This topic describes common issues and solutions for creating, using, and managing clusters.
Migrating self-managed clusters to ACK
ACK provides a migration solution to smoothly migrate a self-managed Kubernetes cluster to an ACK cluster with minimal impact on your business. For more information, see Overview of Kubernetes migration solutions.
Alibaba Cloud Linux and CentOS image compatibility
Yes, they are compatible. For more information, see Alibaba Cloud Linux 3.
Changing container runtime after cluster creation
No, you cannot change the container runtime after the cluster is created. However, you can create node pools that use different runtimes. For more information, see Create and manage a node pool.
To migrate the container runtime of a node from Docker to containerd, see Migrate the container runtime of a node from Docker to containerd.
Docker is not supported as a built-in container runtime in clusters that run Kubernetes 1.24 or later. You must use containerd as the runtime for node pools in these clusters.
Comparison of container runtimes
Container Service for Kubernetes supports three runtimes: containerd, Docker, and Sandboxed-Container. We recommend that you use the containerd runtime. The Docker runtime is supported only in clusters that run Kubernetes 1.22 or earlier. The Sandboxed-Container runtime is supported only in clusters that run Kubernetes 1.24 or earlier. For a comparison of these runtimes, see Comparison of containerd, Sandboxed-Container, and Docker runtimes. When you upgrade an ACK cluster to Kubernetes 1.24 or later, you must migrate the container runtime of nodes from Docker to containerd. For more information, see Migrate the container runtime of a node from Docker to containerd.
ACK and MLPS 2.0 Level 3 certification
You can enable MLPS-based hardening for your cluster and configure baseline check policies. Based on Alibaba Cloud Linux, you can implement MLPS 2.0 Level 3 and configure baseline checks for MLPS compliance to meet the following requirements:
Identity authentication
Access control
Security audit
Intrusion prevention
Malicious code prevention
For more information, see Enable MLPS-based hardening for ACK clusters.
ACK and Istio support
Yes. You can use Alibaba Cloud Service Mesh (ASM). ASM is a service mesh product that is fully compatible with community Istio. Its fully managed control plane lets you focus on developing and deploying your business applications. ASM is compatible with various node operating systems and network plug-ins in ACK clusters. You can add an existing ACK cluster to an ASM instance and use features such as traffic management, fault handling, unified monitoring, and log management. For more information, see Add a cluster to an ASM instance. For information about ASM billing, see ASM billing.
Collect diagnostic information
If a Kubernetes cluster encounters an issue or a node is abnormal, you can use the one-click diagnostic feature provided by ACK to identify the problem. For more information, see Use cluster diagnostics.
If the cluster diagnostics feature does not meet your needs and you need to collect diagnostic information from master and abnormal worker nodes, follow the steps in the following sections to collect information from Linux or Windows nodes.
Linux node
Worker nodes can run Linux or Windows, but master nodes can run only Linux. The following method applies to both master and worker nodes that run Linux. This example uses a master node.
Log on to a master node of the Kubernetes cluster and run the following command to download the diagnostic script.
curl -o /usr/local/bin/diagnose_k8s.sh http://aliacs-k8s-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/public/diagnose/diagnose_k8s.shNoteThe diagnostic script for Linux nodes can be downloaded only from the China (Hangzhou) region.
Run the following command to grant the diagnostic script execution permissions:
chmod u+x /usr/local/bin/diagnose_k8s.shRun the following command to change to the specified directory:
cd /usr/local/binRun the following command to run the diagnostic script:
diagnose_k8s.shThe output is similar to the following. The name of the generated log file varies each time you run the script. This example uses diagnose_1514939155.tar.gz.
...... + echo 'please get diagnose_1514939155.tar.gz for diagnostics' please get diagnose_1514939155.tar.gz for diagnostics + echo 'Please upload diagnose_1514939155.tar.gz' Please upload diagnose_1514939155.tar.gzRun the following command to view the file that contains the cluster diagnostic information:
ls -ltr | grep diagnose_1514939155.tar.gzNoteReplace diagnose_1514939155.tar.gz with the actual name of the log file in your environment.
Windows node
To collect cluster diagnostic information from a Windows worker node, download and run the diagnostic script.
Windows is supported only for worker nodes.
Log on to the abnormal worker node and open a command-line tool.
Run the following command to enter PowerShell mode:
powershellRun the following command to download and run the diagnostic script.
You can download the diagnostic script for Windows nodes from your cluster's region. Replace
[$Region_ID]in the command with the ID of your cluster's region.Invoke-WebRequest -UseBasicParsing -Uri http://aliacs-k8s-[$Region_ID].oss-[$Region_ID].aliyuncs.com/public/pkg/windows/diagnose/diagnose.ps1 | Invoke-ExpressionThe following output indicates that the diagnostic information is successfully collected.
INFO: Compressing diagnosis clues ... INFO: ...done INFO: Please get diagnoses_1514939155.zip for diagnosticsNoteThe diagnoses_1514939155.zip file is saved in the directory where the script is run.
Troubleshoot ACK cluster issues
Step 1: Check cluster nodes
Run the following command to view the status of the nodes in the cluster. Verify that all nodes exist and are in the Ready state.
Run the following command to view detailed information and events for a node.
Replace
[$NODE_NAME]with the name of your node.kubectl describe node [$NODE_NAME]NoteFor more information about the output of kubectl, see Node Status.

Step 2: Check cluster components
If you cannot identify the issue after checking the cluster nodes, check the cluster component logs on the control plane.
Run the following command to view all components in the kube-system namespace.
kubectl get pods -n kube-systemThe expected output is as follows.
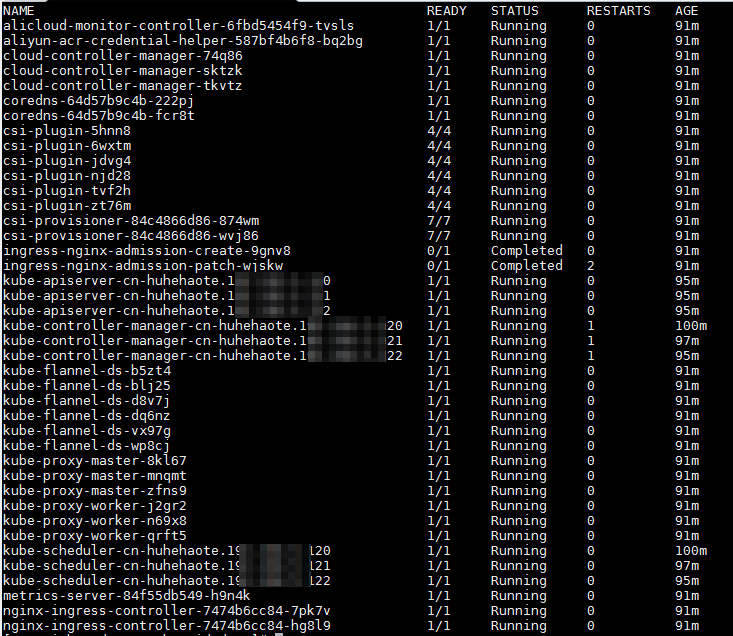 Pods whose names start with
Pods whose names start with kube-are system components of the Kubernetes cluster. Pods whose names start with coredns- are DNS add-onscoredns-are DNS plug-ins. This output indicates that the components are in a normal state. If a component is in an abnormal state, proceed to the next step.Run the following command to view the logs of the abnormal component to identify and resolve the issue.
Replace
[$Component_Name]with the name of the abnormal component.kubectl logs -f [$Component_Name] -n kube-system
Step 3: Check the kubelet component
Run the following command to check the status of the kubelet.
systemctl status kubeletIf the status of the kubelet is not
active (running), run the following command to view the kubelet logs to identify and resolve the issue.journalctl -u kubelet
Common cluster issues
The following table lists some common causes of ACK cluster failures and their solutions.
Issue | Solution |
The API Server component or a master component stops:
| ACK components have built-in high availability. We recommend that you check whether the component itself is abnormal. For example, the API Server of an ACK cluster uses a CLB instance by default. You can troubleshoot the abnormal status of the CLB instance. |
The backend data for the API Server is lost:
| If you created a snapshot, you can restore data from the snapshot when an issue occurs. If you did not create a snapshot, submit a ticket. After the issue is resolved, take the following measures to prevent this issue:
|
An individual node shuts down, and all pods on that node stop running. | Use a workload such as a Deployment, StatefulSet, or DaemonSet to create pods instead of directly creating pods. This ensures that replacement pods are scheduled on healthy nodes if a node fails. |
The kubelet component fails:
|
|
Issues are caused by manual configurations or other reasons. | If you have created a snapshot, you can use it to restore data when an issue occurs. If you have not created a snapshot, submit a ticket to report the issue. After the issue is resolved, periodically create snapshots for the data volume that is used by the kubelet. For more information, see Create a snapshot for a single disk volume. |
Configure fine-grained authorization
By default, a RAM user or RAM role does not have permissions to call the OpenAPI of any cloud service. To use and manage ACK clusters, you must grant the AliyunCSFullAccess system policy or a custom policy for Container Service for Kubernetes to the RAM user or RAM role. For more information, see Grant access permissions to clusters and cloud resources by using RAM.
Based on the Kubernetes RBAC mechanism, you must use RBAC to authorize a RAM user to manage internal cluster resources, such as creating Deployments and Services.
In scenarios that require fine-grained control over read and write permissions on resources, see Use custom RBAC policies to restrict operations on resources in a cluster to configure more fine-grained RBAC permissions by using a custom ClusterRole and Role.
When a RAM user accesses the console, you must also configure the corresponding cloud service permissions to use features such as viewing node pool scaling activities and cluster monitoring dashboards. For more information, see Permissions required for the Container Service for Kubernetes console.
What IP address ranges must be allowed for the SLB access control policy of a cluster's API Server?
The access control list (ACL) rules for the API Server's SLB instance must allow the following CIDR blocks.
-
The 100.104.0.0/16 CIDR block, which is reserved for the Container Service for Kubernetes control plane.
-
The primary and any additional CIDR blocks of the cluster's Virtual Private Cloud (VPC), or the CIDR blocks of the vSwitches where the cluster nodes reside.
-
The egress CIDR blocks of clients that need to access the API server.
-
For ACK Edge clusters, you must also add the egress CIDR blocks of edge nodes.
-
For ACK Lingjun clusters, you must also add the CIDR blocks of the Lingjun Virtual Private Datacenter (VPD).
For more information, see Configure the access control policy for the API Server.
Access a master node
Dedicated cluster: For more information, see Connect to the master node of a dedicated ACK cluster by using SSH.
Managed cluster: The control plane nodes of an ACK managed cluster are fully managed. You cannot log on to the terminals of the control plane nodes. If you need to log on to control plane nodes, consider using a dedicated cluster.
If a master node of an ACK dedicated cluster is accidentally deleted, can the cluster be upgraded?
No. After you delete a master node from a dedicated cluster, you cannot add master nodes or upgrade the cluster. You can create a dedicated ACK cluster (discontinued).
ACK dedicated cluster: Can master nodes be removed or added, and what are the high-risk operations?
No. Adding or removing master nodes from a dedicated cluster may cause the cluster to become unusable and unrecoverable.
For the master nodes of a dedicated cluster, improper operations can render the master nodes or even the entire cluster unusable. High-risk operations include replacing master or etcd certificates, modifying core components, deleting or formatting data in core directories such as /etc/kubernetes on a node, and reinstalling the operating system. For more information, see High-risk operations related to clusters.
ACK dedicated clusterAPI Servererror:api/v1/namespaces/xxx/resourcequotes": x509: certificate has expired or is not yet valid: current time XXX is after xxx. What do I do?
Symptoms
When you create a pod in a dedicated cluster, the API Server returns a certificate expiration error, or the logs or events of the kube-controller-manager show a certificate expiration error. The error message is as follows.
"https://localhost:6443/api/v1/namespaces/xxx/resourcequotes": x509: certificate has expired or is not yet valid: current time XXX is after XXX"https://[::1]:6443/api/v1/namespaces/xxx/resourcequotes": x509: certificate has expired or is not yet valid: current time XXX is after XXXCause
In Kubernetes, the API Server has a built-in certificate for its internal LoopbackClient. In the community version, this certificate has a validity period of 1 year and cannot be automatically rotated. It is rotated and updated only when the API Server pod restarts. If the cluster has not been upgraded for more than a year, the internal certificate expires, causing API requests to fail. For more information, see #86552.
To reduce the stability risks caused by the short validity period of certificates in the community version, ACK extends the default validity period of this built-in certificate to 10 years for clusters that run Kubernetes 1.24 or later. For more information about the changes and their scope of impact, see Product Change: Validity Period of ACK Cluster API Server Internal Certificates.
Solution
You can log on to a master node and run the following command to query the expiration time of the LoopbackClient certificate.
In the command, XX.XX.XX.XX is the local IP address of the master node.
curl --resolve apiserver-loopback-client:6443:XX.XX.XX.XX -k -v https://apiserver-loopback-client:6443/healthz 2>&1 |grep expireFor clusters with 1-year certificates that have expired or are about to expire, see Manually upgrade an ACK cluster to upgrade the cluster to version 1.24 or later. We recommend that you migrate to an ACK Managed Cluster Pro instance (Hot migrate a dedicated ACK cluster to an ACK Managed Cluster Pro instance).
For a dedicated cluster that cannot be upgraded in the short term, log on to each master node and manually restart the API Server to generate a new valid certificate.
containerd node
crictl pods | grep kube-apiserver- | awk '{print $1}' | xargs -I '{}' crictl stopp {}Docker node
docker ps | grep kube-apiserver- | awk '{print $1}' | xargs -I '{}' docker restart {}