[脅威の分析と応答] の クラウドオブザーバビリティ 機能と Simple Log Service (SLS) を使用して、サービスのヘルス状態、ログ使用量、およびその他の運用メトリックをモニタリングし、アラートを作成します。
ビジネスシナリオ
日常の 運用保守 中に、[脅威の分析と応答] に関して次の問題が発生する可能性があります:
サービス可用性のリスク:ログの取り込み の中断やコアモジュールの異常な動作が検出されず、セキュリティ分析機能が低下する可能性があります。
コスト管理の困難:ログの取り込み トラフィックが想定を超え、タイムリーなモニタリングがないと、予期しない SLS のストレージおよびクエリコストが発生する可能性があります。
運用保守の効率低下:統一されたモニタリングビューとアラートメカニズムがないため、Agentic SOC の運用状態を既存の 運用保守 システムに統合することは困難です。
ワークフロー
クラウドオブザーバビリティ機能は、Agentic SOC の運用状態ログを Simple Log Service (SLS) へ配信します。その後、SLS アラートを使用してこれらのログをモニタリングし、通知を送信できます。

ログ生成:[脅威の分析と応答] のモジュール (使用量メータリングやモジュールのヘルス状態など) は、実行時にモニタリングログを生成します。
ログ配信:クラウドオブザーバビリティ機能を有効にすると、Agentic SOC はこれらのモニタリングログを指定した SLS プロジェクトへリアルタイムで配信します。
ログストレージ:ログは SLS の Logstore に保存されます。
モニタリングとアラート:SLS のアラートルールは、クエリステートメント (SQL) を定期的に実行し、トリガー条件 が満たされているかどうかを判断します。
通知の送信:アラートがトリガーされると、アクションポリシー がテキストメッセージ、DingTalk、メールなどの指定されたチャネルに通知を送信します。
操作手順
ステップ 1:クラウドオブザーバビリティ機能の有効化
[脅威の分析と応答] コンソールで クラウドオブザーバビリティ 機能を有効にして、モニタリングログを Simple Log Service (SLS) へ配信します。
Cloud Observability 設定ページへの移動
Security Center コンソール - [System Settings] - [Feature Settings] にログインします。ページの上部で、アセットが配置されているリージョン:[Chinese Mainland] または [Outside Chinese Mainland] を選択します。
[設定] タブで、[Cloud Observability] をクリックします。
機能の有効化
[Basic Settings] セクションの [Cloud Observability] 設定タブで、[Enable Cloud Observability] スイッチをオンにします。
ログストレージ情報の設定
[Detailed Configuration] セクションの [Cloud Observability] 設定タブで、次のパラメーターを指定します:
[Monitoring Module]:配信したいログタイプのスイッチをオンにします。
[Module Health]:各モジュールの実行状態、接続状態、およびパフォーマンスをモニタリングします。
[Usage Metering]:ログの取り込み トラフィックとログストレージ容量をモニタリングします。
[Log Storage Location]:
[Region:]クラウドオブザーバビリティのログを保存するリージョンを選択します。
警告ログストレージのリージョンは、初期設定後に変更することはできません。システムは選択したリージョンに専用の SLS Project と Logstore を自動的に作成します。
プロジェクト: 選択されたリージョンに基づいて自動的に作成されます。形式:
sas-observability-AccountUID-RegionID。[Logstore Mapping:]2 つの Logstore が自動的に作成されます。
health-log: Module Health ログを格納します。metering-log: Usage Metering のログを格納します。
[Data Retention Days]:データ保持期間を設定します。デフォルト:30 日。
説明保持期間が長いほど、ストレージコストが高くなります。
[Save Configuration]:[Save Configuration] をクリックします。Agentic SOC は、指定された SLS Project へのログ配信を開始します。
重要クラウドオブザーバビリティのログストレージには、Simple Log Service (SLS) によって請求される追加料金が発生します。
ステップ 2:アラート通知ルールの設定
操作手順
[Cloud Observability] タブで、右下隅にある [Alert Center] をクリックして、アラートセンター設定ページに移動します。
[アラートルール] タブで、[アラートの作成] をクリックし、次のパラメーターを設定します:
説明詳細については、「アラートルールの作成」をご参照ください。
パラメータ
説明
[ルール名]
アラート ルールの名前。
[チェック頻度]
SLS がクエリと分析の結果をチェックする頻度。
-
[毎時]:1 時間ごとにクエリと分析の結果をチェックします。
-
[毎日]:毎日指定した時刻にクエリと分析の結果をチェックします。
-
[毎週]:毎週指定した曜日の指定した時刻にクエリと分析の結果をチェックします。
-
[固定間隔]:固定間隔でクエリと分析の結果をチェックします。
-
Cron:Cron で定義された間隔でクエリと分析の結果をチェックします。
説明Cron 式の最小精度は 1 分で、24 時間形式を使用します。例:
-
0/5 * * * *:0 分から開始して 5 分ごとにチェックします。 -
0 0/1 * * *:00:00 から開始して 1 時間ごとにチェックします。 -
0 18 * * *:毎日 18:00 にチェックします。 -
0 0 1 * *:毎月 1 日の 00:00 にチェックします。
Cron 式の構文:「Cron ジョブ」をご参照ください。
-
クエリ統計
入力ボックスをクリックします。[クエリ統計] ダイアログボックスで、クエリおよび分析ステートメントを設定します。
-
関連レポート タブ:監視するダッシュボードを選択します。
-
詳細設定 タブ:
-
タイプ リストから、データソースタイプを選択します:
-
[ログストア]:ログを保存します。詳細については、「クエリと分析のクイックスタート」をご参照ください。
-
Metricstore:メトリクスデータを保存します。詳細については、「メトリクスデータのクエリと分析」をご参照ください。
-
[リソースデータ]:特定のアラート ルールに関連付けられた外部データを設定します。詳細については、「リソースデータの作成」をご参照ください。
-
-
タイプ で ログストア または [Metricstore] を選択し、クエリ・分析文を指定すると、Dedicated SQL を有効にできます。 高性能・高精度のクエリ・分析 (Dedicated SQL)。
-
[自動]:専用 SQL はデフォルトでオフです。同時実行制限に達した場合、または結果が不正確な場合、SLS は専用 SQL で自動的に再試行します。
-
[有効化]:すべてのクエリと分析に専用 SQL を使用します。
-
[クローズ]:専用 SQL を無効にします。
-
-
複数のクエリの結果を関連付けるには、[セット操作] を使用します。 クエリ文を設定する
グループ評価
クエリと分析の結果をグループ化します。詳細については、「グループ評価の設定」をご参照ください。
-
カスタムラベル:SLS は、指定したフィールドごとにクエリと分析の結果をグループ化します。トリガー条件はグループごとに評価され、各チェック間隔内で条件を満たすグループごとにアラートが生成されます。
複数のフィールドを指定できます。
-
[グループ化なし]:各チェック間隔で、トリガー条件が満たされたときに 1 つのアラートのみが生成されます。
-
自動ラベル:[クエリ統計]セクションで [Metricstore] を選択すると、SLS はラベルに基づく自動グループ化をサポートします。
トリガー条件はグループごとに評価され、各チェック間隔内で条件を満たすグループごとにアラートが生成されます。
[トリガー条件]
アラートをトリガーする条件とその重大度を設定します。
-
トリガー条件
-
データが存在する:クエリ結果にデータが含まれている場合にアラートをトリガーします。
-
特定の行数のデータが存在する:クエリ結果のデータ行数が N 行の場合にアラートをトリガーします。
-
データが式に一致する:クエリ結果に式に一致するデータが含まれている場合にアラートをトリガーします。
-
特定の行数のデータが式に一致する:クエリ結果の N 行のデータが式に一致する場合にアラートをトリガーします。
-
-
重大度
アラートのノイズリダクションと通知を制御します。アラートポリシーとアクションポリシーに重大度ベースの条件を追加できます。詳細については、「アラート重大度の設定」をご参照ください。
-
シンプル:重大度を選択します。このルールからのすべてのアラートは同じ重大度になります。
-
条件付き: 追加 をクリックして、特定の条件に基づいて異なる重要度を設定します。
-
アラート条件式の構文については、「アラート条件式の構文」をご参照ください。
[タグの追加]
キーと値の形式でアラートに識別属性を追加します。タグはアラートのノイズリダクションと通知を制御します。アラートポリシーとアクションポリシーにタグベースの条件を追加できます。詳細については、「ラベルとアノテーションの追加」をご参照ください。
[ラベルを追加する]
キーと値の形式でアラートに非識別属性を追加します。アノテーションはアラートのノイズリダクションと通知を制御します。アラートポリシーとアクションポリシーにアノテーションベースの条件を追加できます。詳細については、「ラベルとアノテーションの追加」をご参照ください。
[アノテーションの自動追加] をオンにすると、アラートに count などの情報が自動的に追加されます。 自動アノテーション。
[リカバリ通知]
リカバリ通知 スイッチをオンにすると、アラートが解決されたときにシステムが回復通知を送信します。 たとえば、CPU 使用率が 95% を超えたときにトリガーされたアラートは、使用率が 95% 以下に低下すると回復通知を送信します。 回復通知を設定する。
詳細設定 > 連続トリガーしきい値
トリガー条件を連続で満たす必要のあるチェック回数。一致しないチェックはカウントされません。
詳細設定 > データなしアラート
[無データアラート] スイッチをオンにすると、連続した無データチェックが 連続トリガーのしきい値 を超えた場合にアラートがトリガーされます。 複数のクエリの場合、これはセット演算後の結果に適用されます。 無データアラート。
[ターゲット Logstore]
アラートイベントの送信先。1 つ以上の送信先を設定します。
-
[イベントライブラリ]:アラートイベントをイベントストアに書き込みます。
-
CloudMonitor イベントセンター:アラートイベントを CloudMonitor イベントセンターに書き込み、アラートと通知を管理します。
-
SLS 通知:アラートイベントを SLS 通知サービスに送信し、アラートポリシーとアクションポリシーを通じて管理します。
送信先 - イベントストア
-
[有効化]:オンにすると、指定したイベントストアにアラートを書き込みます。
-
[リージョン]:送信先イベントストアのリージョン。
-
プロジェクト:送信先イベントストアのプロジェクト。
-
[イベントライブラリ]:アラートイベントの送信先イベントストア。
-
[Authorization Method]:
-
[Default Role]: Authorize Now をクリックして、AliyunLogETLRole システムロールに、アラートを宛先の Eventstore に書き込む権限を付与します。 デフォルトロールに権限を付与する。
-
[Custom Role]:カスタムロールを使用して送信先イベントストアにアラートを書き込みます。ロール ARN を入力します。詳細については、「カスタムロールへの権限付与」をご参照ください。
-
送信先 - CloudMonitor イベントセンター
-
[有効化]:オンにすると、CloudMonitor イベントセンターにアラートを送信します。詳細については、「システムイベントの表示」をご参照ください。
送信先 - SLS 通知
-
[有効化]:オンにすると、SLS 通知サービスにアラートを送信し、管理と通知を行います。
-
[アラートポリシー]
シンプルモード
-
デフォルトでは、SLS は組み込みの動的アラートポリシー (sls.builtin.dynamic) を使用してアラートを管理します。
-
アクショングループを設定します。
アクショングループを設定すると、SLS は自動的に
Rule Name-Action Policyという名前のアクションポリシーを作成します。このルールからのすべてのアラートは、このポリシーを使用して通知を行います。詳細については、「通知チャネル」をご参照ください。重要このアクションポリシーは、アクションポリシー ページで変更できます。アクションポリシーの変更時に条件を追加すると、アラートポリシー 設定は自動的に 通常モード に変わります。
-
再送間隔:この間隔内では、繰り返されるアラートはアクションポリシーを 1 回だけトリガーします。
スタンダードモード
-
デフォルトでは、SLS は組み込みの動的アラートポリシー (sls.builtin.dynamic) を使用してアラートを管理します。
-
アラート通知用の組み込みまたはカスタムのアクションポリシーを選択します。詳細については、「アクションポリシー」をご参照ください。
-
再送間隔:この間隔内では、繰り返されるアラートはアクションポリシーを 1 回だけトリガーします。
アドバンストモード
-
アラートを管理するための組み込みまたはカスタムのアラートポリシーを選択します。詳細については、「アラートポリシーの作成」をご参照ください。
-
アラート通知用に、組み込みまたはカスタムのアクションポリシーを選択します。アクションポリシー。また、[カスタムアクションポリシー] を有効化または無効化することもできます。動的アクションポリシーメカニズム。
-
再送間隔:この間隔内では、繰り返されるアラートはアクションポリシーを 1 回だけトリガーします。
-
-
設定が完了したら、[OK] をクリックします。
設定例
トラフィックがゼロに低下
シナリオ:[脅威の分析と応答] への ログの取り込み トラフィックが急に 0 になります。
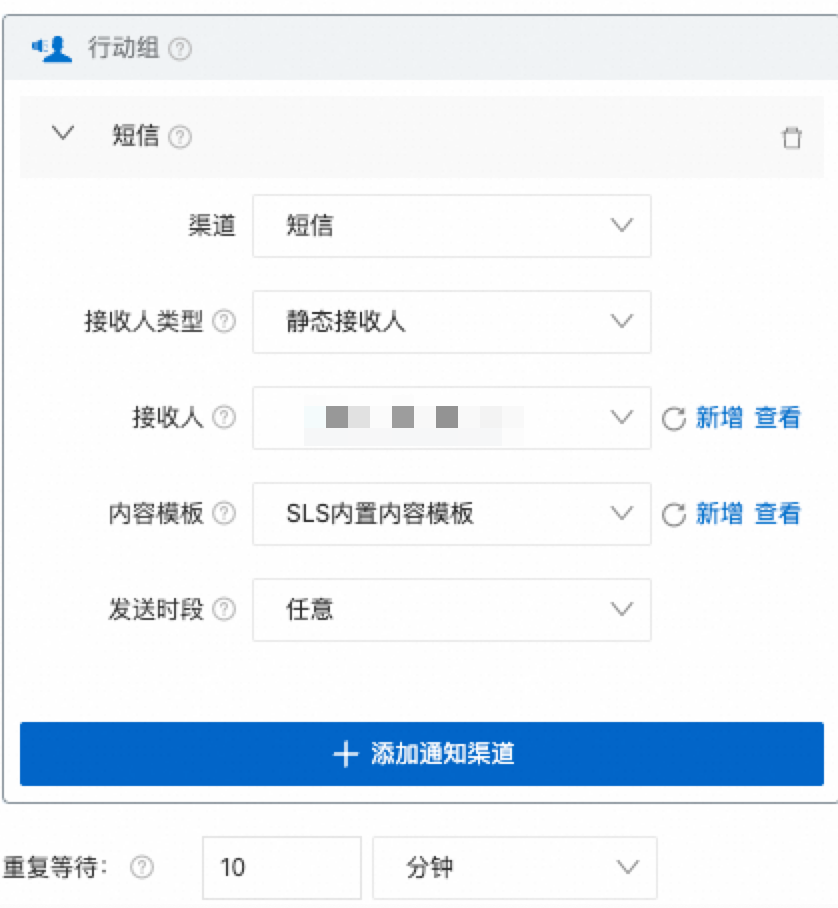
解決策:10 分ごとに、システムは直前の 10 分間のログ量をチェックします。量が 0 の場合、データ報告が中断されたと見なされ、アラートがトリガーされます。アラートはテキストメッセージで送信され、重複通知を避けるために 10 分間の クールダウン期間 が設定されます。
設定:
[確認頻度]:10 分の固定間隔。
[クエリ統計]:[作成] をクリックします。[クエリ統計] ダイアログボックスで、[詳細設定] タブをクリックし、次のパラメーターを指定します:
[タイプ]:Logstore
[権限付与]:デフォルト。
[ログストア]:
metering-log[専用 SQL]:無効。
[時間範囲]:10 分 (相対時間)。クエリ SQL は次のとおりです:
* and type: log_traffic | select if(t.log_size is null, 0, t.log_size) from (select sum(log_size) log_size from log) t
[グループ評価]:グループ化しない。
[トリガー条件]:
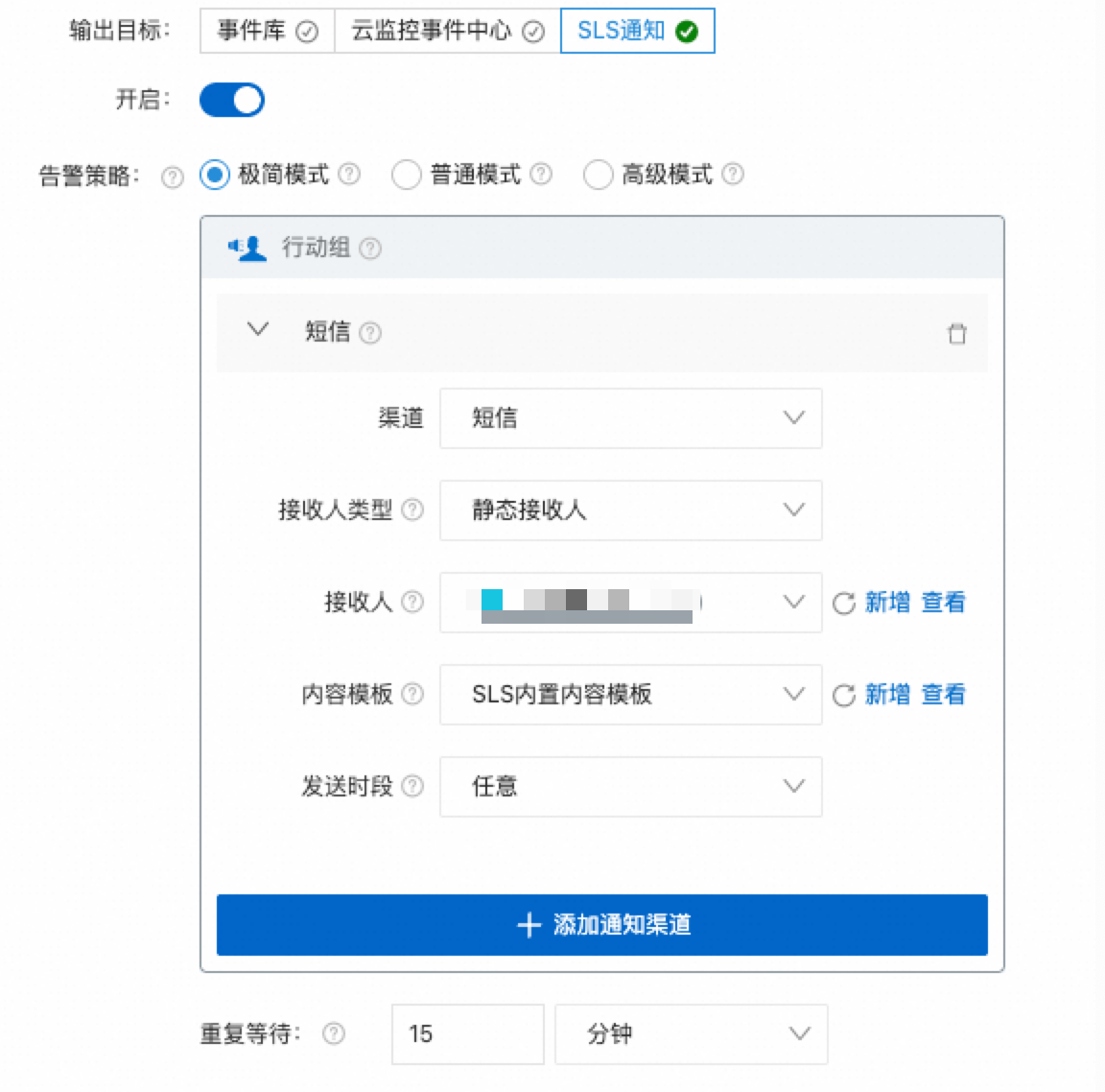
データが条件に一致。[評価式] は_col0<=0です。[出力先]:[SLS 通知] を選択し、スイッチをオンにします。
[アラートポリシー]:
[サイクル]:10 分。
取り込み異常
シナリオ:統合センターのデータソースの状態が異常です。
解決策: 15 分ごとに、システムは Module Health Logstore で
statusがnormalではないログをチェックします。このようなログが見つかった場合、アラートがトリガーされます。設定:
[確認頻度]:15 分の固定間隔。
[クエリ統計]:[作成] をクリックします。[クエリ統計] ダイアログボックスで、[詳細設定] タブをクリックし、次のパラメーターを指定します:
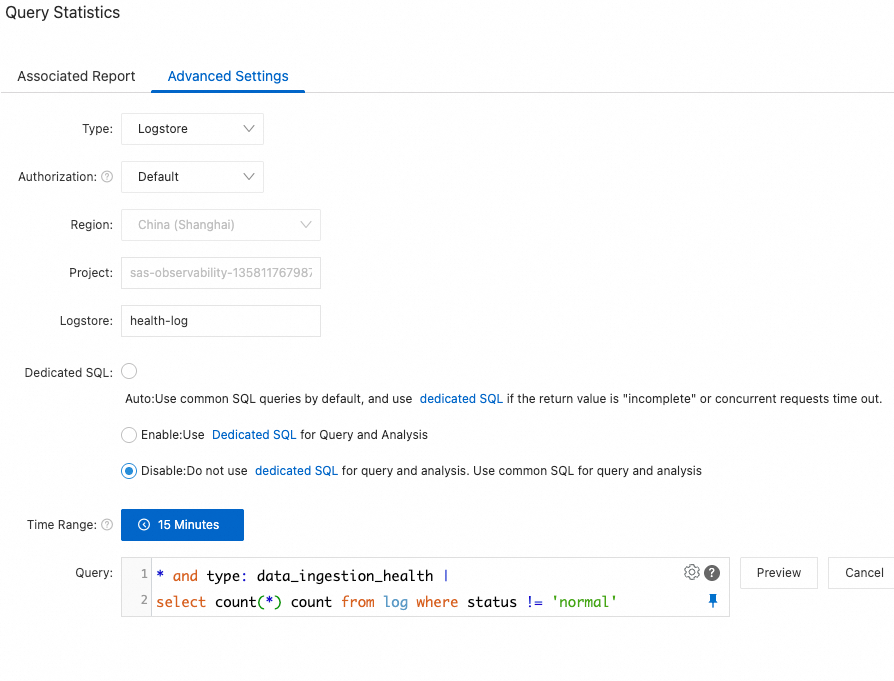
[タイプ]:Logstore
[権限付与]:デフォルト。
[ログストア]:
health-log[専用 SQL]:無効。
[時間範囲]:15 分 (相対時間)。クエリ SQL は次のとおりです:
* and type: data_ingestion_health | select count(*) count from log where status != 'normal'
[トリガー条件]:
Data matches condition。[評価式] はcount>0です。[出力先]:[SLS 通知] を選択し、スイッチをオンにします。
[アラートポリシー]:
[サイクル]:15 分。
コストとリスク
費用: Cloud Observability を有効にすると、監視ログは継続的に SLS に配信されます。ログストレージおよびクエリ分析料金は SLS によって請求されます。デフォルトのデータ保持期間は 30 日です。
リスク:ログストレージのリージョンは、初期設定後に変更することはできません。誤った選択はデータリンクの遅延を増加させ、管理の複雑さを増大させる可能性があるため、リージョンは慎重に選択してください。