーザーペルソナに適しています。 リレーショナルデータベースでは、数十のフィールドを持つテーブルは、すべてのフィールドの組み合わせをカバーするために数百のインデックスを必要とする場合があります。組み合わせが欠落していると、クエリの効率が低下します。 Tablestore では、1 つの多次元インデックスがすべてのフィールドの組み合わせをカバーします。クエリする可能性のあるフィールドをインデックスに追加し、And、Or、Not のロジックを使用して自由に組み合わせます。 |
|
|
ジオクエリ |
モバイルデバイスの普及により、地理位置情報データの価値はますます高まっています。ソーシャルネットワーキング、フードデリバリー、スポーツ、車のインターネット (IoV) などのアプリケーションでは、すべて位置情報を活用したクエリが必要です。 多次元インデックスは、次のジオクエリ機能をサポートしています:
アプリケーションで位置情報ベースのクエリが必要な場合、Tablestore の多次元インデックスは、追加のデータベースや検索システムなしでワンストップソリューションを提供します。 |
|
|
フルテキストインデックス |
指定された語句を含むデータを検索します。ビッグデータ分析、コンテンツ検索、ナレッジマネジメント、ソーシャルメディア分析、ログ分析、AI チャットシステム、コンプライアンスレビュー、パーソナライズされたレコメンデーションに適しています。 多次元インデックスは、トークン化を使用して全文検索を行います。基本的な BM25 の関連度は提供しますが、カスタムの関連度は提供しません。複雑な関連度検索のニーズには、専用の検索システムを使用してください。それ以外の場合は、多次元インデックスで十分です。 利用可能なトークン化の種類は、単語、区切り文字、最小セマンティック、最大セマンティック、あいまい、の 5 種類です。結果のキーワードをハイライト表示するには、要約とハイライト機能を使用します。 |
|
|
ベクトル検索 |
多次元インデックスは、ベクトル検索をサポートしており、大規模なデータセットに対して効率的な近似最近傍クエリを実行できます。検索拡張生成 (RAG)、レコメンデーションシステム、類似性検出 (画像、動画、音声)、自然言語処理に適しています。 |
|
|
あいまいクエリ |
多次元インデックスは、さまざまなシナリオでのあいまい一致のために、ワイルドカードクエリ、プレフィックスクエリ、およびサフィックスクエリを提供します。
|
|
|
列存在クエリ (NULL クエリ) |
列に null 値があるかどうかを確認します。データ整合性チェックやデータクリーニングに適しています。 |
|
|
ネストクエリ |
フラットな構造だけでなく、アプリケーションデータはしばしば多層のネスト構造を持ちます。たとえば、画像タグ付けシステムは、複数のエンティティ (家、車、人) を持つ画像を保存し、それぞれが異なる位置、サイズ、重み (スコア) を持っています。各画像は複数のタグにマッピングされ、各タグには名前と重みスコアがあります。 タグの条件で画像をフィルタリングするには、ネストクエリを使用します。画像タグは JSON 形式で保存されます: ネストクエリは、多層の論理関係を持つデータを処理し、複雑なデータモデリングに柔軟性を提供します。 複雑なネストデータ構造 (JSON など) の場合、要約とハイライト機能を使用して、必要な情報を正確に見つけます。 |
|
|
重複排除 |
多次元インデックスは、クエリ結果を重複排除して多様性を向上させます。重複排除は、単一の結果セット内で特定の属性値が表示される回数を制限します。たとえば、eコマースプラットフォームで |
|
|
ソート |
Tablestore は、デフォルトでプライマリキーでデータをアルファベット順にソートします。他のフィールドでソートするには、多次元インデックスのソート機能を使用します。 多次元インデックスは、昇順または降順、単一条件ソート、および複数条件ソートをサポートしています。すべてのソートはグローバルです。デフォルトでは、多次元インデックスの結果はプライマリキーでアルファベット順にソートされます。 |
|
|
総行数 |
多次元インデックスでデータをクエリする場合、一致する行数を返すことができます。これは、データ検証や操作に役立ちます。
|
|
|
統計集計 |
多次元インデックスは、Max、Min、Avg、Sum、Count、DistinctCount、GroupBy、Percentile、Histogram などの一般的な集計関数を提供します。これらは、軽量分析の基本的な統計ニーズを満たします。 |
サポートされるリージョン
現在、多次元インデックス機能は、次のリージョンで利用可能です:中国 (杭州)、中国 (上海)、中国 (青島)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深圳)、中国 (広州)、中国 (成都)、中国 (香港)、日本 (東京)、シンガポール、マレーシア (クアラルンプール)、インドネシア (ジャカルタ)、フィリピン (マニラ)、タイ (バンコク)、ドイツ (フランクフルト)、英国 (ロンドン)、米国 (シリコンバレー)、米国 (バージニア)、SAU (リヤド - パートナーリージョン)、および 。ベクトル検索機能は、米国 (シリコンバレー) リージョンではまだサポートされていません。
災害復旧
ゾーンディザスタリカバリー機能を備えたリージョンでは、多次元インデックスはデフォルトでゾーン冗長ストレージを提供します。データはリージョン内の複数のゾーンにまたがって保存されます。単一のゾーンで障害が発生しても、読み取りおよび書き込みサービスは中断することなく継続されます。
現在、多次元インデックスは、次のリージョンでゾーン冗長ストレージをサポートしています:中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深圳)、中国 (香港)、日本 (東京)、シンガポール、インドネシア (ジャカルタ)、ドイツ (フランクフルト)、および 。
データライフサイクル
データテーブルに UpdateRow 操作がない場合は、多次元インデックスの TTL を使用できます。詳細については、「ライフサイクル管理」をご参照ください。
特定の期間だけデータを保持する必要があり、時間フィールドの更新が不要な場合は、時間によるテーブルシャーディングで TTL を実装します。
|
ディメンション |
時間によるテーブルシャーディング |
|
原則 |
固定の間隔 (日、週、月、または年) でテーブルをシャーディングします。各テーブルに多次元インデックスを作成し、必要な期間データテーブルを保持します。 たとえば、データを 6 か月間保持するには、各月のデータを個別のテーブル (table_1 から table_6) に保存し、それぞれに独自の多次元インデックスを作成します。毎月、6 か月前のテーブルを削除します。 クエリを実行するとき、時間範囲が単一のテーブル内に収まる場合は、そのテーブルのみをクエリします。複数のテーブルにまたがる場合は、それぞれをクエリして結果をマージします。 |
|
ルール |
単一のテーブル (単一のインデックス) は 500 億行を超えてはなりません。クエリのパフォーマンスは、行数が 200 億行未満の場合に最適です。 |
|
利点 |
|
データバージョン
多次元インデックスは複数のデータバージョンをサポートしていません。複数のバージョンが有効になっているデータテーブルに対して多次元インデックスを作成することはできません。
単一バージョンのテーブルで、書き込みごとにタイムスタンプをカスタマイズする場合、大きいバージョンの後に小さいバージョン番号のデータを書き込むと、大きいバージョンが上書きされる可能性があります。
Search および ParallelScan リクエストが返すデータには、必ずしもタイムスタンププロパティが含まれているとは限りません。
制限
多次元インデックスは、データテーブルから非同期でデータを同期するため、リアルタイムでのクエリはできません。通常のレイテンシーは 3 秒以内です。詳細については、「多次元インデックスの制限」をご参照ください。
課金
検索インデックスは、インデックス データが占有するストレージ スペースと、クエリおよび分析で消費されるコンピューティングリソースに対して課金されます。詳細については、「課金概要」をご参照ください。
開発と統合
API リファレンス
検索インデックスは、インデックス管理とデータクエリ用の API を提供します。データクエリには、汎用的な Search API とデータエクスポート用の ParallelScan API が含まれます。ParallelScan は、一部の機能 (ソート、集約) を犠牲にして、より高いパフォーマンスとスループットを実現します。
|
カテゴリ |
API |
説明 |
|
インデックス管理 |
検索インデックスを作成します。 |
|
|
検索インデックスの構成を更新します。生存時間 (TTL) やインデックススキーマなどが含まれます。 |
||
|
検索インデックスの詳細を取得します。 |
||
|
検索インデックスを一覧表示します。 |
||
|
検索インデックスを削除します。 |
||
|
データクエリ |
フル機能のクエリ API です。クエリ関数、ソート、統計的集計など、検索インデックスのすべての機能をサポートします。結果は指定された順序で返されます。
|
|
|
パラレルスキャンに対応したデータエクスポート API です。 単一の同時実行の場合、ParallelScan のスループットは Search API の 5 倍です。
複数の同時実行リクエストでデータをエクスポートする場合は、ComputeSplits API を使用して、単一の ParallelScan リクエストの最大同時実行数を取得してください。 |
統合方法
検索インデックスを使用するには、次の SDK または CLI ツールを使用できます。
よくある質問
関連ドキュメント
-
SQL でデータをクエリおよび分析するには、Tablestore のSQL クエリ機能を使用します。
説明MaxCompute、Spark、Hive、HadoopMR、Function Compute、Flink などのコンピューティングエンジンを使用して Tablestore のデータを分析することもできます。 詳細については、「コンピューティングと分析の概要」をご参照ください。
付録:SQL マッピング
検索インデックスの一部の機能は、SQL 関数に対応しています。次の表に、そのマッピングを示します。
|
SQL |
検索インデックス |
検索インデックスのドキュメント |
|
Show |
DescribeSearchIndex |
|
|
Select |
任意のクエリの ColumnsToGet パラメーター |
基本クエリなどの任意の検索インデックスクエリ |
|
From |
任意のクエリの IndexName パラメーター 重要
単一のインデックスがサポートされています。複数のインデックスはまだサポートされていません。 |
基本クエリなどの任意の検索インデックスクエリ |
|
Where |
任意のクエリの条件 |
基本クエリなどの任意の検索インデックスクエリ |
|
Order by |
任意のクエリの sort パラメーター |
|
|
Limit |
任意のクエリの limit パラメーター |
|
|
Delete |
|
|
|
Like |
WildcardQuery |
|
|
And |
BoolQuery の演算子: and |
|
|
Or |
BoolQuery の演算子: or |
|
|
Not |
BoolQuery (mustNotQueries) |
|
|
Between |
RangeQuery |
|
|
Null |
ExistsQuery |
|
|
In |
TermsQuery |
|
|
Min |
集約: min |
|
|
Max |
集約: max |
|
|
Avg |
集約: avg |
|
|
Count |
集約: count |
|
|
Count (distinct) |
集約: distinctCount |
|
|
Sum |
集約: sum |
|
|
GROUP BY |
GroupBy |