Hologres は、行指向、列指向、ハイブリッドの 3 種類のテーブルストレージ形式をサポートしています。各形式は、異なるクエリシナリオに合わせて最適化されています。ユースケースに基づいて適切なストレージ形式を選択することで、データ処理とクエリパフォーマンスを大幅に向上させ、ストレージ消費量を削減できます。
ストレージ形式の構文設定
Hologres は、行指向、列指向、ハイブリッドの 3 種類のストレージ形式をサポートしています。テーブルの作成時に orientation プロパティを設定することで、テーブルのストレージ形式を指定します。構文は次のとおりです。
-- Supported from V2.1
CREATE TABLE <table_name> (...) WITH (orientation = '[column | row | row,column]');
-- Supported by all versions
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'orientation', '[column | row | row,column]');
COMMIT;table_name:テーブル名。
orientation:Hologres におけるデータベーステーブルのストレージモードが列指向か行指向かを指定します。Hologres は V1.1 以降、ハイブリッドモードをサポートしています。
デフォルトでは、テーブル作成時に列指向 (列ストレージ) となります。テーブル作成時には、行指向またはハイブリッドストレージを明示的に指定してください。テーブルのストレージ形式を変更するには、テーブルを再作成する必要があります。直接変換はサポートされていません。
使用推奨事項
次の表は、テーブルストレージ形式を選択するための推奨事項を示しています。
ストレージ形式 | シナリオ | 列数制限 | 使用方法 |
列指向 | 複雑なクエリ、データ結合、スキャン、フィルタリング、統計分析を伴う OLAP シナリオに適しています。 | 列数は 300 以下を推奨します。 | 列指向ストレージは、デフォルトで複数のインデックスを作成します。これには文字列型のビットマップインデックスが含まれます。これらのインデックスは、クエリフィルタリングと統計操作を大幅に高速化します。 |
行指向 | 次のクエリ文に示すように、プライマリキーに基づくポイントクエリに適しています。 | 3000 列以下を推奨します。 | 行指向ストレージは、デフォルトでプライマリキーにのみインデックスを作成し、プライマリキー列での高速ルックアップのみをサポートします。これにより、特定のシナリオに適用範囲が限定されます。 |
行と列の共存 | プライマリキー以外のポイントクエリを含む、すべての行指向および列指向シナリオをサポートします。 | 列数は 300 以下を推奨します。 | ハイブリッドストレージは、より広範なシナリオに適用できますが、ストレージオーバーヘッドと内部データ同期コストが高くなります。 |
技術原理
列指向
列指向テーブルでは、データは列ごとに格納されます。列指向ストレージは、デフォルトで ORC 形式を使用します。さまざまなエンコーディングアルゴリズム (RLE や辞書エンコーディングなど) を使用してデータをエンコードし、その後、主要な圧縮アルゴリズム (Snappy、Zlib、Zstd、Lz4 など) を適用して、エンコードされたデータをさらに圧縮します。ビットマップインデックスや遅延マテリアライズなどのメカニズムと組み合わせることで、このアプローチはストレージ効率とクエリパフォーマンスの両方を向上させます。
システムは、基盤となるストレージレイヤーに各テーブルの主キーインデックスファイルを格納します。詳細については、「プライマリキー」をご参照ください。列指向テーブルにプライマリキー (PK) が設定されている場合、システムは行識別子 (RID) を自動的に生成し、データ行全体を迅速に特定します。さらに、分散キーやクラスタリングキーなどの適切なインデックスがクエリ対象の列に定義されている場合、システムはそれらを使用してデータが存在するシャードとファイルを迅速に特定し、クエリパフォーマンスを向上させることができます。その結果、列指向テーブルはより広範なシナリオに適しており、通常は OLAP クエリに使用されます。次の例はこの概念を示しています。
V2.1 以降でサポートされるテーブル作成構文:
CREATE TABLE public.tbl_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, in_time TIMESTAMPTZ NOT NULL, PRIMARY KEY (id) ) WITH ( orientation = 'column', clustering_key = 'class', bitmap_columns = 'name', event_time_column = 'in_time' ); SELECT * FROM public.tbl_col WHERE id ='3333'; SELECT id, class,name FROM public.tbl_col WHERE id < '3333' ORDER BY id;すべてのバージョンでサポートされるテーブル作成構文:
BEGIN; CREATE TABLE public.tbl_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, in_time TIMESTAMPTZ NOT NULL, PRIMARY KEY (id) ); CALL set_table_property('public.tbl_col', 'orientation', 'column'); CALL set_table_property('public.tbl_col', 'clustering_key', 'class'); CALL set_table_property('public.tbl_col', 'bitmap_columns', 'name'); CALL set_table_property('public.tbl_col', 'event_time_column', 'in_time'); COMMIT; SELECT * FROM public.tbl_col WHERE id ='3333'; SELECT id, class,name FROM public.tbl_col WHERE id < '3333' ORDER BY id;
図は次のとおりです。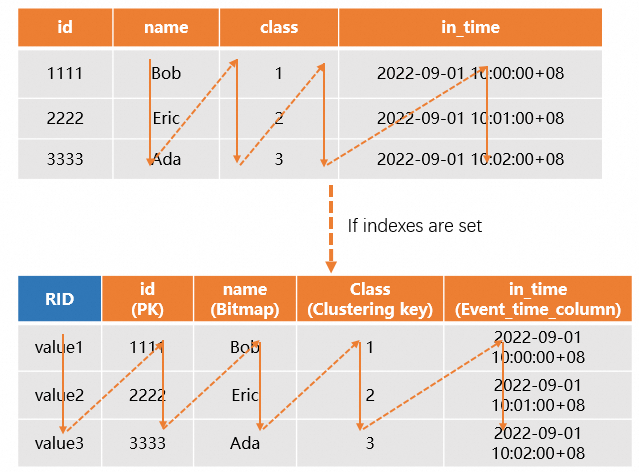
行指向
行指向テーブルでは、データは行ごとに格納されます。行指向ストレージは、デフォルトで SST 形式を使用します。データはキー順に並べられた圧縮ブロックに格納されます。ブロックインデックスやブルームフィルターなどのインデックスは、バックグラウンドコンパクションメカニズムと連携してファイルを整理し、ポイントクエリ効率を最適化します。
(推奨) プライマリキーの設定
システムは、基盤となるストレージレイヤーに各テーブルの主キーインデックスファイルを格納します。詳細については、「プライマリキー」をご参照ください。行指向テーブルにプライマリキー (PK) がある場合、システムはデータ行全体を特定するための行識別子 (RID) を自動的に生成します。システムはまた、PK を分散キーとクラスタリングキーの両方として設定し、データを含むシャードとファイルを迅速に特定できるようにします。プライマリキーに基づくクエリの場合、システムは 1 つの主キーインデックスのみをスキャンして、行全体のすべての列を迅速に取得し、クエリ効率を向上させます。以下に SQL の例を示します。
V2.1 以降でサポートされるテーブル作成構文:
CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT, PRIMARY KEY (id) ) WITH ( orientation = 'row', clustering_key = 'id', distribution_key = 'id' ); -- PK ベースのポイントクエリの例 SELECT * FROM public.tbl_row WHERE id ='1111'; -- 複数キーのクエリ SELECT * FROM public.tbl_row WHERE id IN ('1111','2222','3333');すべてのバージョンでサポートされるテーブル作成構文:
BEGIN; CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); CALL set_table_property('public.tbl_row', 'clustering_key', 'id'); CALL set_table_property('public.tbl_row', 'distribution_key', 'id'); COMMIT; -- PK ベースのポイントクエリの例 SELECT * FROM public.tbl_row WHERE id ='1111'; -- 複数キーのクエリ SELECT * FROM public.tbl_row WHERE id IN ('1111','2222','3333');
図は次のとおりです。
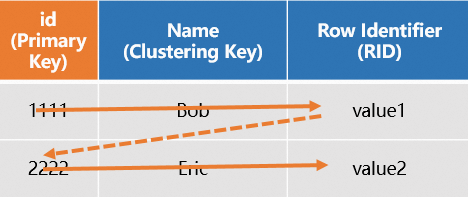
(非推奨) PK とクラスタリングキーの設定の不整合
行指向テーブルを作成し、PK とクラスタリングキーに異なるフィールドを定義した場合、システムはクエリ時にまず PK に基づいてクラスタリングキーと RID を特定します。その後、クラスタリングキーと RID を使用して行全体のデータを取得します。これには 2 回のスキャンが必要となり、パフォーマンスが低下します。SQL の例は次のとおりです。
V2.1 以降でサポートされるテーブル作成構文 (PK とクラスタリングキーが不整合な行指向テーブルの設定):
CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT, PRIMARY KEY (id) ) WITH ( orientation = 'row', clustering_key = 'name', distribution_key = 'id' );すべてのバージョンでサポートされるテーブル作成構文 (PK とクラスタリングキーが不整合な行指向テーブルの設定):
BEGIN; CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); CALL set_table_property('public.tbl_row', 'clustering_key', 'name'); CALL set_table_property('public.tbl_row', 'distribution_key', 'id'); COMMIT;
図は次のとおりです。
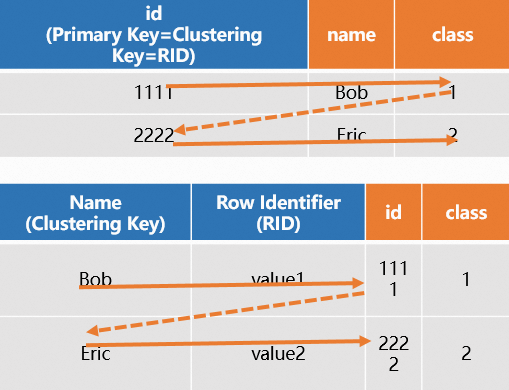
まとめ:行指向テーブルは、プライマリキーに基づくポイントクエリシナリオに非常に適しており、高 QPS のポイントクエリを可能にします。テーブルを作成する際は、PK のみを定義してください。システムは PK を分散キーとクラスタリングキーの両方として自動的に構成し、クエリパフォーマンスを最適化します。PK とクラスタリングキーに異なるフィールドを定義することは、パフォーマンスを低下させるため避けてください。
ハイブリッド
実際のアプリケーションでは、テーブルがプライマリキーポイントクエリと OLAP クエリの両方に使用される場合があります。そのため、Hologres V1.1 ではハイブリッドストレージが導入されました。ハイブリッドストレージは、行指向ストレージと列指向ストレージの両方の機能を組み合わせ、高性能なプライマリキーポイントクエリと OLAP 分析をサポートします。基盤となるレイヤーでは、データは行指向形式と列指向形式で二重に格納されるため、ストレージオーバーヘッドが高くなります。
データ書き込み中、システムは行指向と列指向の両方のコピーを同時に書き込みます。両方のコピーが正常に書き込まれた後にのみ操作は成功を返し、データ原子性を保証します。
クエリ中、オプティマイザーは SQL 文を解析して実行計画を生成します。その後、実行エンジンはこの計画に基づいて、より高いクエリ効率を提供するストレージ形式 (行指向または列指向) を選択します。ハイブリッドテーブルにはプライマリキーが定義されている必要があります。
プライマリキーポイントクエリシナリオ (例:
select * from tbl where pk=xxx文) および SQL 実行を高速化するための固定プランを使用するシナリオでは、オプティマイザーはデフォルトで行指向のプライマリキーポイントクエリパスを使用します。プライマリキー以外のポイントクエリシナリオ (例:
select * from tbl where col1=xx and col2=yyy文) では、特にテーブルに多数の列があり、クエリ結果に多数の列が含まれる場合に、ハイブリッドストレージは大幅な最適化を提供します。実行計画の生成中、オプティマイザーはまず列指向テーブルからデータを読み取ります。次に、取得されたキー値を使用して、行指向テーブルから対応する行をフェッチします。これにより、全表スキャンが回避され、プライマリキー以外のクエリのパフォーマンスが向上します。このシナリオは、ハイブリッドストレージの利点を最大限に活用し、データ取得速度を向上させます。その他の一般的なクエリの場合、システムはデフォルトで列指向ストレージを使用します。
したがって、ハイブリッドテーブルは、一般的なシナリオ、特にプライマリキー以外のポイントクエリにおいて、優れたクエリ効率を提供します。例は次のとおりです。
V2.1 以降でサポートされるテーブル作成構文:
CREATE TABLE public.tbl_row_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, PRIMARY KEY (id) ) WITH ( orientation = 'row,column', distribution_key = 'id', clustering_key = 'class', bitmap_columns = 'name' ); SELECT * FROM public.tbl_row_col WHERE id ='2222'; -- PK ベースのポイントクエリ SELECT * FROM public.tbl_row_col WHERE class='Class Two';-- 非 PK ポイントクエリ SELECT * FROM public.tbl_row_col WHERE id ='2222' AND class='Class Two'; -- 一般的な OLAP クエリすべてのバージョンでサポートされるテーブル作成構文:
BEGIN; CREATE TABLE public.tbl_row_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row_col', 'orientation','row,column'); CALL set_table_property('public.tbl_row_col', 'distribution_key','id'); CALL set_table_property('public.tbl_row_col', 'clustering_key','class'); CALL set_table_property('public.tbl_row_col', 'bitmap_columns','name'); COMMIT; SELECT * FROM public.tbl_row_col WHERE id ='2222'; -- PK ベースのポイントクエリ SELECT * FROM public.tbl_row_col WHERE class='Class Two';-- 非 PK ポイントクエリ SELECT * FROM public.tbl_row_col WHERE id ='2222' AND class='Class Two'; -- 一般的な OLAP クエリ
図は次のとおりです。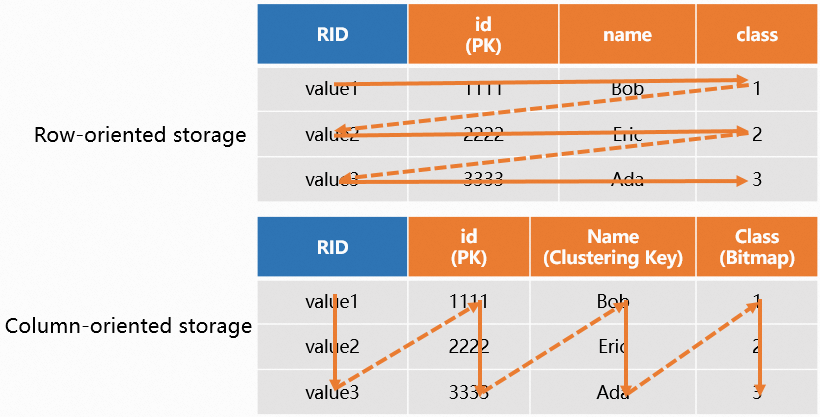
使用例
次の例は、異なるストレージ形式でテーブルを作成する方法を示しています。
V2.1 以降でサポートされるテーブル作成構文:
-- 行指向テーブルの作成 CREATE TABLE public.tbl_row ( a INTEGER NOT NULL, b TEXT NOT NULL, PRIMARY KEY (a) ) WITH ( orientation = 'row' ); -- 列指向テーブルの作成 CREATE TABLE tbl_col ( a INT NOT NULL, b TEXT NOT NULL ) WITH ( orientation = 'column' ); -- 行と列の両方のストレージを持つテーブルの作成 CREATE TABLE tbl_col_row ( pk TEXT NOT NULL, col1 TEXT, col2 TEXT, col3 TEXT, PRIMARY KEY (pk) ) WITH ( orientation = 'row,column' );すべてのバージョンでサポートされるテーブル作成構文:
-- 行指向テーブルの作成 BEGIN; CREATE TABLE public.tbl_row ( a INTEGER NOT NULL, b TEXT NOT NULL, PRIMARY KEY (a) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); COMMIT; -- 列指向テーブルの作成 BEGIN; CREATE TABLE tbl_col ( a INT NOT NULL, b TEXT NOT NULL); CALL set_table_property('tbl_col', 'orientation', 'column'); COMMIT; -- 行と列の両方のストレージを持つテーブルの作成 BEGIN; CREATE TABLE tbl_col_row ( pk TEXT NOT NULL, col1 TEXT, col2 TEXT, col3 TEXT, PRIMARY KEY (pk)); CALL set_table_property('tbl_col_row', 'orientation', 'row,column'); COMMIT;
参考文献
ビジネスのクエリシナリオに基づいて適切なテーブルプロパティを設定する方法の詳細については、「シナリオベースのテーブル作成最適化ガイド」をご参照ください。