Flink と Hologres を使用して、Flink の強力なストリーム処理能力と、Hologres のバイナリロギング (Binlog)、行列混在ストレージ、強力なリソース隔離などの特徴を活用したリアルタイムデータウェアハウスを構築できます。このアプローチにより、増え続けるデータ量とリアルタイムのビジネス要求に対応するための、効率的でスケーラブルなリアルタイムデータ処理と分析が可能になります。このトピックでは、Realtime Compute for Apache Flink と Hologres を使用してリアルタイムデータウェアハウスを構築する方法について説明します。
背景情報
デジタルトランスフォーメーションが加速するにつれて、企業はますますタイムリーなデータを要求するようになっています。大規模なデータセットのバッチ処理用に設計された従来のオフラインシナリオを超えて、多くのユースケースでは現在、リアルタイムのデータインジェスト、ストレージ、および分析が必要とされています。オフラインデータウェアハウスを構築するための方法論は、時間指定スケジューリングを使用して階層化アーキテクチャ (ODS → DWD → DWS → ADS) を実装するなど、十分に確立されていますが、リアルタイムデータウェアハウスのための明確なフレームワークはまだ限られています。ストリーミングウェアハウスの概念は、ウェアハウスの各レイヤー間で効率的なリアルタイムデータフローを可能にすることで、このギャップを埋めます。
実践的なシナリオ
この例では、E コマースプラットフォームを使用して、Flink と Hologres の緊密な統合によってリアルタイムデータウェアハウスを構築する方法を示します。このソリューションは、リアルタイムのデータ変換を可能にし、上位層のアプリケーションクエリをサポートし、再利用可能で階層化されたリアルタイムデータ構造を確立します。トランザクションダッシュボード、行動分析、ユーザープロファイルタグ付けなどのレポート生成、およびパーソナライズドレコメンデーションを含む複数のビジネスシナリオを強化します。
ソリューションアーキテクチャ

-
ODS レイヤーの構築:オペレーショナルデータベースのテーブルをリアルタイムで取り込みます
MySQL には、`orders` (注文テーブル)、`orders_pay` (注文支払いテーブル)、`product_catalog` (製品カテゴリ辞書テーブル) の 3 つのビジネステーブルが含まれています。Flink はこれらのテーブルをリアルタイムで Hologres に同期し、ODS レイヤーを形成します。
-
DWD レイヤーの構築:リアルタイムのワイドテーブルを作成します
注文テーブル、製品カテゴリ辞書テーブル、注文支払いテーブルをリアルタイムで結合し、DWD レイヤーにワイドテーブルを生成します。
-
DWS レイヤーの構築:リアルタイムメトリックを計算します
DWD ワイドテーブルから Binlog を消費し、イベント駆動型集約を使用して、DWS レイヤーにユーザーおよび店舗ディメンションのメトリックテーブルを生成します。
-
Hologres を介してアプリケーションクエリを有効にします。
-
DWS レイヤーの集約メトリックテーブルを、1 秒あたり数百万レコード (RPS) のサポートでクエリします。
-
DWD ワイドテーブルから OLAP 分析を実行したり、リアルタイムレポートをサブ秒の応答時間で生成したりします。
-
ソリューションの利点とコア機能
このソリューションには、次の利点があります:
-
効率的な更新と即時クエリ:Hologres は、各レイヤーでの書き込み操作後の効率的な更新、修正、および即時クエリをサポートします。これにより、リアルタイムデータウェアハウスにおける中間レイヤーデータのクエリ、更新、または修正という従来の課題が解決されます。
-
データレイヤーの再利用:すべての Hologres データレイヤーは、独立して外部アプリケーションにサービスを提供できます。これにより、効率的な再利用が可能になり、階層化されたデータウェアハウス設計の目標が達成されます。
-
アーキテクチャの簡素化と効率の向上:Flink SQL を使用して、リアルタイムの抽出・変換・書き出し (ETL) パイプラインを構築できます。ODS、DWD、DWS レイヤーのデータを Hologres に一元的に保存することで、アーキテクチャの複雑さを軽減し、データ処理効率を向上させることができます。
このソリューションは、Hologres の 3 つのコア機能に依存しており、次の表で詳しく説明します。
|
Hologres のコア機能 |
説明 |
|
Hologres は、リアルタイムの Flink 計算を駆動するための Binlog を提供し、ストリーム処理の上流ソースとして機能します。 |
|
|
Hologres は行列混在ストレージをサポートしています。単一のテーブルに、行指向データと列指向データの両方が強力な整合性で格納されます。この機能により、中間レイヤーのテーブルは、Flink のソーステーブル、プライマリキーのポイントクエリや結合のためのディメンションテーブル、および他のアプリケーション (OLAP やオンラインサービスなど) のクエリターゲットとして同時に機能することができます。 |
|
|
強力なリソース隔離 |
高負荷時、Hologres インスタンスは中間レイヤーでのポイントクエリのパフォーマンスに影響を与える可能性があります。Hologres は、共有ストレージを利用した読み書き分離デプロイメントまたは計算グループインスタンスアーキテクチャを介して強力なリソース隔離をサポートし、Flink の Binlog 消費がオンラインサービスに影響を与えないようにします。 |
注意事項
-
このリアルタイムデータウェアハウスソリューションは、専用の Hologres インスタンスのみをサポートします。
-
Realtime Compute for Apache Flink、RDS MySQL、および Hologres は同じ VPC に存在する必要があります。異なる VPC にある場合は、VPC 間の接続を確立するか、パブリックエンドポイントを使用する必要があります。詳細については、「別の VPC のサービスにアクセスするにはどうすればよいですか?」および「パブリックエンドポイントにアクセスするにはどうすればよいですか?」をご参照ください。
-
Resource Access Management (RAM) ユーザーまたは RAM ロールを使用して Realtime Compute for Apache Flink、Hologres、または RDS MySQL にアクセスする場合、その ID がターゲットリソースに対する必要な権限を持っていることを確認してください。
ステップ 1:事前準備
RDS MySQL インスタンスの作成とデータソースの準備
-
RDS MySQL インスタンスを作成します。詳細については、「RDS MySQL インスタンスの作成」をご参照ください。
RDS MySQL インスタンスは、ご利用の Flink ワークスペースおよび Hologres インスタンスと同じ VPC にある必要があります。
-
データベースとアカウントを作成します。
order_dw という名前のデータベースと、このデータベースに対する読み書き権限を持つ標準アカウントを作成します。詳細については、「データベースの作成」および「アカウントの作成」をご参照ください。
-
MySQL CDC データソースを準備します。
-
インスタンス詳細ページで、Log On to Database をクリックします。
-
ログインページで、作成したデータベースアカウント名とパスワードを入力し、[ログイン] をクリックします。
-
ログイン後、データベースインスタンスページで `order_dw` データベースをダブルクリックして切り替えます。
-
SQL コンソールで、DDL 文を記述して 3 つのビジネステーブルを作成し、サンプルデータを挿入できます。
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- データの準備 INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
-
-
Upload をクリックし、次に [直接実行] をクリックします。
Hologres インスタンスと計算グループの作成
-
専用の Hologres インスタンスを作成します。詳細については、「Hologres インスタンスの購入」をご参照ください。
Hologres インスタンスは RDS MySQL インスタンスと同じ VPC にある必要があります。読み書き分離を使用して Hologres の強力なリソース隔離を体験するには、インスタンスタイプとして Virtual Warehouse を選択し、[計算グループ用に予約された計算リソース] を 64 に設定して、新しい計算グループの追加を有効にします。
-
インスタンスにログインし、データベースを作成して権限を付与します。
order_dw という名前のデータベースを作成し、簡易権限モデルを有効にします。次に、ご利用のユーザーに管理者権限を付与します。データベースの作成と権限付与の手順の詳細については、「DB 管理」をご参照ください。
説明-
ターゲットアカウントが User Account ドロップダウンリストに表示されない場合、そのアカウントは現在のインスタンスに追加されていません。Users ページに移動し、ユーザーを SuperUser として追加できます。
-
Hologres V2.0 以降では、Binlog 拡張がデフォルトで有効になっています。手動での操作は不要です。
-
-
計算グループを追加します。
リソース隔離のために個別の計算グループを使用できます。データインジェストには初期計算グループ `init_warehouse` を使用し、サービスクエリには `read_warehouse_1` を使用します。
すべての予約済み計算リソースは、最初に `init_warehouse` に割り当てられます。新しい計算グループを作成する前に、その割り当てを減らす必要があります。詳細については、「新しい計算グループインスタンスの作成」をご参照ください。
-
クリックして、 を選択し、ターゲットインスタンスと一致するインスタンス名であることを確認します。
-
既存の `init_warehouse` 計算グループの Actions 列にある 設定の調整 をクリックします。リソースを減らし、OK をクリックします。
-
仮想ウェアハウスの新規追加 をクリックし、`read_warehouse_1` という名前を付けて、OK をクリックします。
-
Flink ワークスペースとカタログの作成
-
Flink ワークスペースを作成します。詳細については、「Realtime Compute for Apache Flink のアクティベート」をご参照ください。
Flink ワークスペースは、RDS MySQL および Hologres インスタンスと同じ VPC にある必要があります。
-
Realtime Compute コンソールにログインし、ターゲットワークスペースの [コンソール] をクリックします。
-
セッションクラスターを作成して、後続のカタログ作成およびクエリスクリプトの実行環境を提供します。詳細については、「ステップ 1:セッションクラスターの作成」をご参照ください。
-
Hologres カタログを作成します。
ページの [クエリスクリプト] タブで、次のコードをクエリスクリプトにコピーし、パラメーターを実際の Hologres サービス情報で更新し、コードブロックを選択して Run をクリックします。ページの右下隅で、作成したセッションクラスターを実行環境として使用する必要があります。
CREATE CATALOG dw WITH ( 'type' = 'hologres', 'endpoint' = '<ENDPOINT>', 'username' = 'BASIC$flinktest', 'password' = '${secret_values.holosecrect}', 'dbname' = 'order_dw@init_warehouse', -- データベース名。init_warehouse 計算グループへの接続を指定します。 'binlog' = 'true', -- カタログ作成時にソーステーブル、ディメンションテーブル、結果テーブルのデフォルト WITH パラメーターを設定します。これらのパラメーターはこのカタログ下のテーブルに自動的に適用されます。 'sdkMode' = 'jdbc', -- JDBC モードを使用します。 'cdcmode' = 'true', 'connectionpoolname' = 'the_conn_pool', 'ignoredelete' = 'true', -- ワイドテーブルのマージでリトラクションを防ぐために必要です。 'partial-insert.enabled' = 'true', -- ワイドテーブルのマージで部分的な列更新を有効にするために必要です。 'mutateType' = 'insertOrUpdate', -- ワイドテーブルのマージで部分的な列更新を有効にするために必要です。 'table_property.binlog.level' = 'replica', -- カタログ作成時に永続的な Hologres テーブルプロパティを渡します。Binlog は後続で作成されるすべてのテーブルでデフォルトで有効になります。 'table_property.binlog.ttl' = '259200' );実際の Hologres サービス情報に基づいて、次のパラメーターを更新してください。
パラメーター
説明
注意事項
endpoint
Hologres エンドポイントアドレス。
Hologres インスタンス詳細ページから、指定された VPC ネットワークタイプのドメイン名を取得します。ドメイン名の詳細については、「エンドポイント」をご参照ください。
username
次のいずれかを選択します:
-
カスタムアカウントのユーザー名。フォーマットは
BASIC$<user_name>です。 -
ご利用の Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ID。
-
設定されたユーザーは、ターゲットの Hologres データベースにアクセスできる必要があります。Hologres のデータベース権限とユーザー管理の詳細については、「Hologres 権限モデル」および「ユーザー管理」をご参照ください。
-
この例では、
BASIC$flinktestという名前のカスタムアカウントを使用し、パスワードをプレーンテキストで保存するセキュリティリスクを避けるために、holosecrect という名前のプロジェクト変数を使用してパスワード値を設定します。詳細については、「プロジェクト変数」をご参照ください。
password
-
カスタムアカウントのパスワード。
-
ご利用の Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey Secret。
説明カタログを作成する際に、ソーステーブル、ディメンションテーブル、結果テーブルのデフォルトの `WITH` パラメーターと、Hologres 物理テーブルのデフォルトプロパティ (例:`table_property` で始まるパラメーター) を設定できます。詳細については、「Hologres カタログの管理」および「リアルタイムデータウェアハウス用の Hologres WITH パラメーター」をご参照ください。
-
-
MySQL カタログを作成します。
[クエリスクリプト] に次のコードをコピーし、パラメーターを実際の MySQL サービス情報で更新し、コードブロックを選択して Run をクリックします。ページの右下隅で、作成したセッションクラスターを実行環境として使用する必要があります。
CREATE CATALOG mysqlcatalog WITH( 'type' = 'mysql', 'hostname' = '<hostname>', 'port' = '<port>', 'username' = '<username>', 'password' = '${secret_values.mysql_pw}', 'default-database' = 'order_dw' );実際の MySQL サービス情報に基づいて、次のパラメーターを更新してください。
パラメーター
説明
hostname
MySQL データベースの IP アドレスまたはホスト名。データベースの基本情報ページで、Network Type セクションの [接続詳細の表示] をクリックして、プライベートネットワークアドレスを取得します。
port
MySQL データベースサービスのポート番号。デフォルト値は 3306 です。
username
MySQL データベースサービスのユーザー名。
password
MySQL データベースサービスのパスワード。
この例では、mysql_pw という名前の変数を使用してパスワード値を指定し、プレーンテキスト関連のリスクを回避します。詳細については、「変数管理」をご参照ください。
ステップ 2:リアルタイムデータウェアハウスの構築
ODS レイヤーの構築:オペレーショナルデータベースのテーブルをリアルタイムで取り込みます
カタログと共に CREATE DATABASE AS (CDAS) 文を使用して、ODS レイヤー全体を一度に作成します。ODS レイヤーは通常、OLAP やキー・バリュー (KV) ポイントクエリを直接サポートしません。代わりに、ストリーミングジョブのイベント駆動型ソースとして機能します。Binlog を有効にすると、この要件が満たされます。Binlog は Hologres のコア機能であり、Hologres コネクタは完全・増分モードをサポートしています。つまり、最初に完全データを読み取り、次に Binlog を増分的に消費します。
-
ODS レイヤー用の CDAS 同期ジョブを作成します。
-
ページで、`ODS` という名前の新しい SQL ストリーミングジョブを作成し、次のコードを SQL エディターにコピーします。
CREATE DATABASE IF NOT EXISTS dw.order_dw -- table_property.binlog.level パラメーターはカタログ作成時に設定されたため、CDAS を介して作成されたすべてのテーブルで Binlog が有効になります。 AS DATABASE mysqlcatalog.order_dw INCLUDING all tables -- 取り込む必要がある上流データベースからテーブルを選択します。 /*+ OPTIONS('server-id'='8001-8004') */ ; -- MySQL CDC インスタンスの server-id 範囲を指定します。説明-
デフォルトでは、この例は `order_dw` データベースの Public スキーマにデータを同期します。ターゲットの Hologres データベースの特定のスキーマにデータを同期することもできます。詳細については、「CDAS ターゲットカタログとして使用」をご参照ください。スキーマを指定すると、カタログ使用時のテーブル命名形式が変更されます。詳細については、「Hologres カタログの使用」をご参照ください。
-
ソーステーブルのスキーマが変更された場合、結果テーブルのスキーマは、ソーステーブルで削除、挿入、更新などのデータ変更操作が発生した後にのみ変更を反映します。
-
-
右上隅の [デプロイ] をクリックしてジョブをデプロイします。
-
左側のナビゲーションウィンドウで、 に移動します。新しくデプロイされた `ODS` ジョブの Actions 列にある 起動 をクリックします。[ステートレス開始] を選択し、起動 をクリックします。
-
-
計算グループにデータをロードします。
テーブルグループは Hologres にデータを格納するために使用されます。`read_warehouse_1` を使用して `order_dw` データベースのテーブルグループ (この例では `order_dw_tg_default`。作成手順の詳細については、「テーブルグループ管理」をご参照ください) からデータをクエリする場合、`read_warehouse_1` 計算グループに `order_dw_tg_default` をロードする必要があります。これにより、
init_warehouse計算グループを使用してデータを書き込み、read_warehouse_1計算グループを使用してサービス検索を実行できます。HoloWeb 開発ページで、SQL Editor をクリックします。インスタンス名とデータベース名を確認し、次のコマンドを実行します。詳細については、「新しい計算グループインスタンスの作成」をご参照ください。データがロードされた後、`read_warehouse_1` が `order_dw_tg_default` テーブルグループからデータをロードしたことを確認します。
-- 現在のデータベースのテーブルグループを表示します。 SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; -- テーブルグループを計算グループにロードします。 CALL hg_table_group_load_to_warehouse ('order_dw.order_dw_tg_default', 'read_warehouse_1', 1); -- 計算グループのテーブルグループのロード状態を表示します。 select * from hologres.hg_warehouse_table_groups; -
右上隅で計算グループを `read_warehouse_1` に切り替えます。この計算グループは、後続のクエリと分析に使用できます。

-
[SQL エディター] ページで、次のコマンドを実行して、MySQL から Hologres に同期された 3 つのテーブルを表示できます。
--- orders のデータをクエリします。 SELECT * FROM orders; --- orders_pay のデータをクエリします。 SELECT * FROM orders_pay; --- product_catalog のデータをクエリします。 SELECT * FROM product_catalog;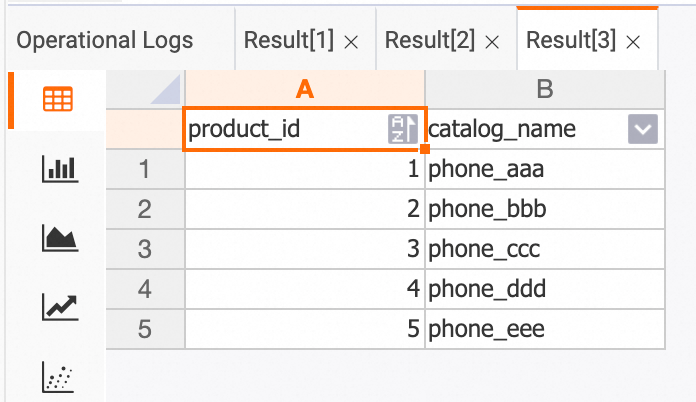
DWD レイヤーの構築:リアルタイムのワイドテーブルを作成します
DWD レイヤーの構築では、Hologres コネクタの部分的な列更新機能を使用します。これにより、`INSERT` DML 文で部分的な更新を簡単に表現できます。このジョブは、ローストアと行列混在ストレージによって実現される Hologres の高性能なポイントクエリ機能を使用して、複数のディメンションテーブルをクエリします。さらに、Hologres の強力なリソース隔離により、書き込み、読み取り、分析のワークロードが互いに干渉しないことが保証されます。
-
Flink カタログ機能を使用して、Hologres に DWD ワイドテーブル `dwd_orders` を作成します。
ページの [クエリスクリプト] タブで、次のコードをクエリスクリプトにコピーし、コードブロックを選択して Run をクリックします。
-- 異なるストリームが同じ結果テーブルに書き込むため、ワイドテーブルのフィールドは null 許容である必要があります。どの列にも null 値が含まれる可能性があります。 CREATE TABLE dw.order_dw.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'platform 0: phone, 1: pc', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); -- カタログを介して Hologres 物理テーブルのプロパティを変更します。 ALTER TABLE dw.order_dw.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' -- Binlog TTL を 1 週間に設定します。 ); -
ODS レイヤーの `orders` および `orders_pay` テーブルからリアルタイムで Binlog を消費します。
ページで、`DWD` という名前の新しい SQL ストリーミングジョブを作成し、次のコードを SQL エディターにコピーしてから、ジョブを [デプロイ] して 起動 します。この SQL ジョブは、`orders` テーブルを `product_catalog` ディメンションテーブルと結合し、最終結果を `dwd_orders` に書き込みます。これにより、リアルタイムのワイドテーブル構築が実現します。
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dwd_orders ( order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name ) SELECT o.*, dim.catalog_name FROM dw.order_dw.orders as o LEFT JOIN dw.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; INSERT INTO dw.order_dw.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM dw.order_dw.orders_pay; END; -
ワイドテーブル `dwd_orders` のデータを表示します。
HoloWeb 開発ページで Hologres インスタンスに接続し、ターゲットデータベースにログインした後、SQL エディターで次のコマンドを実行できます。
SELECT * FROM dwd_orders;
DWS レイヤーの構築:リアルタイムメトリックの計算
-
Flink カタログ機能を使用して、Hologres に DWS 集約テーブル `dws_users` と `dws_shops` を作成します。
ページの [クエリスクリプト] タブで、次のコードをクエリスクリプトにコピーし、コードブロックを選択して Run をクリックします。
-- ユーザーディメンションの集約メトリックテーブル。 CREATE TABLE dw.order_dw.dws_users ( user_id string not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'その日の支払い済み購入金額の合計', primary key(user_id,ds) NOT ENFORCED ); -- 店舗ディメンションの集約メトリックテーブル。 CREATE TABLE dw.order_dw.dws_shops ( shop_id bigint not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'その日の支払い済み購入金額の合計', primary key(shop_id,ds) NOT ENFORCED ); -
DWD ワイドテーブル `dw.order_dw.dwd_orders` をリアルタイムで消費し、Flink で集約を実行し、結果を Hologres DWS テーブルに書き込みます。
ページで、`DWS` という名前の新しい SQL ストリーミングジョブを作成し、次のコードを SQL エディターにコピーしてから、ジョブを [デプロイ] して 起動 します。
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dws_users SELECT order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 注文ストリームと支払いストリームの両方がワイドテーブルに書き込まれています。 GROUP BY order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); INSERT INTO dw.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 注文ストリームと支払いストリームの両方がワイドテーブルに書き込まれています。 GROUP BY order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); END; -
DWS の集約結果を表示します。これは、上流のデータが変更されるとリアルタイムで更新されます。
-
変更前の Hologres コンソールでデータを表示します。
dws_users テーブル
SELECT * FROM dws_users;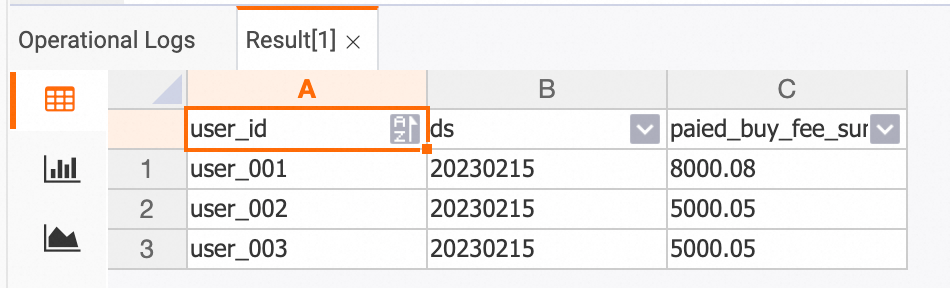
dws_shops テーブル
SELECT * FROM dws_shops;
-
RDS コンソールから `order_dw` データベースの `orders` テーブルと `orders_pay` テーブルにそれぞれ 1 つの新しいレコードを挿入します。
INSERT INTO orders VALUES (100008, 'user_003', 12345, 5, 6000.02, '2023-02-15 09:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 19:40:56'); -
変更後の Hologres コンソールでデータを表示します。
dwd_orders テーブル
SELECT * FROM dwd_orders;
dws_users テーブル
SELECT * FROM dws_users;
dws_shops テーブル
SELECT * FROM dws_shops;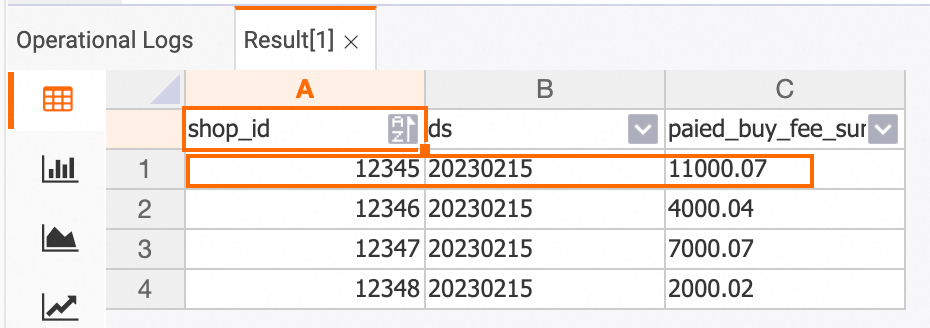
-
データ探索
Binlog が有効になっているため、データの変更を直接観察できます。中間結果のアドホックな探索や最終計算の正当性を検証するために、このソリューションのすべてのレイヤーでデータが永続化されているため、中間状態を簡単に検査できます。
ストリームモード探索
Print コネクタを使用して、他の結果テーブルに送信されるメッセージが期待どおりであることを確認できます。
-
データ探索ストリーミングジョブを作成して開始します。
ページで、`Data-exploration` という名前の新しい SQL ストリーミングジョブを作成し、次のコードを SQL エディターにコピーしてから、ジョブを [デプロイ] して 起動 します。
-- ストリームモード探索:出力を表示してデータの変更を観察します。 CREATE TEMPORARY TABLE print_sink( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int, pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'print' ); INSERT INTO print_sink SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('startTime'='2023-02-15 12:00:00') */ -- startTime は Binlog の生成時刻を指します。 WHERE order_user_id = 'user_001'; -
データ探索の結果を表示します。
のジョブ詳細ページで、ターゲットジョブ名をクリックします。[ジョブログ] タブで、左側の Operational Logs タブをクリックし、[実行中のタスクマネージャー] タブの [パス、ID] をクリックします。Stdout ページで `user_001` に関連するログを検索します。

バッチモード探索
バッチモード探索は、結果テーブルに書き込むことなく、現在の望ましい状態を取得します。これにより、デバッグによって結果を直接検査できます。
ページで、SQL ストリーミングジョブを作成し、次のコードを SQL エディターにコピーしてから、[デバッグ] をクリックします。詳細については、「ジョブのデバッグ」をご参照ください。
Flink ジョブ開発インターフェイスのデバッグ結果は、次の図のように表示されます。
SELECT *
FROM dw.order_dw.dwd_orders /*+ OPTIONS('binlog'='false') */
WHERE order_user_id = 'user_001' and order_create_time > '2023-02-15 12:00:00'; -- バッチモードはフィルタープッシュダウンをサポートし、実行効率を向上させます。
ステップ 3:リアルタイムデータウェアハウスの使用
ステップ 2 では、Flink カタログを使用して、Flink と Hologres を使用する階層化されたリアルタイムデータウェアハウスであるストリーミングウェアハウスを構築する方法を示しました。次のセクションでは、データウェアハウスが構築された後の簡単なアプリケーションシナリオについて説明します。
キー・バリューサービス
DWS レイヤーの集約メトリックテーブルをプライマリキーでクエリでき、数百万 RPS をサポートします。
次の例は、HoloWeb 開発ページで特定の日付の特定のユーザーの支出をクエリする方法を示しています。
-- holo sql
SELECT * FROM dws_users WHERE user_id ='user_001' AND ds = '20230215';
詳細クエリ
DWD ワイドテーブルで OLAP 分析を実行できます。
次の例は、HoloWeb 開発ページで、2023 年 2 月に特定の支払いプラットフォームで特定の顧客の注文詳細をクエリする方法を示しています。
-- holo sql
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time LIMIT 100;
リアルタイムレポート
DWD ワイドテーブルデータに基づいてリアルタイムレポートを生成できます。Hologres の行列混在ストレージと列指向テーブルは、サブ秒の応答時間で優れた OLAP パフォーマンスを提供します。
次の例は、HoloWeb 開発ページで、2023 年 2 月の製品カテゴリごとの総注文数と総注文金額をクエリする方法を示しています。
-- holo sql
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD') AS order_create_date,
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
order_create_date, order_product_catalog_name
ORDER BY
order_create_date, order_product_catalog_name;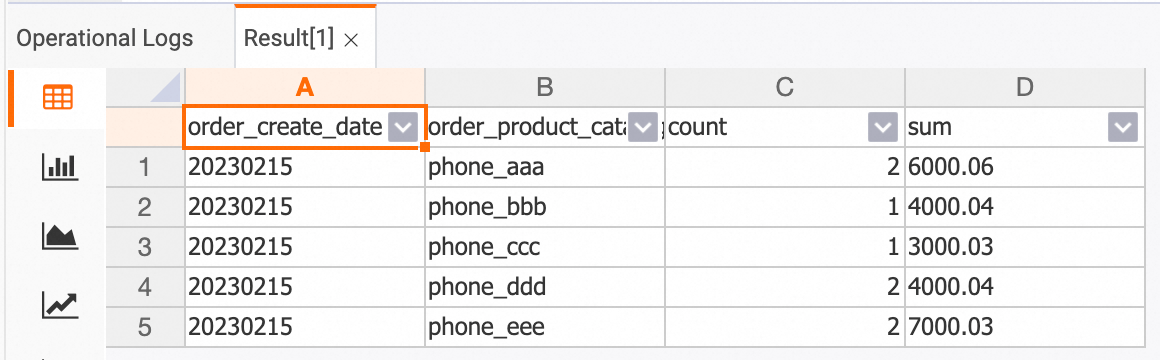
参考資料
-
ビジネスシナリオに関連するベストプラクティスドキュメント:
-
Hologres Binlog 機能の詳細については、「Hologres Binlog のサブスクライブ」をご参照ください。
-
Flink は単一のジョブで複数の `INSERT INTO` 文をサポートしています。構文の詳細については、「INSERT INTO 文」をご参照ください。
-
Realtime Compute for Apache Flink は、さまざまなコネクタをサポートしています。詳細については、「サポートされているコネクタ」をご参照ください。