The PostgreSQL data source provides a bidirectional channel for reading data from and writing data to PostgreSQL. You can configure data synchronization tasks using wizard mode or script mode. This topic describes how DataWorks supports data synchronization for PostgreSQL.
Supported versions
You can configure data sources for PostgreSQL versions 10, 11, 12, 13, 14, 15, and 16.4. To check the version of your PostgreSQL database, run the following statement.
SHOW SERVER_VERSION;Limitations
Offline read and write
You can read data from views.
The PostgreSQL data source supports password-based authentication, including the SCRAM-SHA-256 method. If you change the password or authentication method in the PostgreSQL database, you must update the data source configuration, test the connection again, and manually run related tasks to verify the changes.
PostgreSQL
If a table or column name in PostgreSQL starts with a digit, is case-sensitive, or includes a hyphen (-), you must enclose the name in double quotation marks (""). Otherwise, the PostgreSQL plugin cannot read or write data. In the PostgreSQL Reader and Writer plugins, double quotation marks ("") are a JSON keyword. Therefore, you must escape the double quotation marks with a backslash (\). For example, if a table is named
123Test, the escaped name is\"123Test\".NoteBoth the opening and closing double quotation marks must be escaped with a backslash (\).
Wizard mode does not support escaping. You must switch to script mode to escape characters.
The following code shows an example of how to escape characters in script mode.
"parameter": { "datasource": "abc", "column": [ "id", "\"123Test\"", //Add escape characters ], "where": "", "splitPk": "id", "table": "public.wpw_test" },Updating data in a PostgreSQL data source based on a unique index is not supported. To update data, you must first write the data to a temporary table and then use the
RENAMEoperation.
Real-time read
The following limits apply to real-time sync tasks in Data Integration:
Data Integration provides special support for
ADD COLUMN:Constraint: You cannot combine an
ADD COLUMNoperation with otherADD COLUMN,DROP COLUMN, or other DDL statements in a single transaction.ImportantIf you use
ADD COLUMNwith other operations, such asDROP COLUMN、RENAME COLUMNor otherALTER COLUMNoperations, the data synchronization task may fail to run properly.Limitation: DDL operations other than
ADD COLUMNcannot be recognized.
ALTER TABLE/CREATE TABLEis not supported.Replication of TEMPORARY tables, UNLOGGED tables, and Hyper tables is not supported. PostgreSQL does not provide a mechanism to subscribe to WAL log parsing for these types of tables.
Replication of Sequences (
serial/bigserial/identity) is not supported.The TRUNCATE operation is not supported.
Large object replication (Bytea) is not supported.
Replication of views, materialized views, and foreign tables is not supported.
When PostgreSQL is used as the source for single-table real-time or full-database real-time synchronization, only tables for which the account has owner permissions can be synchronized.
Supported column types
Most PostgreSQL data types are supported. However, some types are not supported for batch synchronization read and write operations. Check your data types before you proceed.
The following table lists the type conversion mappings for PostgreSQL.
Type category | PostgreSQL data type |
Integer | BIGINT, BIGSERIAL, INTEGER, SMALLINT, and SERIAL |
Floating point | DOUBLE PRECISION, MONEY, NUMERIC, and REAL |
String | VARCHAR, CHAR, TEXT, BIT, and INET |
Date and time | DATE, TIME, and TIMESTAMP |
Boolean | BOOL |
Binary | BYTEA |
Column types other than those listed above are not supported.
In PostgreSQL Reader, the MONEY, INET, and BIT types must be converted by using syntax similar to
a_inet::varchar.
Preparations before data synchronization
Before you synchronize data in DataWorks, you must prepare the PostgreSQL environment as described in this section to ensure that PostgreSQL data synchronization tasks can be configured and run properly in DataWorks. The following sections describe the preparation steps for PostgreSQL synchronization.
Preparation 1: Create an account and configure permissions
You must plan a database login account for subsequent operations. This account must have the REPLICATION、 LOGIN permissions on the database.
Real-time synchronization supports only the logical replication mechanism. Logical replication uses a publish-and-subscribe model in which one or more subscribers subscribe to one or more publications on a publisher node. Subscribers pull data from the publications to which they subscribe.
Logical replication of a table typically starts by taking a snapshot of the data on the publisher database and copying it to the subscriber. After the snapshot is complete, changes on the publisher are sent to the subscriber in real time.
Create an account.
For more information, see Create an account.
Configure permissions.
Check whether the account has the
replicationpermission.select userepl from pg_user where usename='xxx'The expected result is True. If the result is False, the account does not have the permission. You can run the following statement to grant the permission.
ALTER USER <user> REPLICATION;
Preparation 2: Check whether a standby database is supported
SELECT pg_is_in_recovery()
Only the primary database is supported. The expected result is False. If the result is True, the database is a standby database. Real-time synchronization does not support standby databases. You must change the data source configuration to point to the primary database. For more information, see Configure the data source.
Preparation 3: Check whether wal_level is set to logical
show wal_level
wal_level specifies the level of wal_log. The expected result is logical. Otherwise, the logical replication mechanism is not supported.
Preparation 4: Check whether a wal_sender process can be started
-- Query max_wal_senders
show max_wal_senders;
-- Query the number of pg_stat_replication entries
select count(*) from pg_stat_replicationIf max_wal_senders is not empty and its value is greater than the number of max_wal_senders entries in pg_stat_replication, idle wal_sender processes are available. The PostgreSQL database starts wal_sender processes for the data synchronization program to send logs to subscribers.
For each table that needs to be synchronized, you must manually run the ALTER TABLE [tableName] REPLICA IDENTITY FULL statement to grant the required permissions. Otherwise, the real-time synchronization task will fail.
After a PostgreSQL real-time synchronization task is started, slots and publications are automatically created in the database. The slot name format is di_slot_ + Solution ID , and the publication name format is di_pub_ + Solution ID. After the real-time synchronization task is stopped or undeployed, you must manually delete the slots and publications. Otherwise, PostgreSQL WAL files may continuously grow.
Add a data source
Before you develop a synchronization task in DataWorks, you must add the required data source to DataWorks by following the instructions in Data source management. You can view parameter descriptions in the DataWorks console to understand the meanings of the parameters when you add a data source.
If SSL authentication is enabled for your PostgreSQL database, you must also enable SSL authentication when you add a PostgreSQL data source in DataWorks. For more information, see Add SSL authentication for a PostgreSQL data source.
Data synchronization task development: PostgreSQL synchronization process guide
For information about the entry point for and the procedure of configuring a synchronization task, see the following configuration guides.
Single-table batch synchronization task configuration guide
For more information about the procedure, see Configure a batch synchronization task in wizard mode and Configure a batch synchronization task in script mode.
For all parameters and script demos for script mode configuration, see Appendix 1: Script demo and parameter description below.
Full-database batch read and full-database real-time read synchronization task configuration guide
For more information about the procedure, see Configure a full-database batch synchronization task and Configure a full-database real-time synchronization task.
FAQ
Primary-standby synchronization data recovery issue
The primary-standby synchronization issue refers to a scenario in which PostgreSQL uses primary-standby disaster recovery, and the standby database continuously recovers data from the primary database. Because there is a time difference between primary and standby data synchronization, especially in certain situations such as network latency, the data recovered on the standby database may differ significantly from the primary database. The data synchronized from the standby database is not a complete snapshot of the current time.
Consistency constraint
PostgreSQL is an RDBMS system that provides a strongly consistent data query interface. For example, when a synchronization task is running and other writers are writing data to the database, PostgreSQL Reader does not retrieve the newly written data because of the snapshot feature of the database.
The above describes the data synchronization consistency characteristics of PostgreSQL Reader in single-thread mode. PostgreSQL Reader can perform concurrent data extraction based on your configuration, so strict data consistency cannot be guaranteed.
After PostgreSQL Reader splits data based on splitPk, multiple concurrent tasks are started sequentially to complete data synchronization. These concurrent tasks do not belong to the same read transaction, and there are time intervals between them. Therefore, the data is not a complete and consistent data snapshot.
Consistent snapshots for multi-threaded operations are technically infeasible. This can only be addressed from an engineering perspective. The following solutions involve trade-offs. You can choose based on your situation.
Use single-threaded synchronization, which means no data sharding. The downside is slower speed, but it ensures consistency.
Stop other data writers to ensure the current data is static, for example, by locking tables or stopping standby database synchronization. The downside is potential impact on online business.
Database encoding issue
PostgreSQL supports only EUC_CN and UTF-8 simplified Chinese encodings on the server side. PostgreSQL Reader uses JDBC for data extraction at the underlying level. JDBC natively supports various encodings and performs encoding conversion at the underlying level. Therefore, PostgreSQL Reader does not require you to specify an encoding and can automatically detect and convert encodings.
If the underlying write encoding of PostgreSQL is inconsistent with its configured encoding, PostgreSQL Reader cannot detect this issue and cannot provide a solution. The exported data may contain garbled characters.
Incremental data synchronization methods
PostgreSQL Reader uses JDBC SELECT statements for data extraction. Therefore, you can use
SELECT…WHERE…to extract incremental data. The methods are as follows:When an online application writes data to the database, it populates the modify field with the modification timestamp, including inserts, updates, and deletes (logical deletes). For such applications, PostgreSQL Reader only needs to append the timestamp from the previous synchronization phase in the where condition.
For newly added sequential data, PostgreSQL Reader only needs to append the maximum auto-increment ID from the previous phase in the where condition.
If there is no column to distinguish between new and modified data at the business level, PostgreSQL Reader cannot perform incremental data synchronization and can only synchronize full data.
SQL security
PostgreSQL Reader provides the querySql statement for you to implement custom SELECT extraction statements. PostgreSQL Reader does not perform any security validation on the querySql statement.
If you cannot select the desired table name when configuring a synchronization task, troubleshoot the issue as follows:
Check whether the data source is connected.
Check whether the PostgreSQL account used for the data source has the required table permissions.
If the database contains a large number of tables, we recommend that you directly search by typing the table name.
PostgreSQL does not support sharded table synchronization. If you have a large number of PostgreSQL tables to synchronize, we recommend that you use a full-database synchronization task. For more information, see Full-database synchronization task configuration guide.
Appendix 1: Script demo and parameter description
Configure a batch synchronization task by using the code editor
If you want to configure a batch synchronization task by using the code editor, you must configure the related parameters in the script based on the unified script format requirements. For more information, see Script mode configuration. The following information describes the parameters that you must configure for data sources when you configure a batch synchronization task by using the code editor.
Reader script demo
To configure a job that extracts data from a PostgreSQL database, use script mode. For more information, see Configure a batch synchronization task in script mode.
{
"type":"job",
"version":"2.0",// The version number.
"steps":[
{
"stepType":"postgresql",// The plugin name.
"parameter":{
"datasource":"",// The data source.
"column":[// The columns.
"col1",
"col2"
],
"where":"",// The filter condition.
"splitPk":"",// The column used as the split key for data sharding. Data synchronization starts concurrent tasks for data synchronization.
"table":""// The table name.
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"stream",
"parameter":{},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"// The error count.
},
"speed":{
"throttle":true, // A value of false for throttle indicates that throttling is disabled and the mbps parameter does not take effect. A value of true indicates that throttling is enabled.
"concurrent":1, // The concurrency of the job.
"mbps":"12"// The throttling rate. 1 mbps = 1 MB/s.
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}Reader script parameters
Parameter | Description | Required | Default value |
datasource | The data source name. Script mode allows you to add data sources. The value of this parameter must be the same as the name of the data source you added. | Yes | N/A |
table | The name of the table from which you want to synchronize data. | Yes | N/A |
column | The set of column names to synchronize in the configured table, described in a JSON array. By default, all columns are used, for example, [*].
| Yes | N/A |
splitFactor | The split factor. You can configure the number of data splits. If multiple concurrent threads are configured, the data is split into concurrency × splitFactor parts. For example, if concurrency is 5 and splitFactor is 5, the data is split into 5 × 5 = 25 parts and executed across 5 concurrent threads. Note Recommended value range: 1 to 100. Excessively large values may cause out-of-memory (OOM) errors. | No | 5 |
splitPk | When PostgreSQL Reader extracts data, if you specify splitPk, the column represented by splitPk is used for data sharding. Data synchronization starts concurrent tasks to improve synchronization performance:
| No | N/A |
where | The filter condition. PostgreSQL Reader concatenates SQL based on the specified column, table, and where conditions, and extracts data based on the SQL. For example, during testing, you can use the where condition to specify a business scenario. Typically, data from the current day is synchronized. You can specify the where condition as
| No | N/A |
querySql (advanced mode, not available in wizard mode) | In some business scenarios, the where configuration is insufficient to describe the filter conditions. You can use this parameter to define custom filter SQL. When this parameter is configured, the data synchronization system ignores the tables, columns, and splitPk configurations, and directly uses the content of this parameter to filter data. For example, to synchronize data after a multi-table JOIN, use | No | N/A |
fetchSize | This parameter specifies the number of records fetched per batch between the plugin and the database server. This value determines the number of network interactions between Data Integration and the server, and can significantly improve data extraction performance. Note A fetchSize value that is too large (>2048) may cause the data synchronization process to run out of memory (OOM). | No | 512 |
Writer script demo
The following is a script configuration example. For more information, see the parameter descriptions above.
{
"type":"job",
"version":"2.0",// The version number.
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"postgresql",// The plugin name.
"parameter":{
"datasource":"",// The data source.
"column":[// The columns.
"col1",
"col2"
],
"table":"",// The table name.
"preSql":[],// The SQL statements executed before the data synchronization task.
"postSql":[],// The SQL statements executed after the data synchronization task.
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"// The error count.
},
"speed":{
"throttle":true,// A value of false for throttle indicates that throttling is disabled and the mbps parameter does not take effect. A value of true indicates that throttling is enabled.
"concurrent":1, // The concurrency of the job.
"mbps":"12"// The throttling rate. 1 mbps = 1 MB/s.
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}Writer script parameters
Parameter | Description | Required | Default value |
datasource | The data source name. Script mode allows you to add data sources. The value of this parameter must be the same as the name of the data source you added. | Yes | N/A |
table | The name of the table to which you want to synchronize data. | Yes | N/A |
writeMode | The write mode. Currently, insert and copy modes are supported:
| No | insert |
column | The columns to which data is written in the destination table, separated by commas. For example, | Yes | N/A |
preSql | The SQL statements to execute before the data synchronization task runs. Currently, wizard mode allows only one SQL statement, while script mode supports multiple SQL statements, for example, to clear old data. | No | N/A |
postSql | The SQL statements to execute after the data synchronization task runs. Currently, wizard mode allows only one SQL statement, while script mode supports multiple SQL statements, for example, to add a timestamp. | No | N/A |
batchSize | The number of records submitted per batch. This value can significantly reduce the number of network interactions between Data Integration and PostgreSQL, and improve overall throughput. However, setting this value too large may cause the Data Integration process to run out of memory (OOM). | No | 1,024 |
pgType | The conversion configuration for PostgreSQL-specific types. Supported types include bigint[], double[], text[], Jsonb, and JSON. The following is a configuration example. | No | N/A |
Appendix 2: Add SSL authentication for a PostgreSQL data source
PostgreSQL SSL authentication file description
When you create or modify a PostgreSQL data source connection in DataWorks, you can configure SSL authentication. The SSL authentication configuration parameters are described below.
PostgreSQL database | DataWorks PostgreSQL data source configuration | |||
SSL link encryption | Client encryption | ACL configuration | Configuration item | Description |
Enabled | Disabled | N/A | Truststore certificate file | Optional. The client uses this certificate to authenticate the server.
|
Enabled | ACL configuration set to prefer |
| Both the Keystore certificate file and Private key file are optional. When ACL configuration is set to prefer, the server does not enforce client certificate verification.
| |
ACL configuration set to verify-ca |
| |||
When the ACL configuration is set to prefer, client content is not enforced for verification.
If no files are configured for SSL authentication, a regular connection is used.
If authentication files are added for SSL authentication, refer to the corresponding descriptions in the table above.
When the ACL configuration is set to verify-ca, configure the Keystore certificate file, Private key file, and Private key password to create the data source.
Obtain PostgreSQL SSL authentication files
This section uses an ApsaraDB RDS for PostgreSQL instance as an example to generate SSL authentication certificates.
Obtain the Truststore certificate file.
For more information about obtaining the Truststore certificate file, see Configure an SSL-encrypted connection.
Go to the RDS instance list, click the RDS instance in the corresponding region, and then click the target instance ID to go to the instance details page.
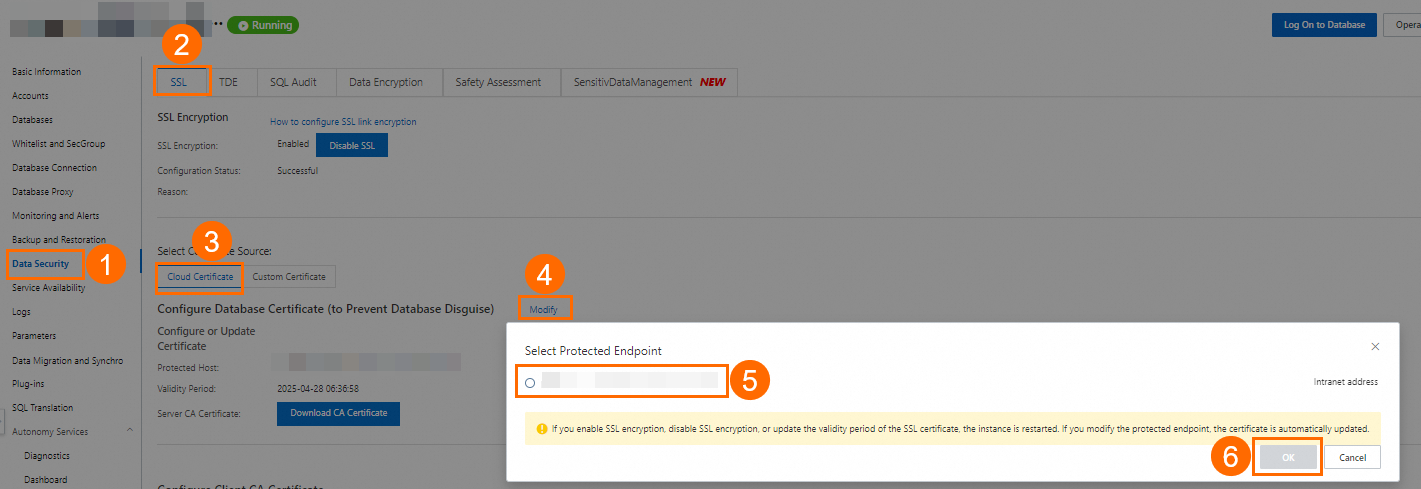
Select the connection string that you want to protect. The following figure shows the procedure:
 Note
NoteIf the public endpoint is enabled, both the internal and public endpoints are displayed. A cloud certificate can protect only one endpoint. Because the internal endpoint is relatively more secure, we recommend that you protect the public endpoint. For more information about how to view internal and public endpoints, see View internal and public endpoints.
If you need to protect both the internal and public endpoints, see Configure a custom certificate.
After you configure the cloud certificate, the Running Status of the instance changes to Modifying SSL. This status lasts about three minutes. Wait until the running status changes to Running before you proceed.
c. Click Download CA Certificate to obtain the Truststore certificate file.
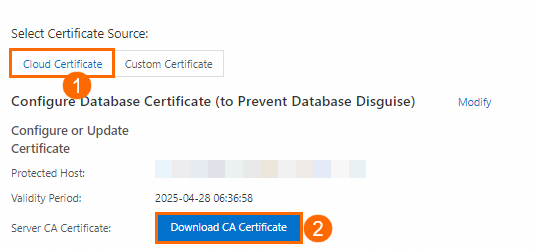
The downloaded CA certificate package contains three files. When you configure the PostgreSQL data source in DataWorks, upload the file with the
.pemextension or the file with the.p7bextension to the Truststore certificate file configuration item.Obtain and configure the Keystore certificate file, Private key file, and Private key password.
Prerequisites: You have completed configuring an SSL-encrypted connection or configuring a custom certificate, and you have the OpenSSL tool.
NoteIf you use a Linux system, OpenSSL is pre-installed. If you use a Windows system, download and install the OpenSSL software package.
For more information about obtaining and configuring the Keystore certificate file, Private key file, and Private key password, see Configure a client certificate.
Use the OpenSSL tool on a Linux system or install the OpenSSL software on a Windows system to generate a self-signed certificate (ca1.crt) and its private key (ca1.key).
openssl req -new -x509 -days 3650 -nodes -out ca1.crt -keyout ca1.key -subj "/CN=root-ca1"Generate a client certificate signing request file (client.csr) and a client certificate private key (client.key).
openssl req -new -nodes -text -out client.csr -keyout client.key -subj "/CN=<client_username>"In this command, the CN value after the
-subjparameter must be set to the username used by the client to access the database.Generate the client certificate (client.crt).
openssl x509 -req -in client.csr -text -days 365 -CA ca1.crt -CAkey ca1.key -CAcreateserial -out client.crtIf your RDS PostgreSQL server requires client CA certificate verification, open the generated client self-signed certificate ca1.crt file, copy the certificate content, and paste it into the Client CA Certificate Public Key Content dialog as the client CA certificate.
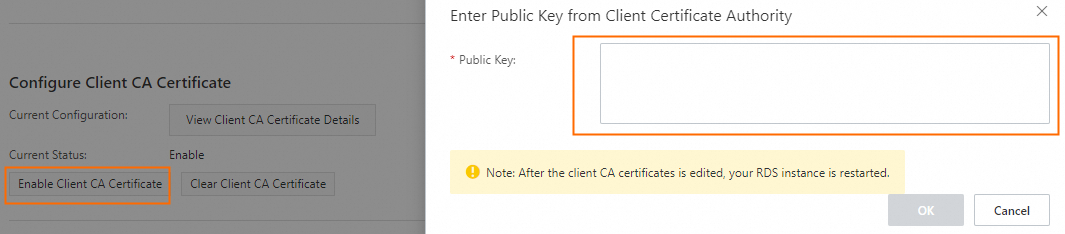
After configuring the client CA certificate on the RDS side, when you configure the PostgreSQL data source in DataWorks, convert the client certificate private key client.key to a client.pk8 file, and upload the client.pk8 file to the Private key file configuration item in the DataWorks PostgreSQL data source configuration.
cp client.key client.pk8Configure the private key password.
openssl pkcs8 -topk8 -inform PEM -in client.key -outform der -out client.pk8 -v1 PBE-MD5-DESNoteWhen you run the command to configure the private key password, you must enter a password. If you set a password, use the same password for the private key password in the DataWorks PostgreSQL data source configuration.
Configure PostgreSQL SSL authentication files
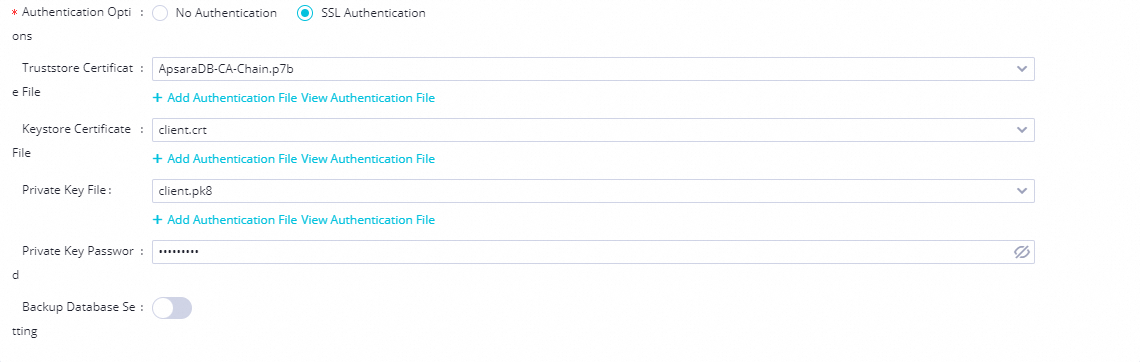
When you upload the obtained certificate files to the DataWorks PostgreSQL configuration items, perform the following operations:
Truststore certificate file: Upload the file with the
.pemextension or the file with the.p7bextension obtained in the Obtain the Truststore certificate file step.Keystore certificate file: Upload the client certificate file client.crt obtained in the Generate the client certificate step.
Private key file: Upload the client.pk8 file converted from the client certificate private key client.key in the Convert the private key file step.
Private key password: The password configured in the Configure the private key password step.
ACL configuration: Go to the RDS instance list, click the RDS instance in the corresponding region, click the target instance ID to go to the instance details page, and then click Data Security > ACL Configuration to modify the setting. You can select different SSL authentication methods. For more information, see Configure ACL.
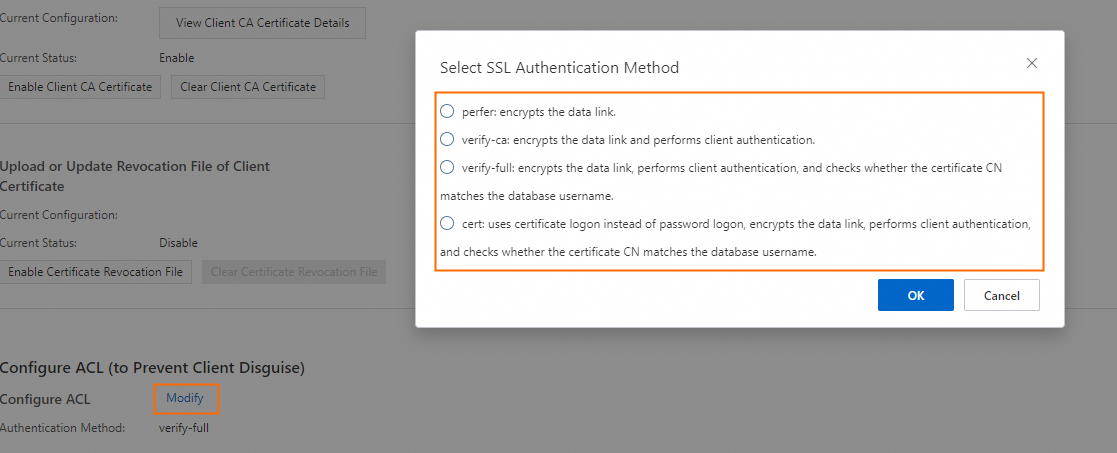
If the ACL authentication method is set to prefer, the PostgreSQL server does not enforce client certificate verification.
If the ACL authentication method is set to verify-ca in RDS PostgreSQL, you must upload the correct client certificate when configuring the PostgreSQL data source in DataWorks, so that the server can verify the client authentication.