ハイブリッドトランザクション/分析処理 (HTAP) ワークロード用にクラスターを設定するには「クイックスタート」セクションを、特定のビジネス要件に合わせてインメモリ列指向インデックス (IMCI) をカスタマイズするには「高度な使用方法」セクションをご参照ください。
クイックスタート
手順1:読み取り専用 IMCI ノードの追加
PolarDB コンソールにログインします。左側のナビゲーションペインで、クラスター をクリックします。クラスターのリージョンを選択し、対象のクラスターを見つけます。 操作 列で、ノードの追加/削除 をクリックして読み取り専用 IMCI ノードを追加します。
-
クラスターの購入時にすでに読み取り専用 IMCI ノードを追加している場合は、この手順をスキップしてください。
-
クラスターは、IMCI のバージョン要件を満たす必要があります。詳細については、「読み取り専用 IMCI ノード」をご参照ください。
手順2:リクエストルーティングの設定
ビジネス要件に基づいて、IMCI を使用するために自動または手動のリクエストルーティングを選択できます。
-
自動リクエストルーティング:オンライン トランザクション処理 (OLTP) とオンライン分析処理 (OLAP) のワークロードが同じアプリケーションからデータベースにアクセスする場合、スキャン行数で決まる推定実行コストに基づき、読み取りリクエストを読み取り専用 IMCI ノードまたは読み取り専用行ストアノードのいずれかに自動的にルーティングできます。
-
手動リクエストルーティング:OLTP と OLAP のワークロードが異なるアプリケーションからデータベースにアクセスする場合、これらのアプリケーションに異なるクラスターエンドポイントを設定できます。その後、異なるエンドポイントのサービスノードに読み取り専用 IMCI ノードと読み取り専用行ストアノードを割り当て、リクエストを行ストアと列ストアにルーティングできます。
自動リクエストルーティング
クラスター詳細ページで、データベースへの接続 セクションに移動します。クラスターのエンドポイント で、サービスノード を 有効 に設定します。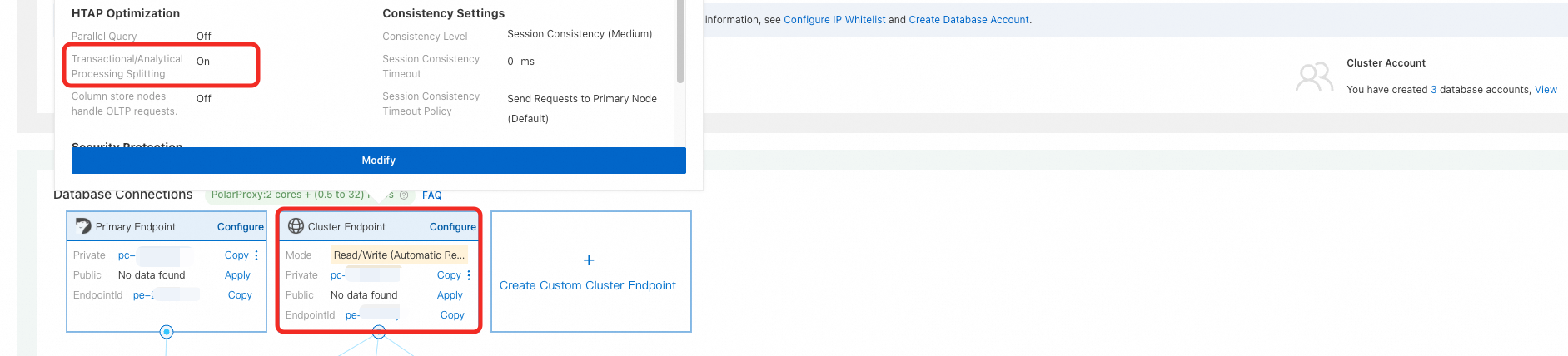
-
サービスノード の変更は、新しい接続にのみ有効です。変更後は、クラスターに再接続してください。
-
DMS を使用してクラスターに接続する場合、DMS はデフォルトで プライマリアドレス を使用することに注意してください。手動でクラスターエンドポイントを使用して PolarDB クラスターに接続する必要があります。
-
自動リクエストルーティングのデフォルトの推定実行コストのしきい値は 50,000 スキャン行です。ビジネス要件に基づいてこのパラメーターを調整することができます。
手動リクエストルーティング
「クラスター詳細」ページで、データベースへの接続 セクションに移動し、カスタムエンドポイントを作成します。サービスノード には、サービスノード のみを含めるようにします。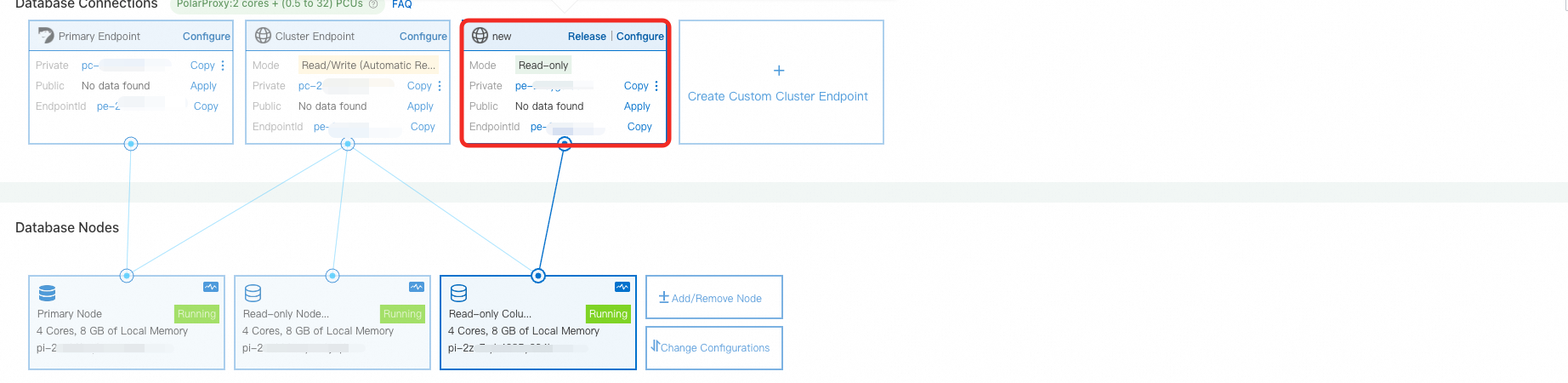
手順3:IMCI の追加
ビジネス要件に基づいて、テーブルに IMCI を手動または自動で追加できます。
クエリを IMCI で高速化するには、SQL ステートメントで参照するすべての列が IMCI で完全にカバーされている必要があります。
手動
IMCI は、ビジネステーブルの IMCI を追加または削除するための完全な DDL ステートメントセットを提供します。ニーズに合ったオプションを選択してください:
|
DDL 構文 |
例 |
|
|
|
|
|
-
IMCI を追加する際、既存のコメントを保持できます。例:
ALTER TABLE <table_name> COMMENT 'COLUMNAR=1 <元のコメント>';。 -
デフォルトでは、データベースまたはテーブルレベルで IMCI を一括で追加すると、テーブルコメントは
'COLUMNAR=1 <元のコメント>'に更新されます。
自動
AutoIndex 機能は、スロークエリに基づいて自動的に IMCI を作成し、実行速度を大幅に向上させることができます。これにより、各スロークエリを理解して調整する必要がなくなります。アプリケーションのワークロードが変化すると、AutoIndex は IMCI 戦略を継続的に監視および調整し、PolarDB クラスターが最適なパフォーマンスを維持できるようにします。
PolarDB クラスター詳細ページで AutoIndex を 有効 するだけで、この機能のメリットを体験できます:

(オプション) 手順4:IMCI のビルド進捗の確認
IMCI を手動で追加した後、ビルドの進捗状況を確認します。クエリを高速化するには、ビルドが完了するのを待ちます。
SELECT * FROM INFORMATION_SCHEMA.IMCI_ASYNC_DDL_STATS;例: STATUS 列の値が Safe to read であることを確認し、IMCI が完全にビルドされたことを確認します。
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
| SCHEMA_NAME | TABLE_NAME | CREATED_AT | STARTED_AT | FINISHED_AT | STATUS | APPROXIMATE_ROWS | SCANNED_ROWS | SCAN_SECOND | SORT_ROUNDS | SORT_SECOND | BUILD_ROWS | BUILD_SECOND | AVG_SPEED | SPEED_LAST_SECOND | ESTIMATE_SECOND |
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
| tpch | lineitem | 2024-10-21 13:44:02 | 2024-10-21 13:44:02 | 2024-10-21 13:50:11 | Safe to read | 590446240 | 600037902(100%) | 369 | 0 | 0 | 0(0%) | 0 | 1625058 | 0 | 0 |
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
1 row in set, 1 warning (0.00 sec)(オプション) 手順5:IMCI の使用状況の確認
IMCI の実行計画は水平ツリーとして表示され、行ストアの実行計画とは形式が大きく異なります。EXPLAIN ステートメントを使用して実行計画を表示し、SQL ステートメントが IMCI で高速化できるかどうかを判断できます。次の例でその違いを示します:
IMCI 実行計画
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
| ID | Operator | Name | E-Rows | E-Cost | Extra Info |
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
| 1 | Select Statement | | | | IMCI Execution Plan (max_dop = 4, max_query_mem = 858993459) |
| 2 | └─Sort | | | | Sort Key: revenue DESC,o_orderdate ASC |
| 3 | └─Hash Groupby | | | | Group Key: (lineitem.L_ORDERKEY, orders.O_ORDERDATE, orders.O_SHIPPRIORITY) |
| 4 | └─Hash Join | | | | Join Cond: orders.O_ORDERKEY = lineitem.L_ORDERKEY |
| 5 | ├─Hash Join | | | | Join Cond: customer.C_CUSTKEY = orders.O_CUSTKEY |
| 6 | │ ├─Table Scan | customer | | | Cond: (C_MKTSEGMENT = "BUILDING") |
| 7 | │ └─Table Scan | orders | | | Cond: (O_ORDERDATE < 03/24/1995) |
| 8 | └─Table Scan | lineitem | | | Cond: (L_SHIPDATE > 03/24/1995) |
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
8 rows in set (0.01 sec)行ストア実行計画
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
| 1 | SIMPLE | customer | NULL | ALL | PRIMARY | NULL | NULL | NULL | 147630 | 10.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | orders | NULL | ref | PRIMARY,ORDERS_FK1 | ORDERS_FK1 | 4 | tpch100g.customer.C_CUSTKEY | 14 | 33.33 | Using where |
| 1 | SIMPLE | lineitem | NULL | ref | PRIMARY | PRIMARY | 4 | tpch100g.orders.O_ORDERKEY | 4 | 33.33 | Using where |
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
3 rows in set, 1 warning (0.00 sec)ヘルパーツール
IMCI を使用して複雑な SQL ステートメントでクエリを実行する場合、SQL ステートメント内の列が IMCI でカバーされていないかどうかを確認する必要があります。カバーされていない列が見つかった場合は、SQL ステートメントの IMCI を作成するための DDL ステートメントを取得したり、特定のワークロードに対してIMCI を作成するための DDL ステートメントを一括で取得したりできます。DDL ステートメントを実行した後、SQL ステートメントで参照するすべての列が IMCI でカバーされていることを確認し、クエリの高速化を有効にします。
PolarDB は、以下の組み込みストアドプロシージャを提供します:
-
SQL ステートメント内の列が IMCI でカバーされているか確認する:
dbms_imci.check_columnar_index('<query_string>');。 -
IMCI を作成するための DDL ステートメントを取得する:
dbms_imci.columnar_advise('<query_string>');およびdbms_imci.columnar_advise_by_columns('<query_string>');。 -
IMCI を作成するための DDL ステートメントを一括で取得する:
dbms_imci.columnar_advise_begin();、dbms_imci.columnar_advise_show();、およびdbms_imci.columnar_advise_end();。
よくある質問
詳細については、「IMCI FAQ」をご参照ください。
高度な使用方法
IMCI の使用を最適化するには、以下のトピックをご参照ください。
|
高度な機能 |
説明 |
|
IMCI はデータを行グループに整理します。各行グループでは、異なる列が列データブロックにパックされます。これらのブロックは、元の行ベースデータのプライマリキーの順序に基づいて並列に構築されるため、全体としては順序付けられていません。ソートキーを設定して列データブロックを並べ替え、クエリのパフォーマンスを向上させることができます。 |
|
|
IMCI は、列指向 JSON、仮想列、インスタント DDL、列数拡張などの一連の機能を統合し、大規模な構造化および半構造化データ分析を処理します。 |
|
|
抽出、変換、ロード (ETL) 機能により、読み書き (RW) ノードで IMCI を使用できます。RW ノードで発行された |
|
|
サーバーレス機能は、ワークロードに基づいてリソースを自動的にスケールアップおよびスケールダウンします。ピーク時にはスケールアップしてワークロードの急増に対応し、オフピーク時にはスケールダウンしてコストを削減します。 |
|
|
ハイブリッドプランは、同じクエリで列インデックスと行インデックスの両方を使用します。ハイブリッドプランは、ワイドテーブルクエリのパフォーマンスを大幅に向上させることができます。実行計画では、列インデックスの恩恵を受ける部分は IMCI で実行され、プライマリキーのみを含む中間結果を生成します。その後、InnoDB プライマリインデックスを使用してプライマリキーで必要な列がフェッチされ、返されます。 |
|
|
大量データに対する複雑なクエリの場合、単一の読み取り専用 IMCI ノードではパフォーマンス要件を満たせない場合があります。超並列処理 (MPP) を使用してクエリを高速化できます。 |
詳細情報
IMCI の背後にある原則についてさらに学ぶには、次のドキュメントをご参照ください:
-
PolarDB インメモリ列指向インデックス (IMCI) の SIGMOD 2023 発表論文