Node assignment meneruskan hasil kueri atau output lain dari node hulu ke node hilir. Node ini mendukung skrip dalam MaxCompute SQL, Python 2, dan Shell, serta secara otomatis menetapkan hasil kueri atau output terakhir ke parameter output (outputs) miliknya. Node hilir kemudian dapat mereferensikan parameter tersebut untuk mengambil output dari node assignment.
Prasyarat
-
Persyaratan versi: Fitur ini hanya tersedia di DataWorks Standard Edition dan versi yang lebih baru.
-
Izin: Akun RAM Anda harus ditambahkan ke workspace target dan diberi peran Development atau Workspace Manager. Untuk informasi selengkapnya, lihat Tambahkan anggota ke workspace.
Konsep utama: Penyerahan dan referensi parameter
Fungsi inti dari node assignment adalah penyerahan parameter, yang mentransfer data dari node hulu ke node hilir.
-
Node assignment hulu: Menghasilkan data. Node ini secara otomatis menetapkan output atau hasil kueri terakhir ke parameter output yang dihasilkan sistem dengan nama
outputs. -
Node bisnis hilir: Menerima dan menggunakan data tersebut. Anda dapat mengonfigurasi parameter input di node (misalnya,
param) dan mengatur nilainya agar mereferensikan parameteroutputsdari node hulu. Hal ini memungkinkan data tersebut tersedia bagi kode Anda.
Format parameter
Tabel berikut menjelaskan format parameter yang diteruskan.
|
Bahasa |
Nilai |
Format |
|
MaxCompute SQL |
Output dari pernyataan |
Node meneruskan output ke node hilir sebagai array dua dimensi. |
|
Python 2 |
Output dari pernyataan |
DataWorks memisahkan string output berdasarkan koma ( Misalnya, jika baris output terakhir dari node assignment adalah Penting
Jika output berisi koma, Anda harus melakukan escape terhadapnya. Misalnya, jika output adalah |
|
Shell |
Output dari pernyataan |
Prosedur
Contoh berikut menunjukkan cara meneruskan hasil node assignment ke node Shell. Dalam praktiknya, Anda dapat menggunakan jenis node apa pun sebagai node hilir.
-
Konfigurasikan node assignment hulu
Di workflow target, buat dan edit node assignment. Pilih MaxCompute SQL, Python 2, atau Shell sesuai kebutuhan, lalu tulis kode untuk menghasilkan hasil yang ingin Anda teruskan ke node hilir.
print '10,20,30,40' -
Konfigurasikan node Shell hilir
Buat node Shell dan referensikan hasil hulu dalam konfigurasi node:
-
Di panel Scheduling Settings di sebelah kanan, klik tab Node Context Parameters.
-
Di bagian Input Parameters, klik Add parameters.
-
Di kotak dialog yang muncul, atur nilainya ke parameter
outputsdari node assignment yang telah Anda buat. Tentukan Parameter Name kustom untuk parameter input node saat ini (misalnya,param).CatatanSetelah Anda mengonfigurasi parameter, dependensi secara otomatis dibuat antara node hilir dan node assignment hulu.
-
Setelah mengonfigurasi parameter, Anda dapat menggunakan format
${param}dalam kode node Shell hilir untuk mereferensikan nilai yang diteruskan dari node hulu.
-
-
Jalankan dan verifikasi
-
Kembali ke kanvas workflow. Di bilah alat, klik Deploy dan pilih Full Deployment.
-
Buka dan jalankan smoke test pada workflow target.
-
Di instans pengujian, periksa apakah hasil akhir sesuai harapan.
-
Buat node assignment menggunakan OpenAPI
Selain menggunakan konsol, Anda dapat membuat node assignment dengan memanggil operasi DataWorks OpenAPI CreateNode. Saat membuat node melalui API, Anda harus mengonfigurasi informasi node dalam parameter Spec FlowSpec.
Untuk bind resource group, tentukan identifier resource group di field runtimeResource.resourceGroup dalam FlowSpec. Kode berikut memberikan contohnya:
{
"version": "1.1.0",
"kind": "Node",
"spec": {
"nodes": [
{
"recurrence": "Normal",
"script": {
"runtime": {
"command": "CONTROLLER_ASSIGNMENT"
},
"content": "print '10,20,30'"
},
"runtimeResource": {
"resourceGroup": "S_res_group_XXX_XXXX"
},
"name": "assignment_node_demo"
}
]
}
}Jika Anda menggunakan kode kustom untuk memanggil API, pastikan parameter diteruskan dengan cara yang sama seperti SDK resmi Alibaba Cloud. Jika tidak, bind resource group mungkin gagal berlaku meskipun parameter diteruskan dengan benar.
Batasan
-
Tingkat penerusan: Node assignment hanya dapat meneruskan parameter ke node anak hilir langsungnya, tidak lintas beberapa tingkat.
-
Batas ukuran: Ukuran nilai maksimum adalah 2 MB. Jika output pernyataan assignment melebihi batas ini, node assignment akan gagal.
-
Batasan sintaksis:
-
Komentar tidak didukung dalam kode node assignment. Menyertakan komentar dapat menyebabkan hasil yang tidak diharapkan.
-
Klausa WITH tidak didukung dalam mode MaxCompute SQL.
-
Contoh berdasarkan bahasa
Format data output (outputs) dan cara node hilir mereferensikannya sedikit berbeda tergantung bahasa node assignment. Contoh berikut menggunakan node Shell sebagai node hilir untuk mengilustrasikan perbedaan tersebut.
Contoh 1: Teruskan hasil kueri MaxCompute SQL
Hasil kueri SQL diteruskan ke node hilir sebagai array dua dimensi.
-
Konfigurasi node hulu (node assignment - SQL)
Asumsikan kode SQL berikut mengembalikan dua baris dan dua kolom:
SELECT 'beijing', '1001' UNION ALL SELECT 'hangzhou', '1002'; -
Konfigurasi dan output node hilir (node Shell)
Di node Shell, tambahkan parameter input bernama
regionyang mereferensikanoutputsdari node SQL hulu.Tulis kode berikut untuk membaca data:
echo "Full result set: ${region}" echo "First row: ${region[0]}" echo "Second field of the first row: ${region[0][1]}"DataWorks langsung mengurai parameter dan melakukan penggantian statis. Output waktu proses adalah sebagai berikut:
Full result set: beijing,1001 hangzhou,1002 First row: beijing,1001 Second field of the first row: 1001
Contoh 2: Teruskan hasil output Python 2
Output pernyataan print Python 2 dipisahkan berdasarkan koma (,) dan diteruskan ke node hilir sebagai array satu dimensi.
-
Konfigurasi node hulu (node assignment - Python 2)
Kode Python 2 adalah sebagai berikut:
print 'Electronics, Clothing, Books'; -
Konfigurasi dan output node hilir (node Shell)
Di node Shell, tambahkan parameter input bernama
typesyang mereferensikanoutputsdari node assignment hulu.Tulis kode berikut untuk membaca data:
# Print the entire one-dimensional array echo "Full result set: ${types}" # Print an element from the array by index echo "Second element: ${types[1]}"DataWorks langsung mengurai parameter dan melakukan penggantian statis. Output waktu proses adalah sebagai berikut:
Full result set: Electronics,Clothing,Books Second element: Clothing
Logika pemrosesan untuk node Shell mirip dengan node Python 2 dan tidak diulang di sini.
Kasus penggunaan: Pemrosesan batch data terpartisi
Contoh ini menunjukkan cara menggunakan node assignment dan node for-each untuk memproses batch data perilaku pengguna dari beberapa lini bisnis. Hal ini memungkinkan Anda menerapkan pemrosesan data otomatis untuk beberapa lini produk dengan satu set logika saja.
Latar belakang
Asumsikan Anda adalah insinyur data di perusahaan internet besar yang bertanggung jawab memproses data dari tiga lini bisnis inti: e-dagang (ecom), keuangan (finance), dan logistik (logistics). Lebih banyak lini bisnis mungkin ditambahkan di masa depan. Anda perlu menjalankan logika agregasi harian yang sama pada log perilaku pengguna untuk lini bisnis ini guna menghitung PV (page view) untuk setiap pengguna dan menyimpan hasilnya di tabel ringkasan terpadu.
-
Tabel sumber hulu (lapisan DWD):
-
dwd_user_behavior_ecom_d: Tabel perilaku pengguna e-dagang. -
dwd_user_behavior_finance_d: Tabel perilaku pengguna keuangan. -
dwd_user_behavior_logistics_d: Tabel perilaku pengguna logistik. -
dwd_user_behavior_${biz_line}_d: Tabel perilaku pengguna untuk lini bisnis potensial lainnya. -
Tabel-tabel ini memiliki struktur yang sama dan dipartisi berdasarkan hari (
dt).
-
-
Tabel target hilir (lapisan DWS):
-
dws_user_summary_d: Tabel ringkasan pengguna. -
Tabel ini dipartisi berdasarkan lini bisnis (
biz_line) dan hari (dt) untuk menyimpan hasil agregasi dari semua lini bisnis.
-
Membuat tugas terpisah untuk setiap lini bisnis sulit dipelihara dan rentan kesalahan. Menggunakan node for-each menyederhanakan pemeliharaan karena Anda hanya perlu memelihara satu set logika pemrosesan, dan sistem secara otomatis melakukan iterasi melalui semua lini bisnis untuk menyelesaikan perhitungan.
Persiapan data
Pertama, buat tabel sampel dan masukkan data uji. Contoh ini menggunakan tanggal bisnis 20251010.
-
Bind compute engine MaxCompute ke workspace.
-
Buka Data Studio dan buat node MaxCompute SQL.
-
Buat tabel sumber (lapisan DWD): Tambahkan kode berikut ke node MaxCompute SQL, pilih, lalu jalankan.
-- Tabel perilaku pengguna e-dagang CREATE TABLE IF NOT EXISTS dwd_user_behavior_ecom_d ( user_id STRING COMMENT 'User ID', action_type STRING COMMENT 'Action type', event_time BIGINT COMMENT 'UNIX timestamp of the event in milliseconds' ) COMMENT 'Detailed e-commerce user behavior log table' PARTITIONED BY (dt STRING COMMENT 'Date partition, format yyyymmdd'); INSERT OVERWRITE TABLE dwd_user_behavior_ecom_d PARTITION (dt='20251010') VALUES ('user001', 'click', 1760004060000), -- 2025-10-10 10:01:00.000 ('user002', 'browse', 1760004150000), -- 2025-10-10 10:02:30.000 ('user001', 'add_to_cart', 1760004300000); -- 2025-10-10 10:05:00.000 -- Verifikasi bahwa tabel perilaku pengguna e-dagang telah dibuat. SELECT * FROM dwd_user_behavior_ecom_d where dt='20251010'; -- Tabel perilaku pengguna keuangan CREATE TABLE IF NOT EXISTS dwd_user_behavior_finance_d ( user_id STRING COMMENT 'User ID', action_type STRING COMMENT 'Action type', event_time BIGINT COMMENT 'UNIX timestamp of the event in milliseconds' ) COMMENT 'Detailed finance user behavior log table' PARTITIONED BY (dt STRING COMMENT 'Date partition, format yyyymmdd'); INSERT OVERWRITE TABLE dwd_user_behavior_finance_d PARTITION (dt='20251010') VALUES ('user003', 'open_app', 1760020200000), -- 2025-10-10 14:30:00.000 ('user003', 'transfer', 1760020215000), -- 2025-10-10 14:30:15.000 ('user003', 'check_balance', 1760020245000), -- 2025-10-10 14:30:45.000 ('user004', 'open_app', 1760020300000); -- 2025-10-10 14:31:40.000 -- Verifikasi bahwa tabel perilaku pengguna keuangan telah dibuat. SELECT * FROM dwd_user_behavior_finance_d where dt='20251010'; -- Tabel perilaku pengguna logistik CREATE TABLE IF NOT EXISTS dwd_user_behavior_logistics_d ( user_id STRING COMMENT 'User ID', action_type STRING COMMENT 'Action type', event_time BIGINT COMMENT 'UNIX timestamp of the event in milliseconds' ) COMMENT 'Detailed logistics user behavior log table' PARTITIONED BY (dt STRING COMMENT 'Date partition, format yyyymmdd'); INSERT OVERWRITE TABLE dwd_user_behavior_logistics_d PARTITION (dt='20251010') VALUES ('user001', 'check_status', 1760032800000), -- 2025-10-10 18:00:00.000 ('user005', 'schedule_pickup', 1760032920000); -- 2025-10-10 18:02:00.000 -- Verifikasi bahwa tabel perilaku pengguna logistik telah dibuat. SELECT * FROM dwd_user_behavior_logistics_d where dt='20251010'; -
Buat tabel target (lapisan DWS): Tambahkan kode berikut ke node MaxCompute SQL, pilih, lalu jalankan.
CREATE TABLE IF NOT EXISTS dws_user_summary_d ( user_id STRING COMMENT 'User ID', pv BIGINT COMMENT 'PV' ) COMMENT 'User daily PV summary table' PARTITIONED BY ( dt STRING COMMENT 'Date partition, format yyyymmdd', biz_line STRING COMMENT 'Business line partition, such as ecom, finance, logistics' );PentingJika workspace berada di Standard Edition, Anda harus deploy node ini ke lingkungan produksi dan lakukan pengisian ulang data.
Implementasi workflow
-
Buat workflow. Di panel Scheduling Parameters di sebelah kanan, atur scheduling parameter bizdate ke hari sebelumnya:
$[yyyymmdd-1]. -
Di workflow, buat node assignment bernama get_biz_list dan gunakan bahasa MaxCompute SQL untuk menulis kode berikut. Node ini mengeluarkan daftar lini bisnis yang akan diproses:
-- Output all business lines to be processed SELECT 'ecom' AS biz_line UNION ALL SELECT 'finance' AS biz_line UNION ALL SELECT 'logistics' AS biz_line; -
Konfigurasikan node for-each
-
Kembali ke kanvas workflow dan buat node for-each hilir untuk node assignment get_biz_list.
-
Buka halaman pengaturan node for-each. Di panel scheduling configuration di sebelah kanan, di bawah , bind parameter loopDataArray ke outputs dari node get_biz_list.
-
Di badan loop node for-each, klik Create Internal Node untuk membuat node MaxCompute SQL, lalu tulis logika pemrosesan untuk badan loop.
Catatan-
Skrip ini dikendalikan oleh node for-each dan dijalankan sekali untuk setiap lini bisnis.
-
Saat waktu proses, variabel bawaan ${dag.foreach.current} diganti secara dinamis dengan nama lini bisnis saat ini. Nilai iterasi yang diharapkan adalah 'ecom', 'finance', dan 'logistics'.
SET odps.sql.allow.dynamic.partition=true; INSERT OVERWRITE TABLE dws_user_summary_d PARTITION (dt='${bizdate}', biz_line) SELECT user_id, COUNT(*) AS pv, '${dag.foreach.current}' AS biz_line FROM dwd_user_behavior_${dag.foreach.current}_d WHERE dt = '${bizdate}' GROUP BY user_id; -
-
-
Tambahkan node verifikasi
Kembali ke workflow. Klik Create Downstream Node untuk node for-each guna membuat node MaxCompute SQL dan tambahkan kode berikut.
SELECT * FROM dws_user_summary_d WHERE dt='20251010' ORDER BY biz_line, user_id;
Penyebaran dan hasil
Deploy workflow ke lingkungan produksi. Buka , temukan workflow target, lalu jalankan smoke test dengan tanggal bisnis diatur ke '20251010'.
Setelah eksekusi selesai, lihat log eksekusi di instans pengujian. Node terakhir harus menghasilkan output berikut:
|
user_id |
pv |
dt |
biz_line |
|
user001 |
2 |
20251010 |
ecom |
|
user002 |
1 |
20251010 |
ecom |
|
user003 |
3 |
20251010 |
finance |
|
user004 |
1 |
20251010 |
finance |
|
user001 |
1 |
20251010 |
logistics |
|
user005 |
1 |
20251010 |
logistics |
Keunggulan
-
Skalabilitas tinggi: Untuk menambahkan lini bisnis baru, Anda hanya perlu menambahkan satu baris SQL ke node assignment. Logika pemrosesan tidak perlu diubah.
-
Pemeliharaan mudah: Semua lini bisnis berbagi logika pemrosesan yang sama. Perubahan di satu tempat berlaku untuk semuanya.
FAQ
-
T: Mengapa saya mendapatkan error "find no select sql in sql assignment!" saat menggunakan MaxCompute SQL?
J: Error ini terjadi karena skrip MaxCompute SQL tidak memiliki pernyataan
SELECT. Tambahkan pernyataanSELECTuntuk mengatasi masalah ini. Perhatikan bahwa klausa WITH tidak didukung, dan penggunaannya juga akan memicu error ini. -
T: Mengapa saya mendapatkan error "OutPut Result is null, cannot handle!" saat menggunakan Shell atau Python?
J: Error ini menunjukkan bahwa skrip tidak menghasilkan output. Pastikan kode Anda mencakup pernyataan output, seperti
printuntuk Python atauechountuk Shell. -
T: Bagaimana cara menangani elemen output yang berisi koma di Shell atau Python?
J: Anda harus melakukan escape terhadap koma (
,) dengan menggantinya menjadi\,. Kode Python berikut memberikan contohnya.categories = ["Electronics", "Clothing, Shoes & Accessories"] # Escape the comma in each element. # Replace ',' with '\,'. escaped_categories = [cat.replace(",", "\,") for cat in categories] # Join the escaped elements with a comma. output_string = ",".join(escaped_categories) print output_string # The final string passed to the downstream node is: # Electronics,Clothing\, Shoes & Accessories -
T: Apakah node hilir dapat menerima hasil dari beberapa node assignment hulu?
J: Ya. Anda dapat menetapkan hasil dari node berbeda ke parameter berbeda.
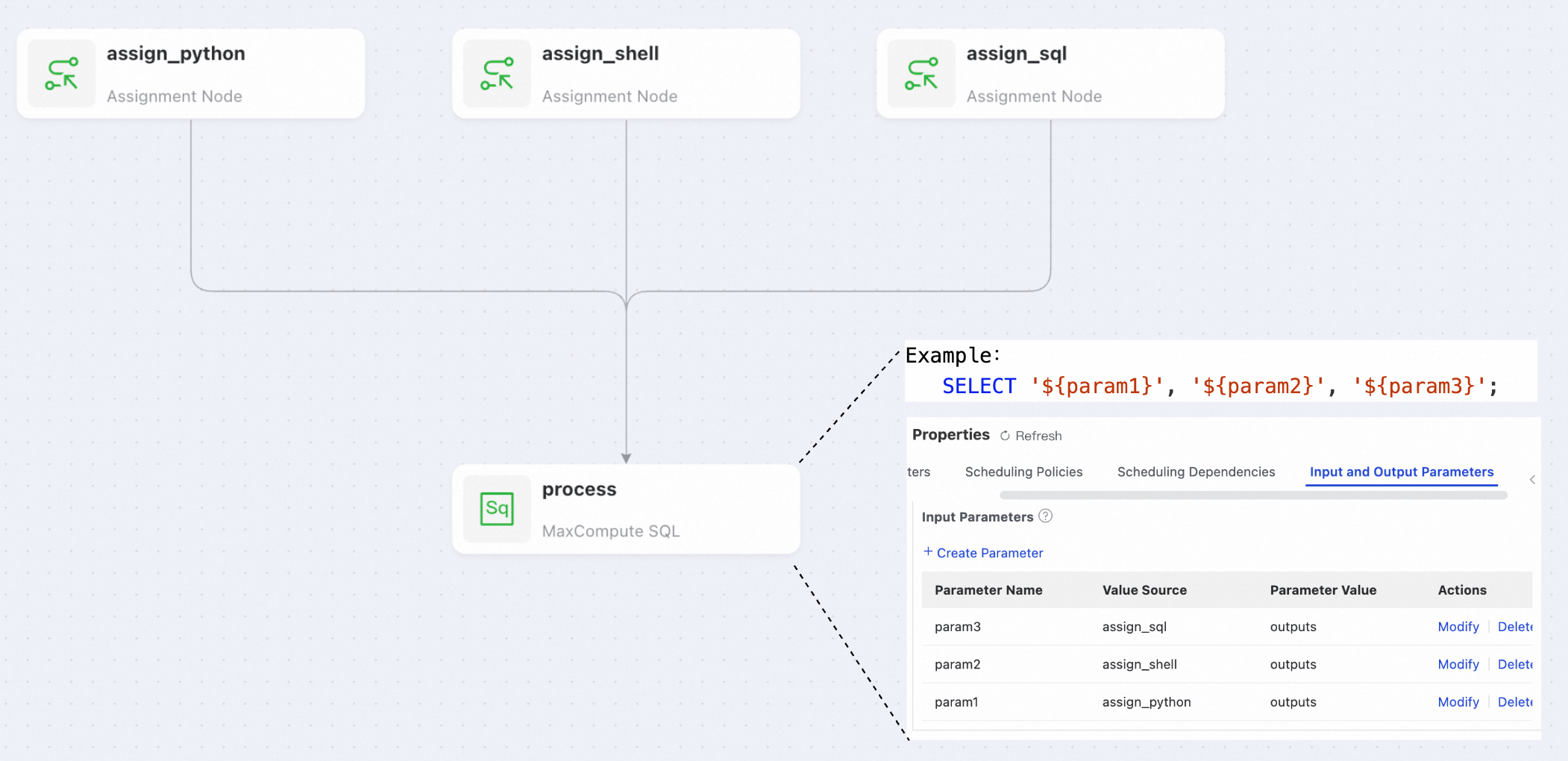
-
T: Apakah node assignment mendukung jenis bahasa lain?
J: Node assignment saat ini hanya mendukung MaxCompute SQL, Python 2, dan Shell. Namun, beberapa jenis node lain, seperti EMR Hive, Hologres SQL, EMR Spark SQL, AnalyticDB for PostgreSQL, ClickHouse SQL, dan MySQL, memiliki fitur bawaan parameter assignment yang mencapai hasil yang sama.
Di bagian Output Parameters, klik Add Assignment Parameter.
Topik terkait
-
Jika node hilir Anda perlu melakukan loop melalui hasil, lihat node for-each dan node do-while.
-
Untuk meneruskan parameter lintas beberapa tingkat dalam workflow, lihat node parameter.
-
Untuk informasi selengkapnya tentang mengonfigurasi penyerahan parameter, lihat Node context parameters.