本トピックでは、Realtime Compute for Apache Flink を使用して、ApsaraMQ for Kafka から Hologres へログデータをリアルタイムで同期する方法について説明します。本チュートリアルを完了すると、ユーザー記録を継続的に Hologres データウェアハウスへストリーミングする実行中の Flink SQL ジョブが完成し、ソーススキーマの変更にも自動的に対応できるようになります。
アーキテクチャ概要
このパイプラインは、以下のデータフローに従います:
[Faker コネクタ] → [ApsaraMQ for Kafka] → [Realtime Compute for Apache Flink] → [Hologres]Faker コネクタは合成ユーザー記録を生成し、それを ApsaraMQ for Kafka のトピックへ書き込みます。Realtime Compute for Apache Flink はそのトピックからデータを読み取り、Flink SQL を用いて変換を行い、結果を Hologres データウェアハウスへ書き込みます。これらの 3 つのサービスは、すべて同一の VPC 内に配置する必要があります。
本チュートリアルの手順
IP アドレスホワイトリストの設定
ApsaraMQ for Kafka インスタンス向けテストデータの準備
Hologres カタログの作成(CTAS メソッドのみ)
データ同期ジョブの開発および開始
完全データ同期の結果の確認
テーブルスキーマ変更の自動同期機能の確認
前提条件
開始する前に、以下の条件が満たされていることを確認してください:
-
Realtime Compute for Apache Flink の開発コンソールにアクセスするために使用する Resource Access Management (RAM) ユーザーまたは RAM ロールには、必要な権限が付与されている必要があります。詳細については、「権限管理」をご参照ください。
-
Flink ワークスペースが作成されています。詳細については、「Realtime Compute for Apache Flink を有効化する」をご参照ください。
-
上流および下流のストレージインスタンスが作成済みであること:
ApsaraMQ for Kafka および Hologres のインスタンスは、Flink ワークスペースと同じ VPC 内に配置されている必要があります。これは厳格なネットワーク要件です。サービスが同じ VPC 内に配置されていない場合、接続エラーが発生します。同じ VPC 内にない場合は、先に進む前にそれらの間で接続を作成する必要があります。詳細については、「Realtime Compute for Apache Flink は VPC をまたいでサービスにアクセスできますか?」または「Realtime Compute for Apache Flink はインターネットにアクセスできますか?」をご参照ください。
ステップ 1:IP アドレスホワイトリストの設定
Flink ワークスペースから Kafka インスタンスおよび Hologres インスタンスへアクセスできるようにするため、Flink ワークスペースが配置されている vSwitch の CIDR ブロックを、両インスタンスのホワイトリストに追加します。
-
Flink ワークスペースが配置されている vSwitch の CIDR ブロックを取得します。
-
Realtime Compute for Apache Flink コンソール にログインします。
-
対象のワークスペースを見つけ、
[アクション] 列で[その他] >[ワークスペースの詳細] を選択します。 -
ワークスペースの詳細 ダイアログボックスで、vSwitch のCIDR ブロック をコピーします。
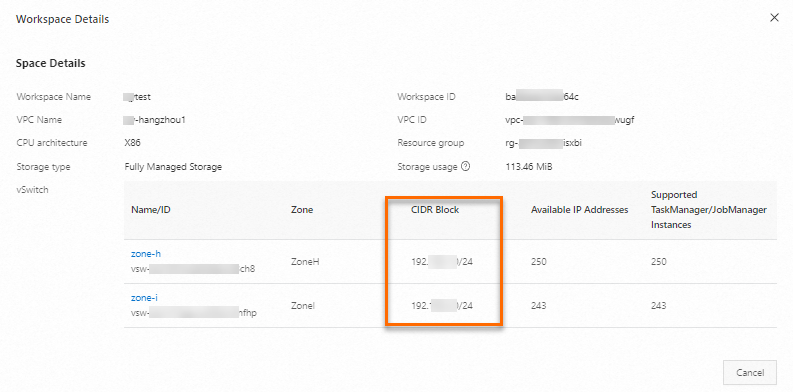
-
-
Kafka インスタンスの IP アドレスのホワイトリストに CIDR ブロックを追加する。
CIDR ブロックを、
[VPC] ネットワークのエンドポイントの許可リストに追加します。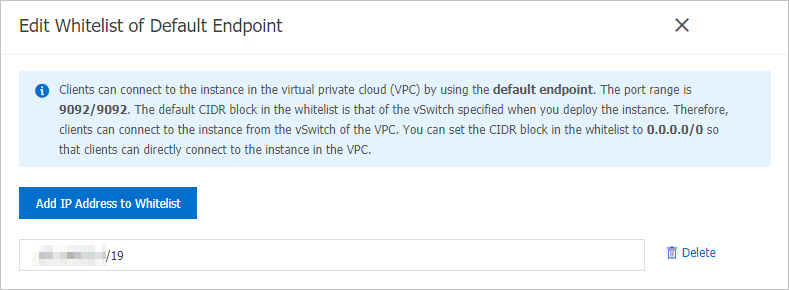
-
Hologres インスタンスの IP アドレスホワイトリストに CIDR ブロックを追加する。
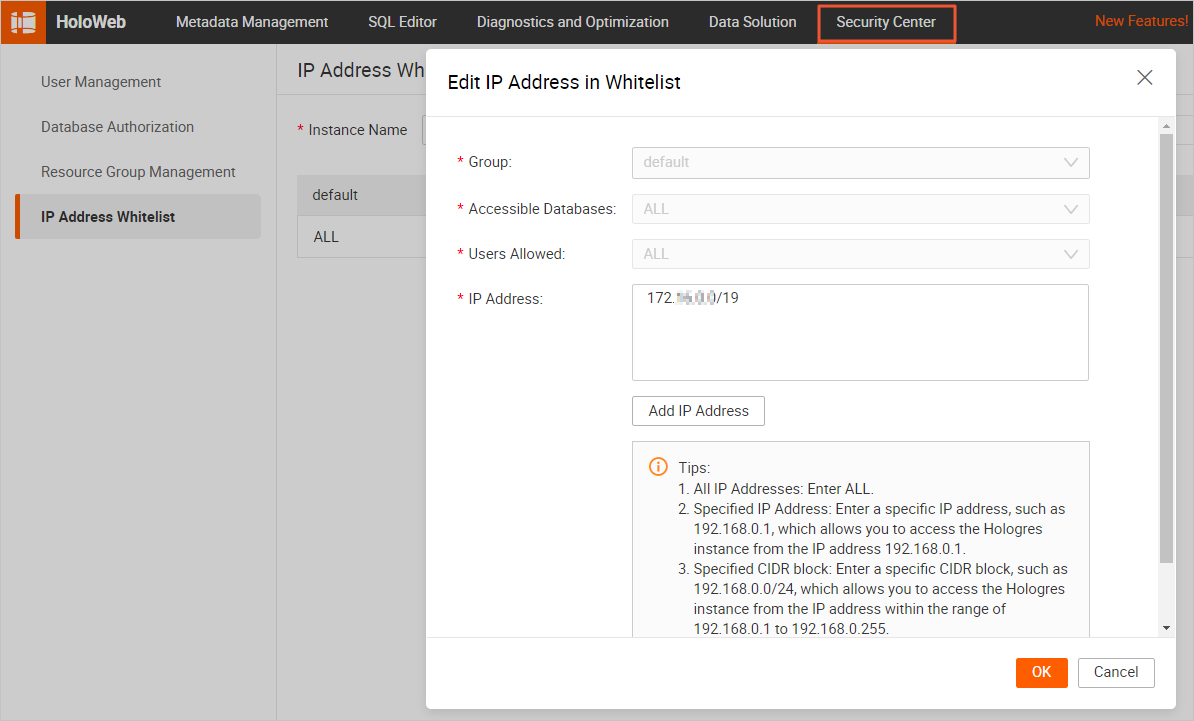
ステップ 2:ApsaraMQ for Kafka インスタンス向けテストデータの準備
Realtime Compute for Apache Flink の Faker コネクタ をデータ生成ツールとして使用し、データを ApsaraMQ for Kafka インスタンスに書き込みます。
このステップおよびステップ 4 で使用するため、
-
ApsaraMQ for Kafka コンソールで、
users という名前のトピックを作成します。 -
Kafka トピックへデータを書き込むジョブを開発します。
-
対象のワークスペースを見つけ、
[コンソール] を[操作] 列でクリックします。 -
左側ナビゲーションウィンドウで、
開発 >ETL を選択します。表示されたページで、新規作成 をクリックします。 -
新規ドラフト ダイアログボックスで、空のストリームドラフト を選択し、次へ をクリックします。ドラフトを以下のように設定します:設定項目
例
説明
名前 kafka-data-input SQL ドラフトの名前。注:ドラフト名は、現在の名前空間内で一意である必要があります。
場所 開発 ドラフトのコードファイルが保存されるフォルダ。デフォルトでは、ドラフトのコードファイルは
開発 フォルダに保存されます。既存のフォルダの右側にあるアイコンをクリックすることで、サブフォルダを作成することもできます。エンジンバージョン vvr-8.0.11-flink-1.17 ドラフトのエンジンバージョンをドロップダウンリストから選択します。
-
作成 をクリックします。 -
以下のコードスニペットを SQL エディターにコピー&ペーストし、
properties.bootstrap.servers のプレースホルダー値を実際の Kafka エンドポイント(上記の注を参照)に置き換えます。CREATE TEMPORARY TABLE source ( id INT, first_name STRING, last_name STRING, `address` ROW<`country` STRING, `state` STRING, `city` STRING>, event_time TIMESTAMP ) WITH ( 'connector' = 'faker', 'number-of-rows' = '100', 'rows-per-second' = '10', 'fields.id.expression' = '#{number.numberBetween ''0'',''1000''}', 'fields.first_name.expression' = '#{name.firstName}', 'fields.last_name.expression' = '#{name.lastName}', 'fields.address.country.expression' = '#{Address.country}', 'fields.address.state.expression' = '#{Address.state}', 'fields.address.city.expression' = '#{Address.city}', 'fields.event_time.expression' = '#{date.past ''15'',''SECONDS''}' ); CREATE TEMPORARY TABLE sink ( id INT, first_name STRING, last_name STRING, `address` ROW<`country` STRING, `state` STRING, `city` STRING>, `timestamp` TIMESTAMP METADATA ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092', 'topic' = 'users', 'format' = 'json' ); INSERT INTO sink SELECT * FROM source; 設定項目
例
説明
properties.bootstrap.servers alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092 Kafka ブローカーのエンドポイント。形式:
host:port,host:port,host:port 。取得方法については、上記の注を参照してください。topic users Kafka トピックの名前。
-
ジョブを開始します。
-
SQL エディターの右上隅にある
デプロイ をクリックします。 -
ドラフトのデプロイ ダイアログボックスで、確認 をクリックします。 -
「
O&M 」>「デプロイメント 」に移動し、対象のデプロイメントを見つけ、「開始 」列の「操作 」をクリックします。デプロイメントを開始する際に設定する必要があるパラメーターについて詳しくは、「デプロイメントの開始」をご参照ください。 -
デプロイメント ページで、デプロイメントの状態を確認します。
Faker コネクタは有限ストリームを提供するため、デプロイメントは
RUNNING 状態に達してから約 1 分後にFINISHED 状態に遷移します。終了後、データは送信先の Kafka トピックへ書き込まれます。以下は、ApsaraMQ for Kafka へ書き込まれた JSON 形式のメッセージのサンプルです:{ "id": 765, "first_name": "Barry", "last_name": "Pollich", "address": { "country": "United Arab Emirates", "state": "Nevada", "city": "Powlowskifurt" } }
-
ステップ 3:Hologres カタログの作成
本ステップは、
CTAS を使用した単一テーブル同期の場合、Realtime Compute for Apache Flink の開発コンソールで、送信先カタログとして Hologres カタログを作成します。このセクションでは、基本的な設定項目について説明します。詳細については、「Hologres カタログの作成」をご参照ください。
|
設定項目 |
説明 |
|---|---|
|
|
任意の名前を入力します。本例では |
|
|
ご利用の Hologres インスタンスのエンドポイント。 |
|
|
Alibaba Cloud アカウントの AccessKey ID。 |
|
|
Alibaba Cloud アカウントの AccessKey Secret。 |
|
|
Hologres の既存のデータベース名を入力します。この例では、 |
ステップ 4:データ同期ジョブの開発および開始
同期方法の選択
コードを記述する前に、ご使用のユースケースに合った方法を選択してください:
|
CTAS |
INSERT INTO |
|
|---|---|---|
|
テーブル作成 |
Flink が Hologres テーブルを自動的に作成 |
まず Hologres で手動でテーブルを作成 |
|
JSON 処理 |
ネストされたカラムが自動展開される( |
ネストされた JSON をネイティブな JSONB カラムに直接マッピング可能 |
|
スキーマ進化 |
新しいネストカラムが出現した際に、Hologres スキーマが自動更新される |
手動でのスキーマ更新が必要 |
|
ステップ 3 の必要性 |
はい — Hologres カタログを事前に作成する必要があります |
いいえ — 接続は WITH 句で直接指定 |
|
推奨用途 |
迅速なセットアップ;スキーマ柔軟なパイプライン |
カラム型に対する完全な制御;JSONB 最適化 |
同期ジョブの作成
-
ターゲットのワークスペースを見つけ、
[操作] 列の[コンソール] をクリックします。 -
左側ナビゲーションウィンドウで、
開発 >ETL を選択します。表示されたページで、新規作成 をクリックします。 -
新規ドラフト ダイアログボックスで、空のストリームドラフト を選択し、次へ をクリックします。ドラフトを以下のように設定します:設定項目
例
説明
名前 flink-quickstart-test SQL ドラフトの名前。注:ドラフト名は、現在の名前空間内で一意である必要があります。
場所 開発 ドラフトのコードファイルが保存されるフォルダ。デフォルトでは、ドラフトのコードファイルは
開発 フォルダに保存されます。既存のフォルダの右側にあるアイコンをクリックすることで、サブフォルダを作成することもできます。エンジンバージョン vvr-8.0.11-flink-1.17 ドラフトのエンジンバージョンをドロップダウンリストから選択します。
-
作成 をクリックします。 -
以下のいずれかのコードスニペットを SQL エディターにコピー&ペーストし、プレースホルダー値を実際の値に置き換えます。
方法 1:CTAS
CREATE TABLE AS(CTAS)文により、Hologres 内に
プレースホルダー値を置き換えます:
|
設定項目 |
例 |
説明 |
|---|---|---|
|
|
|
Kafka ブローカーのエンドポイント。形式: |
|
|
|
Kafka トピックの名前。 |
方法 2:INSERT INTO
ネストされた JSON データを Hologres のネイティブ JSONB カラムとして格納したい場合に、INSERT INTO 文を使用します。この方法では、ジョブを実行する前に、Hologres で
プレースホルダー値を置き換えます:
|
設定項目 |
例 |
説明 |
|---|---|---|
|
|
|
Kafka ブローカーのエンドポイント。形式: |
|
|
|
Kafka トピックの名前。 |
|
|
|
Hologres インスタンスのエンドポイント。形式: |
|
|
|
Alibaba Cloud アカウントの AccessKey ID です。重要: 認証情報を保護するため、AccessKey ペアをプレーンテキストでハードコーディングすることは避け、代わりに変数を使用してください。詳細については、「変数の管理」をご参照ください。 |
|
|
|
Alibaba Cloud アカウントの AccessKey Secret。 |
|
|
|
Hologres データベースの名前。 |
|
|
|
Hologres テーブルの名前です。注: INSERT INTO を使用する場合は、事前に送信先の Hologres データベースに |
ジョブのデプロイおよび開始
-
ドラフトを保存します。
-
デプロイ をクリックします。 -
「
[運用と保守] 」 > 「[デプロイメント] 」に移動し、対象のデプロイメントを見つけ、「[操作] 」列の「[開始] 」をクリックします。デプロイメントの開始時に設定するパラメーターについて詳しくは、「デプロイメントの開始」をご参照ください。 -
デプロイメント ページで、デプロイメントの状態および詳細を確認します。
ステップ 5:完全データ同期の結果の確認
同期ジョブが
-
Hologres コンソール にログインします。
-
インスタンス ページで、対象インスタンスの名前をクリックします。 -
ページの右上隅で、
インスタンスへの接続 をクリックします。 -
メタデータ管理 タブで、sync_kafka_users テーブルのスキーマおよびデータを確認します。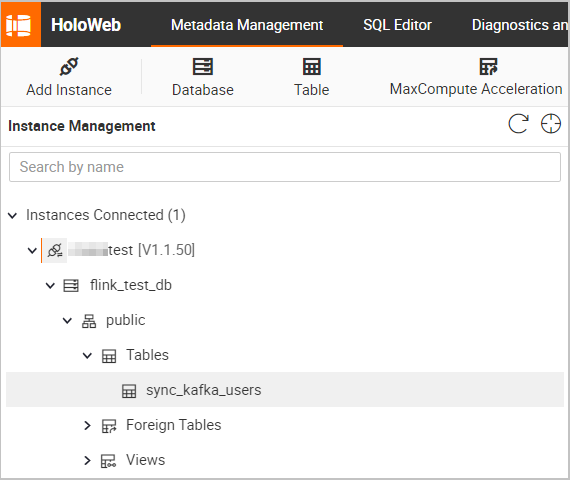
-
テーブルスキーマ:
sync_kafka_users テーブルの名前をダブルクリックして、テーブルスキーマを表示します。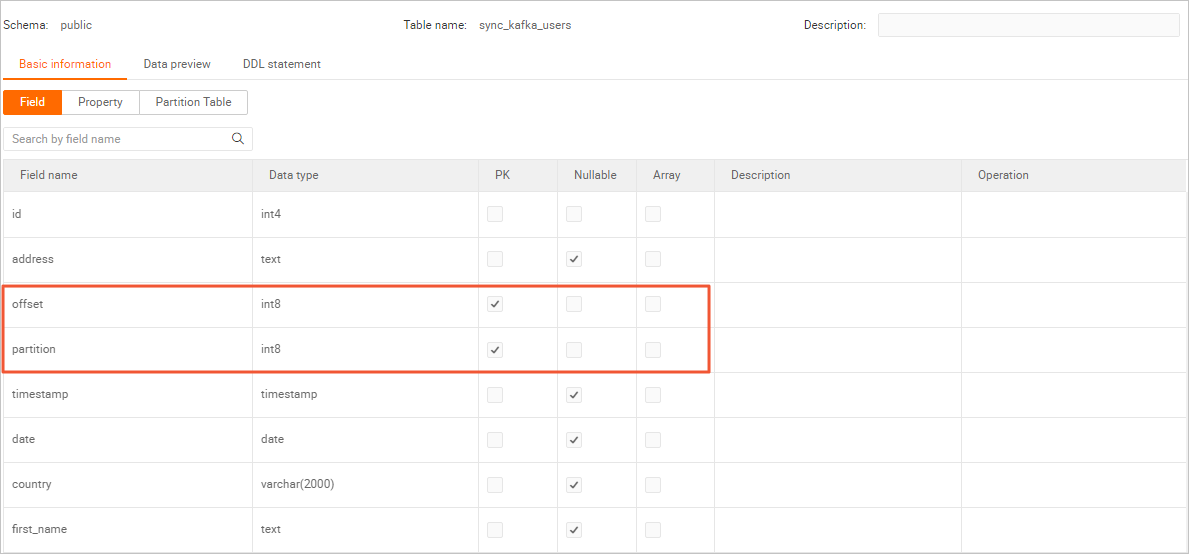 説明
説明Kafka の
partition およびoffset フィールドを Hologres テーブルのプライマリキーとして宣言します。デプロイメントのフェールオーバーによりデータが再送信された場合でも、同じpartition およびoffset 値を持つデータは 1 つのコピーのみが保存されます。 -
テーブルデータ:
sync_kafka_users テーブルページの右上隅で、テーブルの照会 をクリックします。SQL エディターで以下のステートメントを実行し、実行 をクリックします:SELECT * FROM public.sync_kafka_users order by partition, "offset"; 100 行のデータが表示され、Faker コネクタの
'number-of-rows' = '100' 設定と一致しているはずです。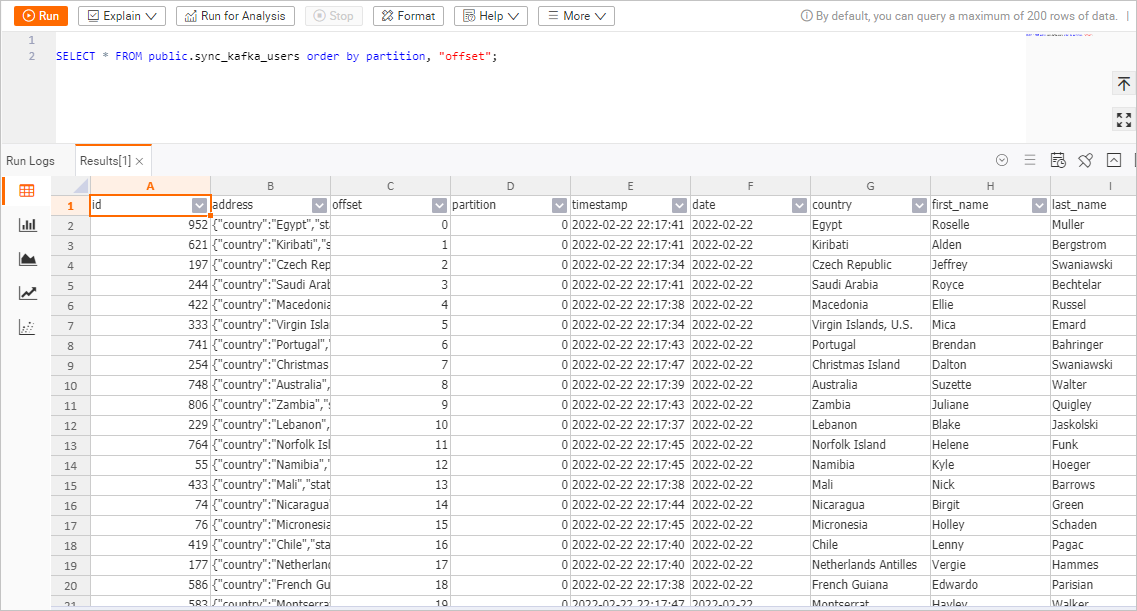
-
ステップ 6:テーブルスキーマ変更の自動同期機能の確認
本ステップでは、スキーマ進化を実証します。新しいネストカラムを含む Kafka メッセージを送信し、Hologres が対応するカラムを自動的に追加することを確認します。
-
ApsaraMQ for Kafka コンソールで、新しいカラムを含むメッセージを送信します。
-
ApsaraMQ for Kafka コンソール にログインします。
-
インスタンス ページで、対象インスタンスの名前をクリックします。 -
左側ナビゲーションウィンドウで、
トピック をクリックします。users という名前のトピックを特定します。 -
[メッセージの送信] を[操作] 列でクリックします。 -
メッセージの送信および消費の開始 パネルで、以下のパラメーターを設定します。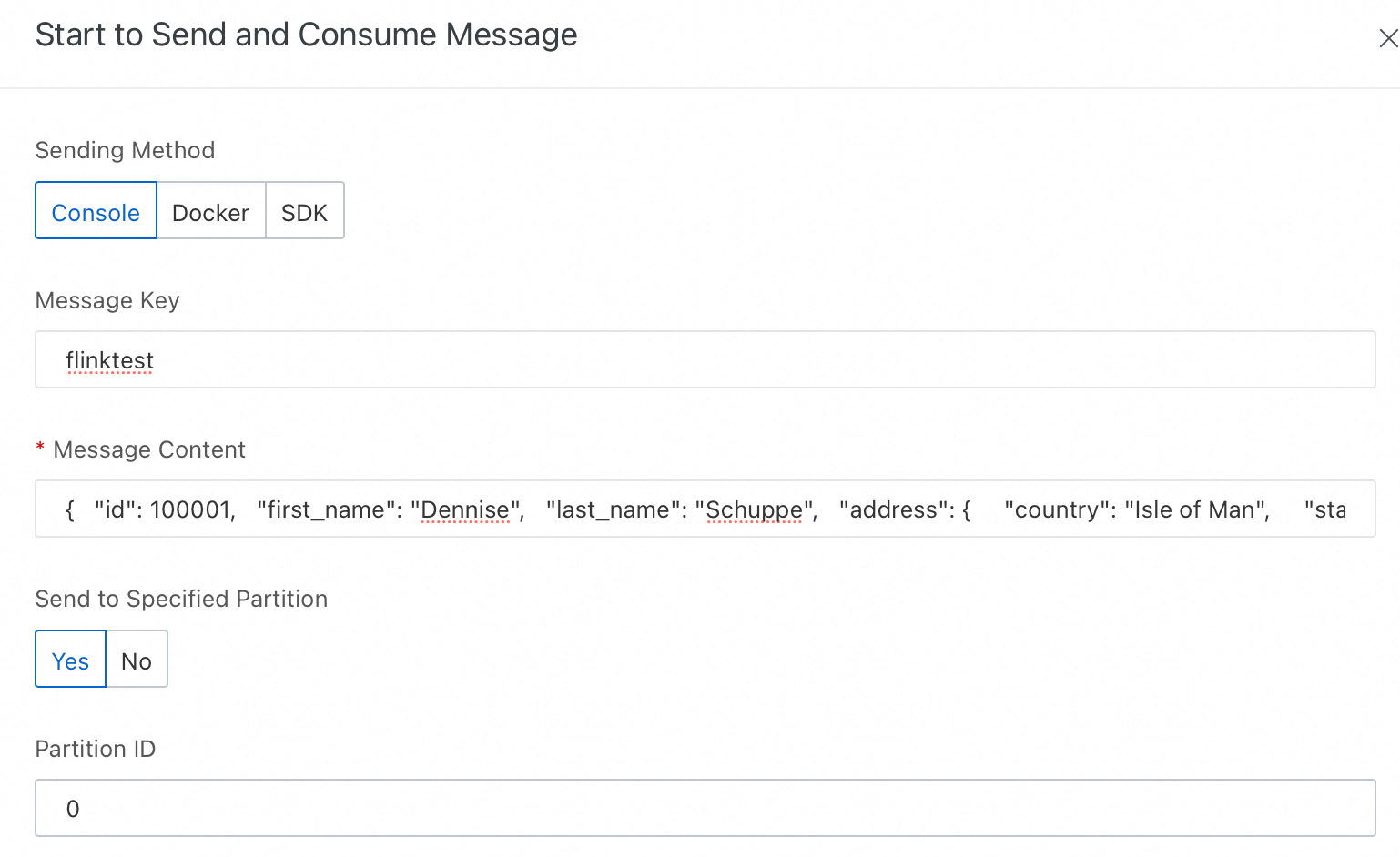
設定項目
例
送信方法 コンソール を選択します。メッセージキー flinktest を入力します。メッセージコンテンツ メッセージコンテンツ フィールドに、以下の JSON コンテンツをコピー&ペーストします。注:本メッセージには、新しいネストカラムhouse-points が含まれています。指定パーティションへの送信 はい を選択します。パーティション ID 0 を入力します。{ "id": 100001, "first_name": "Dennise", "last_name": "Schuppe", "address": { "country": "Isle of Man", "state": "Montana", "city": "East Coleburgh" }, "house-points": { "house": "Pukwudgie", "points": 76 } } -
OK をクリックします。
-
-
Hologres コンソールで、
sync_kafka_users テーブルのスキーマおよびデータの変更を確認します。-
Hologres コンソール にログインします。
-
インスタンス ページで、対象インスタンスの名前をクリックします。 -
ページの右上隅で、
インスタンスへの接続 をクリックします。 -
メタデータ管理 タブで、sync_kafka_users テーブルの名前をダブルクリックします。 -
sync_kafka_users テーブルページの右上隅で、テーブルの照会 をクリックします。SQL エディターで以下のステートメントを実行し、実行 をクリックします:SELECT * FROM public.sync_kafka_users order by partition, "offset"; -
テーブルデータを確認します。
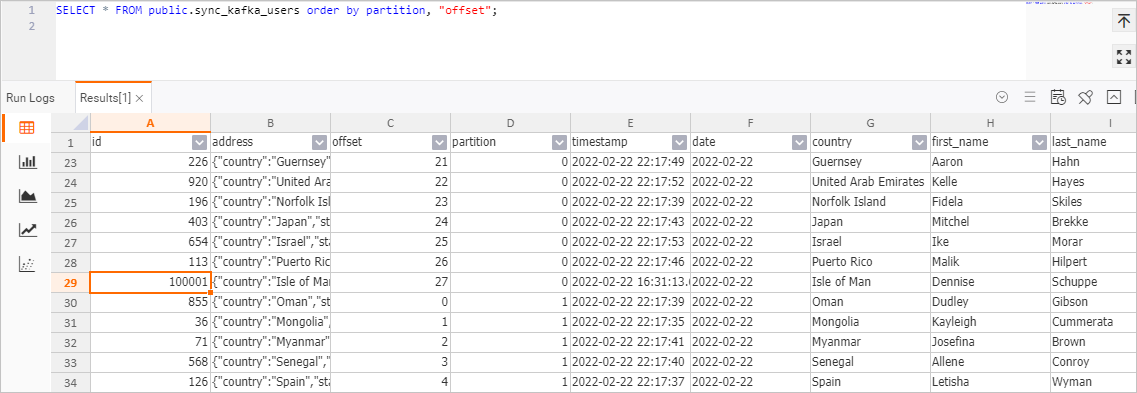
結果より、
id が 100001 のデータレコードが Hologres へ書き込まれていることがわかります。また、house-points.house およびhouse-points.points のカラムも Hologres へ自動的に追加されています。説明Kafka の
users テーブルの WITH 句でjson.infer-schema.flatten-nested-columns.enable がtrue に設定されているため、Realtime Compute for Apache Flink は、新たに出現したネストカラムを自動的に展開します。各カラムへのアクセスパスが、そのカラム名となります。
-
まとめおよび次のステップ
Realtime Compute for Apache Flink を使用して、ApsaraMQ for Kafka から Hologres へユーザー記録をリアルタイムでストリーミングするログインジェストパイプラインを、自動スキーマ進化機能付きで正常に構築しました。
本チュートリアルでは、以下の作業を行いました:
ネットワークホワイトリストを構成し、Flink が Kafka および Hologres へアクセスできるようにしました。
Faker をベースとしたデータ生成器をデプロイし、100 件の合成レコードを Kafka トピックへ書き込みました。
Kafka から Hologres へデータを継続的に同期する Flink SQL ジョブを作成しました。
スキーマ変更(新しいネストカラム)が Hologres へ自動的に伝播されることを検証しました。
さらに学習を進めるには、以下のトピックをご参照ください:
CREATE TABLE AS (CTAS) 文 — 高度な CTAS オプションおよび動作について学びます。
Kafka コネクタ — 本番ワークロード向けのコネクタの全構成オプションを確認します。
デプロイメントを設定する — 本番稼働用にリソース割り当て、チェックポイント、およびその他のデプロイメント設定を調整します。
リファレンス
-
タスクのパフォーマンスを向上させるためにノードの並列度およびリソースを変更する方法について詳しくは、「デプロイメントの設定」をご参照ください。