DataWorks DataStudio menyediakan berbagai jenis node untuk memenuhi kebutuhan pemrosesan data yang berbeda. Anda dapat menggunakan node integrasi data untuk sinkronisasi, node komputasi engine seperti MaxCompute SQL, Hologres SQL, dan EMR Hive untuk pembersihan data, serta node umum seperti node beban nol dan node do-while loop untuk pemrosesan logika kompleks. Node-node ini bekerja sama untuk menangani berbagai tantangan pemrosesan data secara efektif.
Jenis node yang didukung
Tabel berikut mencantumkan jenis node yang didukung oleh penjadwalan berulang. Jenis node yang didukung oleh tugas satu kali atau alur kerja yang dipicu secara manual mungkin berbeda. Untuk informasi paling akurat, rujuk UI.
Ketersediaan node bervariasi tergantung edisi dan Wilayah DataWorks. Untuk informasi paling akurat, rujuk UI.
Jenis node | Nama node | Deskripsi | Kode node | TaskType |
Data Integration | Digunakan untuk sinkronisasi data batch berulang. Mendukung sinkronisasi data antara berbagai sumber data yang berbeda dalam skenario kompleks. Untuk informasi lebih lanjut tentang sumber data yang didukung oleh sinkronisasi batch, lihat Sumber data yang didukung dan solusi sinkronisasi. | 23 | DI | |
Fitur sinkronisasi data real-time di DataWorks memungkinkan Anda menyinkronkan perubahan data dari database sumber ke database tujuan secara real-time. Hal ini menjamin konsistensi data. Anda dapat menyinkronkan satu tabel atau seluruh database. Untuk informasi lebih lanjut tentang sumber data yang didukung oleh sinkronisasi real-time, lihat Sumber data yang didukung dan solusi sinkronisasi. | 900 | RI | ||
Notebook | Notebook menawarkan platform fleksibel dan interaktif untuk pemrosesan dan analisis data. Platform ini membuat pemrosesan data, eksplorasi, visualisasi, dan pembuatan model menjadi lebih efisien dengan meningkatkan intuitivitas, modularitas, dan interaksi. | 1323 | NOTEBOOK | |
MaxCompute | Mendukung penjadwalan berulang tugas MaxCompute SQL. Tugas MaxCompute SQL menggunakan sintaks mirip SQL dan cocok untuk pemrosesan terdistribusi dataset besar (skala terabyte) di mana kinerja real-time tidak kritis. | 10 | ODPS_SQL | |
Template skrip SQL adalah template kode SQL dengan beberapa parameter input dan output. Template ini memproses data dan menghasilkan tabel sink dengan melakukan filter, join, dan agregasi data dari tabel sumber. Selama pengembangan data, Anda dapat membuat node template skrip SQL dan menggunakan komponen yang telah ditentukan ini untuk membangun alur pemrosesan data dengan cepat. Hal ini secara signifikan meningkatkan efisiensi pengembangan. | 1010 | COMPONENT_SQL | ||
Menggabungkan beberapa pernyataan SQL menjadi satu skrip untuk dikompilasi dan dieksekusi. Ini ideal untuk skenario kueri kompleks, seperti subkueri bersarang atau operasi multi-langkah. Dengan mengirimkan seluruh skrip sekaligus, rencana eksekusi terpadu dihasilkan. Pekerjaan hanya perlu masuk antrian dan dieksekusi sekali, sehingga penggunaan resource lebih efisien. | 24 | ODPS_SQL_SCRIPT | ||
Mengintegrasikan SDK Python untuk MaxCompute. Hal ini memungkinkan Anda menulis dan mengedit kode Python langsung di node PyODPS 2 untuk melakukan tugas pemrosesan dan analisis data di MaxCompute. | 221 | PY_ODPS | ||
Gunakan node PyODPS 3 untuk menulis pekerjaan MaxCompute langsung dalam Python dan mengonfigurasinya untuk penjadwalan berulang. | 1221 | PYODPS3 | ||
DataWorks mendukung menjalankan pekerjaan Spark offline (dalam mode Cluster) berbasis MaxCompute. | 225 | ODPS_SPARK | ||
Buat node MaxCompute MR dan kirimkan untuk penjadwalan agar dapat menulis program MapReduce menggunakan API Java MapReduce. Hal ini memungkinkan Anda memproses dataset besar di MaxCompute. | 11 | ODPS_MR | ||
Saat Anda perlu mempercepat kueri pada data MaxCompute di Hologres, Anda dapat menggunakan fitur pemetaan metadata MaxCompute dari katalog data. Fitur ini memetakan metadata tabel MaxCompute ke Hologres, sehingga Anda dapat menggunakan tabel eksternal Hologres untuk mempercepat kueri pada data MaxCompute. | - | - | ||
Mendukung sinkronisasi data dari satu tabel MaxCompute ke Hologres. Hal ini memfasilitasi analisis data besar dan kueri real-time yang efisien. | - | - | ||
Hologres | Node Hologres SQL mendukung kueri pada data di instans Hologres. Hologres dan MaxCompute terhubung secara mulus di lapisan dasar. Hal ini memungkinkan Anda menggunakan node Hologres SQL untuk langsung mengkueri dan menganalisis data skala besar di MaxCompute menggunakan pernyataan PostgreSQL standar tanpa migrasi data. Hasil kueri pun cepat diperoleh. | 1093 | HOLOGRES_SQL | |
Mendukung migrasi data dari satu tabel Hologres ke MaxCompute. | 1070 | HOLOGRES_SYNC_DATA_TO_MC | ||
Menyediakan fitur impor skema tabel satu klik. Fitur ini memungkinkan Anda membuat tabel eksternal Hologres secara batch dengan skema yang sama seperti tabel MaxCompute. | 1094 | HOLOGRES_SYNC_DDL | ||
Menyediakan fitur sinkronisasi data satu klik. Fitur ini memungkinkan Anda menyinkronkan data dari MaxCompute ke database Hologres dengan cepat. | 1095 | HOLOGRES_SYNC_DATA | ||
Serverless Spark | Node Spark berbasis Serverless Spark, cocok untuk pemrosesan data skala besar. | 2100 | SERVERLESS_SPARK_BATCH | |
Node kueri SQL berbasis Serverless Spark. Mendukung sintaks SQL standar dan menyediakan kemampuan analisis data berkinerja tinggi. | 2101 | SERVERLESS_SPARK_SQL | ||
Terhubung ke Serverless Spark melalui antarmuka JDBC/ODBC Kyuubi untuk menyediakan layanan Spark SQL multitenan. | 2103 | SERVERLESS_KYUUBI | ||
Severless StarRocks | Node SQL berbasis EMR Serverless StarRocks. Kompatibel dengan sintaks SQL StarRocks open source dan menyediakan analisis kueri OLAP (Online Analytical Processing) serta analisis kueri Lakehouse yang sangat cepat. | 2104 | SERVERLESS_STARROCKS | |
LLM | Dilengkapi mesin bawaan untuk pemrosesan, analisis, dan penambangan data. Secara cerdas melakukan pembersihan dan penambangan data berdasarkan instruksi bahasa alami Anda. | 2200 | LLM_NODE | |
Flink | Mendukung penggunaan pernyataan SQL standar untuk mendefinisikan logika pemrosesan tugas real-time. Mudah digunakan, mendukung SQL yang kaya, serta memiliki manajemen state dan toleransi kesalahan yang kuat. Kompatibel dengan event time dan processing time, serta dapat diperluas secara fleksibel. Node ini mudah diintegrasikan dengan sistem seperti Kafka dan HDFS serta menyediakan log detail dan alat pemantauan kinerja. | 2012 | FLINK_SQL_STREAM | |
Memungkinkan Anda menggunakan pernyataan SQL standar untuk mendefinisikan dan mengeksekusi tugas pemrosesan data. Cocok untuk menganalisis dan mentransformasi dataset besar, termasuk pembersihan dan agregasi data. Node ini mendukung konfigurasi visual dan menyediakan solusi pemrosesan batch skala besar yang efisien dan fleksibel. | 2011 | FLINK_SQL_BATCH | ||
EMR | Gunakan pernyataan mirip SQL untuk membaca, menulis, dan mengelola dataset besar. Hal ini memungkinkan analisis dan pengembangan data log skala besar secara efisien. | 227 | EMR_HIVE | |
Mesin kueri SQL interaktif untuk kueri real-time cepat pada data besar skala petabyte. | 260 | EMR_IMPALA | ||
Membagi dataset besar menjadi beberapa tugas Map paralel, yang secara signifikan meningkatkan efisiensi pemrosesan data. | 230 | EMR_MR | ||
Mesin kueri SQL terdistribusi yang fleksibel dan dapat diskalakan, yang mendukung analisis interaktif data besar menggunakan bahasa kueri SQL standar. | 259 | EMR_PRESTO | ||
Memungkinkan Anda mengedit skrip Shell kustom untuk menggunakan fitur lanjutan seperti pemrosesan data, pemanggilan komponen Hadoop, dan operasi file. | 257 | EMR_SHELL | ||
Mesin analisis data besar serbaguna yang dikenal karena kinerja tinggi, kemudahan penggunaan, dan penerapan luas. Mendukung komputasi in-memory kompleks dan ideal untuk membangun aplikasi analisis data skala besar dengan latensi rendah. | 228 | EMR_SPARK | ||
Mengimplementasikan mesin kueri SQL terdistribusi untuk memproses data terstruktur dan meningkatkan efisiensi eksekusi pekerjaan. | 229 | EMR_SPARK_SQL | ||
Digunakan untuk memproses data streaming real-time ber-throughput tinggi. Memiliki mekanisme toleransi kesalahan yang dapat memulihkan aliran data yang gagal dengan cepat. | 264 | EMR_SPARK_STREAMING | ||
Mesin kueri SQL terdistribusi yang cocok untuk analisis interaktif lintas berbagai sumber data. | 267 | EMR_TRINO | ||
Gerbang terdistribusi dan multitenan yang menyediakan layanan kueri SQL dan lainnya untuk mesin kueri data lake seperti Spark, Flink, atau Trino. | 268 | EMR_KYUUBI | ||
ADB | Kembangkan dan jadwalkan tugas AnalyticDB for PostgreSQL berulang. | 1000090 | - | |
Kembangkan dan jadwalkan tugas AnalyticDB for MySQL berulang. | 1000126 | - | ||
Kembangkan dan jadwalkan tugas AnalyticDB Spark berulang. | 1990 | ADB_SPARK | ||
Kembangkan dan jadwalkan tugas AnalyticDB Spark SQL berulang. | 1991 | ADB_SPARK_SQL | ||
CDH | Gunakan node ini jika Anda telah menerapkan kluster CDH dan ingin menggunakan DataWorks untuk menjalankan tugas Hive. | 270 | CDH_HIVE | |
Mesin analisis data besar serbaguna dengan kinerja tinggi, kemudahan penggunaan, dan penerapan luas. Gunakan untuk analisis in-memory kompleks dan membangun aplikasi analisis data skala besar dengan latensi rendah. | 271 | CDH_SPARK | ||
Mengimplementasikan mesin kueri SQL terdistribusi untuk memproses data terstruktur dan meningkatkan efisiensi eksekusi pekerjaan. | 272 | CDH_SPARK_SQL | ||
Memproses dataset ultra-besar. | 273 | CDH_MR | ||
Node ini menyediakan mesin kueri SQL terdistribusi, yang meningkatkan kemampuan analisis data di lingkungan CDH. | 278 | CDH_PRESTO | ||
Node CDH Impala memungkinkan Anda menulis dan mengeksekusi skrip SQL Impala, yang memberikan kinerja kueri lebih cepat. | 279 | CDH_IMPALA | ||
Lindorm | Kembangkan dan jadwalkan tugas Lindorm Spark berulang. | 1800 | LINDORM_SPARK | |
Kembangkan dan jadwalkan tugas Lindorm Spark SQL berulang. | 1801 | LINDORM_SPARK_SQL | ||
ClickHouse | Menjalankan kueri SQL terdistribusi dan memproses data terstruktur untuk meningkatkan efisiensi eksekusi pekerjaan. | 1301 | CLICK_SQL | |
Data Quality | Konfigurasikan aturan pemantauan kualitas data untuk memantau kualitas data tabel di sumber data, misalnya untuk memeriksa data kotor. Anda juga dapat menyesuaikan kebijakan penjadwalan untuk menjalankan pekerjaan pemantauan secara berkala guna validasi data. | 1333 | DATA_QUALITY_MONITOR | |
Node perbandingan memungkinkan Anda membandingkan data dari tabel yang berbeda dengan berbagai cara. | 1331 | DATA_SYNCHRONIZATION_QUALITY_CHECK | ||
General | Node beban nol adalah node kontrol. Ini adalah node simulasi kering yang tidak menghasilkan data. Biasanya digunakan sebagai node akar dalam alur kerja untuk membantu Anda mengelola node dan alur kerja. | 99 | VIRTUAL | |
Digunakan untuk pengiriman parameter. Output node mengirimkan hasil kueri terakhir atau output ke node downstream melalui konteks node. Hal ini memungkinkan pengiriman parameter lintas node. | 1100 | CONTROLLER_ASSIGNMENT | ||
Node Shell mendukung sintaks Shell standar tetapi tidak mendukung sintaks interaktif. | 6 | DIDE_SHELL | ||
Mengumpulkan parameter dari node leluhur dan meneruskannya ke node turunan. | 1115 | PARAM_HUB | ||
Memicu eksekusi node turunan dengan memantau objek OSS. | 239 | OSS_INSPECT | ||
Mendukung Python 3. Memungkinkan Anda mengambil parameter upstream dan mengonfigurasi parameter kustom melalui parameter penjadwalan dalam konfigurasi penjadwalan. Juga memungkinkan Anda meneruskan output-nya sendiri sebagai parameter ke node downstream. | 1322 | Python | ||
Menggabungkan status running node leluhur untuk menyelesaikan masalah ketergantungan dan pemicu eksekusi untuk node turunan dari node cabang. | 1102 | CONTROLLER_JOIN | ||
Menilai hasil node leluhur untuk menentukan logika cabang mana yang akan diikuti. Anda dapat menggunakannya bersama node assignment. | 1101 | CONTROLLER_BRANCH | ||
Menelusuri set hasil yang diteruskan oleh node assignment. | 1106 | CONTROLLER_TRAVERSE | ||
Loop bagian logika node. Anda juga dapat menggunakannya dengan node assignment untuk loop hasil yang diteruskan oleh node assignment. | 1103 | CONTROLLER_CYCLE | ||
Memeriksa apakah objek target (tabel partisi MaxCompute, file FTP, atau file OSS) aktif. Saat node Check memenuhi kebijakan pemeriksaan, node tersebut mengembalikan status running sukses. Jika ada dependensi downstream, node tersebut berjalan sukses dan memicu tugas downstream. Objek target yang didukung:
| 241 | CHECK_NODE | ||
Digunakan untuk penjadwalan berulang fungsi pemrosesan event. | 1330 | FUNCTION_COMPUTE | ||
Gunakan node ini jika Anda ingin memicu tugas di DataWorks setelah tugas di sistem pemetaan CDN lain selesai. Catatan DataWorks tidak lagi mendukung pembuatan cross-tenant collaboration nodes. Jika Anda menggunakan node kolaborasi lintas penyewa, gantilah dengan node HTTP trigger, yang menyediakan kemampuan yang sama. | 1114 | SCHEDULER_TRIGGER | ||
Memungkinkan Anda menentukan sumber data SSH untuk mengakses host yang terhubung ke sumber data tersebut dari DataWorks secara remote dan memicu skrip untuk dijalankan di host remote. | 1321 | SSH | ||
Node Data Push dapat mendorong hasil kueri yang dihasilkan oleh node lain dalam alur kerja DataStudio ke grup DingTalk, grup Lark, grup WeCom, Teams, dan kotak surat dengan membuat tujuan dorong data. | 1332 | DATA_PUSH | ||
MySQL node | Node MySQL memungkinkan Anda mengembangkan dan menjadwalkan tugas MySQL berulang. | 1000125 | - | |
SQL Server | Node SQL Server memungkinkan Anda mengembangkan dan menjadwalkan tugas SQL Server berulang. | 10001 | - | |
Oracle node | Node Oracle memungkinkan Anda mengembangkan dan menjadwalkan tugas Oracle berulang. | 10002 | - | |
PostgreSQL node | Node PostgreSQL memungkinkan Anda mengembangkan dan menjadwalkan tugas PostgreSQL berulang. | 10003 | - | |
StarRocks node | Kembangkan dan jadwalkan tugas StarRocks berulang. | 10004 | - | |
DRDS node | Kembangkan dan jadwalkan tugas DRDS berulang. | 10005 | - | |
PolarDB MySQL node | Kembangkan dan jadwalkan tugas PolarDB for MySQL berulang. | 10006 | - | |
PolarDB PostgreSQL node | Node PolarDB PostgreSQL memungkinkan Anda mengembangkan dan menjadwalkan tugas PolarDB for PostgreSQL berulang. | 10007 | - | |
Doris node | Node Doris memungkinkan Anda mengembangkan dan menjadwalkan tugas Doris berulang. | 10008 | - | |
MariaDB node | Node MariaDB memungkinkan Anda mengembangkan dan menjadwalkan tugas MariaDB berulang. | 10009 | - | |
SelectDB node | Node SelectDB memungkinkan Anda mengembangkan dan menjadwalkan tugas SelectDB berulang. | 10010 | - | |
Redshift node | Node Redshift memungkinkan Anda mengembangkan dan menjadwalkan tugas Redshift berulang. | 10011 | - | |
Saphana node | Node Saphana memungkinkan Anda mengembangkan dan menjadwalkan tugas SAP HANA berulang. | 10012 | - | |
Vertica node | Node Vertica memungkinkan Anda mengembangkan dan menjadwalkan tugas Vertica berulang. | 10013 | - | |
DM (Dameng) node | Node DM memungkinkan Anda mengembangkan dan menjadwalkan tugas DM berulang. | 10014 | - | |
KingbaseES node | Node KingbaseES memungkinkan Anda mengembangkan dan menjadwalkan tugas KingbaseES berulang. | 10015 | - | |
OceanBase node | Node OceanBase memungkinkan Anda mengembangkan dan menjadwalkan tugas OceanBase berulang. | 10016 | - | |
DB2 node | Node DB2 memungkinkan Anda mengembangkan dan menjadwalkan tugas DB2 berulang. | 10017 | - | |
GBase 8a node | Node GBase 8a memungkinkan Anda mengembangkan dan menjadwalkan tugas GBase 8a berulang. | 10018 | - | |
Algorithm | PAI Designer adalah alat pemodelan visual untuk membangun alur kerja pengembangan pembelajaran mesin end-to-end. | 1117 | PAI_STUDIO | |
PAI DLC adalah layanan pelatihan berbasis kontainer yang digunakan untuk menjalankan tugas pelatihan terdistribusi. | 1119 | PAI_DLC | ||
Menghasilkan node PAIFlow di DataWorks untuk alur kerja indeks basis pengetahuan PAI. | 1250 | PAI_FLOW | ||
Logic node | Node SUB_PROCESS mengintegrasikan beberapa alur kerja menjadi satu kesatuan untuk dikelola dan dijadwalkan. | 1122 | SUB_PROCESS |
Buat node
Buat node untuk alur kerja terjadwal
Jika tugas Anda perlu berjalan secara otomatis pada waktu tertentu—misalnya, per jam, harian, atau mingguan—Anda dapat membuat node tugas yang dipicu otomatis. Anda dapat membuat node tugas yang dipicu otomatis baru, menambahkan node internal ke alur kerja berulang, atau mengkloning node yang sudah ada.
Buka halaman Workspaces di Konsol DataWorks. Di bilah navigasi atas, pilih Wilayah yang diinginkan. Temukan ruang kerja yang diinginkan dan pilih di kolom Actions.
Di panel navigasi kiri, klik
 untuk membuka halaman Data Studio.
untuk membuka halaman Data Studio.
Buat node tugas terjadwal
Klik
 di sebelah kanan direktori ruang kerja dan pilih Create Node. Pilih jenis node.Penting
di sebelah kanan direktori ruang kerja dan pilih Create Node. Pilih jenis node.PentingSistem menyediakan daftar Common Nodes dan All Nodes. Anda dapat memilih All Nodes di bagian bawah untuk melihat daftar lengkap. Anda juga dapat menggunakan search box untuk menemukan node dengan cepat atau memfilter berdasarkan kategori, seperti MaxCompute, Data Integration, atau General, guna menemukan dan membuat node yang Anda butuhkan.
Anda dapat membuat folder terlebih dahulu untuk mengatur dan mengelola node Anda.
Atur nama node, simpan, lalu buka halaman editor node.
Buat node internal dalam alur kerja terjadwal
Buat alur kerja berulang.
Di kanvas alur kerja, klik Create Node di bilah alat. Pilih jenis node untuk tugas Anda dan seret ke kanvas.
Atur nama node dan simpan.
Buat node dengan mengkloning
Anda dapat menggunakan fitur kloning untuk membuat node baru dengan cepat dari node yang sudah ada. Konten yang dikloning mencakup informasi Penjadwalan node, termasuk Scheduling Parameters, Scheduling Time, dan Scheduling Dependencies.
Di Workspace Directories di panel navigasi kiri, klik kanan node yang akan dikloning dan pilih Clone dari menu pop-up.
Pada kotak dialog yang muncul, Anda dapat mengubah Name dan Path node, atau mempertahankan nilai default. Lalu, klik OK untuk memulai proses kloning.
Setelah kloning selesai, Anda dapat melihat node baru di Workspace Directories.
Buat node untuk alur kerja yang dipicu secara manual
Jika tugas Anda tidak memerlukan penjadwalan berulang tetapi perlu dipublikasikan ke lingkungan produksi untuk eksekusi manual, Anda dapat membuat node internal dalam alur kerja yang dipicu secara manual.
Buka halaman Workspaces di Konsol DataWorks. Di bilah navigasi atas, pilih Wilayah yang diinginkan. Temukan ruang kerja yang diinginkan dan pilih di kolom Actions.
Di panel navigasi kiri, klik
 untuk membuka halaman Manually Triggered Workflow.
untuk membuka halaman Manually Triggered Workflow.Di bilah alat di bagian atas halaman editor alur kerja yang dipicu secara manual, klik Create Internal Node. Pilih jenis node untuk tugas Anda.
Atur nama node dan simpan.
Buat node tugas satu kali
Buka halaman Workspaces di Konsol DataWorks. Di bilah navigasi atas, pilih Wilayah yang diinginkan. Temukan ruang kerja yang diinginkan dan pilih di kolom Actions.
Di panel navigasi kiri, klik
untuk membuka halaman One-time Task.Di bagian Manually Triggered Tasks, klik
 di sebelah kanan Manually Triggered Tasks, pilih Create Node, lalu pilih jenis node yang diperlukan.Catatan
di sebelah kanan Manually Triggered Tasks, pilih Create Node, lalu pilih jenis node yang diperlukan.CatatanTugas satu kali hanya mendukung pembuatan node Batch Synchronization, Notebook, MaxCompute SQL, MaxCompute Script, PyODPS 2, MaxCompute MR, Hologres SQL, Python, dan Shell.
Atur nama node, simpan, lalu buka halaman editor node.
Edit node secara batch
Saat alur kerja berisi banyak node, membuka dan mengeditnya satu per satu tidak efisien. DataWorks menyediakan fitur Inner Node List yang memungkinkan Anda melihat pratinjau, mencari, dan mengedit semua node dalam daftar di sisi kanan kanvas dengan cepat.
Cara menggunakan
Di bilah alat di bagian atas kanvas alur kerja, klik tombol Show Internal Node List untuk membuka panel di sisi kanan.
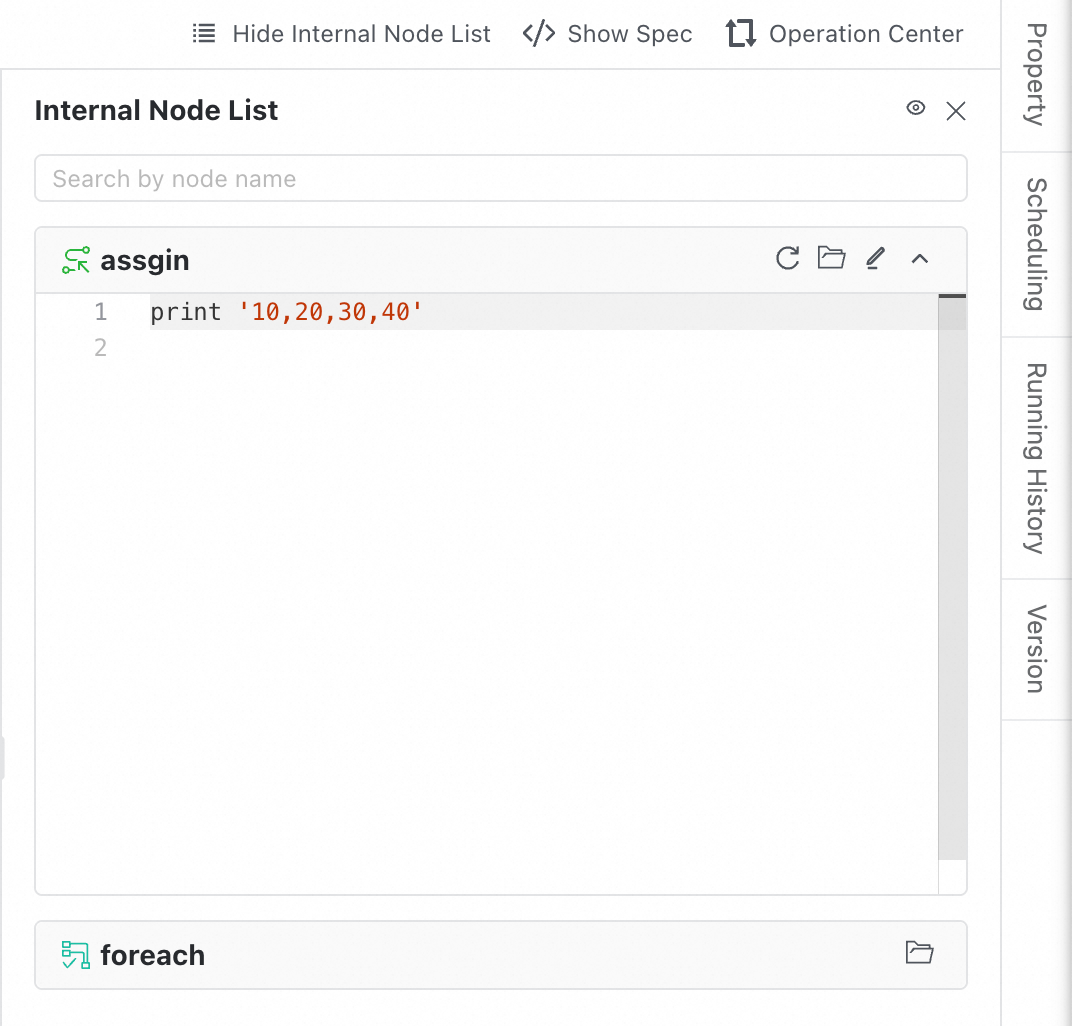
Setelah panel terbuka, panel tersebut menampilkan semua node dalam alur kerja saat ini sebagai daftar.
Pratinjau kode dan pengurutan:
Untuk node yang mendukung pengeditan kode, seperti MaxCompute SQL, editor kode diperluas secara default.
Untuk node yang tidak mendukung pengeditan kode, seperti node beban nol, kartu ditampilkan. Node ini secara otomatis ditempatkan di bagian bawah daftar.
Pencarian dan lokasi cepat:
Search: Di kotak pencarian di bagian atas, Anda dapat memasukkan kata kunci untuk melakukan pencarian fuzzy berdasarkan nama node.
Synchronized focus: Kanvas dan sidebar disinkronkan. Saat Anda memilih node di kanvas, node yang sesuai disorot di sidebar. Demikian pula, saat Anda mengklik node di sidebar, kanvas secara otomatis memfokuskan node tersebut.
Pengeditan online:
Operations: Di pojok kanan atas setiap kartu node tersedia pintasan seperti Load Latest Code, Open Node, dan Edit.
Auto-save: Setelah Anda memasuki mode edit, perubahan Anda disimpan secara otomatis ketika fokus mouse meninggalkan area blok kode.
Conflict detection: Jika pengguna lain memperbarui kode saat Anda sedang mengeditnya, notifikasi kegagalan muncul saat Anda menyimpan. Hal ini mencegah perubahan Anda tertimpa secara tidak sengaja.
Focus mode:
Pilih node dan klik
 di pojok kanan atas jendela mengambang untuk mengaktifkan Focus Mode. Sidebar kemudian hanya menampilkan node yang dipilih, memberikan lebih banyak ruang untuk pengeditan kode.
di pojok kanan atas jendela mengambang untuk mengaktifkan Focus Mode. Sidebar kemudian hanya menampilkan node yang dipilih, memberikan lebih banyak ruang untuk pengeditan kode.
Manajemen versi
Anda dapat menggunakan fitur manajemen versi untuk memulihkan node ke versi historis tertentu. Fitur ini juga menyediakan alat untuk melihat dan membandingkan versi, yang membantu Anda menganalisis perbedaan dan melakukan penyesuaian.
Di Workspace Directories di panel navigasi kiri, klik dua kali nama node target untuk membuka halaman editor node.
Di sisi kanan halaman editor node, klik Version. Di halaman Version, Anda dapat melihat dan mengelola Development History dan Deployment History.
View sebuah versi:
Di tab Development History atau Deployment History, temukan versi node yang ingin Anda lihat.
Klik View di kolom Actions untuk membuka halaman detail. Di halaman ini, Anda dapat melihat kode node dan informasi Scheduling.
CatatanAnda dapat melihat informasi Scheduling dalam mode Code Editor atau visualization. Anda dapat mengganti mode tampilan di pojok kanan atas tab Scheduling.
Compare versi:
Anda dapat membandingkan versi berbeda dari node di tab Development History atau Deployment History.
Bandingkan versi di lingkungan pengembangan atau deployment: Di tab Development History, pilih dua versi dan klik Select Versions to Compare di bagian atas. Anda kemudian dapat membandingkan kode node dan konfigurasi penjadwalan dari versi yang berbeda.
Bandingkan versi antara lingkungan pengembangan dan deployment atau build:
Di tab Development History, temukan versi node.
Klik Compare di kolom Actions. Di halaman detail, Anda dapat memilih versi dari Deployment History atau Build History untuk dibandingkan.
Restore ke versi:
Anda hanya dapat memulihkan node ke versi historis tertentu dari tab Development History. Di tab Development History, temukan versi target dan klik Restore di kolom Actions. Kode node dan informasi Scheduling kemudian dipulihkan ke versi yang dipilih.
Referensi
Untuk informasi lebih lanjut tentang pengembangan node dalam alur kerja berulang dan manual, lihat Scheduled workflow orchestration dan Manually triggered workflows.
Setelah node dibuat dan dikembangkan, Anda dapat mempublikasikannya ke lingkungan produksi. Untuk informasi lebih lanjut, lihat Node scheduling configuration dan Publish nodes and workflows.
FAQ
Apakah saya dapat mengunduh kode node, seperti SQL atau Python, ke mesin lokal?
Jawaban: Fitur unduh langsung tidak tersedia. Sebagai solusi alternatif, Anda dapat menyalin kode ke mesin lokal selama pengembangan. Atau, di DataStudio versi baru, Anda dapat menambahkan file lokal di folder pribadi Anda untuk pengembangan. Setelah pengembangan selesai, Anda dapat mengirimkan kode ke direktori ruang kerja. Dalam hal ini, kode Anda disimpan secara lokal.