In-Memory Column Index (IMCI) は、PolarDB for MySQL に列ストアとインメモリコンピューティングレイヤーを追加することで、オンラインライントランザクション処理 (OLTP) のパフォーマンスを犠牲にしたり、データを移行したりすることなく、単一のクラスターで Hybrid Transactional and Analytical Processing (HTAP) を実現します。
MySQL が列ストアを必要とする理由
MySQL は、単一行の検索、同時書き込み、低レイテンシートランザクションといったオンラインライントランザクション処理 (OLTP) 向けに設計されました。PolarDB クラスターが数百テラバイトのデータを日常的に格納するようになると、ユーザーはアプリケーションを駆動する同じデータに対してリアルタイム分析を行う必要性がますます高まっています。これに対応するため、3つのアーキテクチャアプローチが登場しました。
MySQL + 専用 AP データベース
OLTP 用の MySQL と分析用の専用オンライン分析処理 (OLAP) データベースという2つの独立したシステムをデプロイし、その間に同期パイプラインを構築します。各ワークロードに最適なエンジンを利用できますが、コストは高くなります。2つの技術スタックを維持する必要があり、同期遅延によって分析データが古くなり、リアルタイムの一貫性を確保する簡単な方法もありません。

複数レプリカによる分岐設計
TiDB (バージョン 4.0 以降) のような分散 NewSQL データベースは、各 Raft グループ内の異なるレプリカに異なるストレージフォーマットを割り当てます。1つのレプリカは列ストアである TiFlash を実行して分析クエリを処理し、他のレプリカは OLTP を処理します。インテリジェントなクエリルーティングが適切なレプリカを自動的に選択します。これは新規デプロイメントには適していますが、MySQL からの移行が必要となり、互換性の問題が発生します。
統合型ハイブリッド行列表ストア
最も先進的なアプローチは、行指向データと列指向データの両方を同じデータベースインスタンスに格納するものです。主要な商用データベースはすべてこの設計を採用しています。
Oracle は、Oracle Database 12c (2013) で Database In-Memory スイートを導入しました。これは、インメモリ列ストアとハイブリッド行列実行、およびマテリアライズされた式と JoinGroup に基づくクエリ最適化を使用しています。
SQL Server は、SQL Server 2016 SP1 で列ストアインデックスを追加し、行指向テーブル、列指向テーブル、およびハイブリッドの組み合わせをサポートしました。
IBM Db2 は、Kepler 10.5 (2013) で BLU Acceleration を出荷し、列ストア、インメモリコンピューティング、データスキッピングを組み合わせました。

これら 3つの主要な商用データベースが同じ設計に収束したのには、共通の理由があります。列ストアは、I/O 効率 (圧縮、データスキッピング、列プルーニング) と CPU 効率 (キャッシュフレンドリーなアクセスパターン) の両方を向上させます。しかし、列ストアインデックスはスパースであり、B+ ツリーインデックスのように個々の行を効率的に特定することはできません。ハイブリッド行列エンジンはこの問題を解決します。行ストアが正確な行レベルのインデックスで OLTP を処理し、列ストアがバルク分析スキャンを高速化します。DRAM の低レイテンシーが、列ストア更新におけるパフォーマンスギャップを補います。
PolarDB が新しい実行エンジンを必要とした理由
PolarDB の機能スタックは、オープンソースの MySQL を反映しています。PolarDB は OLTP を効率的に処理し、クラスターあたり最大 500 TB のデータをサポートしますが、複雑な分析クエリは依然として低速です。このボトルネックは、MySQL のアーキテクチャに起因する根本的なものです。
シリアル実行モデル:MySQL の Volcano イテレータモデルは、一度に1行ずつ処理します。各行の取得は、仮想関数ディスパッチを含む複数レイヤーの関数呼び出しをトリガーします。これにより、CPU パイプライン効率が損なわれ、SIMD 命令の使用が妨げられます。
パラレルクエリの非対応:MySQL のエグゼキュータはシングルスレッドです。MySQL 8.0 のパラレルクエリサポートは
COUNT(*)のような基本操作のみをカバーしており、利用可能な CPU コアの数に関係なく、複雑な分析 SQL はシリアルに実行されます。行ストアの I/O の無駄:分析クエリが 50 列のテーブルから 3 列しか必要としない場合でも、MySQL はディスクから 50 列すべてを読み取ります。行ストアフォーマットは、本質的に選択的な列アクセスを非効率にします。
PolarDB のパラレルクエリフレームワークは、スキャン処理を複数のスレッドに分散し、結果をメインスレッドで集約することで、CPU のボトルネックに対処します。
パラレルクエリはシングルコアの制約を打ち破り、スキャン負荷の高いワークロードのクエリ時間を短縮します。しかし、行ストアの I/O 非効率性が上限となり、並列実行だけでは克服できません。その上限を取り除くには、列ストアが必要です。
列ストアは、2つのレベルでパフォーマンスを向上させます。
I/O 効率:クエリは必要な列のみを読み取ります。列データは行ストアに比べて 10 倍以上の効率で圧縮されます。ラフインデックス (データブロックごとの MIN/MAX 統計) と組み合わせることで、無関係なデータブロックを大規模にスキップしてから展開できます。PolarDB のコンピューティングとストレージが分離されたアーキテクチャでは、ネットワーク経由で転送されるデータが少ないほど、クエリ応答が速くなります。
CPU 効率:列データは隣接して格納されるため、CPU キャッシュヒット率が向上し、L1/L2 キャッシュミスによるストールが減少します。隣接した列データは SIMD ベクトル化も可能にし、シングルコアのスループットを倍増させます。
主要な用語
| 用語 | 定義 |
|---|---|
| IMCI | インメモリ列指向インデックス。PolarDB におけるハイブリッド行列表ストアの実装です。 |
| 列指向インデックス | InnoDB のセカンダリインデックスの一種で、行フォーマットの代わりに列フォーマットで列データを格納します。 |
| 行グループ | 列指向インデックスにおけるデータ編成の単位。各行グループは 64,000 行を保持します。 |
| データパック | 1つの行グループ内の単一列のデータで、隣接して格納され、圧縮されています。 |
| ラフインデックス | 各データパックに対して事前に計算された統計情報 (MIN、MAX、SUM、NULL カウント、行数) で、無関係なデータパックを展開せずにスキップするために使用されます。 |
| インメモリ列ストア領域 | アクティブなデータパックがクエリ実行のためにキャッシュされるメモリ領域。列データはディスク上で圧縮され、ここにキャッシュされます。 |
| 並列度 (DOP) | クエリの実行に使用される並列スレッドの数。Auto DOP は、システムリソースに基づいてこれを自動的に選択します。 |
| Volcano モデル | 各演算子が Next() インターフェイスを公開し、子演算子から一度に1行 (またはバッチ) ずつデータをプルするクエリ実行モデルです。 |
| ベクトル化実行 | Volcano モデルの変種で、各 Next() 呼び出しが単一行ではなく行のバッチを返し、SIMD アクセラレーションを可能にします。 |
IMCI の仕組み
IMCI は、4つの技術革新を組み合わせています。
InnoDB の列指向インデックス:DDL ステートメントを使用して、選択した列に列指向インデックスを作成します。列指向インデックスは、行ストアよりも大幅に小さい列圧縮ストレージを使用し、デフォルトでインメモリ列ストア領域に配置されます。メモリが不足すると、共有ストレージにスピルします。
列指向実行エンジン:PolarDB のエグゼキュータは、4,096 行のバッチでデータにアクセスし、SIMD 命令を適用して単一の CPU 操作で複数の値を処理します。すべての主要な演算子 (Scan、Hash Join、Nested Loop Join、Group By) は並列実行をサポートしています。MySQL の行エグゼキュータと比較して、列エグゼキュータは分析ワークロードで数桁高いパフォーマンスを発揮します。
ハイブリッド行列表ストアオプティマイザー:クエリが送信されると、オプティマイザーは行ストアのシリアル実行、行ストアのパラレルクエリ、IMCI の 3つの実行パスのコストを評価し、最もコストの低いプランを選択します。ホワイトリストメカニズムにより、サポートされていない列タイプや演算子を使用するクエリは自動的に行ストアにフォールバックし、100% の MySQL 互換性を維持します。
AP/TP ワークロードの分離:専用の読み取り専用 (RO) ノードを、列指向インデックスを持つ分析ノードとして設定します。分析クエリは、利用可能なすべての CPU とメモリを使用して RO ノードで実行され、読み書き (RW) ノードで実行されている OLTP ワークロードには影響を与えません。

技術アーキテクチャ
ハイブリッド行-列オプティマイザー
オプティマイザーは、クエリを行ストア、パラレルクエリエンジン、または IMCI のいずれで実行するかを決定します。これには、互換性のためのホワイトリストと、パフォーマンスのためのコストベースのプラン選択という2つのメカニズムが関わっています。
MySQL との 100% の互換性の実現
すべてのクエリが IMCI で実行できるわけではありません。2つの制約がカバレッジを制限します。
列カバレッジ:どの列指向インデックスにも含まれていない列を参照するクエリは、それらの列に対して IMCI を使用できません。
演算子カバレッジ:IMCI 実行エンジンは、MySQL の行エグゼキュータの拡張ではなく、完全に書き直されたものです。一部の列タイプ、演算子、および式の形式は、まだ IMCI エンジンに実装されていません。
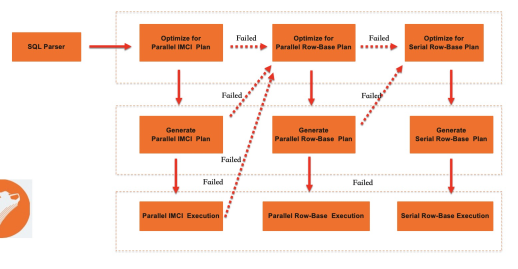
ホワイトリストメカニズムは、データ型、演算子、式、およびサポートされていないシナリオ (複数ステートメントなど) を、既知の正常なリストと照合します。クエリがホワイトリストを通過した場合、IMCI 実行の対象となります。そうでない場合は、MySQL のネイティブな行エグゼキュータにフォールバックします。このフォールバックにより 100% の互換性が保証されます。つまり、IMCI は高速化できるクエリを処理し、それ以外はすべて MySQL が処理します。
クエリプランの変換
プラン変換は、MySQL の抽象構文木 (AST) 表現を IMCI の論理プランに変換します。このプロセスは、実行計画ツリーをトラバースし、AST ノードを関係演算子として書き換え、MySQL の柔軟な型システムとの互換性を維持するために暗黙の型変換を処理します。
その後、論理プランは最適化されて物理プランになります。標準的な最適化 (Hash Join と Nested Loop Join の選択) に加えて、IMCI オプティマイザーは、IMCI エグゼキュータが直接処理できないサブクエリを、同等の結合操作に変換します。
3つの方式によるコストベースの選択
PolarDB のオプティマイザーは、3つの実行パスの中から選択します。
| 実行パス | 説明 | 互換性 | AP ワークロードでのパフォーマンス |
|---|---|---|---|
| 行ストアのシリアル実行 | MySQL のネイティブなシングルスレッドエグゼキュータ | 最高 | 最低 |
| 行ストアのパラレルクエリ | 行ストアデータに対するマルチスレッド実行 | 高 | 中程度 |
| IMCI | 列指向インデックスでのベクトル化・並列実行 | SQL カバレッジが最も狭い | 最高 |
オプティマイザーは、次のプロセスに従います。
SQL ステートメントを解析し、論理プランを生成します。プランを MySQL のネイティブオプティマイザーと IMCI のプランコンパイラの両方に渡します。
行ストアの実行コストを計算します。それがしきい値を超えた場合、クエリを IMCI にプッシュしようとします。
IMCI がクエリを実行できない場合、パラレルクエリプランの生成を試みます。
IMCI もパラレルクエリもクエリを処理できない場合、行ストアのシリアル実行にフォールバックします。
このコストモデルは、IMCI がパラレルクエリよりも、パラレルクエリがシリアル実行よりもパフォーマンスが高いことを前提としています。実際には、行ストアイデックスでのパラレルインデックス結合が、列ストアでのソートマージ結合よりもコストが低くなることがあります。オプティマイザーは、行ストアプランの方が高速である場合でも IMCI を選択することがあります。
列指向実行エンジン
IMCI 実行エンジンは、MySQL の行エグゼキュータから独立した、完全に書き直されたものです。その目標は、行ごとの仮想関数のオーバーヘッドと、実行を並列化できないという2つの根本的なボトルネックを解消することです。
ベクトル化並列エグゼキュータ
このエンジンは、修正された Volcano モデルを使用します。各 Next() 呼び出しは、一度に1行ではなく、4,096 行のバッチを返します。このバッチ単位モデルにより、2つの最適化が可能になります。
ベクトル化:列指向のバッチでデータを処理することで、SIMD 命令が適用可能になります。CPU クロックごとに1つの操作ではなく、SIMD 命令は複数の値を同時に処理します。CPU キャッシュ使用率を最大化する隣接した列ストレージと組み合わせることで、ベクトル化実行は MySQL の行エグゼキュータよりも大幅に高いシングルコアスループットを実現します。
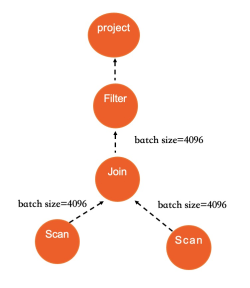
並列実行:Scan、Hash Join、Nested Loop Join、および Group By はすべて並列実行をサポートしています。オプティマイザーがテーブルスキャンが並列実行のしきい値を超えると判断した場合、利用可能な CPU、メモリ、I/O リソース、スケジュールされたタスクのキュー、クエリの複雑さ、および設定可能なパラメーターに基づいて、推奨される DOP を計算します。プラン内のすべての演算子は同じ DOP を使用します。特定のクエリの DOP は、ヒントを使用して上書きできます。
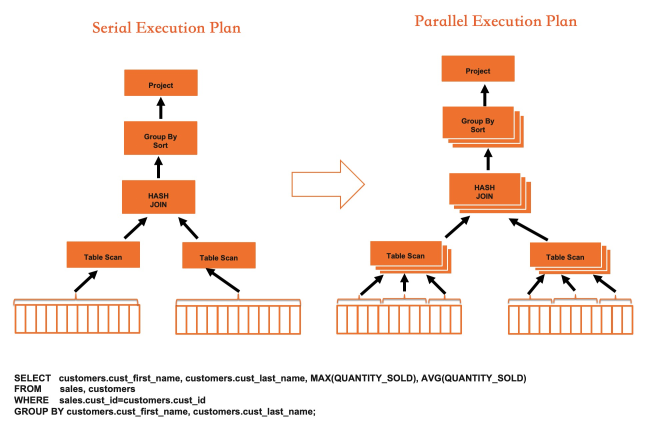
次の図は、IMCI での Hash Join の実行を示しており、並列化とベクトル化がどのように連携して機能するかを示しています。
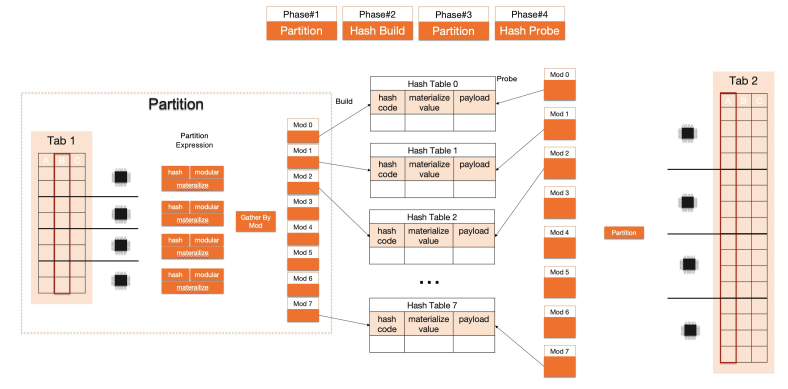
ベクトル化はシングルコアのスループットを向上させ、並列化はシングルコアの制約を打ち破ります。これらが組み合わさることで、IMCI 実行エンジンは、分析 SQL において MySQL の行エグゼキュータよりも数桁高速になります。
ベクトル化された式システム
分析 SQL は、フィルター、プロジェクション、集約、計算列など、式を多用します。MySQL の行エグゼキュータでは、各行の評価が式ツリーの再帰的なトラバースをトリガーし、行ごと、式ノードごとに1つの仮想関数呼び出しが発生します。このパターンは、CPU キャッシュと分岐予測の両方にとって非効率的です。
IMCI の式システムは、ツリーイテレータモデルを2つの最適化で置き換えます。
SIMD によるバッチ処理:列データは隣接しているため、SIMD 命令を使用して同じ式を値のバッチ全体に適用できます。PolarDB は、INT、DECIMAL、DOUBLE に対する算術演算 (+, -, ×, /, abs) など、一般的なデータ型の式カーネルを AVX512 命令を使用して書き換えます。これにより、シングルコアのスループットはスカラー実行と比較して数倍向上します。
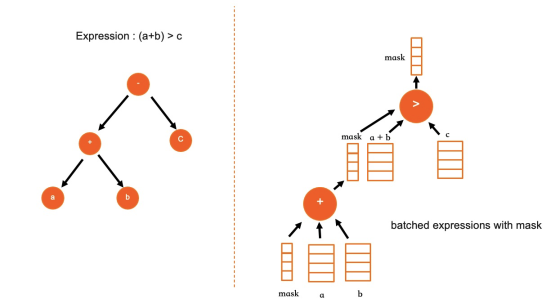
線形な式のレイアウト:クエリのコンパイル中、IMCI の式は (MySQL の構造と同様に) ツリーとして格納されます。実行前に、ツリーは後行順トラバーサルで一次元配列にフラット化されます。実行は配列を線形に反復処理するため、再帰的な関数呼び出しが完全に排除されます。この線形レイアウトは、データと計算を分離するため、並列実行も簡素化されます。
ハイブリッド行列表ストア
OLTP と OLAP は、根本的に異なるストレージ要件を持っています。OLTP は正確な行レベルのインデックスと効率的な単一行の変更を必要とします。OLAP はバルク列スキャンと高い圧縮率を必要とします。PolarDB のハイブリッド行列表ストアは、Oracle Database In-Memory や SQL Server の列ストアインデックスと同じ設計を使用し、両方のフォーマットを1つのエンジンで同時に格納します。
リアルタイムの一貫性:行指向データと列指向データは、トランザクションレベルで同期を保ちます。行ストアに書き込まれたデータは、コミット直後に分析クエリに表示されます。
コスト効率:分析の高速化が必要な列のみを列指向インデックスとして指定します。完全なデータは引き続き行ストアに保持されます。テーブル全体ではなく、実際に分析する列のみをインデックス化します。
運用の簡素化:維持するデータ同期パイプラインも、監視する一貫性のギャップもありません。
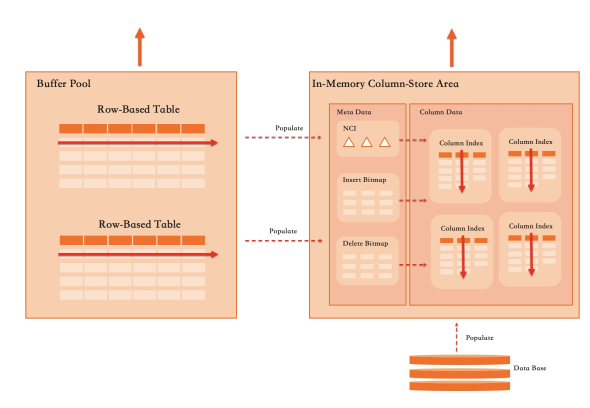
列ストアのメンテナンスは、OLTP のパフォーマンスを低下させないほど軽量でなければなりません。競合が発生した場合は、OLTP のパフォーマンスが優先されます。この制約が、以下のすべての設計決定を形作っています。
セカンダリインデックスとしての列ストア
IMCI は、列ストアを独立したストレージエンジンとしてではなく、InnoDB のセカンダリインデックスとして実装します。この設計には、いくつかの利点があります。
トランザクションの再利用:InnoDB はすでに、同じトランザクション内で、INSERT、UPDATE、DELETE 操作をすべてのセカンダリインデックスにアトミックに適用します。IMCI は、このトランザクションフレームワークを修正なしで継承します。
エンコーディングの再利用:列指向インデックスは、他の行ストアイデックスと同じデータエンコーディングを使用します。フォーマット間でデータを移動する際に、文字セットや照合順序の変換は必要ありません。
柔軟な列選択:列の任意のサブセットに列指向インデックスを作成できます。DDL を使用して列を追加または削除します。ポイントクエリにのみ使用される大きな列 (TEXT、BLOB) を行ストアに保持しながら、カーディナリティの高い分析列 (INT、FLOAT、DOUBLE) をインデックス化します。
リカバリの再利用:クラッシュリカバリは、InnoDB の REDO ログモジュールを再利用します。RO ノードまたはスタンバイノード上の列指向インデックスは REDO ログから再構築され、PolarDB の物理レプリケーションプロセスとクリーンに統合されます。
ライフサイクル管理:列指向インデックスはプライマリインデックスのライフサイクルを共有するため、スキーマ管理が簡素化されます。
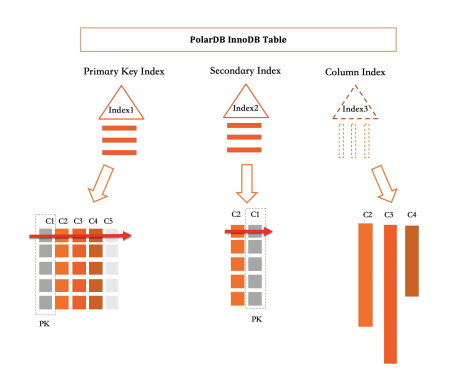
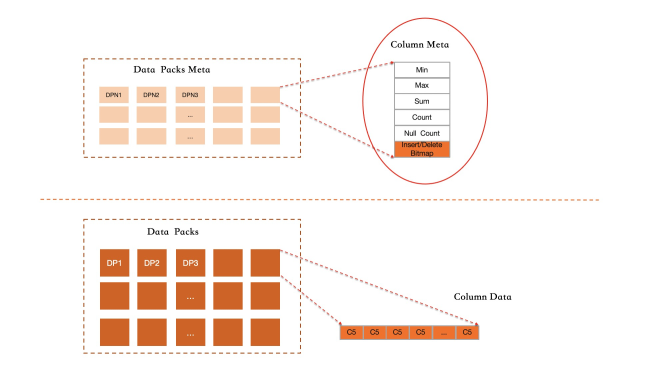
PolarDB では、プライマリインデックスとすべてのセカンダリインデックスは B+ ツリーです。列指向インデックスは論理的にはインデックスであり、インデックス化された列に対するすべての挿入、更新、削除をキャプチャしますが、物理的には、列を単一の行にまとめてエンコードするのではなく、独立して格納します。
上の図に示されているテーブルの場合:プライマリインデックスは 5つの列 (C1–C5) すべてを格納します。セカンダリインデックスは 2つの列 (C2, C1) を B+ ツリーにまとめてエンコードして格納します。列指向インデックスは 3つの列 (C2, C3, C4) を分割された独立した列フォーマットで格納します。
クエリに必要なすべての列が列指向インデックスでカバーされている場合、クエリ実行はそのインデックスのみを使用し、プライマリインデックスには決してアクセスしません。これは、MySQL がすでにサポートしているカバリングインデックス最適化を、列フォーマットデータに適用したものです。カバーされた列に対する分析クエリは、同等の行ストアクエリよりも数十倍から数百倍高速に実行されます。
列指向データの編成
列指向インデックスの各列は、順序付けられていない追記書き込みモードで格納されます。領域の再利用には、インプレース更新ではなく、削除ラベルとバックグラウンドでのコンパクションが使用されます。主要な設計ポイントは次のとおりです。
行グループ:レコードは、それぞれ 64,000 行の行グループに編成されます。行グループ内では、各列は個別のデータパックとして格納されます。
アクティブな行グループ:常に1つの行グループがアクティブであり、新しい書き込みを受け入れます。いっぱいになるとフリーズします。そのすべてのデータパックは圧縮されてディスクにフラッシュされ、各パックのラフインデックス統計が計算されます。
行 ID:新しい各行には行 ID が割り当てられます。システムはこの行 ID を使用して、すべての列データパックにわたってその行のデータを見つけます。プライマリキーから行 ID へのマッピングインデックスは、その後の削除と更新をサポートします。
削除ラベル:削除操作は、列データをインプレースで変更するのではなく、削除ビットマップ内のビットを設定します。更新操作は、古い行に削除ラベルを付け、新しい行データをアクティブな行グループに追加書き込みすることを組み合わせます。
バックグラウンドでのコンパクション:行グループ内の無効な (削除された) レコードがしきい値を超えると、バックグラウンドでのコンパクションが領域を再利用し、分析スキャンのためのストレージ密度を向上させます。
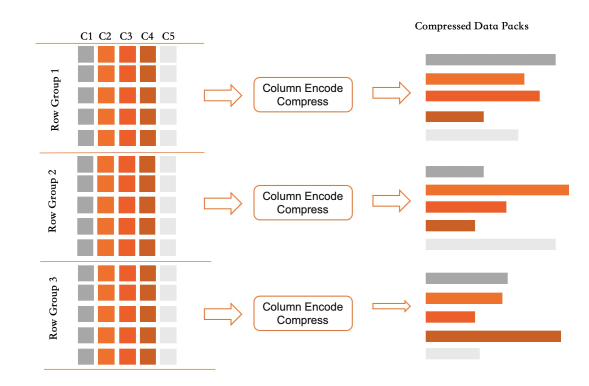
この設計により、書き込み操作は軽量に保たれます。書き込みは列データをメモリに追加し、削除はラベルを設定し、更新はラベルを設定して追加します。列ストアのメンテナンスは OLTP トランザクションに最小限のオーバーヘッドしか追加せず、トランザクションレベルの分離は全体を通して維持されます。
行から列への完全変換と増分変換
列指向インデックスは、2つのシナリオで作成されます。
完全変換 (初期インデックス構築):既存のテーブルに列指向インデックスを作成する場合、PolarDB は InnoDB プライマリインデックスを並列でスキャンし、インデックス化されたすべての列を列フォーマットに変換します。これはオンライン DDL 操作であり、実行中のトランザクションをブロックせず、その速度は利用可能な I/O スループットと CPU リソースによってのみ制限されます。
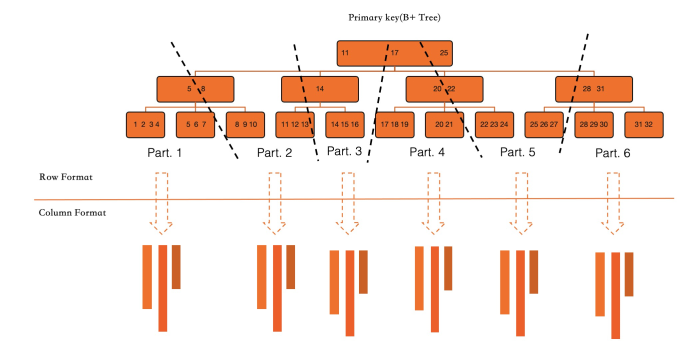
増分変換 (進行中のトランザクション):列指向インデックスが作成された後、インデックス化された列を変更するすべてのトランザクションは、行ストアと列ストアの両方を更新します。
IMCI なし:トランザクションは行をロックし、データページを変更し、コミット前にロックを解放します。
IMCI あり:トランザクションはさらに列ストア更新キャッシュを作成します。データページの変更はキャッシュに記録されます。トランザクションがロックを解放してコミットする前に、キャッシュが列ストアに適用されます。
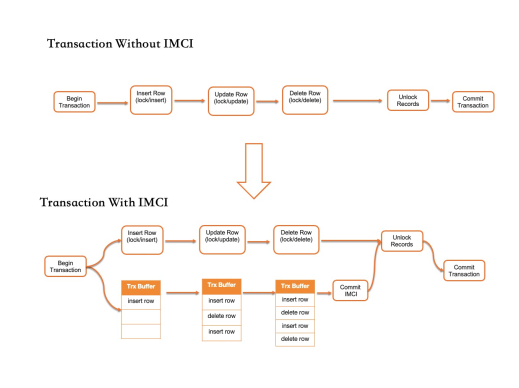
典型的な OLTP トランザクションでは、メモリデータページの変更に費やされる時間は、トランザクション全体の時間のごく一部です。列ストアの更新は、最小限のレイテンシーしか追加しません。多くの行に影響を与える大規模なトランザクションの場合、列ストアの更新はリアルタイムで適用されますが、トランザクションがコミットされるまで不可視のままであり、コミットレイテンシーを狭い範囲内に保ちます。ある程度のデータ新鮮度の遅延を許容できるワークロードの場合、列ストアの更新を非同期で適用して、OLTP パフォーマンスへの影響をさらに軽減できます。
列ストアのトランザクション分離は、行ストアを反映しています。行グループの各行は、それを書き込んだトランザクションの ID を記録します。削除ビットマップの各削除ラベルは、それを設定したトランザクション ID を記録します。AP クエリはこれらのトランザクション ID を使用して、最小限のオーバーヘッドでグローバルに一貫性のあるスナップショットを構築します。
ラフインデックスの仕組み
すべてのデータパックは順序付けられておらず、追記書き込みされるため、列指向インデックスは、順序付けられた B+ ツリーインデックスのように正確な行レベルのフィルタリングをサポートできません。代わりに、IMCI は事前計算された統計情報に基づくラフインデックスの仕組みを使用して、展開前に無関係なデータパックをスキップします。
アクティブなデータパックの書き込みが完了してフリーズすると、システムは次の統計情報を計算し、データパックのメタデータに格納します。
最小値
最大値
値の合計
NULL 値の数
総レコード数
これらの統計情報はメモリに永続化されます。削除を含むフリーズされたデータパックの場合、統計情報はバックグラウンドで更新されます。
クエリ実行時、オプティマイザーはクエリ述語とパックの統計情報に基づいて、各データパックを関連あり、関連なし、または関連の可能性ありに分類します。関連なしのパックは完全にスキップされます。COUNT や SUM などの集約操作では、関連ありのパックは事前計算された統計情報から直接回答できることが多く、展開を完全にスキップできます。
ラフインデックスは、大量のデータをスキャンするクエリ、つまり IMCI がターゲットとするまさにそのワークロードで最も効果的に機能します。少数の特定の行を特定するクエリの場合、コストベースオプティマイザーは代わりに行ストアイデックスにルーティングします。
TP/AP ワークロードのリソース分離
同じクラスターで OLTP と OLAP を実行すると、リソース競合のリスクが生じます。大規模な分析クエリが十分な CPU と I/O を消費し、OLTP のレイテンシーが急上昇する可能性があります。PolarDB は、1回書き込み・多数読み取りアーキテクチャを使用して独立した RO ノードを追加することで、これらのワークロードを分離するための3つのデプロイモードをサポートしています。
| モード | 設定 | 分離レベル | 使用するケース |
|---|---|---|---|
| モード 1 | RW ノードで IMCI を有効化 | なし — TP と AP が CPU とメモリを共有 | 軽い AP 負荷、バッチインポートされたデータに対するレポートクエリ |
| モード 2 | 専用の AP タイプ RO ノードで IMCI を有効化 | CPU とメモリは完全に分離、I/O は共有 | 中程度の AP 負荷、ほとんどの本番 HTAP デプロイメント |
| モード 3 | 独立した共有ストレージを持つ専用スタンバイノードで IMCI を有効化 | CPU、メモリ、I/O が完全に分離 | 重い AP 負荷、OLTP に対する厳格なレイテンシー SLA |
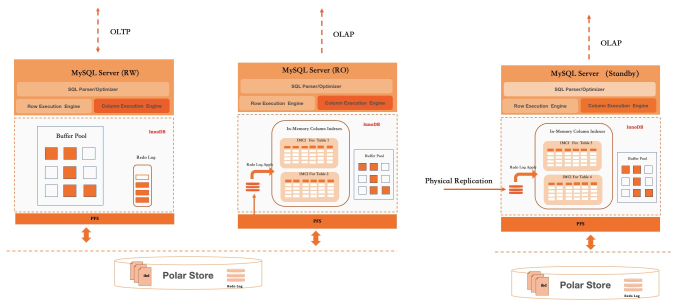
デプロイレベルの分離に加えて、Auto DOP は単一の分析クエリが消費できるリソースを制限します。DOP の計算では、現在のシステム負荷、利用可能な CPU とメモリ、スケジュールされたクエリのキューが考慮され、単一の大規模クエリが他のリクエストを枯渇させるのを防ぎます。
OLAP のパフォーマンス
詳細については、「IMCI のパフォーマンス」をご参照ください。