検索拡張生成 (RAG) は、大規模言語モデル (LLM) をプライベートナレッジベースに接続し、ドメイン固有のデータで応答の精度を向上させます。このガイドでは、LangStudio で RAG アプリケーションを開発し、デプロイする手順を説明します。
背景情報
RAG モデルは、情報検索と生成 AI を組み合わせることで、より正確で文脈に沿った回答を提供します。正確な情報が重要な意思決定を左右する金融やヘルスケアのようなドメインでは、従来の生成モデルは必要なドメイン固有の知識を欠いている場合があります。RAG は、モデルを外部のナレッジベースに接続することで、このギャップを埋めます。このガイドでは、Platform for AI (PAI) 上に構築された金融およびヘルスケア向けの RAG ソリューションを順を追って説明します。
前提条件
-
LangStudio は、ベクトルデータベースとして Faiss と Milvus をサポートしています。Milvus を使用する場合は、まず Milvus インスタンスを作成し、そのインスタンス内に Collection を作成する必要があります。Collection の作成方法については、Milvus の公式ドキュメントをご参照ください。
説明Faiss はテスト環境に適しており、追加のデータベース設定は不要です。本番環境では、より大規模なデータをサポートする Milvus の使用を推奨します。
-
RAG ナレッジベースのコーパスは、OSS にアップロードされている必要があります。金融およびヘルスケアのユースケース向けに、以下のサンプルコーパスが提供されています。
1. (任意) LLM と埋め込みモデルのデプロイ
RAG アプリケーションフローには、LLM サービスと埋め込みモデルサービスの両方が必要です。以下で説明するように、モデルギャラリーから必要なサービスをデプロイするか、すでに OpenAI API 互換のモデルサービスがある場合はこの手順をスキップできます。
[QuickStart] > [Model Gallery] に移動し、以下の 2 つのシナリオでモデルをデプロイします。詳細については、「モデルのデプロイとトレーニング」をご参照ください。
指示チューニング済みの 大規模言語モデルを選択してください。ベースモデルは、ユーザーの指示に確実には従えません。
-
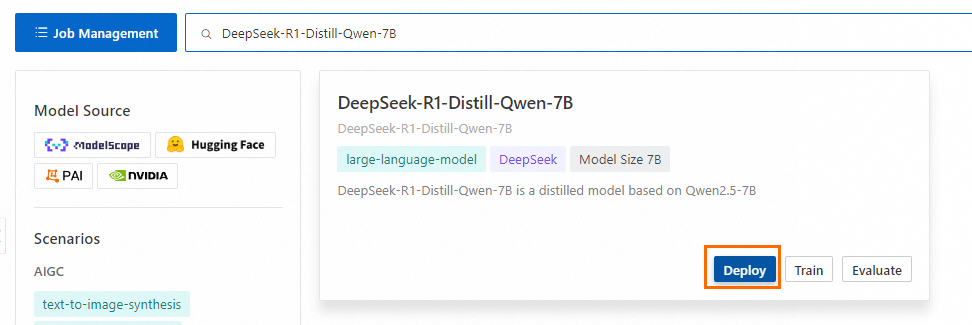
[Scenario] で Large Language Models を選択し、DeepSeek-R1-Distill-Qwen-7B をデプロイします。
-
[Scenario] で [embedding] を選択し、[bge-m3 general vector model] をデプロイします。

2. 接続の作成
このセクションの LLM と埋め込みモデルの接続では、[QuickStart] > [Model Gallery] からデプロイされた EAS サービスを使用します。他の接続タイプについては、「接続の設定」をご参照ください。
2.1 LLM サービス接続の作成
LangStudio でワークスペースを選択し、Configure Service Connection > Model Service タブに移動し、New Connection をクリックして汎用 LLM モデルサービス接続を作成します。
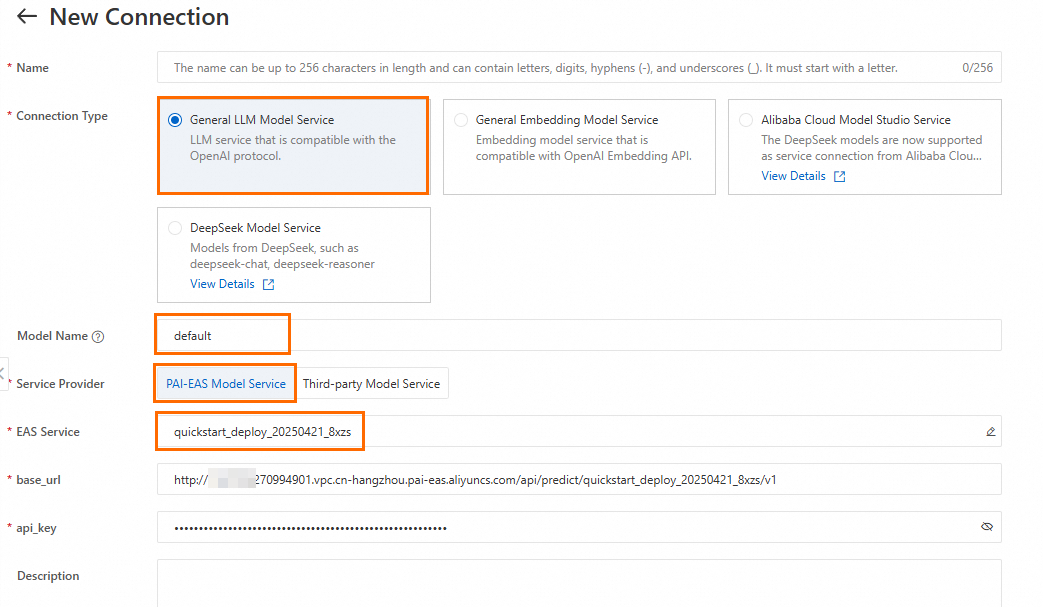
主要なパラメーター:
|
パラメーター |
説明 |
|
Model name |
モデルギャラリーからモデルをデプロイした場合、[Model Gallery] ページでモデルカードをクリックして、詳細ページでモデル名を確認します。詳細については、「接続の作成 - モデルサービス」をご参照ください。 |
|
Service provider |
|
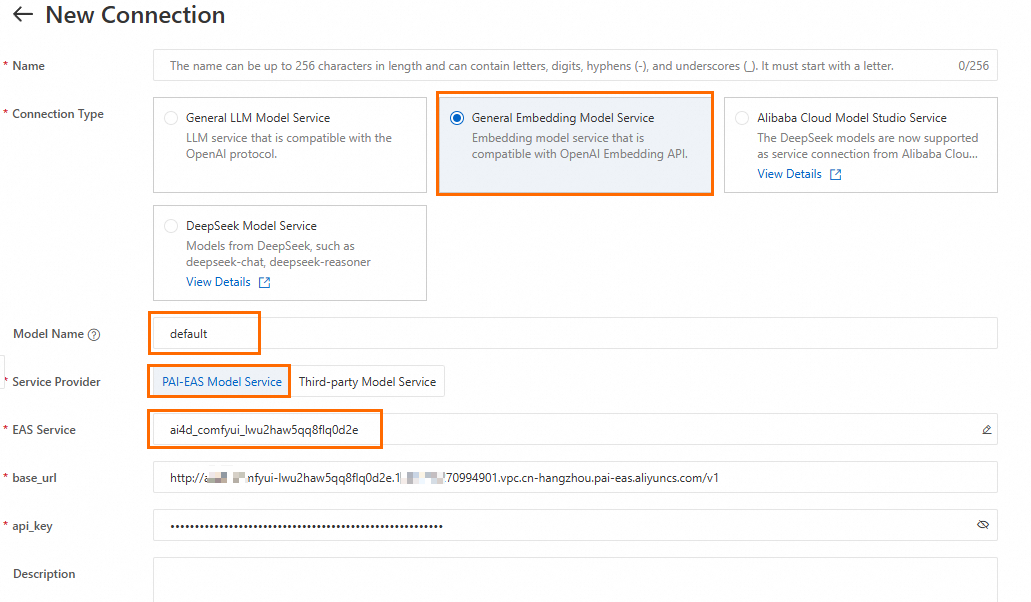
2.2 埋め込みモデルサービス接続の作成
「ステップ 2.1」と同じ手順で、汎用埋め込みモデルサービス接続を作成します。
2.3 ベクトルデータベース接続の作成
Configure Service Connection > Database タブで、New Connection をクリックして Milvus データベース接続を作成します。
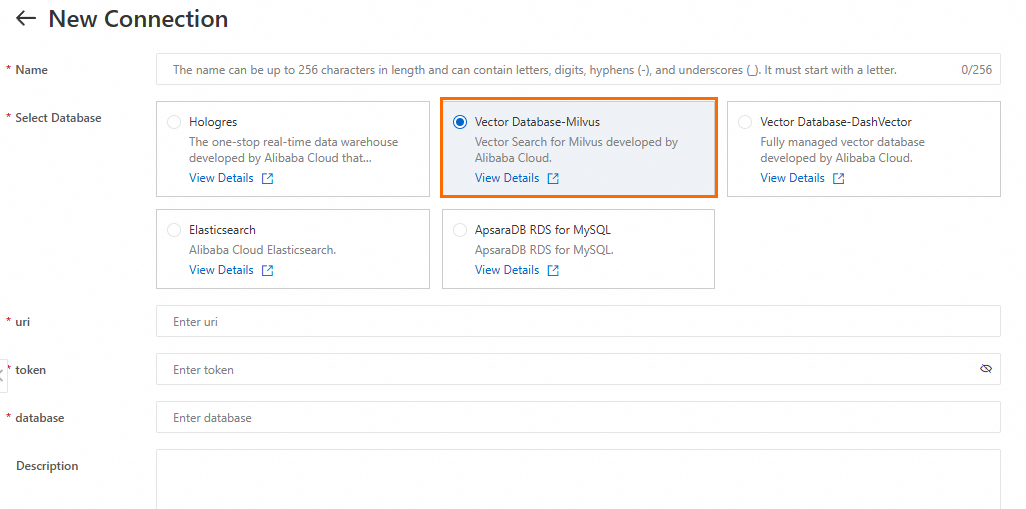
主要なパラメーター:
|
パラメーター |
説明 |
|
uri |
|
|
token |
Milvus インスタンスのユーザー名とパスワード: |
|
database |
データベース名。このトピックでは、デフォルトデータベース |
3. ナレッジベースインデックスの作成
ナレッジベースインデックスを作成します。LangStudio はコーパスを解析し、チャンキングとベクトル化を行い、結果をベクトルデータベースに保存します。次の表に主要なパラメーターを示します。その他の設定については、「ナレッジベースの管理」をご参照ください。
|
パラメーター |
説明 |
|
基本設定 |
|
|
Data source OSS path |
このパラメーターには、「前提条件」で説明されている RAG ナレッジベースコーパスの OSS パスを設定します。 |
|
Output OSS path |
ドキュメント解析による中間結果とインデックスメタデータを保存するパスを指定します。 重要
ベクトルデータベースとして Faiss を使用する場合、アプリケーションフローは生成されたインデックスファイルを OSS に保存します。デフォルトでは、デフォルトの PAI ロール (ランタイムの開始時に設定される Instance RAM Role) を使用すると、アプリケーションフローはワークスペースのデフォルトのストレージバケットにアクセスできます。したがって、このパラメーターを現在のワークスペースのデフォルトストレージパスを含む OSS バケット内のディレクトリに設定することを推奨します。カスタムロールを使用する場合は、OSS へのアクセス権限を付与してください。AliyunOSSFullAccess 権限を推奨します。詳細については、「RAM ロールの権限管理」をご参照ください。 |
|
埋め込みモデルとデータベース |
|
|
Embedding type |
General Embedding Model を選択します。 |
|
Embedding connection |
「ステップ 2.2」で作成した埋め込みモデルサービス接続を選択します。 |
|
Vector database type |
[Vector database Milvus] を選択します。 |
|
Vector database connection |
「ステップ 2.3」で作成した Milvus データベース接続を選択します。 |
|
Table name |
Milvus データベースで作成した Collection の名前。UI 上では「Table name」と表示されますが、これは Milvus の「Collection」を指します。「前提条件」セクションで説明されているように、事前に Collection を作成しておく必要があります。 |
|
VPC 設定 |
|
|
VPC configuration |
Milvus インスタンスの VPC と同じ、または通信可能な VPC を選択します。 |
4. RAG アプリケーションフローの作成と実行
-
LangStudio に移動し、ワークスペースを選択してから、[Application Flow] タブで [New Application Flow] をクリックして RAG アプリケーションフローを作成します。
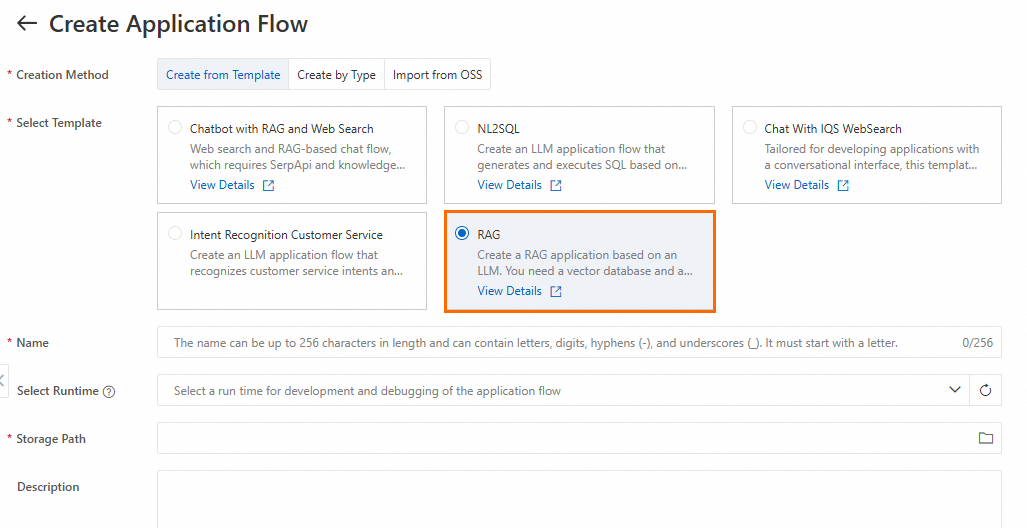
-
ランタイムを開始します。右上隅で Create Runtime をクリックし、パラメーターを設定します。注意:Python ノードを解析したり、より多くのツールにアクセスしたりする前に、ランタイムが実行中である必要があります。
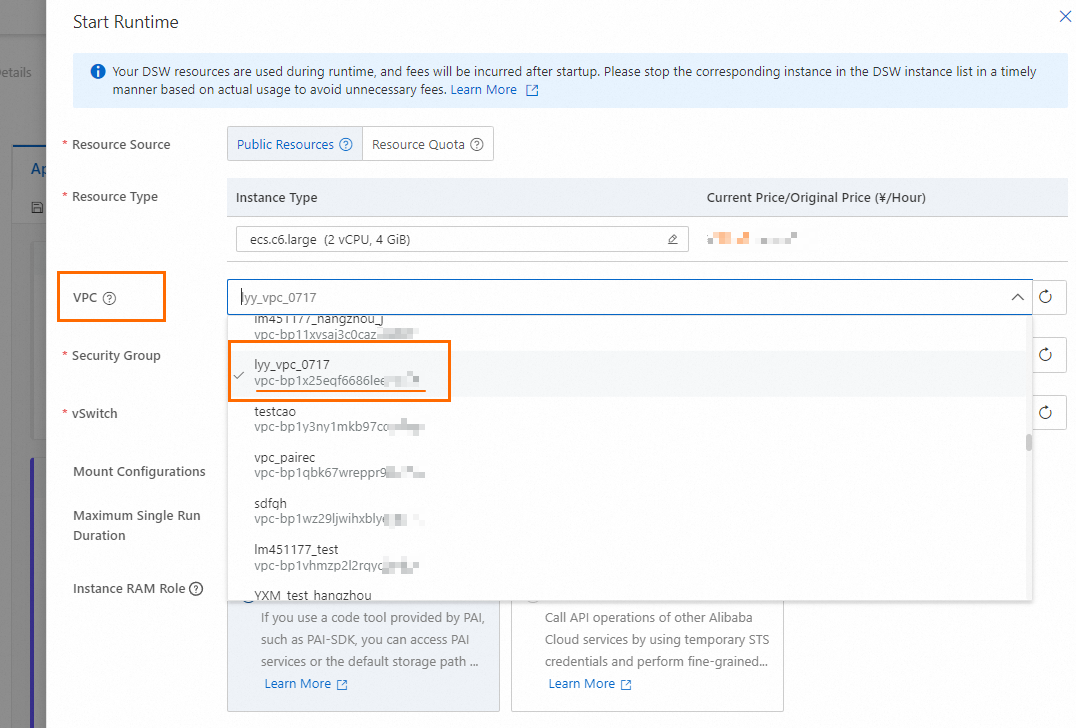
主要なパラメーター:
VPC 設定:「前提条件」で Milvus インスタンスを作成するために使用した VPC を選択するか、選択した VPC が Milvus インスタンスの VPC と通信できることを確認してください。
-
アプリケーションフローを開発します。

他のノードはデフォルト設定のままにするか、必要に応じて調整してください。主要なノードを次のように設定します。
-
ナレッジ検索:ユーザーの質問に関連するテキストをナレッジベースから取得します。
-
ナレッジベースインデックス名:「ステップ 3」で作成したナレッジベースインデックスを選択してください。
-
Top K:一致する結果の上位 K 件を返します。
-
-
LLM ノード:取得したドキュメントをコンテキストとして使用し、ユーザーの質問と一緒に大規模言語モデルに送信し、応答を生成します。
-
モデル設定:「ステップ 2.1」で作成した接続を選択してください。
-
チャット履歴:チャット履歴を有効にし、過去の会話を入力変数として使用するかどうかを指定します。
-
各コンポーネントの詳細については、「事前構築済みコンポーネントライブラリ」をご参照ください。
-
-
フローをデバッグまたは実行します。右上隅で Run をクリックしてフローを実行します。一般的なランタイムの問題については、「FAQ」をご参照ください。
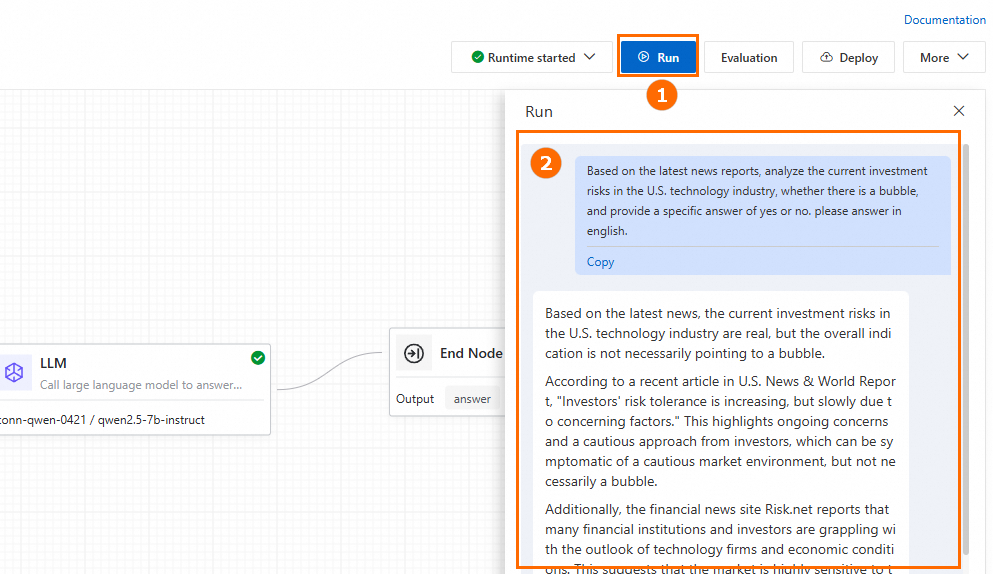
-
トレースを表示します。生成された回答の下にある View Traces をクリックして、トレースの詳細またはトポロジーを表示します。
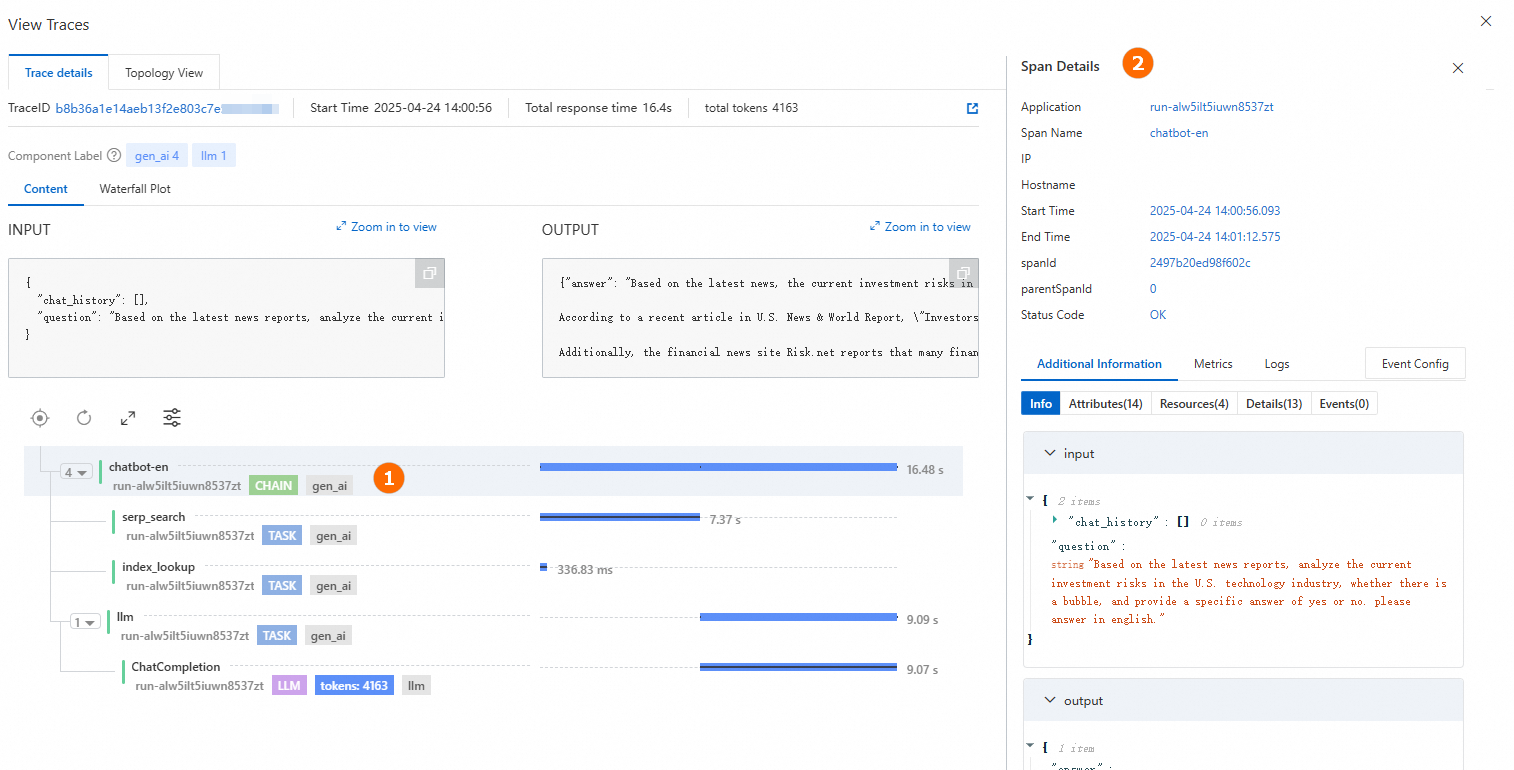
5. アプリケーションフローのデプロイ
アプリケーションフロー開発ページで、右上隅の Deploy をクリックして、アプリケーションフローを EAS サービスとしてデプロイします。他のデプロイ設定はデフォルトのままにするか、必要に応じて調整してください。次の主要なパラメーターを設定します。
-
リソースデプロイ > インスタンス:サービスインスタンスの数を設定してください。このデプロイはテスト目的であるため、インスタンス数を 1 に設定します。本番環境では、単一障害点 (SPOF) のリスクを軽減するために、複数のサービスインスタンスを使用することを推奨します。
-
VPC > VPC:Milvus インスタンスが存在する VPC を選択するか、選択した VPC が Milvus インスタンスが存在する VPC と通信できることを確認してください。
デプロイの詳細については、「アプリケーションフローのデプロイ」をご参照ください。
6. サービスの呼び出し
デプロイ後、PAI-EAS コンソールにリダイレクトされます。Debug タブで、リクエストを設定して送信します。リクエストボディのキーは、アプリケーションフローの「Start」ノードにある「Dialogue input」パラメーターと一致させる必要があります。このガイドで使用するデフォルトのフィールドは questionです。

API を使用するなど、他のサービス呼び出し方法については、「サービスの呼び出し」をご参照ください。