このトピックでは、LangStudio のワークフローアプリケーション開発における AI 機能ノードについて説明します。フロー制御、大規模言語モデル (LLM)、Python 開発、エージェント、ナレッジベース検索、ドキュメント解析、音声認識、Web 検索などのプリセットコンポーネントの設定と使用方法が含まれます。
フロー制御
開始
1 つのアプリケーションフローには、開始ノードを 1 つしか含めることができません。
開始ノードは、アプリケーションフローの開始点を示し、フローの入力パラメーターを設定できます。
対話型アプリケーションフローには、会話履歴とユーザー入力の 2 つのデフォルトフィールドが含まれています。必要に応じて、アップロードされたファイルを受け入れるためのファイルタイプの入力変数など、カスタム変数を追加できます。詳細については、「ファイルタイプの入出力」をご参照ください。

アプリケーションフローを実行する際、現在のセッションの入力パラメーターをチャットパネルで設定します。
条件分岐 (Condition)
このノードは、フロー制御のための if-else ロジックを実装します。条件が true の場合、対応するブランチのみが実行されます。それ以外の場合は、else ブランチが実行されます。このノードは、ワークフローアプリケーション開発ノードと組み合わせて使用できます。
設定インターフェイス

入力
ブランチの条件を設定する際は、次の点にご注意ください。
各ブランチは実行パスを表します。最後のブランチは else ブランチで、他のどのブランチにも一致しない場合に実行されます。このブランチは編集できません。
各ブランチには複数の条件を含めることができます。ブランチ内の条件は、AND/OR 集約をサポートします。
上流ノードの出力、比較演算子(
=、≠、Empty、含まれないなど)、および一致する値を指定して、正確性と有効性を確保します。
出力
出力はありません。
使用例
Condition ノードは、下流ノードに接続するための専用接続ポートを各ブランチに提供します。ブランチの条件がトリガーされると、ワークフローはそのブランチに接続された下流ノードを実行し、他のブランチはスキップされます。その後、ワークフローアプリケーション開発コンポーネントを使用して、すべての条件分岐の下流ノードからの出力を収集できます。

変数集約
このノードは、異なるブランチからの出力結果を単一の統一された変数に統合し、どのブランチが実行されても一貫したアクセスを保証します。これは、ブランチ間で同じ目的を持つ変数を 1 つの出力変数にマッピングし、下流ノードでの冗長な定義を回避できるため、マルチブランチシナリオで特に役立ちます。
設定インターフェイス

入力
変数グループを設定する際は、次の点にご注意ください。
上流ノードは通常、ワークフローアプリケーション開発またはワークフローアプリケーション開発ノードから派生した複数の実行ブランチです。
同じグループ内の変数は、同じ型である必要があります。最初の空でない出力値が、グループの出力になります。
Condition ノードまたは意図認識ノードは 1 つのブランチしかトリガーしないため、各グループには空でない値が 1 つだけ含まれます。変数集約ノードは、この値を抽出して下流で簡単に使用できるようにします。
各 Condition または意図認識ブランチから複数の出力が必要な場合は、複数のグループを作成して、対応する値を個別に抽出します。
出力
出力変数は、設定されたグループに基づいて動的に調整されます。複数のグループがある場合、ノードは複数のキーと値のペアを出力します。キーはグループ名、値はそのグループ内の最初の空でない変数です。
使用例
使用例については、ワークフローアプリケーション開発コンポーネントをご参照ください。
ループ
ループノードは、終了条件が満たされるか、最大ループ回数に達するまで、前の反復の結果に依存する反復タスクを実行します。ループノード内で子フローを設定します。システムは、終了条件がトリガーされるか、実行制限に達するまで、ループ変数を使用して子フローのロジックを繰り返し実行します。
設定インターフェイス
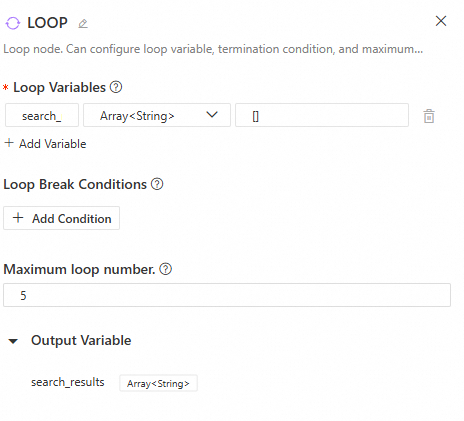
入力
ループ変数:ループの反復間でデータを渡し、ループ終了後に下流ノードで利用できるようにします。値を手動で入力するか、上流ノードの出力を選択して、複数のループ変数を設定します。
ループ終了条件:ループ変数に基づいて設定します。指定された変数がプリセット条件を満たすと、ループは終了します。
最大ループ回数:無限ループを防ぐために、ループの最大実行回数を制限します。
出力
ノードは、ループ実行後のループ変数の現在値を出力します。変数割り当てノードのみがループ変数を更新できます。これがない場合、ループノードの出力は N 回の反復後も初期入力から変更されません。
関連ノード
ループ関連のノードは、ループ内でのみ使用できます。ループ内のノードの右側にある「+」アイコンをクリックして、次の関連ノードを追加します。
ループ中断
ループを終了します。上流ノードは通常、ワークフローアプリケーション開発ノードです。
変数割り当て
ループ内の子ノードからの出力結果をループ変数に割り当てます。

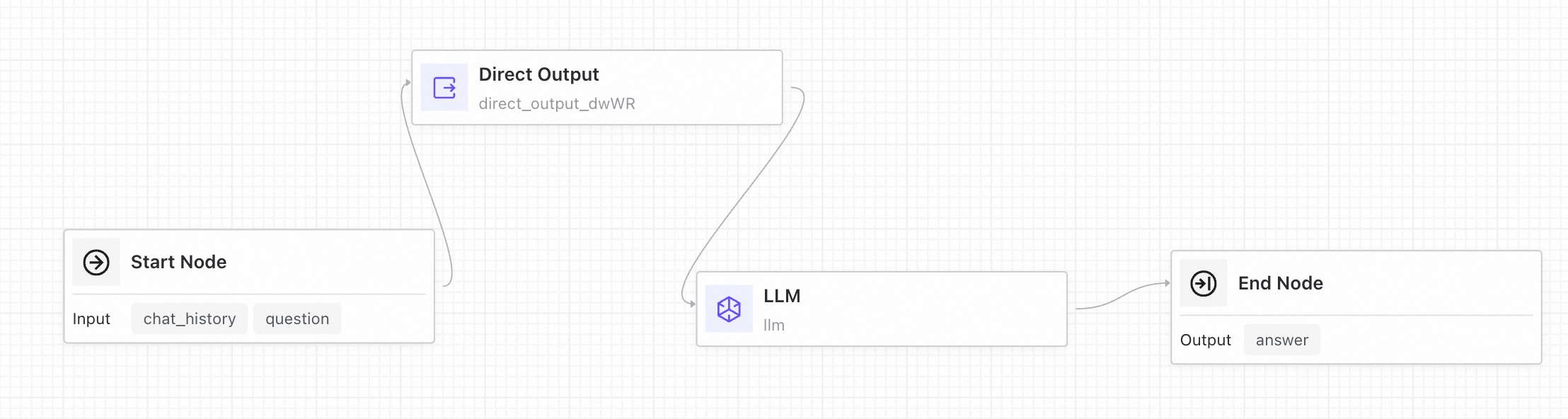
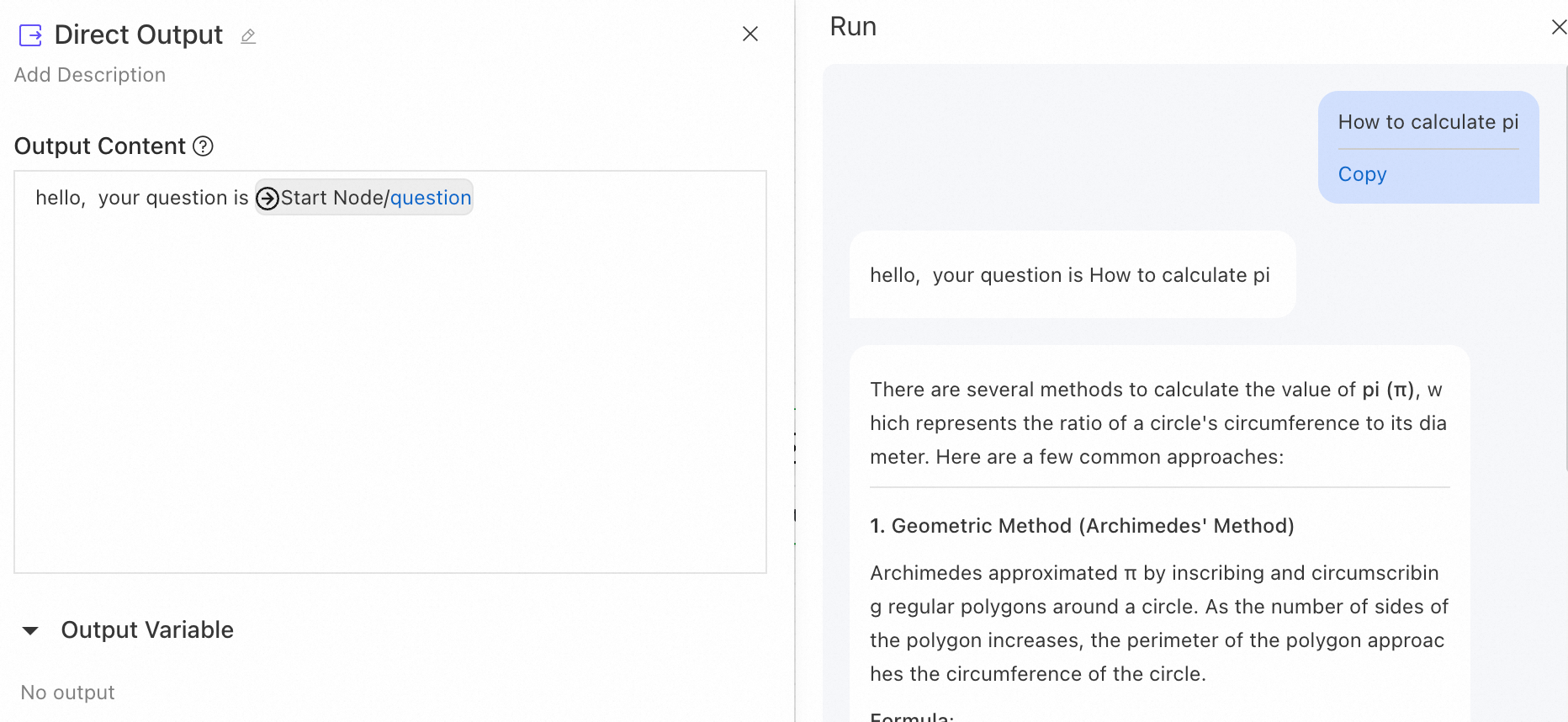
直接出力
[直接出力ノード] は、出力テンプレートを使用して返信メッセージの内容を直接設定し、{{node.variable}} 構文による上流ノード出力の参照とストリーミング出力をサポートします。
使用例:LLM ノードの前に直接出力ノードを追加して、ユーザーに即時メッセージを送信します。
バッチ処理
バッチ処理ノードは、並列バッチ処理によってリストデータを処理します。各リスト要素は同一の子フロー処理を受け、並列実行によって効率が大幅に向上します。
入力
入力リスト:処理するデータリスト。各要素は独立した処理項目となり、バッチプロセッサ内の子フローに分配されます。
出力フィールド:バッチタスクの出力結果として、バッチ子フロー内のノードから出力変数を選択します。
並列数:オプション。同時に実行するタスクの数を制御します。デフォルトは 4 です。有効範囲は 1~10 です。
出力
result:すべてのバッチタスクの出力結果のリスト。バッチノードの設定で指定された「出力フィールド」の実際の出力値を集約します。
関連ノード
バッチ開始
バッチ開始ノードはバッチ処理のエントリーポイントであり、子フロー内の後続ノードのために以下の出力変数を提供します。
item:現在処理中のデータ項目。入力リストの 1 つの要素に対応します。
index:入力リストにおける現在のデータ項目のインデックス位置 (0 から始まります)。
バッチ中断
バッチ中断ノードは、特定の条件が満たされた場合に、現在のデータ項目の処理を終了します。
注:バッチ中断は現在の反復のみを停止し、他のデータ項目の処理には影響しません。
使用例
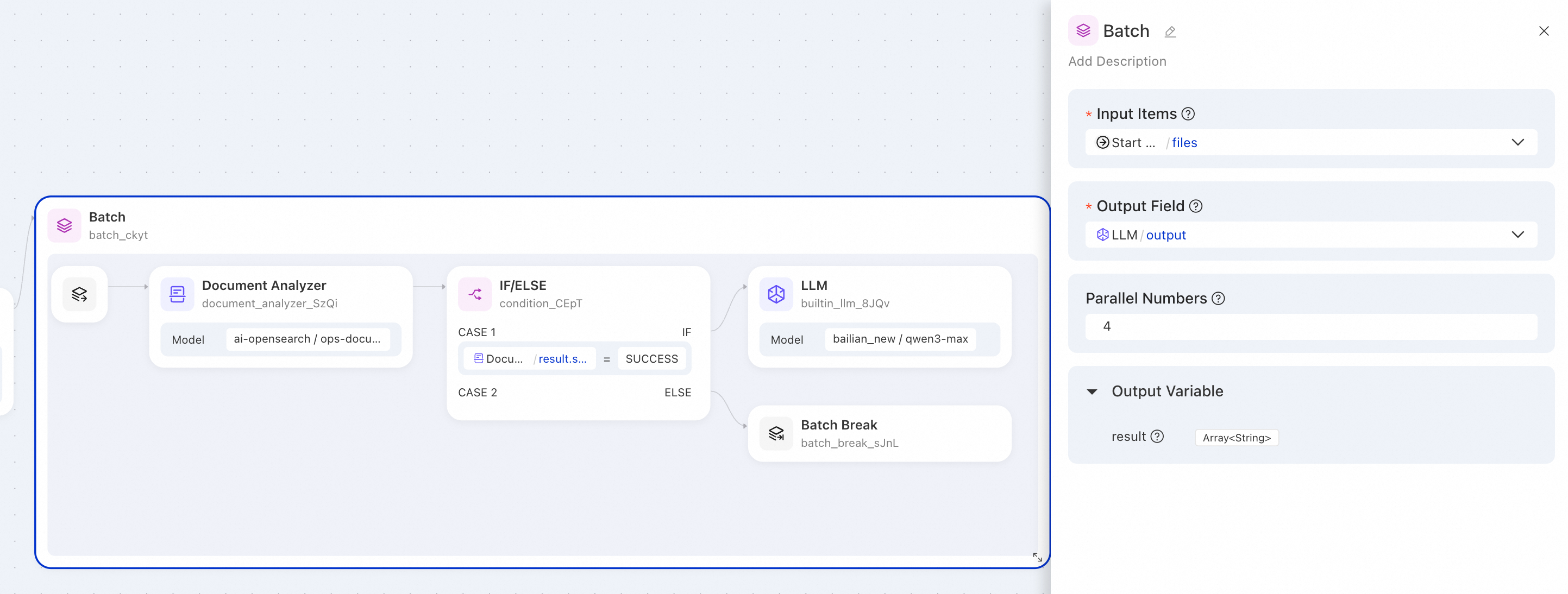
ドキュメントの一括解析とインテリジェント処理
シナリオ:ある企業が複数のドキュメントファイルを一括で解析する必要があります。正常に解析されたドキュメントは LLM によって処理され、失敗したドキュメントは自動的にスキップされます。
バッチ処理ノードの設定:
パラメーター | 値 | 説明 |
入力リスト |
| 上流ノードから出力されたファイルリストを参照 |
出力フィールド |
| LLM ノードの出力フィールドをバッチノードの出力として選択 |
並列数 |
| 4 つのファイルを同時に処理 |
出力例:
{
"result": [
"このドキュメントは XX 製品のユーザーマニュアルで、製品の機能とインストール手順を説明しています...",
"この契約は、12 ヶ月間のソフトウェアサービス調達に関するものです...",
null,
"標準的な付加価値税請求書、2026 年 1 月 15 日発行..."
]
}注:null 値は、ファイルの解析に失敗し、バッチ中断ノードによってスキップされたことを示します。
注意事項
結果の順序保証:出力リストは入力リストと同じ順序を維持します。
子フローの柔軟性:データ項目が異なると、子フロー内で異なる実行パスがトリガーされる場合があります。
null の処理:実行フローが早期に終了したり、出力を生成しなかったりした場合、バッチ出力の対応する位置は null になります。
終了
終了ノードは、アプリケーションフロー (ワークフロー) の完了を示し、フローの出力パラメーターを定義します。1 つのアプリケーションフローには、終了ノードを 1 つしか含めることができません。
出力パラメーターの設定
アプリケーションフローの出力は、最終的な実行結果として任意の上流ノードの出力を参照できます。例えば、以下の設定では、フローの answer 出力は LLM ノードの出力を、search_results は検索ノードの出力を使用します。
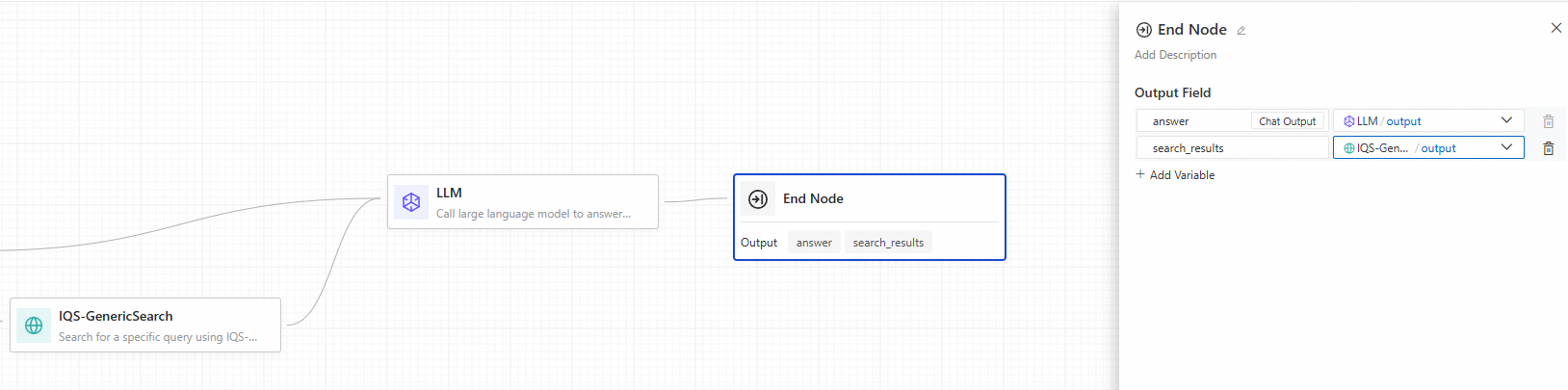 説明
説明対話型アプリケーションフローには、対話応答用のデフォルトの Chat 出力フィールドが含まれています。
アプリケーションフローには、開始ノードと終了ノードの両方を含める必要があります。この 2 つのノード間に接続されているノードのみが実行され、接続されていないノードは無視されます。
AI 機能
大規模言語モデル (LLM)
LLM ノードは、アプリケーションフローのコアコンポーネントであり、自然言語タスクのために大規模言語モデルを呼び出すように特別に設計されています。このノードは、質問に答えたり、複雑な自然言語入力を処理したりするためのインテリジェントなテキスト応答を提供します。また、モデルパラメーターの調整、会話履歴の管理、プロンプトのカスタマイズなど、応答の品質と精度を最適化するための柔軟な設定オプションも提供します。
利用シーン
テキスト生成:トピックやキーワードに基づいてコンテンツを生成します。
コンテンツ分類:メールの種類 (問い合わせ/苦情/迷惑メール) を自動的に分類します。
テキスト変換:テキストを指定された言語に翻訳します。
RAG:検索されたナレッジを使用してユーザーの質問に回答します。
設定インターフェイス

入力
モデル設定:ModelGallery からデプロイされたモデル、カスタムデプロイメント、または Dashscope や DeepSeek などのプロバイダーを使用します。最良の結果を得るには、高性能なモデルを選択してください。以下のパラメーターを設定します。
Temperature:出力のランダム性を制御する 0 から 1 の間の値。値が低い (0 に近い) ほど決定論的な結果が生成され、値が高い (1 に近い) ほど多様な出力が得られます。
Top P:累積確率がしきい値 P を超えないトークンを選択することで、多様性を制御します。
Top K:トークンの選択を最も確率の高い上位 K 個のトークンに制限し、ランダム性を減らして、確率の高い語彙に出力を集中させます。
Presence penalty:すでに生成されたコンテンツにペナルティを課すことで、エンティティや情報の繰り返しを減らします。値が高いほど、繰り返しの可能性が低くなります。
Frequency penalty:頻繁に出現する単語やフレーズの生成確率を減らします。値が高いほど、語彙の多様性が増します。
Max tokens:1 回の生成あたりの最大出力長を設定します。値が低いとテキストが切り捨てられる可能性があり、値が高いとより長い出力が可能になります。
Seed:指定すると、モデルは決定論的サンプリングを試み、同じシードとパラメーターで同じ結果が生成されるようにします。完全な決定論は保証されません。system_fingerprint レスポンスパラメーターを使用して、潜在的な変更を監視してください (プロキシアクセスが必要な場合があります)。
停止シーケンス:検出されるとテキスト生成を停止する最大 4 つのシーケンス。返されるテキストには、停止シーケンス自体は含まれません。
会話履歴:有効にすると、アプリケーションフローのチャット履歴が自動的にプロンプトに挿入されます。
入力変数:変数は、先行するすべてのノードの出力を参照できます。
プロンプト:Jinja2 テンプレートを使用して、SYSTEM/USER/ASSISTANT プロンプトのコンテンツをカスタマイズします。二重中括弧
{{}}を使用して入力変数を参照します。
出力
ノードはデフォルトで String データを返しますが、JSON 出力用に設定することもできます。JSON の場合は、カスタム出力変数を定義します。LLM は変数名に基づいて出力を生成します。
使用例
意図認識
主にフロー制御に使用され、このノードは大規模言語モデルを使用してユーザー入力の意図を分析し、認識結果に基づいて対応するブランチを実行します。マルチ意図設定と会話履歴をサポートします。
設定インターフェイス

入力
ユーザー入力:意図認識のためのユーザー入力を選択します。
マルチ意図設定:必要に応じて意図を定義し、意味的な重複がないように明確な説明を確保します。最後の意図はデフォルトで「その他」となり、一致しない入力を表し、編集はできません。
モデル設定:意図認識のための LLM を設定します。最良の結果を得るには、qwen-max などの高性能なモデルを選択してください。
会話履歴:有効にすると、LLM の推論中にチャット履歴が自動的にプロンプトに挿入されます。
追加プロンプト:システムプロンプトにコンテンツを追加して、意図認識の精度を向上させます。
出力
出力はありません。
使用例
意図認識ノードを下流ノードに接続すると、各意図ブランチに対応する接続ポートができます。意図が認識されると、そのブランチは接続された下流ノードを実行し、他のブランチはスキップされます。ワークフローアプリケーション開発コンポーネントを使用して、すべてのブランチの実行結果 (下流ノードの出力) を収集できます。

エージェント
LangStudio のエージェントノードは、自律エージェント開発を可能にします。推論戦略とツール使用機能をサポートし、異なる推論アプローチ (現在は FunctionCalling と ReAct) を統合して、実行時に Model Context Protocol (MCP) ツールを動的に呼び出し、マルチステップの自律推論を実現します。
ノードパラメーターの設定
エージェント戦略:目的の推論戦略 (FunctionCalling または ReAct) を選択します。
FunctionCalling
OpenAI Chat API の構造化された
tool call定義 (JSON 形式) を実装し、LLM と外部ツールとの対話を実現します。LLM は自動的に意図を識別し、適切なツールを選択し、自然言語の命令からパラメーターを抽出します。その後、システムがツールを呼び出し、結果を返して推論を続行します。利用シーンと利点:
高い互換性を持つ構造化呼び出し:構造化データを使用してツール名とパラメーターを指定するため、ツール呼び出しをサポートするすべてのモデルと互換性があります。
安定したパフォーマンス:天気予報の確認、情報検索、データクエリなど、明確で段階的なタスクに最適です。
ReAct
ReAct (Reasoning + Acting) は、より柔軟な推論アプローチであり、プロンプトを通じてモデルが明示的に思考と行動のステップを生成するように誘導し、クローズドループのマルチステップ推論とツール呼び出しプロセスを作成します。通常、自然言語を使用して呼び出しを記述し (例:「Action=xxx, Action Input=xxx」)、バックエンドツールをトリガーし、結果を推論チェーンにフィードバックします。API レベルの
tool_callsを必要としないため、汎用モデルやフレームワークに適しています。利用シーンと利点:
より強力な推論:各ステップで明示的な推論ロジックを用いて、段階的な思考をガイドします。
透明な戦略:デバッグや解釈可能なエージェントアプリケーションに最適です。
Tool Calling の要件なし:構造化出力をサポートしないモデルでも動作します。
モデル設定:FunctionCalling はネイティブの Tool Calling サポートが必要です。ReAct にはそのような制限はありません。推論能力の高いモデルを選択してください。
会話履歴:有効にすると、会話履歴を自動的にプロンプトに挿入することで、コンテキストメモリを提供します。これにより、エージェントは以前の対話を理解し参照することができ、一貫性のあるコンテキストを意識した応答を提供できます。例えば、会話履歴を有効にすると、エージェントは「彼」、「ここ」、「あの日」などの代名詞を、ユーザーが完全なコンテキストを繰り返す必要なく理解します。
タスク計画:有効にすると、組み込みの write_todos ツールがエージェントの利用可能なツールに自動的に追加されます。複雑なユーザーのクエリに対して、エージェントは自動的に write_todos を呼び出してタスクを段階的に計画・実行し、新しい情報で計画を動的に更新します。
MCP ツール:MCP 接続またはカスタムフォームを介して設定します。SSE およびストリーミング可能な HTTP を使用する MCP サーバーをサポートします。MCP サービスは通常、複数のツールを提供します。
ツールスコープオプションを使用して、LLM に表示されるツールを制御します。
機密性の高い操作を行うツール (例:ユーザーデータの変更) は、「承認ツール」機能で保護します。ワークフローがこれらのツールに到達すると、ノードは自動的に一時停止し、続行する前に手動確認を待ちます。
ツール:カスタム (OpenAPI) ツールや Python ツールなど、エージェントが利用できる非 MCP ツールを設定します。選択したツールについては、説明や出力パラメーターを編集し (例:モデルからパラメーターを隠してデフォルト値を設定)、セキュリティのために「承認が必要」を有効にします。
プロンプト設定
入力変数:プロンプトで上流ノードの変数を参照するには、ここに対応する入力変数を定義し、その値を上流の参照に設定します。その後、Jinja2 構文
{{}}をプロンプトで使用して動的データを渡します。システムプロンプト:エージェントのタスク目標とコンテキストを指定して、期待される応答をガイドします。ReAct ではオプションです。
ユーザープロンプト:モデルの応答の基礎として、ユーザーの入力やクエリを受け取ります。
ループ回数:エージェントの最大実行ループ数を設定します (1~99)。エージェントは、以下のいずれかの条件が満たされるまで繰り返します。
LLM が完全な応答のために十分な情報を収集したと判断した場合
最大ループ回数に達した場合
応答の完全性と実行効率のバランスを取るために、適切なループ回数を設定してください。タスク計画が有効な場合は、計画が完全に実行されるようにデフォルトの最大値を使用してください。
出力変数:
intermediate_steps:エージェントの中間推論プロセス (String)
text:エージェントの最終出力 (String)
トレース/ログの表示
アプリケーションフローページの右上隅にある [実行] をクリックした後、ダイアログボックスの実行結果の下にあるトレースまたはログを表示します。
中間出力の表示:エージェントノードの右上隅にある実行ステータスアイコンをクリックし、ドロワーの [出力] の下にある intermediate_steps を見つけて、エージェントの推論プロセスを確認します。
トレースの表示:現在の実行のトレース情報を検査します。これには、モデルの入力、出力 (ツール呼び出しとパラメーターを含む)、トークンの使用状況、およびタイミングが含まれます。
ログの表示:アプリケーションフローが失敗した場合、操作ログを表示して詳細な実行情報を確認します。
また、右上隅の [その他] > [実行履歴] をクリックし、特定の実行レコードを選択して、トレースまたはログを表示することもできます。
ドキュメント解析
組み込みのインテリジェントドキュメント解析と、AI 検索オープンプラットフォームのドキュメント解析サービスをサポートします。
組み込みパーサー:PDF、DOCX、PPTX、TXT、HTML、CSV、XLSX、XLS、JSONL、MD の複数の形式から構造化コンテンツとメタデータを抽出します。
AI 検索オープンプラットフォーム:高精度な構造化解析を提供し、論理階層 (タイトル、段落) とコンテンツ (テキスト、表、画像) を抽出し、抽出品質を向上させます。事前に設定された AI 検索オープンプラットフォームのモデルサービス接続が必要です。サポートされている形式:PDF、DOCX、PPTX、TXT、HTML。
このツールは、下流の RAG、要約、Q&A シナリオをサポートします。設定インターフェイス: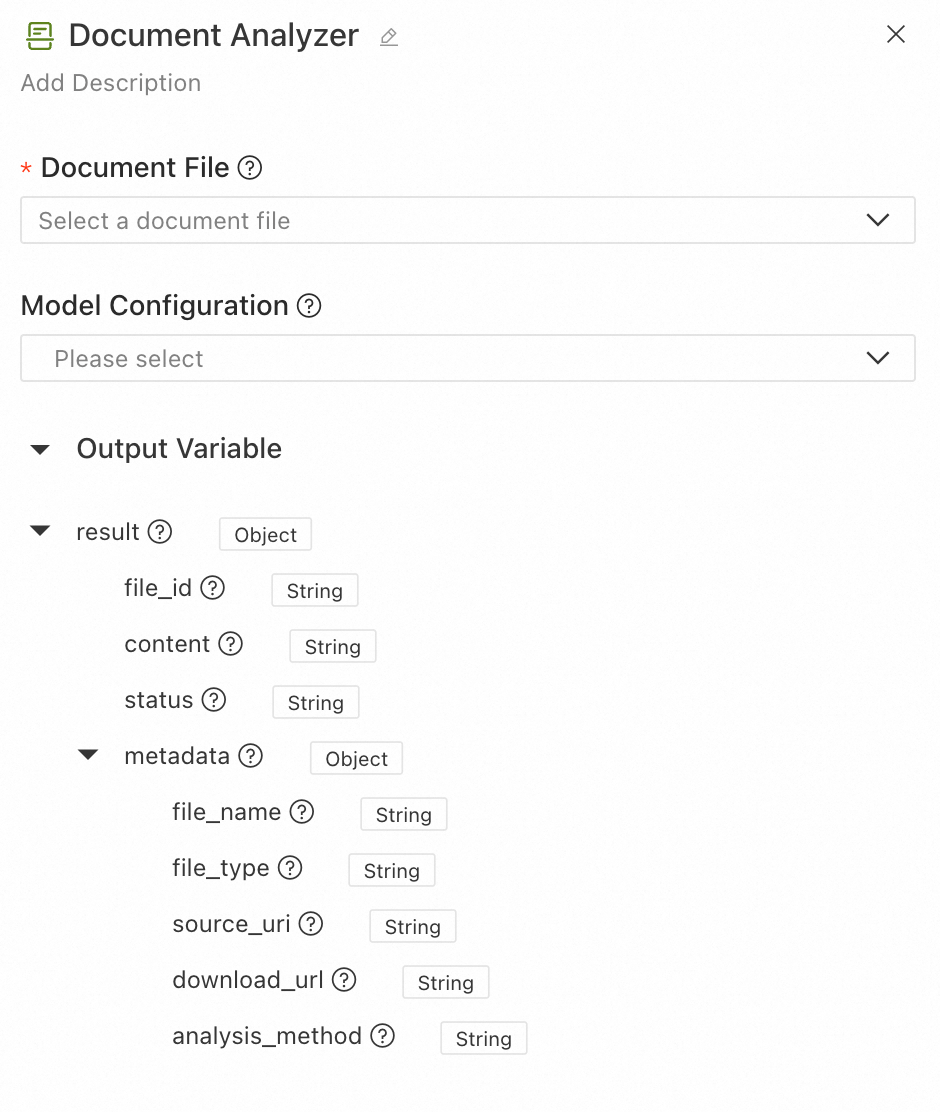
ドキュメントファイル:インテリジェント解析のために単一のドキュメントを入力します。上流からファイルタイプのフィールドを選択します。
モデル設定:(オプション) LangStudio で事前に設定された AI 検索オープンプラットフォームのモデルサービス接続を選択します。設定がない場合、システムは組み込みの基本パーサーを使用します。
出力:
file_id:入力ファイルの一意の識別子
content:階層情報 (タイトル、段落) を含む構造化テキストコンテンツ
status:解析ステータス (SUCCESS または FAIL)
metadata:ドキュメントのメタデータと解析の詳細
file_name:ファイル名
file_type:ファイルタイプ
source_uri:元のファイル URI
download_url:ダウンロード可能なファイル URL
analysis_method:使用された解析メソッド。「opensearch」は AI 検索オープンプラットフォームの構造化解析を示し、「builtin」は組み込みの基本解析を示します。
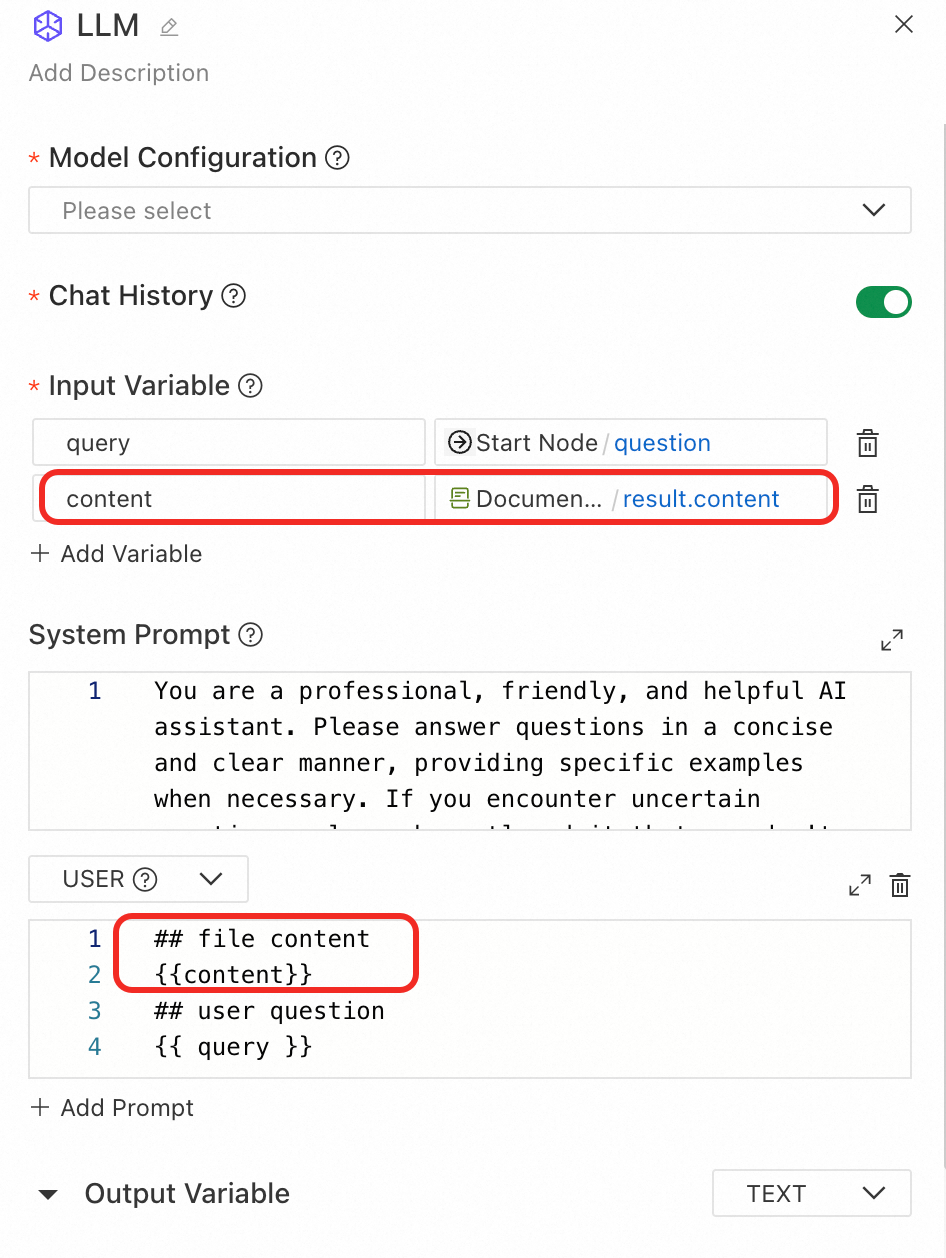
下流での使用例:必要に応じて、下流ノードでドキュメント解析結果を参照します。解析されたコンテンツを LLM ノードで使用するには、以下のようにユーザープロンプトに含めます。
音声認識
音声認識ツールを使用して、音声または動画ファイルをテキストに変換します。複数の音声フォーマットと言語をサポートします。
入力
モデル設定:音声認識モデルを設定します。現在、Alibaba Cloud Model Studio の音声認識サービスをサポートしています。最適な認識品質と多言語サポートのために
paraformer-v2を使用してください。音声/動画ファイル:認識するファイルを選択します。サポートされている形式については、「ファイルタイプの入出力」をご参照ください。
認識言語:音声認識の言語を指定します。中国語、英語、日本語、広東語、韓国語、ドイツ語、フランス語、ロシア語、または自動検出をサポートします。注:
paraformer-v2モデルのみがこの機能をサポートしており、他のモデルはデフォルトで自動検出になります。
出力
file_id:入力ファイルの一意の識別子。
status:認識ステータス (
SUCCESSまたはFAIL)。content:書き起こされたテキストコンテンツ。
segments:タイムスタンプとテキストの詳細を含む文セグメントのリスト。
metadata:以下を含むファイルメタデータ:
file_name:ファイル名
file_type:ファイルタイプ
source_uri:ファイル URI
download_url:ダウンロード URL
データ検索
ナレッジベース検索 (インデックス検索)
ナレッジベースからユーザーの質問に関連するテキストコンテンツを取得し、下流の LLM ノードでコンテキストとして使用します。
設定インターフェイス

入力
ナレッジベースのインデックス名:LangStudio に登録されているナレッジベースを選択します。詳細については、「ナレッジベース管理」をご参照ください。
検索キーワード:ナレッジベース検索のために、上流ノードの出力パラメーター (String 形式) を参照します。
Top K:ナレッジベースのインデックスから返される最も関連性の高い結果の数。
出力
検索出力変数 result (型:List[Dict]) には、以下のキーが含まれます。
キー
説明
content
取得されたドキュメントチャンクのコンテンツ — クエリに関連するナレッジベースからのテキスト断片。
score
ドキュメントチャンクとクエリの間の類似度スコア。スコアが高いほど、関連性が高いことを示します。
top_k の最もスコアの高いレコードを示す出力例:
[ { "score": 0.8057173490524292, "content": "パンデミック関連の不確実性により、XX 銀行は経済動向と中国本土の状況に基づき、貸倒引当金および非信用資産減損引当金を積極的に積み増し、不良資産の処分を加速させ、引当金カバー率を強化しました。2020年には、純利益 289 億 2800 万元を達成し、前年比 2.6% 増となり、収益性は徐々に改善しています。(百万元) 2020 2019 変化率 (%)\n営業成績と収益性\n営業収益 153,542 137,958 11.3\n減損前営業利益 107,327 95,816 12.0\n純利益 28,928 28,195 2.6\n経費率(1)(%) 29.11 29.61 0.50 パーセントポイント低下\n平均総資産利益率 (%) 0.69 0.77 0.08 パーセントポイント低下\n加重平均 ROE (%) 9.58 11.30 1.72 パーセントポイント低下\n純金利マージン(2)(%) 2.53 2.62 0.09 パーセントポイント低下\n注:(1) 経費率 = 営業経費および管理費 / 営業収益。", "id": "49f04c4cb1d48cbad130647bd0d75f***1cf07c4aeb7a5d9a1f3bda950a6b86e", "metadata": { "page_label": "40", "file_name": "2021-02-04_China XX Insurance Group Co., Ltd._XX_China XX_2020_Annual Report.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__China_XX_Insurance_Group_Co.__Ltd.__601318__China_XX__2020__Annual_Report.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } }, { "score": 0.7708036303520203, "content": "72 億元、前年比 5.2% 増。\n2020\n(百万元) 生命・健康保険 損害保険 銀行 信託 証券 その他 資産運用 テクノロジー その他事業・連結消去 グループ合計\n株主帰属純利益 95,018 16,083 16,766 2,476 2,959 5,737 7,936 (3,876) 143,099\n少数株主持分 1,054 76 12,162 3 143 974 1,567 281 16,260\n純利益 (A) 96,072 16,159 28,928 2,479 3,102 6,711 9,503 (3,595) 159,359\n調整項目:\n 短期投資変動(1)(B) 10,308 – – – – – – – 10,308\n 割引率の影響 (C) (7,902) – – – – – – – (7,902)\n 経営陣がコア業務から除外した一時項目 (D) – – – – – – 1,282 – 1,282\nコア利益 (E=A-B-C-D) 93,666 16,159 28,928 2,479 3,102 6,711 8,221 (3,595) 155,670\n株主帰属コア利益 92,672 16,", "id": "8066c16048bd722d030a85ee8b1***36d5f31624b28f1c0c15943855c5ae5c9f", "metadata": { "page_label": "19", "file_name": "2021-02-04_China XX Insurance Group Co., Ltd._XXX_China XX_2020_Annual Report.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__China_XX_Insurance_Group_Co.__Ltd.__601318__China_XX__2020__Annual_Report.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } } ]使用例
Alibaba Cloud IQS - Web 検索 (IQS-GenericSearch)
Alibaba Cloud Information Query Service を使用して、時間範囲フィルタリング付きの標準検索を実行します。
設定インターフェイス

入力
検索キーワード:Web 検索のキーワード。100 文字を超えるキーワードは 100 文字に切り捨てられます。キーワードが 2 文字未満の場合はエラーが発生します。
時間範囲:データ時間範囲を選択します — NoLimit、OneDay、OneWeek、OneMonth、または OneYear。
IQS 接続:起動時に承認されたロールが設定されていない場合、事前に設定された IQS 接続を選択できます。IQS 接続の設定方法については、「サービス接続設定 - カスタム接続」をご参照ください。キーを
api_keyに設定し、対応する値を入力します。この値は Information Query Service - 認証情報管理 から取得できます。IQS 接続の詳細については、「LangStudio と Alibaba Cloud Information Query Service を使用した DeepSeek Web 検索アプリケーションフローの構築」をご参照ください。
出力
output:Web 検索出力変数 (型:List[Dict]) には、以下のキーが含まれます。
キー
説明
title
検索結果のタイトル — 通常、コンテンツを要約した Web ページまたはドキュメントのタイトル。
link
完全なコンテンツにアクセスするための検索結果の URL。
summary
検索結果の要約 — コア情報の簡単な概要。
content
詳細情報を含む完全な検索結果のコンテンツ。
markdown_text
Markdown 形式の検索コンテンツ (空の場合があります)。
score
関連性や品質を示す検索結果のスコア。スコアが高いほど、検索意図との一致度が高いことを意味します。
publish_time
情報の適時性を示すコンテンツの公開時間 (タイムスタンプまたは日付)。
host_logo
情報源を特定するためのソース Web サイトのロゴまたはアイコン (画像 URL)。
hostname
情報源を示すソース Web サイトのホスト名またはドメイン。
site_label
テーマの背景を示すソース Web サイトのラベルまたはカテゴリ。
scene_items:検索結果を強化する補助情報。このパラメーターは通常、汎用検索では空です。時間、天気、カレンダーなど、特定のシナリオで汎用検索が不十分な場合、システムは scene_items を返して、正確でコンテキストを意識した情報を提供します。
使用例
LangStudio と Alibaba Cloud Information Query Service を使用した DeepSeek Web 検索アプリケーションフローの構築
SerpAPI - Web 検索 (SerpAPI-GenericSearch)
SerpApi を使用して Web 検索を実行します。複数の検索エンジン (Bing、Google、Baidu、Yahoo、およびカスタム)、設定可能な場所、および結果数をサポートします。
設定インターフェイス

入力
SerpApi 接続:LangStudio で事前に設定された SerpApi 接続を選択します。詳細については、「SerpApi 接続の作成」をご参照ください。
検索キーワード:上流ノードの出力パラメーター (String 形式) を参照します。
検索エンジン:bing、google、baidu、yahoo、およびカスタム入力をサポートします。
場所:検索場所。最良の結果を得るには、都市を指定します (例:
Shanghai, China)。結果数:返す検索結果の数。
出力
Web 検索出力変数 output (型:List[Dict]) には、以下のキーが含まれます。
キー
説明
title
検索結果のタイトル — 通常、コンテンツを要約した Web ページまたはドキュメントのタイトル。
link
完全なコンテンツにアクセスするための検索結果の URL。
summary
検索結果の要約 — コア情報の簡単な概要。
使用例
HTTP リクエスト
HTTP リクエストツールは、複数の HTTP メソッド、認証タイプ、およびリクエストボディ形式をサポートし、外部 API 統合を簡素化します。
入力
リクエストメソッド:HTTP メソッド — GET、POST、PUT、PATCH、DELETE、HEAD、OPTIONS。
URL:ターゲットリクエストアドレス。
リクエストヘッダー:カスタム HTTP ヘッダー。キーと値のペアとして、1 行に 1 つのヘッダーを入力します。
リクエストパラメーター:クエリ文字列パラメーター。キーと値のペアとして、1 行に 1 つのパラメーターを入力します。
認証:デフォルトで無効。有効にすると、標準認証 (Bearer または Basic) を選択します。
Bearer:Bearer トークン認証を使用します。
Bearerプレフィックスは含めないでください。Basic:ユーザー名とパスワードを使用した基本認証を使用します。システムは自動的に認証情報を Base64 に変換します。
カスタム認証の場合は、リクエストヘッダーを手動で設定します。
リクエストボディ:以下の形式をサポートします。
none:リクエストボディなし
JSON:JSON データを送信
form-data:multipart/form-data を送信 (ファイルアップロードをサポート)
x-www-form-urlencoded:URL エンコードされたフォームデータを送信
raw-text:プレーンテキストを送信
binary:バイナリファイルデータを送信 (ファイルアップロードをサポート)
SSL 検証:デフォルトで有効。サーバーの SSL 証明書を検証するかどうかを選択します。本番環境では有効にしておいてください。
タイムアウト:リクエストタイムアウト (1~600 秒)。デフォルトは 10 秒です。
リトライ設定:デフォルトで無効。失敗時にリトライするかどうかを選択します。
最大リトライ回数:リトライ回数 (0~10)
リトライ間隔:リトライ間の時間 (100~10000 ミリ秒)
出力
body:応答のテキストコンテンツ。応答がファイルの場合は空の文字列。
status_code:HTTP 応答ステータスコード (例:200、404、500)。
headers:キーと値のペアとしての HTTP 応答ヘッダー。
file:ファイルオブジェクト (応答がファイルの場合)。
データ処理
Python 開発
アプリケーションフローは、複雑なデータ処理ロジックのためのカスタム Python コードノードをサポートし、ストリーミング入出力をサポートします。設定インターフェイス:

Python コードを記述するだけで、システムが自動的に入力と出力を解析します。次の点にご注意ください。
エントリー関数は、ノードとしてロードするために
@toolでデコレートする必要があります。説明Python ノードのストリーミング入力を有効にするには、
@tool(properties={"streaming_pass_through": True})を設定します。そうしないと、LLM またはエージェントからの入力は、ストリームではなく完全な出力テキストになります。サポートされている入出力タイプ:int、float、bool、str、dict、TypedDict、dataclass (出力のみ)、list、File。
エントリー関数のパラメーターは、ノード入力として動的に解析されます。出力は、他のノードから参照できるように出力辞書に配置されます。
重要自動入出力解析はランタイムに依存します。実行中のランタイムがない場合、ノードの入出力情報を設定することはできません。
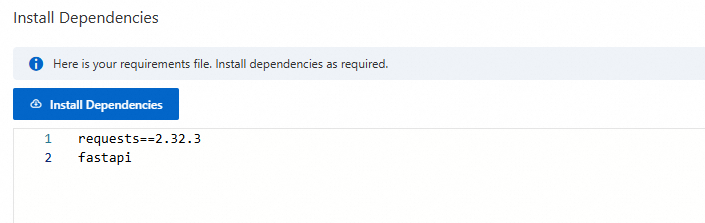
依存関係をインストールするには、キャンバスエリアの右上にある [依存関係のインストール] をクリックし、パッケージ名を入力します。requirements.txt ファイルはアプリケーションフローと共に保存され、ランタイムの起動時またはサービスデプロイ時に環境にインストールされます。
使用例 1:次のコードを入力して、入力と出力をマッピングします。
from langstudio.core import tool
from dataclasses import dataclass
@dataclass
class Result:
output1: str
output2: int
@tool
def invoke(foo: str, bar: int) -> Result:
return Result(
output1="hello" + foo,
output2=bar + 10
)

使用例 2:ストリーミング入出力。Python ノードを使用して、LLM/エージェント出力から思考プロセスのテキストストリームをトリミングし、<think>\n\n</think> セクションを破棄して、クリーンな最終結果ストリームを生成します。サンプルコード:
import re
from typing import Iterator
from langstudio.core import tool
@tool(properties={"streaming_pass_through": True})
def strip_think(
stream: Iterator[str],
) -> Iterator[str]: # 入力:ストリーミング文字列イテレータ、出力:フィルタリングされたストリーミング文字列イテレータ
# <think>\n...\n</think> 構造に一致させ、閉じタグの後のテキストをキャプチャ
pattern = re.compile(r"<think>\n[\s\S]*\n</think>(.*)")
in_thinking = True # 現在 <think> ブロック内にいるかどうかを示すフラグ
think_buf = "" # 未処理のコンテンツを保存するためのバッファー
for chunk in stream:
if in_thinking:
think_buf += chunk
m = pattern.search(think_buf) # バッファーに完全な思考ブロックが含まれているか確認
if m:
in_thinking = False
result_part = m.groups()[0]
if result_part:
yield result_part # 結果テキストが存在すればすぐに出力
else:
yield chunk # 思考ブロックを抜けた後、後続のすべてのチャンクを直接出力
テンプレート変換
テンプレート変換ツールは、Jinja2 テンプレート構文を使用して、柔軟なテキストフォーマットとデータ変換を可能にします。
入力
変換モードはJinja2 モードとノード参照モードをサポートします。
Jinja2 モード:完全な Jinja2 構文を使用して、カスタム出力フォーマットを作成します。複雑な構造化出力、条件付きロジック、ループレンダリングに適しています。
テンプレート変数:テンプレートで使用される変数を定義します。
重要Python の組み込みメソッド名 (例:
items、keys、values) は使用しないでください。item_listやproduct_listのような説明的な名前を使用してください。テンプレートコンテンツ:変数置換
{{ variable }}、ループ{% for %}、条件{% if %}、フィルター{{ value | filter }}をサポートする Jinja2 テンプレート文字列。重要テンプレートで参照されるすべての変数は、変数リストで定義する必要があります。そうしないと、エラーが発生します。
ノード参照モード:上流ノードの出力を直接参照し、自動的に文字列に連結します。単純なテキストの組み合わせに適しています。
テンプレートコンテンツ:上流ノードの出力フィールドを選択します。システムはそれらを順番に自動的に連結します。
出力
output:レンダリングされたテンプレートのテキスト結果。注:入出力のテンプレートコンテンツはどちらも 100,000 文字に制限されており、超過したコンテンツは切り捨てられます。
使用例
例 1:注文確認メールの生成
変数の設定:
変数名 | 変数値 |
customer_name |
|
order_id |
|
products |
|
total |
|
テンプレートコンテンツ:
田中 太郎様:
ご注文 {{ order_id }} が確定しました。詳細は以下の通りです。
{% for product in products %}
- {{ product.name }}: ¥{{ product.price }}
{% endfor %}
合計: ¥{{ total }}
ご購入いただきありがとうございます!出力結果:
Zhang San 様
ご注文 ORD-2025-001 が確定しました。ご注文内容:
- ノートパソコン: ¥8999
- ワイヤレスマウス: ¥199
合計: ¥9198
ご購入いただき、誠にありがとうございます。例 2:ナレッジベース検索結果のフォーマット
変数の設定:
変数名 | 変数値 |
chunks |
|
テンプレートコンテンツ:
{% for chunk in chunks %}
### 関連性: {{ "%.2f" % chunk.score }}
#### {{ chunk.title }}
{{ chunk.content }}
---
{% endfor %}出力結果:
### 関連性: 0.95
#### 製品紹介
これは詳細な製品説明です...
---リスト操作
リスト操作ツールは、リストデータに対して柔軟なフィルタリングとソートを実行し、詳細な処理と選択を可能にします。
入力
リスト入力:処理するリストデータ。任意のサブタイプ (文字列、数値、ブール値、ファイルオブジェクト、辞書) をサポートします。
操作:連続した操作のチェーン。フィルターとソートの操作タイプをサポートします。
フィルター操作:フィルタリング方法はリストのタイプによって異なります。注:すべてのフィルターは大文字と小文字を区別します。
フィルターキー
説明
適用範囲
インデックス
リスト内の要素の位置でフィルタリング
すべてのリストタイプ
要素の値
要素の値でフィルタリング
すべてのリストタイプ
カスタム属性
カスタム属性でフィルタリング
辞書タイプのリストのみ
ファイル属性
ファイル属性でフィルタリング
ファイルタイプのリストのみ
ソート操作:ソート方法はリストのタイプによって異なります。
ソートキー
説明
適用範囲
要素の値
要素の値でソート
文字列、数値、またはブール値のリストのみ
カスタム属性
カスタム属性でソート
辞書タイプのリストのみ
ファイル属性
ファイル属性でソート
ファイルタイプのリストのみ (フィルター操作と同じ属性)
出力
result:処理されたリストの結果。
first_item:結果リストの最初の要素 (空の場合は None)。
last_item:結果リストの最後の要素 (空の場合は None)。
使用例
例 1:ファイル分類 - フィルタリングとサイズによるソートで上位 3 つの画像ファイルを取得
シナリオ:ユーザーが混合ファイルリストをアップロードします。画像ファイルをフィルタリングし、ファイル名の長さでソートし、画像認識のために上位 3 つを保持します。
操作の設定:
操作 1 - フィルター (ファイルカテゴリによる):
フィルターキー:item.category
フィルター演算子:equals
フィルター値:image
操作 2 - ソート (ファイル名の長さによる):
ソートキー:item.file_name
ソート方向:asc
操作 3 - フィルター (上位 3 つを保持):
フィルターキー:index
フィルター演算子:less than
フィルター値:3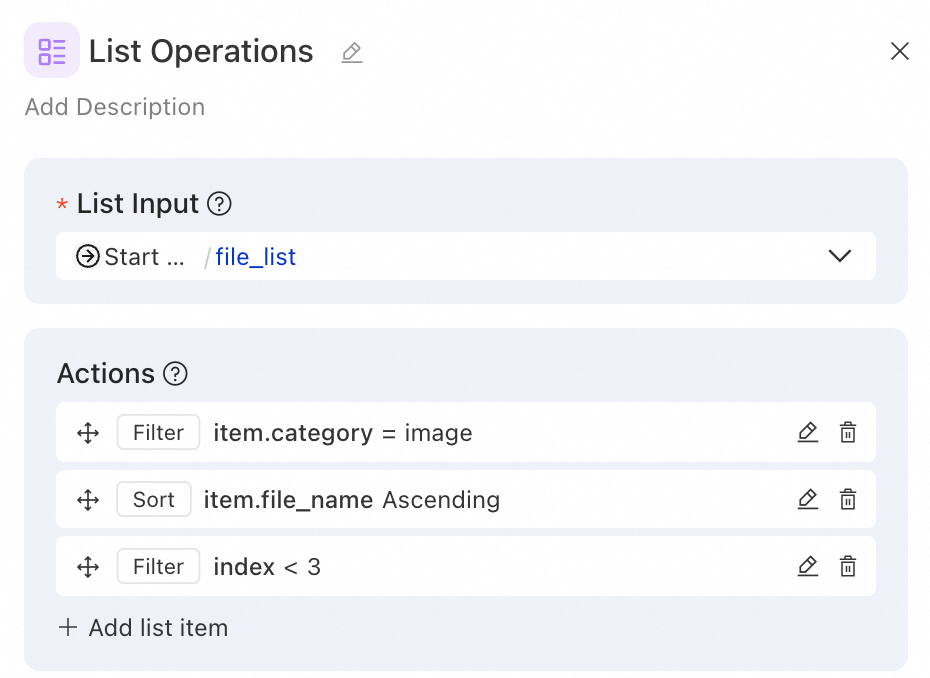
例 2:データ分析 — 高スコアのユーザーをフィルタリングし、Top 5 を取得
シナリオ:ユーザー評価リストから、スコアが 80 以上のユーザーをフィルタリングし、スコアの降順でソートして、上位 5 人を取得します。
入力リスト:
[
{"name": "Zhang San", "score": 95, "department": "Technology"},
{"name": "Li Si", "score": 72, "department": "Marketing"},
{"name": "Wang Wu", "score": 88, "department": "Technology"},
{"name": "Zhao Liu", "score": 91, "department": "Product"},
{"name": "Qian Qi", "score": 65, "department": "Marketing"},
{"name": "Sun Ba", "score": 98, "department": "Technology"}
]操作の設定:
操作 1 - フィルター (高スコアのユーザー):
フィルターキー:item.score
フィルター演算子:greater than or equal
フィルター値:80
操作 2 - ソート (スコアの降順):
ソートキー:item.score
ソート方向:desc
操作 3 - フィルター (上位 5 人):
フィルターキー:index
フィルター演算子:less than
フィルター値:5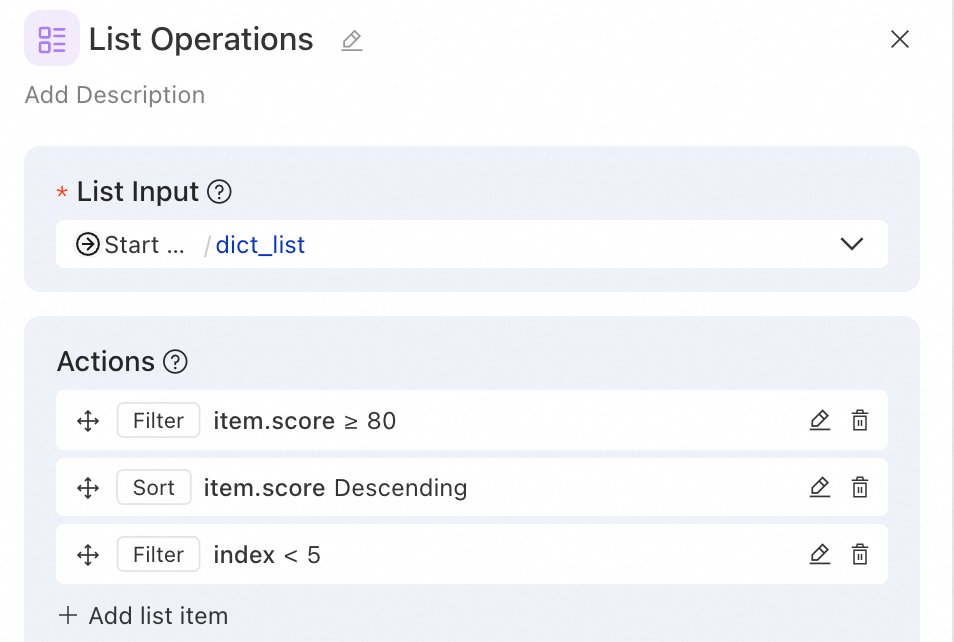
出力結果:
[
{"name": "Sun Ba", "score": 98, "department": "Technology"},
{"name": "Zhang San", "score": 95, "department": "Technology"},
{"name": "Zhao Liu", "score": 91, "department": "Product"},
{"name": "Wang Wu", "score": 88, "department": "Technology"}
]注意事項:
ツールの入力が Python ノードのカスタム
list出力変数を参照する場合、リスト操作ノードで演算子が正確に一致するように、Python ノードで明示的な要素タイプ (例:list[str]) を定義してください。