The sidecar mode injects a dedicated LoongCollector (Logtail) container into each application pod for per-pod log collection. Use this mode when you need fine-grained control, multi-tenant isolation, or lifecycle-bound log collection.
How it works
In sidecar mode, the application container and a LoongCollector (Logtail) container run side-by-side in a pod, sharing volumes for log access and lifecycle synchronization.
-
Log sharing: The application container writes logs to a shared volume (typically an
emptyDir), which the LoongCollector (Logtail) container mounts read-only to collect in real time. -
Configuration association: Each LoongCollector (Logtail) sidecar declares its identity through a unique
custom identifier. A machine group in the SLS console with the same identifier distributes collection configurations to all matching sidecar instances. -
Lifecycle synchronization: Signal files (
cornerstoneandtombstone) in the shared volume coordinate container shutdown. Combined with thegraceful termination period(terminationGracePeriodSeconds), this ensures LoongCollector (Logtail) finishes sending remaining logs before the pod exits.
Before you begin
Create a Project and a logstore to store your logs. If you already have them, skip to Step 1: Inject the LoongCollector Sidecar Container.
-
Project: A resource management unit in SLS that isolates logs by project or service.
-
logstore: A storage unit for logs.
Create a project
Create a logstore
-
Click the name of your Project.
-
In the left-side navigation pane, choose
 , and then click +.
, and then click +. -
On the Create logstore page, configure the following core settings:
-
Logstore Name: Must be unique within the Project. Cannot be changed after creation.
-
Logstore Type: Select Standard or Query based on the feature comparison.
-
Billing Mode:
-
Pay-by-feature: Billed independently for storage, indexing, and read/write operations. Ideal for small-scale or unpredictable usage.
-
Pay-by-ingested-data: Billed only for raw data ingested. Includes 30 days of free storage and free data processing and shipping. Ideal when retention is around 30 days or pipelines are complex.
-
-
Data Retention Period: Log retention in days. Range: 1 to 3,650 (3,650 = permanent). Default: 30.
-
Leave the other parameters at their default settings and click OK. Other parameters are described in Manage logstore.
-
Step 1: Inject the LoongCollector sidecar container
Inject a LoongCollector sidecar container into your application pod with a shared volume for log collection. For a quick test, use the Appendix: YAML example.
1. Modify the pod YAML configuration
-
Define shared volumes
In
spec.template.spec.volumes, add three shared volumes at the same level ascontainers:volumes: # Shared log directory (written by the application container, read by the sidecar) - name: ${shared_volume_name} # <-- The name must match the name in volumeMounts emptyDir: {} # Signal directory for inter-container communication (for graceful start/stop) - name: tasksite emptyDir: medium: Memory # Use memory as the medium for better performance sizeLimit: "50Mi" # Shared host time zone configuration: Synchronizes the time zone for all containers in the pod - name: tz-config # <-- The name must match the name in volumeMounts hostPath: path: /usr/share/zoneinfo/Asia/Shanghai # Modify the time zone as needed -
Configure application container mounts
In the
volumeMountssection of your application container, such asyour-business-app-container, add the following volume mounts:Ensure that the application container writes logs to the
${shared_volume_path}directory so that LoongCollector can collect them.volumeMounts: # Mount the shared log volume to the application log output directory - name: ${shared_volume_name} mountPath: ${shared_volume_path} # Example: /var/log/app # Mount the communication directory - name: tasksite mountPath: /tasksite # Shared directory for communication with the LoongCollector container # Mount the timezone file - name: tz-config mountPath: /etc/localtime readOnly: true -
Inject the LoongCollector sidecar container
In the
spec.template.spec.containersarray, append the following sidecar container definition:- name: loongcollector image: aliyun-observability-release-registry.cn-shenzhen.cr.aliyuncs.com/loongcollector/loongcollector:v3.1.1.0-20fa5eb-aliyun command: ["/bin/bash", "-c"] args: - | echo "[$(date)] LoongCollector: Starting initialization" # Start the LoongCollector service /etc/init.d/loongcollectord start # Wait for the configuration to download and the service to be ready sleep 15 # Verify the service status if /etc/init.d/loongcollectord status; then echo "[$(date)] LoongCollector: Service started successfully" touch /tasksite/cornerstone else echo "[$(date)] LoongCollector: Failed to start service" exit 1 fi # Wait for the application container to complete (via the tombstone file signal) echo "[$(date)] LoongCollector: Waiting for application container to complete" until [[ -f /tasksite/tombstone ]]; do sleep 2 done # Allow time to upload remaining logs echo "[$(date)] LoongCollector: Business completed, waiting for log transmission" sleep 30 # Stop the service echo "[$(date)] LoongCollector: Stopping service" /etc/init.d/loongcollectord stop echo "[$(date)] LoongCollector: Shutdown complete" # health check livenessProbe: exec: command: ["/etc/init.d/loongcollectord", "status"] initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 failureThreshold: 3 # resource configuration resources: requests: cpu: "100m" memory: "128Mi" limits: cpu: "2000m" memory: "2048Mi" # environment variable configuration env: - name: ALIYUN_LOGTAIL_USER_ID value: "${your_aliyun_user_id}" - name: ALIYUN_LOGTAIL_USER_DEFINED_ID value: "${your_machine_group_user_defined_id}" - name: ALIYUN_LOGTAIL_CONFIG value: "/etc/ilogtail/conf/${your_region_config}/ilogtail_config.json" # Enable full drain mode to ensure all logs are sent before the pod terminates - name: enable_full_drain_mode value: "true" # Append pod environment information as log tags - name: ALIYUN_LOG_ENV_TAGS value: "_pod_name_|_pod_ip_|_namespace_|_node_name_|_node_ip_" # Automatically inject pod and node metadata as log tags - name: "_pod_name_" valueFrom: fieldRef: fieldPath: metadata.name - name: "_pod_ip_" valueFrom: fieldRef: fieldPath: status.podIP - name: "_namespace_" valueFrom: fieldRef: fieldPath: metadata.namespace - name: "_node_name_" valueFrom: fieldRef: fieldPath: spec.nodeName - name: "_node_ip_" valueFrom: fieldRef: fieldPath: status.hostIP # Volume mounts (shared with the application container) volumeMounts: # Read-only mount for the application log directory - name: ${shared_volume_name} # <-- Shared log directory name mountPath: ${dir_containing_your_files} # <-- Path to the shared directory in the sidecar readOnly: true # Mount the communication directory - name: tasksite mountPath: /tasksite # Mount the timezone - name: tz-config mountPath: /etc/localtime readOnly: true
2. Adapt the application container lifecycle logic
Depending on the workload type, modify the application container to support a coordinated exit with the sidecar:
Short-lived tasks (Job/CronJob)
# 1. Wait for LoongCollector to be ready
echo "[$(date)] Application: Waiting for LoongCollector to be ready..."
until [[ -f /tasksite/cornerstone ]]; do
sleep 1
done
echo "[$(date)] Application: LoongCollector is ready, starting application logic"
# 2. Execute core application logic (ensure logs are written to the shared directory)
echo "Hello, World!" >> /app/logs/business.log
# 3. Save the exit code
retcode=$?
echo "[$(date)] Application: Task completed with exit code: $retcode"
# 4. Notify LoongCollector that the application task is complete
touch /tasksite/tombstone
echo "[$(date)] Application: Tombstone created, exiting"
exit $retcodeLong-lived services (Deployment / StatefulSet)
# Define the signal handler function
_term_handler() {
echo "[$(date)] [nginx-demo] Caught SIGTERM, starting graceful shutdown..."
# Send a QUIT signal to Nginx for a graceful stop
if [ -n "$NGINX_PID" ]; then
kill -QUIT "$NGINX_PID" 2>/dev/null || true
echo "[$(date)] [nginx-demo] Sent SIGQUIT to Nginx PID: $NGINX_PID"
# Wait for Nginx to stop gracefully
wait "$NGINX_PID"
EXIT_CODE=$?
echo "[$(date)] [nginx-demo] Nginx stopped with exit code: $EXIT_CODE"
fi
# Notify LoongCollector that the application container has stopped
echo "[$(date)] [nginx-demo] Writing tombstone file"
touch /tasksite/tombstone
exit $EXIT_CODE
}
# Register the signal handler
trap _term_handler SIGTERM SIGINT SIGQUIT
# Wait for LoongCollector to be ready
echo "[$(date)] [nginx-demo]: Waiting for LoongCollector to be ready..."
until [[ -f /tasksite/cornerstone ]]; do
sleep 1
done
echo "[$(date)] [nginx-demo]: LoongCollector is ready, starting application logic"
# Start Nginx
echo "[$(date)] [nginx-demo] Starting Nginx..."
nginx -g 'daemon off;' &
NGINX_PID=$!
echo "[$(date)] [nginx-demo] Nginx started with PID: $NGINX_PID"
# Wait for the Nginx process
wait $NGINX_PID
EXIT_CODE=$?
# Also notify LoongCollector if the exit was not caused by a signal
if [ ! -f /tasksite/tombstone ]; then
echo "[$(date)] [nginx-demo] Unexpected exit, writing tombstone"
touch /tasksite/tombstone
fi
exit $EXIT_CODE3. Set the termination grace period
In spec.template.spec, set a termination grace period that is long enough to allow LoongCollector to upload all remaining logs.
spec:
# ... Your other existing spec configurations ...
template:
spec:
terminationGracePeriodSeconds: 600 # 10-minute graceful stop period4. Variables
|
Parameter |
Description |
|
|
The ID of your Alibaba Cloud account. Configure user identifiers. |
|
|
A custom identifier used to create a machine group. Example: Important
Ensure that this identifier is unique within the Project's region. |
|
|
The configuration that corresponds to your SLS Project's region and network access type. Service regions. Example: If your Project is in the China (Hangzhou) region, use |
|
|
A custom name for the shared volume. Important
The |
|
|
The mount path in the LoongCollector container where the text logs are located. |
5. Apply configuration and verify
-
Run the following command to deploy the changes:
kubectl apply -f <YOUR-YAML> -
Check the pod status to confirm that the LoongCollector container was injected successfully:
kubectl describe pod <YOUR-POD-NAME>If you see two containers (the application container and
loongcollector) and their status is Running, the injection is successful.
Step 2: Create a custom-identifier machine group
This step registers LoongCollector sidecar instances with SLS for centralized collection configuration management.
Procedure
-
Create a machine group
-
Go to the target project. In the left-side navigation pane, click
 .
. -
On the Machine Groups page, click
 > Create Machine Group.
> Create Machine Group.
-
-
Configure the machine group
Configure the following parameters and click OK:
-
Name: The name of the machine group. Cannot be changed after creation. The name must meet the following requirements:
-
Contain only lowercase letters, digits, hyphens (-), and underscores (_).
-
Start and end with a lowercase letter or a digit.
-
Be 2 to 128 characters long.
-
-
Machine Group Identifier: Select Custom Identifier.
-
Custom Identifier: Enter the value of the
ALIYUN_LOGTAIL_USER_DEFINED_IDenvironment variable that you set for the LoongCollector container in the YAML file in Step 1. The value must match exactly. Otherwise, the association will fail.
-
-
Check the machine group heartbeat status
After creating the machine group, click its name to check the heartbeat status in the Machine Group Status section.
-
OK: LoongCollector has connected to SLS, and the machine group is registered.
-
FAIL:
-
The configuration change may take up to two minutes to take effect. Refresh the page and check the status again.
-
If the status is still FAIL after two minutes, see Troubleshoot Logtail machine group issues.
-
-
Each pod corresponds to a separate LoongCollector instance. For fine-grained management, use different custom identifiers for different applications or environments.
Step 3: Create a collection configuration
A collection configuration specifies which log files LoongCollector collects, how to parse them, and which content to filter.
Procedure
-
On the
 Logstore page, click the
Logstore page, click the  before the target Logstore name to expand.
before the target Logstore name to expand. -
Click
 next to Data Collection. In the Quick Data Import dialog box, find the Kubernetes - File card and click Integrate Now.
next to Data Collection. In the Quick Data Import dialog box, find the Kubernetes - File card and click Integrate Now. -
Configure the Machine Group Configurations, and then click Next.
-
Scenario: Select Kubernetes Clusters.
-
Deployment Method: Select Sidecar.
-
Select Machine Group: In the Source Machine Group list, select the machine group you created in Step 2. Click
 to move it to the Applied Machine Group list.
to move it to the Applied Machine Group list.
-
-
On the Logtail Configurations page, configure the Logtail collection rules.
1. Global and input configurations
Define the name, log source, and collection scope for the collection configuration.
Global Configurations:
-
Configuration Name: A custom name for the collection configuration. This name must be unique within the project and cannot be changed after it is created. Naming conventions:
-
Can contain only lowercase letters, digits, hyphens (-), and underscores (_).
-
Must start and end with a lowercase letter or a digit.
-
Input Configurations:
-
Type: Select Text Log Collection.
-
Logtail Deployment Mode: Select Sidecar.
-
File Path Type:
-
Path in Container: Collect log files from within a container.
-
Host Path: Collect local service logs from the host.
-
-
File Path: The path for log collection.
-
Linux: The path must start with a forward slash (/). For example,
/data/mylogs/**/*.logspecifies all files that have the .log extension in the/data/mylogsdirectory and its subdirectories. -
Windows: The path must start with a drive letter, such as
C:\Program Files\Intel\**\*.Log.
-
-
Maximum Directory Monitoring Depth: Specifies the maximum directory depth for the
**wildcard in the File Path. The default value of 0 monitors only the current directory.
2. Log processing and structuring
Configure log processing rules to transform raw, unstructured logs into structured, searchable data. This improves the efficiency of log queries and analysis. First, add a log sample:
In the Processor Configurations section of the Logtail Configuration page, click Add Sample Log and enter the log content to be collected. The system identifies the log format based on the sample and helps generate regular expressions and parsing rules, which simplifies the configuration.
Use case 1: Process multiline logs (such as Java stack logs)
Because logs such as Java exception stacks and JSON objects often span multiple lines, the default collection mode splits them into multiple incomplete records, which causes a loss of context. To prevent this, enable multiline mode and configure a Regex to Match First Line to merge consecutive lines of the same log into a single, complete log.
Example:
|
Raw log without any processing |
In default collection mode, each line is a separate log, breaking the stack trace and losing context |
With multiline mode enabled, a Regex to Match First Line identifies the complete log, preserving its full semantic structure. |
|
|
|
|



Procedure: In the Processor Configurations section of the Logtail Configuration page, enable Multi-line Mode:
-
For Type, select Custom or Multi-line JSON.
-
Custom: For raw logs with a variable format, configure a Regex to Match First Line to identify the starting line of each log.
-
Regex to Match First Line: Automatically generate or manually enter a regular expression that matches a complete line of data. For example, the regular expression for the preceding example is
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*.-
Automatic generation: Click Generate. Then, in the Log Sample text box, select the log content that you want to extract and click Automatically Generate.
-
Manual entry: Click Manually Enter Regular Expression. After you enter the expression, click Validate.
-
-
-
Multi-line JSON: SLS automatically handles line breaks within a single raw log if the log is in standard JSON format.
-
-
Processing Method If Splitting Fails:
-
Discard: Discards a text segment if it does not match the start-of-line rule.
-
Retain Single Line: Retains unmatched text on separate lines.
-
Scenario 2: Structured logs
When raw logs are unstructured or semi-structured text, such as NGINX access logs or application output logs, direct querying and analysis are often inefficient. SLS provides various data parsing plugins that can automatically convert raw logs of different formats into structured data. This provides a solid data foundation for subsequent analysis, monitoring, and alerting.
Example:
|
Raw log |
Structured log |
|
|
Configuration steps: In the Processor Configurations area of the Logtail Configurations page:
-
Add a parsing plugin: Click Add Processor, and configure a plugin such as a regular expression, delimiter, or JSON parsing plugin based on your log format. For example, to collect NGINX logs, select .
-
NGINX Log Configuration: Copy the entire
log_formatdefinition from your Nginx server's configuration file (nginx.conf) and paste it into this text box.Example:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';ImportantThe format definition must exactly match the log_format on your server. Otherwise, parsing will fail.
-
General configuration parameter descriptions: The following parameters are common to many parsing plugins and have consistent functions.
-
Original Field: Specifies the source field to be parsed. Defaults to
content, which is the entire collected log entry. -
Retain Original Field if Parsing Fails: Recommended. If the plugin fails to parse a log, this option retains the raw log content in the original field.
-
Retain Original Field if Parsing Succeeds: If selected, this option retains the raw log content even after successful parsing.
-
3. Log filtering
Collecting large volumes of low-value logs (such as DEBUG or INFO level) wastes storage, increases costs, reduces query efficiency, and poses data leakage risks. Configure filtering policies for efficient and secure log collection.
Content filtering
Filter fields based on log content, such as collecting only logs where the level is WARNING or ERROR.
Example:
|
Raw log without any processing |
Collect only |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page
Click Add Processor and select :
-
Field Name: The log field to use for filtering.
-
Field Value: The regular expression used for filtering. Only full matches are supported, not partial keyword matches.
Collection blacklist
Use a blacklist to exclude specified directories or files, which prevents irrelevant or sensitive logs from being uploaded.
Procedure: In the section of the Logtail Configuration page, enable Collection Blacklist and click Add.
Supports full and wildcard matching for directories and filenames. The only supported wildcard characters are the asterisk (*) and the question mark (?).
-
File Path Blacklist: Specifies the file paths to exclude. Examples:
-
/home/admin/private*.log: Ignores all files in the/home/admin/directory that start with private and end with .log. -
/home/admin/private*/*_inner.log: Ignores files that end with _inner.log within directories that start with private under the/home/admin/directory.
-
-
File Blacklist: A list of filenames to ignore during collection. Example:
-
app_inner.log: Ignores all files namedapp_inner.logduring collection.
-
-
Directory Blacklist: Directory paths cannot end with a forward slash (/). Examples:
-
/home/admin/dir1/: The directory blacklist will not take effect. -
/home/admin/dir*: Ignores files in all subdirectories that start with dir under the/home/admin/directory during collection. -
/home/admin/*/dir: Ignores all files in subdirectories named dir at the second level of the/home/admin/directory. For example, files in the/home/admin/a/dirdirectory are ignored, but files in the/home/admin/a/b/dirdirectory are collected.
-
Container filtering
Set collection conditions based on container metadata (environment variables, Pod labels, namespaces, container names) to control which containers' logs are collected.
Configuration steps: On the Logtail Configurations page, in the Input Configurations area, enable Container Filtering and click Add.
Multiple conditions have an "AND" relationship. All regular expression matching is based on Go's RE2 regular expression engine, which has some limitations compared to engines such as PCRE. Follow the guidelines in Appendix: Regular expression limits (container filtering) when you write regular expressions.
-
Environment variable blacklist/whitelist: Filter containers based on their environment variables.
-
K8s Pod label blacklist/whitelist: Filter containers based on the Pod labels of their host pods.
-
K8s Pod name regex match: Filter containers based on their Pod name.
-
K8s Namespace regex match: Filter containers based on their namespace.
-
K8s container name regex match: Filter containers based on their name.
-
Container label blacklist/whitelist: Filter containers based on their labels. This method is intended for Docker and is not recommended for Kubernetes.
4. Log classification
In scenarios where multiple applications share the same log format, distinguishing the log source can be difficult. Configure log topics and log tagging to automate context association and logical classification.
Log topics
When multiple applications have logs with the same format but different paths (such as /apps/app-A/run.log and /apps/app-B/run.log), generate a topic to differentiate logs from each service.
Procedure: : Select a method for generating topics. The following three types are supported:
-
Machine Group Topic: When a collection configuration is applied to multiple machine groups, LoongCollector automatically uses the name of the server's machine group as the
__topic__field for upload. This is suitable for use cases where logs are divided by host. -
Custom: Uses the format
customized://<custom_topic_name>, such ascustomized://app-login. This format is suitable for static topic use cases with fixed business identifiers. -
File Path Extraction: Extract key information from the full path of the log file to dynamically mark the log source. This is suitable for situations where multiple users or applications share the same log filename but have different paths. For example, when multiple users or services write logs to different top-level directories but the sub-paths and filenames are identical, the source cannot be distinguished by filename alone:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.logConfigure File Path Extraction and use a regular expression to extract key information from the full path. The matched result is then uploaded to the logstore as the topic.
File path extraction rule: Based on regular expression capturing groups
When you configure a regular expression, the system automatically determines the output field format based on the number and naming of capturing groups. The rules are as follows:
In the regular expression for a file path, you must escape the forward slash (/).
Capturing group type
Use case
Generated field
Regex example
Matching path example
Generated field example
Single capturing group (only one
(.*?))Only one dimension is needed to distinguish the source (such as username or environment)
Generates the
__topic__field\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__: userAMultiple capturing groups - unnamed (multiple
(.*?))Multiple dimensions are needed to distinguish the source, but no semantic tags are required
Generates a tag field
__tag__:__topic_{i}__, where{i}is the ordinal number of the capturing group\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA__tag__:__topic_2__svcAMultiple capturing groups - named (using
(?P<name>.*?)Multiple dimensions are needed to distinguish the source, and the field meanings should be clear for easy querying and analysis
Generates a tag field
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
Log tagging
Enable log tag enrichment to extract key information from container environment variables or Kubernetes Pod labels as tags for fine-grained log grouping.
Configuration steps: In the Input Configurations area of the Logtail Configurations page, enable Log Tag Enrichment and click Add.
-
Environment Variables: Configure the environment variable name and the tag name. The value of the environment variable is stored as the value of the tag.
-
Environment Variable Name: The name of the environment variable to extract.
-
Tag Name: The name of the tag.
-
-
Pod Labels: Configure the Pod label name and the tag name. The value of the Pod label is stored as the value of the tag.
-
Pod Label Name: The name of the Kubernetes Pod label to extract.
-
Tag Name: The name of the tag.
-
5. Output configuration
By default, all logs are sent to the current Logstore with lz4 compression. To distribute logs to multiple Logstores, configure additional output destinations.
Dynamic multi-destination distribution
-
Multi-destination distribution is available only for LoongCollector 3.0.0 and later. This feature is not supported by Logtail.
-
You can configure a maximum of five output destinations.
-
After you configure multiple output destinations, the collection configuration no longer appears in the list of collection configurations for the current Logstore. To view, modify, or delete a multi-destination distribution configuration, see Manage multi-destination distribution configurations.
Configuration steps: In the Output Configurations area of the Logtail Configurations page.
-
Click
 to expand the output configuration.
to expand the output configuration. -
Click Add Output Targets and complete the following configuration:
-
Logstores: Select the destination Logstore.
-
Compression Method: lz4 and zstd are supported.
-
Route Settings: Route logs based on tag fields. The system uploads matching logs to the destination Logstore. If this configuration is empty, the system uploads all collected logs to this destination.
-
Tag Name: The name of the tag field used for routing. Enter only the field name (for example,
__path__), without the__tag__:prefix. Tag fields fall into two categories:Tags are described in Manage LoongCollector collection tags.
-
Agent-related: Related to the collection agent and independent of plugins. Examples include
__hostname__and__user_defined_id__. -
Input plugin-related: Provided by input plugins to enrich logs with contextual information. Examples include
__path__for file collection and_pod_name_or_container_name_for Kubernetes collection.
-
-
Tag Value: If a log's tag field matches this value, the system sends the log to this destination Logstore.
-
Discard this tag?: If enabled, the system removes this tag field from logs before uploading them.
-
-
Step 4: Configure query and analysis
After you configure log processing and plugins, click Next to go to the Query and Analysis Configurations page:
-
Full-text index is enabled by default, which supports keyword searches on raw log content.
-
For precise queries by field, wait for the Preview Data to load, and then click Automatic Index Generation. SLS generates a field index based on the first entry in the preview data.
After the configuration is complete, click Next to finish setting up the entire collection process.
Step 5: View uploaded logs
After you create a collection configuration and apply it to a machine group, the system deploys it and starts collecting incremental logs.
-
Verify new log entries: LoongCollector collects only incremental logs. Run
tail -f /path/to/your/log/fileand use your application to generate new log entries. -
Query logs: Go to the Search & Analyze page of the target Logstore and click Search & Analyze. The default time range is the last 15 minutes. Check if new logs appear. The default fields for container text logs are as follows:
Parameter
Description
tag:hostname
The name of the container's host.
tag:path
The path of the log file in the container.
tag:container_ip
The IP address of the container.
tag:image_name
The name of the image used by the container.
NoteIf multiple images have the same hash but different names or tags, the collection configuration selects one of the names based on the hash. The selected name is not guaranteed to match the one defined in the YAML file.
tag:pod_name
The name of the pod.
tag:namespace
The namespace to which the pod belongs.
tag:pod_uid
The unique identifier (UID) of the pod.
Key configurations for log integrity
The following configuration parameters directly affect log collection integrity and reliability.
LoongCollector resource configuration
Proper resource configuration is essential for collection performance in high-volume scenarios. Key parameters:
# Configure CPU and memory resources based on the log generation rate
resources:
limits:
cpu: "2000m"
memory: "2Gi"
# Parameters that affect collection performance
env:
- name: cpu_usage_limit
value: "2"
- name: mem_usage_limit
value: "2048"
- name: max_bytes_per_sec
value: "209715200"
- name: process_thread_count
value: "8"
- name: send_request_concurrency
value: "20"
To configure Logtail based on your data volume, see Logtail network types, startup parameters, and configuration files.
Server-side quota configuration
Server-side quota limits or network issues can block data transmission, creating backpressure that affects log integrity. Use CloudLens for SLS to monitor Project resource quotas.
Initial collection configuration optimization
The initial file collection policy at pod startup affects log integrity, especially in high-throughput scenarios.
The initial collection size specifies where collection begins in a new file. Default: 1024 KB.
-
If a file is smaller than 1024 KB, collection starts from its beginning.
-
If a file is larger than 1024 KB, collection starts 1024 KB from its end.
-
The initial collection size can range from 0 to 10,485,760 KB (10 GB).
enable_full_drain_mode
This parameter ensures LoongCollector completes all data collection and transmission before terminating upon receiving a SIGTERM signal.
# Parameter that affects collection integrity
env:
- name: enable_full_drain_mode
value: "true" # Enable full drain mode
FAQ
Manage multi-destination distribution configurations
Multi-destination distribution configurations apply to multiple Logstores and must be managed at the Project level:
-
Log in to the Log Service console and click the name of the target Project.
-
On the target Project page, in the left-side navigation pane, click
 .Note
.NoteThis page centralizes management of all collection configurations within the Project, including those remaining after a Logstore is deleted.
Next steps
-
Data visualization: Use a visualization dashboard to monitor trends in key metrics.
-
Automated alerting for data anomalies: Set up alert policies to detect system anomalies in real time.
-
SLS collects only incremental logs. To collect historical logs, see Import historical log files.
Appendix: YAML example
This example shows a complete Kubernetes configuration with an Nginx application container and a LoongCollector sidecar container.
Before using this configuration, replace the following placeholders:
-
Replace
${your_aliyun_user_id}with your Alibaba Cloud account ID. -
Replace
${your_machine_group_user_defined_id}with the custom identifier of the machine group that you created in Step 3. The value must match exactly. -
Replace
${your_region_config}with the configuration name that matches the region and network type of your SLS project.Example: If your project is in the China (Hangzhou) region, use
cn-hangzhoufor internal network access orcn-hangzhou-internetfor public network access.
Short-lived tasks (Job/CronJob)
apiVersion: batch/v1
kind: Job
metadata:
name: demo-job
spec:
backoffLimit: 3
activeDeadlineSeconds: 3600
completions: 1
parallelism: 1
template:
spec:
restartPolicy: Never
terminationGracePeriodSeconds: 300
containers:
# Application container
- name: demo-job
image: debian:bookworm-slim
command: ["/bin/bash", "-c"]
args:
- |
# Wait for LoongCollector to be ready.
echo "[$(date)] Business: Waiting for LoongCollector to be ready..."
until [[ -f /tasksite/cornerstone ]]; do
sleep 1
done
echo "[$(date)] Business: LoongCollector is ready, starting business logic"
# Run the application logic.
echo "Hello, World!" >> /app/logs/business.log
# Save the exit code.
retcode=$?
echo "[$(date)] Business: Task completed with exit code: $retcode"
# Notify LoongCollector that the task is finished.
touch /tasksite/tombstone
echo "[$(date)] Business: Tombstone created, exiting"
exit $retcode
# Resource requests and limits
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500"
memory: "512Mi"
# volume mounts
volumeMounts:
- name: app-logs
mountPath: /app/logs
- name: tasksite
mountPath: /tasksite
# LoongCollector sidecar container
- name: loongcollector
image: aliyun-observability-release-registry.cn-hongkong.cr.aliyuncs.com/loongcollector/loongcollector:v3.1.1.0-20fa5eb-aliyun
command: ["/bin/bash", "-c"]
args:
- |
echo "[$(date)] LoongCollector: Starting initialization"
# Start the LoongCollector service.
/etc/init.d/loongcollectord start
# Wait for the configuration to download and the service to be ready.
sleep 15
# Verify the service status.
if /etc/init.d/loongcollectord status; then
echo "[$(date)] LoongCollector: Service started successfully"
touch /tasksite/cornerstone
else
echo "[$(date)] LoongCollector: Failed to start service"
exit 1
fi
# Wait for the application container to finish.
echo "[$(date)] LoongCollector: Waiting for business container to complete"
until [[ -f /tasksite/tombstone ]]; do
sleep 2
done
echo "[$(date)] LoongCollector: Business completed, waiting for log transmission"
# Allow sufficient time to send remaining logs.
sleep 30
echo "[$(date)] LoongCollector: Stopping service"
/etc/init.d/loongcollectord stop
echo "[$(date)] LoongCollector: Shutdown complete"
# health check
livenessProbe:
exec:
command: ["/etc/init.d/loongcollectord", "status"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
# Resource requests and limits
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
# environment variables
env:
- name: ALIYUN_LOGTAIL_USER_ID
value: "your-user-id"
- name: ALIYUN_LOGTAIL_USER_DEFINED_ID
value: "your-user-defined-id"
- name: ALIYUN_LOGTAIL_CONFIG
value: "/etc/ilogtail/conf/cn-hongkong/ilogtail_config.json"
- name: ALIYUN_LOG_ENV_TAGS
value: "_pod_name_|_pod_ip_|_namespace_|_node_name_"
# Inject pod metadata.
- name: "_pod_name_"
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: "_pod_ip_"
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: "_namespace_"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "_node_name_"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# volume mounts
volumeMounts:
- name: app-logs
mountPath: /app/logs
readOnly: true
- name: tasksite
mountPath: /tasksite
- name: tz-config
mountPath: /etc/localtime
readOnly: true
# Volume definitions
volumes:
- name: app-logs
emptyDir: {}
- name: tasksite
emptyDir:
medium: Memory
sizeLimit: "10Mi"
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
Long-lived services (Deployment / StatefulSet)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-demo
namespace: production
labels:
app: nginx-demo
version: v1.0.0
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
version: v1.0.0
spec:
terminationGracePeriodSeconds: 600 # 10-minute graceful shutdown period
containers:
# Application container - Web application
- name: nginx-demo
image: anolis-registry.cn-zhangjiakou.cr.aliyuncs.com/openanolis/nginx:1.14.1-8.6
# Startup command and signal handling
command: ["/bin/sh", "-c"]
args:
- |
# Define the signal handler.
_term_handler() {
echo "[$(date)] [nginx-demo] Caught SIGTERM, starting graceful shutdown..."
# Send the QUIT signal to Nginx for a graceful stop.
if [ -n "$NGINX_PID" ]; then
kill -QUIT "$NGINX_PID" 2>/dev/null || true
echo "[$(date)] [nginx-demo] Sent SIGQUIT to Nginx PID: $NGINX_PID"
# Wait for Nginx to stop gracefully.
wait "$NGINX_PID"
EXIT_CODE=$?
echo "[$(date)] [nginx-demo] Nginx stopped with exit code: $EXIT_CODE"
fi
# Notify LoongCollector that the application container has stopped.
echo "[$(date)] [nginx-demo] Writing tombstone file"
touch /tasksite/tombstone
exit $EXIT_CODE
}
# Register the signal handler.
trap _term_handler SIGTERM SIGINT SIGQUIT
# Wait for LoongCollector to be ready.
echo "[$(date)] [nginx-demo]: Waiting for LoongCollector to be ready..."
until [[ -f /tasksite/cornerstone ]]; do
sleep 1
done
echo "[$(date)] [nginx-demo]: LoongCollector is ready, starting business logic"
# Start Nginx.
echo "[$(date)] [nginx-demo] Starting Nginx..."
nginx -g 'daemon off;' &
NGINX_PID=$!
echo "[$(date)] [nginx-demo] Nginx started with PID: $NGINX_PID"
# Wait for the Nginx process to exit.
wait $NGINX_PID
EXIT_CODE=$?
# If the process exits without a signal, notify LoongCollector.
if [ ! -f /tasksite/tombstone ]; then
echo "[$(date)] [nginx-demo] Unexpected exit, writing tombstone"
touch /tasksite/tombstone
fi
exit $EXIT_CODE
# Resource requests and limits
resources:
requests:
cpu: "200m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
# volume mounts
volumeMounts:
- name: nginx-logs
mountPath: /var/log/nginx
- name: tasksite
mountPath: /tasksite
- name: tz-config
mountPath: /etc/localtime
readOnly: true
# LoongCollector sidecar container
- name: loongcollector
image: aliyun-observability-release-registry.cn-shenzhen.cr.aliyuncs.com/loongcollector/loongcollector:v3.1.1.0-20fa5eb-aliyun
command: ["/bin/bash", "-c"]
args:
- |
echo "[$(date)] LoongCollector: Starting initialization"
# Start the LoongCollector service.
/etc/init.d/loongcollectord start
# Wait for the configuration to download and the service to be ready.
sleep 15
# Verify the service status.
if /etc/init.d/loongcollectord status; then
echo "[$(date)] LoongCollector: Service started successfully"
touch /tasksite/cornerstone
else
echo "[$(date)] LoongCollector: Failed to start service"
exit 1
fi
# Wait for the application container to finish.
echo "[$(date)] LoongCollector: Waiting for business container to complete"
until [[ -f /tasksite/tombstone ]]; do
sleep 2
done
echo "[$(date)] LoongCollector: Business completed, waiting for log transmission"
# Allow sufficient time to send remaining logs.
sleep 30
echo "[$(date)] LoongCollector: Stopping service"
/etc/init.d/loongcollectord stop
echo "[$(date)] LoongCollector: Shutdown complete"
# health check
livenessProbe:
exec:
command: ["/etc/init.d/loongcollectord", "status"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
# Resource requests and limits
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "2000m"
memory: "2048Mi"
# environment variables
env:
- name: ALIYUN_LOGTAIL_USER_ID
value: "${your_aliyun_user_id}"
- name: ALIYUN_LOGTAIL_USER_DEFINED_ID
value: "${your_machine_group_user_defined_id}"
- name: ALIYUN_LOGTAIL_CONFIG
value: "/etc/ilogtail/conf/${your_region_config}/ilogtail_config.json"
# Enable full drain mode to send all logs when the pod stops.
- name: enable_full_drain_mode
value: "true"
# Append pod environment information as log tags.
- name: "ALIYUN_LOG_ENV_TAGS"
value: "_pod_name_|_pod_ip_|_namespace_|_node_name_|_node_ip_"
# Get pod and node information.
- name: "_pod_name_"
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: "_pod_ip_"
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: "_namespace_"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "_node_name_"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: "_node_ip_"
valueFrom:
fieldRef:
fieldPath: status.hostIP
# volume mounts
volumeMounts:
- name: nginx-logs
mountPath: /var/log/nginx
readOnly: true
- name: tasksite
mountPath: /tasksite
- name: tz-config
mountPath: /etc/localtime
readOnly: true
# Volume definitions
volumes:
- name: nginx-logs
emptyDir: {}
- name: tasksite
emptyDir:
medium: Memory
sizeLimit: "50Mi"
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
Appendix: Native processors
In the Processor Configurations section of the Logtail Configuration page, add processors to structure raw logs. To add a processing plugin to an existing collection configuration, follow these steps:
-
In the navigation pane on the left, choose
 Logstores and find the target logstore.
Logstores and find the target logstore. -
Click the
 icon before its name to expand the logstore.
icon before its name to expand the logstore. -
Click Logtail Configuration. In the configuration list, find the target Logtail configuration and click Manage Logtail Configuration in the Actions column.
-
On the Logtail configuration page, click Edit.
This section introduces only commonly used processing plugins that cover common log processing use cases. For more features, see Extended processors.
Rules for combining plugins (for LoongCollector / Logtail 2.0 and later):
-
Native and extended processors can be used independently or combined as needed.
-
Prioritize native processor because they offer better performance and higher stability.
-
When native features cannot meet your business needs, add extended processors after the configured native ones for supplementary processing.
Order constraint:
All plugins are executed sequentially in the order they are configured, which forms a processing chain. Note: All native processors must precede any extended processors. After you add an extended processor, you cannot add more native processors.
Regex parsing
Use regular expressions to extract fields from logs into key-value pairs for independent querying and analysis.
Example:
|
Raw log without any processing |
Using the regular expression parsing plugin |
|
|
Procedure: In the Processor Configurations section of the Logtail Configurations page, click Add Processor and select .
-
Regular Expression: A regular expression to match log content. You can generate it automatically or enter it manually.
-
Auto-generate:
-
Click Generate.
-
In the Log Sample box, select the log content to extract.
-
Click Generate Regular Expression.
For example, if you paste a log in Apache Combined format into the Log Sample box, it will contain fields such as client IP, timestamp, request method and path, status code, Referer, and User-Agent.
-
-
Manual entry: Manually Enter Regular Expression based on the log format.
After entering the expression, click Validate to test if it correctly parses the log content.
-
-
Extracted Field: Set a field name (key) for each piece of extracted log content (value).
-
For information about other parameters, see the general parameter descriptions in Use case 2: Structured logs.
Delimiter parsing
Use delimiter parsing to split log content into key-value pairs. Supports single-character and multi-character delimiters.
Example:
|
Raw log without any processing |
Fields split by the specified character |
|
|
Procedure: In the Processor Configurations section of the Logtail Configurations page, click Add Processor and select .
-
Delimiter: The character used to split the log content.
Example: For a CSV file, select Custom and enter a comma (,).
-
Quote: When a field value contains the delimiter, you must specify a quote character to wrap the field to prevent incorrect splitting.
-
Extracted Field: Assign a field name (key) to each column in sequential order. The field names must meet the following rules:
-
Can contain only letters, digits, and underscores (_).
-
Must start with a letter or an underscore (_).
-
Can be up to 128 bytes in length.
-
-
For information about other parameters, see the general parameter descriptions in Use case 2: Structured logs.
JSON parsing
Parses logs formatted as JSON objects into key-value pairs.
Example:
|
Raw log without any processing |
Automatic extraction of standard JSON key-value pairs |
|
|
Procedure: In the Processor Configurations section of the Logtail Configurations page, click Add Processor and select .
-
Original Field: The default value is
content. This field contains the raw log to be parsed. -
For information about other parameters, see the general parameter descriptions in Use case 2: Structured logs.
Expanding JSON fields
Expands a field containing a nested JSON object into multiple key-value pairs.
Example:
|
Raw log without any processing |
Expansion depth: 0, using expansion depth as a prefix |
Expansion depth: 1, using expansion depth as a prefix |
|
|
|
Procedure: In the Processor Configurations section of the Logtail Configurations page, click Add Processor and select .
-
Original Field: The name of the original field to expand, for example,
content. -
JSON Expansion Depth: The expansion level of the JSON object. A value of 0 (the default) fully expands the object, 1 expands only the current level, and so on.
-
Character to Concatenate Expanded Keys: The character used to join field names during JSON expansion. The default is an underscore (_).
-
Name Prefix of Expanded Keys: A prefix to add to the field names after JSON expansion.
-
Expand Array: Turn on this switch to expand arrays into key-value pairs with indexes.
Example:
{"k":["a","b"]}is expanded tok[0]: "a", k[1]: "b".To rename an expanded field (for example, from
prefix_s_key_k1tonew_field_name), add a Rename Fields processor to complete the mapping. -
For information about other parameters, see the general parameter descriptions in Use case 2: Structured logs.
JSON array parsing
Use the json_extract function to extract JSON objects from a JSON array.
Example:
|
Raw log without any processing |
Extract JSON array structure |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, switch the Processing Mode to SPL, configure the SPL Statement, and use the json_extract function to extract JSON objects from the JSON array.
Example: Extract elements from the JSON array in the log field content and store the results in new fields json1 and json2.
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache log parsing
Structure log content based on the definitions in your Apache log configuration file, parsing it into multiple key-value pairs.
Example:
|
Raw log without any processing |
Apache Common Log Format |
|
|
Procedure: In the Processor Configurations section of the Logtail Configurations page, click Add Processor and select .
-
Log Format: combined
-
APACHE LogFormat Configuration: The system automatically populates this field based on the selected Log Format.
ImportantEnsure the auto-populated content exactly matches the
LogFormatdefinition in your server's Apache configuration file (typically/etc/apache2/apache2.conf). -
For information about other parameters, see the general parameter descriptions in Use case 2: Structured logs.
Data Masking
Mask sensitive data in logs.
Example:
|
Raw log without any processing |
Masking result |
|
|
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Original Field: The field that contains the log content before parsing.
-
Data Masking Method:
-
const: Replaces sensitive content with a constant string.
-
md5: Replaces sensitive content with its MD5 hash.
-
-
Replacement String: If Data Masking Method is set to const, enter a string to replace the sensitive content.
-
Content Expression that Precedes Replaced Content: The expression used to find sensitive content, which is configured using RE2 syntax.
-
Content Expression to Match Replaced Content: The regular expression used to match sensitive content. The expression must be written in RE2 syntax.
Time Parsing
Parse the time field in the log and set the parsing result as the log's __time__ field.
Example:
|
Raw log without any processing |
Time parsing |
|
|
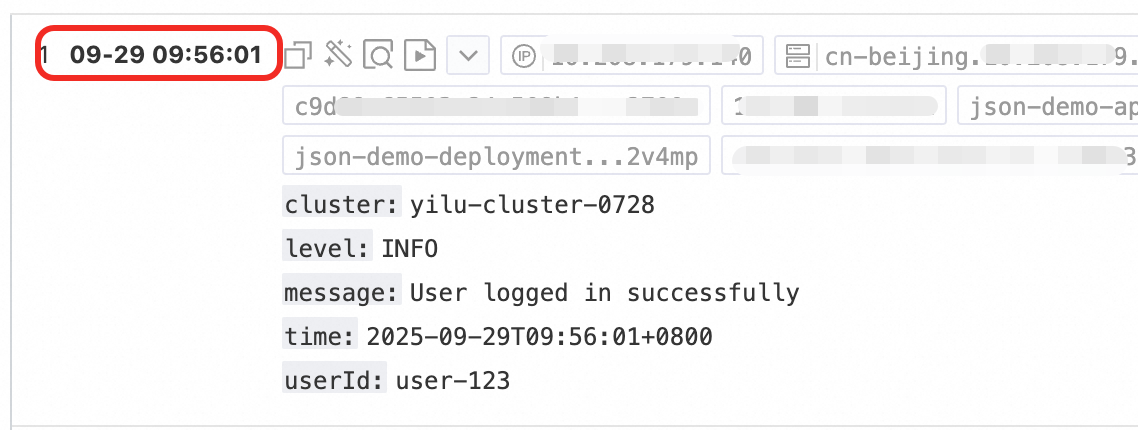
Procedure: In the Processor Configurations section of the Logtail Configuration page, click Add Processor and select :
-
Original Field: The field that contains the log content before parsing.
-
Time Format: Set the time format that corresponds to the timestamps in the log.
-
Time Zone: Select the time zone for the log time field. By default, this is the time zone of the environment where the LoongCollector (Logtail) process is running.
Regular expression limitations for container filtering
Regular expressions for container filtering use the Go RE2 engine, which has syntax limitations compared to PCRE.
1. Named group syntax differences
Go uses the (?P<name>...) syntax to define a named group and does not support the (?<name>...) syntax from PCRE.
-
Correct syntax:
(?P<year>\d{4}) -
Incorrect syntax:
(?<year>\d{4})
2. Unsupported regular expression features
The RE2 engine does not support the following common but complex regular expression features:
-
Assertions:
(?=...),(?!...),(?<=...), and(?<!...) -
Conditional expressions:
(?(condition)true|false) -
Recursive matching:
(?R)and(?0) -
Subprogram references:
(?&name)and(?P>name) -
Atomic groups:
(?>...)
3. Recommendations
Use tools such as Regex101 to debug regular expressions. Select the Golang (RE2) mode to ensure compatibility. Unsupported syntax prevents the plugin from parsing or matching correctly.