Agentic SOC 機能により、Kafka、Amazon S3、Alibaba Cloud Object Storage Service (OSS) などのさまざまなチャネルからログを一元的に収集できます。これにより、マルチクラウド環境にわたる一貫したセキュリティ管理を実現するための統合ログ分析およびセキュリティ運用センター(SOC)を構築できます。
ワークフロー

ソリューションの選択
開始前に、データソースの種類、コスト、リアルタイム性要件に基づき、最も適したログインポートチャネルを選択してください。
インポートチャネル | 適用範囲/利用シーン | 特徴 |
Kafka |
|
|
S3(または S3 互換オブジェクトストレージ) |
|
|
OSS(Alibaba Cloud Object Storage Service) | ログデータは Alibaba Cloud OSS にすでに保存されています。 | Alibaba Cloud エコシステムとの統合度が高いため、構成が簡素化されます。 |
中間チャネルへのログ配信
Agentic SOC のインポート機能は、Kafka、S3、OSS などのチャネルからデータを取得します。そのため、まずログデータを事前に選択した中間チャネルへ配信する必要があります。
配信方法の例:
OSS:ログデータを Alibaba Cloud OSS バケットに保存します。詳細については、「OSS クイックスタート」をご参照ください。
Huawei Cloud:Huawei Cloud Log Tank Service (LTS) の ログダンプ 機能を使用して、データを Kafka または Object Storage Service (OBS) に保存します。詳細については、「Huawei Cloud ログデータのインポート」をご参照ください。
Tencent Cloud:Tencent Cloud Log Service (CLS) の ログダンプ 機能を使用して、データを Kafka または Cloud Object Storage (COS) に保存します。詳細については、「Tencent Cloud ログデータのインポート」をご参照ください。
Azure:Azure Event Hubs が Apache Kafka プロトコルと互換性を持つことを利用して、Event Hub を Agentic SOC がログデータを取得可能な Kafka サービスとして扱います。詳細については、「Azure ログデータのインポート」をご参照ください。
アクセス情報の保存:AccessKey ペアやパスワードなどのアクセス認証情報、およびエンドポイントやバケット名などのエンドポイント情報を安全に保管してください。
サードパーティサービスへの Security Center のアクセス許可付与
サードパーティのデータチャネルを利用する場合、Agentic SOC がこれらのリソースにアクセスできるよう権限を付与する必要があります。これにより、Agentic SOC はこれらのチャネルからログデータを読み取れるようになります。
Kafka および S3(Object Storage Service)
Security Center コンソールにログインし、「システム設定 > 機能設定」に移動します。国際向けコンソールのいずれかをご利用ください。ページ左上隅にあるリージョン選択メニューから、ご利用の資産が配置されているリージョンを選択します:Chinese Mainland または Outside Chinese Mainland。
「マルチクラウドの設定と管理」タブで、「マルチクラウドアセット」を選択し、「権限の新規付与」をクリックします。表示されたパネルで、ドロップダウンリストから IDC を選択し、以下のパラメーターを構成します:
説明各クラウドプロバイダーの公式ドキュメントを参照して、エンドポイントなどの構成項目の具体的な値を確認してください。
現在のバージョンでは、AWS S3、Tencent Cloud COS、Huawei Cloud OBS など、汎用 Kafka や S3 互換ストレージサービスを構成する場合、UI 上の分類のために IDC を選択します。この選択は機能の動作には影響しません。
Kafka
Service Provider: Apache を選択します。
Service: Kafka を選択します。
Endpoint: Kafka のパブリックエンドポイント。
説明Event Hub のエンドポイントは
<YOUR-NAMESPACE>.servicebus.windows.net:9093です。ユーザー名/パスワード: Kafka のユーザー名およびパスワード。
説明Event Hub の Kafka デフォルトユーザー名は
$ConnectionString、パスワードは プライマリ接続文字列 です。通信プロトコル: Kafka 構成における `security.protocol`。サポートされる値は、プレーンテキスト(デフォルト)、sasl_plaintext、sasl_ssl、ssl です。
SASL 認証メカニズム: Kafka 構成における `sasl.mechanism`。サポートされる値は、plain、SCRAM-SHA-256、SCRAM-SHA-512 です。
S3
Service Provider: AWS-S3 を選択できます。
Service: S3 を選択します。
Endpoint: オブジェクトストレージサービスのエンドポイント。
Access Key Id/Secret Access Key: S3 へのアクセスに使用する AccessKey ペアを入力します。
同期ポリシーの構成
AK サービスのステータスチェック:Security Center が AccessKey ペアの有効性を自動的にチェックする間隔を指定します。[無効] を選択して、このチェックを無効にできます。
OSS
クラウドリソースアクセス権限付与 ページに移動し、「権限付与の確認」をクリックして、システムロールによる OSS リソースへのアクセス権限を付与します。
Resource Access Management (RAM) ユーザーの場合、以下の権限も構成する必要があります。詳細については、「カスタムポリシーの作成」および「RAM ユーザー権限の管理」をご参照ください。
{ "Statement": [ { "Effect": "Allow", "Action": "ram:PassRole", "Resource": "acs:ram:*:*:role/aliyunlogimportossrole" }, { "Effect": "Allow", "Action": "oss:GetBucketWebsite", "Resource": "*" }, { "Effect": "Allow", "Action": "oss:ListBuckets", "Resource": "*" } ], "Version": "1" }
データインポートタスクの作成
データソースの作成
ログデータ専用の Agentic SOC データソースを作成します。既にデータソースが存在する場合は、このステップをスキップできます。
Security Center コンソールにログインし、「Agentic SOC > Integration Center」に移動します。国際向けコンソールのいずれかをご利用ください。ページ左上隅にあるリージョン選択メニューから、ご利用の資産が配置されているリージョンを選択します:Chinese Mainland または Outside Chinese Mainland。
「Data Source」タブで、ログ受信用のデータソースを作成します。詳細については、「Simple Log Service (SLS) 向けデータソースの作成」をご参照ください。
Source Data Source Type: Agentic SOC Dedicated Collection Channel(推奨)または User Log Service を選択します。
インスタンス接続: データの分離を目的として、新しい Logstore を作成することを推奨します。
「Data Import」タブで、「Add Data」をクリックします。表示されたパネルで、「Data Source Type」に応じて以下の設定を構成します:
説明各クラウドプロバイダーの公式ドキュメントを参照して、構成項目の具体的な値を確認してください。
Kafka
Endpoint: 「サードパーティサービスへの Security Center のアクセス許可付与」手順で入力した Kafka のパブリックエンドポイントを選択します。
Topics: ログが格納されている Kafka Topic を選択します。
説明Event Hub の名前が Kafka Topic となります。
Value Type: ログの保存形式。
サードパーティストレージ形式
値タイプ
JSON 形式
json
生ログ形式
text
S3
Endpoint: S3 バケットのエンドポイント。
S3 バケット: S3 バケットの ID。
File Path Prefix Filter: ファイルパスのプレフィックスで S3 オブジェクトをフィルターし、インポート対象の特定オブジェクトを特定します。たとえば、インポート対象の S3 オブジェクトが csv/ ディレクトリに格納されている場合、このパラメーターを csv/ に設定します。
警告このパラメーターは必須です。空欄のままにすると、システムが S3 バケット全体を走査します。バケット内のファイル数が多い場合、フル走査はインポートパフォーマンスを大幅に低下させます。
File Path Regex Filter: 正規表現を使用してファイルをフィルターし、インポート対象の特定ファイルを特定します。デフォルトでは空欄であり、フィルター処理は行われません。たとえば、S3 ファイルのパスが
testdata/csv/bill.csvの場合、正規表現を(testdata/csv/)(.*)に設定できます。説明効率向上のため、このパラメーターを File Path Prefix Filter と併用することを推奨します。このパラメーターと File Path Prefix Filter は論理積(AND)で評価されます。
正規表現のデバッグ方法については、「正規表現のデバッグ方法」をご参照ください。
Data Format: ファイルのパース形式。各オプションの説明は以下のとおりです。
CSV: 区切り文字でデータを区切るテキストファイル。ファイルの先頭行をフィールド名として使用するか、手動でフィールド名を指定できます。フィールド名の行を除く各行は、ログフィールドの値としてパースされます。
JSON: S3 ファイルを 1 行ずつ読み取り、各行を JSON オブジェクトとしてパースします。パース後、JSON オブジェクト内のフィールドがログフィールドに対応します。
Text: S3 ファイルの各行を 1 つのログエントリとしてパースします。
Multi-line Text: 先頭行または末尾行の正規表現を指定することで、複数行のログをパースするモードです。
CSV または Multi-line Text を選択した場合、以下の追加パラメーターを設定する必要があります。
CSV
パラメーター
説明
Separator
ログの区切り文字を設定します。デフォルト値はカンマ (,) です。
引用符
CSV 文字列で使用される引用符。
Escape Character
ログのエスケープ文字を設定します。デフォルト値はバックスラッシュ (\) です。
Max Line Span
ログエントリが複数行にわたる場合、その最大行数を指定します。デフォルト値は 1 です。
First Row as Header
このスイッチを有効化すると、CSV ファイルの先頭行がフィールド名として使用されます。たとえば、以下の図の先頭行がログフィールドの名前として抽出されます。
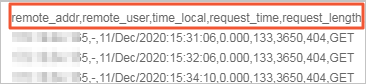
Skip rows
スキップするログ行数を指定します。たとえば、1 に設定した場合、ログ収集は CSV ファイルの 2 行目から開始されます。
Multi-line Text
パラメーター
説明
Regex Match Position
以下のとおり、正規表現マッチの位置を設定します:
Prefix Regex: ログエントリの先頭行をマッチさせる正規表現。マッチしない後続の行は、最大行数に達するまで当該ログエントリの一部とみなされます。
Suffix Regex: ログエントリの末尾行をマッチさせる正規表現。マッチしない部分は、最大行数に達するまで次のログエントリの一部とみなされます。
Regex
ログ内容に応じて正しい正規表現を設定します。詳細については、「正規表現のデバッグ方法」をご参照ください。
Max Lines
1 つのログエントリの最大行数。
Encoding Format: インポート対象の S3 ファイルのエンコード形式。サポートされる形式は GBK および UTF-8 です。
Compression format: システムが S3 データの圧縮設定に基づいて圧縮形式を自動検出します。
Modified Time: タスク開始時刻の 30 分前から変更されたすべてのファイル(新規追加ファイルを含む)をインポートします。
New File Check Cycle: インポートタスクが新規ファイルを定期的にスキャンする間隔。この指定された間隔で、タスクが自動的に新規ファイルをスキャンおよびインポートします。
OSS
重要現在、サイズが最大 5 GB の OSS ファイルのみインポート可能です。圧縮ファイルのサイズは、圧縮後のサイズで計算されます。
OSS Region: OSS データが格納されているリージョン。
説明クロスリージョンアクセスではデータ転送コストが発生します。このコストは OSS サービスによって課金されます。詳細については、「課金の詳細」をご参照ください。
Bucket: インポート対象ファイルを格納する OSS バケット。
File Path Prefix Filter: ファイルパスのプレフィックスで OSS オブジェクトをフィルターし、インポート対象の特定オブジェクトを特定します。たとえば、インポート対象のファイルが csv/ ディレクトリに格納されている場合、このパラメーターを csv/ に設定します。
警告このパラメーターは必須です。空欄のままにすると、システムが OSS バケット全体を走査します。バケット内のファイル数が多い場合、フル走査はインポートパフォーマンスを低下させ、不要なコストを発生させる可能性があります。
File Path Regex Filter: 正規表現を指定してファイルをフィルターし、インポート対象の特定ファイルを特定します。デフォルトでは空欄であり、フィルター処理は行われません。たとえば、OSS ファイルのパスが
testdata/csv/bill.csvの場合、正規表現を(testdata/csv/)(.*)に設定できます。説明効率向上のため、このパラメーターを File Path Prefix Filter と併用することを推奨します。このパラメーターと File Path Prefix Filter は論理積(AND)で評価されます。
正規表現のデバッグ方法については、「正規表現のデバッグ方法」をご参照ください。
Modified Time: 開始時刻をタスク開始時刻の 30 分前に設定します。この時刻以降に変更されたすべてのファイル(新規追加ファイルを含む)がインポートされます。
Data Format: ファイルをパースする際に使用する形式。各オプションの説明は以下のとおりです。
CSV: 区切り文字でデータを区切るテキストファイル。ファイルの先頭行をフィールド名として使用するか、手動でフィールド名を指定できます。フィールド名の行を除く各行は、ログフィールドの値としてパースされます。
Single-Line JSON: OSS ファイルを 1 行ずつ読み取り、各行を JSON オブジェクトとしてパースします。JSON オブジェクト内のフィールドがログフィールドとなります。
Text: OSS ファイルの各行を 1 つのログエントリとしてパースします。
Multi-line Text: 先頭行または末尾行の正規表現を指定することで、複数行のログをパースするモードです。
ORC: ORC ファイル形式。構成は不要で、ファイルは自動的にログ形式にパースされます。
Parquet: Parquet ファイル形式。構成は不要で、ファイルは自動的にログ形式にパースされます。
OSS Access Log: Alibaba Cloud OSS アクセスログの形式。詳細については、「ログストレージ」をご参照ください。
Download Alibaba Cloud CDN logs: Alibaba Cloud CDN のダウンロードログの形式。詳細については、「クイックスタート」をご参照ください。
CSV または Multi-line Text を選択した場合、以下の追加パラメーターを設定する必要があります。
CSV
パラメーター
説明
Separator
ログの区切り文字を設定します。デフォルト値はカンマ (,) です。
引用符
CSV 文字列で使用される引用符。
Escape Character
ログのエスケープ文字を設定します。デフォルト値はバックスラッシュ (\) です。
Max Line Span
ログエントリが複数行にわたる場合、その最大行数を指定します。デフォルト値は 1 です。
First Row as Header
このスイッチを有効化すると、CSV ファイルの先頭行がフィールド名として使用されます。たとえば、以下の図の先頭行がログフィールドの名前として抽出されます。
Skip rows
スキップするログ行数を指定します。たとえば、1 に設定した場合、ログ収集は CSV ファイルの 2 行目から開始されます。
Multi-line Text
パラメーター
説明
Regex Match Position
以下のとおり、正規表現マッチの位置を設定します:
Prefix Regex: ログエントリの先頭行をマッチさせる正規表現。マッチしない後続の行は、最大行数に達するまで当該ログエントリの一部とみなされます。
Suffix Regex: ログエントリの末尾行をマッチさせる正規表現。マッチしない部分は、最大行数に達するまで次のログエントリの一部とみなされます。
Regex
ログ内容に応じて正しい正規表現を設定します。詳細については、「正規表現のデバッグ方法」をご参照ください。
Max Lines
1 つのログエントリの最大行数。
Encoding Format: インポート対象の OSS ファイルのエンコード形式。サポートされる形式は GBK および UTF-8 です。
Compression format: システムが構成済みの OSS データ圧縮形式に基づいて圧縮形式を自動検出します。
New File Check Cycle: インポートタスクが新規ファイルを定期的にスキャンする間隔。その後、タスクが自動的に新規ファイルをスキャンおよびインポートします。
宛先データソースの構成
データソース名: ステップ 1 で作成したデータソースを選択します。
ターゲット Logstore: ステップ 1 で設定した Logstore。
構成を保存するには、OK をクリックします。Security Center が自動的にデータインポートチャネルからログをプルします。
インポート済みデータの分析
データが正常に取り込まれた後、Security Center がログを分析できるよう、パースルールおよび検出ルールを構成する必要があります。
新しいアクセスポリシーの作成
詳細については、「プロダクト連携」をご参照ください。新しい連携ポリシーを作成し、以下のパラメーターを構成します:
Data Source: データインポートタスクで構成した ターゲットデータソース を選択します。
Standardized Rule: Agentic SOC は、一部のクラウドプロダクト向けに組み込みの標準化ルールを提供しており、そのまま使用できます。
Standardization Method: アクセスログをアラートログに変換する場合、サポートされるのは Real-time Consumption のみです。
脅威検出ルールの構成
セキュリティ要件に応じて、ルール管理でログ検出ルールを有効化または作成し、ログの分析、アラートの生成、セキュリティイベントの作成を行う必要があります。詳細については、「検出ルール」をご参照ください。
費用とコスト
Agentic SOC および SLS の課金: 費用負担者は、選択した データストレージ方法 によって異なります。
説明Agentic SOC の課金について詳しくは、「Agentic SOC のサブスクリプション」および「Agentic SOC の従量課金」をご参照ください。
Simple Log Service (SLS) の課金について詳しくは、「課金の概要」をご参照ください。
データソースタイプ
Agentic SOC の課金項目
SLS の課金項目
特別な注意事項
Agentic SOC Dedicated Collection Channel
ログ取り込み料金。
ログストレージおよび書き込み料金。
説明上記項目は ログアクセストラフィック を消費します。
ログストレージおよび書き込みを除く料金(インターネットトラフィックなど)。
Agentic SOC が SLS リソースを作成および管理します。したがって、Logstore のストレージおよび書き込み料金は Agentic SOC が負担します。
User Log Service
ログ取り込み料金は ログアクセストラフィック の消費により発生します。
ログ関連のすべての料金(ログストレージおよび書き込み、データ転送コストなど)。
すべてのログリソースは Simple Log Service (SLS) が管理します。したがって、SLS がログ関連のすべての料金を負担します。
OSS 関連のコスト: OSS からのデータインポート時に、OSS がトラフィックおよびリクエストに対して課金します。これらの課金項目の価格については、「OSS の料金」をご参照ください。
コスト算出式
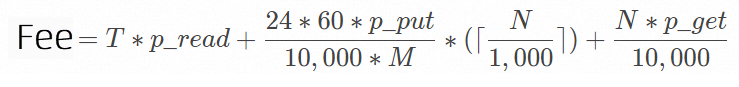
フィールド
説明
N1 日あたりのインポートファイル数。
T1 日あたりのインポートデータ総量(GB 単位)。
p_readデータ 1 GB あたりのトラフィック料金。
同一リージョン内でのインポートの場合、OSS から内部ネットワーク経由のアウトバウンドトラフィックが発生します。このトラフィックは無料です。
クロスリージョンでのインポートの場合、OSS からインターネット経由のアウトバウンドトラフィックが発生します。
p_put10,000 回の PUT リクエストあたりの料金。
Simple Log Service は、宛先バケット内のファイル一覧を取得するために ListObjects API 操作を使用します。OSS はこの操作を PUT リクエストとして課金します。この操作は 1 回の呼び出しで最大 1,000 件のデータを返します。したがって、1,000,000 個の新規ファイルがある場合、1,000,000 ÷ 1,000 = 1,000 回のリクエストが必要です。
p_get10,000 回の GET リクエストあたりの料金。
M新規ファイルの確認間隔(分単位)。
データインポート構成を作成する際に、新規ファイルの確認間隔 パラメーターを設定できます。
課金の例
サードパーティのコスト: