このトピックでは、Tablestore の集約機能を使用してデータを分析する方法について説明します。この機能を使用すると、最小値、最大値、合計、平均値、カウント、個別カウント、パーセンタイルなどのメトリックを計算したり、フィールド値、範囲、位置、フィルターに基づいてデータをグループ化したり、ヒストグラムおよび日付ヒストグラムを生成したり、各グループ内の行を取得したり、ネストされたクエリを実行したりできます。また、複数の集約関数を組み合わせて複雑なクエリを構築することも可能です。
操作手順
次の図は、集約処理の全体的な流れを示しています。
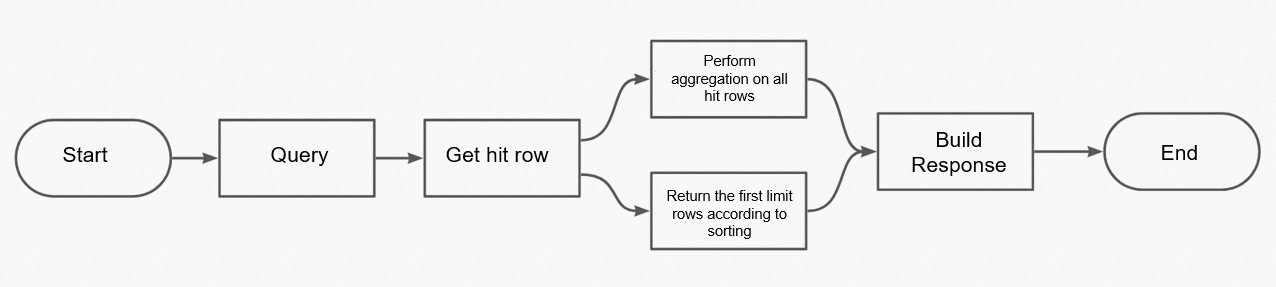
クエリが完了すると、サーバーは一致するすべてのドキュメントを集約します。そのため、集約を含むリクエストは、含まないリクエストよりも処理が複雑になります。
特徴
集約機能は、MIN()、MAX()、SUM()、AVG()、COUNT()、COUNT(DISTINCT)、ANY_VALUE()、および GROUP BY など、さまざまな SQL 関数と類似した機能を提供します。また、パーセンタイル統計、フィールド値によるグループ化、複数フィールドによるグループ化、範囲によるグループ化、地理的位置によるグループ化、フィルターによるグループ化、ヒストグラム集約、日付ヒストグラム集約、サブ集約などの機能もサポートしています。以下の表にこれらの機能の詳細を示します。
|
特徴 |
説明 |
|
最小値 |
フィールド内の最小値を返します。SQL の MIN 関数と同様です。 |
|
最大値 |
フィールドの最大値を返します。SQL の |
|
合計 |
数値フィールドの値の合計を返します。SQL の sum 関数と同様です。 |
|
平均値 |
数値フィールドの平均値を計算します。SQL の |
|
カウント |
指定されたフィールドの値の数、または多次元インデックス内の行の総数を返します。SQL の COUNT 関数と同様です。 |
|
個別カウント |
指定されたフィールドの個別値の数を返します。SQL の COUNT(DISTINCT) 関数と同様です。 |
|
パーセンタイル統計 |
パーセンタイル統計を使用して、データセットのパーセンタイル分布を分析します。たとえば、日常的な運用管理 (O&M) 中に、P25、P50、P90、P99 などのパーセンタイルを確認することで、リクエスト遅延の分布を追跡できます。 |
|
フィールド値によるグループ化 |
指定されたフィールドの値に基づいてクエリ結果をグループ化します。同じフィールド値を持つ行が 1 つのグループを形成します。この操作は、各グループの値とその行数を返します。 |
|
サブ集約 |
グループ化集約はネストをサポートしており、グループ内にサブ集約を追加できます。 |
|
複数フィールドによるグループ化 |
複数のフィールドに基づいてクエリ結果をグループ化します。この機能は、ページネーショントークンを使用したページングをサポートしています。 |
|
範囲によるグループ化 |
フィールドの値に基づいてクエリ結果をカスタム範囲にグループ化し、各範囲のカウントを返します。 |
|
地理的位置によるグループ化 |
原点からの距離に基づいてクエリ結果をグループ化します。この操作は、指定された距離範囲内のアイテムを同じグループに配置し、各範囲のカウントを返します。 |
|
フィルターによるグループ化 |
指定されたフィルターに基づいてクエリ結果をグループ化します。この集約は、各フィルターに一致するドキュメントの数を返します。結果は、フィルターを追加したのと同じ順序で返されます。 |
|
ヒストグラム集約 |
指定されたデータ間隔に基づいてクエリ結果をグループ化します。同じ間隔内にフィールド値が存在する行は同じグループに配置されます。この操作は、各グループの開始値と対応する行数を返します。 |
|
日付ヒストグラム集約 |
日付フィールドの場合、行を指定された時間間隔のバケットにグループ化し、各バケットの行数を返します。 |
|
集約グループからの行の取得 |
クエリ結果をグループ化した後、トップ行集約を使用して各グループから選択された行を取得します。この機能は、MySQL の |
|
複数集約 |
単一のクエリで複数の集約を組み合わせることができます。 説明
複数の集約を含む複雑なクエリは、応答時間を影響する可能性があります。 |
関連 API
集約の API オペレーションは Search です。
前提条件
集約は、Tablestore コンソール、CLI、または SDK を使用して実行できます。
Tablestore コンソールおよび CLI は、集約機能の一部のみをサポートしています。
Table Store 操作に必要な権限を持つ Alibaba Cloud アカウントまたは RAM ユーザーを使用します。RAM ユーザーに権限を付与するには、「RAM ポリシーを使用した RAM ユーザーへの権限付与」をご参照ください。
SDK またはコマンドラインツールを使用する場合は、Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey を作成 してください。
データテーブルを作成しました。
検索インデックスがデータテーブルに対して作成されました。
SDK を使用する場合は、Tablestore Client を初期化 してください。
コマンドラインツールを使用する場合は、ツールをダウンロードして起動し、インスタンスへの接続を設定してターゲットテーブルを選択します。詳細については、「コマンドラインツールのダウンロード」、「ツールの起動と接続情報の設定」、および「データテーブル操作」をご参照ください。
コンソール
[インデックス管理] タブに移動します。
Table Store コンソール にログインします。
上部ナビゲーションバーで、リソースグループとリージョンを選択します。
[概要] ページで、インスタンス名をクリックするか、[操作] 列の [インスタンス管理] をクリックします。
[インスタンス詳細] タブの [データテーブルリスト] タブで、データテーブル名をクリックするか、[操作] 列の [インデックス管理] をクリックします。
[インデックス管理] タブで、対象の多次元インデックスを見つけ、[操作] 列の [検索] をクリックします。
-
検索 ダイアログボックスで、クエリ条件を指定します。
デフォルトでは、すべての列が返されます。特定の列を返すには、[すべての列を取得] をオフにして、列名をカンマ区切りで入力します。
説明デフォルトでは、Table Store はデータテーブルのプライマリキー列を返します。
論理演算子を選択してください: [AND]、[OR]、または [NOT]。
[And] を選択すると、指定されたすべての条件を満たすデータが返されます。[Or] を選択すると、指定された条件の少なくとも 1 つを満たすデータが返されます。[Not] を選択すると、指定された条件を満たさないデータが返されます。
-
インデックスフィールドを選択し、追加 をクリックして、フィールドのクエリタイプと値を設定します。
このステップを繰り返して、複数のインデックスフィールドのクエリ条件を追加できます。
デフォルトでは、ソートは無効になっています。特定のフィールドで結果をソートするには、[ソートを有効化] をオンにして、ソートフィールドを追加し、ソート順を設定します。
-
デフォルトでは、統計機能は無効になっています。特定のフィールドの統計情報を収集するには、[統計情報を収集] スイッチをオンにして、統計情報を収集するフィールドを追加し、必要に応じて統計タイプ、項目、デフォルト値を設定します。
統計用のフィールドを一度に複数追加できます。[統計タイプ] の有効値は、[最小値]、[最大値]、[合計]、[平均値]、[カウント]、および [個別カウント] です。[デフォルト] パラメーターは、行にフィールドが存在しない場合に使用する値を指定します。
-
OK をクリックします。
インデックス タブに、クエリに一致するデータと統計結果が表示されます。
CLI
Tablestore CLI の search コマンドでデータをクエリする際に、集約を実行することもできます。サポートされている集約タイプには、最小値 (min)、最大値 (max)、合計、平均値 (avg)、カウントがあります。詳細については、「多次元インデックス」をご参照ください。
-
次の
searchコマンドを実行して、search_index検索インデックスを使用してテーブル内のデータを照会および分析し、すべてのインデックス付きカラムを返します。search -n search_index --return_all_indexed -
プロンプトに従ってクエリ条件を入力します。
次の例は、
gid列の値が 10 未満または 77 である行を取得し、gid列の平均値を計算するクエリを示しています。{ "Offset": -1, "Limit": 10, "Collapse": null, "Sort": null, "GetTotalCount": true, "Token": null, "Query": { "Name": "BoolQuery", "Query": { "MinimumShouldMatch": 1, "MustQueries": null, "MustNotQueries": null, "FilterQueries": null, "ShouldQueries": [{ "Name": "RangeQuery", "Query": { "FieldName": "gid", "From": null, "To": 10, "IncludeLower": false, "IncludeUpper": false } }, { "Name": "TermQuery", "Query": { "FieldName": "gid", "Term": 77 } }] } }, "Aggregations": [{ "Name": "avg", "Aggregation": { "AggName": "agg1", "Field": "gid", "MissingValue": null } }] }
Tablestore SDK
Tablestore SDK for Java、Tablestore SDK for Go、Tablestore SDK for Python、Tablestore SDK for Node.js、Tablestore SDK for .NET、および Tablestore SDK for PHP を使用して集約を実行できます。このトピックの例では、Tablestore SDK for Java を使用しています。
集約機能は、多次元インデックスで定義されたフィールドタイプをサポートしています。これらのタイプとデータテーブルフィールドタイプとのマッピングの詳細については、「データタイプ」をご参照ください。
最小値
フィールド内の最小値を返します。SQL の MIN 関数と同様です。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Date タイプのみサポートされています。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * 商品テーブルには各商品の価格が記録されています。浙江省で製造された商品の最低価格をクエリします。 * SQL ステートメント: SELECT min(column_price) FROM product where place_of_production="Zhejiang". */ public void min(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addAggregation(AggregationBuilders.min("min_agg_1", "column_price").missing(100)) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MinAggregation aggregation = new MinAggregation(); aggregation.setAggName("min_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // MinAggregation aggregation2 = AggregationBuilders.min("min_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } }
Max
フィールドの最大値を返します。SQL の max 関数と同様です。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Date タイプのみサポートされています。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * 商品テーブルには各商品の価格が記録されています。浙江省で製造された商品の最高価格をクエリします。 * SQL ステートメント: SELECT max(column_price) FROM product where place_of_production="Zhejiang". */ public void max(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addAggregation(AggregationBuilders.max("max_agg_1", "column_price").missing(0)) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MaxAggregation aggregation = new MaxAggregation(); aggregation.setAggName("max_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // MaxAggregation aggregation2 = AggregationBuilders.max("max_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } }
合計
数値フィールドの値の合計を返します。SQL の sum 関数と同様です。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long および Double タイプのみサポートされています。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * 各プロダクトの価格はプロダクトテーブルに記載されています。浙江省で生産されたプロダクトの最大価格をクエリします。 * SQL ステートメント: SELECT sum(column_price) FROM product where place_of_production="Zhejiang". */ public void sum(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //特定のデータではなく集約結果のみを取得したい場合は、クエリパフォーマンスを向上させるために limit を 0 に設定します。 .addAggregation(AggregationBuilders.sum("sum_agg_1", "column_number").missing(10)) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //次のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); SumAggregation aggregation = new SumAggregation(); aggregation.setAggName("sum_agg_1"); aggregation.setFieldName("column_number"); aggregation.setMissing(ColumnValue.fromLong(100)); //次のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // SumAggregation aggregation2 = AggregationBuilders.sum("sum_agg_1", "column_number").missing(10).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } }
平均値
数値フィールドの平均値を計算します。SQL の avg 関数と同様です。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Date タイプのみサポートされています。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * 商品テーブルには各商品の販売数量が記録されています。浙江省で製造された商品の平均価格をクエリします。 * SQL ステートメント: SELECT avg(column_price) FROM product where place_of_production="Zhejiang". */ public void avg(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addAggregation(AggregationBuilders.avg("avg_agg_1", "column_price")) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); AvgAggregation aggregation = new AvgAggregation(); aggregation.setAggName("avg_agg_1"); aggregation.setFieldName("column_price"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // AvgAggregation aggregation2 = AggregationBuilders.avg("avg_agg_1", "column_price").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } }
カウント
指定されたフィールドの値の数、または多次元インデックス内の行の総数をカウントします。SQL の count 関数と同様です。
多次元インデックス内の行の総数、またはクエリ条件を満たす行の総数をクエリするには、次の方法を使用します。
-
集約のカウント機能を使用します。リクエストでカウントパラメーターを * に設定します。
-
クエリ機能を使用して、クエリ条件を満たす行の数を取得します。クエリで setGetTotalCount パラメーターを true に設定します。MatchAllQuery を使用して、多次元インデックス内の行の総数を取得します。
多次元インデックス内で列を含む行の数をクエリするには、カウント式の値として列名を使用します。この方法は、スパース列を含むシナリオに適しています。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Boolean、Keyword、Geo_point、Date タイプのみサポートされています。
-
例
/** * 商店の罰則記録は商店テーブルに記録されています。浙江省に所在し、罰則記録が存在する商店の数をクエリできます。商店に罰則記録が存在しない場合、罰則記録に対応するフィールドもその商店には存在しません。 * SQL ステートメント: SELECT count(column_history) FROM product where place_of_production="Zhejiang". */ public void count(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addAggregation(AggregationBuilders.count("count_agg_1", "column_history")) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); CountAggregation aggregation = new CountAggregation(); aggregation.setAggName("count_agg_1"); aggregation.setFieldName("column_history"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // CountAggregation aggregation2 = AggregationBuilders.count("count_agg_1", "column_history").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } }
個別カウント
指定されたフィールドの個別値の数を返します。SQL の count(distinct) 関数と同様です。
個別値の数は近似値です。
-
個別カウント機能を使用する前の行の総数が 10,000 未満の場合、計算結果は正確な値に近くなります。
-
個別カウント機能を使用する前の行の総数が 1 億以上の場合、誤差率は約 2% になります。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Boolean、Keyword、Geo_point、Date タイプのみサポートされています。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * 商品が製造された都道府県の個別数をクエリします。 * SQL ステートメント: SELECT count(distinct column_place) FROM product. */ public void distinctCount(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addAggregation(AggregationBuilders.distinctCount("dis_count_agg_1", "column_place")) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); DistinctCountAggregation aggregation = new DistinctCountAggregation(); aggregation.setAggName("dis_count_agg_1"); aggregation.setFieldName("column_place"); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // DistinctCountAggregation aggregation2 = AggregationBuilders.distinctCount("dis_count_agg_1", "column_place").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } }
パーセンタイル統計
パーセンタイル統計を使用して、データセットのパーセンタイル分布を分析します。たとえば、日常的な運用管理 (O&M) 中に、P25、P50、P90、P99 などのパーセンタイルを確認することで、リクエスト遅延の分布を追跡できます。
結果の精度を向上させるために、p1 や p99 などの極端なパーセンタイル値を指定することを推奨します。p50 などの他の値の代わりに極端なパーセンタイル値を使用すると、返される結果がより正確になります。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Date タイプのみサポートされています。
percentiles
p50、p90、p99 などのパーセンタイルです。1 つ以上のパーセンタイルを指定できます。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * パーセンタイルを使用して、システムに送信された各リクエストの応答時間の分布を分析します。 */ public void percentilesAgg(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("indexName") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addAggregation(AggregationBuilders.percentiles("percentilesAgg", "latency") .percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)) .missing(1.0)) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //結果を取得します。 PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); PercentilesAggregation aggregation = new PercentilesAggregation(); aggregation.setAggName("percentilesAgg"); aggregation.setFieldName("latency"); aggregation.setPercentiles(Arrays.asList(25.0d, 50.0d, 99.0d)); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // AggregationBuilders.percentiles("percentilesAgg", "latency").percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)).missing(1.0).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //結果を取得します。 PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } }
フィールド値によるグループ化
指定されたフィールドの値に基づいてクエリ結果をグループ化します。同じフィールド値を持つ行が 1 つのグループを形成します。この操作は、各グループの値とその行数を返します。
-
フィールド値によるグループ化は並列計算を使用します。これは正確な統計方法ではないため、結果に若干の誤差が含まれる可能性があります。
-
複数フィールドによるグループ化を実行するには、ネストされたグループ化 または 複数フィールドによるグループ化 を使用できます。これらの 2 つの方法の比較については、「付録:複数フィールドによるグループ化の異なる実装方法の比較」をご参照ください。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long、Double、Boolean、Keyword、Date タイプのみサポートされています。
groupBySorter
グループのソートルールです。デフォルトでは、グループ内のアイテム数に基づいて降順でソートされます。複数のソートルールを設定した場合、ルールを設定した順序に基づいてグループがソートされます。次のソートルールがサポートされています。
-
groupKeySortInAsc: 値をアルファベット順にソートします。
-
groupKeySortInDesc: 値をアルファベット逆順にソートします。
-
rowCountSortInAsc: 行数を昇順にソートします。
-
rowCountSortInDesc (デフォルト): 行数を降順にソートします。
-
subAggSortInAsc: サブ集約結果から取得した値を昇順にソートします。
-
subAggSortInDesc: サブ集約結果から取得した値を降順にソートします。
size
返すグループの数です。デフォルト値は 10、最大値は 2000 です。
subAggregations
各グループ内のデータに対して実行できるサブ集約操作です。たとえば、最大値、合計、平均値の計算などです。
subGroupBys
各親グループ内のデータに対して実行できるサブグループ化操作で、データをさらにグループ化します。
-
-
例
単一フィールドによるグループ化
/** * 各カテゴリの商品数、および商品価格の最大値と最小値をクエリします。 * 返される結果の例: 果物: 5。最高価格は 2 米ドル、最低価格は 0.5 米ドル。日用品: 10。最高価格は 13 米ドル、最低価格は 0.1 米ドル。電子機器: 3。最高価格は 1,160 米ドル、最低価格は 310 米ドル。その他商品: 15。最高価格は 130 米ドル、最低価格は 11 米ドル。 */ public void groupByField(SyncClient client) { //ビルダーを使用してクエリ文を作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //集約結果のみを取得し、具体的なデータを取得しない場合は、limit を 0 に設定してクエリパフォーマンスを向上させます。 .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //値を表示します。 System.out.println(item.getKey()); //行数を表示します。 System.out.println(item.getRowCount()); //最低価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //最高価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } //ビルダーを使用せずにクエリ文を作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、TermQuery を使用してクエリ文を作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); GroupByField groupByField = new GroupByField(); groupByField.setGroupByName("name1"); groupByField.setFieldName("column_type"); //サブ集約操作を設定します。 MinAggregation minAggregation = AggregationBuilders.min("subName1", "column_price").build(); MaxAggregation maxAggregation = AggregationBuilders.max("subName2", "column_price").build(); groupByField.setSubAggregations(Arrays.asList(minAggregation, maxAggregation)); //以下のコメントでは、ビルダーを使用してクエリ文を作成しています。ビルダーを使用してクエリ文を作成する方法は、aggregation を使用してクエリ文を作成する方法と同じ効果があります。 // GroupByBuilders.groupByField("name1", "column_type") // .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) // .addSubAggregation(AggregationBuilders.max("subName2", "column_price").build()); List<GroupBy> groupByList = new ArrayList<GroupBy>(); groupByList.add(groupByField); searchQuery.setGroupByList(groupByList); searchRequest.setSearchQuery(searchQuery); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //値を表示します。 System.out.println(item.getKey()); //行数を表示します。 System.out.println(item.getRowCount()); //最低価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //最高価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } }ネストモードでの複数フィールドによるグループ化
/** * 複数フィールドによるグループ化クエリ結果のネストモードでの例。 * 多次元インデックスで、SQL ステートメントの複数 GROUP BY フィールドと同等の効果を得るために、ネストモードで 2 つの groupBy フィールドを使用します。 * SQL ステートメント: select a,d, sum(b),sum(c) from user group by a,d. */ public void GroupByMultiField(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) //returnAllColumns を false に設定し、addColumesToGet に値を指定すると、クエリパフォーマンスが向上します。 //.addColumnsToGet("col_1","col_2") .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) //クエリ条件を指定します。クエリ条件は SQL の WHERE 句と同様に使用できます。ネストクエリを実行するには QueryBuilders.bool() を使用します。 .addGroupBy( GroupByBuilders .groupByField("unique name_1", "field_a") .size(20) .addSubGroupBy( GroupByBuilders .groupByField("unique name_2", "field_d") .size(20) .addSubAggregation(AggregationBuilders.sum("unique name_3", "field_b")) .addSubAggregation(AggregationBuilders.sum("unique name_4", "field_c")) ) ) .build()) .build(); SearchResponse response = client.search(searchRequest); //指定された条件を満たす行をクエリします。 List<Row> rows = response.getRows(); //集約結果を取得します。 GroupByFieldResult groupByFieldResult1 = response.getGroupByResults().getAsGroupByFieldResult("unique name_1"); for (GroupByFieldResultItem resultItem : groupByFieldResult1.getGroupByFieldResultItems()) { System.out.println("field_a key:" + resultItem.getKey() + " Count:" + resultItem.getRowCount()); //サブ集約結果を取得します。 GroupByFieldResult subGroupByResult = resultItem.getSubGroupByResults().getAsGroupByFieldResult("unique name_2"); for (GroupByFieldResultItem item : subGroupByResult.getGroupByFieldResultItems()) { System.out.println("field_a " + resultItem.getKey() + " field_d key:" + item.getKey() + " Count: " + item.getRowCount()); double sumOf_field_b = item.getSubAggregationResults().getAsSumAggregationResult("unique name_3").getValue(); double sumOf_field_c = item.getSubAggregationResults().getAsSumAggregationResult("unique name_4").getValue(); System.out.println("sumOf_field_b:" + sumOf_field_b); System.out.println("sumOf_field_c:" + sumOf_field_c); } } }集約のグループソートの設定
/** * 集約のソートルールを設定する例。 * 方法: GroupBySorter を指定してソートルールを設定します。複数のソートルールを設定した場合、ルールを設定した順序に基づいてグループがソートされます。GroupBySorter は昇順または降順でのソートをサポートしています。 * デフォルトでは、グループは行数の降順 (GroupBySorter.rowCountSortInDesc()) でソートされます。 */ public void groupByFieldWithSort(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") //.addGroupBySorter(GroupBySorter.subAggSortInAsc("subName1")) //サブ集約結果から取得した値に基づいてグループを昇順にソートします。 .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) //集約結果から取得した値に基づいてグループを昇順にソートします。 //.addGroupBySorter(GroupBySorter.rowCountSortInDesc()) //各グループの集約結果から取得した行数に基づいてグループを降順にソートします。 .size(20) .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); }
ネストされたグループ化
グループ化集約はネストをサポートしており、グループ内にサブ集約を追加できます。
パフォーマンスと複雑さのバランスを取るために、ネスト深度の上限が設定されています。詳細については、「多次元インデックスの制限事項」をご参照ください。
-
適用シナリオ
-
マルチレベルグループ化 (GroupBy + SubGroupBy)
第 1 レベルでデータをグループ化した後、第 2 レベルでグループ化を実行します。たとえば、まず都道府県でデータをグループ化し、次に市区町村でグループ化して、各都道府県の市区町村ごとのデータを取得します。
-
グループ化後の集約 (GroupBy + SubAggregation)
第 1 レベルでデータをグループ化した後、各グループ内のデータに対して集約操作 (最大値や平均値の計算など) を実行します。たとえば、都道府県でデータをグループ化した後、各都道府県グループの特定のメトリックの最大値を取得します。
-
-
例
次の例は、都道府県と市区町村でネストされたグループ化を実行し、各都道府県の注文総数と各市区町村の注文総数および最大注文金額を計算する方法を示しています。
public static void subGroupBy(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()).limit(20) //第 1 レベルのグループ化: 都道府県でグループ化し、各都道府県の注文 ID 数 (注文総数) をカウントします。 //第 2 レベルのグループ化: 市区町村でグループ化し、各市区町村の注文 ID 数 (注文総数) をカウントし、各市区町村の最大注文金額を計算します。 .addGroupBy(GroupByBuilders.groupByField("provinceName", "province") .addSubAggregation(AggregationBuilders.count("provinceOrderCounts", "order_id")) .addGroupBySorter(GroupBySorter.rowCountSortInDesc()) .addSubGroupBy(GroupByBuilders.groupByField("cityName", "city") .addSubAggregation(AggregationBuilders.count("cityOrderCounts", "order_id")) .addSubAggregation(AggregationBuilders.max("cityMaxAmount", "order_amount")) .addGroupBySorter(GroupBySorter.subAggSortInDesc("cityMaxAmount")))) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //第 1 レベルのグループ化結果を取得します (各都道府県の注文総数) GroupByFieldResult results = resp.getGroupByResults().getAsGroupByFieldResult("provinceName"); for (GroupByFieldResultItem item : results.getGroupByFieldResultItems()) { System.out.println("都道府県:" + item.getKey() + "\t注文総数:" + item.getSubAggregationResults().getAsCountAggregationResult("provinceOrderCounts").getValue()); //第 2 レベルのグループ化結果を取得します (各市区町村の注文総数および最大注文金額) GroupByFieldResult subResults = item.getSubGroupByResults().getAsGroupByFieldResult("cityName"); for (GroupByFieldResultItem subItem : subResults.getGroupByFieldResultItems()) { System.out.println("\t(市区町村)" + subItem.getKey() + "\t注文総数:" + subItem.getSubAggregationResults().getAsCountAggregationResult("cityOrderCounts").getValue() + "\t最大注文金額:" + subItem.getSubAggregationResults().getAsMaxAggregationResult("cityMaxAmount").getValue()); } } }
複合グループ化
複数のフィールドに基づいてクエリ結果をグループ化します。この機能は、ページネーショントークンを使用したページングをサポートしています。
この機能は、Java SDK および Go SDK のみで利用できます。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
sources
クエリ結果をグループ化するフィールドです。最大 32 個のフィールドでクエリ結果をグループ化し、結果となるグループに対して集約操作を実行できます。次のグループタイプがサポートされています。
-
GroupByField: フィールド値によるグループ化。groupByName、fieldName、groupBySorter パラメーターを設定します。
-
GroupByHistogram: ヒストグラムによるクエリ。groupByName、fieldName、interval、groupBySorter パラメーターを設定します。
-
GroupByDateHistogram: 日付ヒストグラムによるクエリ。groupByName、fieldName、interval、timeZone、groupBySorter パラメーターを設定します。
重要-
sources 内のグループ項目では、辞書順でのグループ値 (groupKeySort) によるソートのみがサポートされています。デフォルトでは、グループは降順でソートされます。
-
特定の列にフィールド値が存在しない場合、返される結果の値は NULL になります。
nextToken
次のページのデータを取得するために使用するページネーショントークンです。デフォルトでは、このパラメーターは空です。
最初のリクエストでは、nextToken を空に設定します。1 回のリクエストでクエリ条件を満たすすべてのデータが返されない場合、レスポンスの nextToken パラメーターは空ではありません。この nextToken を使用してページングクエリを実行します。
説明nextToken を永続化する必要がある場合やフロントエンドページに送信する必要がある場合は、保存または送信する前に Base64 エンコーディングを使用して nextToken を文字列としてエンコードすることを推奨します。nextToken 自体は文字列ではありません。new String(nextToken) を直接使用してエンコードすると、トークン情報が失われます。
size
1 ページあたりのグループ数です。デフォルト値は 10、最大値は 2000 です。
重要-
返すグループ数を制限する必要がある場合は、ほとんどの場合、size パラメーターを設定することを推奨します。
-
size パラメーターと suggestedSize パラメーターを同時に設定することはできません。
suggestedSize
返すグループ数です。サーバー側で許可されている最大グループ数または -1 より大きい値を指定します。サーバー側は、その容量に基づいてグループ数を返します。
このパラメーターをサーバー側で許可されている最大グループ数より大きい値に設定した場合、システムはその値をサーバー側で許可されている最大グループ数に調整します。実際に返されるグループ数は、min(suggestedSize, サーバー側で許可されている最大グループ数, グループの総数) になります。
重要このパラメーターは、Apache Spark や PrestoSQL などの高スループット計算エンジンと Tablestore を相互接続するシナリオに適しています。
subAggregations
各グループ内のデータに対して実行できるサブ集約操作です。たとえば、最大値、合計、平均値の計算などです。
subGroupBys
各親グループ内のデータに対して実行できるサブグループ化操作で、データをさらにグループ化します。
重要subGroupBy では GroupByComposite パラメーターはサポートされていません。
-
-
例
/** * クエリ結果のグループ化と集約: SourceGroupBy パラメーターに渡された groupbyField、groupByHistogram、groupByDataHistogram などのパラメーターに基づいて、クエリ結果をグループ化し、結果となるグループに対して集約操作を実行します。 * 複数フィールドの集約結果をフラット構造で返します。 */ public static void groupByComposite(SyncClient client) { GroupByComposite.Builder compositeBuilder = GroupByBuilders .groupByComposite("groupByComposite") .size(2000) .addSources(GroupByBuilders.groupByField("groupByField", "Col_Keyword") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()).build()) .addSources(GroupByBuilders.groupByHistogram("groupByHistogram", "Col_Long") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5) .build()) .addSources(GroupByBuilders.groupByDateHistogram("groupByDateHistogram", "Col_Date") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5, DateTimeUnit.DAY) .timeZone("+05:30").build()); SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .returnAllColumnsFromIndex(true) .searchQuery(SearchQuery.newBuilder() .addGroupBy(compositeBuilder.build()) .build()) .build(); SearchResponse resp = client.search(searchRequest); while (true) { if (resp.getGroupByResults() == null || resp.getGroupByResults().getResultAsMap().size() == 0) { System.out.println("groupByComposite Result is null or empty"); return; } GroupByCompositeResult result = resp.getGroupByResults().getAsGroupByCompositeResult("groupByComposite"); if(!result.getSourceNames().isEmpty()) { for (String sourceGroupByNames: result.getSourceNames()) { System.out.printf("%s\t", sourceGroupByNames); } System.out.print("rowCount\t\n"); } for (GroupByCompositeResultItem item : result.getGroupByCompositeResultItems()) { for (String value : item.getKeys()) { String val = value == null ? "NULL" : value; System.out.printf("%s\t", val); } System.out.printf("%d\t\n", item.getRowCount()); } // トークンを使用してグループをページングします。 if (result.getNextToken() != null) { searchRequest.setSearchQuery( SearchQuery.newBuilder() .addGroupBy(compositeBuilder.nextToken(result.getNextToken()).build()) .build() ); resp = client.search(searchRequest); } else { break; } } }
範囲によるグループ化
フィールドの値に基づいてクエリ結果をカスタム範囲にグループ化し、各範囲のカウントを返します。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long および Double タイプのみサポートされています。
range[double_from, double_to)
グループ化のための値範囲です。
最小値を指定するには double_from を Double.MIN_VALUE に設定し、最大値を指定するには double_to を Double.MAX_VALUE に設定します。
subAggregation および subGroupBy
サブ集約操作です。グループ化結果に基づいてサブ集約操作を実行します。
たとえば、販売数量と都道府県でクエリ結果をグループ化した後、指定された範囲内で販売数量の割合が最も大きい都道府県を取得するには、GroupByRange 内で GroupByField を指定する必要があります。
-
例
/** * 販売数量を範囲 [0, 1000)、[1000, 5000)、[5000, Double.MAX_VALUE) に基づいてグループ化し、各範囲の販売数量を取得します。 */ public void groupByRange(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByRange("name1", "column_number") .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name1").getGroupByRangeResultItems()) { //行数を表示します。 System.out.println(item.getRowCount()); } }
地理的グループ化
原点からの距離に基づいてクエリ結果をグループ化します。この操作は、指定された距離範囲内のアイテムを同じグループに配置し、各範囲のカウントを返します。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Geo_point タイプのみサポートされています。
origin(double lat, double lon)
中心点の経度と緯度です。
double lat は中心点の緯度を指定します。double lon は中心点の経度を指定します。
range[double_from, double_to)
グループ化に使用する距離範囲です。単位はメートルです。
最小値を指定するには double_from を Double.MIN_VALUE に設定し、最大値を指定するには double_to を Double.MAX_VALUE に設定します。
subAggregation および subGroupBy
サブ集約操作です。グループ化結果に基づいてサブ集約操作を実行します。
-
例
/** * ワンダープラザからの地理的位置に基づいてユーザーをグループ化し、各距離範囲のユーザー数を取得します。距離範囲は [0, 1000)、[1000, 5000)、[5000, Double.MAX_VALUE) です。単位はメートルです。 */ public void groupByGeoDistance(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByGeoDistance("name1", "column_geo_point") .origin(3.1, 6.5) .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集約結果を取得します。 for (GroupByGeoDistanceResultItem item : resp.getGroupByResults().getAsGroupByGeoDistanceResult("name1").getGroupByGeoDistanceResultItems()) { //行数を表示します。 System.out.println(item.getRowCount()); } }
フィルターによるグループ化
指定されたフィルターに基づいてクエリ結果をグループ化します。この集約は、各フィルターに一致するドキュメントの数を返します。結果は、フィルターを追加したのと同じ順序で返されます。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
filter
クエリに使用できるフィルターです。結果は、フィルターを指定した順序で返されます。
subAggregation および subGroupBy
サブ集約操作です。グループ化結果に基づいてサブ集約操作を実行します。
-
例
/** * 次のフィルターを指定して、各フィルターに一致するアイテムの数を取得します: 販売数量が 100 を超える、産地が浙江省、説明に杭州が含まれる。 */ public void groupByFilter(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByFilter("name1") .addFilter(QueryBuilders.range("number").greaterThanOrEqual(100)) .addFilter(QueryBuilders.term("place","Zhejiang")) .addFilter(QueryBuilders.match("text","Hangzhou")) ) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //フィルターの順序に基づいて集約結果を取得します。 for (GroupByFilterResultItem item : resp.getGroupByResults().getAsGroupByFilterResult("name1").getGroupByFilterResultItems()) { //行数を表示します。 System.out.println(item.getRowCount()); } }
ヒストグラムによるグループ化
指定されたデータ間隔に基づいてクエリ結果をグループ化します。同じ間隔内にフィールド値が存在する行は同じグループに配置されます。この操作は、各グループの開始値と対応する行数を返します。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Long および Double タイプのみサポートされています。
interval
集約結果を取得するために使用するデータ間隔です。
fieldRange[min,max]
interval パラメーターとともに使用してグループ数を制限する範囲です。
(fieldRange.max-fieldRange.min)/interval式で決定されるグループ数は 2,000 を超えてはなりません。minDocCount
最小行数です。グループ内の行数が最小行数未満の場合、そのグループの集約結果は返されません。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
-
-
例
/** * 年齢層別のユーザー分布の統計情報を収集します。 */ public static void groupByHistogram(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .addGroupBy(GroupByBuilders .groupByHistogram("groupByHistogram", "age") .interval(10) .minDocCount(0L) .addFieldRange(0, 99)) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = ots.search(searchRequest); //集約操作が実行されたときに返される結果を取得します。 GroupByHistogramResult results = resp.getGroupByResults().getAsGroupByHistogramResult("groupByHistogram"); for (GroupByHistogramItem item : results.getGroupByHistogramItems()) { System.out.println("key:" + item.getKey().asLong() + " value:" + item.getValue()); } }
日付ヒストグラム
日付フィールドのクエリ結果を、指定された時間間隔のバケットにグループ化します。各バケットには同じ間隔からの行が含まれ、開始時刻と行数を返します。
この機能には Tablestore Java SDK 5.16.1 以降が必要です。完全なバージョン履歴については、「Java SDK バージョン履歴」をご参照ください。
-
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
fieldName
集約操作を実行するフィールドの名前です。Date タイプのみサポートされています。
重要検索インデックスの日付型は、Tablestore SDK for Java V5.13.9 以降でサポートされています。
interval
統計的区間。
fieldRange[min,max]
interval パラメーターとともに使用してグループ数を制限する範囲です。
(fieldRange.max-fieldRange.min)/interval式で決定されるグループ数は 2,000 を超えてはなりません。minDocCount
最小行数です。グループ内の行数が最小行数未満の場合、そのグループの集約結果は返されません。
missing
集約操作を実行するフィールドのデフォルト値で、フィールド値が空の行に適用されます。
-
missing パラメーターの値を指定しない場合、その行は無視されます。
-
missing パラメーターの値を指定した場合、そのパラメーターの値が行のフィールド値として使用されます。
timeZone
+hh:mmまたは-hh:mm形式のタイムゾーンです。例:+08:00または-09:00。このパラメーターは、フィールドが Date タイプの場合にのみ必要です。Date タイプのフィールドでこのパラメーターを指定しない場合、集約結果に N 時間のオフセットが発生する可能性があります。この問題を回避するために、timeZone パラメーターを指定してください。
-
-
例
/** * 2017 年 5 月 1 日 10:00:00 から 2017 年 5 月 21 日 13:00:00 までの col_date フィールドのデータの日次分布の統計情報を収集します。 */ public static void groupByDateHistogram(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .returnAllColumns(false) .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .getTotalCount(false) .addGroupBy(GroupByBuilders .groupByDateHistogram("groupByDateHistogram", "col_date") .interval(1, DateTimeUnit.DAY) .minDocCount(1) .missing("2017-05-01 13:01:00") .fieldRange("2017-05-01 10:00", "2017-05-21 13:00:00")) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = ots.search(searchRequest); //集約操作が実行されたときに返される結果を取得します。 List<GroupByDateHistogramItem> items = resp.getGroupByResults().getAsGroupByDateHistogramResult("groupByDateHistogram").getGroupByDateHistogramItems(); for (GroupByDateHistogramItem item : items) { System.out.printf("millisecondTimestamp:%d, count:%d \n", item.getTimestamp(), item.getRowCount()); } }
トップ行集約
クエリ結果をグループ化した後、トップ行集約を使用して各グループから選択された行を取得します。この機能は、MySQL の ANY_VALUE(field) 関数と同様です。
トップ行集約を使用する場合、多次元インデックスにネストタイプ、Geopoint、または配列タイプのフィールドが含まれていると、集約は各行のプライマリキーのみを返します。他のフィールドを取得するには、データテーブルを別にクエリする必要があります。
-
パラメーター
パラメーター
説明
aggregationName
集約操作の一意の名前です。この名前に基づいて特定の集約操作の結果をクエリします。
limit
各グループで返される行の最大数です。デフォルトでは、1 行のデータのみが返されます。
sort
グループ内のデータをソートするために使用するソート方法です。
columnsToGet
返却するフィールド。検索インデックス内のフィールドのみがサポートされています。配列、日付、ジオポイント、およびネストされたフィールドはサポートされていません。
このパラメーターの値は、SearchRequest の columnsToGet パラメーターの値と同じです。SearchRequest の columnsToGet パラメーターにのみ値を指定する必要があります。
-
例
/** * 学校の活動申請フォームには、学生の氏名、クラス、担任教師、クラス委員長などの情報を指定できるフィールドが含まれています。クラスで学生をグループ化して、申請統計と各クラスのプロパティ情報を表示します。 * SQL ステートメント: select className, teacher, monitor, COUNT(*) as number from table GROUP BY className. */ public void testTopRows(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders.groupByField("groupName", "className") .size(5) //返すグループ数を指定します。「多次元インデックスの制限事項」トピックの「GroupByField で返されるグループ数」の説明で、返すグループ数に指定できる最大値をご確認ください。 .addSubAggregation(AggregationBuilders.topRows("topRowsName") .limit(1) .sort(new Sort(Arrays.asList(new FieldSort("teacher", SortOrder.DESC)))) //教師を降順で行をソートします。 ) ) .build()) .addColumnsToGet(Arrays.asList("teacher", "monitor")) .build(); SearchResponse resp = client.search(searchRequest); List<GroupByFieldResultItem> items = resp.getGroupByResults().getAsGroupByFieldResult("groupName").getGroupByFieldResultItems(); for (GroupByFieldResultItem item : items) { String className = item.getKey(); long number = item.getRowCount(); List<Row> topRows = item.getSubAggregationResults().getAsTopRowsAggregationResult("topRowsName").getRows(); Row row = topRows.get(0); String teacher = row.getLatestColumn("teacher").getValue().asString(); String monitor = row.getLatestColumn("monitor").getValue().asString(); } }
複数集約
単一のクエリで複数の集約を組み合わせることができます。
複数の集約を含む複雑なクエリは、応答時間を増加させる可能性があります。
複数集約の組み合わせ
public void multipleAggregation(SyncClient client) {
//クエリ文を作成します。
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.build())
.build();
//クエリ文を実行します。
SearchResponse resp = client.search(searchRequest);
//集約操作の結果から最小値を取得します。
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
//集約操作の結果から合計を取得します。
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
//集約操作の結果から個別値の数を取得します。
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
}集約と GroupBy の組み合わせ
public void multipleGroupBy(SyncClient client) {
//クエリ文を作成します。
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.addGroupBy(GroupByBuilders.groupByField("name4", "type"))
.addGroupBy(GroupByBuilders.groupByRange("name5", "long").addRange(1, 15))
.build())
.build();
//クエリ文を実行します。
SearchResponse resp = client.search(searchRequest);
//集約操作の結果から最小値を取得します。
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
//集約操作の結果から合計を取得します。
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
//集約操作の結果から個別値の数を取得します。
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
//集約操作の結果から GroupByField の値を取得します。
for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name4").getGroupByFieldResultItems()) {
//キーを表示します。
System.out.println(item.getKey());
//行数を表示します。
System.out.println(item.getRowCount());
}
//集約操作の結果から GroupByRange の値を取得します。
for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name5").getGroupByRangeResultItems()) {
//行数を表示します。
System.out.println(item.getRowCount());
}
}付録:複数フィールドによるグループ化方法の比較
複数のフィールドでクエリ結果をグループ化する場合は、ネストモードの groupBy パラメーターまたは GroupByComposite パラメーターを使用します。次の表は、ネストモードの groupBy パラメーターと GroupByComposite パラメーターの違いを示しています。
|
特徴 |
groupBy (ネスト) |
複数フィールドによるグループ化 |
|
size |
2000 |
2000 |
|
フィールドの制限 |
最大 3 レベルまでサポートされています。 |
最大 32 レベルまでサポートされています。 |
|
ページング |
サポートされていません |
nextToken パラメーターを使用してサポートされています |
|
グループ内の行のソートルール |
|
アルファベット順またはアルファベット逆順 |
|
集約のサポート |
はい |
はい |
|
互換性 |
Date タイプのフィールドの場合、クエリ結果は指定された形式で返されます。 |
DATE タイプのフィールドの場合、クエリ結果はタイムスタンプ文字列として返されます。 |