LangStudio で Web 検索と検索拡張生成 (RAG) を備えたチャットアシスタントアプリケーションフローを構築します。このフローは、リアルタイムの Web 検索と検索拡張生成 (RAG) を統合し、モデルがドメイン固有のナレッジベースとリアルタイムの Web データの両方にアクセスできるようにすることで、より正確な回答を生成できます。
背景情報
このアプリケーションフローは、RAG とリアルタイムの Web 検索を組み合わせて、正確な回答を提供します。モデルはドメイン固有のナレッジを取得し、それをリアルタイムの Web データで補完します。これは、金融やヘルスケアなどの高精度が求められるドメインで特に効果的です。
前提条件
-
SerpApi の公式サイトで登録し、
api_keyを取得します。 -
Milvus を使用するには、Milvus インスタンスを作成します。
説明Faiss はテスト用であり、個別のデータベースは必要ありません。本番環境では、大規模データ用に Milvus を使用してください。
-
RAG ナレッジベースのコーパスを OSS にアップロードします。
1. (任意) LLM と埋め込みモデルのデプロイ
モデルギャラリーから必要なモデルサービスをデプロイします。互換性のあるモデルサービスが既にある場合は、この手順をスキップしてください。
[Quick Start] > [Model Gallery] に移動し、次の 2 つのシナリオのモデルをデプロイします。詳細については、「モデルのデプロイとトレーニング」をご参照ください。
指示チューニング済みの LLM を使用してください。ベースモデルは、ユーザーの指示に正しく従うことができません。
-
[Scenario] には Large Language Models を選択します。この例では [DeepSeek-R1] を使用します。詳細については、「DeepSeek-V3 および DeepSeek-R1 モデルのワンクリックデプロイ」をご参照ください。
-
[Scenario] には [Embedding] を選択します。この例では、汎用ベクトルモデルの [bge-m3] を使用します。
2. 接続の作成
このガイドの LLM および埋め込みモデルサービスの接続は、QuickStart > [Model Gallery] からデプロイされた EAS サービスに基づいています。他の接続タイプと設定については、「接続の設定」をご参照ください。
2.1 LLM 接続の作成
-
LangStudio に移動し、リージョンとワークスペースを選択します。
-
Connection > Model Service タブで New Connection をクリックし、次のパラメーターを設定します:
-
Connection Type:General LLM Service を選択します。
-
Service Provider:PAI-EAS Model Service を選択します。
-
EAS Service:手順 1 でデプロイした LLM サービスを選択します。
サービスを選択すると、LangStudio はデプロイされた LLM の VPC エンドポイントとトークンを使用して、
base_urlフィールドとapi_keyフィールドを自動的に入力します。 -
Model Name:OpenAI API リクエストの
modelパラメーターの値です。[Model Gallery] でモデルカードをクリックして、モデル詳細ページで確認します。 -
[Tool Call]、Structured output、Deep Reasoning、Vision:モデルの機能に基づいてこれらのオプションを有効にします。
-
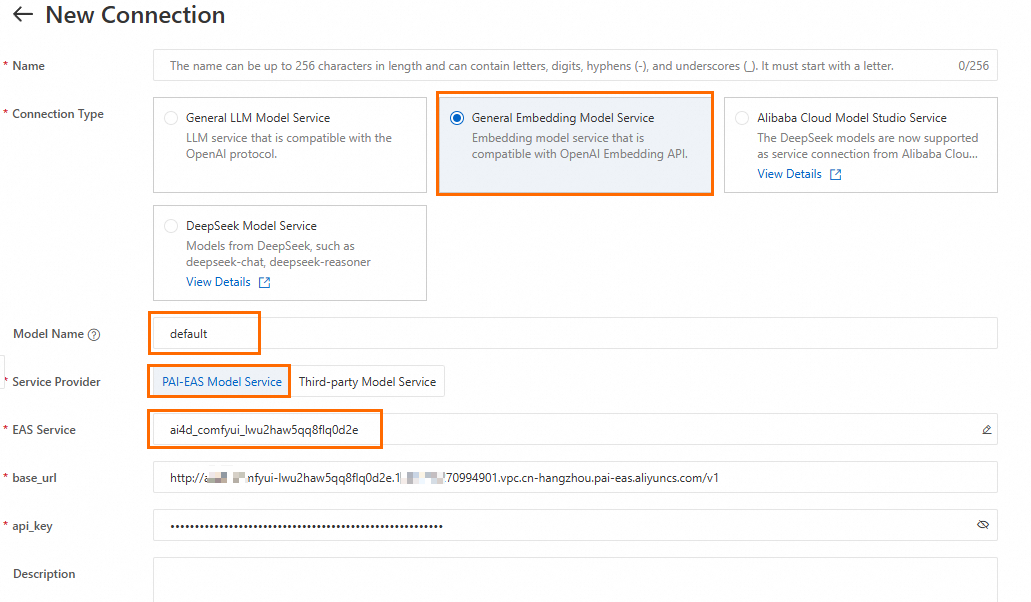
2.2 埋め込みモデル接続の作成
セクション 2.1 と同じ手順で埋め込みモデル接続を作成します。
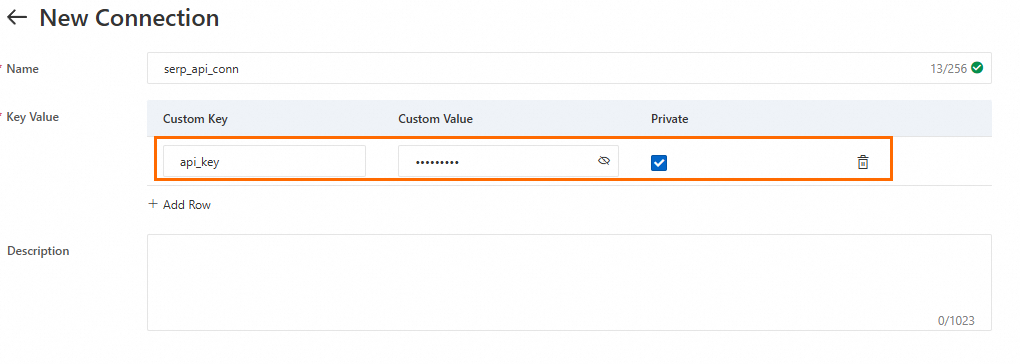
2.3 SerpApi 接続の作成
Connection > Custom タブで、New Connection をクリックして SerpApi 接続を作成します。「前提条件」セクションで取得した api_key を設定します。
3. ナレッジベースインデックスの作成
ナレッジベースインデックスを作成して、コーパスを解析、チャンク化、ベクトル化してベクトルデータベースに格納します。主要なパラメーターを以下に示します。詳細については、「ナレッジベースの管理」をご参照ください。
|
パラメーター |
説明 |
|
基本設定 |
|
|
データソース OSS パス |
「前提条件」セクションの RAG ナレッジベースのコーパスへの OSS パスを指定します。 |
|
出力 OSS パス |
ドキュメント解析中に生成される中間結果とインデックスデータのパスです。 重要
FAISS を使用する場合、フローはインデックスファイルを OSS に保存します。デフォルトの PAI ロール (ランタイムの開始時に設定される Instance RAM Role) を使用すると、フローはワークスペースのデフォルトストレージバケットにアクセスできます。このパラメーターを ワークスペースのデフォルトストレージパス と同じ OSS バケット内のディレクトリに設定してください。カスタムロールを使用する場合は、そのロールに OSS へのアクセス権を付与してください (AliyunOSSFullAccess を推奨します)。詳細については、「RAM ロールの権限管理」をご参照ください。 |
|
埋め込みモデルとデータベース |
|
|
埋め込みタイプ |
General Embedding Model Service を選択します。 |
|
埋め込み接続 |
セクション 2.2 で作成した埋め込みモデルサービス接続を選択します。 |
|
ベクトルデータベースタイプ |
FAISS を選択します。このガイドでは FAISS を例として使用します。 |
4. アプリケーションフローの作成と実行
-
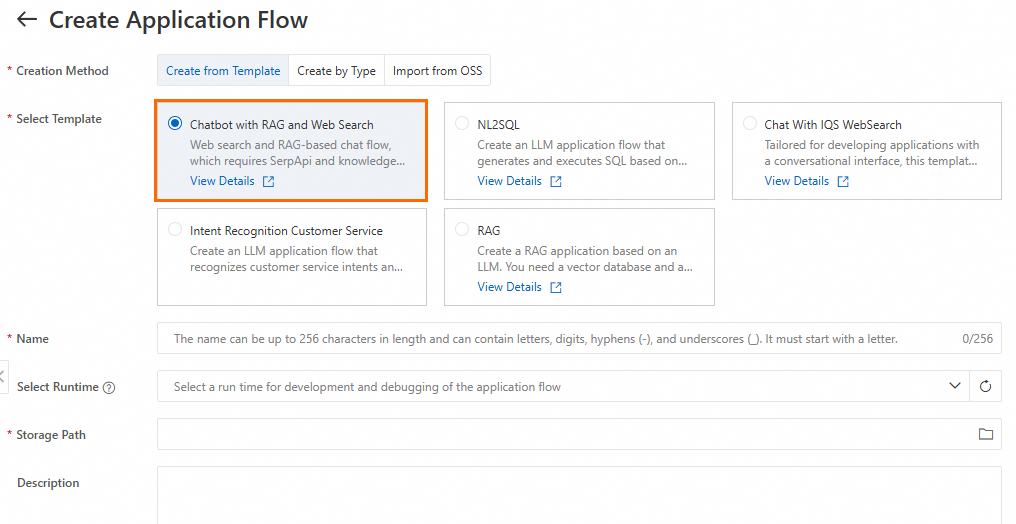
LangStudio に移動し、ワークスペースを選択して [Application Flows] タブに移動し、[New Application Flow] をクリックして、Web 検索と RAG を備えたチャットアシスタントフローを作成します。
-
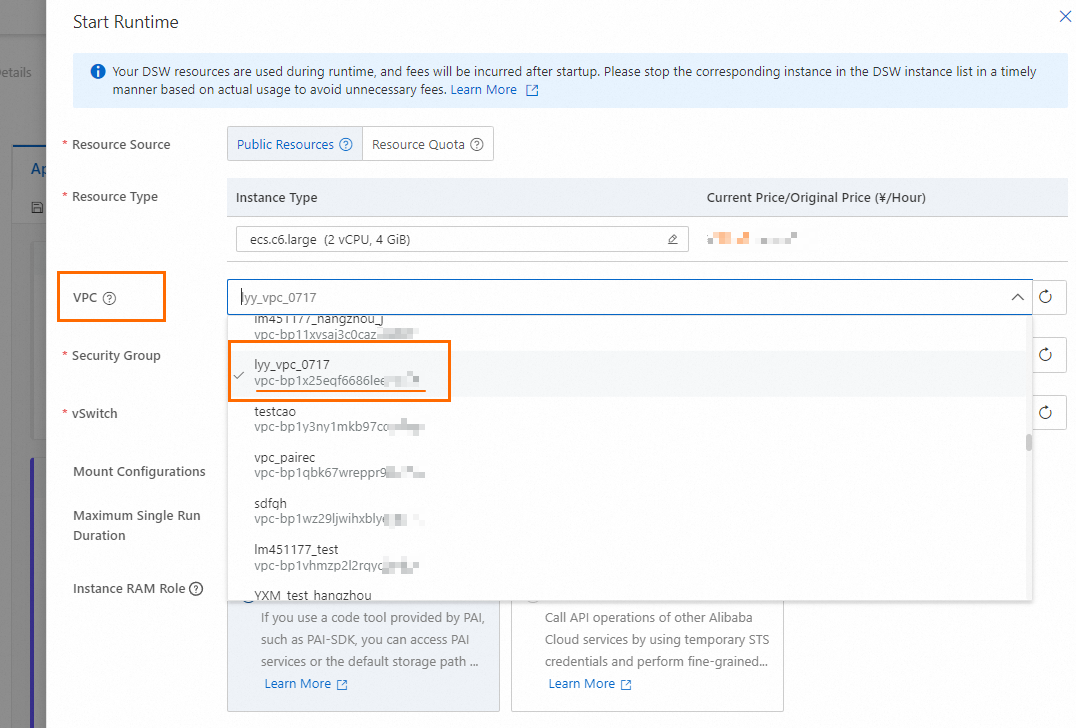
右上隅にある Select Runtime をクリックしてランタイムを選択します。Python ノードを解析したり、より多くのツールを表示したりするには、実行中のランタイムが必要です。
利用可能なランタイムがない場合は、Runtime タブの [LangStudio] ページに移動し、New Runtime をクリックして作成します。
 主要なパラメーター:
主要なパラメーター:VPC 設定:手順 3 で Milvus を選択した場合は、Milvus インスタンスと同じ VPC、または相互接続された VPC を使用します。FAISS は VPC 設定を必要としません。
-
アプリケーションフローを開発します。
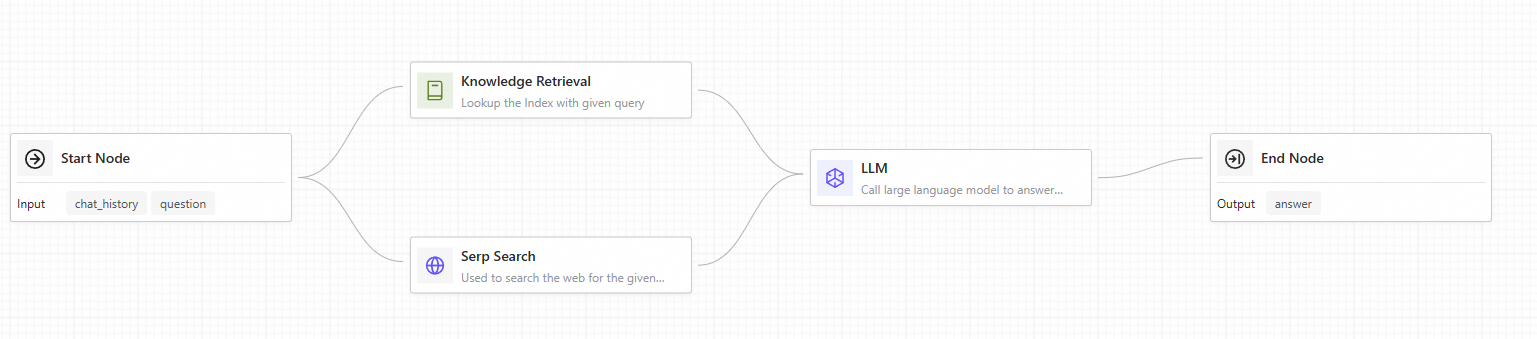
残りの設定はデフォルトのままにするか、必要に応じて調整します。主要なノード設定:
-
ナレッジベース検索:ナレッジベースから関連テキストを取得します。
-
ナレッジベースインデックス名:手順 3 で作成したナレッジベースインデックスを選択します。
-
Top K:上位 K 件の一致する結果を返します。
-
-
Serp Search:SerpApi を介して Web を検索し、結果を返します。
-
SerpApi 接続:セクション 2.3 で作成した SerpApi 接続を選択します。
-
検索エンジン:Bing、Google、Baidu、Yahoo、およびカスタム入力をサポートしています。サポートされているエンジンとパラメーターについては、SerpApi の公式サイトをご参照ください。
-
-
大規模モデルノード:取得したドキュメントと検索結果をコンテキストとしてユーザーのクエリとともに LLM に送信し、応答を生成します。
-
モデル設定:セクション 2.1 で作成した接続を選択します。
-
会話履歴:会話履歴を入力変数として有効にします。
-
詳細については、「プリセットコンポーネントリファレンス」をご参照ください。
-
-
右上隅にある Run をクリックしてアプリケーションフローを実行します。一般的な問題のトラブルシューティングについては、「FAQ」をご参照ください。
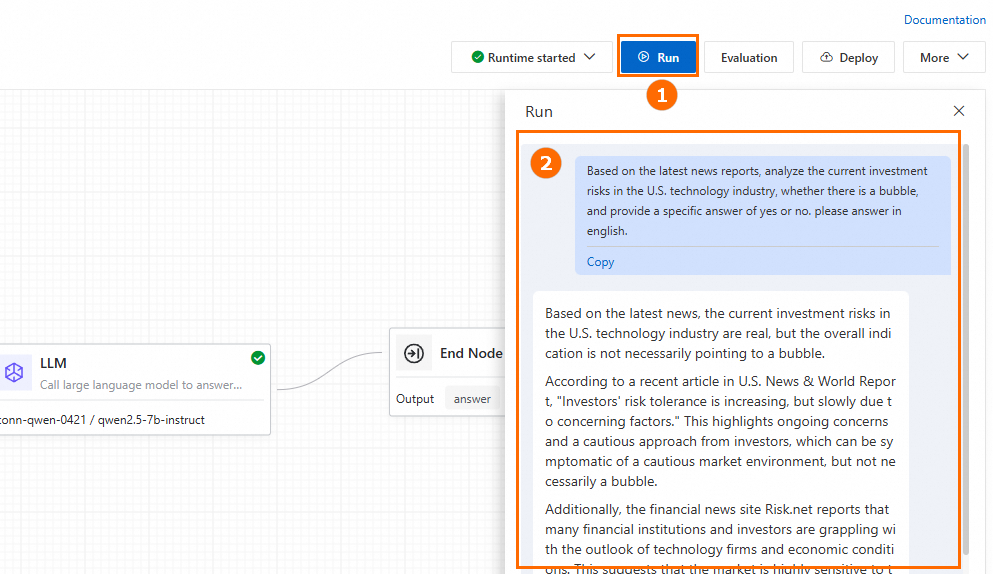
-
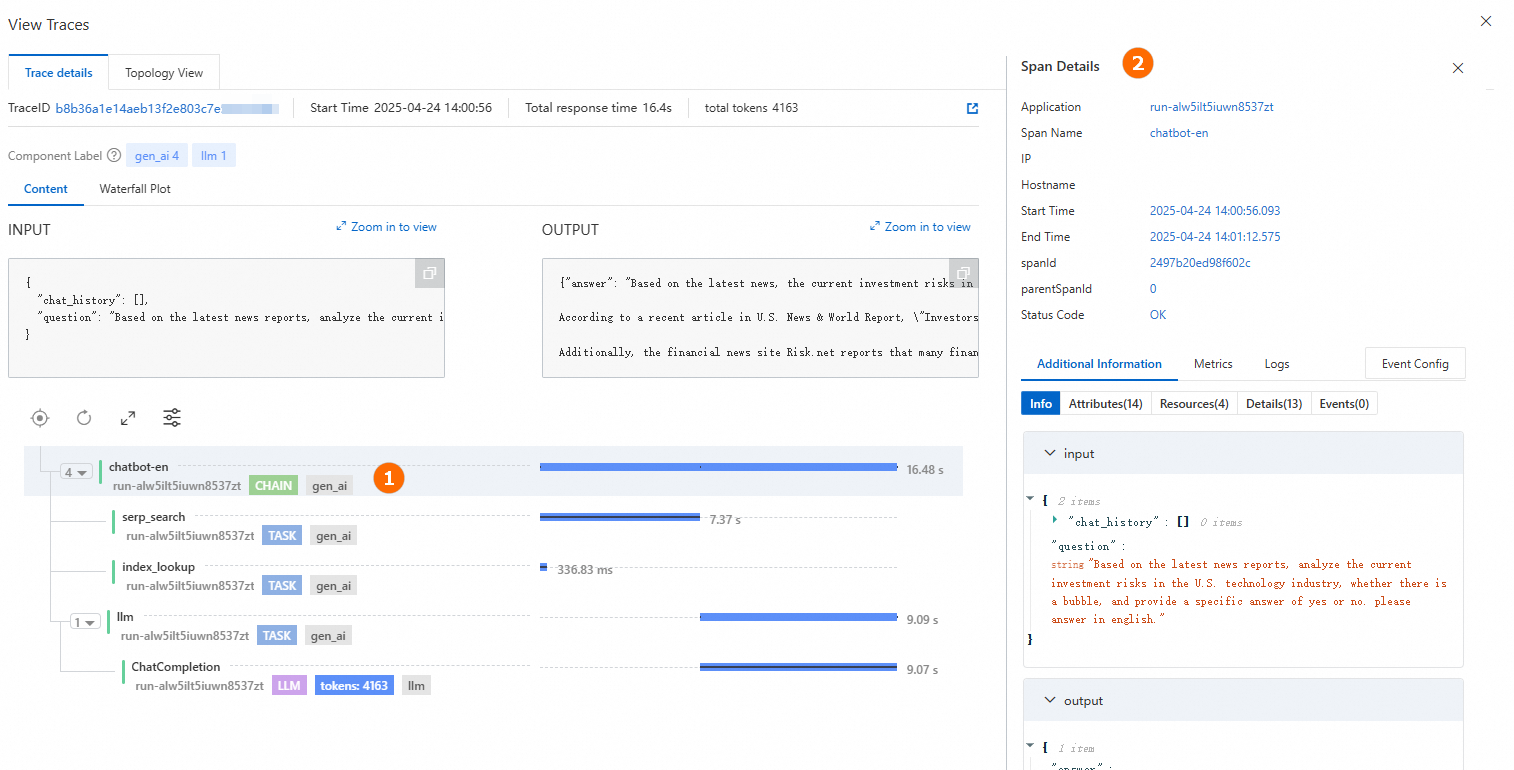
生成された回答の下にある View Traces をクリックして、トレースの詳細またはトポロジービューを表示します。
5. アプリケーションフローのデプロイ
アプリケーションフロー開発ページで、右上隅にある Deploy をクリックして、フローを EAS サービスとしてデプロイします。主要なパラメーター:
-
Resource Information > Instances:サービスインスタンスの数を設定します。テストの場合は 1 に設定します。本番環境では、単一障害点を防ぐために複数のインスタンスを使用してください。
-
VPC > VPC:SerpApi はパブリックインターネットアクセスを必要とするため、この機能を備えた VPC を設定します。デフォルトでは EAS サービスにはこの機能がありません。詳細については、「EAS サービスがパブリックリソースまたは内部リソースにアクセスできるようにする」をご参照ください。手順 3 で Milvus を選択した場合は、Milvus インスタンスと同じ VPC を使用するか、VPC が相互接続されていることを確認してください。
詳細については、「アプリケーションフローのデプロイ」をご参照ください。
6. サービスの呼び出し
デプロイ後、PAI-EAS コンソールにリダイレクトされます。Debug タブでリクエストを送信します。リクエストボディのキーは、アプリケーションフローの [Start] ノードの [Conversation Input] フィールドと一致する必要があります。デフォルトのフィールド名は question です。

API 呼び出しを含む他の呼び出し方法については、「アプリケーションフローのデプロイ - サービスの呼び出し」をご参照ください。