このトピックでは、Realtime Compute for Apache Flink、Paimon、StarRocks を使用してストリーミングデータレイクハウスを構築する方法について説明します。
背景情報
ビジネスのデジタル化が進むにつれて、タイムリーなデータへの需要が高まっています。従来のオフラインデータウェアハウスは、明確な方法論に従っています。スケジュールされたオフラインジョブを使用して、前の期間からの新しい変更を、運用データストア (ODS)、データウェアハウス詳細 (DWD)、データウェアハウスサマリー (DWS)、およびアプリケーションデータストア (ADS) レイヤーを含む階層型ウェアハウスにマージします。しかし、このアプローチには、高レイテンシーと高コストという 2 つの大きな問題があります。オフラインジョブは通常、1 時間に 1 回、あるいは 1 日に 1 回しか実行されません。これは、データコンシューマーが前の時間または日のデータしか見ることができないことを意味します。さらに、データ更新はしばしばパーティション全体を上書きします。このプロセスは、パーティション内のすべての元のデータを再読み取りして新しい変更とマージする必要があるため、非効率的です。
Realtime Compute for Apache Flink と Paimon を使用してストリーミングデータレイクハウスを構築することで、従来のオフラインデータウェアハウスの問題を解決できます。Flink のリアルタイムコンピューティング機能により、データはデータウェアハウスレイヤー間をリアルタイムで流れることができます。Paimon の効率的な更新機能により、データの変更を分レベルのレイテンシーでダウンストリームのコンシューマーに配信できます。したがって、ストリーミングデータレイクハウスは、レイテンシーとコストの両方で利点があります。
Paimon の特徴の詳細については、「特徴」および Apache Paimon 公式ウェブサイトをご参照ください。
アーキテクチャと利点
アーキテクチャ
Realtime Compute for Apache Flink は、大量のリアルタイムデータを効率的に処理できる強力なストリーム処理エンジンです。Paimon は、ストリーム処理とバッチ処理のための統一されたレイクストレージフォーマットであり、高スループットの更新と低レイテンシーのクエリをサポートします。Paimon は Flink と深く統合されており、統合されたストリーミングデータレイクハウスソリューションを提供します。次の図は、Flink と Paimon で構築されたストリーミングデータレイクハウスのアーキテクチャを示しています。
Flink はデータソースから Paimon にデータを書き込み、ODS レイヤーを形成します。
Flink は ODS レイヤーの changelog をサブスクライブし、データを処理した後、Paimon に書き戻して DWD レイヤーを形成します。
Flink は DWD レイヤーの changelog をサブスクライブし、データを処理した後、Paimon に書き戻して DWS レイヤーを形成します。
最後に、E-MapReduce の StarRocks が Paimon 外部テーブルを読み取り、アプリケーションクエリを実行します。

利点
このソリューションには、次の利点があります。
Paimon の各レイヤーは、分レベルのレイテンシーでダウンストリームのコンシューマーに変更を配信できます。これにより、従来のオフラインデータウェアハウスのレイテンシーが時間単位、あるいは日単位から分単位に短縮されます。
Paimon の各レイヤーは、パーティションを上書きすることなく、変更データを直接受け入れることができます。これにより、従来のオフラインデータウェアハウスでのデータ更新と修正のコストが大幅に削減されます。また、中間レイヤーのデータがクエリ、更新、修正が困難であるという問題も解決します。
モデルが統一され、アーキテクチャが簡素化されます。ETL (抽出、変換、ロード) パイプラインのロジックは Flink SQL を使用して実装されます。ODS、DWD、DWS レイヤーのデータは Paimon に一元的に保存されます。これにより、アーキテクチャの複雑さが軽減され、データ処理効率が向上します。
このソリューションは、Paimon の 3 つのコア機能に依存しています。次の表に詳細を示します。
Paimon のコア機能 | 詳細 |
プライマリキーテーブルの更新 | Paimon は、基盤となるレイヤーで LSM (Log-Structured Merge-tree) ツリーデータ構造を使用して、効率的なデータ更新を実現します。 Paimon のプライマリキーテーブルと基盤となるデータ構造の詳細については、Primary Key Table および File Layouts をご参照ください。 |
増分データ生成メカニズム (Changelog Producer) | Paimon は、任意の入力データストリームに対して完全な changelog を生成できます。すべての update_after レコードには対応する update_before レコードがあります。これにより、変更がダウンストリームのコンシューマーに完全に渡されることが保証されます。詳細については、「増分データ生成メカニズム」をご参照ください。 |
データマージメカニズム (Merge Engine) | Paimon のプライマリキーテーブルが同じプライマリキーを持つ複数のレコードを受け取ると、結果テーブルはそれらを 1 つのレコードにマージして一意性を維持します。Paimon は、重複排除、部分更新、事前集約など、さまざまなマージ動作をサポートしています。詳細については、「データマージメカニズム」をご参照ください。 |
利用シーン
このトピックでは、E コマースプラットフォームを例に、ストリーミングデータレイクハウスを構築してデータを処理・クレンジングし、アプリケーションからのデータクエリをサポートする方法を示します。ストリーミングデータレイクハウスは、データの階層化と再利用を実装します。また、取引ダッシュボードのレポートクエリ、行動データ分析、ユーザーペルソナのタグ付け、パーソナライズされたレコメンデーションなど、複数のビジネスシナリオをサポートします。

ODS レイヤーの構築:ビジネスデータベースのデータをリアルタイムでデータウェアハウスに取り込みます。
MySQL データベースには、orders テーブル、orders_pay テーブル、product_catalog ディクショナリテーブルの 3 つのビジネス テーブルがあります。Flink はこれらのテーブルからリアルタイムで OSS にデータを書き込みます。データは Paimon フォーマットで ODS レイヤーとして保存されます。DWD レイヤーの構築:トピックベースのワイドテーブルを作成します。
orders テーブル、product_catalog テーブル、orders_pay テーブルは、Paimon の部分更新マージメカニズムを使用してワイド化されます。これにより、DWD レイヤーのワイドテーブルが生成され、分レベルのレイテンシーで changelog が生成されます。DWS レイヤーの構築:メトリックを計算します。
Flink はワイドテーブルの changelog をリアルタイムで消費します。Paimon の事前集約マージメカニズムを使用して、DWM レイヤーの `dwm_users_shops` (ユーザー-店舗集約中間テーブル) を生成します。最終的に、DWS レイヤーの `dws_users` (ユーザー集約メトリックテーブル) と `dws_shops` (店舗集約メトリックテーブル) を生成します。
前提条件
Data Lake Formation (DLF) を有効化済みであること。ストレージサービスとして DLF 2.5 の使用を推奨します。詳細については、「DLF の概要」をご参照ください。
フルマネージド Flink を有効化済みであること。詳細については、「Realtime Compute for Apache Flink の有効化」をご参照ください。
EMR の StarRocks を有効化済みであること。詳細については、「コンピューティングとストレージが分離されたインスタンスのクイックスタート」をご参照ください。
StarRocks インスタンス、DLF、および Flink ワークスペースは同じリージョンにある必要があります。
制限事項
このストリーミングデータレイクハウスソリューションは、Ververica Runtime (VVR) 11.1.0 以降でのみサポートされています。
ストリーミングデータレイクハウスの構築
MySQL CDC データソースの準備
このトピックでは、ApsaraDB RDS for MySQL インスタンスを例として使用します。order_dw という名前のデータベースを作成し、3 つのビジネステーブルにデータを入力する必要があります。
ApsaraDB RDS for MySQL インスタンスの作成。
重要ApsaraDB RDS for MySQL インスタンスは、Flink ワークスペースと同じ VPC にある必要があります。同じ VPC にない場合は、「VPC をまたいで他のサービスにアクセスするにはどうすればよいですか?」をご参照ください。
データベースとアカウントの作成 (非推奨、"ステップ 1" にリダイレクト)。
order_dw という名前のデータベースを作成します。order_dw データベースに対する読み取りおよび書き込み権限を持つ特権アカウントまたは標準アカウントを作成します。
3 つのテーブルを作成し、データを挿入します。
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee bigint not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- データを準備します。 INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
メタデータ管理
Paimon カタログの作成
左側のナビゲーションウィンドウで、[メタデータ管理] ページに移動し、[カタログの作成] をクリックします。
[組み込みカタログ] タブで、[Apache Paimon] をクリックし、次に [次へ] をクリックします。
次のパラメーターを入力し、ストレージタイプとして DLF を選択して、[OK] をクリックします。
構成項目
説明
必須
備考
metastore
メタストアのタイプ。
はい
この例では、dlf を選択します。
catalog name
DLF データカタログの名前。
重要Resource Access Management (RAM) ユーザーまたはロールを使用する場合は、DLF データに対する読み取りおよび書き込み権限があることを確認してください。詳細については、「データ権限付与管理」をご参照ください。
はい
DLF 2.5 の使用を推奨します。AccessKey やその他の情報を入力する必要はありません。既存の DLF データカタログをすばやく選択できます。データカタログを作成するには、「データカタログ」をご参照ください。
paimoncatalog という名前のデータカタログを作成した後、リストからそれを選択します。
データカタログに order_dw データベースを作成します。このデータベースは、MySQL の order_dw データベース内のすべてのテーブルからデータを同期するために使用されます。
左側のナビゲーションウィンドウで、 を選択します。[新規作成] をクリックして、一時的なクエリを作成します。
-- paimoncatalog データソースを使用します。 USE CATALOG paimoncatalog; -- order_dw データベースを作成します。 CREATE DATABASE order_dw;The following statement has been executed successfully!というメッセージは、データベースが作成されたことを示します。
Paimon カタログの使用方法の詳細については、「Paimon カタログの管理」をご参照ください。
MySQL カタログの作成
[メタデータ管理] ページで、[カタログの作成] をクリックします。
[組み込みカタログ] タブで [MySQL] をクリックし、次に [次へ] をクリックします。
次のパラメーターを入力し、[OK] をクリックして mysqlcatalog という名前の MySQL カタログを作成します。
構成項目
説明
必須
備考
catalog name
カタログの名前。
はい
英語でカスタム名を入力します。このトピックでは mysqlcatalog を例として使用します。
hostname
MySQL データベースの IP アドレスまたはホスト名。
はい
詳細については、「インスタンスのエンドポイントとポートの表示と管理」をご参照ください。ApsaraDB RDS for MySQL インスタンスとフルマネージド Flink ワークスペースは同じ VPC にあるため、プライベートネットワークアドレスを入力します。
port
MySQL データベースサービスのポート番号。デフォルト値は 3306 です。
いいえ
詳細については、「インスタンスのエンドポイントとポートの表示と管理」をご参照ください。
default-database
デフォルトの MySQL データベースの名前。
はい
同期するデータベースの名前を入力します。このトピックでは order_dw です。
username
MySQL データベースサービスのユーザー名。
はい
これは、「MySQL CDC データソースの準備」セクションで作成したアカウントです。
password
MySQL データベースサービスのパスワード。
はい
これは、「MySQL CDC データソースの準備」セクションで作成したアカウントのパスワードです。
ODS レイヤーの構築:ビジネスデータベースデータのリアルタイム取り込み
Flink CDC (Change Data Capture) と YAML データインジェストジョブを使用して、MySQL から Paimon にデータを同期します。これにより、ODS レイヤーが 1 ステップで構築されます。
YAML データインジェストジョブを作成して開始します。
Realtime Compute for Apache Flink コンソールの ページで、ods という名前の空の YAML ドラフトジョブを作成します。
次のコードをエディターにコピーします。ユーザー名やパスワードなどのパラメーターを必ず変更してください。
source: type: mysql name: MySQL Source hostname: rm-bp1e********566g.mysql.rds.aliyuncs.com port: 3306 username: ${secret_values.username} password: ${secret_values.password} tables: order_dw.\.* # 正規表現を使用して order_dw データベース内のすべてのテーブルを読み取ります。 # (オプション) 増分フェーズ中に新しく作成されたテーブルからデータを同期します。 scan.binlog.newly-added-table.enabled: true # (オプション) テーブルとフィールドのコメントを同期します。 include-comments.enabled: true # (オプション) TaskManager の OutOfMemory エラーの可能性を防ぐために、無制限のチャンクを優先的にディスパッチします。 scan.incremental.snapshot.unbounded-chunk-first.enabled: true # (オプション) 読み取りを高速化するために解析フィルターを有効にします。 scan.only.deserialize.captured.tables.changelog.enabled: true sink: type: paimon name: Paimon Sink catalog.properties.metastore: rest catalog.properties.uri: http://cn-beijing-vpc.dlf.aliyuncs.com catalog.properties.warehouse: paimoncatalog catalog.properties.token.provider: dlf pipeline: name: MySQL to Paimon Pipeline構成項目
説明
必須
例
catalog.properties.metastoreメタストアのタイプ。値は rest に固定されます。
はい
rest
catalog.properties.token.providerトークンプロバイダー。値は dlf に固定されます。
はい
dlf
catalog.properties.uriDLF Rest Catalog Server にアクセスするための URI。フォーマットは
http://[region-id]-vpc.dlf.aliyuncs.comです。リージョン ID の詳細については、「エンドポイント」をご参照ください。はい
http://cn-beijing-vpc.dlf.aliyuncs.com
catalog.properties.warehouseDLF カタログの名前。
はい
paimoncatalog
Paimon の書き込みパフォーマンスの最適化方法の詳細については、「Paimon のパフォーマンス最適化」をご参照ください。
右上隅の [デプロイ] をクリックします。
ページで、デプロイしたばかりの ods ジョブを見つけます。[アクション] 列で [開始] をクリックします。[ステートレス開始] を選択してジョブを開始します。ジョブの開始設定の詳細については、「ジョブを開始する」をご参照ください。
MySQL から Paimon に同期された 3 つのテーブルのデータを表示します。
Realtime Compute for Apache Flink コンソールの ページの [クエリスクリプト] タブで、次のコードをクエリスクリプトにコピーします。 コードスニペットを選択し、右上隅にある [実行] をクリックします。
SELECT * FROM paimoncatalog.order_dw.orders ORDER BY order_id;
DWD レイヤーの構築:トピックベースのワイドテーブル
DWD レイヤーの Paimon ワイドテーブル dwd_orders の作成
Realtime Compute for Apache Flink コンソールのページにある[クエリスクリプト]タブで、次のコードをクエリスクリプトにコピーします。コードスニペットを選択し、右上隅にある[実行]をクリックします。
CREATE TABLE paimoncatalog.order_dw.dwd_orders ( order_id BIGINT, order_user_id STRING, order_shop_id BIGINT, order_product_id BIGINT, order_product_catalog_name STRING, order_fee BIGINT, order_create_time TIMESTAMP, order_update_time TIMESTAMP, order_state INT, pay_id BIGINT, pay_platform INT COMMENT 'platform 0: phone, 1: pc', pay_create_time TIMESTAMP, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'merge-engine' = 'partial-update', -- partial-update マージエンジンを使用してワイドテーブルを生成します。 'changelog-producer' = 'lookup' -- lookup changelog プロデューサーを使用して低レイテンシーで changelog を生成します。 );Query has been executedというメッセージは、テーブルが作成されたことを示します。ODS レイヤーのテーブル orders と orders_pay からの changelog のリアルタイム消費
Realtime Compute for Apache Flink コンソールの ページで、dwd という名前の SQL ストリームジョブを作成し、次のコードを SQL エディターにコピーし、ジョブを [デプロイ] してから、ステートレスで [開始] します。
この SQL ジョブは、orders テーブルと product_catalog テーブルの間でディメンションテーブル結合を実行します。結合の結果は、orders_pay テーブルのデータとともに、dwd_orders テーブルに書き込まれます。Paimon の partial-update マージエンジンは、orders テーブルと orders_pay テーブルで同じ order_id を持つレコードのデータをワイド化するために使用されます。
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3'; SET 'table.exec.sink.upsert-materialize' = 'NONE'; SET 'execution.checkpointing.interval' = '10s'; SET 'execution.checkpointing.min-pause' = '10s'; -- Paimon は現在、単一のジョブ内で同じテーブルへの複数の INSERT 文をサポートしていません。そのため、UNION ALL を使用します。 INSERT INTO paimoncatalog.order_dw.dwd_orders SELECT o.order_id, o.user_id, o.shop_id, o.product_id, dim.catalog_name, o.buy_fee, o.create_time, o.update_time, o.state, NULL, NULL, NULL FROM paimoncatalog.order_dw.orders o LEFT JOIN paimoncatalog.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id UNION ALL SELECT order_id, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, pay_id, pay_platform, create_time FROM paimoncatalog.order_dw.orders_pay;dwd_orders ワイドテーブルのデータの表示
Realtime Compute for Apache Flink コンソールのページの[クエリスクリプト] タブで、次のコードをクエリスクリプトにコピーします。コードスニペットを選択し、右上隅にある[実行] をクリックします。
SELECT * FROM paimoncatalog.order_dw.dwd_orders ORDER BY order_id;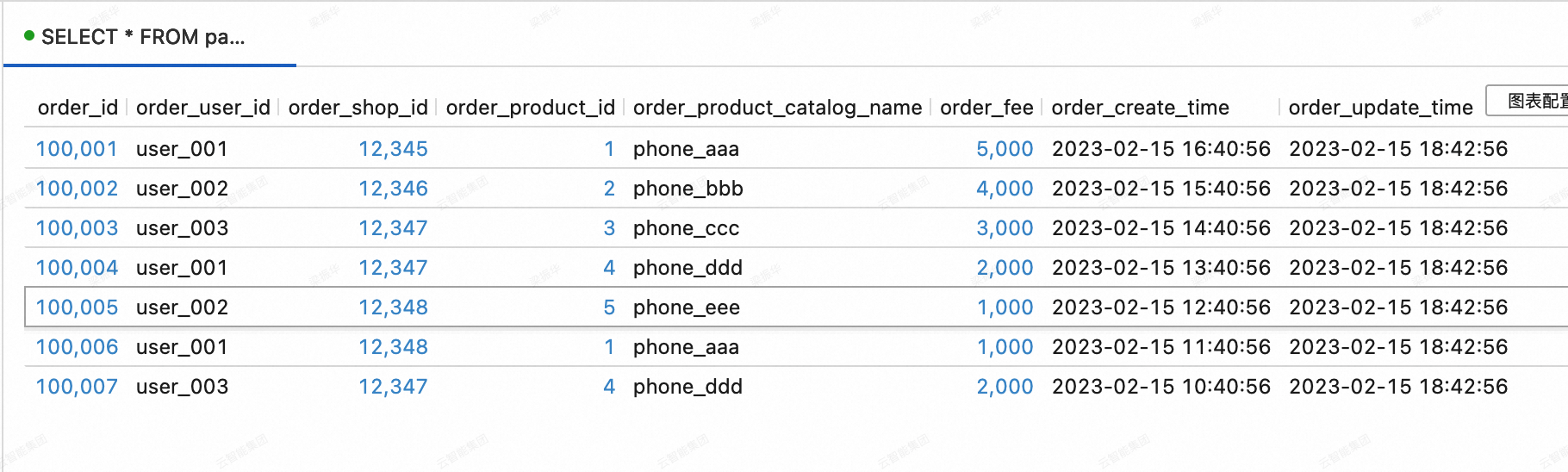
DWS レイヤーの構築:メトリック計算
DWS レイヤーの集約テーブル dws_users と dws_shops の作成
Realtime Compute for Apache Flink コンソールのページの[クエリスクリプト]タブで、次のコードをクエリスクリプトにコピーします。 コードスニペットを選択し、右上隅にある[実行]をクリックします。
-- ユーザーディメンション集約メトリックテーブル。 CREATE TABLE paimoncatalog.order_dw.dws_users ( user_id STRING, ds STRING, paid_buy_fee_sum BIGINT COMMENT '当日の支払総額', PRIMARY KEY (user_id, ds) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', -- aggregation マージエンジンを使用して集約テーブルを生成します。 'fields.paid_buy_fee_sum.aggregate-function' = 'sum' -- paid_buy_fee_sum フィールドのデータを合計して集約結果を生成します。 -- dws_users テーブルは下流でストリーミング消費されないため、changelog プロデューサーを指定する必要はありません。 ); -- 店舗ディメンション集約メトリックテーブル。 CREATE TABLE paimoncatalog.order_dw.dws_shops ( shop_id BIGINT, ds STRING, paid_buy_fee_sum BIGINT COMMENT '当日の支払総額', uv BIGINT COMMENT '当日のユニーク購入ユーザー総数', pv BIGINT COMMENT '当日のユーザーによる購入総数', PRIMARY KEY (shop_id, ds) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', -- aggregation マージエンジンを使用して集約テーブルを生成します。 'fields.paid_buy_fee_sum.aggregate-function' = 'sum', -- paid_buy_fee_sum フィールドのデータを合計して集約結果を生成します。 'fields.uv.aggregate-function' = 'sum', -- uv フィールドのデータを合計して集約結果を生成します。 'fields.pv.aggregate-function' = 'sum' -- pv フィールドのデータを合計して集約結果を生成します。 -- dws_shops テーブルは下流でストリーミング消費されないため、changelog プロデューサーを指定する必要はありません。 ); -- ユーザーと店舗の両方の視点から集約テーブルを同時に計算するために、ユーザーと店舗の複合プライマリキーを持つ中間テーブルを作成します。 CREATE TABLE paimoncatalog.order_dw.dwm_users_shops ( user_id STRING, shop_id BIGINT, ds STRING, paid_buy_fee_sum BIGINT COMMENT '当日のユーザーによる店舗での支払総額', pv BIGINT COMMENT '当日のユーザーによる店舗での購入回数', PRIMARY KEY (user_id, shop_id, ds) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', -- aggregation マージエンジンを使用して集約テーブルを生成します。 'fields.paid_buy_fee_sum.aggregate-function' = 'sum', -- paid_buy_fee_sum フィールドのデータを合計して集約結果を生成します。 'fields.pv.aggregate-function' = 'sum', -- pv フィールドのデータを合計して集約結果を生成します。 'changelog-producer' = 'lookup', -- lookup changelog プロデューサーを使用して低レイテンシーで changelog を生成します。 -- DWM レイヤーの中間テーブルは通常、上位アプリケーションから直接クエリされないため、書き込みパフォーマンスを最適化できます。 'file.format' = 'avro', -- Avro ローストアフォーマットは、より効率的な書き込みパフォーマンスを提供します。 'metadata.stats-mode' = 'none' -- 統計を破棄すると、オンライン分析処理 (OLAP) クエリのコストが増加しますが、書き込みパフォーマンスは向上します。これは継続的なストリーム処理には影響しません。 );Query has been executedという応答は、作成が成功したことを示します。DWD レイヤーの dwd_orders テーブルのデータを変更します
Realtime Compute for Apache Flink コンソールの タブで、dwm という名前の新しい SQL ストリームジョブを作成し、次のコードを SQL エディターにコピーして、ジョブを [デプロイ] し、次にステートレスで [開始] します。
この SQL ジョブは、dwd_orders テーブルから dwm_users_shops テーブルにデータを書き込みます。Paimon の事前集約マージエンジンを使用して、order_fee を自動的に合計し、ユーザーごと、店舗ごとの総消費額を計算します。また、値 1 を合計して、ユーザーごと、店舗ごとの購入回数を計算します。
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3'; SET 'table.exec.sink.upsert-materialize' = 'NONE'; SET 'execution.checkpointing.interval' = '10s'; SET 'execution.checkpointing.min-pause' = '10s'; INSERT INTO paimoncatalog.order_dw.dwm_users_shops SELECT order_user_id, order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, order_fee, 1 -- 1 つの入力レコードは 1 回の購入を表します。 FROM paimoncatalog.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL;DWM レイヤーのテーブル dwm_users_shops からの changelog のリアルタイム消費
Realtime Compute for Apache Flink コンソールのページで、dws という名前の新しい SQL ストリームジョブを作成します。 次のコードを SQL エディターにコピーし、ジョブを [デプロイ] して、ステートレスで [開始] します。
この SQL ジョブは、dwm_users_shops テーブルから dws_users テーブルと dws_shops テーブルにデータを書き込みます。Paimon の事前集約マージエンジンを使用して、dws_users テーブルで各ユーザーの総消費額 (paid_buy_fee_sum) を計算します。dws_shops テーブルでは、各店舗の総収益 (paid_buy_fee_sum)、購入ユーザー数 (1 を合計)、および総購入数 (pv) を計算します。
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3'; SET 'table.exec.sink.upsert-materialize' = 'NONE'; SET 'execution.checkpointing.interval' = '10s'; SET 'execution.checkpointing.min-pause' = '10s'; -- DWD ジョブとは異なり、ここでの各 INSERT 文は異なる Paimon テーブルに書き込むため、同じジョブ内に含めることができます。 BEGIN STATEMENT SET; INSERT INTO paimoncatalog.order_dw.dws_users SELECT user_id, ds, paid_buy_fee_sum FROM paimoncatalog.order_dw.dwm_users_shops; -- プライマリキーは店舗です。一部の人気店舗のデータ量は他の店舗よりもはるかに多い場合があります。 -- したがって、ローカルマージを使用して、Paimon に書き込む前にメモリ内でデータを事前集約します。これにより、データスキューを軽減できます。 INSERT INTO paimoncatalog.order_dw.dws_shops /*+ OPTIONS('local-merge-buffer-size' = '64mb') */ SELECT shop_id, ds, paid_buy_fee_sum, 1, -- 1 つの入力レコードは、その店舗での 1 人のユーザーによるすべての消費を表します。 pv FROM paimoncatalog.order_dw.dwm_users_shops; END;dws_users テーブルと dws_shops テーブルのデータの表示
Realtime Compute for Apache Flink コンソールのページの[クエリスクリプト]タブで、次のコードをクエリスクリプトにコピーします。コードスニペットを選択し、右上隅にある[実行]をクリックします。
--dws_users テーブルのデータを表示します。 SELECT * FROM paimoncatalog.order_dw.dws_users ORDER BY user_id;
--dws_shops テーブルのデータを表示します。 SELECT * FROM paimoncatalog.order_dw.dws_shops ORDER BY shop_id;
ビジネスデータベースの変更のキャプチャ
ストリーミングデータレイクハウスが構築された後、ビジネスデータベースからの変更をキャプチャする能力をテストできます。
MySQL の order_dw データベースに次のデータを挿入します。
INSERT INTO orders VALUES (100008, 'user_001', 12345, 3, 3000, '2023-02-15 17:40:56', '2023-02-15 18:42:56', 1), (100009, 'user_002', 12348, 4, 1000, '2023-02-15 18:40:56', '2023-02-15 19:42:56', 1), (100010, 'user_003', 12348, 2, 2000, '2023-02-15 19:40:56', '2023-02-15 20:42:56', 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 18:40:56'), (2009, 100009, 1, '2023-02-15 19:40:56'), (2010, 100010, 0, '2023-02-15 20:40:56');dws_users テーブルと dws_shops テーブルのデータを表示します。 Realtime Compute for Apache Flink コンソールのページの[クエリスクリプト]タブで、次のコードをクエリスクリプトにコピーします。 コードスニペットを選択し、右上隅の[実行]をクリックします。
dws_users テーブル
SELECT * FROM paimoncatalog.order_dw.dws_users ORDER BY user_id;
dws_shops テーブル
SELECT * FROM paimoncatalog.order_dw.dws_shops ORDER BY shop_id;
ストリーミングデータレイクハウスの使用
前のセクションでは、Paimon カタログを作成し、Flink で Paimon テーブルに書き込む方法を示しました。このセクションでは、ストリーミングデータレイクハウスを構築した後の StarRocks を使用したデータ分析の簡単なシナリオをいくつか示します。
まず、StarRocks インスタンスにログインし、oss-paimon 用のカタログを作成します。詳細については、「Paimon カタログ」をご参照ください。
CREATE EXTERNAL CATALOG paimon_catalog
PROPERTIES
(
'type' = 'paimon',
'paimon.catalog.type' = 'filesystem',
'aliyun.oss.endpoint' = 'oss-cn-beijing-internal.aliyuncs.com',
'paimon.catalog.warehouse' = 'oss://<bucket>/<object>'
);プロパティ | 必須 | 備考 |
type | はい | データソースのタイプ。値は paimon です。 |
paimon.catalog.type | はい | Paimon が使用するメタストアのタイプ。この例では、メタストアタイプとして filesystem を使用します。 |
aliyun.oss.endpoint | はい | ウェアハウスとして OSS または OSS-HDFS を使用する場合は、対応するエンドポイントを指定する必要があります。 |
paimon.catalog.warehouse | はい | フォーマットは oss://<bucket>/<object> です。このフォーマットでは:
OSS コンソールでバケットとオブジェクト名を表示できます。 |
ランキングクエリ
DWS レイヤーの集約テーブルを分析します。次の例は、StarRocks を使用して 2023 年 2 月 15 日に取引額が最も高かった上位 3 店舗をクエリする方法を示しています。
SELECT ROW_NUMBER() OVER (ORDER BY paid_buy_fee_sum DESC) AS rn, shop_id, paid_buy_fee_sum
FROM dws_shops
WHERE ds = '20230215'
ORDER BY rn LIMIT 3;
詳細クエリ
この例は、StarRocks を使用して DWD レイヤーのワイドテーブルを分析し、2023 年 2 月に特定の支払いプラットフォームを使用して支払いを行った特定の顧客の注文詳細をクエリする方法を示しています。
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' AND order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time;;
データレポート
次の例は、DWD レイヤーのワイドテーブルを分析する方法を示しています。StarRocks を使用して、2023 年 2 月の各製品カテゴリの総注文数と総注文額をクエリできます。
SELECT
order_create_time AS order_create_date,
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
order_create_date, order_product_catalog_name
ORDER BY
order_create_date, order_product_catalog_name;
参考
Flink のバッチ処理機能を使用してオフライン Paimon データレイクハウスを構築するには、「Flink バッチ処理のクイックスタート」をご参照ください。