デフォルトでは、PolarDBのインメモリ列インデックス (IMCI) エグゼキュータは行番号を使用して中間結果を示します。 大規模なクエリに必要なデータ量をメモリに完全に格納できない場合、多数のランダムなI/O操作と繰り返しのI/O操作が発生する可能性があり、実行効率に影響を与えます。 この問題を解決するために、IMCIエグゼキュータは、中間結果の具体化に基づいて演算子のセットを実装します。 このトピックでは、Hash Join演算子を使用して中間結果を具体化するHash Match演算子の実装について説明します。
実行プラン
Hash Match演算子の実装は、ビルドフェーズとプローブフェーズの2つのフェーズで構成されます。 第1の段階では、結合述語が、左テーブルの各行をハッシュテーブルに構築するためのキーとして取られる。 第2のフェーズでは、右テーブルがトラバースされ、データエントリが、右テーブルおよびハッシュテーブルの結合述語に基づいて照合される。 次に、異なるタイプの結合のマッチング結果に基づいて、結果セットが出力される。
ビルドフェーズでは、1つのハッシュテーブルを使用して、左側のテーブルのすべてのデータを含めることができます。 ただし、すべてのデータを含むハッシュテーブルは大きすぎます。 重大な競合が発生するか、ビルドプロセス中にスケールアウトまたはスケールアップを継続する必要があります。 したがって、ビルドフェーズでは、特定のルールに基づいて左側のテーブルのデータをパーティション化し、パーティションごとに独立したハッシュテーブルを構築できます。 プローブフェーズでは、システムは、右側のテーブルの行が存在するパーティション内のハッシュテーブルを検索します。
ビルドフェーズ
IMCIが有効な操作では、ハッシュマッチ演算子のビルド機能がdoOpenに実装されます。これは、doBuildとdoMergeの2つのフェーズで構成されます。 各フェーズでは、スレッドグループを使用して同時処理を実行します。
DoBuild
doBuildフェーズでは、スレッドグループ内のワーカースレッドは、左側のテーブルのデータを使用して、各パーティションの独立したハッシュテーブルを構築します。
ワーカー \パーティション | パーティション0 | パーティション1 | ... | パーティションN |
Worker0 | HashMap00 | HashMap01 | ... | HashMap0N |
Worker1 | HashMap10 | HashMap11 | ... | HashMap1N |
... | ... | ... | ... | ... |
労働者 | HashMapM0 | HashMapM1 | ... | HashMapMN |
ハッシュテーブルは、ワーカースレッドを使用してパーティションごとに構築されます。 また、チャンク群を生成して実体化結果を格納する。 ハッシュテーブルのUInt64タイプの値は、現在のキーに対応するチャンクの位置のみを示します。 UInt64値は、UInt16、UInt16、およびUInt32の3つの部分に分割できます。 最初のUInt16値は、チャンクが属するワーカースレッドを示します。 第2のUInt16値は、チャンクのオフセットを示す。 UInt32値は、チャンクの配列インデックスを示します。 ワーカースレッドは、左側のテーブルからタプルを並列に取得し、パーティション規則に基づいてロックすることなく、ワーカースレッドとパーティションに対応するハッシュテーブルにタプルを挿入します。 このプロセスは、左のテーブルのすべてのデータが検索されるまで繰り返される。
DoMerge
doBuildフェーズが完了すると、ワーカースレッドを使用して各パーティションのハッシュテーブルが作成されます。 構築フェーズで構築されたハッシュテーブルは、探索が一致するかどうかを判定するためにプローブフェーズで使用される。 したがって、データがビルドフェーズで分割される場合、データは、プローブフェーズでの分割規則に基づいて、対応するハッシュテーブルで検索されなければならない。 doBuildフェーズでは、パーティションごとにハッシュテーブルが作成されます。 それらは、プローブ相で1つずつ検索することができる。 しかし、このプロセスは便利ではなく、クエリのパフォーマンスを低下させます。 したがって、Hash Match演算子は、パーティション内のすべてのハッシュテーブルをdoMergeフェーズで1つにマージします。
\パーティションの構築 | パーティション0 | パーティション1 | ... | パーティションN |
マージ | HashMap0 | HashMap1 | ... | HashMapN |
doMergeフェーズは、スレッドグループによって実行されます。 無意味なロック同期を防ぐために、パーティション内のハッシュテーブルは、ワーカースレッドによって独立してマージされます。 パーティションの数がワーカースレッドの数よりも多い。 したがって、doMergeフェーズでは、各ワーカースレッドのワークロードは基本的に同じです。
ビルドフレーズでのデータの流出
各ワーカースレッドのワークロードは基本的に同じです。 したがって、各ワーカースレッドが処理するデータ量は同じであり、総メモリの平均値を各ワーカースレッドのメモリクォータと見なすことができます。
メモリサイズには制限があり、Hash Match演算子はメモリ内のすべてのパーティションのハッシュテーブルとチャンクを格納できません。 ハッシュテーブルとチャックはすべてパーティションで分割されています。 したがって、メモリが不足している場合、パーティションによって余分なデータがディスクに流出します。
このようにして、ビルドフェーズおよびプローブフェーズにおける動作は、メモリ内のパーティションにおいて正常に実行することができる。 現在、Hash Match演算子は、メモリ内のパーティションが正常に処理できるようになるまで、最も高いパーティションから開始して、パーティション全体のデータをスピルします。 パーティションを処理できない場合、OutOfMemoryError例外がスローされます。
doBuildフェーズで、キーと値のペアをハッシュテーブルに追加できない場合、またはメモリ不足のためにチャンクのデータをワーカースレッドに格納できない場合、ワーカースレッドの最上位パーティションのデータをディスクにスピルする必要があります。 チャンクは一時ファイルに書き込まれ、チャンクのメモリが解放され、ハッシュテーブルが削除されます。 パーティションを処理する必要がある場合、一時ファイル内のチャンクが読み取られ、チャンクを使用してパーティションのハッシュテーブルが構築されます。 ワーカースレッドの最上位パーティションの数は、他のワーカースレッドに表示されます。 ワーカースレッドの最上位パーティションの数が他のワーカースレッドの数よりも多い場合、ワーカーは最上位パーティションの数を更新し、メモリを解放します。 doBuildフェーズでは、ワーカースレッドは、パーティション番号が既存の最大数よりも大きいパーティションにハッシュテーブルを構築しません。 データはチャンクに格納され、チャンクがいっぱいになるとディスクにスピルされます。
プローブフェーズ
ビルドフェーズでは、左側のテーブルが読み取られ、ハッシュテーブルを構築するために使用されます。 プローブフェーズでは、ビルドフェーズでビルドされたハッシュテーブルのマッチング結果に基づいて、ライトテーブルのデータが読み出されて出力される。 データはビルドフェーズで分割されます。 したがって、プローブフェーズにおける動作は、同じ分割規則に基づいて実行されなければならない。
DoFetch
プローブフェーズでは、スレッドグループはデータを処理するために使用され、親ノードでのメモリフェッチ操作によって駆動されます。 doFetchフェーズでは、Hash Match演算子のワーカースレッドが右テーブルのデータをフェッチし、特定のパーティションのハッシュテーブルでフェッチされたタプルを検索します。 検索されたタプルは、マッチング結果に基づいて処理される。 このプロセスは、すべてのワーカースレッドが右側のテーブルからデータをフェッチするまで繰り返されます。
プローブフレーズにデータがこぼれる
ビルドフェーズのすべてのパーティションを格納するにはメモリが不十分な場合、プローブフェーズのメモリとディスクを別々にパーティション分割する必要があります。
doFetchフェーズでは、ワーカースレッドが右テーブルからデータをフェッチした後、タプルに対応するパーティションがメモリ内にある場合、ワーカースレッドは、マッチングのためにハッシュテーブルを直接検索する。 パーティションがディスク内にある場合、タプルは、ワーカースレッドが属するパーティションのチャンク内に格納される必要がある。 チャンクが満杯の場合、データをディスクにフラッシュし、チャンクのメモリを解放する必要があります。 すべてのワーカースレッドが右テーブルからデータをフェッチし、プローブフェーズが完了した後、メモリ内のパーティションデータが処理され、解放されます。
メモリ内のすべてのパーティションが処理された後、ディスク内のパーティションが処理されます。 ディスク内のパーティションのデータは、パーティションごとに異なる一時ファイルに格納されます。 したがって、ロック同期を防止するために、プローブフェーズでは、各ディスクパーティションはワーカースレッドによって独立して処理される。 パーティションの数がワーカースレッドの数よりも多い。 したがって、各ワーカースレッドのワークロードは基本的に同じです。
ワーカーを使用したディスク内のパーティションの処理も、ビルドフェーズとプローブフェーズの2つのフェーズで構成されます。
ビルドフェーズでは、ワーカースレッドが左側のテーブルのパーティションの一時ファイルからデータを読み取り、チャンクをシリアル化します。 次に、ワーカースレッドは、チャンクのデータに基づいてハッシュテーブルを構築しました。 このプロセスは、すべてのワーカースレッドが左側のテーブルからデータを読み取るまで繰り返されます。
プローブフェーズでは、ワーカースレッドが右側のテーブルのパーティションの一時ファイルからデータを読み取り、チャンクをシリアル化します。 次に、ワーカースレッドは、一致する結果に基づいてタプルを検索および処理します。 このプロセスは、すべてのワーカースレッドが左側のテーブルからデータを読み取るまで繰り返されます。
パーティションが処理された後、ハッシュ一致演算子は完了します。 メモリパーティションおよびディスクパーティションの処理は、この参考文献では異なって説明されている。 ただし、実装はコードのセットに統合されます。
プローブ関連プロセス
プローブ関連プロセスは、ProbeMem、ProbeLeft、およびProbeDiskのステップからなる。 すべてのステップは、プローブ関数を使用して実行されます。
ProbeMenステージでは、データは右のテーブルから読み取られ、データパーティションに基づいてメモリまたはディスクで処理されます。 メモリでプローブ関数を呼び出さない場合は、一時ファイルにデータを格納します。 このように、ProbeDiskステップでは、特定のディスクパーティション内のデータを、プローブ関数を使用してロードし、処理することができる。
ProbeLeftステージでは、LEFT OUTER JOIN、LEFT SEMI JOIN、LEFT ANTI SEMI JOINなどのLEFT JOIN操作が実行されます。 ハッシュテーブル内のすべてのキーと値のペアがトラバースされ、一致または不一致のタプルが除外されます。
ProbeDiskステージでは、パーティションごとにディスクパーティションでプローブ操作が実行されます。 ディスクパーティションが処理されると、一時ファイル内のチャンクが読み込まれ、プローブ機能によって処理されます。 LEFT JOINオペレーションが実行される場合、JOINオペレーションは、パーティションを処理するために呼び出されなければならない。
論理を結合する
ハッシュマッチ演算子は、INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN、LEFT SEMI JOIN、LEFT ANTI SEMI JOIN、RIGHT ANTI SEMI JOIN、およびPostFilter機能をサポートします。 すべてのJOIN操作は、ビルドフェーズとプローブフェーズで構成されます。 ビルド段階は、NULL値の処理を除いて基本的に同じです。 プローブ位相は異なります。 次のセクションでは、さまざまな種類のJOIN操作の処理ロジックの概要を説明します。
インナー
右側のテーブルのタプルがNULLではなく、左側のテーブルに基づいて作成されたハッシュテーブルと一致する場合、左右のテーブルのタプルが出力されます。
LeftOuter
右側のテーブルのタプルがNULLではなく、左側のテーブルに基づいて作成されたハッシュテーブルと一致する場合、左右のテーブルのタプルが出力されます。 一致しない左側のテーブルのすべてのタプルが出力され、右側のテーブルの対応する位置がNULLに設定されます。 PostFilterがLEFT OUTER JOINに存在する場合、左側のテーブルに基づいて作成された一致するハッシュテーブルは、PostFilter機能を使用して検証する必要があります。
RightOuter
右側のテーブルのタプルがNULLではなく、左側のテーブルに基づいて作成されたハッシュテーブルと一致する場合、左右のテーブルのタプルが出力されます。 そうでない場合、タプルは出力され、左テーブル内の対応する位置はNULLに設定される。 PostFilterがRIGHT OUTER JOINに存在する場合、左側のテーブルに基づいて作成された一致したハッシュテーブルは、PostFilter機能を使用して検証する必要があります。
LeftSemi
LEFT SEMI JOINはLEFT OUTER JOINに似ています。 左右のテーブルのタプルは出力されません。 左の表のタプルとNULL、TRUE、またはFALSE値は、次の真理値表に基づいて出力されるか、左の表のタプルのみが出力されるか、または値が出力されません。 LEFT SEMI JOINにPostFilterが存在する場合、左側のテーブルに基づいて作成された一致するハッシュテーブルは、PostFilter機能を使用して検証する必要があります。
//+------------------------------+--------------+----------------+
// | mathched | semi_probe_ |! semi_probe_ |
//+------------------------------+--------------+----------------+
// | normal true | (left, TRUE) | (left, ONLY) |
//+------------------------------+--------------+----------------+
//+------------------------------+--------------+----------------+
//| ! mathched | semi_probe_ |! semi_probe_ |
//+------------------------------+--------------+----------------+
// | NULL v.s。 (空セット) | | |
// | 例えば、NULL IN (空セット) | (左、偽) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
// | NULL v.s。 (セット) | | |
// | たとえば、NULL IN (1、2、3) | (左、NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
// | left_row v.s. (NULLで設定) | | |
// | 例: 10 IN (1, NULL, 3) | (left, NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
// | 通常のfalse | | |
// | 例えば、10 IN (1、2、3) | (left, FALSE)| NO_OUTPUT |
//+------------------------------+--------------+----------------+LeftAntiSemi
LEFT ANTI SEMI JOINはLEFT OUTER JOINに似ています。 左右のテーブルのタプルは出力されません。 次の真理値表に基づいて、左側の表のタプルのみが出力されるか、値が出力されません。 PostFilterがLEFT ANTI SEMI JOINに存在する場合、左側のテーブルに基づいて作成された一致したハッシュテーブルは、PostFilter機能を使用して検証する必要があります。
//+------------------------------+----------------+
//| ! mathched |! semi_probe_ |
//+------------------------------+----------------+
// | NULL v.s。 (空セット) | |
// | 例えば、NULL NOT IN (空セット) | (左、のみ) |
//+------------------------------+----------------+
// | NULL v.s。 (セット) | |
// | 例えば、NULL NOT IN (1、2、3) | (left, ONLY) |
//+------------------------------+----------------+
// | left_row v.s. (NULLで設定) | |
// | 例えば、10 NOT IN (1, NULL, 3) | (left, ONLY) |
//+------------------------------+----------------+
// | 通常のfalse | |
// | 例えば、10 NOT IN (1、2、3) | (left, ONLY) |
//+------------------------------+----------------+RightSemi
RIGHT SEMI JOINはRIGHT OUTER JOINに似ています。 左右のテーブルのタプルは出力されません。 右テーブルのタプルとNULL、TRUE、またはFALSE値は、次の真理値表に基づいて出力されるか、右テーブルのタプルのみが出力されるか、または値が出力されません。 PostFilterがRIGHT SEMI JOINに存在する場合、左側のテーブルに基づいて作成された一致したハッシュテーブルは、PostFilter機能を使用して検証する必要があります。
//+------------------------------+--------------+----------------+
// | mathched | semi_probe_ |! semi_probe_ |
//+------------------------------+--------------+----------------+
// | normal true | (right, TRUE)| (right, ONLY) |
//+------------------------------+--------------+----------------+
//+------------------------------+--------------+----------------+
//| ! mathched | semi_probe_ |! semi_probe_ |
//+------------------------------+--------------+----------------+
// | NULL v.s。 (空セット) | | |
// | 例えば、NULL IN (空のセット) | (右、偽) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
// | NULL v.s。 (セット) | | |
// | 例えば、NULL IN (1、2、3) | (右、NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
// | left_row v.s. (NULLで設定) | | |
// | 例えば、10 IN (1, NULL, 3) | (右, NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
// | 通常のfalse | | |
// | 例えば、10 IN (1、2、3) | (右、偽) | NO_OUTPUT |
//+------------------------------+--------------+----------------+RightAntiSemi
RIGHT SEMI JOINはRIGHT OUTER JOINに似ています。 左右のテーブルのタプルは出力されません。 右テーブルのタプルは、次の真理値表に基づいて出力されるか、右テーブルのタプルのみが出力されるか、値が出力されません。 PostFilterがRIGHT ANTI SMEI JOINに存在する場合、左側のテーブルに基づいて作成された一致したハッシュテーブルは、PostFilter機能を使用して検証する必要があります。
//+------------------------------+----------------+
//| ! mathched |! semi_probe_ |
//+------------------------------+----------------+
// | NULL v.s。 (空セット) | |
// | 例えば、NULL NOT IN (空セット) | (右のみ) |
//+------------------------------+----------------+
// | NULL v.s。 (セット) | |
// | 例えば、NULL NOT IN (1、2、3) | (右、のみ) |
//+------------------------------+----------------+
// | left_row v.s. (NULLで設定) | |
// | 例えば、10 NOT IN (1, NULL, 3) | (右, のみ) |
//+------------------------------+----------------+
// | 通常のfalse | |
// | 例えば、10 NOT IN (1、2、3) | (右、のみ) |
//+------------------------------+----------------+ハッシュマッチ演算子の実装
Hash Match演算子は、メモリとディスクの処理、複数のJOIN操作、およびPostFilter機能を含むプロセスを定義します。
HashMap
Hash Match演算子を実装するために、書き込み操作とクエリ操作が提供されます。
size_t PutValue(uint64_t hash_code、const char * key_buf、uint64_t key_len、const uint64_tタプル);
ValueIterator FindValue(uint64_t hash_code、const char * key_data、const uint64_t key_len、const bool need_mark = false); ハッシュテーブル全体をトラバースするために2つのイテレータが用意されています。
enum IteratorType { Normal = 0, NoneMark = 1, Mark = 2, END };
クラスTableIterator {
public:
void Next();
bool IsValid() const { return valid_; }
ValueIterator GetIterator(IteratorType型);
プライベート:
IteratorTypeタイプ_ = IteratorType::END;
};
クラスValueIterator {
structリスナー {
virtual void BlockEvent() {}
};
void SetListener(Listener * listener) { listener_ = listener; }
void Next();
bool IsValid() const { return valid_; }
private:
IteratorTypeタイプ_ = IteratorType::Normal;
Listener * listener_ = nullptr;
};TableIteratorイテレータはハッシュテーブル内のすべてのキーと値のペアをトラバースし、ValueIteratorイテレータはキーと値のペアのすべてのデータブロックをトラバースします。 どちらのイテレータも、異なるJOIN操作に適用される次の3つの反復モデルをサポートします。Normal、NoneMark、およびMark。
TableIteratorイテレータはすべてのハッシュテーブルをトラバースし、主にLEFT_OUTER、LEFT_ANTI_SEMI、およびLEFT_SEMIに適用されます。
情報
HMInfoは、メモリパーティション番号やパーティションオブジェクトなど、すべてのワーカーが共有するグローバルデータを格納します。 パーティションは、現在のパーティションのマージされたハッシュテーブル、左右のテーブルのチャンクセット、および左右のテーブルの一時ファイルを格納します。 Hash Match演算子は、パーティションごとに一時ファイルを生成します。 ワーカーは、pread関数、pwrite関数、およびoffsetアトミック変数を使用して、アトミックな読み取りおよび書き込み操作を実行できます。
ローカル情報
HMLocalInfoには、現在のワーカーのメモリパーティション番号や左右のHMLocalPartitionsなど、現在のワーカーのプライベートデータが格納されます。 各HMLocalPartitionは、ワーカーの現在のパーティションのハッシュテーブル、チャンクセット、および書き込まれているチャンクオブジェクトを格納します。
フェッチャー
Hash Match演算子は、左側のテーブルからのデータのフェッチ、右側のテーブルからのデータのフェッチ、InfoまたはLocalInforメモリのチャンクセットからのチャンクオブジェクトの読み取り、一時ファイルからのチャンクオブジェクトの読み取りとシリアル化など、複数のフェッチメソッドをサポートします。 これらのメソッドはすべて、ビルドおよびプローブフェーズのチャンクからデータをフェッチするために使用できます。
クラスHashMatchFetcher final {
boolフェッチ (コンテキスト&コンテキスト、TupleChunk *&mat_chunk);
// 左または右の子からフェッチする
bool FetchMem (コンテキスト&コンテキスト);
// 情報チャンクからのフェッチ (一時ファイルからのロードを含む)
bool FetchDisk (コンテキスト&コンテキスト、TupleChunk *&mat_chunk);
size_t part_index_ = 0;
TupleChunkチャンク_;
}; ビルダー
Builderは、doBuildフェーズでメモリパーティションとディスクパーティションを集中的に処理します。
MemBuilder: 左側のテーブルのデータがフェッチされ、チャンクセットに格納されます。 タプルがメモリパーティションに属する場合、ハッシュテーブルが書き込まれる。 タプルがディスクパーティションに属する場合、チャンクのデータはディスクにスピルされる。
DiskBuilder: チャンクセットは一時テーブルから読み取られ、このパーティションのハッシュテーブルを構築するために使用されます。
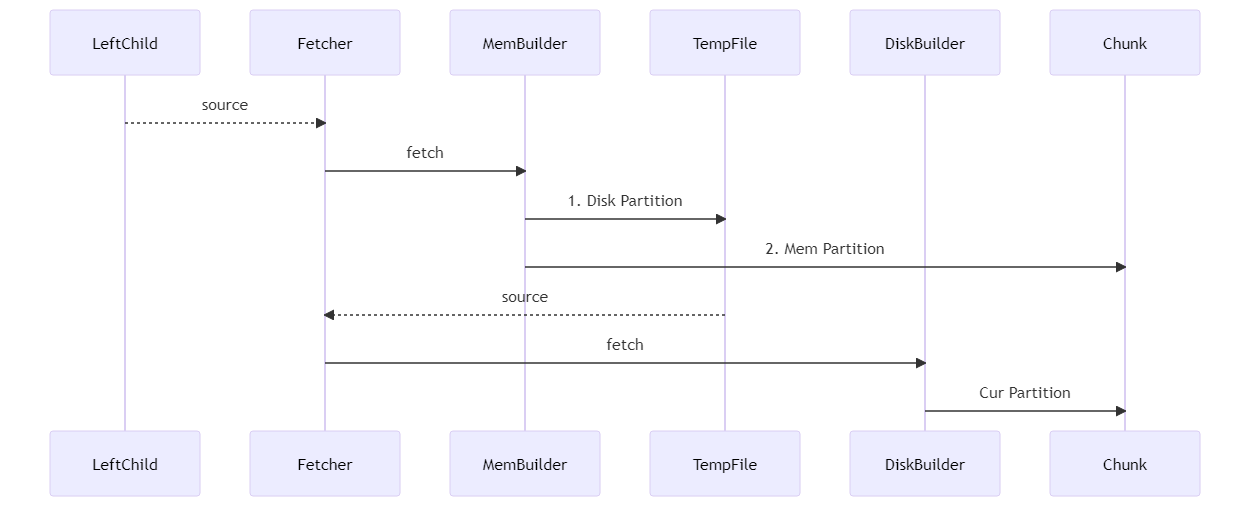
クラスHashMatchBuilder {
voidビルド ();
virtual void ChunkResult(const size_tオフセット、const bool is_null、
const size_t part_index、const uint64_t hash_val、
const char * key_data, const size_t key_len) = 0;
仮想ボイドChunkDone() = 0;
HashMatchFetcherフェッチャー_;
};
クラスHashMatchMemBuilder final: パブリックHashMatchBuilder {
void ChunkResult(const size_tオフセット、const bool is_null、
const size_t part_index、const uint64_t hash_val、
const char * key_data、const size_t key_len) オーバーライド;
void ChunkDone() オーバーライド;
TupleChunk origin_chunk_;
};
クラスHashMatchDiskBuilder final: パブリックHashMatchBuilder {
void ChunkResult(const size_tオフセット、const bool is_null、
const size_t part_index、const uint64_t hash_val、
const char * key_data、const size_t key_len) オーバーライド;
void ChunkDone() オーバーライド;
const size_t part_index_ = 0;
}; Prober
プローブフェーズでのProbeMen、ProbeLeft、およびProbeDisk操作はすべて、Proberのプローブ機能を使用して実行されます。
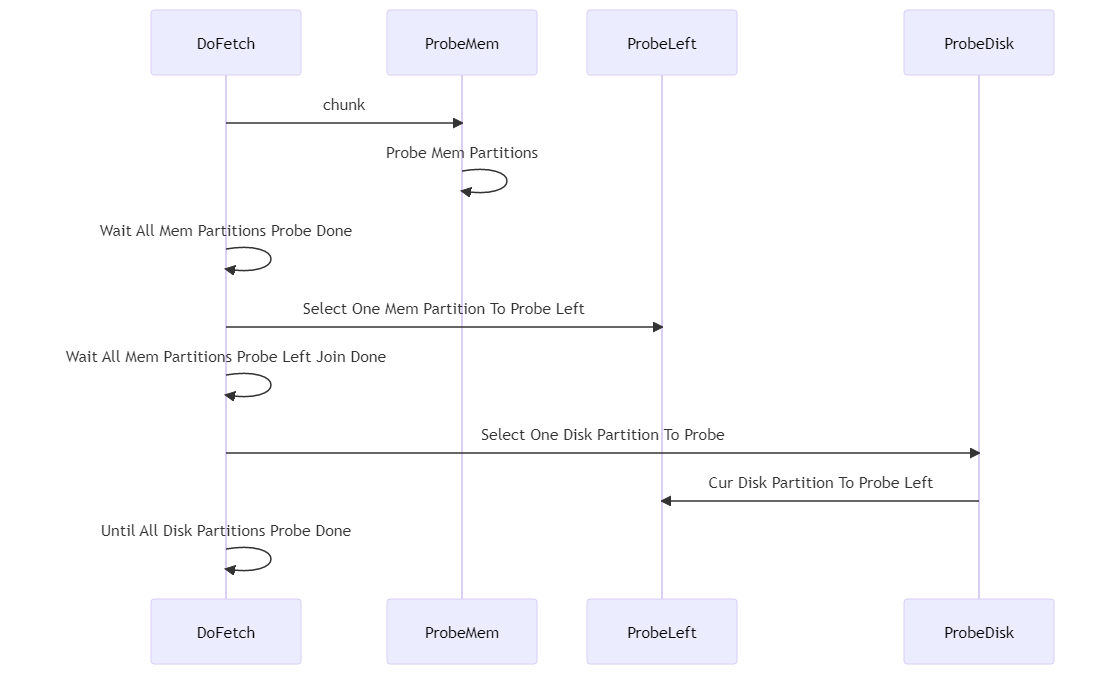
クラスHashMatchProber final {
public:
void ProbeResult(TupleChunk * tpchunk, size_t &chunk_off, const size_t chunk_size);
bool ProbeIter (コンテキストとコンテキスト、TupleChunk * tpchunk、size_t &chunk_off、const size_t chunk_size);
boolプローブ (コンテキスト&コンテキスト、TupleChunk * tpchunk、size_t &chunk_off、const size_t chunk_size、const boolディスク);
private:
const HashMatch &join_;
HMInfo * info_ = nullptr;
HMLocalInfo * local_info_ = nullptr;
size_t part_index_ = 0;
PostFilterフィルター_;
LeftIteratorが点灯_;
RightIterator rit_;
TraverseIterator tit_; // プローブ左に使用
}; HashMatchProber::PostFilterは、PostFilter機能を使用してJOIN操作のプローブを処理します。 プローブフェーズの後にフェッチされた結果セットは、PostFilterによって検証する必要があります。
struct PostFilter final {
bool Evaluate();
boolプローブ (TupleChunk * tpchunk、size_t &chunk_off、const size_t chunk_size);
const HashMatchProber &prober_;
const RTExprTreePtr &post_expr_;
const HashMatchExpr &left_expr_;
const HashMatchExpr &right_expr_;
std::shared_ptr <式::ExprEnv> post_env_ = nullptr;
};Proberは、LeftIterator、RightIterator、およびTraverseIteratorのイテレータをサポートしています。
struct Iterator {
virtual void InitExpr() {}
virtual void FiniExpr() {}
仮想void Init(const size_t part_index);
仮想ボイドFini();
virtual bool有効 (コンテキストとコンテキスト) { return false; }
virtual void Next() = 0;
HashMatchProber&プローバー_;
PostFilter &filter_;
};HashMatchProber::LeftIteratorは、HashMap::ValueIteratorを使用して、ハッシュテーブル内の特定のキーのすべての値をトラバースし、その値に基づいて特定のチャンクタプルを見つけます。 このように、指定されたキーのすべてのタプルは、異なるタイプのJOIN操作とPostFilter機能を処理するために提供されます。
// プローブ用
struct LeftIterator final : public Iterator, public ValueIterator::Listener {
void BlockEvent() オーバーライド;
bool有効な (コンテキストとコンテキスト) オーバーライド;
void Next() オーバーライド;
bool Find(const size_t part_index、const uint64_t hash_val、
const char * key_data、const uint64_t key_len);
ValueIterator it_;
};HashMatchProber::RightIteratorは、HashMatchFetcherを継続的に使用して、適切なテーブルまたは一時ファイルからチャンクセットをフェッチし、すべてのチャンクとすべてのタプルをトラバースする機能を提供します。 すべてのJOIN操作は、ProbeMemまたはProbeDiskステージでRightIteratorを使用してチャンクをフェッチし、パーティション内のハッシュテーブルを検索します。 ハッシュテーブルが存在する場合、キーのすべてのタプルをトラバースするためにLeftIteratorオブジェクトが確立されます。 さらに、LEFT JOINも、ProbeLeftを使用して処理する必要があります。
// プローブ用
構造体RightIterator: パブリックIterator {
bool有効な (コンテキストとコンテキスト) オーバーライド;
void Next() オーバーライド;
HashMatchFetcherフェッチャー_;
TupleChunk origin_chunk_;
size_t chunk_size_ = 0;
};HashMatchProber::TraverseIteratorは、主にLEFT OUTER JOIN、Left SEMI JOIN、LEFT ANTI SEMI JOINなどのLEFT JOINに使用されます。 HashMap::TableIteratorを使用してハッシュテーブル全体をトラバースし、一致または不一致のキーを除外し、LeftIteratorを使用してキーのすべてのタプルをトラバースします。 LEFT JOINは、ProbeMemまたはProbeDiskを使用してハッシュテーブルを検索し、照合を実行します。 ハッシュテーブルが一致する場合、ハッシュテーブル内のキーと値のペアがマークされます。 次に、ProbeLeftはTraverseIteratorを使用して、一致または一致しないキーと値のペアを除外します。
// for ProbeLeft
struct TraverseIterator final: パブリックIterator {
bool有効な (コンテキストとコンテキスト) オーバーライド;
void Next() オーバーライド;
TableIterator tit_;
LeftIteratorが点灯_;
IteratorType it_type_ = IteratorType::END;
};テスト
Hash Join演算子とHash Match演算子のパフォーマンスを比較するテストが実行されます。 テストでは、両方のオペレーターを使用して、TPCベンチマーク-H (TPC-H) のQ14を実行します。 照会するデータのサイズは1テラバイトです。 2つの演算子は同様のアルゴリズムを使用します。 違いは、中間結果が具体化されるかどうかです。
select
100.00 * sum (場合)
「PROMO % 」のようなp_typeのとき
その後l_extendedprice * (1 - l_discount)
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
から
lineitem,
部分
ここで
l_partkey = p_partkey
およびl_shipdate >= date '1995-09-01'
およびl_shipdate < date '1995-09-01 '+ interval '1' 月; クエリは、100 GBのLRUキャッシュと実行メモリで実行されます。
クエリ (TPCH1T)
HashJoin
HashMatch
Q14
23.96秒
12.56秒
クエリは、最長使用頻度 (LRU) キャッシュと32 GBのエグゼキュータメモリで実行されます。
クエリ (TPCH1T)
HashJoin
HashMatch
Q14
10分以上
35.73秒