This article is based on the keynote speech given by Owen Ip and Jenny Chen, Data Engineer at Lalamove, at Flink Forward Asia in Jakarta 2024.
This presentation outlines the development of a scalable and cost-effective cloud-native streaming platform at Lalamove, led by data engineers Owen Ip and Jenny Chen. The session will provide a comprehensive overview of Lalamove's operations, delve into the architectural framework of its streaming platform, and address the challenges faced during the implementation of a cloud-native solution. Furthermore, the presentation will highlight the adoption of Apache Paimon as a tool to enhance the stability of the existing data pipeline.

Founded in Hong Kong in 2013, Lalamove is an on-demand delivery platform born with a mission to empower communities by making delivery fast, simple and affordable. At the click of a button, individuals, small businesses and corporations can access a wide fleet of delivery vehicles operated by professional driver partners. Powered by technology, Lalamove seamlessly connects people, vehicles, freight and roads, moving things that matter and bringing benefits to local communities in 13 markets across Asia, Latin America and EMEA.

Lalamove’s streaming platform is engineered to support substantial workloads, maintaining over 500 computing nodes with more than 8,000 Vcores during peak seasons. This robust infrastructure accommodates thousands of streaming jobs across two regional clusters. Primary use cases for this platform include real-time data analytics, anti-fraud monitoring, and a range of location-based services. The architecture employs Apache Flink, enabling processing of vast data sets with a latency of seconds with high processing throughput.

The architecture of Lalamove's platform is designed for maximum efficiency. At its core, the streaming platform is built on a hybrid cloud service model. This platform allows the scheduling of jobs across both Hadoop YARN clusters and Kubernetes clusters.
In the engine layer, Lalamove provides a customized Flink SQL environment, which extends numerous connectors to manage stateful computations. This flexibility enables the company to offer different versions of its service to platform users. For task development, users can submit either SQL or JAR tasks, investigate their data pipelines through data lineage, and upload User Defined Functions (UDFs) for implementing custom business logic. Furthermore, stress testing is incorporated to verify that the data pipelines can handle increased workloads during peak seasons.
For task operations, monitoring, logging, and alerting mechanisms are provided to ensure that users' data pipelines remain stable, observable, and cost-effective.
Moving forward, the strategies Lalamove implemented to ensure the highest levels of stability and cost-effectiveness on its platform will be discussed.

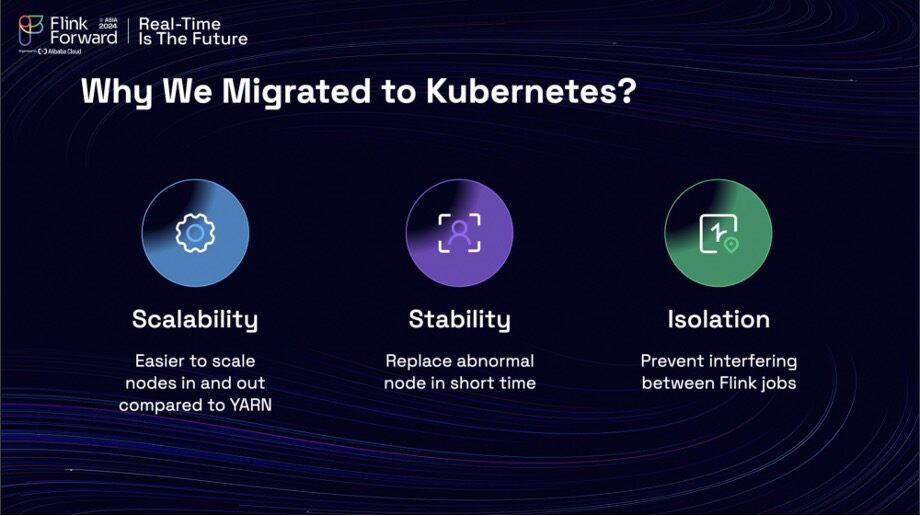
First, the reasons for migrating to a Kubernetes cluster were threefold. The enhanced scalability of infrastructure resources compared to a traditional YARN cluster was a significant factor. Additionally, Kubernetes offered improved stability for recovering from node disasters and provided better isolation to prevent interference between Flink jobs deployed on the same machine. The Kubernetes cluster architecture utilized the open-source Flink Kubernetes operator to manage the lifecycle of Flink jobs.
Furthermore, customized features, such as a metrics reporter and listener, were implemented to report job status and operator metrics back to the streaming platform, enabling effective job management on Kubernetes. Having established a foundational understanding of our stream platform, let's now turn our attention to the challenges that accompany its growth and evolution.
The first challenge is the increasing workload resulting from business growth. As the Lalamove expands into new markets and cities, opens additional business lines, and attracts more users to its delivery service, there is a pressing need for a scalable and maintainable platform.

Another significant challenge involves the continuous evolution of technology, particularly the rapid development cycles of Kubernetes. To ensure better stability, it is crucial to keep platform's infrastructure updated in order to receive ongoing support from the cloud service provider. Additionally, the platform and Flink engine are in constant improvement, necessitating efficient mechanisms for rolling out updates and optimizations to running jobs. Being responsible for managing thousands of tasks compounds these challenges, ultimately leading to increased maintenance costs for the platform.
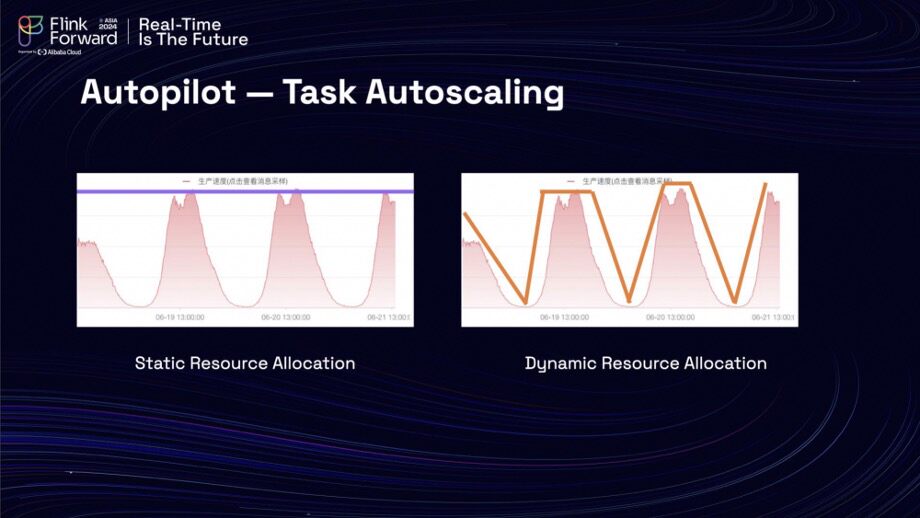
Finally, infrastructure costs present another challenge. A recent analysis of resource usage within the clusters revealed a clear pattern: resource consumption is low during nighttime but surges during the daytime, reflective of the business's nature. This observation raises the question of whether it is possible to dynamically allocate resources based on this usage pattern, as illustrated in a graph. This could lead to more efficient resource management and cost savings.
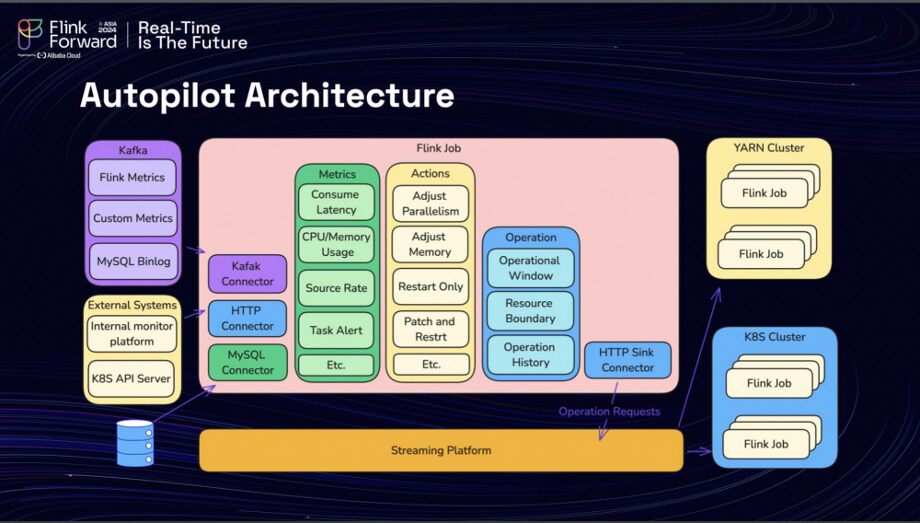
There are three significant challenges that lead to increasing infrastructure and maintenance costs, leading to the development of a solution known as the Autopilot. The team utilized Apache Flink to implement this autopilot, leveraging various extendable connectors such as Kafka, MySQL, and HTTP to collect job-related metrics from diverse sources. Flink serves as a robust engine, streamlining the operation of tasks across clusters. For instance, by monitoring consumer latency metrics from a Kafka topic, the system can autonomously adjust the parallelism of a job when latency exceeds acceptable levels, thereby enhancing consumer speed. The execution of operations via the Autopilot must adhere to predetermined operational windows and resource boundaries to ensure that all actions are manageable and within control. Once an action is identified, it signals the streaming platform to perform the operation.
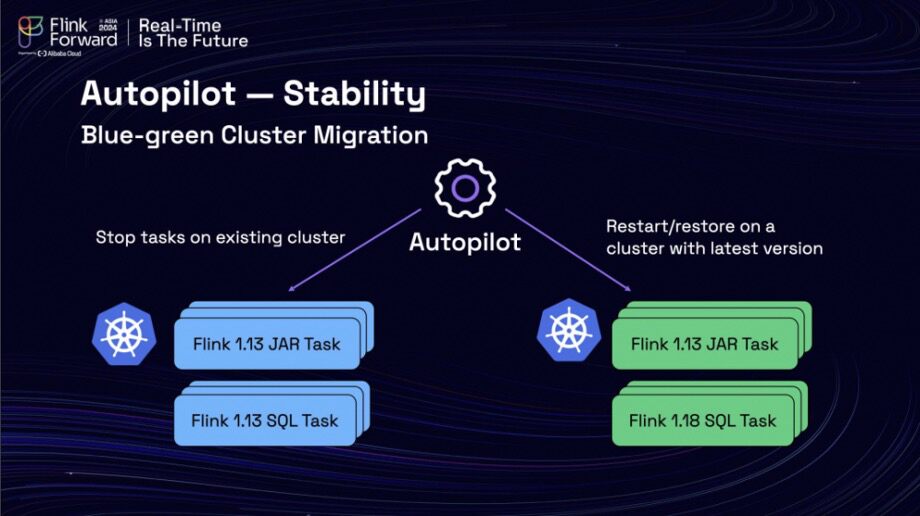
This approach significantly aids in reducing maintenance costs. For instance, during a Kubernetes upgrade, the team adopted a blue-green upgrade strategy rather than an in-place upgrade, utilizing the autopilot to establish auto-creation rules that facilitate the migration of tasks from the old clusters to the new ones. This ensures that job migration occurs within the operational window, preventing any disruption to production environments.
In addition to managing Kubernetes upgrades, the autopilot continuously monitors metrics related to Flink job. When the system detects alerting metrics, it can automatically redeploy Flink jobs that previously required manual intervention. The team also defined rules for optimizing Flink by automating the rolling upgrades of jobs based on collected metrics.
In addition, the Lalamove team recognized the potential of leveraging their autopilot to implement their own resource autoscaling. Although Flink offers an open-source autoscaler, they opted to develop their own solution for several key reasons. First, their autopilot allows them to define an operational window that ensures optimal stability. Also, the self-developed autoscaler enables prioritization of tasks for scaling, such as older low-priority tasks. Additionally, their autoscaler is compatible with any version of Flink, which is particularly beneficial for versions lower than 1.8 1.18 that are not supported by the open-source Flink autoscaler. Furthermore, the autopilot offers enhanced extendability, allowing for the easy addition of more metrics to inform scaling decisions. The team can even adapt the Flink autoscaler report to achieve faster autoscaling capabilities.

After applying their autoscaling rules to the cluster, the team noticed a reduction in overall resource usage. However, they found themselves unable to reduce the number of machines in use. The issue arose from the default Kubernetes auto-scheduler, which evenly redistributes Flink jobs following resource scale-ins to maintain overall customer usage. This practice resulted in resource fragmentation.
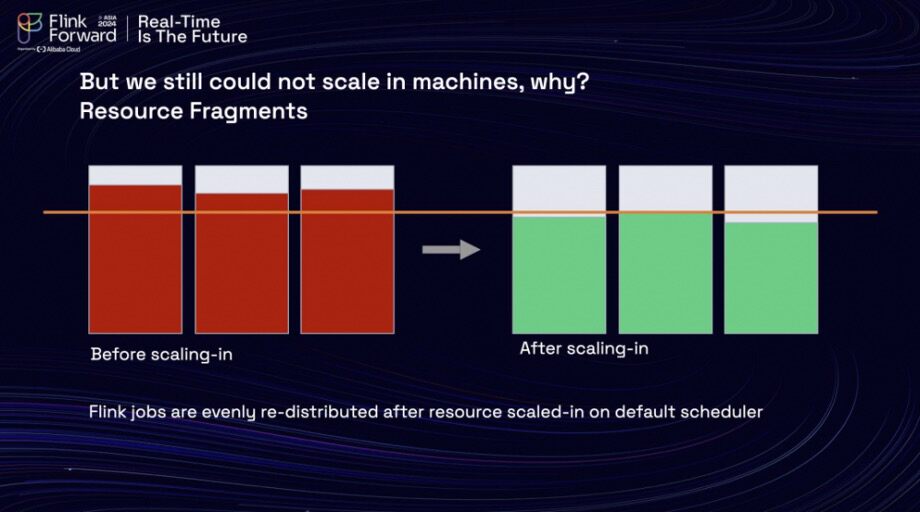
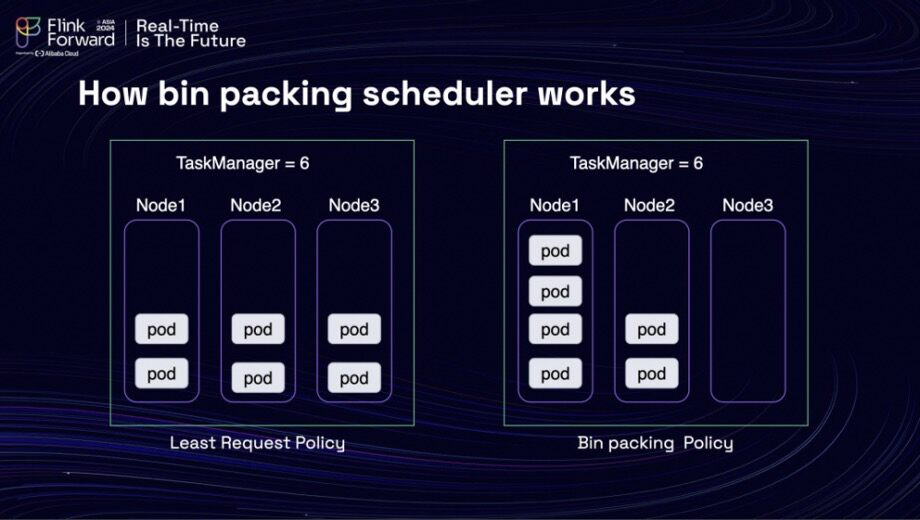
Upon conducting research, the team discovered that a bin packing scheduling strategy could potentially alleviate the situation. The graph on the left illustrated the default behavior of the Kubernetes scheduler under the Least Request Policy, while the graph on the right demonstrated how the Bin-packing Policy could help redeploy pods to higher-utilization nodes, thereby reducing resource fragmentation.
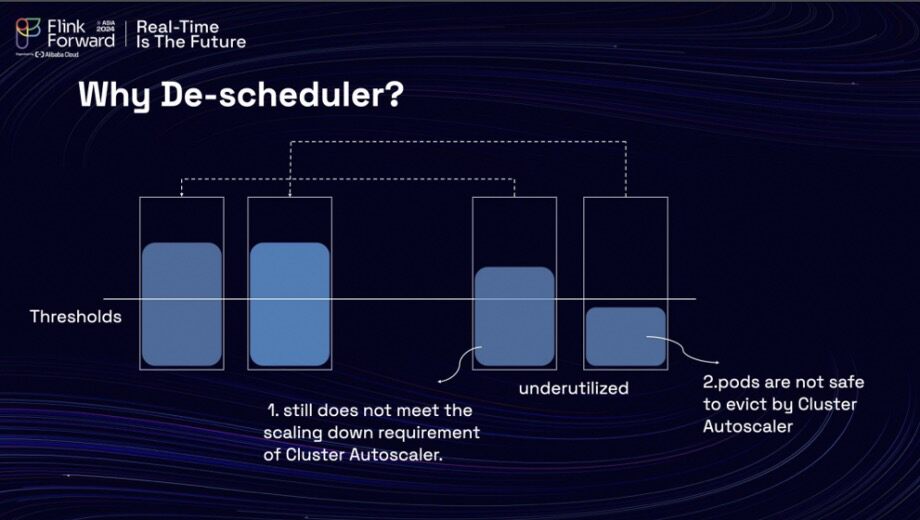
Despite implementing this strategy, the team still could not scale down their machines. The team utilizes Cluster Autoscaler, a Kubernetes tool, to assist in both scaling in and scaling out their machines within the Kubernetes cluster. There are several factors that hinder their ability to scale in these machines effectively. Firstly, not all of the Pods in the cluster can be scaled in, and there are instances where Pods remain on nodes that are under low utilization. As a result, the utilization of these nodes does not meet the necessary criteria for scaling down as defined by Cluster Autoscaler. Additionally, the replica set of the task manager is set to 0, which prevents eviction by the Cluster Autoscaler. Consequently, it is imperative for the scheduled autoscaler to safely evict the Pods from the low-utilization nodes.
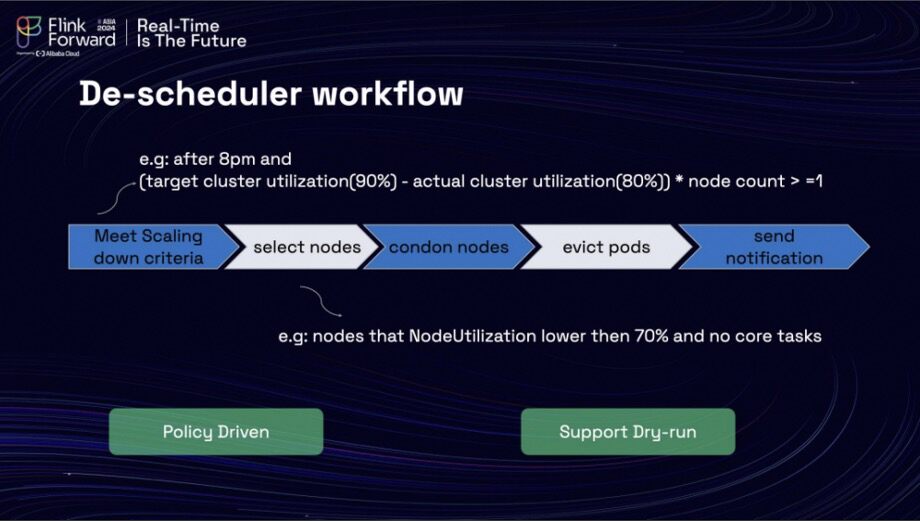
The workflow of the scheduled autoscaler is as follows. Initially, it monitors whether the cluster has met the criteria for scaling down. For instance, it checks if the time is after 8 PM and if the cluster usage is below 90%. Following this, it identifies the nodes with low utilization and marks them as unready and unschedulable, ensuring that no Pods are rescheduled to these nodes once they are evicted. After the Pods are successfully evicted from the nodes, the job manager identifies the eviction and restores the task from the last successful checkpoint, ensuring a safe recovery process. The schedulers then continue to monitor the nodes and the cluster, sending notifications once a node has been scaled down by the scheduler and the Cluster Autoscaler.
Thanks to the work that had been done previously, significant achievements were noted. Firstly, 100% of the tasks were successfully migrated to the new cluster with minimal manual intervention. Secondly, more than 15% of the machines experienced scaling during non-peak hours. Lastly, the overall platform demonstrated increased stability compared to before, resulting in a reduced need for manual maintenance.

In the journey toward enhancing their data infrastructure, Lalamove recently began exploring a new direction centered around Apache Paimon. The company’s previous data warehouse infrastructure comprised several layers, forming a multilayered architecture designed to optimize data handling. At the foundation, the Operational Data Store (ODS) layer played a crucial role in consuming various database elements, showcasing a variety of tables that capture attributes and events. Above the ODS layer, the detail layer (DWD) processed and joined changes from the ODS, while the Data Warehouse Base (DWB) layer built upon this detail layer. The final data mart layer generated vital metrics that were subsequently directed to data applications such as MySQL, HBase, and Doris.
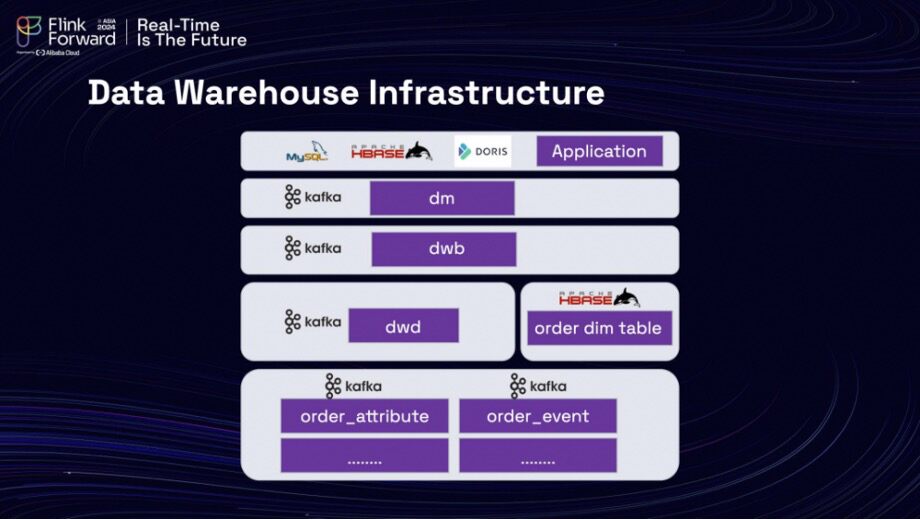
A typical scenario within this data warehousing framework involves managing tables such as 'order' and 'order_freight.' These tables produce database changes that are streamed downstream as binlog changes. To effectively integrate this data, the team employs a streaming join that allows for real-time data processing. Additionally, there is a table known as 'order_attribute',which functions as a key-value table that must be synchronized with Hbase. To create a cohesive dataset for the detailed layer (DWD), the team executes a task that requires combining this data through a lookup join. This dual-join process—streaming join and lookup join—presents significant challenges that the team actively works to overcome.

In the request to enhance their data pipeline, the team understood the necessity of implementing in-memory caching for their lookup joins. This approach aimed to minimize frequent requests to HBase. However, an ongoing streaming job was concurrently writing data to HBase, resulting in a lack of synchronization between the in-memory cache and HBase. This inconsistency inevitably led to latency issues, complicating their data processing efforts.

Additionally, the complexities of streaming joins presented their own set of challenges. In a typical scenario, both tables involved in the join required the maintenance of state in memory. For instance, when joining two tables, Apache Flink would store intermediate results in memory, causing the state to balloon over time and consume significant resources. This demand for memory became increasingly problematic, especially as the data grew.
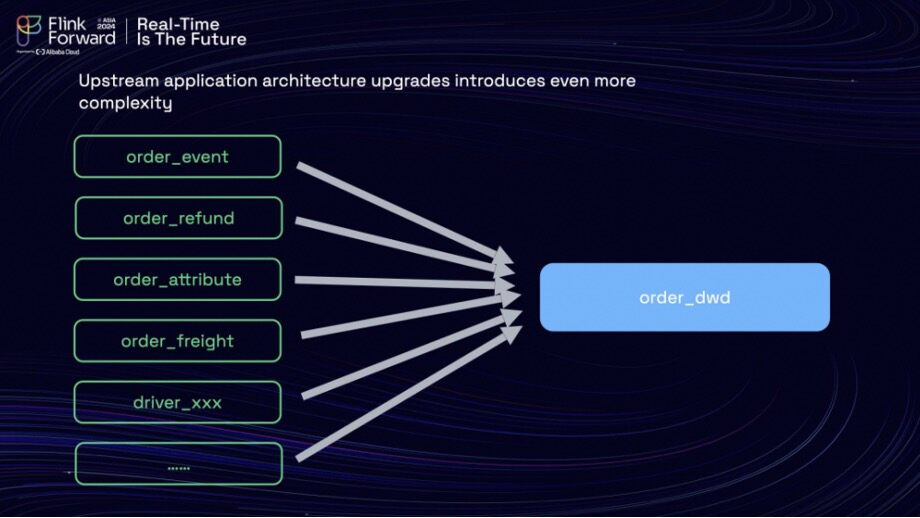
To compound matters, architectural upgrades in upstream applications introduced even more tables requiring integration into their detailed data layer. This escalation made the data pipeline increasingly complex, prompting the team to explore new solutions in search of efficiency. Their investigation led them to choose Apache Paimon as a potential remedy.
Apache Paimon presented several compelling advantages. Firstly, it supports flexible merge functions, including partial updates, which can effectively replace traditional joins and simplify the data pipeline. Secondly, it accommodates both batch and streaming read/write operations, offering versatility that the team needed. Lastly, Paimon includes a changelog producer, enabling computations on incrementally updated datasets. This capability significantly reduced overall computation costs, marking a promising step forward in optimizing their data management strategies.

In addressing the joint problem, the team resolved the issue by replacing traditional joins with partial updates. They established a table with the order ID as the primary key, allowing several additional tables to partially update the columns they produced. Once each stream was updated, they would output the downstream data accordingly. This approach minimized data inconsistency and latency. Paimon also utilized the Log-Structured Merge-tree (LSM) data structure and compaction processes to merge data, creating a changelog for the downstream outputs.

To ensure stability during the transition from their current data warehouse infrastructure to a data lake infrastructure, the team implemented a series of migration steps. The first step involved replacing the detailed layer, moving from Kafka to Paimon, while several tables from the (ODS were partially updated to the DWD layer. Another task was set up to consume from the detailed DWD Paimon table, extracting the changelog and producing it to Kafka. This method allowed downstream layers to continue querying from Kafka, effectively reducing migration costs.

The next phase entailed migrating all layers, including both detailed and base layers, to Paimon. This dual-layer strategy facilitated both batch and streaming processes within the DWB and DWD layers.

Recognizing the challenges associated with Kafka—particularly in terms of queuing historical data and query complexities—the team aimed to leverage Paimon for time travel capabilities. By using Paimon, they sought to enhance stability and observability. They implemented observability measures akin to those used in Kafka, monitoring consumption lag and checkpoints to ensure their data jobs operated smoothly. Additionally, they employed a data lake management tool named Amoro to visualize files and check for issues related to small files. Paimon provided numerous system tables, enabling the team to extract crucial metadata regarding timestamps, snapshots, tags, branches, as well as consumer ID management and lifecycle management.


The transition to a data lake marks just the beginning of the team's journey. They envision a promising roadmap for the future. On the Cloud-native front, they plan to explore more scheduler frameworks, such as Yunikorn, or Volcano, to implement diverse scheduling strategies. Furthermore, they intend to leverage large language models to assist in identifying problems during maintenance. For instance, when users lack comprehensive knowledge about Flink, these models could help pinpoint the root causes of issues and offer suggestions for task optimization. From a data lake perspective, they aim to delve deeper into Paimon's functionalities, including merge functions, aggregations, and indexes, expanding its usability across various scenarios. Ultimately, the team aspires to unify batch and stream processing, lowering both development and computational costs. This comprehensive approach represents their commitment to enhancing data management while paving the way for future innovations.

207 posts | 58 followers
FollowPM - C2C_Yuan - August 3, 2022
Alibaba Cloud Big Data and AI - April 15, 2026
Alibaba Cloud Community - October 8, 2023
Alibaba Cloud Community - June 14, 2024
Apache Flink Community - February 24, 2025
Alibaba Cloud Community - October 30, 2023
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Message Queue for Apache Kafka
Message Queue for Apache Kafka
A fully-managed Apache Kafka service to help you quickly build data pipelines for your big data analytics.
Learn More ApsaraMQ for RocketMQ
ApsaraMQ for RocketMQ
ApsaraMQ for RocketMQ is a distributed message queue service that supports reliable message-based asynchronous communication among microservices, distributed systems, and serverless applications.
Learn More ApsaraDB for SelectDB
ApsaraDB for SelectDB
A cloud-native real-time data warehouse based on Apache Doris, providing high-performance and easy-to-use data analysis services.
Learn MoreMore Posts by Apache Flink Community

