Agentic SOC centralizes log collection from sources such as Kafka, Amazon S3, Alibaba Cloud Object Storage Service (OSS), and third-party APIs, enabling you to build a unified log analysis and security operations center (SOC) for consistent security management in a cross-cloud environment.
Workflow

Choose a solution
Before you start, choose the most suitable import channel based on your data source, cost, and real-time requirements.
Import channel | Use cases | Features |
Kafka |
|
|
S3 (or S3-compatible object storage) |
|
|
OSS (Alibaba Cloud Object Storage Service) | For log data already stored in Alibaba Cloud OSS. | Tightly integrated with the Alibaba Cloud ecosystem for simple configuration. |
API |
|
|
Intermediate channels
Agentic SOC imports data from channels like Kafka, S3, OSS, and third-party service APIs. You must first deliver your source logs to one of these intermediate channels.
Example delivery methods:
OSS: Store log data in an Alibaba Cloud OSS bucket. For more information, see OSS Quick Start.
Use the log dump feature of Huawei Cloud Log Tank Service (LTS) to dump data to Kafka or OBS. For more information, see Import Huawei Cloud log data.
Use the log dump feature of Tencent Cloud Log Service (CLS) to dump data to Kafka or COS. For more information, see Import Tencent Cloud log data.
Use Azure Event Hub, which is compatible with the Apache Kafka protocol. This lets Agentic SOC retrieve log data from it as a Kafka service. For more information, see Import Azure log data.
Save access information: Securely store your access credentials (such as an AccessKey and password) and endpoint information (such as an endpoint and bucket name).
Grant Security Center access to third-party services
If you use third-party data channels, you must grant Security Center permission to access their resources. This allows Security Center to read the log data.
Kafka, S3, and API
Go to the Security Center console > System Settings > Feature Settings. In the upper-left corner of the page, select the region where your protected assets are located: Chinese Mainland or Outside Chinese Mainland.
On the Multi-cloud Configuration Management tab, select Multi-cloud Assets, and then click Grant Permission. From the drop-down list, select IDC. In the panel that appears, configure the following parameters:
NoteFor configuration values, such as endpoints, see the official documentation of the respective cloud vendor.
In the current version, when you configure a generic Kafka, S3-compatible object storage service (such as AWS S3, Tencent Cloud COS, or Huawei Cloud OBS), or an API, select the IDC option. This option is for UI classification only and does not affect functionality.
Kafka
Service Provider: Select Apache.
Service: Select Kafka.
Endpoint: The public endpoint of Kafka.
NoteThe Event Hub endpoint is
<YOUR-NAMESPACE>.servicebus.windows.net:9093.Username/Password: The username and password for Kafka.
NoteFor Event Hub, the default Kafka username is
$ConnectionString, and the password is the primary connection string.Communication Protocol: The
security.protocolin the Kafka configuration. Supported values include plaintext (default), sasl_plaintext, sasl_ssl, and ssl.SASL Authentication Mechanism: The
sasl.mechanismin the Kafka configuration. Supported values include plain, SCRAM-SHA-256, and SCRAM-SHA-512.
S3
Service Provider: Select AWS-S3.
Service: Select S3.
Endpoint: The endpoint of the object storage service.
Access Key Id/Secret Access Key: The access key pair for accessing S3.
API
Service Provider: Select a vendor, such as Salesforce, Lark, or Akamai.
Service: Select an integrated API for the chosen vendor.
Salesforce API: Salesforce REST API.
Lark API: Lark REST API.
Akamai API: Akamai REST API.
Endpoint: The endpoint of the vendor's API service.
To find the Endpoint for Salesforce: Log on to Salesforce, click the Setup menu, and search for
My Domainin the Quick Find box. In the results, clickMy Domainto view its details. The Current My Domain URL is the Endpoint.The Endpoint for Lark is https://open.larksuite.com.
To find the Endpoint for Akamai, log on to the Akamai console. Search for and open
Identity & Access, then find the API client user and view its details. The Host value is the Endpoint.
Access Key Id/Secret Access Key: The access key pair used to call the API.
To find the Access Key Id/Secret Access Key for Salesforce: Log on to Salesforce, click the Setup menu, and search for
App Managerin the Quick Find box. Find the connected app for your API in the app list. Click View from the app's drop-down menu. The Consumer Key corresponds to the Access Key Id, and the Consumer Secret corresponds to the Secret Access Key.To find the Access Key Id/Secret Access Key for Lark: Log on to the Lark Developer Console and open your application. In the left-side navigation pane, click Credentials & Basic Info. The App ID corresponds to the Access Key Id, and the App Secret corresponds to the Secret Access Key. Note that the App ID must have API call permissions. You may need to contact your Lark account manager to enable them.
To find the Access Key Id/Secret Access Key for Akamai: Log on to the Akamai console, search for and open
Identity & Access, find the API client user, and view its details. The Client Token corresponds to the Access Key Id, and the Client Secret corresponds to the Secret Access Key. Important: The Client Secret is displayed only when you create the credential. Make sure to record it immediately.
Access Token: The access token for calling the API. This parameter is required only if you select Akamai as the vendor.
To find the Access Token for Akamai, log on to the Akamai console. Search for and open
Identity & Access, then find the API client user and view its details to locate the Access Token.
Device Name: A unique name to identify the device.
Configure synchronization policy
AK Service Status Check: The interval at which Security Center automatically checks the validity of the access key pair. Select "Disable" to turn off the check.
OSS
Go to the Cloud Resource Access Authorization page and click Authorize to grant the system role permission to access OSS resources.
If you are a Resource Access Management (RAM) user, you must also grant the following permissions. For more information, see Create a custom policy and Manage RAM user permissions.
{ "Statement": [ { "Effect": "Allow", "Action": ["ram:PassRole", "ram:GetRole"], "Resource": "acs:ram:*:*:role/aliyunlogimportossrole" }, { "Effect": "Allow", "Action": "oss:GetBucketWebsite", "Resource": "*" }, { "Effect": "Allow", "Action": "oss:ListBuckets", "Resource": "*" } ], "Version": "1" }
Create a data import task
Create a data source
Create a dedicated Agentic SOC data source for your logs. If you already have one, skip this step.
Go to the Security Center console > Agentic SOC > Manage > Integration Settings page. In the upper-left corner, select the region of your protected assets: Chinese Mainland or Outside Chinese Mainland.
On the Data Source tab, create a data source to receive logs. For more information, see Create a data source for logs that are not ingested into Simple Log Service (SLS).
Source Data Source Type: Select Agentic SOC Dedicated Collection Channel (Recommended) or User Log Service.
Add Instances: We recommend creating a new Logstore to isolate data.
On the Data Import tab, click Add Data. In the panel that opens, configure the following parameters based on the Data Source Type:
NoteFor specific parameter values, refer to the official documentation from the relevant cloud provider.
Kafka
Endpoint: Select the public Kafka address you specified when authorizing Security Center to access third-party services.
topic: Select the Kafka topic that contains the logs.
NoteIf you use Azure Event Hubs, the Event Hub name corresponds to the Kafka topic.
Value Type: The storage format of the logs. The following table shows common mappings.
Third-party storage format
Value type
JSON format
json
Raw log format
text
S3
Endpoint: The endpoint of the S3 bucket.
S3 bucket: The name of the S3 bucket.
File Path Prefix Filter: Filters S3 files by file path prefix to accurately locate the files to import. For example, if all files to be imported are in the
csv/directory, you can specify the prefix ascsv/.WarningWe strongly recommend configuring this parameter. If not configured, the system traverses the entire S3 bucket. A full traversal of a bucket with many files can significantly degrade import performance.
File Path Regex Filter: Filters files by using a regular expression to accurately locate the files to import. By default, this parameter is empty, which indicates that no filtering is performed. For example, if an S3 file is named
testdata/csv/bill.csv, you can set the regular expression to(testdata/csv/)(.*).NoteWe recommend that you configure this setting together with the File Path Prefix Filter to improve efficiency. This configuration and the File Path Prefix Filter are combined by a logical AND.
For information about how to debug regular expressions, see How to debug a regular expression.
Data Format: The format used to parse the file. The following formats are supported:
CSV: A text file with fields separated by a delimiter. You can specify that the first row of the file is used as field names, or you can specify the field names manually. Each row after the header is parsed as the values of a single log entry.
JSON: Reads the S3 file line by line and parses each line as a JSON object. The fields of the JSON object correspond to the log fields.
Text: Parses each line in an S3 file as a single log entry.
Multi-line Text: Parses logs that span multiple lines. You can use a regular expression to match the first or last line of a log entry.
If you set the data format to CSV or Multi-line Text, you must configure additional parameters as described in the following sections.
CSV
Parameter
Description
Separator
The delimiter for fields in a log. The default value is a comma (
,).quote character
The character used to quote strings in the CSV file.
Escape Character
The character used to escape special characters in a log. The default value is a backslash (
\).Max Line Span
The maximum number of lines that a single log entry can span. The default value is 1.
First Row as Header
If you turn on this switch, the first row of the CSV file is used as the field names. For example, the first row of the following CSV data is extracted as the log field names.
remote_addr,remote_user,time_local,request_time,request_length xxx5,-,11/Dec/2020:15:31:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:32:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:34:10,0,000,133,3650,404,GETSkip rows
The number of lines to skip at the beginning of the file. For example, if you set this parameter to 1, log collection starts from the second line of the CSV file.
Multi-line Text
Parameter
Description
Regex Match Position
The position in a log entry where the regular expression is matched. Valid values:
Prefix Regex: Uses a regular expression to match the first line of a log entry. Subsequent lines that do not match the expression are appended to the log entry until another line matches the expression or the maximum number of lines is reached.
Suffix Regex: Uses a regular expression to match the last line of a log entry. Lines are aggregated into a single log entry until a line matches this expression. Aggregation stops if the maximum line limit is reached before a match is found.
Regex
Specify the regular expression based on the log content. For information about how to debug regular expressions, see How to debug a regular expression.
Max Lines
The maximum number of lines for a single log entry.
Encoding Format: The encoding format of the S3 files to import. GBK and UTF-8 are supported.
Compression format: The compression format of the S3 data. The system automatically detects the format.
Modified Time: Imports files modified within the 30 minutes prior to the task's start time, and continues to import newly modified files.
New File Check Cycle: The interval at which the task scans for and imports new files.
OSS
ImportantYou can import OSS files up to 5 GB in size. For compressed files, this limit applies to the size of the compressed file itself.
OSS Region: The region where the OSS data is stored.
NoteCross-region access incurs public bandwidth fees. These fees are charged by the OSS service. For more information, see Billing overview.
Bucket: The name of the source OSS bucket.
File Path Prefix Filter: Filters OSS files by file path prefix to accurately locate the files to import. For example, if all files to be imported are in the
csv/directory, you can specify the prefix ascsv/.WarningWe recommend configuring this parameter. If not configured, the system traverses the entire OSS bucket. This can degrade import performance and incur unnecessary costs if the bucket contains a large number of files.
File Path Regex Filter: Filters files by using a regular expression to accurately locate the files to import. By default, this parameter is empty, which indicates that no filtering is performed. For example, if an OSS file is named
testdata/csv/bill.csv, you can set the regular expression to(testdata/csv/)(.*).NoteWe recommend that you configure this setting together with the File Path Prefix Filter to improve efficiency. This configuration and the File Path Prefix Filter are combined by using a logical AND.
For information about how to debug regular expressions, see How to debug a regular expression.
Modified Time: Imports files modified within the 30 minutes prior to the task's start time, and continues to import newly modified files.
Data Format: The format used to parse the file. The following formats are supported:
CSV: A text file with fields separated by a delimiter. You can specify that the first row of the file is used as field names, or you can specify the field names manually. Each row other than the header is parsed as the values of a log entry.
Single-Line JSON: Reads the OSS file line by line and parses each line as a JSON object. The fields in the JSON object correspond to the fields in the log.
Text: Parses each line in an OSS file as a single log entry.
Multi-line Text: Parses logs that span multiple lines. You can specify a regular expression to match the first or last line of a log entry.
ORC: The ORC file format. No additional configuration is needed as the system automatically parses these files into logs.
Parquet: The Parquet file format. No additional configuration is needed as the system automatically parses these files into logs.
OSS Access Log: For Alibaba Cloud OSS access logs. For format details, see Log saving.
Download Alibaba Cloud CDN logs: For Alibaba Cloud CDN download logs. For format details, see Quick start.
If you set the data format to CSV or Multi-line Text, you must configure additional parameters as described in the following sections.
CSV
Parameter
Description
Separator
The delimiter for fields in a log. The default value is a comma (
,).quote character
The character used to quote strings in the CSV file.
Escape Character
The character used to escape special characters in a log. The default value is a backslash (
\).Max Line Span
The maximum number of lines that a single log entry can span. The default value is 1.
First Row as Header
If you turn on this switch, the first row of the CSV file is used as the field names. For example, the first row of the following CSV data is extracted as the log field names.
remote_addr,remote_user,time_local,request_time,request_length xxx5,-,11/Dec/2020:15:31:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:32:06,0,000,133,3650,404,GET xxx5,-,11/Dec/2020:15:34:10,0,000,133,3650,404,GETSkip rows
The number of lines to skip at the beginning of the file. For example, if you set this parameter to 1, log collection starts from the second line of the CSV file.
Multi-line Text
Parameter
Description
Regex Match Position
The position in a log entry where the regular expression is matched. Valid values:
Prefix Regex: Uses a regular expression to match the first line of a log entry. Subsequent lines that do not match the expression are appended to the log entry until another line matches the expression or the maximum number of lines is reached.
Suffix Regex: Uses a regular expression to match the last line of a log entry. Lines are aggregated into a single log entry until a line matches this expression. Aggregation stops if the maximum line limit is reached before a match is found.
Regex
Specify the regular expression based on the log content. For information about how to debug regular expressions, see How to debug a regular expression.
Max Lines
The maximum number of lines for a single log entry.
Encoding Format: The encoding format of the OSS files to import. GBK and UTF-8 are supported.
Compression format: The compression format of the OSS data. The system automatically detects the format.
New File Check Cycle: The interval at which the task scans for and imports new files.
API
Service: Select a product's REST API.
Client ID: Select the client identifier for the product. If the required identifier is not available in the drop-down list, click the Go to configure multi-cloud asset authorization link to add or manage identifiers.
Collection Playbook Template: Select the collection playbook template for the product.
Playbook Name: Enter a name for the playbook.
Playbook Parameter Settings: Enter the playbook parameters. These settings are required only for some playbooks.
Import Frequency: The interval at which the task queries the API to pull new logs.
Configure the target data source
Data Source Name: Select the data source created in Step 1.
Target Logstore: The Logstore configured in Step 1.
Click OK. Security Center will then automatically begin ingesting logs from the specified data source.
Analyze imported data
After data is ingested, you must configure parsing and detection rules for Security Center to analyze the logs.
Create a new integration policy
Create a new integration policy and configure the following parameters. For more information, see product integration.
Data Source: Select the target data source configured in the data import task.
Standardized Rule: Agentic SOC provides built-in standardization rules for some cloud products.
Standardization Method: When standardizing ingested logs into alert logs, only the Real-time Consumption method is supported.
Configure threat detection rules
Based on your security requirements, enable or create log detection rules in rule management to analyze logs, generate alerts, and create security events. For more information, see Detection rules.
Billing and costs
Agentic SOC and SLS billing: The party responsible for the costs depends on the selected data storage method.
NoteFor more information about Agentic SOC billing, see Agentic SOC subscription and Agentic SOC pay-as-you-go.
For more information about Simple Log Service (SLS) billing, see Billing overview.
Data source type
Agentic SOC billable items
SLS billable items
Notes
Agentic SOC Dedicated Collection Channel
Log ingestion fees.
Log storage and write fees.
NoteThese items consume Log Ingestion Traffic.
Fees other than log storage and writes, such as outbound data transfer.
Agentic SOC creates and manages SLS resources. Therefore, Agentic SOC bills you for Logstore storage and write fees.
User Log Service
Log ingestion fees, which consume Log Ingestion Traffic.
All log-related fees, including log storage and writes, outbound data transfer, and more.
Simple Log Service (SLS) manages all log resources. Therefore, SLS bills you for all log-related fees.
OSS costs: When you import data from OSS, OSS charges you for outbound data transfer and requests. For pricing details, see OSS Pricing.
Cost calculation formula
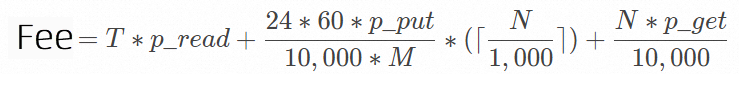
Parameter
Description
NThe number of files imported per day.
TThe total volume of data imported per day, in GB.
p_readThe traffic fee per GB of data.
If you import data from an OSS bucket in the same region as your SLS project, it generates free internal network traffic.
If you import data from an OSS bucket in a different region, outbound internet traffic is generated.
p_putThe fee per 10,000 PUT requests.
Simple Log Service calls the ListObjects API operation to obtain the list of files in the destination bucket. This operation is billed as a PUT request by OSS. Each API call can return a maximum of 1,000 objects. Therefore, if you need to import 1,000,000 new files, you must make 1,000,000/1,000 = 1,000 requests.
p_getThe fee per 10,000 GET requests.
MThe new file check interval, in minutes.
You can set the New File Check Cycle parameter when you create a data import configuration.
Billing examples
Third-party costs: