Saat sebuah instance Elastic Compute Service (ECS) mulai berjalan, sistem operasi instance mungkin gagal memulai karena kesalahan konfigurasi atau shutdown yang tidak terduga. Topik ini menjelaskan cara menyelesaikan masalah tersebut berdasarkan pengecualian startup yang Anda temukan setelah menggunakan Virtual Network Computing (VNC) untuk terhubung ke instance atau berdasarkan laporan yang dikembalikan oleh fitur diagnostik kesehatan.
Windows
1662001135: Sistem operasi Windows masuk ke Lingkungan Pemulihan Windows karena pengecualian
Deskripsi Masalah
Sebuah instance Windows berjalan normal selama periode waktu yang lama sebelum direstart. Namun, sistem operasi instance gagal memulai. Saat menggunakan VNC untuk terhubung ke instance, jendela System Recovery Options akan ditampilkan.
Penyebab
Jendela System Recovery Options menunjukkan bahwa sistem operasi Windows masuk ke Lingkungan Pemulihan Windows (WinRE) akibat pengecualian. Masalah ini dapat disebabkan oleh faktor-faktor berikut:
Kerusakan registri, masalah disk, masalah driver, kerusakan atau kehilangan file sistem, atau kerusakan file Boot Configuration Data (BCD).
Kesalahan operasi, virus, perangkat lunak antivirus pihak ketiga, atau restart paksa yang tidak terduga.
Solusi
Gunakan solusi yang disediakan oleh dukungan teknis Microsoft. Untuk informasi lebih lanjut, lihat Cara Kerja Windows RE.
Untuk mencegah instance masuk ke antarmuka pemulihan sistem setelah restart dan memastikan bahwa sistem dapat pulih dari kegagalan, lakukan operasi harian berikut:
Simpan data penting pada disk data.
Buat snapshot secara berkala untuk disk sistem dan disk data instance. Jika terjadi masalah, Anda dapat menggunakan snapshot untuk memulihkan data.
Cadangkan file registri sebelum Anda memodifikasi kunci registri sistem untuk mencegah upaya merusak file sistem.
Jalankan Windows Update secara berkala untuk memastikan bahwa pembaruan keamanan terbaru dari Microsoft diinstal pada instance.
Beli edisi Pusat Keamanan atau gunakan alat antivirus komersial lainnya di ECS untuk menghapus virus serta memperbarui versi perangkat lunak antivirus secara berkala.
1662001136: Penyimpangan terjadi pada sistem file sistem operasi Windows
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance ECS, pesan kesalahan Checking file system on, CHKDSK is verifying files, atau CHKDSK is verifying indexes akan ditampilkan.
Penyebab
Masalah ini dapat terjadi karena penyebab berikut:
Instance ECS dimatikan secara tidak terduga.
Sistem internal Windows rusak.
Solusi
Solusi 1: Pulihkan disk sistem dari snapshot
Gunakan snapshot untuk memulihkan data dan konfigurasi disk sistem. Ikuti langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah rollback disk dilakukan, data yang ditambahkan, dihapus, atau dimodifikasi sejak pembuatan snapshot hingga waktu rollback akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot sebagai cadangan sebelum melakukan rollback disk. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Buka Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya dari sumber daya yang ingin dikelola.

Pada tab Disk Snapshots, temukan snapshot yang akan digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
Solusi 2: Reset disk sistem
Reset disk sistem untuk menangani pengecualian sistem. Ikuti langkah-langkah berikut.
Operasi reset akan membersihkan data dari disk. Disarankan untuk membuat snapshot guna mencadangkan data sebelum melakukan operasi reset. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Hentikan instance ECS.
Buka Konsol ECS - Instance.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya dari sumber daya yang ingin dikelola.
Klik instance target untuk masuk ke halaman detailnya. Klik All Actions untuk membuka panel tindakan. Kemudian, cari dan klik Stop.
Inisialisasi ulang disk sistem.
Temukan instance yang ingin diinisialisasi ulang disk sistemnya. Klik All Actions untuk membuka panel tindakan. Lalu, cari dan klik Reinitialize Disk.
Di kotak dialog Reinitialize Disk yang muncul, konfigurasikan parameter yang diperlukan.
Klik OK.
Instance akan mulai secara otomatis setelah inisialisasi ulang selesai.
1662001137: Sistem operasi Windows mengalami kesalahan internal
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance, salah satu pesan kesalahan berikut akan ditampilkan: An internal error has occurred atau The system cannot find the file specified.
Penyebab
Sistem operasi Windows rusak, yang menyebabkan sistem gagal memulai.
Solusi
Anda dapat mencoba me-restart instance untuk memperbaiki kesalahan. Jika kesalahan tetap ada, pulihkan atau reset disk sistem.
Solusi 1: Restart instance
Restart instance untuk memperbaiki kesalahan sistem dengan mengikuti langkah-langkah berikut.
Buka halaman Instances di konsol ECS. Di pojok kiri atas halaman, pilih grup sumber daya target dan wilayah yang diinginkan.
Klik ID instance target untuk membuka halaman detailnya. Di pojok kanan atas, klik Restart.
Di kotak dialog yang muncul, pilih mode restart.
Normal Restart (default): Sistem operasi mencoba menutup semua proses secara normal sebelum restart.
Pilih Force Restart. Opsi ini setara dengan operasi mematikan daya dan berisiko menyebabkan kehilangan data dari memori serta korupsi sistem file. Gunakan opsi ini hanya jika instance tidak merespons restart normal.
Klik OK.
Solusi 2: Pulihkan disk sistem dari snapshot
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback disk, data yang ditambahkan, dihapus, atau dimodifikasi dari titik waktu snapshot hingga titik waktu rollback akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot sebagai cadangan sebelum melakukan rollback disk. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
Solusi 3: Reset disk sistem
Reset disk sistem untuk menghapus pengecualian sistem. Lakukan langkah-langkah berikut:
Operasi reset akan membersihkan data dari disk. Sebelum melakukan operasi reset, disarankan untuk membuat snapshot sebagai cadangan data. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Hentikan instance ECS.
Buka Konsol ECS - Instance.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Klik instance target untuk masuk ke halaman detailnya. Klik All Actions guna membuka panel tindakan. Selanjutnya, cari dan klik Stop.
Inisialisasi ulang disk sistem.
Temukan instance yang ingin Anda inisialisasi ulang disk sistemnya. Klik All Actions untuk membuka panel tindakan, lalu cari dan klik Reinitialize Disk.
Di kotak dialog Reinitialize Disk yang muncul, konfigurasikan parameter-parameter yang diperlukan.
Klik OK.
Instance akan mulai secara otomatis setelah inisialisasi ulang selesai.
1662001138: File BCD Windows hilang atau rusak
Deskripsi Masalah
Saat menggunakan koneksi VNC untuk masuk ke instance, pesan kesalahan An error occurred while attempting to read the boot configuration data akan ditampilkan.
Penyebab
File BCD Windows hilang atau rusak.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau diubah dari saat snapshot dibuat hingga rollback disk dilakukan akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot disk guna mencadangkan data sebelum melakukan rollback. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1662001139: Sektor boot atau file driver dalam sistem operasi Windows hilang atau rusak
Deskripsi Masalah
Saat menggunakan koneksi VNC untuk masuk ke instance, layar biru akan muncul dengan pesan kesalahan INACCESSIBLE BOOT DEVICE.
Penyebab
Masalah ini terjadi karena penyebab berikut:
Sektor boot sistem operasi Windows hilang atau rusak.
File driver sistem operasi Windows hilang atau rusak.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau dimodifikasi dari titik waktu snapshot dibuat hingga titik waktu rollback disk dilakukan akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot guna mencadangkan data sebelum melakukan rollback pada disk. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi ECS console - Snapshots.
Di bilah navigasi atas, pilih Wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1662001140: File BOOTMGR sistem operasi Windows hilang atau rusak
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instans, pesan kesalahan BOOTMGR is missing akan ditampilkan.
Penyebab
File BOOTMGR sistem operasi Windows hilang atau rusak.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau dimodifikasi dari titik waktu snapshot hingga titik waktu rollback akan hilang. Untuk mencegah kehilangan data akibat perubahan, disarankan untuk membuat snapshot disk guna mencadangkan data sebelum melakukan rollback. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi ECS console - Snapshots.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1662001141: File sistem operasi Windows hilang atau rusak
Deskripsi Masalah
Saat menggunakan VNC untuk menyambungkan ke Instans, pesan kesalahan Missing operating system akan ditampilkan.
Penyebab
File BOOTMGR dari sistem operasi Windows hilang atau rusak.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback disk, data yang ditambahkan, dihapus, atau dimodifikasi dari titik waktu snapshot hingga titik waktu rollback akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot sebagai cadangan sebelum melakukan rollback disk. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1662001142: File registri sistem operasi Windows rusak atau hilang
Deskripsi masalah
Saat menggunakan koneksi VNC untuk masuk ke instans, sistem operasi Windows gagal memulai dan menampilkan pesan kesalahan Windows Failed To Start. A Recent Hardware Or Software Change Might Be The Cause.
Penyebab
Masalah ini dapat terjadi karena registri sistem Windows hilang atau rusak, yang mencegah sistem untuk dimuat.
Solusi
Gunakan Snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau dimodifikasi dari titik waktu pembuatan Snapshot hingga titik waktu rollback akan hilang. Untuk mencegah kehilangan data akibat perubahan, disarankan untuk membuat Snapshot guna mencadangkan data sebelum melakukan rollback disk. Untuk informasi lebih lanjut, lihat Create a snapshot for a disk.
Kunjungi ECS console - Snapshots.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1662001151: Terjadi kesalahan inisialisasi karena operasi Sysprep yang tidak lengkap di sistem operasi Windows
Deskripsi masalah
Instance ECS tiba-tiba restart atau mengalami kesalahan. Saat menggunakan koneksi VNC untuk masuk ke instance, pesan kesalahan Windows Could Not Complete The Installation akan ditampilkan.
Penyebab
Operasi Sysprep tidak lengkap saat dilakukan upaya untuk me-restart instance.
Solusi
Operasi reset akan membersihkan data dari disk. Sebelum melakukan operasi reset, disarankan untuk membuat snapshot sebagai cadangan data. Untuk informasi lebih lanjut, lihat Buat snapshot untuk sebuah disk.
Hentikan instance ECS.
Buka ECS console - Instance.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Klik instance target untuk membuka halaman detailnya. Klik All Actions guna membuka panel aksi. Selanjutnya, cari dan klik Stop.
Re-inisialisasi disk sistem.
Temukan instance yang disk sistemnya ingin Anda re-inisialisasi. Klik All Actions untuk membuka panel aksi, lalu cari dan klik Reinitialize Disk.
Di kotak dialog Reinitialize Disk yang muncul, konfigurasikan parameter-parameter yang diperlukan.
Klik OK.
Instance akan mulai secara otomatis setelah re-inisialisasi selesai.
1671696280: Sistem Windows gagal memulai karena konfigurasi BCD abnormal atau kegagalan sistem file disk
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance, sistem Windows gagal memulai dan menampilkan pesan kesalahan Windows failed to start. A recent hardware or software change might be the cause.. Nilai Status adalah 0xc0000001.
Penyebab
Masalah ini dapat terjadi karena konfigurasi Boot Configuration Data (BCD) Windows tidak normal atau sistem file disk gagal, yang mencegah sistem memuat.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau dimodifikasi dari waktu snapshot dibuat hingga waktu rollback disk dilakukan akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot disk sebagai cadangan sebelum melakukan rollback. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1671696281: File sistem Windows rusak atau driver tidak kompatibel
Deskripsi Masalah
Saat menggunakan koneksi VNC untuk masuk ke instance, sistem Windows gagal memulai dan antarmuka startup macet di layar Choose Your Keyboard Layout.
Penyebab
File sistem Windows rusak atau driver tidak kompatibel.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau diubah dari waktu snapshot dibuat hingga saat rollback dilakukan akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot sebagai cadangan data sebelum melakukan rollback pada disk. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1671696282: Sistem Windows gagal memulai karena kegagalan disk sistem atau perubahan perangkat keras
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance, layar macet di halaman Windows Error Recovery.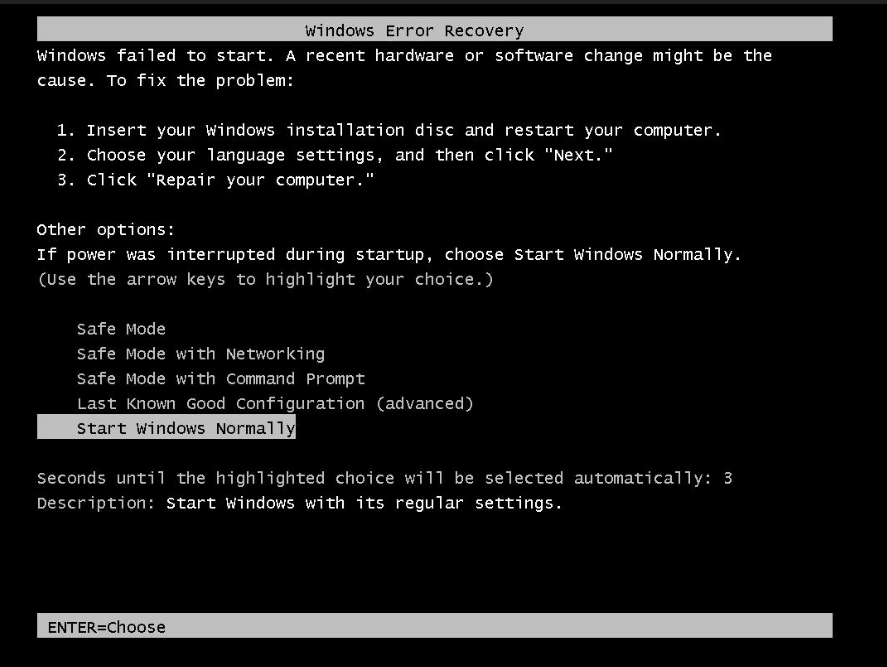
Penyebab
Masalah ini dapat terjadi karena disk sistem Windows gagal atau perangkat keras telah berubah, yang mencegah sistem memulai.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau diubah dari titik waktu pembuatan Snapshot hingga saat rollback akan hilang. Untuk mencegah kehilangan data akibat modifikasi, kami sarankan Anda membuat Snapshot untuk mencadangkan data sebelum melakukan rollback pada disk. Untuk informasi lebih lanjut, lihat Buat Snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1671696284: Sistem operasi Windows tidak dapat menemukan perangkat bootable
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke Instans, pesan kesalahan berikut ditampilkan: An operating system wasn't found. Try disconnecting any drives that don't contain an operating system.
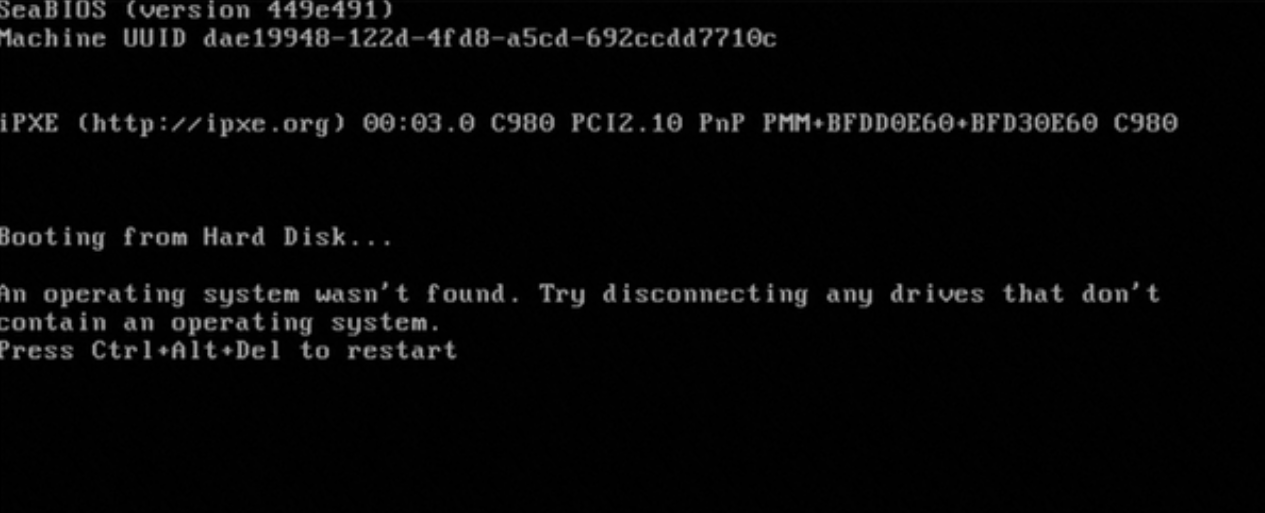
Penyebab
Sistem operasi Windows tidak dapat menemukan perangkat yang dapat digunakan oleh driver untuk boot sistem.
Solusi
Gunakan snapshot untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau dimodifikasi antara waktu pembuatan snapshot dan waktu rollback disk akan hilang. Untuk mencegah kehilangan data akibat modifikasi, kami menyarankan Anda membuat snapshot untuk disk guna mencadangkan data sebelum melakukan rollback. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
1706506808: Sistem operasi Windows tidak dapat menemukan disk boot
Deskripsi Masalah
Instance ECS yang menjalankan sistem operasi Windows tidak dapat dimulai, dan pesan kesalahan "tidak ada perangkat bootable" muncul.
Jika sistem operasi gagal memulai, Anda hanya dapat menggunakan VNC untuk terhubung ke instance.

Penyebab
Anda dapat menggunakan fitur diagnostik kesehatan instance untuk mengidentifikasi penyebab masalah. Untuk informasi lebih lanjut tentang cara menggunakan fitur ini, lihat Memperbaiki kegagalan startup sistem operasi pada instance.
Solusi
Pilih solusi spesifik berdasarkan laporan yang dihasilkan oleh fitur diagnostik kesehatan instance. Untuk informasi lebih lanjut, lihat Apa yang harus saya lakukan jika pesan kesalahan "tidak ada perangkat bootable" muncul saat memulai instance Windows?
1706506809: Sistem operasi Windows tiba-tiba mogok
Deskripsi Masalah
Kesalahan dapat terjadi pada instance ECS yang menjalankan sistem operasi Windows, seperti kernel panic, out of memory (OOM), atau blue screen freeze.
Penyebab
Downtime pada instance ECS disebabkan oleh berbagai faktor, termasuk crash proses layanan inti sistem, akses ilegal ke memori oleh kernel atau driver, atau korupsi struktur data kernel.
Solusi
Untuk mengidentifikasi penyebab dan menyelesaikan masalah, gunakan alat diagnostik mandiri atau analisis peristiwa sistem. Untuk informasi lebih lanjut, lihat Memecahkan masalah downtime instance Windows.
1706506811: Sistem operasi dalam mode pemilihan boot
Deskripsi Masalah
Saat instance Windows dijalankan, sistem operasi gagal dimuat dan masuk ke mode Repair. Pesan "Preparing Automatic Repair" ditampilkan.
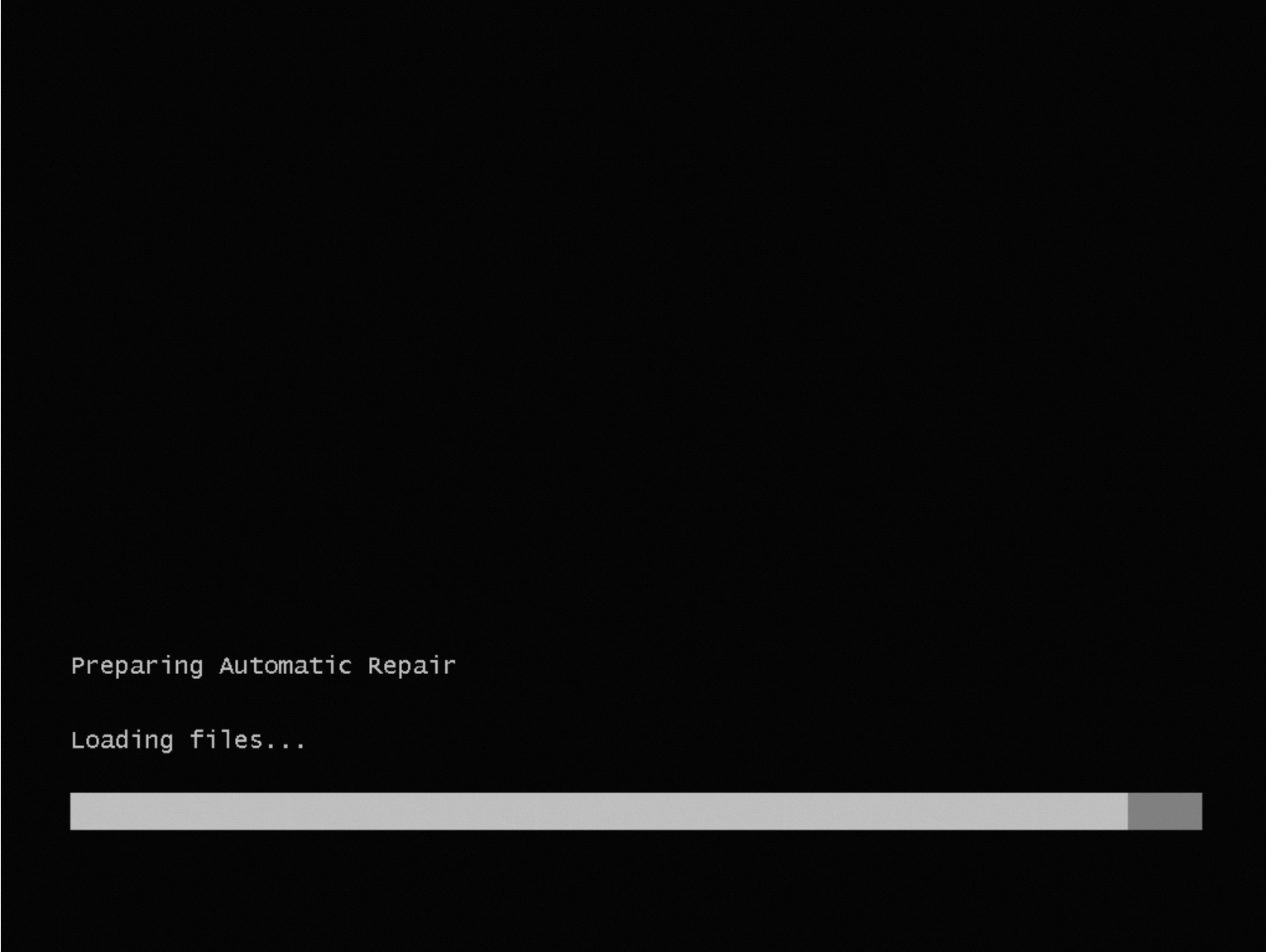
Penyebab
Gunakan fitur diagnostik kesehatan instance untuk mengidentifikasi penyebab masalah ini. Untuk panduan penggunaan fitur tersebut, lihat Memperbaiki kegagalan startup sistem operasi pada instance.
Solusi
Pilih solusi yang sesuai berdasarkan laporan dari fitur diagnostik kesehatan instance. Informasi lebih lanjut dapat ditemukan di Apa yang harus saya lakukan jika sistem operasi masuk ke mode Preparing Automatic Repair saat saya memulai instance Windows?.
1706506813: File registri sistem operasi Windows rusak
Deskripsi Masalah
Saat instance Windows dijalankan, pesan kesalahan berikut muncul: "Windows gagal memulai. Perubahan perangkat keras atau perangkat lunak baru-baru ini mungkin menjadi penyebabnya."
Penyebab
File registri utama instance tidak tersedia atau mengalami kerusakan, sehingga sistem operasi tidak dapat dimulai.
Solusi
Masuk ke mode Repair atau perbaiki file registri yang rusak pada instance. Untuk detail lebih lanjut, lihat bagian Perbaiki file registri yang rusak dalam topik "Apa yang harus saya lakukan jika sistem operasi masuk ke mode Preparing Automatic Repair saat saya memulai instance Windows?".
1706506814: File sistem penting dari sistem operasi Windows rusak
Deskripsi Masalah
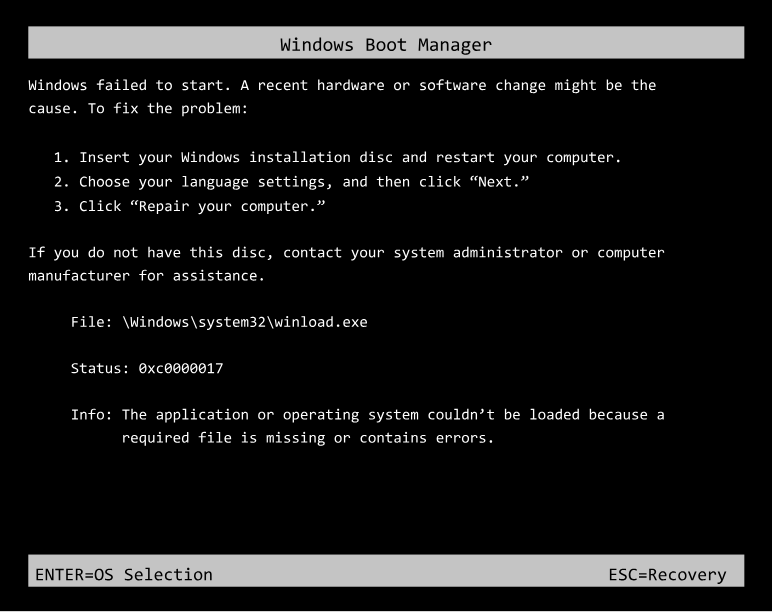
Penyebab
Penyebab utama adalah terjadinya pengecualian pada komponen inti Windows. Masalah ini dapat disebabkan oleh hal-hal berikut:
Citra yang dibangun dari versi Preview telah kedaluwarsa.
Kerusakan file sistem: File sistem dihapus atau kontennya rusak, sehingga mencegah sistem untuk memulai.
Solusi
Citra kedaluwarsa yang dibuat dari versi Public Preview: Jika instance ECS Anda menggunakan citra kustom yang dibuat dari versi Public Preview, Anda perlu membangun ulang citra tersebut. Untuk informasi lebih lanjut, lihat Praktik Terbaik untuk Image Builder.
Jika file sistem rusak atau dihapus, Anda dapat memperbaiki atau memulihkan file sistem. Untuk detail lebih lanjut, lihat Apa yang harus saya lakukan jika pesan kesalahan 0xc0000017 muncul saat saya masuk ke instance Windows menggunakan VNC?
1706506815: Sistem operasi Windows tidak dapat mengenali tanda tangan digital
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance Windows, muncul pesan kesalahan "Status: 0xc0000428".
Penyebab
Sistem operasi pada instance Windows tidak dapat mengenali tanda tangan SHA256 yang digunakan oleh driver viostor.sys, sehingga mencegah instance memulai dengan sukses.
Solusi
Secara sementara, nonaktifkan mode Driver Signature Enforcement untuk masuk ke sistem Windows. Selanjutnya, instal patch KB3033929 di instance Windows guna mendukung algoritma SHA256. Langkah ini memastikan bahwa sistem dapat mengenali tanda tangan SHA256 yang digunakan oleh driver viostor.sys. Untuk informasi lebih lanjut, lihat Apa yang harus saya lakukan jika kesalahan "Status: 0xc0000428" terjadi saat saya menggunakan VNC untuk masuk ke instance Windows?
1706506816: Ketidaksesuaian mode boot gambar terjadi
Deskripsi Masalah
Saat instance ECS dijalankan, sistem operasi internal instance gagal memulai. Saat Anda terhubung ke instance menggunakan VNC, halaman EFI Shell ditampilkan.
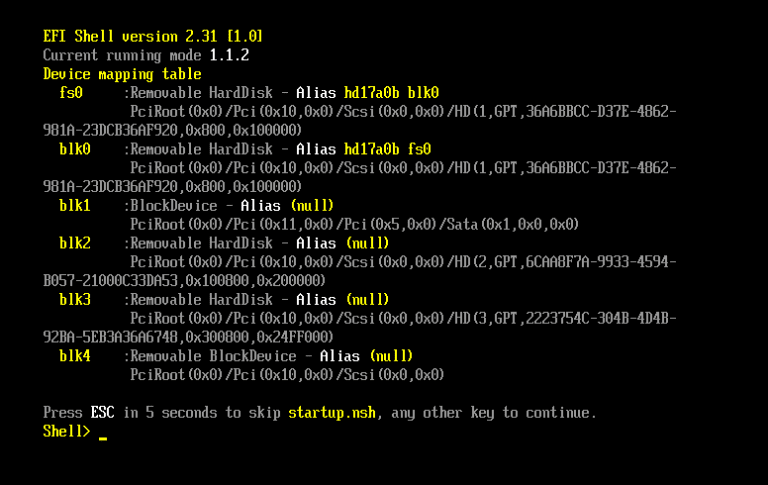
Penyebab
Jika halaman EFI Shell muncul, instance ECS gagal memulai dalam mode UEFI. Masalah ini dapat disebabkan oleh faktor-faktor berikut:
Gambar instance tidak mendukung UEFI, tetapi mode boot gambar telah diubah ke UEFI. Hal ini dapat terjadi saat menjalankan instance ECS yang dibuat dari gambar kustom.
Gambar instance mendukung UEFI, namun firmware UEFI internal pada gambar mengalami kerusakan.
Solusi
Ubah mode boot gambar ke mode lain atau perbaiki firmware UEFI. Untuk informasi lebih lanjut, lihat Apa yang harus saya lakukan jika sistem operasi internal instance Linux ECS gagal memulai dan pesan kesalahan "UEFI Interactive Shell" muncul?
Linux
1662001143: Boot GRUB gagal dalam sistem operasi Linux
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance, prompt grub> atau grub rescue> akan ditampilkan. Hal ini menunjukkan bahwa terjadi kesalahan selama proses startup sistem operasi Linux.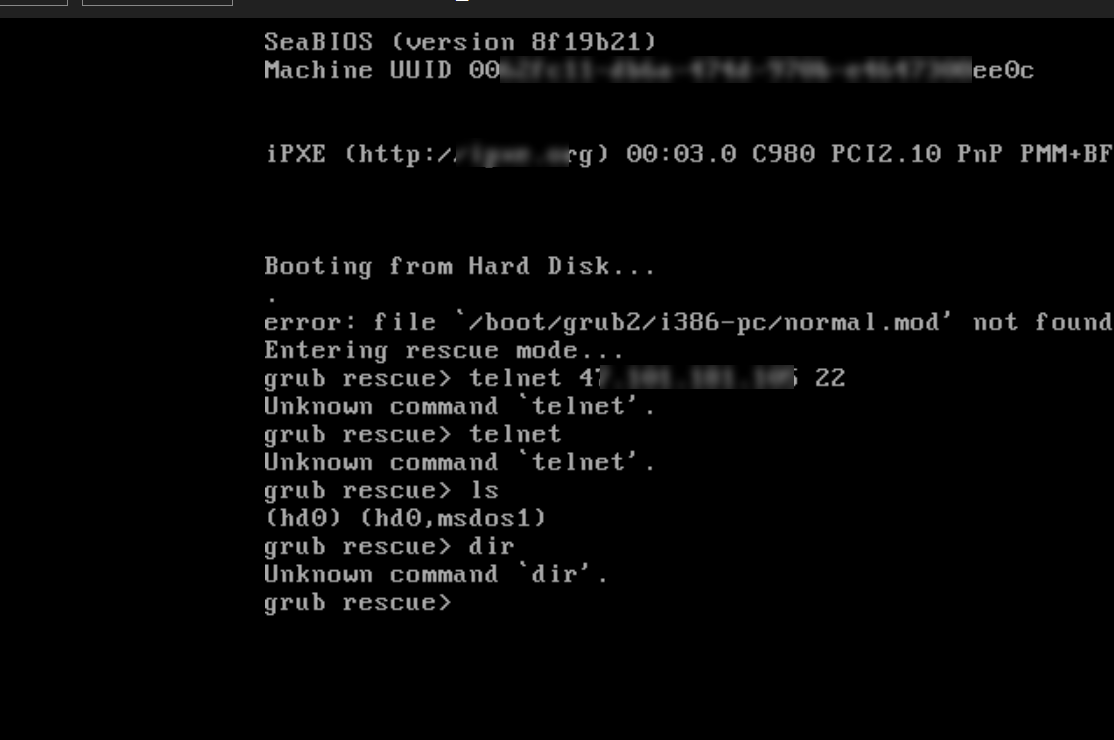
Penyebab
GRand Unified Bootloader (GRUB) boot gagal.
Masalah ini dapat terjadi karena penyebab berikut:
Beberapa file komponen GRUB hilang, seperti file /boot/grub2/grub.cfg.
Konfigurasi GRUB2 salah atau bootloader GRUB2 pada disk rusak.
Jika antarmuka VNC menampilkan pesan serupa
/boot/grub2/i386-pc/normal.mod notfound., hal ini menunjukkan bahwa modul dependensi utama untuk GRUB2 tidak ditemukan.Jika antarmuka VNC menampilkan pesan serupa
error: no such partition, hal ini menunjukkan bahwa GRUB2 tidak dapat mengenali partisi yang sesuai.Jika antarmuka VNC menampilkan pesan serupa
error: unknown filesystem, hal ini menunjukkan bahwa GRUB2 tidak dapat mengenali jenis sistem file pada partisi tersebut.
Solusi
Solusi 1: Perbaiki disk data pada instance ECS yang abnormal
Lepaskan disk sistem dari instance ECS yang bermasalah dan pasang disk sebagai disk data ke instance ECS yang sehat.
Untuk informasi lebih lanjut, lihat Langkah 1 hingga Langkah 2 di Praktik Terbaik untuk Pemulihan Data pada Instance Linux.
CatatanSetelah langkah ini selesai, jika Anda belum keluar dari lingkungan chroot, jalankan perintah
exitpada instance Elastic Compute Service (ECS) yang sehat untuk keluar darinya.Gunakan salah satu metode berikut untuk memperbaiki disk sistem:
Metode 1: Jika modul dependensi utama untuk GRUB2 hilang atau informasi GRUB2 pada disk rusak, jalankan perintah
grub2-install /dev/vdbdalam lingkungan chroot untuk menginstal ulang GRUB2 dan memperbaiki masalah. Ikuti langkah-langkah berikut:Temukan nama perangkat di OS untuk disk sistem yang bermasalah setelah disk dipasang menggunakan nomor seri disk.
Untuk informasi lebih lanjut, lihat Kueri nomor seri disk. Pada contoh ini, disk bernama /dev/vdb digunakan.
Masuk ke instance sehat, beralih ke pengguna root, dan jalankan perintah berikut secara berurutan untuk masuk ke direktori mount instance sehat. Dalam contoh ini, /mnt digunakan.
mount -o bind /proc/ /mnt/proc/ mount -o bind /sys/ /mnt/sys/ mount -o bind /dev/ /mnt/dev/ chroot /mntMasuk ke instance sehat, beralih ke pengguna root, dan jalankan perintah berikut untuk beralih ke direktori mount. Dalam contoh ini, direktori mount adalah /mnt.
Jalankan perintah
grub2-install /dev/vdbuntuk menginstal ulang GRUB pada disk sistem.Pada instance ECS yang sehat, jalankan perintah
exituntuk keluar dari lingkungan chroot.
Metode 2: Inisialisasi ulang disk sistem melalui konsol ECS. Untuk informasi lebih lanjut, lihat Inisialisasi Ulang Disk Sistem.
PeringatanSaat disk sistem diinisialisasi ulang, semua data yang tersimpan di disk akan dihapus. Kami menyarankan Anda untuk membuat Snapshot guna mencadangkan data terlebih dahulu. Untuk informasi lebih lanjut tentang cara membuat Snapshot, lihat Buat Snapshot untuk Disk.
Pasang kembali disk sistem ke instance ECS yang bermasalah.
Untuk informasi lebih lanjut, lihat Langkah 3 di Praktik Terbaik untuk Pemulihan Data pada Instance Linux.
Gunakan SSH atau VNC untuk masuk ke instance ECS yang telah diperbaiki. Kemudian, periksa apakah instance ECS berjalan seperti yang diharapkan.
Solusi 2: Pulihkan disk sistem dari snapshot
Jika boot GRUB2 pada disk sistem masih gagal, Anda dapat melakukan operasi dalam Solusi 2.
Jika Anda memiliki snapshot dari disk sistem, Anda dapat menggunakan snapshot tersebut untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback pada disk, data yang ditambahkan, dihapus, atau diubah sejak snapshot dibuat hingga disk di-rollback akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot guna mencadangkan data sebelum melakukan rollback pada disk. Untuk informasi lebih lanjut, lihat Buat snapshot untuk disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
Solusi 3: Reset disk sistem
Jika disk sistem Anda tidak menyimpan data penting, Anda dapat meresetnya. Lakukan langkah-langkah berikut:
Operasi reset akan membersihkan data dari disk. Sebelum melakukan operasi reset, disarankan untuk membuat snapshot guna mencadangkan data. Untuk informasi lebih lanjut, lihat Buat Snapshot untuk Disk.
Hentikan instance ECS.
Kunjungi Konsol ECS - Instance.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Klik instance target untuk masuk ke halaman detailnya. Klik All Actions guna membuka panel tindakan. Selanjutnya, cari dan klik Stop.
Inisialisasi ulang disk sistem.
Temukan instance yang ingin Anda inisialisasi ulang disk sistemnya. Klik All Actions untuk membuka panel tindakan, lalu cari dan klik Reinitialize Disk.
Di kotak dialog Reinitialize Disk yang muncul, konfigurasikan parameter-parameter yang diperlukan.
Klik OK.
Instance akan mulai secara otomatis setelah inisialisasi ulang selesai.
1662001144: UUID file sistem root salah dalam file konfigurasi GRUB sistem operasi Linux
Deskripsi Masalah
Saat Anda menggunakan VNC untuk terhubung ke instance, log yang ditunjukkan pada gambar berikut ditampilkan di terminal VNC.
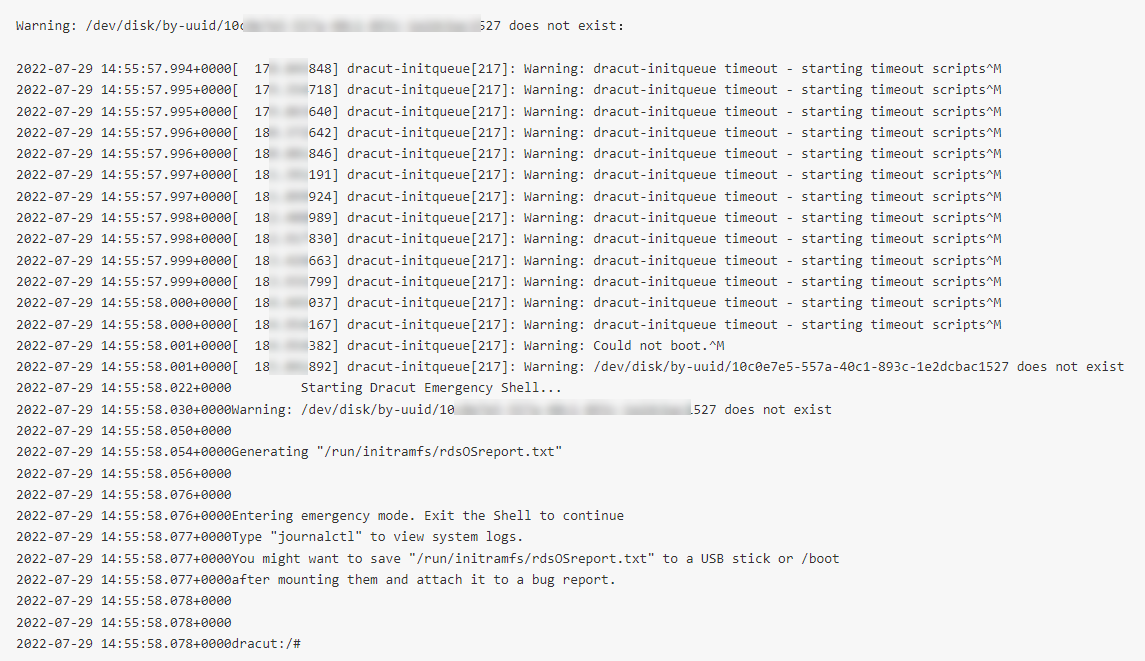
Penyebab
Masalah ini umumnya terjadi ketika UUID perangkat dikonfigurasikan dalam file grub.cfg, tetapi perangkat yang sesuai tidak tersedia.
Sebagai contoh, gambar menunjukkan bahwa perangkat dengan UUID telah dikonfigurasikan menggunakan root=UUID=10c0e7e5-557a-40c1-893c-1e2dcba*****, namun perangkat tersebut tidak tersedia di instance ECS.

Solusi
Lepaskan disk sistem dari instance ECS yang bermasalah dan pasang disk sebagai disk data ke instance ECS yang sehat.
Untuk informasi lebih lanjut, lihat Langkah 1 hingga Langkah 2 dalam Praktik Terbaik untuk Pemulihan Data pada Instans Linux.
Masuk ke instance sehat dan temukan nama perangkat di OS untuk disk sistem yang bermasalah setelah dipasang menggunakan nomor seri disk.
Untuk informasi lebih lanjut, lihat Kueri Nomor Seri Disk. Pada contoh ini, disk dengan nama /dev/vdb digunakan.
Jalankan perintah berikut untuk menanyakan UUID file sistem yang sesuai dengan
/dev/vdb1.blkid /dev/vdb1UUID file sistem dikembalikan.
/dev/vdb1: UUID="10c0e7e5-557a-40c1-893c-1e2dcba*****" TYPE="ext4"Ganti UUID dalam file
grub2.cfgpada disk sistem yang bermasalah dengan nilai UUID yang telah Anda peroleh.Pasang kembali disk sistem ke instance ECS yang bermasalah.
Untuk informasi lebih lanjut, lihat Langkah 3 di Praktik Terbaik Pemulihan Data pada Instans Linux.
Gunakan SSH atau VNC untuk masuk ke instance ECS yang telah diperbaiki. Kemudian, periksa apakah instance ECS berjalan seperti yang diharapkan.
1662001145: Sistem operasi Linux macet saat shutdown
Deskripsi Masalah
Instance ECS tetap berada dalam status Stopping. Saat menggunakan VNC untuk masuk ke instance, pesan kesalahan berikut akan ditampilkan:
CentOS release 5.8(Final)
Kernel 2.6.18-308.el5 on anx 86_64
iZuf6isbofkgfnm5qp***** login: md: stopping allmddevices.
System halted.Penyebab
Sistem macet karena alasan yang tidak diketahui selama shutdown. Anda dapat menganalisis log sistem untuk mendapatkan penyebab utamanya.
Solusi
Restart paksa instance di konsol ECS. Lakukan langkah-langkah berikut:
Jika Anda memaksa restart instance, data yang tersimpan di cache dalam memori mungkin hilang.
Buka halaman Instances di konsol ECS. Di pojok kiri atas halaman, pilih grup sumber daya target dan wilayah yang diinginkan.
Klik ID instance target untuk membuka halaman detailnya. Di pojok kanan atas, klik Restart.
Di kotak dialog yang muncul, pilih mode restart.
Pilih Force Restart. Tindakan ini setara dengan operasi mematikan daya dan berisiko menyebabkan kehilangan data dari memori serta kerusakan pada sistem file. Gunakan opsi ini hanya jika Instans tidak merespons terhadap restart normal.
Klik OK.
1662001146: Linux: Perangkat yang dikonfigurasi untuk titik pemasangan di /etc/fstab tidak ada
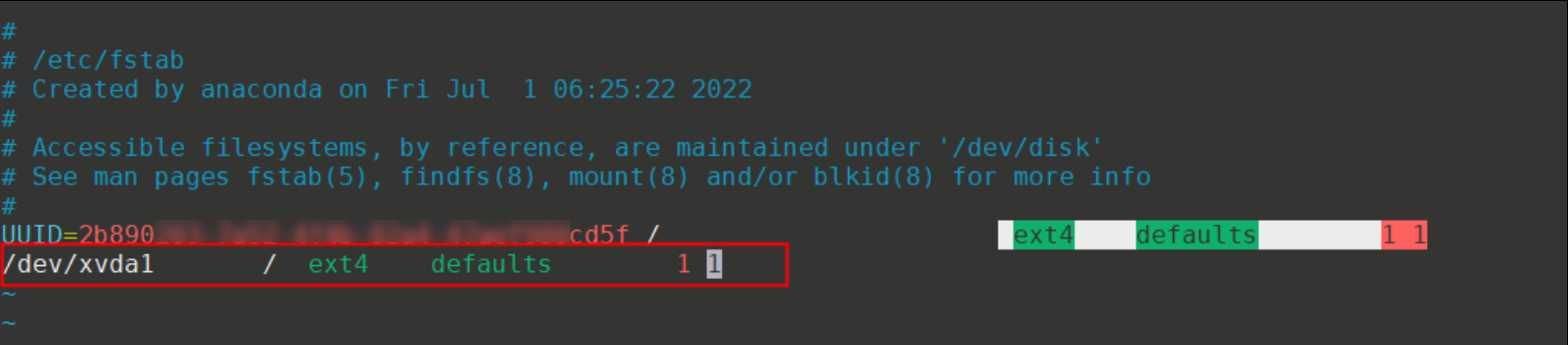
Deskripsi Masalah
Saat menggunakan VNC untuk terhubung ke instance ECS, pesan kesalahan berikut ditampilkan secara berulang: A start job is running.
Booting from 0000:7c00
/: clean, 53966/2621440 files, 648440/10485499 blocks
A start job is running for dev-xvda1.device (5s / 1min 30s)
A start job is running for dev-xvda1.device (6s / 1min 30s)
A start job is running for dev-xvda1.device (7s / 1min 30s)
......Penyebab
Masalah ini dapat terjadi karena titik pemasangan untuk perangkat yang tidak tersedia telah dikonfigurasi di file /etc/fstab pada Instance ECS.
Seperti yang ditunjukkan pada gambar berikut, sistem melaporkan pesan A start job is running for dev-xvda1.device karena perangkat /dev/xvda1 yang dikonfigurasi di file /etc/fstab pada instans tidak tersedia.
Solusi
Tunggu hingga proses deteksi sistem selesai.
Jika output pada gambar berikut ditampilkan, deteksi sistem selesai.
Masukkan kata sandi logon yang berbeda dari kata sandi VNC untuk logon ke sistem operasi.
Jalankan perintah
mount -auntuk menampilkan baris spesifik yang melaporkan kesalahan.Tanggapan berikut menunjukkan bahwa baris 11 dalam file konfigurasi
/etc/fstabmengandung kesalahan.
Jalankan
vim /etc/fstabuntuk mengedit file/etc/fstab.Beri tanda komentar (#) atau hapus baris dalam file
/etc/fstab, ketik:wq, lalu tekanEnteruntuk menyimpan dan keluar.Mulai ulang Instance ECS.
Untuk informasi lebih lanjut, lihat Mulai ulang instans.
Hubungkan ke Instance ECS. Jika pesan kesalahan tidak lagi ditampilkan, masalah telah teratasi.
1662001147: Sistem operasi Linux mogok
Deskripsi Masalah
Sistem operasi internal instance ECS gagal memulai. Setelah menggunakan koneksi VNC untuk masuk ke instance, pesan kesalahan Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block muncul dalam log seperti /var/log/dmesg dan /var/log/messages.
Penyebab
Berbagai masalah, seperti masalah kernel dan masalah bisnis, dapat menyebabkan kesalahan Kernel panic berikut:
Kernel panic - not syncingfatal exception in interruptKernel panic - not syncing: Attempted to kill the idle task!Kernel panic - not syncing: killing interrupt handler!Kernel panic - not syncing: Attempted to kill init!
Solusi
Pilih solusi yang sesuai dengan kebutuhan Anda.
Restart instance ECS
Untuk memulihkan bisnis Anda, Anda dapat memaksa me-restart instance di konsol ECS. Lakukan langkah-langkah berikut:
Jika Anda memaksa me-restart instance, data yang tersimpan di cache dalam memori mungkin hilang.
Buka halaman Instances di konsol ECS. Di pojok kiri atas halaman, pilih grup sumber daya target dan wilayah yang diinginkan.
Klik ID instance target untuk membuka halaman detailnya. Di pojok kanan atas, klik Restart.
Di kotak dialog yang muncul, pilih mode restart.
Pilih Force Restart. Opsi ini setara dengan operasi mematikan daya dan memiliki risiko kehilangan data dari memori serta korupsi sistem file. Gunakan opsi ini hanya jika instance tidak merespons restart normal.
Klik OK.
Aktifkan Layanan Kdump
Kernel panic umumnya disebabkan oleh kegagalan aplikasi atau kernel sistem operasi pada instance ECS. Untuk mengidentifikasi penyebabnya, Anda dapat mengaktifkan layanan Kdump guna mendapatkan file kernel dan menganalisisnya. Informasi lebih lanjut dapat ditemukan di Cara Mengaktifkan Layanan Kdump untuk Instance Linux.
1662001148: File sistem penting hilang dalam sistem operasi Linux
Deskripsi Masalah
Sistem operasi internal instance ECS gagal memulai. Saat menggunakan koneksi VNC untuk masuk ke instance, antarmuka startup menampilkan pesan kesalahan execute/bin/sh, giving up: No such file or directory.
0K] Stopped dracut cmdline hook.
Stopping dracut cmdline hook...
OK] Stopped Create Static Device Nodes in/dev.
Stopping Create Static Device Nodes in/dev...
OK] Stopped Create list of required sta...ce nodes for the current kernel.
Stopping Create list of required st...nodes for the current kernel...
OK]ClOSed udev Control Socket.
OK]ClOSed udev Kernel Socket.
Starting Cleanup udev dDB.
[OK] Started Cleanup udev dDB.
6.573859] system d-journald[106]: Received SIGTERM from PID 1(systemd).
[DK]Reached target Switch Root.
[OK] Started Plymouth switch root service.
Starting Switch Root...
[6.583367] systemd[1]: No /sbin/init, trying fallback
[6.584388] systemd[1]: Failed to execute/bin/sh, giving up: No such file or directory
[892.889761] random: crng init done Penyebab
Masalah ini dapat terjadi jika file /bin/sh atau /bin/bash, atau tautan simboliknya, dihapus dari instance ECS, sehingga menyebabkan instance gagal memulai.
Solusi
Solusi 1: Perbaiki disk data pada instance ECS yang abnormal
Lepaskan disk sistem dari instance ECS yang bermasalah dan pasang disk sebagai disk data ke instance ECS yang sehat.
Untuk informasi lebih lanjut, lihat Langkah 1 hingga Langkah 2 di Praktik Terbaik untuk Pemulihan Data pada Instance Linux.
Pada instance ECS yang sehat, salin file /bin/sh atau /bin/bash ke disk data baru yang merupakan disk sistem dari instance ECS yang bermasalah.
Sebagai contoh, salin file /bin/sh dari instance sehat ke instance ECS yang bermasalah. Ganti parameter 192.168.XXX.XXX dengan alamat IP sebenarnya dari instance ECS yang bermasalah.
scp /bin/sh root@192.168.XXX.XXX:/bin/shSambungkan kembali disk sistem ke instance ECS yang bermasalah.
Untuk informasi lebih lanjut, lihat Langkah 3 di Praktik Terbaik untuk Pemulihan Data pada Instance Linux.
Gunakan SSH atau VNC untuk masuk ke instance ECS yang bermasalah yang telah diperbaiki. Kemudian, periksa apakah instance ECS berjalan sesuai harapan.
Solusi 2: Pulihkan disk sistem dari snapshot
Jika masalah berlanjut, Anda dapat melakukan operasi dalam Solusi 2.
Jika Anda memiliki snapshot dari disk sistem, Anda dapat menggunakan snapshot tersebut untuk memulihkan disk sistem. Lakukan langkah-langkah berikut:
Operasi rollback tidak dapat dibatalkan. Setelah Anda melakukan rollback disk, data yang ditambahkan, dihapus, atau dimodifikasi dari titik waktu snapshot hingga titik waktu rollback akan hilang. Untuk mencegah kehilangan data akibat modifikasi, disarankan untuk membuat snapshot sebagai cadangan sebelum melakukan rollback disk. Untuk informasi lebih lanjut, lihat Buat Snapshot untuk Disk.
Kunjungi Konsol ECS - Snapshot.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
Solusi 3: Reset disk sistem
Jika disk sistem Anda tidak berisi data penting, Anda dapat meresetnya. Lakukan langkah-langkah berikut:
Operasi reset akan membersihkan data dari disk. Sebelum melakukan operasi reset, disarankan untuk membuat snapshot guna mencadangkan data. Untuk informasi lebih lanjut, lihat Buat Snapshot untuk Disk.
Hentikan instance ECS.
Kunjungi Konsol ECS - Instance.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Klik instance target untuk masuk ke halaman detailnya. Klik All Actions guna membuka panel tindakan. Selanjutnya, cari dan klik Stop.
Inisialisasi ulang disk sistem.
Temukan instance yang ingin Anda inisialisasi ulang disk sistemnya. Klik All Actions untuk membuka panel tindakan, lalu cari dan klik Reinitialize Disk.
Di kotak dialog Reinitialize Disk yang muncul, konfigurasikan parameter-parameter yang diperlukan.
Klik OK.
Instance akan mulai secara otomatis setelah inisialisasi ulang selesai.
1662001149: Penyimpangan terjadi dalam sistem file saat utilitas fsck memeriksa sistem file selama startup sistem operasi Linux
Deskripsi Masalah
Sistem operasi macet selama startup. Saat Anda menggunakan VNC untuk terhubung ke instance ECS, pesan kesalahan berikut ditampilkan:
fsck from util-linux 2.20.1
fsck from util-linux 2.20.1
: clean, 193163/ 1310720 files, 2415199/ 5242368 blocks
/dev/vdb: Superblock last write time(Tue Nov 2300:31:582021,
now=WedNov1018:28:552021) is in the future.
/dev/vdb: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY.
(i.e., without -a or -p options)
mountall: fsck /data[294] terminated with status 4
mountall: File system has errors: /data
Errors were found while checking the disk dr iue for/data.
Press F to attempt to fix the errors, I to ignore, S to skip mounting, or M for manualPenyebab
Sistem file /dev/vdb yang terkait dengan titik pemasangan /data mengalami pengecualian. Saat menjalankan fsck, kesalahan muncul dan konfirmasi manual diperlukan untuk melakukan perbaikan.
Solusi
Solusi untuk masalah ini bervariasi berdasarkan hasil yang dikembalikan oleh utilitas fsck.
Sesuai petunjuk, tekan
Funtuk memperbaiki kesalahan secara otomatis.Jika perbaikan gagal, Anda dapat mencoba menekan
Suntuk melewati titik mount yang sesuai/datadan melanjutkan proses memulai OS.Setelah masuk ke OS, jalankan perintah berikut untuk memperbaiki pengecualian pada sistem file
/dev/vdb, di mana titik mount yang sesuai adalah/data.fsck -y /dev/vdbSetelah Anda memperbaiki sistem file, jalankan perintah berikut untuk me-restart instance:
rebootHubungkan ke instance ECS. Jika pesan kesalahan tidak lagi ditampilkan, masalah terselesaikan.
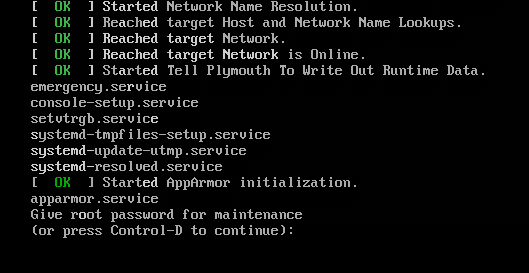
1662001150: Perangkat yang tidak ada dikonfigurasikan untuk mount point di file /etc/fstab sistem operasi Linux, atau utilitas fsck mendeteksi kesalahan dalam sistem file
Deskripsi Masalah
Saat instance ECS dijalankan, sistem operasi mengalami macet dengan menampilkan pesan kesalahan Give root password for maintenance. Contoh:
Booting from Hard Disk...
Booting from 0000:7c00
[ 2.845229] EXT4-fs (vdb1): Unrecognized mount option "default" or missing value
Welcome to emergency mode! After logging in, type "journalctl -xb" to view
system logs, "systemctl reboot" to reboot, "systemctl default" or ^D to
try again to boot into default mode.
Give root password for maintenance
(or press Control-D to continue):Penyebab
Masalah ini dapat terjadi karena penyebab berikut:
Perangkat yang dikonfigurasi untuk dipasang pada titik pemasangan di file
/etc/fstabpada Instance ECS tidak tersedia.Pemeriksaan fsck diaktifkan untuk sistem file saat startup sistem. Pemeriksaan fsck mendeteksi kesalahan dalam sistem file, yang harus diperbaiki secara manual.
Solusi
Anda dapat memilih salah satu solusi berikut berdasarkan penyebab utama dari masalah tersebut.
Solusi 1: Perbaiki kesalahan konfigurasi
Masukkan kata sandi instance untuk masuk ke sistem.
Jalankan perintah berikut untuk mengatur opsi mount untuk partisi root menjadi rw (baca dan tulis):
mount / -o remount,rwJalankan perintah berikut untuk melihat pesan kesalahan:
journalctl -xbSebagai contoh,
[ 2.845229] EXT4-fs (vdb1): Opsi mount "default" tidak dikenali atau nilai hilangmenunjukkan bahwa mode mount untuk/dev/vdb1dalam file/etc/fstabdisetel ke 'default', yang merupakan kesalahan. Nilai ini perlu diubah menjadi 'defaults'.Ubah mode mount untuk
/dev/vdb1di file konfigurasi/etc/fstabmenjadi `defaults`.Jalankan perintah berikut untuk membuka file konfigurasi
/etc/fstab:vim /etc/fstabTekan tombol
iuntuk memasuki mode edit.Ubah mode mount untuk
/dev/vdb1menjadi `defaults`./dev/vdb1 / ext4 default l lTekan tombol Esc, lalu masukkan
:wquntuk menyimpan dan keluar dari mode edit.
Mulai ulang Instance ECS.
Untuk informasi lebih lanjut, lihat Mulai Ulang sebuah Instans.
Hubungkan ke Instance ECS. Jika pesan kesalahan tidak lagi ditampilkan, masalah telah teratasi.
Solusi 2: Tangani kesalahan sistem file
Setelah Anda memasukkan kata sandi instance untuk masuk ke sistem, pilih solusi berdasarkan kesalahan yang terdeteksi oleh utilitas fsck.
1671696288: Kesalahan switch root initrd yang gagal ditampilkan di sistem operasi Linux
Deskripsi masalah
Sistem operasi Linux gagal memulai. Saat menggunakan VNC untuk masuk ke instance, pesan kesalahan serupa dengan Failed to start Switch Root akan ditampilkan, seperti yang terlihat pada gambar berikut.
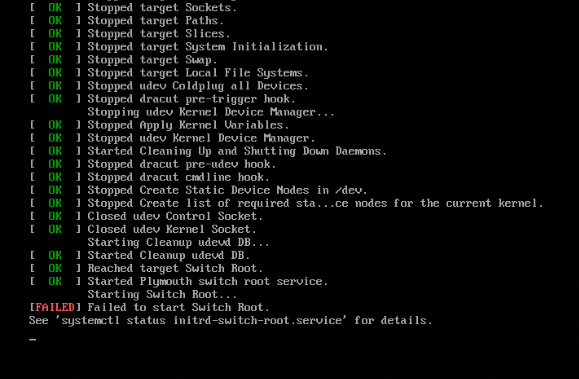
Penyebab
Saat sistem operasi Linux mulai, terjadi kegagalan selama proses switch root. Kegagalan ini dapat disebabkan oleh hal-hal berikut:
Penyebab umumnya adalah file
/etc/os-releaseatau/usr/lib/os-releasetidak tersedia. Untuk memperbaikinya, lihat Solusi 1: Buat file yang hilang.Untuk informasi tentang penyebab lainnya, lihat bagian Solusi 2: Pulihkan disk sistem dari snapshot.
Solusi
Solusi 1: Buat file yang hilang
Lepaskan disk sistem dari instance ECS yang bermasalah dan sambungkan disk tersebut sebagai disk data ke instance ECS yang sehat.
Untuk informasi lebih lanjut, lihat Langkah 1 hingga Langkah 2 di Praktik Terbaik untuk Pemulihan Data pada Instance Linux.
CatatanInstance yang sehat sebaiknya menjalankan Distribusi Linux yang sama dengan instance bermasalah agar memudahkan pemulihan file
/etc/os-releasedi tahap berikutnya.Pada instance ECS yang sehat, lakukan tindakan yang sesuai berdasarkan keberadaan file
/etc/os-releasedi disk sistem yang bermasalah.CatatanDalam contoh ini, sistem file dari disk sistem sebelumnya dipasang ke direktori /mnt.
Skenario
Prosedur
File
/etc/os-releasetidak adaLakukan operasi berdasarkan apakah Distribusi Linux dari instance ECS yang sehat dan yang bermasalah sama.
Distribusi Linux yang sama: Jalankan perintah
cp /etc/os-release /mnt/etc/os-releaseuntuk menyalin file/etc/os-releasedari instance yang sehat ke instance ECS yang bermasalah.Distribusi Linux yang berbeda: Jalankan perintah
vi /mnt/etc/os-releaseuntuk secara manual membuat dan mengedit file/etc/os-release. Isi konten file/etc/os-releasedengan merujuk pada konten file/etc/os-releasepada instance yang sehat dengan Distribusi Linux yang sama.
CatatanAnda mungkin menemukan bahwa file
/etc/os-releasepada instance yang sehat dengan Distribusi Linux yang sama adalah tautan simbolik ke file lain. Anda dapat memilih metode perbaikan sesuai kebutuhan.Ikuti langkah-langkah di atas untuk langsung memulihkan file
/etc/os-releasedengan konten sebenarnya.Ini karena
systemddapat mengenali sistem dengan benar selama salah satu file/etc/os-releaseatau/usr/lib/os-releaseada.Ikuti langkah-langkah di bawah ini untuk pertama-tama memulihkan file lain yang ditunjuk oleh
/etc/os-release, lalu pulihkan tautan simbolik/etc/os-releaseuntuk memastikan integritas dan konsistensi file sistem.
File
/etc/os-releaseadaJalankan perintah
ls -hal /etc/os-release. Jika pesan serupa dengan berikut ini dikembalikan, itu menunjukkan bahwa file/etc/os-releaseadalah tautan simbolik ke file/usr/lib/os-release.lrwxrwxrwx 1 root root 19 Dec 20 15:13 os-release -> /usr/lib/os-releaseLakukan tindakan yang sesuai berdasarkan apakah file
/usr/lib/os-releasehilang.File
/usr/lib/os-releasetidak ada:Distribusi Linux yang sama: Jalankan perintah
cp /usr/lib/os-release /mnt/usr/lib/os-releaseuntuk menyalin file/usr/lib/os-releasedari instance yang sehat ke instance ECS yang bermasalah.Distribusi Linux yang berbeda: Jalankan perintah
vi /mnt/usr/lib/os-releaseuntuk secara manual membuat dan mengedit file/usr/lib/os-release. Isi konten file/usr/lib/os-releasedengan merujuk pada konten file/usr/lib/os-releasepada instance yang sehat dengan Distribusi Linux yang sama.
File
/usr/lib/os-releaseada: Gunakan snapshot untuk memulihkan disk sistem untuk diperbaiki. Untuk informasi lebih lanjut, lihat Kembalikan disk menggunakan snapshot.
Sambungkan kembali disk sistem ke instance ECS yang bermasalah.
Untuk informasi lebih lanjut, lihat Langkah 3 di Praktik Terbaik untuk Pemulihan Data pada Instance Linux.
Gunakan SSH atau VNC untuk masuk ke instance ECS yang bermasalah yang telah diperbaiki. Kemudian, periksa apakah instance ECS berjalan sesuai harapan.
Solusi 2: Pulihkan disk sistem dari snapshot
Kunjungi ECS console - Snapshots.
Di bilah navigasi atas, pilih wilayah dan kelompok sumber daya untuk sumber daya yang ingin Anda kelola.
Pada tab Disk Snapshots, cari snapshot yang ingin digunakan untuk rollback. Di kolom Actions, klik Roll Back Disk.
Di kotak dialog yang muncul, klik OK.
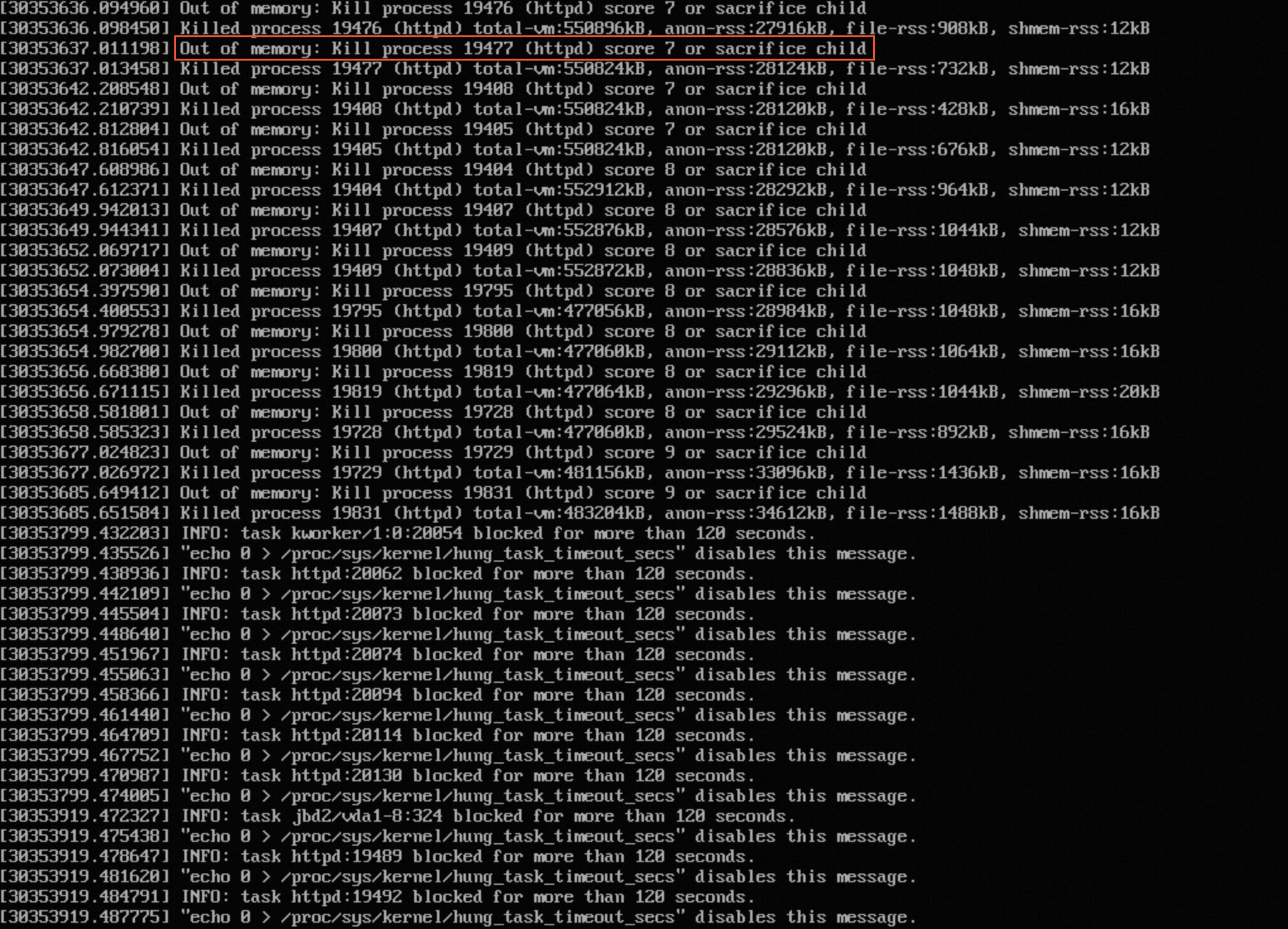
1684829582: Instans Linux memiliki ruang memori yang tidak mencukupi, menyebabkan kesalahan kehabisan memori di sistem operasi
Deskripsi masalah
Saat menggunakan instans Linux, Anda mungkin mengalami masalah seperti crash program, pengecualian baca/tulis proses, instans ECS yang hang, atau tersendat. Banyak pesan Out of Memory (OOM) muncul di log sistem /var/log/message, seperti yang ditunjukkan pada gambar berikut:
Penyebab
Mekanisme OOM memungkinkan kernel Linux untuk secara paksa melepaskan memori proses jika memori sistem tidak mencukupi.
Banyak pesan kesalahan OOM muncul karena sistem kekurangan sumber daya memori, dan sistem tidak dapat mengalokasikan ruang memori yang cukup untuk program atau proses. Akibatnya, program tidak dapat berjalan sesuai harapan atau proses tidak dapat membaca atau menulis data.
Solusi
Anda dapat melakukan langkah-langkah berikut untuk mendiagnosis penyebab OOM, seperti sumber daya sistem yang tidak mencukupi, kebocoran memori, konfigurasi sistem yang tidak tepat, atau alokasi memori yang tidak sesuai:
Hubungkan ke instans ECS.
Untuk informasi lebih lanjut, lihat Hubungkan ke instans Linux menggunakan kata sandi atau kunci.
Jalankan perintah berikut untuk melihat dan mencatat proses tempat terjadinya kesalahan OOM, waktu terjadinya kesalahan OOM, dan frekuensi terjadinya kesalahan OOM:
cat /var/log/messageLihat beban sistem dan log aplikasi bisnis dari instans Linux selama periode OOM.
Lihat beban sistem dari instans Linux.
Gunakan CloudMonitor untuk menanyakan informasi beban dari instans ECS.
Periksa informasi beban sistem dengan menjalankan perintah
free,top, atausar. Untuk detail lebih lanjut, lihat Diagnosis dan Perbaikan Masalah Beban Tinggi pada Instans Linux.
Lihat penyebab kesalahan OOM di log aplikasi bisnis.
Gunakan alat analisis memori seperti Valgrind, jprofiler, dan jmap untuk menganalisis penggunaan memori aplikasi Anda.
Analisis penyebab kesalahan OOM berdasarkan beban sistem dan log layanan dari instans Linux dan perbaiki kesalahan tersebut.
Memori instans Linux Anda tidak cukup untuk mendukung bisnis Anda.
Ubah konfigurasi memori instans. Untuk informasi lebih lanjut, lihat Tingkatkan tipe instans dari instans langganan atau Ubah tipe instans dari instans berbayar sesuai penggunaan.
Kode aplikasi Anda mengandung cacat, seperti kebocoran memori dan alokasi memori yang berlebihan atau tidak tepat.
Optimalkan kode aplikasi Anda berdasarkan masalah yang dilaporkan di log aplikasi bisnis Anda.
Amati status berjalan dari instans ECS. Jika pesan kesalahan OOM tidak lagi muncul, masalah telah diselesaikan.