DataWorks Notebook adalah lingkungan interaktif dan modular untuk analisis serta pengembangan data. Anda dapat menggunakan sel Python, SQL, dan Markdown secara bersamaan untuk terhubung ke mesin komputasi seperti MaxCompute, EMR, dan AnalyticDB—mulai dari pemrosesan data dan analisis eksploratif hingga visualisasi dan pengembangan model.
Jalankan Notebook pertama Anda
Bagian ini memandu Anda membuat Notebook, meneruskan variabel dari Python ke SQL, dan mengkueri data dari tabel MaxCompute.
Prasyarat
Sebelum memulai, pastikan Anda telah:
DataStudio baru yang diaktifkan di ruang kerja Anda
Membuat kelompok sumber daya Serverless—diperlukan untuk menjalankan Notebook di lingkungan produksi.
Membuat instans lingkungan pengembangan pribadi—diperlukan untuk menjalankan dan men-debug Notebook di lingkungan pengembangan. Jika belum membuatnya, lihat Buat instans lingkungan pengembangan pribadi.
Langkah-langkah
Buat node Notebook Di Data Studio, buat node Notebook di bawah Workspace Directories. Masukkan nama seperti
hello_notebook, lalu kirimkan.Personal Development Environment Di bilah navigasi atas, klik Personal Development Environment dan pilih instans lingkungan pengembangan pribadi Anda dari daftar drop-down.
Definisikan variabel Python Tambahkan sel Python dan masukkan kode berikut. Ini mendefinisikan variabel
cityuntuk kueri SQL pada langkah berikutnya.# Definisikan variabel untuk kueri SQL berikutnya city = 'Beijing' print(f"Variabel city telah ditetapkan: city = {city}")Tulis sel SQL yang mereferensikan variabel tersebut Di bawah sel Python, tambahkan sel SQL. Di pojok kanan bawah sel, ubah tipe SQL menjadi MaxCompute SQL, lalu masukkan:
-- Kueri menggunakan variabel yang didefinisikan di Python SELECT '${city}' AS city;Sintaks
${city}secara otomatis mengambil nilai dari sel Python di atasnya.Jalankan semua sel dan verifikasi output Klik Run All di bilah alat Notebook. Dua hal terjadi:
Sel Python mencetak
Variabel city telah ditetapkan: city = Beijing.Sel SQL menampilkan hasil kueri dalam bentuk tabel di bawahnya.
Anda telah membuat dan menjalankan Notebook yang meneruskan data antara Python dan SQL.
Konsep utama
Memahami konsep berikut membantu Anda menghindari kejutan saat memindahkan Notebook dari lingkungan pengembangan ke produksi.
Lingkungan pengembangan vs. lingkungan produksi
| Lingkungan pengembangan | Lingkungan produksi | |
|---|---|---|
| Runtime | Instans lingkungan pengembangan pribadi | Kelompok sumber daya dan gambar yang ditentukan di Scheduling |
| Tujuannya | Debugging interaktif; bebas menginstal library Python | Eksekusi terjadwal berulang dan alur kerja yang dipicu secara manual dari Data Studio |
| Jaringan | Instans lingkungan pengembangan pribadi yang tidak disambungkan ke virtual private cloud (VPC) mendapatkan IP publik acak dengan bandwidth terbatas | Ditentukan oleh VPC kelompok sumber daya; tidak memiliki akses jaringan publik secara default kecuali Gateway NAT dikonfigurasi |
| Cara menjaga konsistensi | Jika Anda menginstal paket melalui pip install di lingkungan pengembangan, buat gambar DataWorks dari lingkungan tersebut dan pilih di Scheduling | Pilih gambar kustom di Scheduling untuk memastikan dependensi yang sama tersedia saat runtime |
Untuk memastikan konsistensi jaringan antar lingkungan, sambungkan kelompok sumber daya Serverless yang sama ke instans lingkungan pengembangan pribadi Anda.
Sumber daya komputasi dan kernel
Sumber daya komputasi: Mesin komputasi backend yang terhubung ke Notebook—misalnya, MaxCompute atau EMR Serverless Spark. Sel SQL harus diikat ke sumber daya komputasi agar dapat dijalankan.
Kernel Python: Lingkungan backend yang mengeksekusi kode Python—biasanya instans lingkungan pengembangan pribadi Anda. Gunakan Magic Commands seperti
%odpsdi sel Python untuk terhubung ke sumber daya komputasi, mengirimkan tugas, atau memanipulasi data.
Jenis folder
Lokasi pembuatan Notebook menentukan model kolaborasi, izin, dan jalur penerapannya.
| Jenis folder | Paling cocok untuk | Kolaborasi dan penerapan |
|---|---|---|
| Workspace Directories | Kolaborasi tim dan tugas terjadwal | Dibagikan di seluruh ruang kerja; harus diterapkan ke lingkungan produksi agar dapat dijalankan sesuai jadwal |
| Personal Directory | Pengembangan dan debugging pribadi | Hanya terlihat oleh Anda; untuk menjadwalkan node, pertama-tama commit ke Workspace Directory, lalu terapkan |
Kembangkan dan debug Notebook
Data Studio tidak menyimpan kode Anda secara otomatis. Simpan secara berkala selama pengembangan, atau aktifkan auto-save dengan membuka Settings > Files: Auto Save.
Jika Notebook tidak merespons, klik Restart di bilah alat untuk me-restart kernel.
Atur sel
| Aksi | Cara |
|---|---|
| Add a cell | Arahkan kursor ke tepi atas atau bawah sel dan klik tombol seperti + SQL, atau gunakan tombol di bilah alat |
| Switch cell type | Klik label tipe di pojok kanan bawah sel (misalnya, Python) dan pilih tipe baru. Kode yang ada tetap dipertahankan — perbarui secara manual agar sesuai dengan tipe baru |
| Reorder cells | Arahkan kursor ke garis vertikal biru di sebelah kiri sel, lalu seret ke posisi baru |
Jalankan sel
Pilih opsi eksekusi yang tepat sesuai aktivitas Anda:
Jalankan satu sel — klik Run pada sel tersebut. Gunakan ini saat melakukan iterasi pada sel tertentu selama pengembangan aktif.
Jalankan semua sel — klik Run All di bilah alat Notebook. Gunakan ini sebelum membagikan atau menjadwalkan Notebook untuk memastikan semua sel dieksekusi dengan benar dari awal hingga akhir.
Teruskan parameter antar sel
Dari Python ke SQL
Variabel yang didefinisikan di sel Python tersedia di sel SQL berikutnya menggunakan sintaks ${nama_variabel}.
Contoh:
# Sel Python
table_name = "dwd_user_info_d"
limit_num = 10-- Sel SQL
SELECT * FROM ${table_name} LIMIT ${limit_num};Dari SQL ke Python
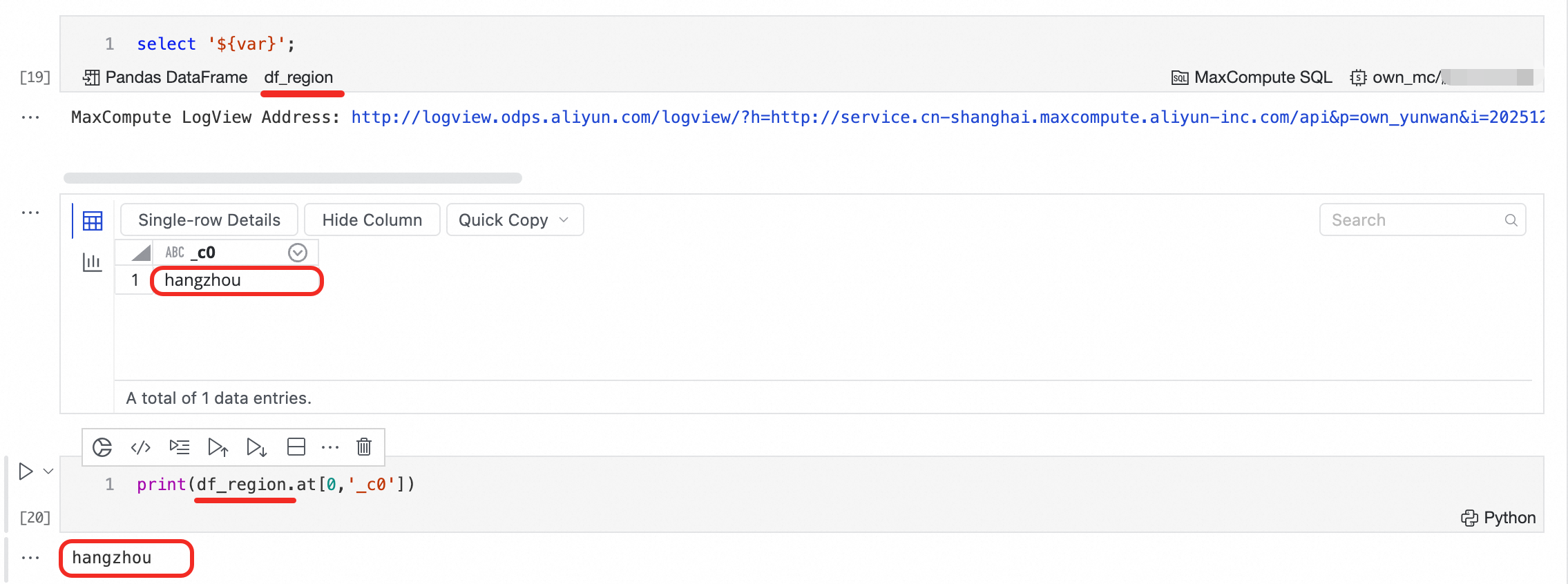
Saat sel SQL mengeksekusi kueri SELECT, hasilnya secara otomatis disimpan sebagai variabel DataFrame. Akses variabel tersebut di sel Python berikutnya.
Nama variabel: Secara default diawali dengan
df_. Klik nama tersebut di pojok kiri bawah sel SQL untuk mengganti namanya.Tipe variabel: Bergantung pada mesin SQL. Klik label DataFrame di pojok kiri bawah untuk mengganti tipe jika beberapa tipe didukung.
| Mesin SQL | Tipe yang didukung |
|---|---|
| MaxCompute SQL | Pandas DataFrame, MaxCompute MaxFrame |
| AnalyticDB for Spark SQL | Pandas DataFrame, PySpark MaxFrame |
| Tipe SQL lainnya | Pandas DataFrame |
Jika sebuah sel berisi beberapa pernyataan SQL, hanya hasil dari pernyataan terakhir yang disimpan ke variabel DataFrame.
Contoh:
Gunakan DataWorks Copilot
DataWorks Copilot adalah asisten pemrograman AI bawaan yang menghasilkan dan menjelaskan kode. Untuk membukanya:
Klik ikon Copilot
 di pojok kiri atas sel yang dipilih.
di pojok kiri atas sel yang dipilih.Klik kanan di dalam sel SQL dan pilih Copilot.
Tekan
Cmd+I(Mac) atauCtrl+I(Windows).
Jadwalkan dan terapkan Notebook
Untuk menjalankan Notebook secara berkala, konfigurasikan pengaturan penjadwalannya dan terapkan ke lingkungan produksi.
1. Siapkan penjadwalan berparameter
Penjadwalan berparameter memungkinkan Notebook menerima nilai berbeda pada setiap eksekusi—berguna untuk memproses data dari partisi harian berbeda tanpa mengubah kode.
Kapan menggunakan ini: Konfigurasikan penjadwalan berparameter ketika Notebook Anda perlu memproses irisan data berbeda tiap kali dijalankan, misalnya membaca partisi kemarin setiap hari.
Di sel Python yang berisi definisi parameter Anda, klik ... di pojok kanan atas sel dan pilih Mark Cell as Parameters. Tag
parametersmuncul, menandainya sebagai titik masuk parameter.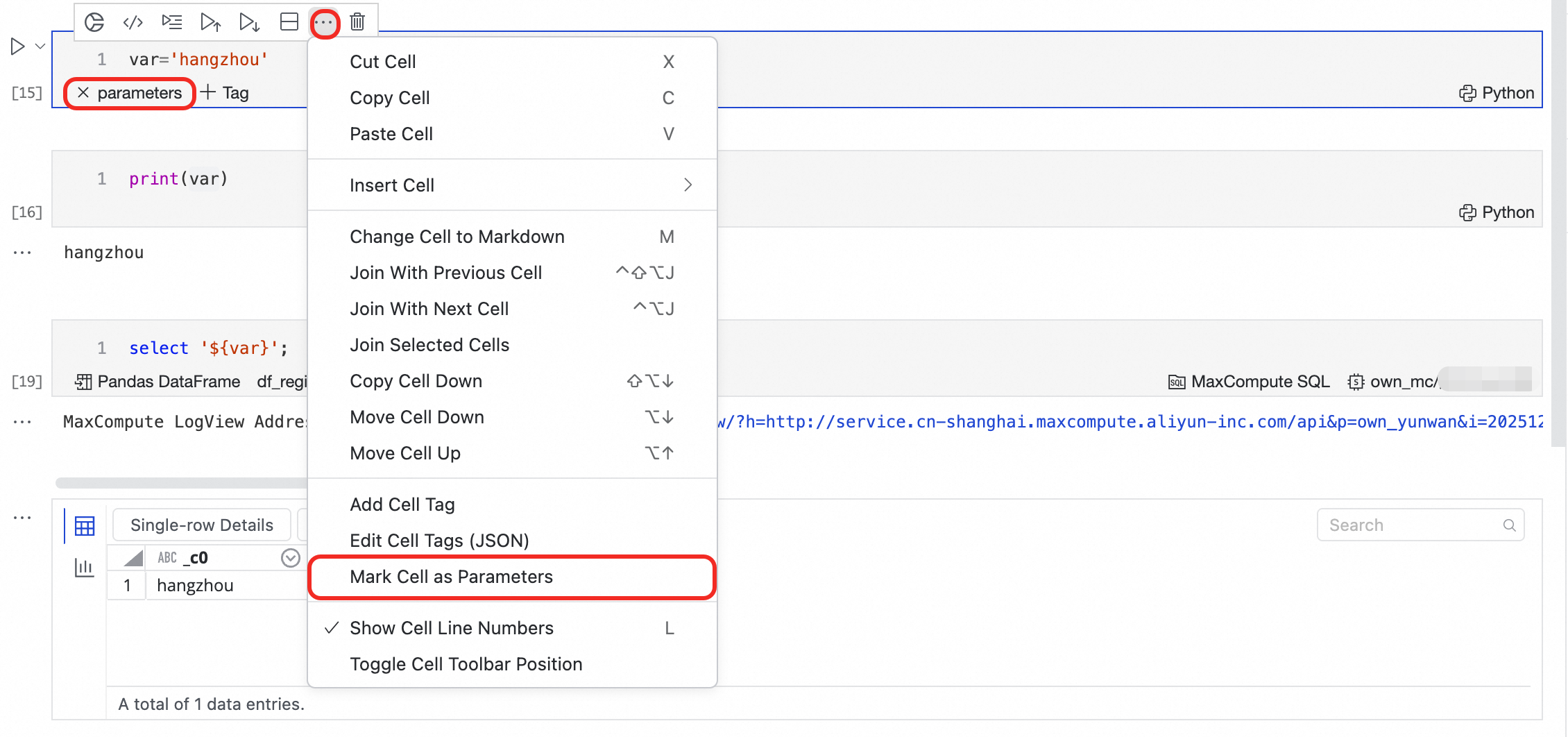
Di panel kanan, klik Scheduling, lalu perluas Scheduling Parameters. Tetapkan nilai untuk variabel (seperti
var) yang didefinisikan dalam kode Anda.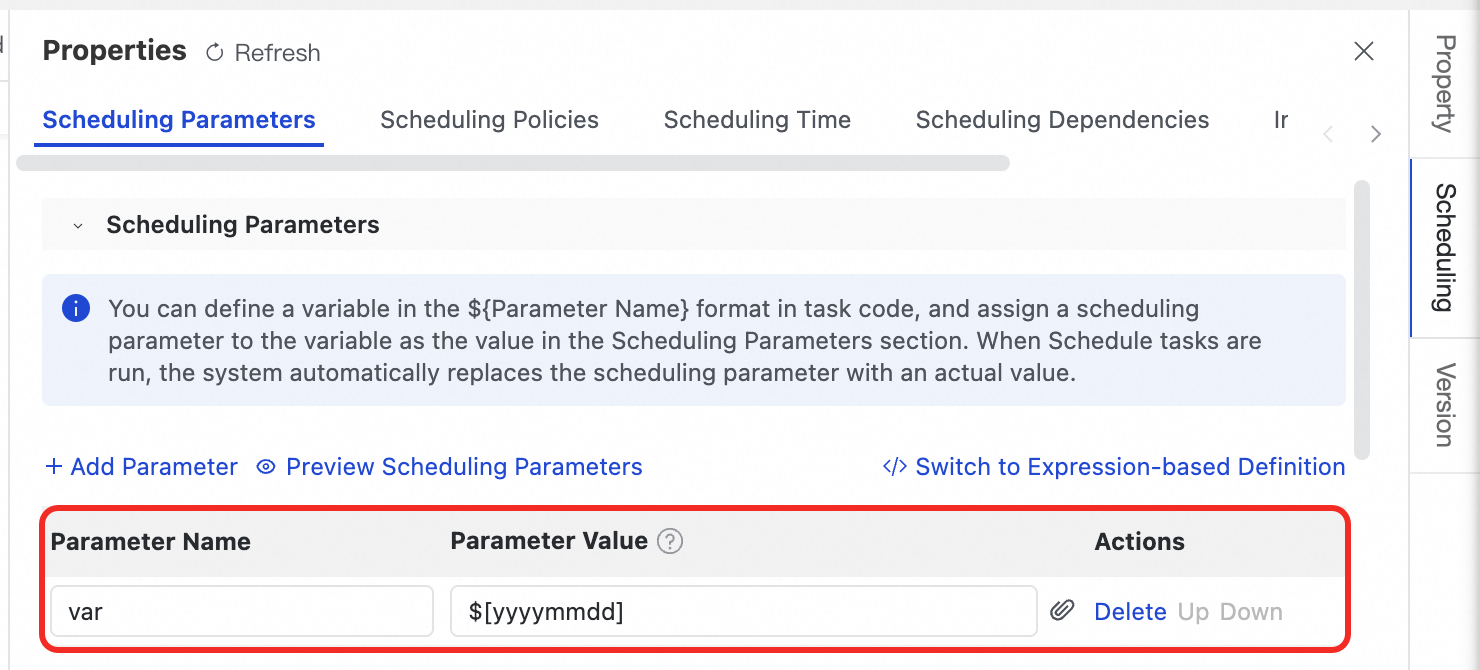
Saat runtime, sistem penjadwalan mengganti variabel dalam kode Anda dengan nilai yang dikonfigurasi.
2. Konfigurasikan lingkungan runtime
Pilih gambar: Di Scheduling, pilih gambar yang mencakup semua dependensi Python yang dibutuhkan Notebook. Jika Anda menginstal paket di instans lingkungan pengembangan pribadi menggunakan
pip install, buat gambar DataWorks dari lingkungan tersebut dan pilih di sini.Pilih kelompok sumber daya: Pilih kelompok sumber daya untuk mengeksekusi tugas. Untuk kelompok sumber daya Serverless, konfigurasikan tidak lebih dari 16 CU untuk menghindari kegagalan startup. Satu tugas mendukung maksimal 64 CU.
Asosiasikan peran RAM (opsional): Untuk menerapkan kontrol izin detail halus, asosiasikan peran Resource Access Management (RAM) dengan node tersebut. Node akan dijalankan dengan identitas peran tersebut. Untuk detailnya, lihat Konfigurasikan peran terasosiasi untuk node.
3. Terapkan node
Hanya node di Workspace Directories yang dapat diterapkan dan dijadwalkan secara berkala.
Notebook di Workspace Directory: Klik Deploy di bilah alat.
Notebook di Personal Directory: Klik Save, lalu klik Commit to Workspace Directory, kemudian terapkan.
Setelah diterapkan, pantau dan kelola tugas Notebook di halaman Auto Triggered Nodes di Operation Center.
FAQ
Mengapa kode saya dapat mengakses jaringan publik saat pengembangan tetapi gagal saat eksekusi terjadwal?
Kebijakan jaringan berbeda antar lingkungan. Saat pengembangan, instans lingkungan pengembangan pribadi tanpa VPC secara default memiliki akses jaringan publik terbatas—cukup untuk menginstal paket atau memanggil API eksternal. Di lingkungan produksi, tugas dijalankan di dalam VPC tanpa akses jaringan publik kecuali Gateway NAT dikonfigurasi pada VPC kelompok sumber daya. Untuk memperbaikinya, pastikan instans lingkungan pengembangan pribadi dan kelompok sumber daya Serverless diatur dalam VPC yang sama.
Mengapa eksekusi terjadwal gagal menemukan paket pihak ketiga yang berfungsi baik di pengembangan?
Lingkungan produksi menggunakan gambar yang Anda pilih di Scheduling, bukan instans pengembangan lokal Anda. Masukkan semua dependensi Python ke dalam gambar kustom dan tentukan di Scheduling. Lihat Buat gambar DataWorks dari lingkungan pengembangan pribadi.
Bagaimana cara mengubah versi kernel Python?
Instal versi Python yang diperlukan di terminal ![]() lingkungan pengembangan pribadi Anda. Lalu klik
lingkungan pengembangan pribadi Anda. Lalu klik ![]() di sisi kanan bilah alat Notebook untuk beralih ke versi kernel tersebut. Hindari menginstal beberapa kernel Python tambahan—versi baru mungkin tidak memiliki dependensi yang diperlukan oleh sel SQL dan menyebabkannya berhenti berfungsi.
di sisi kanan bilah alat Notebook untuk beralih ke versi kernel tersebut. Hindari menginstal beberapa kernel Python tambahan—versi baru mungkin tidak memiliki dependensi yang diperlukan oleh sel SQL dan menyebabkannya berhenti berfungsi.