This article is based on the speech delivered by Xintong Song, Yuan Mei and Lincoln Lee, who are all from the Alibaba Cloud Flink team, at Flink Forward Asia in Jakarta 2024.
Xintong
Hello, good morning, everyone. My name is Xintong. I'm from the Alibaba Cloud Flink Team, and I'm one of the Apache Flink PMC members.I'm also the release manager of the Flink 2.0. Today, it is my honor to share with you about Flink 2.0, together with my colleagues Yuan Mei and Lincoln Lee, who are both Apache Flink PMC members.
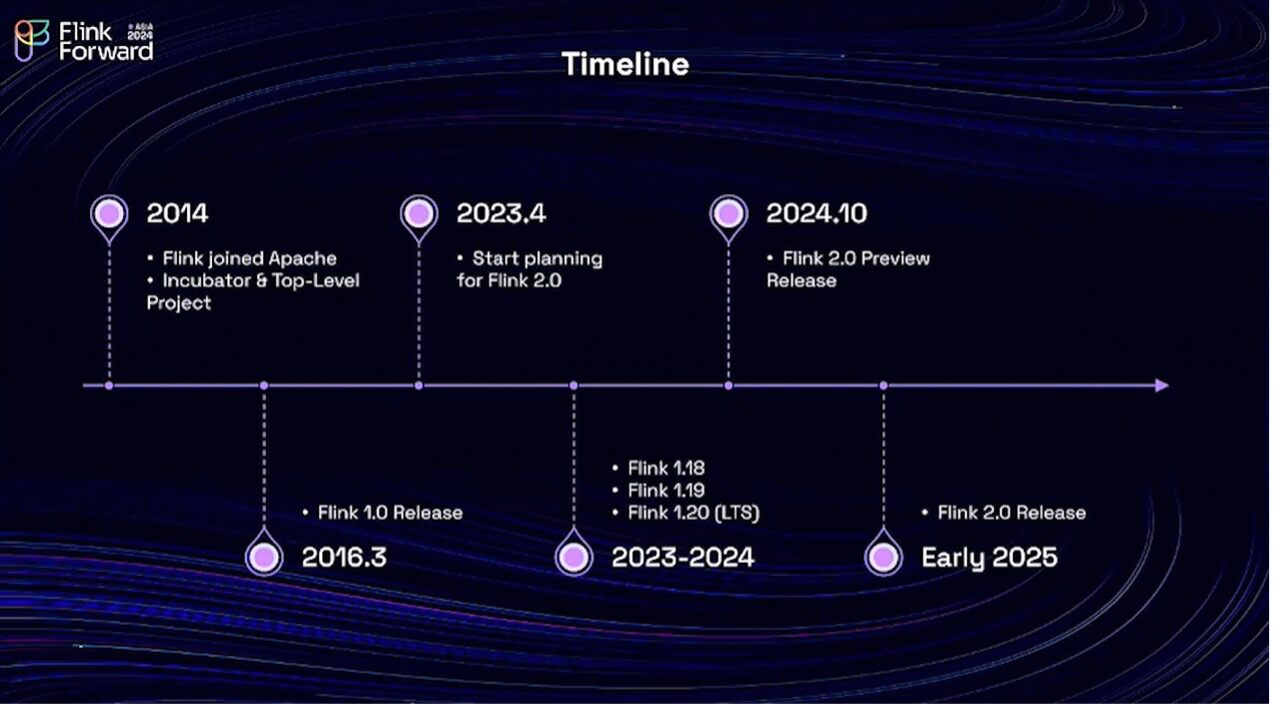
Well, we mentioned that Apache Flink joined the Apache Software Foundation in 2014, but the first formal version, Flink 1.0, was actually released in 2016. Since then, Flink has released many minor releases. There have been 1.X releases, such as versions 1.17, 1.18, but we have never released another major version in the past eight years. In 2023, we realized that Flink has undergone many changes since it was first shaped as Flink 1.0. We are also facing increasing challenges. To address these challenges, we need to make some significant architectural upgrades to the project. In April 2023, we kicked off the planning for the Flink 2.0 in the community and the preparation of the Flink 2.0 took quite long. We have been through three minor releases, the versions 1.18,1.19 and 1.20.
Finally, in October 2024 at Flink Forward Berlin 2024, we announced a preview release for Flink 2.0, which is expected to be shipped in early 2025. So we can see that the preparation for Flink 2.0 takes a long time. This period is almost two years—from April 2023 to early 2025. The reason it takes so long is that we are making some compatibility-breaking changes in this major version. And we want to leave enough time for our users ,our partners projects to adapt to these breaking changes. Here is a summary of the breaking changes.

We have removed some deprecated APIs, for example, the DataSet API, the Scala DataStream API, and some old connector APIs. For the existing APIs, we also made updates like the DataStream API and Table API, REST API, Flink client and SQL client. For the configuration, we have removed the old 'flink-conf.yaml' file, and users can now use the new 'conf-yaml' file, which strictly follows the YAML standard. Additionally, we removed some deprecated config options.
It should be noted that savepoint and checkpoint compatibility is not 100% guaranteed between versions 1.0 and 2.0. This is primarily due to the upgrades made to Flink's serialization framework. The community is working on tools to help users migrate between incompatible states. Additionally, support for Java 8 has been dropped, and the per-job deployment mode will be removed in version 2.0. Furthermore, as previously mentioned, some older connector APIs are being deprecated. This means any existing connectors relying on outdated APIs will need to be migrated to the new APIs to remain compatible with Flink 2.0. As a first step, the Flink community will work on the following four most commonly used connectors: Kafka connector, Paimon connector, JDBC connector, and Elasticsearch connector. These connectors will be supported by the time Flink 2.0 is formally released, and support for the remaining connectors will be gradually rolled out. We invite community developers to actively contribute and help accelerate the adoption of Flink 2.0 as well as the growth of the connector ecosystem.
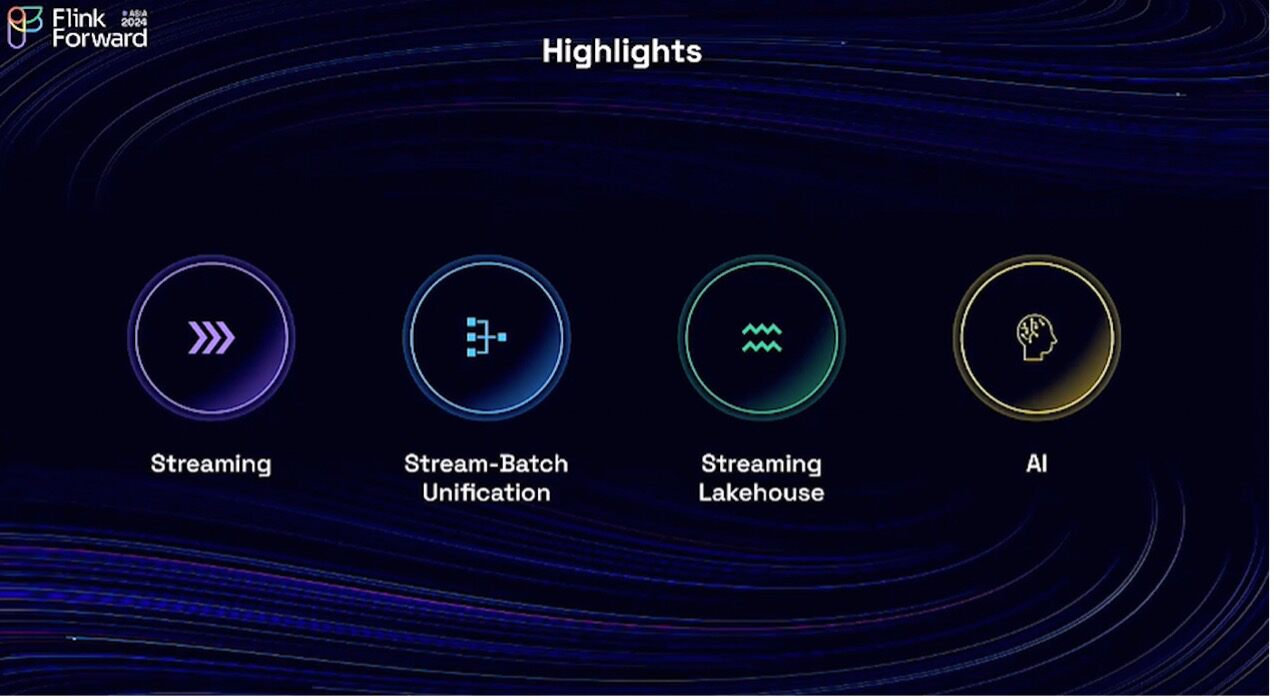
We have spent some time on the progress and breaking changes of Flink 2.0. The remaining time of this talk will focus on the technical highlights of Flink 2.0, and we are going to talk about four directions: Streaming, Stream-Batch Unification, the Streaming Lakehouse, and AI. First, we'd like to talk about Streaming, and for this part, I'd like to invite my colleague, Yuan Mei, a Flink PMC member, to the stage.Please welcome Yuan Mei.
Yuan Mei
I am Yuan Mei, director of engineering at Alibaba Cloud. I'm also a PMC member of Flink. Today, I'm going to share some of the very exciting work we've done in Apache Flink 2.0, specifically focusing on the 2.0 architecture evolution --- disaggregated state management, which enables Flink's cloud-native future.

2024 is the 10th anniversary of Flink after it became the top-level project of the Apache Software Foundation. Over the past decade, Flink has been blooming and widely used in many different areas, and it has developed rich upstream and downstream ecosystems.Thus, Flink has become a de facto standard for stream processing in the open-source area, as well as in academia and industry, globally. I think three symbolic characteristics depicted above are at the core of Flink's foundation: distributed at large scale, high performance, and stateful computation.
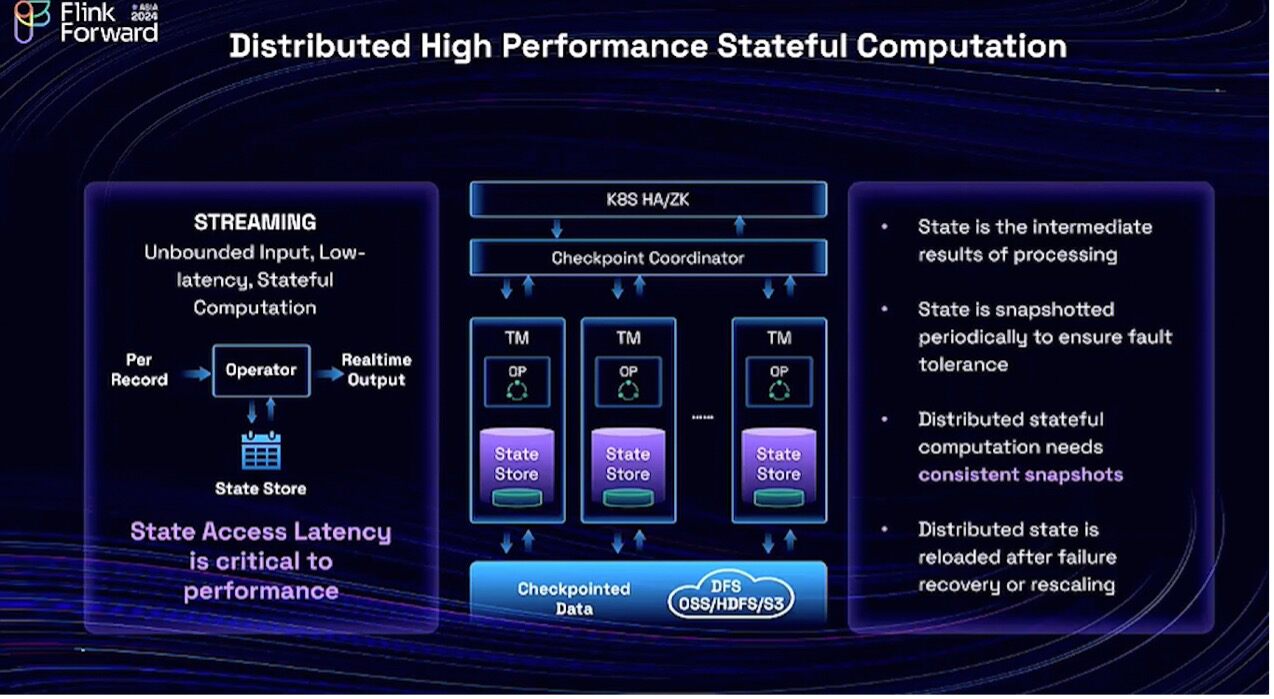
What is stateful computation? For a stream processing system, the input is unbounded and continuous, generating low-latency output based on this continuous input and the state (which basically means the intermediate results of the processing).Thus, for each input record, it must access the storage, retrieve the intermediate result, and then able to generate the new output. Hence, state access latency is critical to performance. It is important to remember this and I will explain later the reason. Because the State Access Latency is critical in Flink, we co-locate the state store together with computation as shown in the middle of the graph.
States must be periodically snapshotted so that when a failure happens or a rescaling operation is performed, we can restore the state. For distributed systems, we must ensure that the snapshot is consistent across all of the distributed nodes. A consistent snapshot means that each distributed node holds a subpart of the snapshot that corresponds to the exact same input offset. The procedure for creating a consistent snapshot is the well-known Flink checkpoint procedure.

This tightly coupled architecture guarantees high performance for Flink, but it can hinder the expansion and development of Flink, especially when the state size grows large and exceeds the capacity of the local disk. Along with the cloud-native trend in recent years, we face additional challenges. As you can see, we summarize the challenges in four parts.
The first challenge is that computation and storage need to scale independently. We do not want to incur extra costs for computation simply because our state size grows larger.
The second challenge is containerization. Containerization is a commonly used technology in cloud-native environments, requiring predictable and smooth resource usage. In a tightly coupled architecture, the checkpointing procedure occurs over a very short period, significantly boosting resource usage in both the CPU and networking. This creates resource usage peaks, making the entire cluster unstable.
The third challenge is cloud storage, such as S3 and OSS, which is commonly used and readily available nowadays. So how can we effectively utilize such cost-effective and massive storage? They are highly available and scalable, so how can we utilize them with improved hardware, network speed, and bandwidth? Is it possible to eliminate the need for local disks?
The fourth challenge is elasticity for stateful computation. Rescaling is lighteight for stateless computation. However, for stateful computation, we must redistribute the state across containers during rescaling. State redistribution takes time, and is it still achievable within sub-second intervals? That's also a challenge for us.

To address these challenges, we introduce ForSt DB, facilitating disaggregated state management in Apache Flink 2.0. "ForSt" stands for "For Streaming." Essentially, ForSt DB is a "For Streaming Database."It is a straightforward name that reflects its purpose well: ForSt DB. ForSt DB has already been open-sourced by Alibaba Cloud.

ForSt DB natively supports writing to and reading from DFS—the distributed file system, such as S3/OSS/HDFS. How writing to DFS address all the challenges mentioned above?
First, state is no-longer constrained by local disk. DFS provides unlimited storage space so that state size is not constrained by local disks anymore. The second one is Instant Rescale&Recovery, which is possible now because we can read from DFS directly, eliminating the need to download the state during recovery or rescaling. The third is Light-weight Checkpointing. Since both state and the checkpoint data reside on the same DFS, they can share the same physical files. Hence we can make the checkpointing procedure light-weighted. As mentioned earlier, the current checkpoint procedure leads to peak resource usage in the coupled architecture. Implementing a lightweight checkpointing procedure could significantly smooth out resource consumption.
The diagram illustrates the architecture upgrade from Flink 1.0 (left) to Flink 2.0 (right). At first glance, the change appears straightforward: transitioning from local disk to remote storage. However, this seemingly simple shift to DFS for state management in Flink introduces significant complexities.
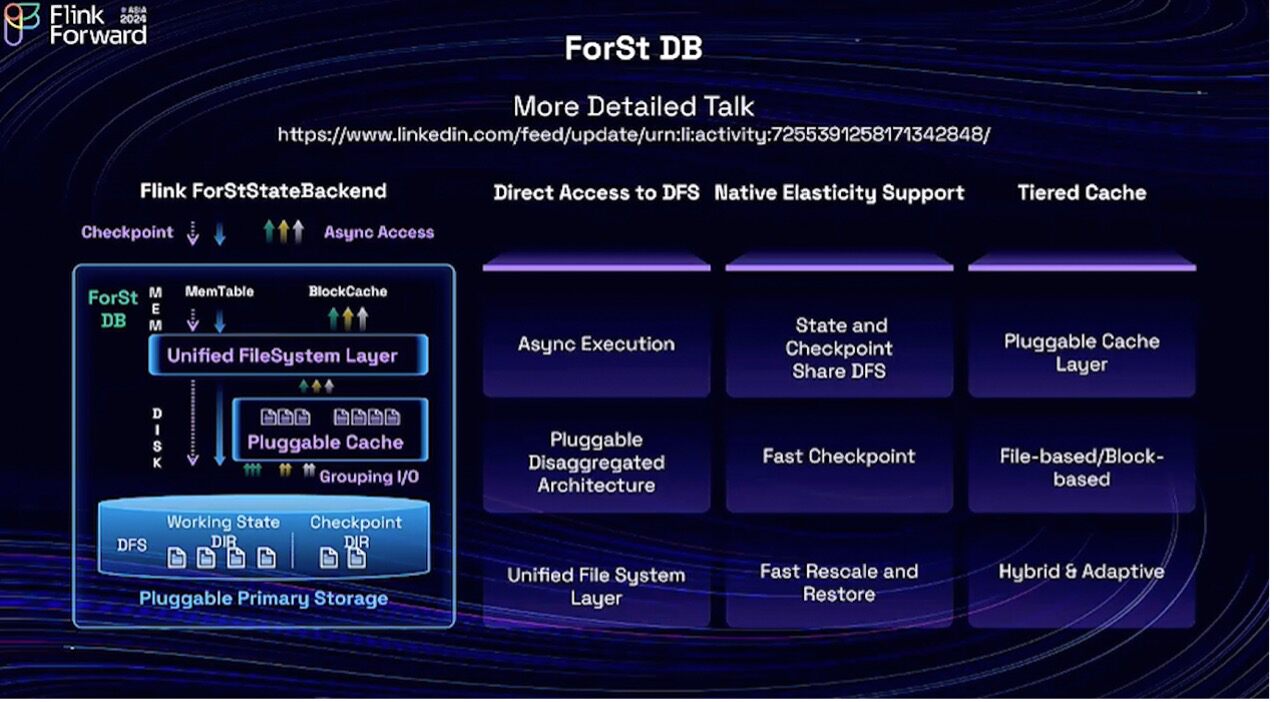
As mentioned earlier, state access latency is critical for performance. Accessing state on a DFS introduces significantly higher latency compared to a local disk. In fact, we've observed that typical DFS access latency is 10 times longer compared to local disks. This means that simply swapping out the local disk for a DFS could result in a 10x performance decrease, rendering Flink unusable for most applications. This latency challenge has plagued previous attempts at disaggregated storage in Flink. However, with Flink 2.0 and ForSt DB, we've finally solve the problem.
The key insight here is Async Execution, which separates CPU processing from state access. This insight is crucial for making performance comparable when accessing DFS compared to accessing a local disk.
The second point I want to highlight in the middle column is the checkpointing procedure. For a streaming processing system, a native and deep integration of databases and the checkpoint procedure have to be done, otherwise, you cannot guarantee a consistent snapshot or exactly-once and you will lose all the benefits that Flink provides. Therefore, we made significant efforts in this area and also achieved native elasticity support.
The third part is tiered cache. As we know, when using disaggregated storage, caching is critical for boosting performance. However, if we have a local disk available, we should make good use of it. To that end, we have made significant efforts to develop a hybrid adaptive tiered cache. If you're interested, I have a more detailed talk here. You can follow the link to see a more comprehensive discussion about how this innovative solution works.

Flink 2.0 is expected to be released in March 2025. In the blue box, there are six major areas we plan to achieve in this release. ForSt DB and Async Execution are the cornerstones that make disaggregation successful. The ForSt DB preview version has already been released. The link is shown here, and it shares some of the experimental results. If you are interested, you can also try it out. The official version will target Flink 2.0 with end-to-end support for Flink disaggregation, including 70% support for SQL Async operations and SQL migration.

Here is a list of FLIPs (Flink improvement proposals) for the disaggregation. If you are interested, these proposals are all public within the Apache Flink community, covering all the details of the technology I discussed today for your reference.

To wrap up this section, let's look at some exciting results from our ForSt DB preview version, as shown above. These experiments compare ForSt DB with the latest Flink 1.20 release.
First, as you can see, synchronous execution with DFS is indeed much slower, around 10 times slower in the streaming Agg benchmark. This confirms what we discussed earlier about the significant latency impact of accessing state on a DFS. But now look at the async mode! Without any caching, we're already close to Flink 1.20 performance, only about 15% slower. And with a 50% cache, we actually achieve a 50% performance improvement over Flink 1.20. This means that even with half the local disk capacity, we can outperform the previous version. This is a remarkable result! It demonstrates that ForSt DB not only solves the performance challenges of disaggregated state but also unlocks new possibilities for leveraging cost-effective cloud storage and optimizing resource utilization.
If you're interested in how these remarkable improvements were achieved, feel free to check the technical documentation or watch my talk linked above. That covers all I want to mention in the streaming part. Next, let's invite my colleague, Lincoln, for Streaming-Batch Unification.
Lincoln

Thanks for Yuan's great talk. I'm Lincoln, and I also come from Alibaba Cloud. Now let's talk about the Streaming Batch Unification. What exactly is the Streaming Batch Unification? From a data engineering perspective, we can summarize it in one sentence: writing and storing just one set of data and one piece of code to meet both real-time and offline data processing needs. One code also implies the requirement for the unification of execution engines. Even when using SQL as a user API, we still have differences across various dialects. Thus, the most straightforward way to develop just one piece of code is to use a single engine.
Lincoln
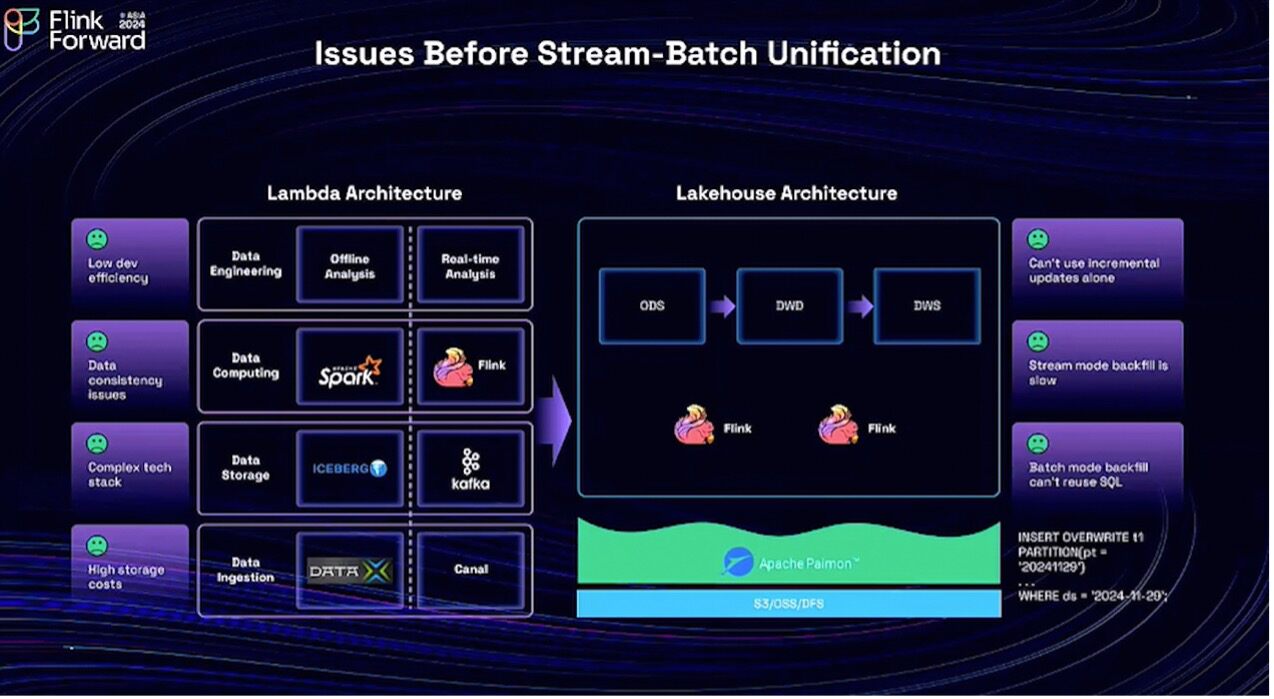
Now let's look at the challenges in real-world data engineering architecture. On the left is the classic Lambda architecture, which can be broken down into layers. There's the data ingestion layer, responsible for ingesting data into lakes or warehouses. Next is the data storage layer, consisting of both offline storage and message queues. The rest is the data development based on the specific computing engine.
From top to bottom, we have two different tech stacks for the two pipelines. This will lead to several issues in development, such as high storage costs due to storage redundancy and a complex technical stack. Additionally, users need to develop separately for both batch and real-time development, which may cause potential inconsistency.
In recent years, new unified stream-batch lake storage systems, such as Apache Paimon, have emerged, making the lakehouse architecture more relevant. Apache Paimon supports both streaming and batch writes. Together with the Flink engine, it can provide a continuously incremental update pipeline and greatly unify computation and development.
However, some issues remain unresolved. For instance, in streaming mode, data backfilling is quite slow. Additionally, achieving better performance with batch mode refresh still requires modifications to the original SQL.

Then, let's return to Flink's perspective. Over the past decade, we have achieved computational unification, evolving from a stream-batch unified engine architecture to a production-ready SQL engine. The new Apache Paimon serves as a unified storage solution for both streaming and batch processing, while Flink CDC provides a unified method for data ingestion. However, what is still needed to fully implement a comprehensive streaming-batch unified development stack?
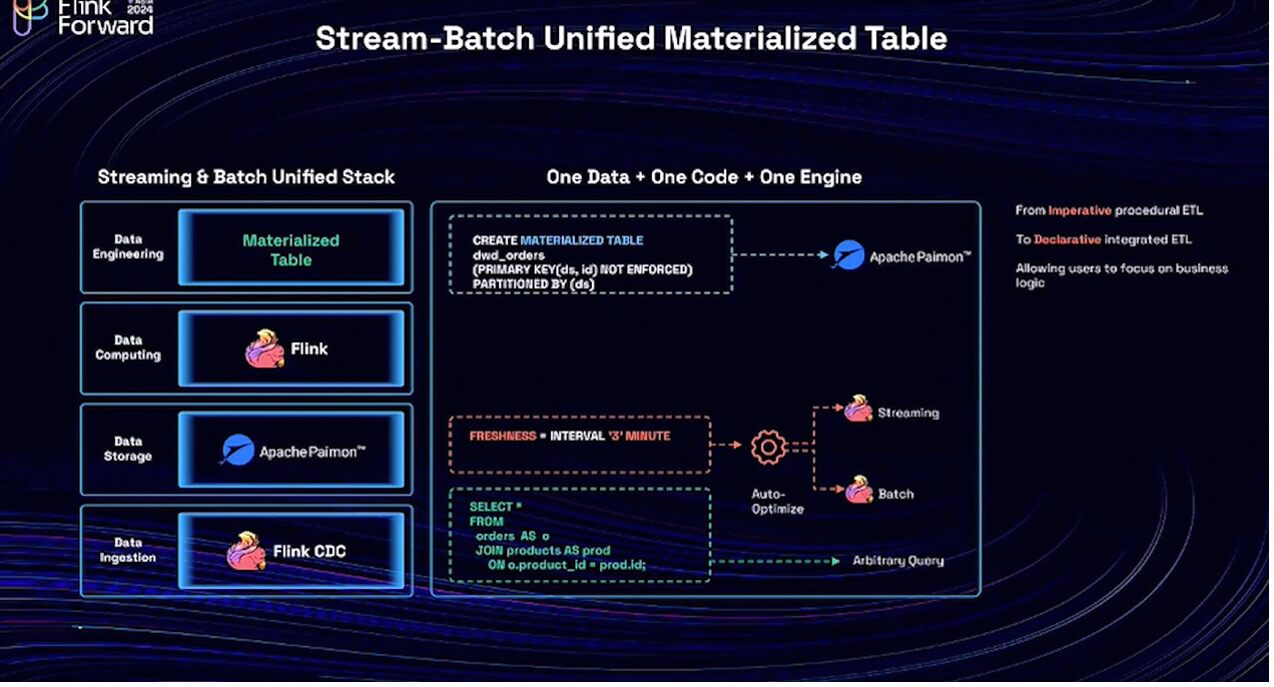
The core issue preventing the unification of streaming and batch code lies in the differences in programming models. For instance, the batch model is designed for static data and typically involves partition operations, such as "INSERT OVERWRITE PARTITION", where each partition has defined filtering conditions. On the other hand, streaming processing deals with streaming data, or unbounded data, and does not involve such partition operations,this leads to different SQL written in the two different models.
To address these issues, we have introduced the new Materialized Table. We can use a simple script to create a materialized table. It consists of three main parts. The first is the Create Materialized Table object. Then, a Paimon table will be created under the Paimon catalog. The second is data freshness, allowing users to set it according to their needs. The last part is the query definition, which describes the business logic. With the Materialized Table, users can use declarative SQL and maintain a unified one. Users just need to describe their business logic and set the data freshness according to their needs, and the engine will handle the rest automatically.
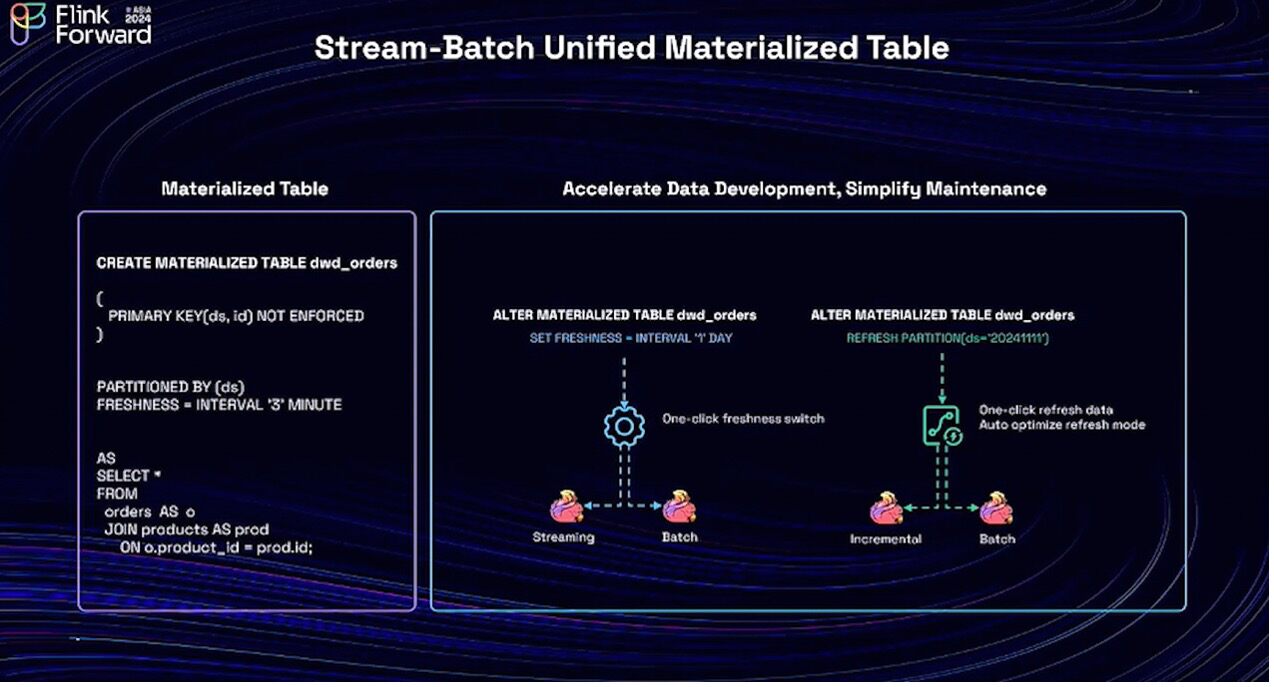
Additionally, when using Materialized Tables, users can enhance their maintenance work beyond writing just one piece of code. For example, during a promotion, we provide users with the second-level real-time data, and after the promotion ends, in order to reduce the operational costs, users can change the data freshness to day-level with a single click. Furthermore, for data backfilling, which is commonly used in data warehouses, we can also trigger it with a single command. Materialized Table not only helps users achieve writing just one piece of code, thereby improving their development and maintenance efficiency, but it also brings cost efficiency.
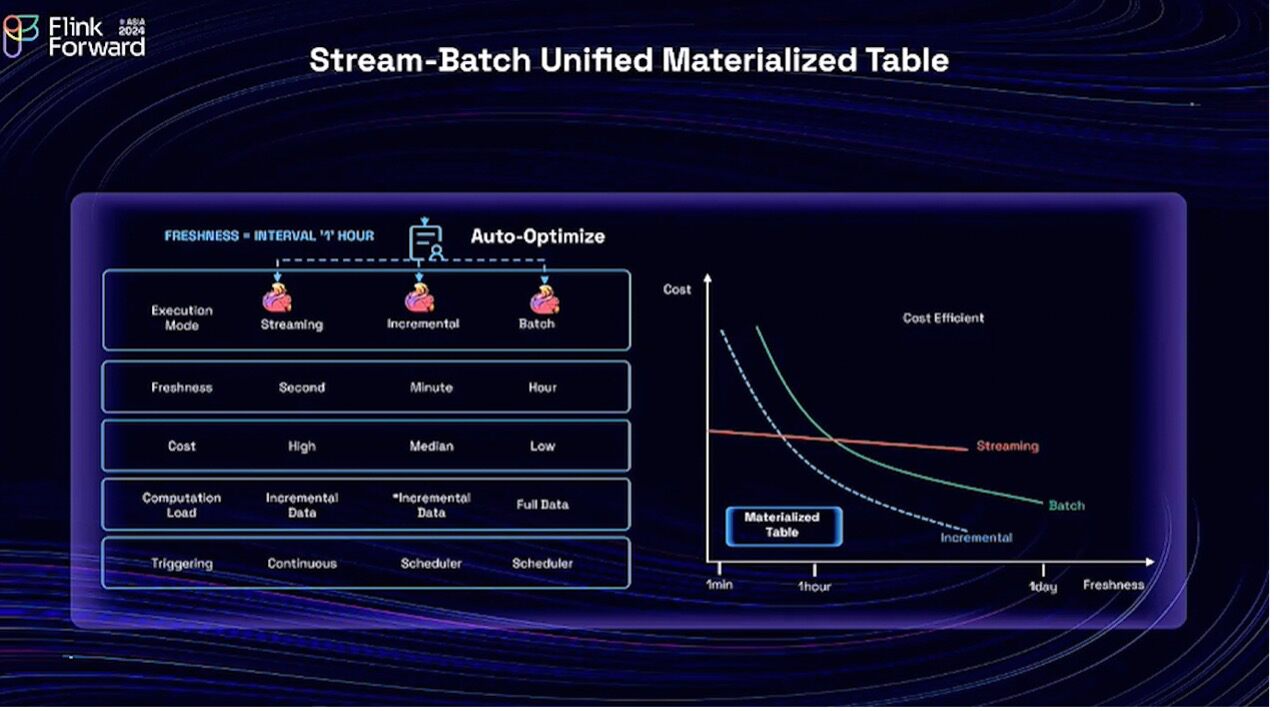
Materialized Tables support three different refresh modes: streaming mode for continuous refresh, batch mode for full refresh, and incremental refresh. Looking at the cost curve on the right side:
Streaming mode: Provides second-level real-time data freshness, but costs remain high even if data freshness is set to hourly because streaming mode requires residential computing resources.
Batch mode: Most cost-effective for data freshness ranging from hours to days. It's ideal for one-time computations, but becomes very costly for achieving minute-level freshness due to the need to recalculate all data each time.
Incremental refresh: Offers freshness between the two modes and reduces costs by only calculating incremental changes.
Thus, Materialized Table completes the final piece of the puzzle for Flink's Streaming-Batch Unification.
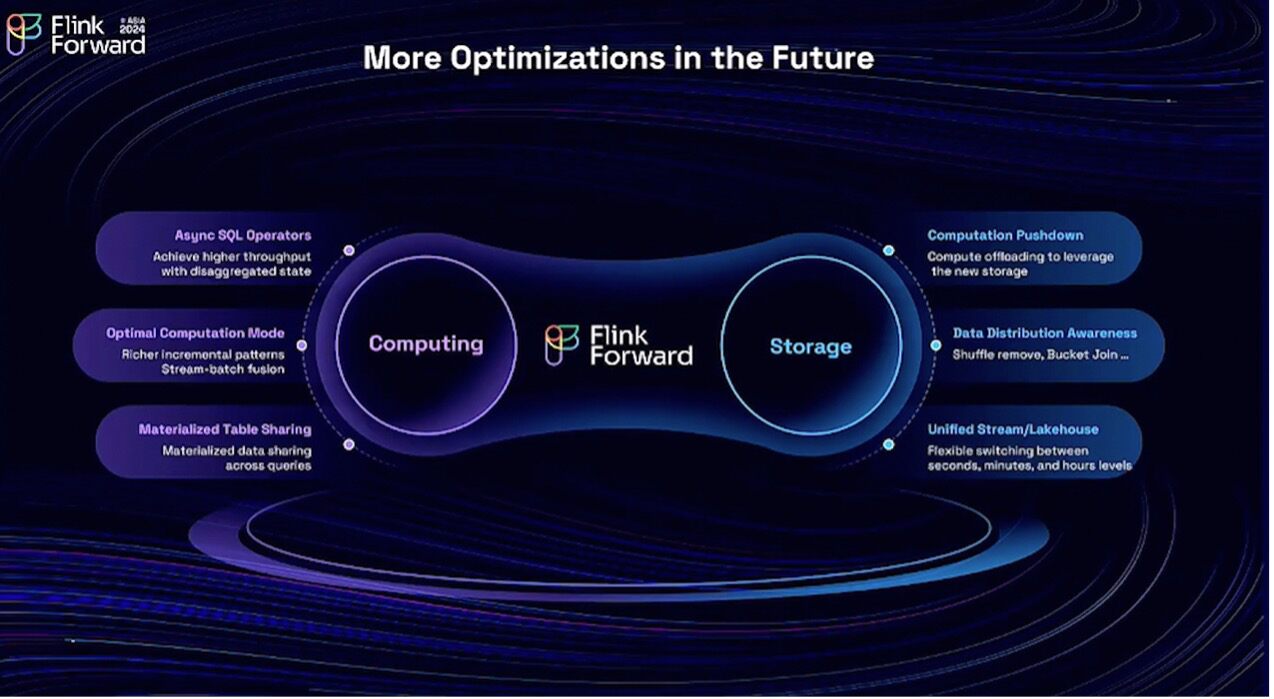
However, this is not the end. We will advance in joint optimization for both the computation and storage layers. For the computation aspect, we will improve operational efficiency, which involves a new disaggregated state, offering more efficient computation modes and enabling materialized data sharing.
For storage integration, we will leverage the new capabilities of storage, such as additional computation offloading. Together with the new unified stream lake storage, we aim to provide users with seamless switching between second-level, minute-level, and hour-level operations. This concludes the content on stream-batch unification. Thank you all. Now let's hand the stage over to Xintong.
Xintong
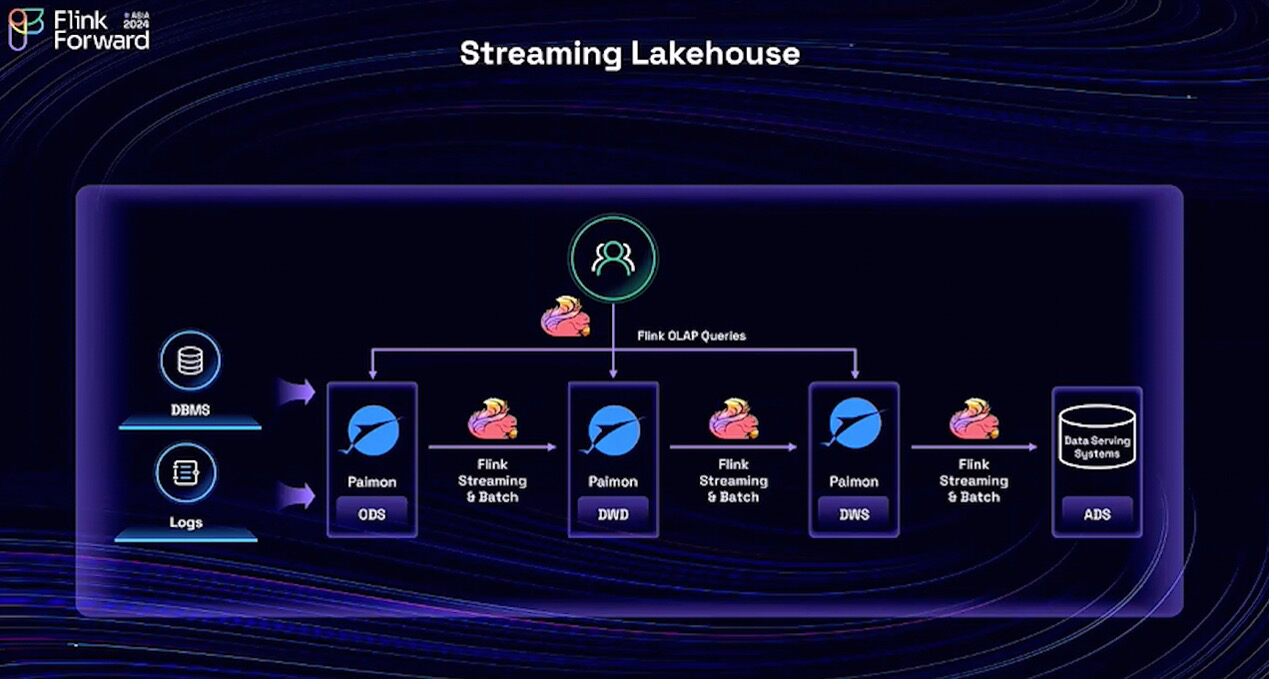
Thank you, Lincoln, and thank you, Yuan, for the sharing. Next, let's talk about the streaming lakehouse. The streaming lakehouse is a new architecture, as previously introduced in Lincoln and Feng's presentation. It's a new data analytics architecture that we built with Flink and Paimon. This architecture is completely stream-batch unified, and all the data in the streaming lakehouse is real-time and queryable. However, in order for this new architecture to land well in production, it requires deep integration between the two projects, Flink and Paimon. So we have been doing a lot in that direction.

Xintong
We have been improving the integration of Flink and Paimon in many commonly used scenarios. For example, in wide table scenarios, when people want to build a wide table, they typically use joining operations. However, joining is an expensive operation in data processing. Now, with Flink and Paimon, in some use cases where the primary key is available, we can replace the join operations with Paimon's partial update features, which will significantly reduce computational costs.
In certain scenarios where we utilize Paimon as a dimensional table, we have implemented numerous enhancements to improve its functionality. For example, we have improved the performance of Flink's Lookup Join with respect to the data distribution inside Paimon. To address the single key data skew problem, we have supported the Flink skew join optimization. There is also a new feature called a Proc-Time Temporal Join in Flink, which can be used in some use cases to replace the Lookup Join, especially in scenarios where the dimensional table is not frequently updated, and it can also reduce computational costs. We are also supporting some new emerging stream-batch unification scenarios, such as data synchronization with Flink CDC and Materialized Tables, which Lincoln just introduced.
Regarding engine capabilities, we have significantly improved the performance of reading from and writing to Paimon with Flink. For example, we have supported Paimon's deletion vector, data ordering, and some native file I/O implementations. For Paimon's maintenance actions, such as compaction and metadata cleanups, these can now be easily done with Flink, as the procedures and name arguments are fully supported.
Moreover, for semi-structured data like the JSON or XML, we frequently see those data in the AI and feature engineering scenarios. We are also working on some techniques, such as variant data types, to speed up the read/write and processing of semi-structured data.
That covers the integration of Flink and Paimon. The next topic, let's talk about AI. Through our interactions with the Flink community, developers, and users, this is actually a very frequently asked question. People often say that generative AI and large language models (LLMs) are very popular these days. What can Flink do in this area?
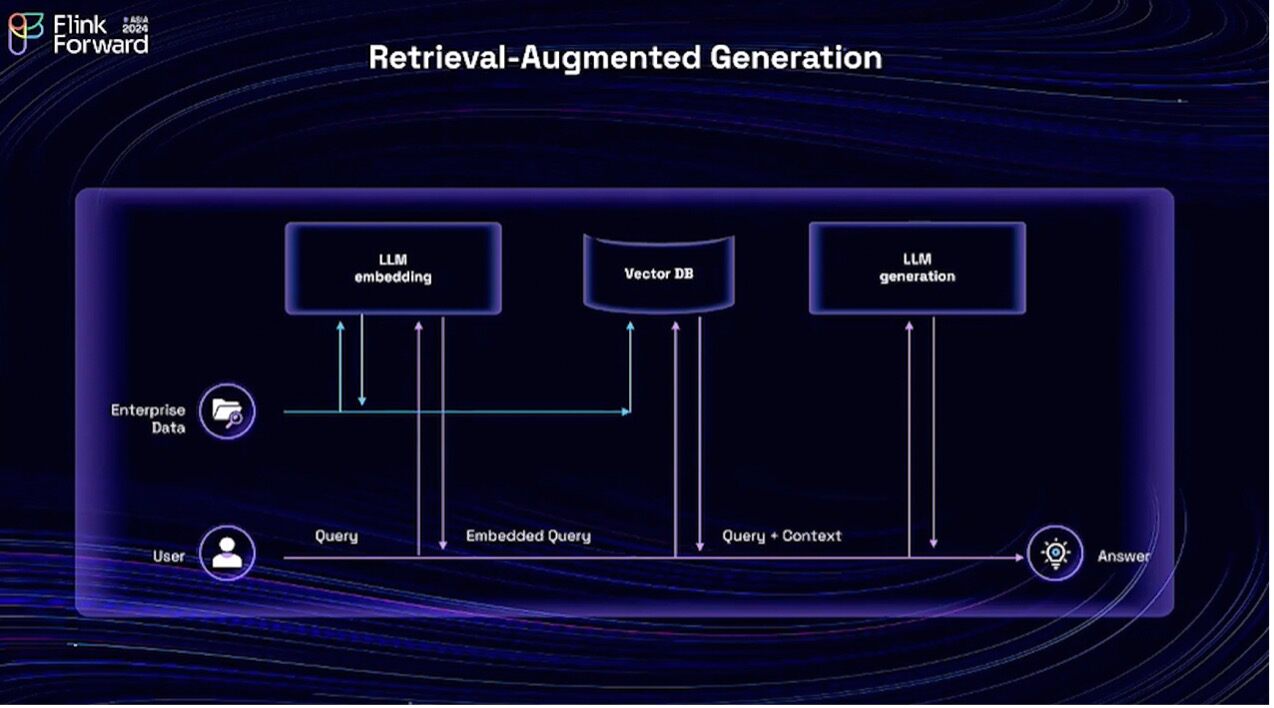
Let's look at the simplified version of the Retrieval-Augmented Generation(RAG) architecture. The idea of RAG is to leverage a knowledge base, such as some internal enterprise data or maybe some domain-specific knowledge. Thus, RAG leverages such knowledge bases to assist LLMs in content generation.
In this architecture, there are two steps. The first step is to prepare the knowledge base, and we use the LLM to generate a vector for each piece of data in the knowledge base. This is called the embedding, where the generated vector is stored in a vector database. In the second step, when user queries arrive, we perform the same embedding for these queries to generate a vector. Then we use this vector to search in the vector database(DB) for the most relevant content. We then provide the query and context together to the LLM for content generation.
The question is: how can Flink help in this architecture? We know that Flink is effective at real-time data processing. The question can be rephrased as: Is there any demand for real-time data processing in this architecture? I believe the answer is yes. First, the knowledge base is not static and constantly updated. When updates are made to the knowledge base, we expect the results to be reflected in the generated content as soon as possible. That depends on the real-time responsiveness of the blue pipeline in this figure.
When a user submits a query, it is expected that the content will be generated as soon as possible. This largely depends on the performance of the model itself, but the real-time responsiveness of the purple data pipeline also matters. We observed that there's a critical path in this architecture: the invocation of the large language model for both embedding and content generation. In order to speed up this critical path, the Flink community has introduced ML model invocation support in Flink.

Now Flink's users can just use Flink SQL to create a model, similar to creating a catalog. We can define the input and output data structures of the model as well as any model-specific arguments. Once the model is defined, we can simply use it within Flink SQL, like invoking a function or a table function. This will help integrate the model invocation with data processing and the validations before and after the model invocations. The design has already been approved by the Flink community and is currently under development.
This is the first step the Flink community has taken towards generative AI, and we believe there will be more efforts in this direction. This is what we present to you today for the Flink 2.0. Thank you for listening.
How we build a Scalable, Cost-effective Cloud-Native Streaming platform in Lalamove
A Guide to Preventing Fraud Detection in Real-Time with Apache Flink

206 posts | 58 followers
FollowAlibaba Cloud Community - December 6, 2024
Apache Flink Community - August 29, 2025
Apache Flink Community - December 17, 2024
Apache Flink Community - January 31, 2024
Apache Flink Community - October 12, 2024
Apache Flink Community - July 28, 2025
206 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More MaxCompute
MaxCompute
Conduct large-scale data warehousing with MaxCompute
Learn More Real-Time Streaming
Real-Time Streaming
Provides low latency and high concurrency, helping improve the user experience for your live-streaming
Learn More EventBridge
EventBridge
EventBridge is a serverless event bus service that connects to Alibaba Cloud services, custom applications, and SaaS applications as a centralized hub.
Learn MoreMore Posts by Apache Flink Community

